머신러닝
├─ 지도학습 (Supervised Learning)
├─ 비지도학습 (Unsupervised Learning)
└─ 차원축소 (Dimensionality Reduction)
https://standout.tistory.com/1745
머신러닝이란?: 기원과 정의, 한계와 문제점
기원Machine Learning 데이터으 지능적인 행동에 따른 컴퓨터 알고리즘 개발 및 연구분야 머신러닝이란, 데이터를 이용해 컴퓨터가 스스로 규칙(패턴)을 학습하고, 이를 기반으로 예측이나 판단을
standout.tistory.com
지도학습 (Supervised Learning): 정답이있는데이터, 값을예측하는 회귀, 카테고리를 맞추는 분류, 여러개모델을 합치는앙상블
https://standout.tistory.com/1533
기계학습과 기계학습의 분야: 지도학습/비지도학습/강화학습
기계학습과 기계학습의 분야 기계학습이란?인공지능(AI)의 한 분야데이터와 통계적 모델링 기법을 사용하여 컴퓨터 시스템이 스스로 학습할 수 있게 만드는 기술https://standout.tistory.com/1529 자동
standout.tistory.com
대표앙상블
Bagging(Random Forest): 여러 트리를 병렬로 만들어 투표.
Random Forest: Bagging에서 특정중요한 변수를 트리 대부분에서 써버리면 비슷해져 다양한 의견을 듣지 못하고 전부 비슷한 내용만 알게 된다 .이때 사용할 특성을 랜덤으로 제한해서 보완한것을 말함.
Boosting: bagging은 트리들이 동시에 학습했으나 Boostring은 앞 모델이 틀린 문제를 뒤 모델이 집중적으로공부한다 .
AdaBoost : 최초의 Boostinㅎ 알고리즘으로 틀린문제에 가중치를 준다. 틀린데이터를 중요데이터로 인식하는것.
Gradient Boosting: AdaBoost는 틀린데이터 찾기라면 Gradient Boosting은 오차 자체를 학습해 실제값이 100이고 예측값이 80이었다면 오차값 20을 줄이는 방향으로 학습해 성능이 점점 좋아진다. XGBoost, LightGBM, CatBoost 모두 같은 계열
https://standout.tistory.com/1767
머신러닝의 Ensemble Learning 앙상블이란?
Ensemble Learning 앙상블이란?여러 뜻이있으나,, 머신러닝중점으로 이해해보자 . 여러개의 모델을 함께 사용해서 하나의 더 강한 모델을 만드는 방법과적합, 성능 흔들림, 특정 패턴에 약함 등의 모
standout.tistory.com
샘플코드 decision_tree_torch_bagging_added 를 분석해보자.
어제 작성했던 코드에 앙상블을 추가한것이다.
데이터 처리(pandas, numpy), 머신러닝 전처리(sklearn), 딥러닝(PyTorch), 시각화(matplotlib) 주요 라이브러리
sk.learn.compose.ColumnTransformer 수치형/범주형 컬럼에 서로 다른 전처리를 사용할때.
sklearn.preprocessing oneHotEndoder, StandardScaler, LabelEncoder 문자 범주데이터를 0~1숫자로 변환
Pipeline 여러 전처리 단계를 하나로 묶어 실행
sklearn.metrics accuracy_score, confusion_matrix, classification_report 모델 평가지표 계산
GPU(cuda) 사용 가능 여부를 확인하여 학습 장치를 설정하고 출력한다.
# ============================================================
# 1. 필요한 라이브러리 불러오기
# ============================================================
# pandas는 CSV 파일을 읽고 표 형태의 데이터를 다루기 위한 라이브러리입니다.
import pandas as pd
# numpy는 숫자 배열 계산을 빠르게 처리하기 위한 라이브러리입니다.
import numpy as np
# torch는 PyTorch의 핵심 라이브러리입니다.
# 텐서 생성, 신경망 학습, 자동 미분 등을 처리합니다.
import torch
# torch.nn은 신경망 계층, 손실 함수 등을 만들 때 사용하는 모듈입니다.
import torch.nn as nn
# torch.optim은 Adam, SGD 같은 최적화 알고리즘을 제공하는 모듈입니다.
import torch.optim as optim
# Dataset과 DataLoader는 데이터를 PyTorch 모델에 넣기 좋은 형태로 관리하는 도구입니다.
from torch.utils.data import Dataset, DataLoader
# train_test_split은 데이터를 학습용과 테스트용으로 나누는 함수입니다.
from sklearn.model_selection import train_test_split
# ColumnTransformer는 수치형/범주형 컬럼에 서로 다른 전처리를 적용할 때 사용합니다.
from sklearn.compose import ColumnTransformer
# OneHotEncoder는 문자 범주 데이터를 0과 1의 숫자 벡터로 변환합니다.
from sklearn.preprocessing import OneHotEncoder, StandardScaler, LabelEncoder
# Pipeline은 여러 전처리 단계를 하나로 묶어 실행할 때 사용합니다.
from sklearn.pipeline import Pipeline
# accuracy_score와 confusion_matrix는 모델 평가 지표를 계산합니다.
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# matplotlib은 그래프를 그리기 위한 라이브러리입니다.
import matplotlib.pyplot as plt
# random은 파이썬의 난수 생성을 제어할 때 사용합니다.
import random
# os는 파일 경로 확인 등에 사용합니다.
import os
# 경고 메시지를 줄여 출력 화면을 깔끔하게 만들기 위해 사용합니다.
import warnings
# 불필요한 경고 메시지를 숨깁니다.
warnings.filterwarnings("ignore")
# 현재 사용 가능한 장치를 확인합니다.
# Colab에서 GPU를 켜면 cuda가 출력되고, 그렇지 않으면 cpu가 출력됩니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 현재 학습에 사용할 장치를 출력합니다.
print("사용 장치:", device)
난수를 코드를 다시 실행해도 최대한 같은 결과가 나오도록 한다 .
# ============================================================
# 2. 난수 고정
# ============================================================
# 난수를 고정하면 코드를 다시 실행해도 최대한 같은 결과가 나오도록 만들 수 있습니다.
SEED = 123
# 파이썬 random 라이브러리의 난수를 고정합니다.
random.seed(SEED)
# numpy 난수를 고정합니다.
np.random.seed(SEED)
# PyTorch CPU 연산의 난수를 고정합니다.
torch.manual_seed(SEED)
# PyTorch GPU 연산의 난수를 고정합니다.
torch.cuda.manual_seed_all(SEED)
# CUDA 연산의 재현성을 높이기 위한 설정입니다.
torch.backends.cudnn.deterministic = True
# 실행 속도 최적화보다 재현성을 우선하도록 설정합니다.
torch.backends.cudnn.benchmark = False
데이터를 불러오고 공개데이터에서 가져왔을때를 대비해 라벨명 일부가 다를경우 변경한다 .
# ============================================================
# 3. 데이터 불러오기
# ============================================================
# 사용한 파일 경로입니다.
local_path = "data/credit_info.csv"
# 공개 German Credit 데이터셋 주소입니다.
# Colab에서 data/credit_info.csv 파일이 없을 때 자동으로 읽어옵니다.
url = "https://raw.githubusercontent.com/stedy/Machine-Learning-with-R-datasets/master/credit.csv"
# data 폴더가 없으면 새로 생성합니다.
os.makedirs("data", exist_ok=True)
# local_path 파일이 실제로 존재하는지 확인합니다.
if os.path.exists(local_path):
# 파일이 있으면 사용자가 제공한 로컬 CSV 파일을 읽습니다.
credit_info = pd.read_csv(local_path)
else:
# 파일이 없으면 공개 URL에서 CSV 파일을 읽습니다.
credit_info = pd.read_csv(url)
# 다음 실행 때도 같은 파일을 사용할 수 있도록 data 폴더에 저장합니다.
credit_info.to_csv(local_path, index=False)
# 목표 변수를 Repay라고 사용합니다.
# 공개 데이터셋은 목표 컬럼명이 default일 수 있으므로 Repay로 바꿉니다.
if "Repay" not in credit_info.columns and "default" in credit_info.columns:
# default 컬럼명을 Repay로 변경합니다.
credit_info = credit_info.rename(columns={"default": "Repay"})
# 데이터의 앞부분 5행을 확인합니다.
credit_info.head()
데이터구조를 확인하고 기본정보를 탐색한다.
# ============================================================
# 4. 데이터 구조 확인
# ============================================================
# 데이터의 행과 열 개수를 확인합니다.
print("데이터 크기:", credit_info.shape)
# 각 컬럼의 자료형과 결측치 여부를 확인합니다.
credit_info.info()
# 컬럼 이름 목록을 출력합니다.
print("\n컬럼 목록:")
print(credit_info.columns.tolist())# ============================================================
# 5. 기본 탐색
# ============================================================
# checking_balance 컬럼은 신청자의 수표 계좌 잔고 범주를 의미합니다.
# value_counts()는 R의 table()과 비슷하게 값별 개수를 세어 줍니다.
print("checking_balance 빈도:")
print(credit_info["checking_balance"].value_counts())
# savings_balance 컬럼은 신청자의 저축 계좌 잔고 범주를 의미합니다.
print("\nsavings_balance 빈도:")
print(credit_info["savings_balance"].value_counts())
# months_loan_duration은 대출 기간입니다.
# describe()는 평균, 표준편차, 최솟값, 최댓값 등을 보여줍니다.
print("\nmonths_loan_duration 요약:")
print(credit_info["months_loan_duration"].describe())
# amount는 대출 금액입니다.
print("\namount 요약:")
print(credit_info["amount"].describe())
# Repay는 상환 여부 또는 채무불이행 여부를 나타내는 목표 변수입니다.
print("\nRepay 빈도:")
print(credit_info["Repay"].value_counts())
# Repay 비율을 확인합니다.
print("\nRepay 비율:")
print(credit_info["Repay"].value_counts(normalize=True))
x와 y를 분리한다.
수치형과 범주형 컬럼을 구분하고
학습, 테스트 데이터를 분리한다.
# ============================================================
# 6. 입력 X와 정답 y 분리
# ============================================================
# 목표 컬럼명을 변수로 저장합니다.
target_col = "Repay"
# 목표 컬럼이 실제 데이터에 있는지 확인합니다.
if target_col not in credit_info.columns:
# 목표 컬럼이 없으면 에러를 발생시켜 문제 원인을 바로 알 수 있게 합니다.
raise ValueError("데이터에 Repay 컬럼이 없습니다. 목표 컬럼명을 확인하세요.")
# X는 Repay를 제외한 모든 컬럼입니다.
X = credit_info.drop(columns=[target_col])
# y는 모델이 예측해야 하는 Repay 컬럼입니다.
y = credit_info[target_col]
# LabelEncoder는 문자 라벨을 숫자 라벨로 바꿉니다.
# 예: no -> 0, yes -> 1 과 같은 방식입니다.
label_encoder = LabelEncoder()
# y 값을 숫자 형태로 변환합니다.
y_encoded = label_encoder.fit_transform(y)
# 어떤 원래 라벨이 어떤 숫자로 바뀌었는지 확인합니다.
print("라벨 매핑:")
for original_label, encoded_label in zip(label_encoder.classes_, range(len(label_encoder.classes_))):
print(f"{original_label} -> {encoded_label}")# ============================================================
# 7. 수치형 컬럼과 범주형 컬럼 구분
# ============================================================
# 수치형 컬럼은 int64, float64 같은 숫자 자료형 컬럼입니다.
numeric_features = X.select_dtypes(include=["int64", "float64"]).columns.tolist()
# 범주형 컬럼은 object, category 같은 문자 또는 범주 자료형 컬럼입니다.
categorical_features = X.select_dtypes(include=["object", "category", "bool"]).columns.tolist()
# 수치형 컬럼 목록을 출력합니다.
print("수치형 컬럼:", numeric_features)
# 범주형 컬럼 목록을 출력합니다.
print("범주형 컬럼:", categorical_features)# ============================================================
# 8. 학습 데이터와 테스트 데이터 분리
# ============================================================
# train_test_split은 데이터를 학습용과 테스트용으로 나눕니다.
# test_size=0.2는 전체 데이터의 20%를 테스트용으로 사용한다는 뜻입니다.
# 800개 학습 / 200개 테스트 분리와 같은 비율입니다.
# stratify=y_encoded는 정답 라벨 비율이 학습/테스트에 비슷하게 유지되도록 합니다.
X_train, X_test, y_train, y_test = train_test_split(
X,
y_encoded,
test_size=0.2,
random_state=SEED,
stratify=y_encoded
)
# 분리된 데이터 크기를 확인합니다.
print("X_train 크기:", X_train.shape)
print("X_test 크기:", X_test.shape)
print("y_train 크기:", y_train.shape)
print("y_test 크기:", y_test.shape)
# 학습 데이터의 클래스 비율을 확인합니다.
print("\n학습 데이터 클래스 비율:")
print(pd.Series(y_train).value_counts(normalize=True).sort_index())
# 테스트 데이터의 클래스 비율을 확인합니다.
print("\n테스트 데이터 클래스 비율:")
print(pd.Series(y_test).value_counts(normalize=True).sort_index())
수치형데이터를 standardscaler로 표준화하고
범주형 데이터를 onehotencoder로 숫자벡터화한다.
columtransformer은 컬럼 종류별로 다른 전처리를 한다 .
학습데이터는 fit.transform, 테스트는 transform 만 진행한다.
pytorch 가 지원하는 float32fh astype한다.
정답은 long타입 int64로 astype한다.
# ============================================================
# 9. 전처리 파이프라인 생성
# ============================================================
# 수치형 데이터 전처리: StandardScaler로 표준화합니다.
numeric_transformer = Pipeline(
steps=[
# StandardScaler는 수치 데이터의 크기 차이를 줄여 학습을 안정적으로 만듭니다.
("scaler", StandardScaler())
]
)
# 범주형 데이터 전처리: OneHotEncoder로 숫자 벡터화합니다.
categorical_transformer = Pipeline(
steps=[
# handle_unknown="ignore"는 테스트 데이터에 학습 때 보지 못한 범주가 나와도 에러를 막습니다.
("onehot", OneHotEncoder(handle_unknown="ignore"))
]
)
# ColumnTransformer는 컬럼 종류별로 다른 전처리를 적용합니다.
preprocessor = ColumnTransformer(
transformers=[
# numeric_features 컬럼에는 numeric_transformer를 적용합니다.
("num", numeric_transformer, numeric_features),
# categorical_features 컬럼에는 categorical_transformer를 적용합니다.
("cat", categorical_transformer, categorical_features)
]
)
# fit_transform은 학습 데이터 기준으로 전처리 규칙을 학습하고 바로 변환합니다.
X_train_processed = preprocessor.fit_transform(X_train)
# transform은 학습 데이터에서 만든 규칙을 테스트 데이터에 그대로 적용합니다.
X_test_processed = preprocessor.transform(X_test)
# OneHotEncoder 결과가 희소 행렬일 수 있으므로 일반 numpy 배열로 변환합니다.
X_train_processed = X_train_processed.toarray() if hasattr(X_train_processed, "toarray") else X_train_processed
X_test_processed = X_test_processed.toarray() if hasattr(X_test_processed, "toarray") else X_test_processed
# PyTorch는 float32 자료형을 주로 사용하므로 float32로 변환합니다.
X_train_processed = X_train_processed.astype(np.float32)
X_test_processed = X_test_processed.astype(np.float32)
# 정답 라벨은 분류 문제에서 long 타입으로 사용합니다.
y_train = y_train.astype(np.int64)
y_test = y_test.astype(np.int64)
# 전처리 후 입력 특성 개수를 확인합니다.
print("전처리 후 학습 입력 크기:", X_train_processed.shape)
print("전처리 후 테스트 입력 크기:", X_test_processed.shape)
라벨과 정답들을 들을 torch를 tensor로 변환한다.
학습용 dataset 객체를 생성한다.
테스트용 dataset을 생성한다.
batch size를 지정한다.
학습용, 테스트용 dataset과 batch_size가 지정된 dataloader를 생성한다.
# ============================================================
# 10. PyTorch Dataset 클래스 정의
# ============================================================
# CreditDataset은 대출 데이터를 PyTorch가 사용할 수 있는 형태로 포장하는 클래스입니다.
class CreditDataset(Dataset):
# __init__은 Dataset 객체가 만들어질 때 한 번 실행됩니다.
def __init__(self, features, labels):
# 입력 특성을 torch 텐서로 변환합니다.
self.features = torch.tensor(features, dtype=torch.float32)
# 정답 라벨을 torch 텐서로 변환합니다.
self.labels = torch.tensor(labels, dtype=torch.long)
# __len__은 데이터가 총 몇 개인지 반환합니다.
def __len__(self):
# labels의 길이가 전체 데이터 개수입니다.
return len(self.labels)
# __getitem__은 특정 번호의 데이터 1개를 반환합니다.
def __getitem__(self, idx):
# idx번째 입력 데이터와 정답 라벨을 함께 반환합니다.
return self.features[idx], self.labels[idx]
# 학습용 Dataset 객체를 생성합니다.
train_dataset = CreditDataset(X_train_processed, y_train)
# 테스트용 Dataset 객체를 생성합니다.
test_dataset = CreditDataset(X_test_processed, y_test)
# 한 번에 학습할 데이터 개수입니다.
# 32개씩 묶어서 모델에 넣습니다.
batch_size = 32
# 학습용 DataLoader를 생성합니다.
# shuffle=True는 매 epoch마다 데이터 순서를 섞어 학습 효과를 높입니다.
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 테스트용 DataLoader를 생성합니다.
# 테스트는 순서를 섞을 필요가 없으므로 shuffle=False입니다.
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 첫 번째 미니배치를 꺼내 입력과 정답 크기를 확인합니다.
sample_X, sample_y = next(iter(train_loader))
# 미니배치 입력 크기를 출력합니다.
print("미니배치 입력 크기:", sample_X.shape)
# 미니배치 정답 크기를 출력합니다.
print("미니배치 정답 크기:", sample_y.shape)
linear과 relu를 사용해 신경망을 구현한다.
nn.dropout(0.2)이 중간에 들어가면서 일부 뉴런을 무작위로 꺼 과적합을 줄이는데 도움이 되도록 한다 .
forward로 정의한 신경망을 통과해 출력값을 만들도록한다.
# ============================================================
# 11. PyTorch 모델 정의
# ============================================================
# CreditMLP는 대출 상환 여부를 분류하는 신경망 모델입니다.
class CreditMLP(nn.Module):
# __init__은 모델 구조를 정의하는 부분입니다.
def __init__(self, input_dim, num_classes):
# 부모 클래스 nn.Module의 초기화 함수를 실행합니다.
super(CreditMLP, self).__init__()
# self.network는 여러 신경망 계층을 순서대로 묶은 구조입니다.
self.network = nn.Sequential(
# 첫 번째 완전연결층입니다.
# input_dim개의 입력을 받아 64개의 값으로 변환합니다.
nn.Linear(input_dim, 64),
# ReLU는 음수는 0으로, 양수는 그대로 통과시키는 활성화 함수입니다.
# 모델이 복잡한 패턴을 학습할 수 있게 도와줍니다.
nn.ReLU(),
# Dropout은 일부 뉴런을 무작위로 끄는 기법입니다.
# 과적합을 줄이는 데 도움이 됩니다.
nn.Dropout(0.2),
# 두 번째 완전연결층입니다.
# 64개의 입력을 받아 32개의 값으로 변환합니다.
nn.Linear(64, 32),
# 두 번째 ReLU 활성화 함수입니다.
nn.ReLU(),
# 마지막 출력층입니다.
# 32개의 입력을 클래스 개수만큼의 점수로 변환합니다.
nn.Linear(32, num_classes)
)
# forward는 입력 데이터가 모델을 통과하는 계산 과정을 정의합니다.
def forward(self, x):
# 입력 x를 self.network에 통과시켜 출력값을 만듭니다.
return self.network(x)
# 입력 특성 개수입니다.
input_dim = X_train_processed.shape[1]
# 분류할 클래스 개수입니다.
num_classes = len(label_encoder.classes_)
# 모델 객체를 생성하고 학습 장치(cpu 또는 cuda)로 이동합니다.
model = CreditMLP(input_dim=input_dim, num_classes=num_classes).to(device)
# 모델 구조를 출력합니다.
print(model)
crossentroyloss로 손실값, optimadam을 활용해 학습률을 자동조정해가며 파라미터를 업데이트하도록 생성한다.
# ============================================================
# 12. 손실 함수와 최적화 알고리즘 설정
# ============================================================
# CrossEntropyLoss는 다중 분류 문제에서 많이 사용하는 손실 함수입니다.
# 모델의 예측이 정답과 얼마나 다른지 숫자로 계산합니다.
criterion = nn.CrossEntropyLoss()
# Adam은 학습률을 자동으로 조정해 가며 모델 파라미터를 업데이트하는 최적화 알고리즘입니다.
optimizer = optim.Adam(
model.parameters(), # 학습할 모델 파라미터를 지정합니다.
lr=0.001 # learning rate, 즉 한 번에 얼마나 크게 수정할지 정합니다.
)
평가함수를 정의한다.
기울기계산이 필요없음으로 no_grad로 메모리를 절약한다.
미니배치 단위로 데이터를 꺼내가며 criterion 손실값을 계산하고 손실값에 데이터 개수를 곱해 누적한다.
torc.max 가장 점수가 높은 클래스 번호를 예측값으로 선택한다.
예측값과 정답이 같은 개수를 누적한다.
평균손실, 정확도를 계산해 반환한다.
# ============================================================
# 13. 평가 함수 정의
# ============================================================
# evaluate 함수는 검증 또는 테스트 데이터에서 모델 성능을 계산합니다.
def evaluate(model, data_loader, criterion):
# 모델을 평가 모드로 바꿉니다.
# Dropout 같은 학습 전용 동작이 꺼집니다.
model.eval()
# 전체 손실값을 누적할 변수입니다.
total_loss = 0.0
# 맞힌 개수를 누적할 변수입니다.
correct = 0
# 전체 데이터 개수를 누적할 변수입니다.
total = 0
# 평가할 때는 기울기 계산이 필요 없으므로 no_grad를 사용합니다.
with torch.no_grad():
# DataLoader에서 미니배치 단위로 데이터를 꺼냅니다.
for batch_X, batch_y in data_loader:
# 입력 데이터를 학습 장치로 이동합니다.
batch_X = batch_X.to(device)
# 정답 라벨을 학습 장치로 이동합니다.
batch_y = batch_y.to(device)
# 모델에 입력 데이터를 넣어 예측 점수를 계산합니다.
outputs = model(batch_X)
# 예측 점수와 정답 사이의 손실값을 계산합니다.
loss = criterion(outputs, batch_y)
# 현재 미니배치 손실값에 데이터 개수를 곱해 누적합니다.
total_loss += loss.item() * batch_X.size(0)
# 가장 점수가 높은 클래스 번호를 예측값으로 선택합니다.
_, predicted = torch.max(outputs, 1)
# 전체 데이터 개수를 누적합니다.
total += batch_y.size(0)
# 예측값과 정답이 같은 개수를 누적합니다.
correct += (predicted == batch_y).sum().item()
# 평균 손실값을 계산합니다.
avg_loss = total_loss / total
# 정확도를 계산합니다.
accuracy = correct / total
# 평균 손실값과 정확도를 반환합니다.
return avg_loss, accuracy
정의한 미니배피 단위로 학습을 실행한다.
optimizer.zero_grida()로 이전 배치에서 계산된 기울기를 초기호하고
model() 데이터를 넣어 예측 점수를 계산해
criterion 손실값을 계산하고
loss.backward() 손실값을 기준으로 기울기를 계산해
optimizer.step() 파라미터를 업데이트한다.
손실값은 누적하고
가장 큰 점수를 가진 클래스를 예측값으로 선택해
예측값과 정답이 같은 개수를 누적하고
손실값, 정확도를 반환한다 .
# ============================================================
# 14. 모델 학습 실행
# ============================================================
# 전체 학습 반복 횟수입니다.
epochs = 50
# 학습 과정을 저장할 리스트입니다.
train_losses = []
train_accuracies = []
test_losses = []
test_accuracies = []
# epoch 수만큼 반복 학습합니다.
for epoch in range(epochs):
# 모델을 학습 모드로 바꿉니다.
# Dropout 같은 학습 전용 동작이 켜집니다.
model.train()
# 한 epoch 동안의 손실값을 누적할 변수입니다.
running_loss = 0.0
# 한 epoch 동안 맞힌 개수를 누적할 변수입니다.
correct = 0
# 한 epoch 동안 전체 데이터 개수를 누적할 변수입니다.
total = 0
# 학습 데이터를 미니배치 단위로 반복합니다.
for batch_X, batch_y in train_loader:
# 입력 데이터를 학습 장치로 이동합니다.
batch_X = batch_X.to(device)
# 정답 라벨을 학습 장치로 이동합니다.
batch_y = batch_y.to(device)
# 이전 미니배치에서 계산된 기울기를 초기화합니다.
optimizer.zero_grad()
# 모델에 입력 데이터를 넣어 예측 점수를 계산합니다.
outputs = model(batch_X)
# 예측 결과와 실제 정답 사이의 손실값을 계산합니다.
loss = criterion(outputs, batch_y)
# 손실값을 기준으로 각 파라미터의 기울기를 계산합니다.
loss.backward()
# 계산된 기울기를 사용하여 모델 파라미터를 업데이트합니다.
optimizer.step()
# 현재 미니배치 손실값을 누적합니다.
running_loss += loss.item() * batch_X.size(0)
# 가장 큰 점수를 가진 클래스를 예측값으로 선택합니다.
_, predicted = torch.max(outputs, 1)
# 전체 데이터 개수를 누적합니다.
total += batch_y.size(0)
# 예측값과 정답이 같은 개수를 누적합니다.
correct += (predicted == batch_y).sum().item()
# 한 epoch의 평균 학습 손실값을 계산합니다.
train_loss = running_loss / total
# 한 epoch의 학습 정확도를 계산합니다.
train_acc = correct / total
# 테스트 데이터에 대한 손실값과 정확도를 계산합니다.
test_loss, test_acc = evaluate(model, test_loader, criterion)
# 그래프 출력을 위해 값을 리스트에 저장합니다.
train_losses.append(train_loss)
train_accuracies.append(train_acc)
test_losses.append(test_loss)
test_accuracies.append(test_acc)
# epoch마다 학습 결과를 출력합니다.
print(
f"Epoch [{epoch + 1:02d}/{epochs}] "
f"Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}, "
f"Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.4f}"
)
위 내용을 그래프로출력
# ============================================================
# 15. 학습 과정 그래프 출력
# ============================================================
# 그래프 크기를 지정합니다.
plt.figure(figsize=(8, 5))
# 학습 손실값 변화를 선 그래프로 표시합니다.
plt.plot(train_losses, label="Train Loss")
# 테스트 손실값 변화를 선 그래프로 표시합니다.
plt.plot(test_losses, label="Test Loss")
# 그래프 제목을 지정합니다.
plt.title("Loss 변화")
# x축 이름을 지정합니다.
plt.xlabel("Epoch")
# y축 이름을 지정합니다.
plt.ylabel("Loss")
# 범례를 표시합니다.
plt.legend()
# 그래프를 출력합니다.
plt.show()
# 새로운 그래프 크기를 지정합니다.
plt.figure(figsize=(8, 5))
# 학습 정확도 변화를 선 그래프로 표시합니다.
plt.plot(train_accuracies, label="Train Accuracy")
# 테스트 정확도 변화를 선 그래프로 표시합니다.
plt.plot(test_accuracies, label="Test Accuracy")
# 그래프 제목을 지정합니다.
plt.title("Accuracy 변화")
# x축 이름을 지정합니다.
plt.xlabel("Epoch")
# y축 이름을 지정합니다.
plt.ylabel("Accuracy")
# 범례를 표시합니다.
plt.legend()
# 그래프를 출력합니다.
plt.show()

model.eval() 평가모드로 전황해 no_grad()를 사용하고 예측값을 numpy로 정답도 numpy 배열로 변환해 리스트에 추가하며 반환한다. 정확도를 계산해 출력한다 .
# ============================================================
# 16. 테스트 데이터 전체 예측
# ============================================================
# 모델을 평가 모드로 변경합니다.
model.eval()
# 예측값을 저장할 리스트입니다.
all_predictions = []
# 실제 정답을 저장할 리스트입니다.
all_labels = []
# 테스트 과정에서는 기울기 계산이 필요 없으므로 no_grad를 사용합니다.
with torch.no_grad():
# 테스트 데이터를 미니배치 단위로 반복합니다.
for batch_X, batch_y in test_loader:
# 입력 데이터를 학습 장치로 이동합니다.
batch_X = batch_X.to(device)
# 모델 예측 점수를 계산합니다.
outputs = model(batch_X)
# 가장 점수가 높은 클래스를 예측값으로 선택합니다.
_, predicted = torch.max(outputs, 1)
# 예측값을 CPU로 옮긴 뒤 numpy 배열로 변환하여 리스트에 추가합니다.
all_predictions.extend(predicted.cpu().numpy())
# 실제 정답도 numpy 배열로 변환하여 리스트에 추가합니다.
all_labels.extend(batch_y.numpy())
# 리스트를 numpy 배열로 변환합니다.
all_predictions = np.array(all_predictions)
all_labels = np.array(all_labels)
# 정확도를 계산합니다.
test_accuracy = accuracy_score(all_labels, all_predictions)
# 테스트 정확도를 출력합니다.
print("테스트 정확도:", round(test_accuracy, 4))
confusion_matrix를 계산해 표형태의 dataframe으로 변환해 출력한다.
classfication_report()로 상세 리포트를 출력한다 .
# ============================================================
# 17. Confusion Matrix 출력
# ============================================================
# Confusion Matrix를 계산합니다.
cm = confusion_matrix(all_labels, all_predictions)
# Confusion Matrix를 표 형태의 DataFrame으로 변환합니다.
cm_df = pd.DataFrame(
cm,
index=[f"Actual_{label}" for label in label_encoder.classes_],
columns=[f"Pred_{label}" for label in label_encoder.classes_]
)
# Confusion Matrix를 출력합니다.
cm_df# ============================================================
# 18. 상세 분류 리포트 출력
# ============================================================
# classification_report는 precision, recall, f1-score를 한 번에 보여줍니다.
# precision은 예측한 것 중 실제로 맞은 비율입니다.
# recall은 실제 정답 중 모델이 찾아낸 비율입니다.
# f1-score는 precision과 recall을 함께 고려한 점수입니다.
report = classification_report(
all_labels,
all_predictions,
target_names=[str(cls) for cls in label_encoder.classes_]
)
# 상세 평가 결과를 출력합니다.
print(report)
신규데이터를 가져다가 예측해본다.
여기까지가 어제까지의내용이었다.
# ============================================================
# 19. 신규 대출 신청자 예측 예시
# ============================================================
# 테스트 데이터에서 첫 번째 신청자 데이터를 하나 가져옵니다.
new_applicant = X_test.iloc[[0]]
# 신규 신청자 데이터를 확인합니다.
display(new_applicant)
# 학습 데이터 기준으로 만든 전처리기를 사용하여 신규 데이터를 변환합니다.
new_applicant_processed = preprocessor.transform(new_applicant)
# 희소 행렬이면 일반 배열로 변환합니다.
new_applicant_processed = (
new_applicant_processed.toarray()
if hasattr(new_applicant_processed, "toarray")
else new_applicant_processed
)
# float32 자료형으로 변환합니다.
new_applicant_processed = new_applicant_processed.astype(np.float32)
# numpy 배열을 PyTorch 텐서로 변환합니다.
new_applicant_tensor = torch.tensor(new_applicant_processed, dtype=torch.float32).to(device)
# 모델을 평가 모드로 변경합니다.
model.eval()
# 기울기 계산 없이 예측합니다.
with torch.no_grad():
# 모델의 출력 점수를 계산합니다.
output = model(new_applicant_tensor)
# softmax는 점수를 확률처럼 해석할 수 있게 변환합니다.
probabilities = torch.softmax(output, dim=1)
# 가장 확률이 높은 클래스를 선택합니다.
predicted_class = torch.argmax(probabilities, dim=1).item()
# 숫자 라벨을 원래 문자 라벨로 되돌립니다.
predicted_label = label_encoder.inverse_transform([predicted_class])[0]
# 예측 결과를 출력합니다.
print("예측 라벨:", predicted_label)
# 클래스별 예측 확률을 출력합니다.
for label, prob in zip(label_encoder.classes_, probabilities.cpu().numpy()[0]):
print(f"{label} 확률: {prob:.4f}")
globals() 변수를 조회해 기존 모델의 정확도를 변수에 저장한다.
여러개의 기본 모델을 병렬로 학습시키는 앙상블 모델 sklearn.ensembl BaggingClassifier과
bagging안에서 사용할 기본모델 sklearn.tree DecisionTreeClassifier를 추가 import한다 .
# ============================================================
# 추가 1. 앙상블 평가에 필요한 라이브러리 불러오기
# ============================================================
# pandas는 성능 비교표를 만들 때 사용합니다.
import pandas as pd
# numpy는 배열 계산에 사용합니다.
import numpy as np
# matplotlib은 성능 비교 그래프를 그릴 때 사용합니다.
import matplotlib.pyplot as plt
# accuracy_score는 정확도를 계산합니다.
from sklearn.metrics import accuracy_score
# confusion_matrix는 실제값과 예측값의 관계를 표로 정리합니다.
from sklearn.metrics import confusion_matrix
# classification_report는 precision, recall, f1-score를 한 번에 출력합니다.
from sklearn.metrics import classification_report
# 기존 PyTorch MLP 모델의 정확도가 저장되어 있는지 확인합니다.
# 위쪽 기존 코드를 순서대로 실행했다면 test_accuracy 변수가 존재합니다.
if "test_accuracy" in globals():
# 기존 PyTorch 모델의 정확도를 baseline_accuracy 변수에 저장합니다.
baseline_accuracy = test_accuracy
else:
# 기존 모델 평가 셀을 실행하지 않은 경우를 대비하여 None으로 둡니다.
baseline_accuracy = None
# 기존 모델 정확도를 확인합니다.
print("기존 PyTorch MLP 테스트 정확도:", baseline_accuracy)
# BaggingClassifier는 여러 개의 기본 모델을 병렬로 학습시키는 앙상블 모델입니다.
from sklearn.ensemble import BaggingClassifier
# DecisionTreeClassifier는 Bagging 안에서 사용할 기본 모델입니다.
from sklearn.tree import DecisionTreeClassifier
DecisionTreeClassifier 기본모델로 사용할 의사결정트리를 생성한다.
baggingclassifier를 통해 base_tree를 n_estimators 갯수만큼 만들어 학습데이터중 0.8을 사용한다.
boostrap = true 데이터를 뽑을때 중복 추출을 허용하고
seed 난수를 고정하며
n_jobs = -1 를 설정해 가능한 cpu 코어를 모두 사용하여 학습속도를 높이도록 한다 .
학습데이터를 fit해 bagging모델을 학습시킨다.
# ============================================================
# 추가 2. Bagging 모델 생성 및 학습
# ============================================================
# 기본 모델로 사용할 의사결정트리를 생성합니다.
# max_depth를 제한하지 않으면 각 트리는 데이터를 깊게 학습할 수 있습니다.
base_tree = DecisionTreeClassifier(
random_state=SEED
)
# BaggingClassifier를 생성합니다.
ensemble_model = BaggingClassifier(
# estimator는 Bagging 안에서 반복해서 사용할 기본 모델입니다.
estimator=base_tree,
# n_estimators는 만들 의사결정트리 개수입니다.
# 트리 개수가 많을수록 안정성이 좋아질 수 있지만 학습 시간이 늘어납니다.
n_estimators=100,
# max_samples는 각 트리가 학습할 때 원본 학습 데이터 중 몇 %를 사용할지 정합니다.
# 0.8은 전체 학습 데이터의 80%를 무작위로 뽑아 각 트리에 사용한다는 뜻입니다.
max_samples=0.8,
# bootstrap=True는 데이터를 뽑을 때 중복 추출을 허용한다는 뜻입니다.
# 같은 행이 한 트리의 학습 데이터에 여러 번 들어갈 수 있습니다.
bootstrap=True,
# random_state는 결과가 매번 크게 달라지지 않도록 난수를 고정합니다.
random_state=SEED,
# n_jobs=-1은 가능한 CPU 코어를 모두 사용하여 학습 속도를 높입니다.
n_jobs=-1
)
# fit은 학습 데이터와 정답을 사용하여 Bagging 모델을 학습합니다.
ensemble_model.fit(X_train_processed, y_train)
# 학습이 끝났음을 확인합니다.
print("Bagging 모델 학습 완료")
끝났다.
지금까지 pytorch로 했던 코드들은 학습과정을 직접 구현했었다.
bagging은 baggingclassifier, fit이 끝이다. sklearn이 이미 다 만들어놨기 때문인데 실제로 내부에서 데이터갠덤추출, 100개 bootstrap 데이터 생성 및 트리 생성, 트리 학습, 투표 함수생성, 예측 함수생성이 자동으로 이루어지기 때문이다.
즉 fit() 한줄안에서 많은 것들이 돌아가고있는것 .
baggingclassifier는 bagging 알고리즘 전체를 이미 구현해놓은 클래스나 다름이 없다.
성능평가.
예측값을 생성해 정확도 계산
confusion_matrix 를 계산해 표형태로 변환 출력
classification_report로 상세 평가결과 출력
# ============================================================
# 추가 3. Bagging Classifier 예측 및 성능 평가
# ============================================================
# 학습된 Bagging Classifier 모델에 테스트 데이터를 넣어 예측값을 생성합니다.
bagging_predictions = ensemble_model.predict(X_test_processed)
# 실제 정답 y_test와 예측값을 비교하여 정확도를 계산합니다.
bagging_accuracy = accuracy_score(y_test, bagging_predictions)
# 정확도를 출력합니다.
print("Bagging Classifier 테스트 정확도:", round(bagging_accuracy, 4))
# Confusion Matrix를 계산합니다.
ensemble_cm = confusion_matrix(y_test, bagging_predictions)
# Confusion Matrix를 보기 좋은 표 형태로 변환합니다.
ensemble_cm_df = pd.DataFrame(
ensemble_cm,
index=[f"Actual_{label}" for label in label_encoder.classes_],
columns=[f"Pred_{label}" for label in label_encoder.classes_]
)
# Confusion Matrix를 출력합니다.
display(ensemble_cm_df)
# precision, recall, f1-score를 포함한 상세 평가 결과를 출력합니다.
print(classification_report(
y_test,
bagging_predictions,
target_names=[str(cls) for cls in label_encoder.classes_]
))
기존 저장해놨던 모델의 정확도를 비교표에 추가해 dataframe으로 변환하고 정렬하며 보기좋게 반올림해 출력한다.
그래프도 표현한다.
# ============================================================
# 추가 4. 기존 PyTorch 모델과 Bagging Classifier 성능 비교
# ============================================================
# 성능 비교 결과를 저장할 리스트를 만듭니다.
comparison_rows = []
# 기존 PyTorch MLP 정확도가 있으면 비교표에 추가합니다.
if baseline_accuracy is not None:
# 기존 PyTorch 모델의 이름과 정확도를 저장합니다.
comparison_rows.append({"Model": "PyTorch MLP", "Accuracy": baseline_accuracy})
# 이번에 학습한 앙상블 모델의 이름과 정확도를 저장합니다.
comparison_rows.append({"Model": "Bagging Classifier", "Accuracy": bagging_accuracy})
# 리스트를 표 형태의 DataFrame으로 변환합니다.
comparison_df = pd.DataFrame(comparison_rows)
# 정확도가 높은 모델이 위에 오도록 정렬합니다.
comparison_df = comparison_df.sort_values(by="Accuracy", ascending=False).reset_index(drop=True)
# 정확도 값을 소수점 네 자리까지 보기 좋게 반올림합니다.
comparison_df["Accuracy"] = comparison_df["Accuracy"].round(4)
# 성능 비교표를 출력합니다.
display(comparison_df)
# 그래프 크기를 지정합니다.
plt.figure(figsize=(7, 4))
# 모델별 정확도를 막대그래프로 표시합니다.
plt.bar(comparison_df["Model"], comparison_df["Accuracy"])
# 그래프 제목을 지정합니다.
plt.title("모델별 테스트 정확도 비교")
# x축 이름을 지정합니다.
plt.xlabel("모델")
# y축 이름을 지정합니다.
plt.ylabel("정확도")
# y축 범위를 0부터 1까지로 지정합니다.
plt.ylim(0, 1)
# 각 막대 위에 정확도 값을 표시합니다.
for index, value in enumerate(comparison_df["Accuracy"]):
# text는 그래프에 글자를 표시하는 함수입니다.
plt.text(index, value + 0.01, str(value), ha="center")
# 그래프를 출력합니다.
plt.show()
대표앙상블
Bagging(Random Forest): 여러 트리를 병렬로 만들어 투표.
Random Forest: Bagging에서 특정중요한 변수를 트리 대부분에서 써버리면 비슷해져 다양한 의견을 듣지 못하고 전부 비슷한 내용만 알게 된다 .이때 사용할 특성을 랜덤으로 제한해서 보완한것을 말함.
Boosting: bagging은 트리들이 동시에 학습했으나 Boostring은 앞 모델이 틀린 문제를 뒤 모델이 집중적으로공부한다 .
AdaBoost : 최초의 Boostinㅎ 알고리즘으로 틀린문제에 가중치를 준다. 틀린데이터를 중요데이터로 인식하는것.
Gradient Boosting: AdaBoost는 틀린데이터 찾기라면 Gradient Boosting은 오차 자체를 학습해 실제값이 100이고 예측값이 80이었다면 오차값 20을 줄이는 방향으로 학습해 성능이 점점 좋아진다. XGBoost, LightGBM, CatBoost 모두 같은 계열
샘플코드 decision_tree_torch_random_forest_added 를 분석해보자.
데이터 처리(pandas, numpy), 머신러닝 전처리(sklearn), 딥러닝(PyTorch), 시각화(matplotlib) 주요 라이브러리
sk.learn.compose.ColumnTransformer 수치형/범주형 컬럼에 서로 다른 전처리를 사용할때.
sklearn.preprocessing oneHotEndoder, StandardScaler, LabelEncoder 문자 범주데이터를 0~1숫자로 변환
Pipeline 여러 전처리 단계를 하나로 묶어 실행
sklearn.metrics accuracy_score, confusion_matrix, classification_report 모델 평가지표 계산
GPU(cuda) 사용 가능 여부를 확인하여 학습 장치를 설정하고 출력한다.
# ============================================================
# 1. 필요한 라이브러리 불러오기
# ============================================================
# pandas는 CSV 파일을 읽고 표 형태의 데이터를 다루기 위한 라이브러리입니다.
import pandas as pd
# numpy는 숫자 배열 계산을 빠르게 처리하기 위한 라이브러리입니다.
import numpy as np
# torch는 PyTorch의 핵심 라이브러리입니다.
# 텐서 생성, 신경망 학습, 자동 미분 등을 처리합니다.
import torch
# torch.nn은 신경망 계층, 손실 함수 등을 만들 때 사용하는 모듈입니다.
import torch.nn as nn
# torch.optim은 Adam, SGD 같은 최적화 알고리즘을 제공하는 모듈입니다.
import torch.optim as optim
# Dataset과 DataLoader는 데이터를 PyTorch 모델에 넣기 좋은 형태로 관리하는 도구입니다.
from torch.utils.data import Dataset, DataLoader
# train_test_split은 데이터를 학습용과 테스트용으로 나누는 함수입니다.
from sklearn.model_selection import train_test_split
# ColumnTransformer는 수치형/범주형 컬럼에 서로 다른 전처리를 적용할 때 사용합니다.
from sklearn.compose import ColumnTransformer
# OneHotEncoder는 문자 범주 데이터를 0과 1의 숫자 벡터로 변환합니다.
from sklearn.preprocessing import OneHotEncoder, StandardScaler, LabelEncoder
# Pipeline은 여러 전처리 단계를 하나로 묶어 실행할 때 사용합니다.
from sklearn.pipeline import Pipeline
# accuracy_score와 confusion_matrix는 모델 평가 지표를 계산합니다.
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# matplotlib은 그래프를 그리기 위한 라이브러리입니다.
import matplotlib.pyplot as plt
# random은 파이썬의 난수 생성을 제어할 때 사용합니다.
import random
# os는 파일 경로 확인 등에 사용합니다.
import os
# 경고 메시지를 줄여 출력 화면을 깔끔하게 만들기 위해 사용합니다.
import warnings
# 불필요한 경고 메시지를 숨깁니다.
warnings.filterwarnings("ignore")
# 현재 사용 가능한 장치를 확인합니다.
# Colab에서 GPU를 켜면 cuda가 출력되고, 그렇지 않으면 cpu가 출력됩니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 현재 학습에 사용할 장치를 출력합니다.
print("사용 장치:", device)
난수를 코드를 다시 실행해도 최대한 같은 결과가 나오도록 한다 .
# ============================================================
# 2. 난수 고정
# ============================================================
# 난수를 고정하면 코드를 다시 실행해도 최대한 같은 결과가 나오도록 만들 수 있습니다.
SEED = 123
# 파이썬 random 라이브러리의 난수를 고정합니다.
random.seed(SEED)
# numpy 난수를 고정합니다.
np.random.seed(SEED)
# PyTorch CPU 연산의 난수를 고정합니다.
torch.manual_seed(SEED)
# PyTorch GPU 연산의 난수를 고정합니다.
torch.cuda.manual_seed_all(SEED)
# CUDA 연산의 재현성을 높이기 위한 설정입니다.
torch.backends.cudnn.deterministic = True
# 실행 속도 최적화보다 재현성을 우선하도록 설정합니다.
torch.backends.cudnn.benchmark = False
데이터를 불러오고 공개데이터에서 가져왔을때를 대비해 라벨명 일부가 다를경우 변경한다 .
# ============================================================
# 3. 데이터 불러오기
# ============================================================
# 사용한 파일 경로입니다.
local_path = "data/credit_info.csv"
# 공개 German Credit 데이터셋 주소입니다.
# Colab에서 data/credit_info.csv 파일이 없을 때 자동으로 읽어옵니다.
url = "https://raw.githubusercontent.com/stedy/Machine-Learning-with-R-datasets/master/credit.csv"
# data 폴더가 없으면 새로 생성합니다.
os.makedirs("data", exist_ok=True)
# local_path 파일이 실제로 존재하는지 확인합니다.
if os.path.exists(local_path):
# 파일이 있으면 사용자가 제공한 로컬 CSV 파일을 읽습니다.
credit_info = pd.read_csv(local_path)
else:
# 파일이 없으면 공개 URL에서 CSV 파일을 읽습니다.
credit_info = pd.read_csv(url)
# 다음 실행 때도 같은 파일을 사용할 수 있도록 data 폴더에 저장합니다.
credit_info.to_csv(local_path, index=False)
# 목표 변수를 Repay라고 사용합니다.
# 공개 데이터셋은 목표 컬럼명이 default일 수 있으므로 Repay로 바꿉니다.
if "Repay" not in credit_info.columns and "default" in credit_info.columns:
# default 컬럼명을 Repay로 변경합니다.
credit_info = credit_info.rename(columns={"default": "Repay"})
# 데이터의 앞부분 5행을 확인합니다.
credit_info.head()
데이터구조를 확인한다.
데이터를 기본탐색한다.
# ============================================================
# 4. 데이터 구조 확인
# ============================================================
# 데이터의 행과 열 개수를 확인합니다.
print("데이터 크기:", credit_info.shape)
# 각 컬럼의 자료형과 결측치 여부를 확인합니다.
credit_info.info()
# 컬럼 이름 목록을 출력합니다.
print("\n컬럼 목록:")
print(credit_info.columns.tolist())# ============================================================
# 5. 기본 탐색
# ============================================================
# checking_balance 컬럼은 신청자의 수표 계좌 잔고 범주를 의미합니다.
# value_counts()는 R의 table()과 비슷하게 값별 개수를 세어 줍니다.
print("checking_balance 빈도:")
print(credit_info["checking_balance"].value_counts())
# savings_balance 컬럼은 신청자의 저축 계좌 잔고 범주를 의미합니다.
print("\nsavings_balance 빈도:")
print(credit_info["savings_balance"].value_counts())
# months_loan_duration은 대출 기간입니다.
# describe()는 평균, 표준편차, 최솟값, 최댓값 등을 보여줍니다.
print("\nmonths_loan_duration 요약:")
print(credit_info["months_loan_duration"].describe())
# amount는 대출 금액입니다.
print("\namount 요약:")
print(credit_info["amount"].describe())
# Repay는 상환 여부 또는 채무불이행 여부를 나타내는 목표 변수입니다.
print("\nRepay 빈도:")
print(credit_info["Repay"].value_counts())
# Repay 비율을 확인합니다.
print("\nRepay 비율:")
print(credit_info["Repay"].value_counts(normalize=True))
입력데이터와 정답데이터를 분리한다.
수치형과 범주형을 구분한다.
학습데이터와 테스트 데이터를 분리한다.
# ============================================================
# 6. 입력 X와 정답 y 분리
# ============================================================
# 목표 컬럼명을 변수로 저장합니다.
target_col = "Repay"
# 목표 컬럼이 실제 데이터에 있는지 확인합니다.
if target_col not in credit_info.columns:
# 목표 컬럼이 없으면 에러를 발생시켜 문제 원인을 바로 알 수 있게 합니다.
raise ValueError("데이터에 Repay 컬럼이 없습니다. 목표 컬럼명을 확인하세요.")
# X는 Repay를 제외한 모든 컬럼입니다.
X = credit_info.drop(columns=[target_col])
# y는 모델이 예측해야 하는 Repay 컬럼입니다.
y = credit_info[target_col]
# LabelEncoder는 문자 라벨을 숫자 라벨로 바꿉니다.
# 예: no -> 0, yes -> 1 과 같은 방식입니다.
label_encoder = LabelEncoder()
# y 값을 숫자 형태로 변환합니다.
y_encoded = label_encoder.fit_transform(y)
# 어떤 원래 라벨이 어떤 숫자로 바뀌었는지 확인합니다.
print("라벨 매핑:")
for original_label, encoded_label in zip(label_encoder.classes_, range(len(label_encoder.classes_))):
print(f"{original_label} -> {encoded_label}")# ============================================================
# 7. 수치형 컬럼과 범주형 컬럼 구분
# ============================================================
# 수치형 컬럼은 int64, float64 같은 숫자 자료형 컬럼입니다.
numeric_features = X.select_dtypes(include=["int64", "float64"]).columns.tolist()
# 범주형 컬럼은 object, category 같은 문자 또는 범주 자료형 컬럼입니다.
categorical_features = X.select_dtypes(include=["object", "category", "bool"]).columns.tolist()
# 수치형 컬럼 목록을 출력합니다.
print("수치형 컬럼:", numeric_features)
# 범주형 컬럼 목록을 출력합니다.
print("범주형 컬럼:", categorical_features)# ============================================================
# 8. 학습 데이터와 테스트 데이터 분리
# ============================================================
# train_test_split은 데이터를 학습용과 테스트용으로 나눕니다.
# test_size=0.2는 전체 데이터의 20%를 테스트용으로 사용한다는 뜻입니다.
# 800개 학습 / 200개 테스트 분리와 같은 비율입니다.
# stratify=y_encoded는 정답 라벨 비율이 학습/테스트에 비슷하게 유지되도록 합니다.
X_train, X_test, y_train, y_test = train_test_split(
X,
y_encoded,
test_size=0.2,
random_state=SEED,
stratify=y_encoded
)
# 분리된 데이터 크기를 확인합니다.
print("X_train 크기:", X_train.shape)
print("X_test 크기:", X_test.shape)
print("y_train 크기:", y_train.shape)
print("y_test 크기:", y_test.shape)
# 학습 데이터의 클래스 비율을 확인합니다.
print("\n학습 데이터 클래스 비율:")
print(pd.Series(y_train).value_counts(normalize=True).sort_index())
# 테스트 데이터의 클래스 비율을 확인합니다.
print("\n테스트 데이터 클래스 비율:")
print(pd.Series(y_test).value_counts(normalize=True).sort_index())
전처리 파이프라인은 Pipeline() 생성하고 수치형데이터, 범주형데이터를 변환한다.
columntransformer로 컬럼 종류별로 다른 전처리를 사용한다 .
학습데이터에게 fit.transform, 테스트 데이터에게 transform, onehotencoder결과가 행렬일 수 있으니 numpy 배열로 변환한다.
pytorch의 기본자료형 float32로 astype
정답라벨은 long 인 int64로 astype
# ============================================================
# 9. 전처리 파이프라인 생성
# ============================================================
# 수치형 데이터 전처리: StandardScaler로 표준화합니다.
numeric_transformer = Pipeline(
steps=[
# StandardScaler는 수치 데이터의 크기 차이를 줄여 학습을 안정적으로 만듭니다.
("scaler", StandardScaler())
]
)
# 범주형 데이터 전처리: OneHotEncoder로 숫자 벡터화합니다.
categorical_transformer = Pipeline(
steps=[
# handle_unknown="ignore"는 테스트 데이터에 학습 때 보지 못한 범주가 나와도 에러를 막습니다.
("onehot", OneHotEncoder(handle_unknown="ignore"))
]
)
# ColumnTransformer는 컬럼 종류별로 다른 전처리를 적용합니다.
preprocessor = ColumnTransformer(
transformers=[
# numeric_features 컬럼에는 numeric_transformer를 적용합니다.
("num", numeric_transformer, numeric_features),
# categorical_features 컬럼에는 categorical_transformer를 적용합니다.
("cat", categorical_transformer, categorical_features)
]
)
# fit_transform은 학습 데이터 기준으로 전처리 규칙을 학습하고 바로 변환합니다.
X_train_processed = preprocessor.fit_transform(X_train)
# transform은 학습 데이터에서 만든 규칙을 테스트 데이터에 그대로 적용합니다.
X_test_processed = preprocessor.transform(X_test)
# OneHotEncoder 결과가 희소 행렬일 수 있으므로 일반 numpy 배열로 변환합니다.
X_train_processed = X_train_processed.toarray() if hasattr(X_train_processed, "toarray") else X_train_processed
X_test_processed = X_test_processed.toarray() if hasattr(X_test_processed, "toarray") else X_test_processed
# PyTorch는 float32 자료형을 주로 사용하므로 float32로 변환합니다.
X_train_processed = X_train_processed.astype(np.float32)
X_test_processed = X_test_processed.astype(np.float32)
# 정답 라벨은 분류 문제에서 long 타입으로 사용합니다.
y_train = y_train.astype(np.int64)
y_test = y_test.astype(np.int64)
# 전처리 후 입력 특성 개수를 확인합니다.
print("전처리 후 학습 입력 크기:", X_train_processed.shape)
print("전처리 후 테스트 입력 크기:", X_test_processed.shape)
특성과라벨을 torch.tensor로 변환하고
학습용 dataset creditdataset객체를 생성한다.
테스트용 dataset creditdataset객체를 생성한다.
위 내용과 배치수로 학습용, 테스트용 dataloader를 생성한다.
# ============================================================
# 10. PyTorch Dataset 클래스 정의
# ============================================================
# CreditDataset은 대출 데이터를 PyTorch가 사용할 수 있는 형태로 포장하는 클래스입니다.
class CreditDataset(Dataset):
# __init__은 Dataset 객체가 만들어질 때 한 번 실행됩니다.
def __init__(self, features, labels):
# 입력 특성을 torch 텐서로 변환합니다.
self.features = torch.tensor(features, dtype=torch.float32)
# 정답 라벨을 torch 텐서로 변환합니다.
self.labels = torch.tensor(labels, dtype=torch.long)
# __len__은 데이터가 총 몇 개인지 반환합니다.
def __len__(self):
# labels의 길이가 전체 데이터 개수입니다.
return len(self.labels)
# __getitem__은 특정 번호의 데이터 1개를 반환합니다.
def __getitem__(self, idx):
# idx번째 입력 데이터와 정답 라벨을 함께 반환합니다.
return self.features[idx], self.labels[idx]
# 학습용 Dataset 객체를 생성합니다.
train_dataset = CreditDataset(X_train_processed, y_train)
# 테스트용 Dataset 객체를 생성합니다.
test_dataset = CreditDataset(X_test_processed, y_test)
# 한 번에 학습할 데이터 개수입니다.
# 32개씩 묶어서 모델에 넣습니다.
batch_size = 32
# 학습용 DataLoader를 생성합니다.
# shuffle=True는 매 epoch마다 데이터 순서를 섞어 학습 효과를 높입니다.
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 테스트용 DataLoader를 생성합니다.
# 테스트는 순서를 섞을 필요가 없으므로 shuffle=False입니다.
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 첫 번째 미니배치를 꺼내 입력과 정답 크기를 확인합니다.
sample_X, sample_y = next(iter(train_loader))
# 미니배치 입력 크기를 출력합니다.
print("미니배치 입력 크기:", sample_X.shape)
# 미니배치 정답 크기를 출력합니다.
print("미니배치 정답 크기:", sample_y.shape)
nnModule를 상속받아 초기화함수를 거쳐 linear과 relu, dropout를 활용하여 신경망구조를 생성한다.
forward로 위 함수를 통과하도록 저으이한다.
creditMLP 만든 class로 model객체를 생성한다.
# ============================================================
# 11. PyTorch 모델 정의
# ============================================================
# CreditMLP는 대출 상환 여부를 분류하는 신경망 모델입니다.
class CreditMLP(nn.Module):
# __init__은 모델 구조를 정의하는 부분입니다.
def __init__(self, input_dim, num_classes):
# 부모 클래스 nn.Module의 초기화 함수를 실행합니다.
super(CreditMLP, self).__init__()
# self.network는 여러 신경망 계층을 순서대로 묶은 구조입니다.
self.network = nn.Sequential(
# 첫 번째 완전연결층입니다.
# input_dim개의 입력을 받아 64개의 값으로 변환합니다.
nn.Linear(input_dim, 64),
# ReLU는 음수는 0으로, 양수는 그대로 통과시키는 활성화 함수입니다.
# 모델이 복잡한 패턴을 학습할 수 있게 도와줍니다.
nn.ReLU(),
# Dropout은 일부 뉴런을 무작위로 끄는 기법입니다.
# 과적합을 줄이는 데 도움이 됩니다.
nn.Dropout(0.2),
# 두 번째 완전연결층입니다.
# 64개의 입력을 받아 32개의 값으로 변환합니다.
nn.Linear(64, 32),
# 두 번째 ReLU 활성화 함수입니다.
nn.ReLU(),
# 마지막 출력층입니다.
# 32개의 입력을 클래스 개수만큼의 점수로 변환합니다.
nn.Linear(32, num_classes)
)
# forward는 입력 데이터가 모델을 통과하는 계산 과정을 정의합니다.
def forward(self, x):
# 입력 x를 self.network에 통과시켜 출력값을 만듭니다.
return self.network(x)
# 입력 특성 개수입니다.
input_dim = X_train_processed.shape[1]
# 분류할 클래스 개수입니다.
num_classes = len(label_encoder.classes_)
# 모델 객체를 생성하고 학습 장치(cpu 또는 cuda)로 이동합니다.
model = CreditMLP(input_dim=input_dim, num_classes=num_classes).to(device)
# 모델 구조를 출력합니다.
print(model)
손실함수를 생성한다.
nn.CrossEntroyloss 를 활용한다. 다중분류문제에서 많이 사용하는 손실함수로 모델의 예측이 정답과 얼마나 다른지를 숫자로 계산한다
optim.adam 알고리즘을 활용해 학습률을 자동으로 조정해가며 파라미터를 업데이트하도록 한다
# ============================================================
# 12. 손실 함수와 최적화 알고리즘 설정
# ============================================================
# CrossEntropyLoss는 다중 분류 문제에서 많이 사용하는 손실 함수입니다.
# 모델의 예측이 정답과 얼마나 다른지 숫자로 계산합니다.
criterion = nn.CrossEntropyLoss()
# Adam은 학습률을 자동으로 조정해 가며 모델 파라미터를 업데이트하는 최적화 알고리즘입니다.
optimizer = optim.Adam(
model.parameters(), # 학습할 모델 파라미터를 지정합니다.
lr=0.001 # learning rate, 즉 한 번에 얼마나 크게 수정할지 정합니다.
)
평가함수를 생성한다.
mode.eval() 평가모드로바꾼다.
no_grad를 사용해 메모리를 절약하고 dataloader에서 미니batch단위로데이터를 꺼내 입력데이터를 학습장치device로 이동하고 model예측점수를 계산한다.
손실값에 데이터 개수를 곱해 누적한다.
가장 점수가 높은 클래스 번호를 예측값으로 선택한다.
예측값과 정답이 같은 개수를 누적한다 .
평균 손실값과 정확도를 계산해 반환한다.
# ============================================================
# 13. 평가 함수 정의
# ============================================================
# evaluate 함수는 검증 또는 테스트 데이터에서 모델 성능을 계산합니다.
def evaluate(model, data_loader, criterion):
# 모델을 평가 모드로 바꿉니다.
# Dropout 같은 학습 전용 동작이 꺼집니다.
model.eval()
# 전체 손실값을 누적할 변수입니다.
total_loss = 0.0
# 맞힌 개수를 누적할 변수입니다.
correct = 0
# 전체 데이터 개수를 누적할 변수입니다.
total = 0
# 평가할 때는 기울기 계산이 필요 없으므로 no_grad를 사용합니다.
with torch.no_grad():
# DataLoader에서 미니배치 단위로 데이터를 꺼냅니다.
for batch_X, batch_y in data_loader:
# 입력 데이터를 학습 장치로 이동합니다.
batch_X = batch_X.to(device)
# 정답 라벨을 학습 장치로 이동합니다.
batch_y = batch_y.to(device)
# 모델에 입력 데이터를 넣어 예측 점수를 계산합니다.
outputs = model(batch_X)
# 예측 점수와 정답 사이의 손실값을 계산합니다.
loss = criterion(outputs, batch_y)
# 현재 미니배치 손실값에 데이터 개수를 곱해 누적합니다.
total_loss += loss.item() * batch_X.size(0)
# 가장 점수가 높은 클래스 번호를 예측값으로 선택합니다.
_, predicted = torch.max(outputs, 1)
# 전체 데이터 개수를 누적합니다.
total += batch_y.size(0)
# 예측값과 정답이 같은 개수를 누적합니다.
correct += (predicted == batch_y).sum().item()
# 평균 손실값을 계산합니다.
avg_loss = total_loss / total
# 정확도를 계산합니다.
accuracy = correct / total
# 평균 손실값과 정확도를 반환합니다.
return avg_loss, accuracy
train_loader 를 돌며 미니배치 단위로 학습데이터를 반복한다.
학습장치로 이동한다 .
optimizer.zero_grad로 앞선 배치에서 게산된 기울기를 초기화한다 .
model(batchx) 입력 데이터를 넣어 예측 점수를 계산한다 .
criterion(outputs, batch_y) 예측결과와 실제 정답사이의 손실값을 게산한다.
loss.backward() 손실값을 기준으로 각 파라미터의 기울기르 계산해
optimizer.step() 모델의 파리미터를 업데이트한다.
현재 미니배치에서 손실값을 누적하고
torch.max 가장 큰 점수를 가진 클래스를 예측값으로 선택해
전체 데이터 개수를 누적한뒤
예측값과 정답이 같은 개수를 누적한다.
평균 학습손실값과 정확도를 계산해 반환한다 .
# ============================================================
# 14. 모델 학습 실행
# ============================================================
# 전체 학습 반복 횟수입니다.
epochs = 50
# 학습 과정을 저장할 리스트입니다.
train_losses = []
train_accuracies = []
test_losses = []
test_accuracies = []
# epoch 수만큼 반복 학습합니다.
for epoch in range(epochs):
# 모델을 학습 모드로 바꿉니다.
# Dropout 같은 학습 전용 동작이 켜집니다.
model.train()
# 한 epoch 동안의 손실값을 누적할 변수입니다.
running_loss = 0.0
# 한 epoch 동안 맞힌 개수를 누적할 변수입니다.
correct = 0
# 한 epoch 동안 전체 데이터 개수를 누적할 변수입니다.
total = 0
# 학습 데이터를 미니배치 단위로 반복합니다.
for batch_X, batch_y in train_loader:
# 입력 데이터를 학습 장치로 이동합니다.
batch_X = batch_X.to(device)
# 정답 라벨을 학습 장치로 이동합니다.
batch_y = batch_y.to(device)
# 이전 미니배치에서 계산된 기울기를 초기화합니다.
optimizer.zero_grad()
# 모델에 입력 데이터를 넣어 예측 점수를 계산합니다.
outputs = model(batch_X)
# 예측 결과와 실제 정답 사이의 손실값을 계산합니다.
loss = criterion(outputs, batch_y)
# 손실값을 기준으로 각 파라미터의 기울기를 계산합니다.
loss.backward()
# 계산된 기울기를 사용하여 모델 파라미터를 업데이트합니다.
optimizer.step()
# 현재 미니배치 손실값을 누적합니다.
running_loss += loss.item() * batch_X.size(0)
# 가장 큰 점수를 가진 클래스를 예측값으로 선택합니다.
_, predicted = torch.max(outputs, 1)
# 전체 데이터 개수를 누적합니다.
total += batch_y.size(0)
# 예측값과 정답이 같은 개수를 누적합니다.
correct += (predicted == batch_y).sum().item()
# 한 epoch의 평균 학습 손실값을 계산합니다.
train_loss = running_loss / total
# 한 epoch의 학습 정확도를 계산합니다.
train_acc = correct / total
# 테스트 데이터에 대한 손실값과 정확도를 계산합니다.
test_loss, test_acc = evaluate(model, test_loader, criterion)
# 그래프 출력을 위해 값을 리스트에 저장합니다.
train_losses.append(train_loss)
train_accuracies.append(train_acc)
test_losses.append(test_loss)
test_accuracies.append(test_acc)
# epoch마다 학습 결과를 출력합니다.
print(
f"Epoch [{epoch + 1:02d}/{epochs}] "
f"Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}, "
f"Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.4f}"
)
위 내용을 그래프로 그린다 .
# ============================================================
# 15. 학습 과정 그래프 출력
# ============================================================
# 그래프 크기를 지정합니다.
plt.figure(figsize=(8, 5))
# 학습 손실값 변화를 선 그래프로 표시합니다.
plt.plot(train_losses, label="Train Loss")
# 테스트 손실값 변화를 선 그래프로 표시합니다.
plt.plot(test_losses, label="Test Loss")
# 그래프 제목을 지정합니다.
plt.title("Loss 변화")
# x축 이름을 지정합니다.
plt.xlabel("Epoch")
# y축 이름을 지정합니다.
plt.ylabel("Loss")
# 범례를 표시합니다.
plt.legend()
# 그래프를 출력합니다.
plt.show()
# 새로운 그래프 크기를 지정합니다.
plt.figure(figsize=(8, 5))
# 학습 정확도 변화를 선 그래프로 표시합니다.
plt.plot(train_accuracies, label="Train Accuracy")
# 테스트 정확도 변화를 선 그래프로 표시합니다.
plt.plot(test_accuracies, label="Test Accuracy")
# 그래프 제목을 지정합니다.
plt.title("Accuracy 변화")
# x축 이름을 지정합니다.
plt.xlabel("Epoch")
# y축 이름을 지정합니다.
plt.ylabel("Accuracy")
# 범례를 표시합니다.
plt.legend()
# 그래프를 출력합니다.
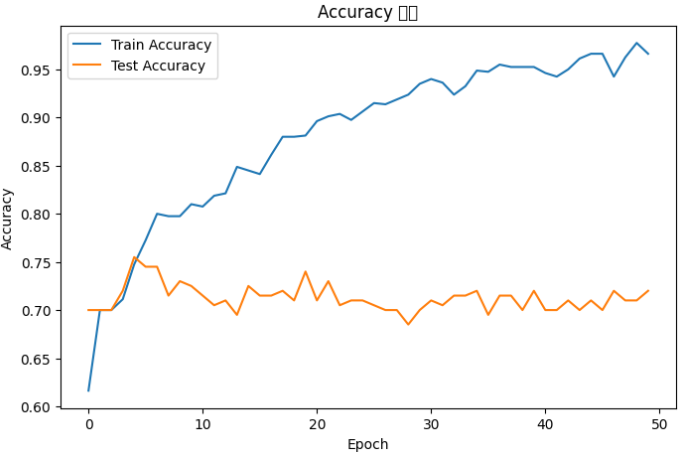
plt.show()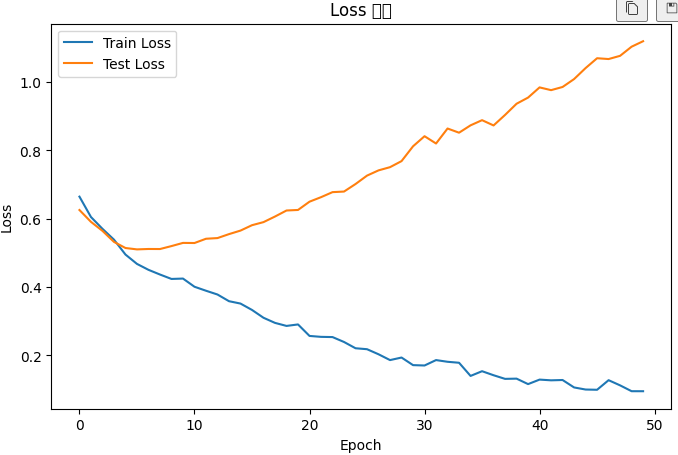
model.eval() 평가모드로 전환해
test_loader 에 미니배치 단위로 반복한다.
예측모델 점수를 계산해
toch.max() 가장 점수가높은 클래스를 예측값으로 선택해
예측값을 cpu로 옮긴뒤 numpy 배열로 변환해 리스트에 추가한다 .
정답을 cpu로 옮긴뒤 numpy 배열로 변환해 리스트에 추가한다 .
정확도를 계산해 출력한다.
# ============================================================
# 16. 테스트 데이터 전체 예측
# ============================================================
# 모델을 평가 모드로 변경합니다.
model.eval()
# 예측값을 저장할 리스트입니다.
all_predictions = []
# 실제 정답을 저장할 리스트입니다.
all_labels = []
# 테스트 과정에서는 기울기 계산이 필요 없으므로 no_grad를 사용합니다.
with torch.no_grad():
# 테스트 데이터를 미니배치 단위로 반복합니다.
for batch_X, batch_y in test_loader:
# 입력 데이터를 학습 장치로 이동합니다.
batch_X = batch_X.to(device)
# 모델 예측 점수를 계산합니다.
outputs = model(batch_X)
# 가장 점수가 높은 클래스를 예측값으로 선택합니다.
_, predicted = torch.max(outputs, 1)
# 예측값을 CPU로 옮긴 뒤 numpy 배열로 변환하여 리스트에 추가합니다.
all_predictions.extend(predicted.cpu().numpy())
# 실제 정답도 numpy 배열로 변환하여 리스트에 추가합니다.
all_labels.extend(batch_y.numpy())
# 리스트를 numpy 배열로 변환합니다.
all_predictions = np.array(all_predictions)
all_labels = np.array(all_labels)
# 정확도를 계산합니다.
test_accuracy = accuracy_score(all_labels, all_predictions)
# 테스트 정확도를 출력합니다.
print("테스트 정확도:", round(test_accuracy, 4))
confusion_matrix를 계산하고 dataframe으로 변환해 출력한다.
# ============================================================
# 17. Confusion Matrix 출력
# ============================================================
# Confusion Matrix를 계산합니다.
cm = confusion_matrix(all_labels, all_predictions)
# Confusion Matrix를 표 형태의 DataFrame으로 변환합니다.
cm_df = pd.DataFrame(
cm,
index=[f"Actual_{label}" for label in label_encoder.classes_],
columns=[f"Pred_{label}" for label in label_encoder.classes_]
)
# Confusion Matrix를 출력합니다.
cm_df
classification_report로 상세 리포트를 출력한다.
# ============================================================
# 18. 상세 분류 리포트 출력
# ============================================================
# classification_report는 precision, recall, f1-score를 한 번에 보여줍니다.
# precision은 예측한 것 중 실제로 맞은 비율입니다.
# recall은 실제 정답 중 모델이 찾아낸 비율입니다.
# f1-score는 precision과 recall을 함께 고려한 점수입니다.
report = classification_report(
all_labels,
all_predictions,
target_names=[str(cls) for cls in label_encoder.classes_]
)
# 상세 평가 결과를 출력합니다.
print(report)
신규대출자 데이터를 세팅해 예측한다.
# ============================================================
# 19. 신규 대출 신청자 예측 예시
# ============================================================
# 테스트 데이터에서 첫 번째 신청자 데이터를 하나 가져옵니다.
new_applicant = X_test.iloc[[0]]
# 신규 신청자 데이터를 확인합니다.
display(new_applicant)
# 학습 데이터 기준으로 만든 전처리기를 사용하여 신규 데이터를 변환합니다.
new_applicant_processed = preprocessor.transform(new_applicant)
# 희소 행렬이면 일반 배열로 변환합니다.
new_applicant_processed = (
new_applicant_processed.toarray()
if hasattr(new_applicant_processed, "toarray")
else new_applicant_processed
)
# float32 자료형으로 변환합니다.
new_applicant_processed = new_applicant_processed.astype(np.float32)
# numpy 배열을 PyTorch 텐서로 변환합니다.
new_applicant_tensor = torch.tensor(new_applicant_processed, dtype=torch.float32).to(device)
# 모델을 평가 모드로 변경합니다.
model.eval()
# 기울기 계산 없이 예측합니다.
with torch.no_grad():
# 모델의 출력 점수를 계산합니다.
output = model(new_applicant_tensor)
# softmax는 점수를 확률처럼 해석할 수 있게 변환합니다.
probabilities = torch.softmax(output, dim=1)
# 가장 확률이 높은 클래스를 선택합니다.
predicted_class = torch.argmax(probabilities, dim=1).item()
# 숫자 라벨을 원래 문자 라벨로 되돌립니다.
predicted_label = label_encoder.inverse_transform([predicted_class])[0]
# 예측 결과를 출력합니다.
print("예측 라벨:", predicted_label)
# 클래스별 예측 확률을 출력합니다.
for label, prob in zip(label_encoder.classes_, probabilities.cpu().numpy()[0]):
print(f"{label} 확률: {prob:.4f}")
마찬가지로 코드는 여기서 끝난다. 공부를 위해 다시 흝었었다 .
코드는 동일하다. 이제부터 random forest 적용기법의 코드가 나온다 .
마찬가지로 globals를 조회해 앞선 모델의 정확도를 저장한다.
randomforeseclassfier 하나를 추가 import해 여러개 의사결정트리르 사용하는 대표적인 앙상블 모델을 사용한다
# ============================================================
# 추가 1. 앙상블 평가에 필요한 라이브러리 불러오기
# ============================================================
# pandas는 성능 비교표를 만들 때 사용합니다.
import pandas as pd
# numpy는 배열 계산에 사용합니다.
import numpy as np
# matplotlib은 성능 비교 그래프를 그릴 때 사용합니다.
import matplotlib.pyplot as plt
# accuracy_score는 정확도를 계산합니다.
from sklearn.metrics import accuracy_score
# confusion_matrix는 실제값과 예측값의 관계를 표로 정리합니다.
from sklearn.metrics import confusion_matrix
# classification_report는 precision, recall, f1-score를 한 번에 출력합니다.
from sklearn.metrics import classification_report
# 기존 PyTorch MLP 모델의 정확도가 저장되어 있는지 확인합니다.
# 위쪽 기존 코드를 순서대로 실행했다면 test_accuracy 변수가 존재합니다.
if "test_accuracy" in globals():
# 기존 PyTorch 모델의 정확도를 baseline_accuracy 변수에 저장합니다.
baseline_accuracy = test_accuracy
else:
# 기존 모델 평가 셀을 실행하지 않은 경우를 대비하여 None으로 둡니다.
baseline_accuracy = None
# 기존 모델 정확도를 확인합니다.
print("기존 PyTorch MLP 테스트 정확도:", baseline_accuracy)
# RandomForestClassifier는 여러 개의 의사결정트리를 사용하는 대표적인 앙상블 모델입니다.
from sklearn.ensemble import RandomForestClassifier
randomForestClassifier 객체를 만들어
생성할 트리갯수 n_estimators,
트리깊이 max_depth를 설정한다.
max_features=sqrt는 각 분기에서 일부만 후보로 사용한다는 의미로 트리들이 서로 비슷해지는 문제를 줄인다.
class_weight = balanced는 클래스 비율이 불균형할때 적은 클래스에 더 큰 가중치를 줘 한쪽 클래스가 더 많은 경우 도움이 되도록 한다.
random_state=seed 로 난수를 고정한가.
n_jobs = -1 마찬가지로 가능한 cpu코어를 모두 사용해 성능을 높인다 .
fit() randomforestclassifier 객체를 학습시키고 출력한다.
# ============================================================
# 추가 2. Random Forest 모델 생성 및 학습
# ============================================================
# RandomForestClassifier를 생성합니다.
ensemble_model = RandomForestClassifier(
# n_estimators는 생성할 의사결정트리 개수입니다.
n_estimators=300,
# max_depth=None은 트리 깊이를 별도로 제한하지 않는 설정입니다.
# 필요하면 3, 5, 10 같은 숫자로 제한하여 과적합을 줄일 수 있습니다.
max_depth=None,
# max_features="sqrt"는 각 분기에서 전체 특성 중 일부만 후보로 사용한다는 뜻입니다.
# 이 설정은 트리들이 서로 비슷해지는 문제를 줄이는 데 도움이 됩니다.
max_features="sqrt",
# class_weight="balanced"는 클래스 비율이 불균형할 때 적은 클래스에 더 큰 가중치를 줍니다.
# 신용위험 데이터처럼 한쪽 클래스가 더 많은 경우 도움이 될 수 있습니다.
class_weight="balanced",
# random_state는 결과 재현을 위해 난수를 고정합니다.
random_state=SEED,
# n_jobs=-1은 가능한 CPU 코어를 모두 사용합니다.
n_jobs=-1
)
# fit은 전처리된 학습 데이터와 정답을 이용하여 Random Forest를 학습합니다.
ensemble_model.fit(X_train_processed, y_train)
# 학습이 끝났음을 출력합니다.
print("Random Forest 모델 학습 완료")
predict 예측값을 생성해
accuracy_score 정확도를 계산하고 추력한다.
confusion_matrix를 계산해 출력한다.
classification_report 상세표를 출력한다.
# ============================================================
# 추가 3. Random Forest 예측 및 성능 평가
# ============================================================
# 학습된 Random Forest 모델에 테스트 데이터를 넣어 예측값을 생성합니다.
rf_predictions = ensemble_model.predict(X_test_processed)
# 실제 정답 y_test와 예측값을 비교하여 정확도를 계산합니다.
rf_accuracy = accuracy_score(y_test, rf_predictions)
# 정확도를 출력합니다.
print("Random Forest 테스트 정확도:", round(rf_accuracy, 4))
# Confusion Matrix를 계산합니다.
ensemble_cm = confusion_matrix(y_test, rf_predictions)
# Confusion Matrix를 보기 좋은 표 형태로 변환합니다.
ensemble_cm_df = pd.DataFrame(
ensemble_cm,
index=[f"Actual_{label}" for label in label_encoder.classes_],
columns=[f"Pred_{label}" for label in label_encoder.classes_]
)
# Confusion Matrix를 출력합니다.
display(ensemble_cm_df)
# precision, recall, f1-score를 포함한 상세 평가 결과를 출력합니다.
print(classification_report(
y_test,
rf_predictions,
target_names=[str(cls) for cls in label_encoder.classes_]
))
기존 모델과 비교하며 그래프를 그린다
# ============================================================
# 추가 4. 기존 PyTorch 모델과 Random Forest 성능 비교
# ============================================================
# 성능 비교 결과를 저장할 리스트를 만듭니다.
comparison_rows = []
# 기존 PyTorch MLP 정확도가 있으면 비교표에 추가합니다.
if baseline_accuracy is not None:
# 기존 PyTorch 모델의 이름과 정확도를 저장합니다.
comparison_rows.append({"Model": "PyTorch MLP", "Accuracy": baseline_accuracy})
# 이번에 학습한 앙상블 모델의 이름과 정확도를 저장합니다.
comparison_rows.append({"Model": "Random Forest", "Accuracy": rf_accuracy})
# 리스트를 표 형태의 DataFrame으로 변환합니다.
comparison_df = pd.DataFrame(comparison_rows)
# 정확도가 높은 모델이 위에 오도록 정렬합니다.
comparison_df = comparison_df.sort_values(by="Accuracy", ascending=False).reset_index(drop=True)
# 정확도 값을 소수점 네 자리까지 보기 좋게 반올림합니다.
comparison_df["Accuracy"] = comparison_df["Accuracy"].round(4)
# 성능 비교표를 출력합니다.
display(comparison_df)
# 그래프 크기를 지정합니다.
plt.figure(figsize=(7, 4))
# 모델별 정확도를 막대그래프로 표시합니다.
plt.bar(comparison_df["Model"], comparison_df["Accuracy"])
# 그래프 제목을 지정합니다.
plt.title("모델별 테스트 정확도 비교")
# x축 이름을 지정합니다.
plt.xlabel("모델")
# y축 이름을 지정합니다.
plt.ylabel("정확도")
# y축 범위를 0부터 1까지로 지정합니다.
plt.ylim(0, 1)
# 각 막대 위에 정확도 값을 표시합니다.
for index, value in enumerate(comparison_df["Accuracy"]):
# text는 그래프에 글자를 표시하는 함수입니다.
plt.text(index, value + 0.01, str(value), ha="center")
# 그래프를 출력합니다.
plt.show()
대표앙상블
Bagging(Random Forest): 여러 트리를 병렬로 만들어 투표.
Random Forest: Bagging에서 특정중요한 변수를 트리 대부분에서 써버리면 비슷해져 다양한 의견을 듣지 못하고 전부 비슷한 내용만 알게 된다 .이때 사용할 특성을 랜덤으로 제한해서 보완한것을 말함.
Boosting: bagging은 트리들이 동시에 학습했으나 Boostring은 앞 모델이 틀린 문제를 뒤 모델이 집중적으로공부한다 .
AdaBoost : 최초의 Boosting 알고리즘으로 틀린문제에 가중치를 준다. 틀린데이터를 중요데이터로 인식하는것.
Gradient Boosting: AdaBoost는 틀린데이터 찾기라면 Gradient Boosting은 오차 자체를 학습해 실제값이 100이고 예측값이 80이었다면 오차값 20을 줄이는 방향으로 학습해 성능이 점점 좋아진다. XGBoost, LightGBM, CatBoost 모두 같은 계열
샘플코드 decision_tree_torch_adaboost_added 를 분석해보자.
마찬가지. import
# ============================================================
# 1. 필요한 라이브러리 불러오기
# ============================================================
# pandas는 CSV 파일을 읽고 표 형태의 데이터를 다루기 위한 라이브러리입니다.
import pandas as pd
# numpy는 숫자 배열 계산을 빠르게 처리하기 위한 라이브러리입니다.
import numpy as np
# torch는 PyTorch의 핵심 라이브러리입니다.
# 텐서 생성, 신경망 학습, 자동 미분 등을 처리합니다.
import torch
# torch.nn은 신경망 계층, 손실 함수 등을 만들 때 사용하는 모듈입니다.
import torch.nn as nn
# torch.optim은 Adam, SGD 같은 최적화 알고리즘을 제공하는 모듈입니다.
import torch.optim as optim
# Dataset과 DataLoader는 데이터를 PyTorch 모델에 넣기 좋은 형태로 관리하는 도구입니다.
from torch.utils.data import Dataset, DataLoader
# train_test_split은 데이터를 학습용과 테스트용으로 나누는 함수입니다.
from sklearn.model_selection import train_test_split
# ColumnTransformer는 수치형/범주형 컬럼에 서로 다른 전처리를 적용할 때 사용합니다.
from sklearn.compose import ColumnTransformer
# OneHotEncoder는 문자 범주 데이터를 0과 1의 숫자 벡터로 변환합니다.
from sklearn.preprocessing import OneHotEncoder, StandardScaler, LabelEncoder
# Pipeline은 여러 전처리 단계를 하나로 묶어 실행할 때 사용합니다.
from sklearn.pipeline import Pipeline
# accuracy_score와 confusion_matrix는 모델 평가 지표를 계산합니다.
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# matplotlib은 그래프를 그리기 위한 라이브러리입니다.
import matplotlib.pyplot as plt
# random은 파이썬의 난수 생성을 제어할 때 사용합니다.
import random
# os는 파일 경로 확인 등에 사용합니다.
import os
# 경고 메시지를 줄여 출력 화면을 깔끔하게 만들기 위해 사용합니다.
import warnings
# 불필요한 경고 메시지를 숨깁니다.
warnings.filterwarnings("ignore")
# 현재 사용 가능한 장치를 확인합니다.
# Colab에서 GPU를 켜면 cuda가 출력되고, 그렇지 않으면 cpu가 출력됩니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 현재 학습에 사용할 장치를 출력합니다.
print("사용 장치:", device)
skstnfmf rhwjdgksek.
np.random, torch.manual_seed, torch.cuda.manual_seed_all, torch.backends.cudnn.deterministic, torch.backends.cudnn.benchmark가 있다 .
# ============================================================
# 2. 난수 고정
# ============================================================
# 난수를 고정하면 코드를 다시 실행해도 최대한 같은 결과가 나오도록 만들 수 있습니다.
SEED = 123
# 파이썬 random 라이브러리의 난수를 고정합니다.
random.seed(SEED)
# numpy 난수를 고정합니다.
np.random.seed(SEED)
# PyTorch CPU 연산의 난수를 고정합니다.
torch.manual_seed(SEED)
# PyTorch GPU 연산의 난수를 고정합니다.
torch.cuda.manual_seed_all(SEED)
# CUDA 연산의 재현성을 높이기 위한 설정입니다.
torch.backends.cudnn.deterministic = True
# 실행 속도 최적화보다 재현성을 우선하도록 설정합니다.
torch.backends.cudnn.benchmark = False
데이터를 불러오고 최소가공한다.
# ============================================================
# 3. 데이터 불러오기
# ============================================================
# 사용한 파일 경로입니다.
local_path = "data/credit_info.csv"
# 공개 German Credit 데이터셋 주소입니다.
# Colab에서 data/credit_info.csv 파일이 없을 때 자동으로 읽어옵니다.
url = "https://raw.githubusercontent.com/stedy/Machine-Learning-with-R-datasets/master/credit.csv"
# data 폴더가 없으면 새로 생성합니다.
os.makedirs("data", exist_ok=True)
# local_path 파일이 실제로 존재하는지 확인합니다.
if os.path.exists(local_path):
# 파일이 있으면 사용자가 제공한 로컬 CSV 파일을 읽습니다.
credit_info = pd.read_csv(local_path)
else:
# 파일이 없으면 공개 URL에서 CSV 파일을 읽습니다.
credit_info = pd.read_csv(url)
# 다음 실행 때도 같은 파일을 사용할 수 있도록 data 폴더에 저장합니다.
credit_info.to_csv(local_path, index=False)
# 목표 변수를 Repay라고 사용합니다.
# 공개 데이터셋은 목표 컬럼명이 default일 수 있으므로 Repay로 바꿉니다.
if "Repay" not in credit_info.columns and "default" in credit_info.columns:
# default 컬럼명을 Repay로 변경합니다.
credit_info = credit_info.rename(columns={"default": "Repay"})
# 데이터의 앞부분 5행을 확인합니다.
credit_info.head()
데이터 구조를 확인한다.
데이터를 기본탐색한다.
# ============================================================
# 4. 데이터 구조 확인
# ============================================================
# 데이터의 행과 열 개수를 확인합니다.
print("데이터 크기:", credit_info.shape)
# 각 컬럼의 자료형과 결측치 여부를 확인합니다.
credit_info.info()
# 컬럼 이름 목록을 출력합니다.
print("\n컬럼 목록:")
print(credit_info.columns.tolist())# ============================================================
# 5. 기본 탐색
# ============================================================
# checking_balance 컬럼은 신청자의 수표 계좌 잔고 범주를 의미합니다.
# value_counts()는 R의 table()과 비슷하게 값별 개수를 세어 줍니다.
print("checking_balance 빈도:")
print(credit_info["checking_balance"].value_counts())
# savings_balance 컬럼은 신청자의 저축 계좌 잔고 범주를 의미합니다.
print("\nsavings_balance 빈도:")
print(credit_info["savings_balance"].value_counts())
# months_loan_duration은 대출 기간입니다.
# describe()는 평균, 표준편차, 최솟값, 최댓값 등을 보여줍니다.
print("\nmonths_loan_duration 요약:")
print(credit_info["months_loan_duration"].describe())
# amount는 대출 금액입니다.
print("\namount 요약:")
print(credit_info["amount"].describe())
# Repay는 상환 여부 또는 채무불이행 여부를 나타내는 목표 변수입니다.
print("\nRepay 빈도:")
print(credit_info["Repay"].value_counts())
# Repay 비율을 확인합니다.
print("\nRepay 비율:")
print(credit_info["Repay"].value_counts(normalize=True))
입력데이터와 정답데이터를 분리한다.
labelencoder를 사용해 문자라벨은 숫자라벨로 바꾼다.
수치형 컬럼과 범주형 컬럼을 구분한다.
학습데이터와 테스트 데이터를 분리한다.
# ============================================================
# 6. 입력 X와 정답 y 분리
# ============================================================
# 목표 컬럼명을 변수로 저장합니다.
target_col = "Repay"
# 목표 컬럼이 실제 데이터에 있는지 확인합니다.
if target_col not in credit_info.columns:
# 목표 컬럼이 없으면 에러를 발생시켜 문제 원인을 바로 알 수 있게 합니다.
raise ValueError("데이터에 Repay 컬럼이 없습니다. 목표 컬럼명을 확인하세요.")
# X는 Repay를 제외한 모든 컬럼입니다.
X = credit_info.drop(columns=[target_col])
# y는 모델이 예측해야 하는 Repay 컬럼입니다.
y = credit_info[target_col]
# LabelEncoder는 문자 라벨을 숫자 라벨로 바꿉니다.
# 예: no -> 0, yes -> 1 과 같은 방식입니다.
label_encoder = LabelEncoder()
# y 값을 숫자 형태로 변환합니다.
y_encoded = label_encoder.fit_transform(y)
# 어떤 원래 라벨이 어떤 숫자로 바뀌었는지 확인합니다.
print("라벨 매핑:")
for original_label, encoded_label in zip(label_encoder.classes_, range(len(label_encoder.classes_))):
print(f"{original_label} -> {encoded_label}")
# ============================================================
# 7. 수치형 컬럼과 범주형 컬럼 구분
# ============================================================
# 수치형 컬럼은 int64, float64 같은 숫자 자료형 컬럼입니다.
numeric_features = X.select_dtypes(include=["int64", "float64"]).columns.tolist()
# 범주형 컬럼은 object, category 같은 문자 또는 범주 자료형 컬럼입니다.
categorical_features = X.select_dtypes(include=["object", "category", "bool"]).columns.tolist()
# 수치형 컬럼 목록을 출력합니다.
print("수치형 컬럼:", numeric_features)
# 범주형 컬럼 목록을 출력합니다.
print("범주형 컬럼:", categorical_features)# ============================================================
# 8. 학습 데이터와 테스트 데이터 분리
# ============================================================
# train_test_split은 데이터를 학습용과 테스트용으로 나눕니다.
# test_size=0.2는 전체 데이터의 20%를 테스트용으로 사용한다는 뜻입니다.
# 800개 학습 / 200개 테스트 분리와 같은 비율입니다.
# stratify=y_encoded는 정답 라벨 비율이 학습/테스트에 비슷하게 유지되도록 합니다.
X_train, X_test, y_train, y_test = train_test_split(
X,
y_encoded,
test_size=0.2,
random_state=SEED,
stratify=y_encoded
)
# 분리된 데이터 크기를 확인합니다.
print("X_train 크기:", X_train.shape)
print("X_test 크기:", X_test.shape)
print("y_train 크기:", y_train.shape)
print("y_test 크기:", y_test.shape)
# 학습 데이터의 클래스 비율을 확인합니다.
print("\n학습 데이터 클래스 비율:")
print(pd.Series(y_train).value_counts(normalize=True).sort_index())
# 테스트 데이터의 클래스 비율을 확인합니다.
print("\n테스트 데이터 클래스 비율:")
print(pd.Series(y_test).value_counts(normalize=True).sort_index())
전처리 Pipeline()을 만들고 수치형데이터에 standardScaler를 수행해 데이터 크기 차이를 줄이고
범주형 데이터에는 onehotencoder를 사용해 숫자로 벡터화하되 handle_unkown=ignore학습때 모지못한 범주는 무시해 에러를 막는다 .
columtransformer로 컬럼 종류별 다른 전처리를 적용하며
학습데이터만 fit.transform 전처리 규칙을 학습하고 변환한다.
onehotencoder 겨리과가 행렬일수있음으로 numpy 배열로 변환한고
pytorch기본형으로 특성 들을 float32로변환한다.
정답라벨은 long타입으로 변환한다 .
# ============================================================
# 9. 전처리 파이프라인 생성
# ============================================================
# 수치형 데이터 전처리: StandardScaler로 표준화합니다.
numeric_transformer = Pipeline(
steps=[
# StandardScaler는 수치 데이터의 크기 차이를 줄여 학습을 안정적으로 만듭니다.
("scaler", StandardScaler())
]
)
# 범주형 데이터 전처리: OneHotEncoder로 숫자 벡터화합니다.
categorical_transformer = Pipeline(
steps=[
# handle_unknown="ignore"는 테스트 데이터에 학습 때 보지 못한 범주가 나와도 에러를 막습니다.
("onehot", OneHotEncoder(handle_unknown="ignore"))
]
)
# ColumnTransformer는 컬럼 종류별로 다른 전처리를 적용합니다.
preprocessor = ColumnTransformer(
transformers=[
# numeric_features 컬럼에는 numeric_transformer를 적용합니다.
("num", numeric_transformer, numeric_features),
# categorical_features 컬럼에는 categorical_transformer를 적용합니다.
("cat", categorical_transformer, categorical_features)
]
)
# fit_transform은 학습 데이터 기준으로 전처리 규칙을 학습하고 바로 변환합니다.
X_train_processed = preprocessor.fit_transform(X_train)
# transform은 학습 데이터에서 만든 규칙을 테스트 데이터에 그대로 적용합니다.
X_test_processed = preprocessor.transform(X_test)
# OneHotEncoder 결과가 희소 행렬일 수 있으므로 일반 numpy 배열로 변환합니다.
X_train_processed = X_train_processed.toarray() if hasattr(X_train_processed, "toarray") else X_train_processed
X_test_processed = X_test_processed.toarray() if hasattr(X_test_processed, "toarray") else X_test_processed
# PyTorch는 float32 자료형을 주로 사용하므로 float32로 변환합니다.
X_train_processed = X_train_processed.astype(np.float32)
X_test_processed = X_test_processed.astype(np.float32)
# 정답 라벨은 분류 문제에서 long 타입으로 사용합니다.
y_train = y_train.astype(np.int64)
y_test = y_test.astype(np.int64)
# 전처리 후 입력 특성 개수를 확인합니다.
print("전처리 후 학습 입력 크기:", X_train_processed.shape)
print("전처리 후 테스트 입력 크기:", X_test_processed.shape)
torch.tensor로 특성들을 torch 텐서로 변환한다 .
dataset 객체를 생성하고 batch갯수를 지정해 dataloader에 담는다.
# ============================================================
# 10. PyTorch Dataset 클래스 정의
# ============================================================
# CreditDataset은 대출 데이터를 PyTorch가 사용할 수 있는 형태로 포장하는 클래스입니다.
class CreditDataset(Dataset):
# __init__은 Dataset 객체가 만들어질 때 한 번 실행됩니다.
def __init__(self, features, labels):
# 입력 특성을 torch 텐서로 변환합니다.
self.features = torch.tensor(features, dtype=torch.float32)
# 정답 라벨을 torch 텐서로 변환합니다.
self.labels = torch.tensor(labels, dtype=torch.long)
# __len__은 데이터가 총 몇 개인지 반환합니다.
def __len__(self):
# labels의 길이가 전체 데이터 개수입니다.
return len(self.labels)
# __getitem__은 특정 번호의 데이터 1개를 반환합니다.
def __getitem__(self, idx):
# idx번째 입력 데이터와 정답 라벨을 함께 반환합니다.
return self.features[idx], self.labels[idx]
# 학습용 Dataset 객체를 생성합니다.
train_dataset = CreditDataset(X_train_processed, y_train)
# 테스트용 Dataset 객체를 생성합니다.
test_dataset = CreditDataset(X_test_processed, y_test)
# 한 번에 학습할 데이터 개수입니다.
# 32개씩 묶어서 모델에 넣습니다.
batch_size = 32
# 학습용 DataLoader를 생성합니다.
# shuffle=True는 매 epoch마다 데이터 순서를 섞어 학습 효과를 높입니다.
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 테스트용 DataLoader를 생성합니다.
# 테스트는 순서를 섞을 필요가 없으므로 shuffle=False입니다.
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 첫 번째 미니배치를 꺼내 입력과 정답 크기를 확인합니다.
sample_X, sample_y = next(iter(train_loader))
# 미니배치 입력 크기를 출력합니다.
print("미니배치 입력 크기:", sample_X.shape)
# 미니배치 정답 크기를 출력합니다.
print("미니배치 정답 크기:", sample_y.shape)
신경망을 만들고 forward로 해당 함수를 타도록 세팅한다.
creditMLP 모델객체를 생성한뒤 to(device)학습장치로 이동한다.
# ============================================================
# 11. PyTorch 모델 정의
# ============================================================
# CreditMLP는 대출 상환 여부를 분류하는 신경망 모델입니다.
class CreditMLP(nn.Module):
# __init__은 모델 구조를 정의하는 부분입니다.
def __init__(self, input_dim, num_classes):
# 부모 클래스 nn.Module의 초기화 함수를 실행합니다.
super(CreditMLP, self).__init__()
# self.network는 여러 신경망 계층을 순서대로 묶은 구조입니다.
self.network = nn.Sequential(
# 첫 번째 완전연결층입니다.
# input_dim개의 입력을 받아 64개의 값으로 변환합니다.
nn.Linear(input_dim, 64),
# ReLU는 음수는 0으로, 양수는 그대로 통과시키는 활성화 함수입니다.
# 모델이 복잡한 패턴을 학습할 수 있게 도와줍니다.
nn.ReLU(),
# Dropout은 일부 뉴런을 무작위로 끄는 기법입니다.
# 과적합을 줄이는 데 도움이 됩니다.
nn.Dropout(0.2),
# 두 번째 완전연결층입니다.
# 64개의 입력을 받아 32개의 값으로 변환합니다.
nn.Linear(64, 32),
# 두 번째 ReLU 활성화 함수입니다.
nn.ReLU(),
# 마지막 출력층입니다.
# 32개의 입력을 클래스 개수만큼의 점수로 변환합니다.
nn.Linear(32, num_classes)
)
# forward는 입력 데이터가 모델을 통과하는 계산 과정을 정의합니다.
def forward(self, x):
# 입력 x를 self.network에 통과시켜 출력값을 만듭니다.
return self.network(x)
# 입력 특성 개수입니다.
input_dim = X_train_processed.shape[1]
# 분류할 클래스 개수입니다.
num_classes = len(label_encoder.classes_)
# 모델 객체를 생성하고 학습 장치(cpu 또는 cuda)로 이동합니다.
model = CreditMLP(input_dim=input_dim, num_classes=num_classes).to(device)
# 모델 구조를 출력합니다.
print(model)
손실함수를 정의한다.
평가함수를 정의한다 .
# ============================================================
# 12. 손실 함수와 최적화 알고리즘 설정
# ============================================================
# CrossEntropyLoss는 다중 분류 문제에서 많이 사용하는 손실 함수입니다.
# 모델의 예측이 정답과 얼마나 다른지 숫자로 계산합니다.
criterion = nn.CrossEntropyLoss()
# Adam은 학습률을 자동으로 조정해 가며 모델 파라미터를 업데이트하는 최적화 알고리즘입니다.
optimizer = optim.Adam(
model.parameters(), # 학습할 모델 파라미터를 지정합니다.
lr=0.001 # learning rate, 즉 한 번에 얼마나 크게 수정할지 정합니다.
)# ============================================================
# 13. 평가 함수 정의
# ============================================================
# evaluate 함수는 검증 또는 테스트 데이터에서 모델 성능을 계산합니다.
def evaluate(model, data_loader, criterion):
# 모델을 평가 모드로 바꿉니다.
# Dropout 같은 학습 전용 동작이 꺼집니다.
model.eval()
# 전체 손실값을 누적할 변수입니다.
total_loss = 0.0
# 맞힌 개수를 누적할 변수입니다.
correct = 0
# 전체 데이터 개수를 누적할 변수입니다.
total = 0
# 평가할 때는 기울기 계산이 필요 없으므로 no_grad를 사용합니다.
with torch.no_grad():
# DataLoader에서 미니배치 단위로 데이터를 꺼냅니다.
for batch_X, batch_y in data_loader:
# 입력 데이터를 학습 장치로 이동합니다.
batch_X = batch_X.to(device)
# 정답 라벨을 학습 장치로 이동합니다.
batch_y = batch_y.to(device)
# 모델에 입력 데이터를 넣어 예측 점수를 계산합니다.
outputs = model(batch_X)
# 예측 점수와 정답 사이의 손실값을 계산합니다.
loss = criterion(outputs, batch_y)
# 현재 미니배치 손실값에 데이터 개수를 곱해 누적합니다.
total_loss += loss.item() * batch_X.size(0)
# 가장 점수가 높은 클래스 번호를 예측값으로 선택합니다.
_, predicted = torch.max(outputs, 1)
# 전체 데이터 개수를 누적합니다.
total += batch_y.size(0)
# 예측값과 정답이 같은 개수를 누적합니다.
correct += (predicted == batch_y).sum().item()
# 평균 손실값을 계산합니다.
avg_loss = total_loss / total
# 정확도를 계산합니다.
accuracy = correct / total
# 평균 손실값과 정확도를 반환합니다.
return avg_loss, accuracy
epoch수만큼 반복학습한다.
손실값, 정확도를 저장한다 .
위 내용을 그래프로 표현한다.
# ============================================================
# 14. 모델 학습 실행
# ============================================================
# 전체 학습 반복 횟수입니다.
epochs = 50
# 학습 과정을 저장할 리스트입니다.
train_losses = []
train_accuracies = []
test_losses = []
test_accuracies = []
# epoch 수만큼 반복 학습합니다.
for epoch in range(epochs):
# 모델을 학습 모드로 바꿉니다.
# Dropout 같은 학습 전용 동작이 켜집니다.
model.train()
# 한 epoch 동안의 손실값을 누적할 변수입니다.
running_loss = 0.0
# 한 epoch 동안 맞힌 개수를 누적할 변수입니다.
correct = 0
# 한 epoch 동안 전체 데이터 개수를 누적할 변수입니다.
total = 0
# 학습 데이터를 미니배치 단위로 반복합니다.
for batch_X, batch_y in train_loader:
# 입력 데이터를 학습 장치로 이동합니다.
batch_X = batch_X.to(device)
# 정답 라벨을 학습 장치로 이동합니다.
batch_y = batch_y.to(device)
# 이전 미니배치에서 계산된 기울기를 초기화합니다.
optimizer.zero_grad()
# 모델에 입력 데이터를 넣어 예측 점수를 계산합니다.
outputs = model(batch_X)
# 예측 결과와 실제 정답 사이의 손실값을 계산합니다.
loss = criterion(outputs, batch_y)
# 손실값을 기준으로 각 파라미터의 기울기를 계산합니다.
loss.backward()
# 계산된 기울기를 사용하여 모델 파라미터를 업데이트합니다.
optimizer.step()
# 현재 미니배치 손실값을 누적합니다.
running_loss += loss.item() * batch_X.size(0)
# 가장 큰 점수를 가진 클래스를 예측값으로 선택합니다.
_, predicted = torch.max(outputs, 1)
# 전체 데이터 개수를 누적합니다.
total += batch_y.size(0)
# 예측값과 정답이 같은 개수를 누적합니다.
correct += (predicted == batch_y).sum().item()
# 한 epoch의 평균 학습 손실값을 계산합니다.
train_loss = running_loss / total
# 한 epoch의 학습 정확도를 계산합니다.
train_acc = correct / total
# 테스트 데이터에 대한 손실값과 정확도를 계산합니다.
test_loss, test_acc = evaluate(model, test_loader, criterion)
# 그래프 출력을 위해 값을 리스트에 저장합니다.
train_losses.append(train_loss)
train_accuracies.append(train_acc)
test_losses.append(test_loss)
test_accuracies.append(test_acc)
# epoch마다 학습 결과를 출력합니다.
print(
f"Epoch [{epoch + 1:02d}/{epochs}] "
f"Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}, "
f"Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.4f}"
)# ============================================================
# 15. 학습 과정 그래프 출력
# ============================================================
# 그래프 크기를 지정합니다.
plt.figure(figsize=(8, 5))
# 학습 손실값 변화를 선 그래프로 표시합니다.
plt.plot(train_losses, label="Train Loss")
# 테스트 손실값 변화를 선 그래프로 표시합니다.
plt.plot(test_losses, label="Test Loss")
# 그래프 제목을 지정합니다.
plt.title("Loss 변화")
# x축 이름을 지정합니다.
plt.xlabel("Epoch")
# y축 이름을 지정합니다.
plt.ylabel("Loss")
# 범례를 표시합니다.
plt.legend()
# 그래프를 출력합니다.
plt.show()
# 새로운 그래프 크기를 지정합니다.
plt.figure(figsize=(8, 5))
# 학습 정확도 변화를 선 그래프로 표시합니다.
plt.plot(train_accuracies, label="Train Accuracy")
# 테스트 정확도 변화를 선 그래프로 표시합니다.
plt.plot(test_accuracies, label="Test Accuracy")
# 그래프 제목을 지정합니다.
plt.title("Accuracy 변화")
# x축 이름을 지정합니다.
plt.xlabel("Epoch")
# y축 이름을 지정합니다.
plt.ylabel("Accuracy")
# 범례를 표시합니다.
plt.legend()
# 그래프를 출력합니다.
plt.show()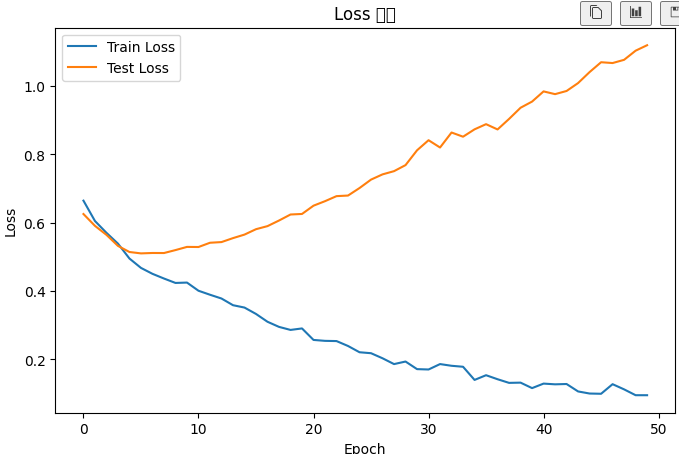

성능평가한다.
confusion matrix를 출력한다 .
classification_report 상세 리포트를 출력한다.
# ============================================================
# 16. 테스트 데이터 전체 예측
# ============================================================
# 모델을 평가 모드로 변경합니다.
model.eval()
# 예측값을 저장할 리스트입니다.
all_predictions = []
# 실제 정답을 저장할 리스트입니다.
all_labels = []
# 테스트 과정에서는 기울기 계산이 필요 없으므로 no_grad를 사용합니다.
with torch.no_grad():
# 테스트 데이터를 미니배치 단위로 반복합니다.
for batch_X, batch_y in test_loader:
# 입력 데이터를 학습 장치로 이동합니다.
batch_X = batch_X.to(device)
# 모델 예측 점수를 계산합니다.
outputs = model(batch_X)
# 가장 점수가 높은 클래스를 예측값으로 선택합니다.
_, predicted = torch.max(outputs, 1)
# 예측값을 CPU로 옮긴 뒤 numpy 배열로 변환하여 리스트에 추가합니다.
all_predictions.extend(predicted.cpu().numpy())
# 실제 정답도 numpy 배열로 변환하여 리스트에 추가합니다.
all_labels.extend(batch_y.numpy())
# 리스트를 numpy 배열로 변환합니다.
all_predictions = np.array(all_predictions)
all_labels = np.array(all_labels)
# 정확도를 계산합니다.
test_accuracy = accuracy_score(all_labels, all_predictions)
# 테스트 정확도를 출력합니다.
print("테스트 정확도:", round(test_accuracy, 4))# ============================================================
# 17. Confusion Matrix 출력
# ============================================================
# Confusion Matrix를 계산합니다.
cm = confusion_matrix(all_labels, all_predictions)
# Confusion Matrix를 표 형태의 DataFrame으로 변환합니다.
cm_df = pd.DataFrame(
cm,
index=[f"Actual_{label}" for label in label_encoder.classes_],
columns=[f"Pred_{label}" for label in label_encoder.classes_]
)
# Confusion Matrix를 출력합니다.
cm_df# ============================================================
# 18. 상세 분류 리포트 출력
# ============================================================
# classification_report는 precision, recall, f1-score를 한 번에 보여줍니다.
# precision은 예측한 것 중 실제로 맞은 비율입니다.
# recall은 실제 정답 중 모델이 찾아낸 비율입니다.
# f1-score는 precision과 recall을 함께 고려한 점수입니다.
report = classification_report(
all_labels,
all_predictions,
target_names=[str(cls) for cls in label_encoder.classes_]
)
# 상세 평가 결과를 출력합니다.
print(report)
신규데이터로 재예츠갛ㄴ다.
# ============================================================
# 19. 신규 대출 신청자 예측 예시
# ============================================================
# 테스트 데이터에서 첫 번째 신청자 데이터를 하나 가져옵니다.
new_applicant = X_test.iloc[[0]]
# 신규 신청자 데이터를 확인합니다.
display(new_applicant)
# 학습 데이터 기준으로 만든 전처리기를 사용하여 신규 데이터를 변환합니다.
new_applicant_processed = preprocessor.transform(new_applicant)
# 희소 행렬이면 일반 배열로 변환합니다.
new_applicant_processed = (
new_applicant_processed.toarray()
if hasattr(new_applicant_processed, "toarray")
else new_applicant_processed
)
# float32 자료형으로 변환합니다.
new_applicant_processed = new_applicant_processed.astype(np.float32)
# numpy 배열을 PyTorch 텐서로 변환합니다.
new_applicant_tensor = torch.tensor(new_applicant_processed, dtype=torch.float32).to(device)
# 모델을 평가 모드로 변경합니다.
model.eval()
# 기울기 계산 없이 예측합니다.
with torch.no_grad():
# 모델의 출력 점수를 계산합니다.
output = model(new_applicant_tensor)
# softmax는 점수를 확률처럼 해석할 수 있게 변환합니다.
probabilities = torch.softmax(output, dim=1)
# 가장 확률이 높은 클래스를 선택합니다.
predicted_class = torch.argmax(probabilities, dim=1).item()
# 숫자 라벨을 원래 문자 라벨로 되돌립니다.
predicted_label = label_encoder.inverse_transform([predicted_class])[0]
# 예측 결과를 출력합니다.
print("예측 라벨:", predicted_label)
# 클래스별 예측 확률을 출력합니다.
for label, prob in zip(label_encoder.classes_, probabilities.cpu().numpy()[0]):
print(f"{label} 확률: {prob:.4f}")
여기까지가 마찬가지의 코드였다.
adaboost 적용기법을 사용해보자.
이전 모델이 틀린 데이터에 더 큰 가중치를 주어 다음 모델이 데이터를 더 집중적으로 학습하게 한다 .
import 동일하나 아래가 다르다 .
sklearn.emsemble adaboostlassifier 이전 모델 오답에 더 집중하는 boosting 앙상블 모델
sklearn.tree decisiontreeclassifier adaboost 안에서 사용할 약한 학습기
# ============================================================
# 추가 1. 앙상블 평가에 필요한 라이브러리 불러오기
# ============================================================
# pandas는 성능 비교표를 만들 때 사용합니다.
import pandas as pd
# numpy는 배열 계산에 사용합니다.
import numpy as np
# matplotlib은 성능 비교 그래프를 그릴 때 사용합니다.
import matplotlib.pyplot as plt
# accuracy_score는 정확도를 계산합니다.
from sklearn.metrics import accuracy_score
# confusion_matrix는 실제값과 예측값의 관계를 표로 정리합니다.
from sklearn.metrics import confusion_matrix
# classification_report는 precision, recall, f1-score를 한 번에 출력합니다.
from sklearn.metrics import classification_report
# 기존 PyTorch MLP 모델의 정확도가 저장되어 있는지 확인합니다.
# 위쪽 기존 코드를 순서대로 실행했다면 test_accuracy 변수가 존재합니다.
if "test_accuracy" in globals():
# 기존 PyTorch 모델의 정확도를 baseline_accuracy 변수에 저장합니다.
baseline_accuracy = test_accuracy
else:
# 기존 모델 평가 셀을 실행하지 않은 경우를 대비하여 None으로 둡니다.
baseline_accuracy = None
# 기존 모델 정확도를 확인합니다.
print("기존 PyTorch MLP 테스트 정확도:", baseline_accuracy)
# AdaBoostClassifier는 이전 모델의 오답에 더 집중하는 Boosting 앙상블 모델입니다.
from sklearn.ensemble import AdaBoostClassifier
# DecisionTreeClassifier는 AdaBoost 안에서 사용할 약한 학습기입니다.
from sklearn.tree import DecisionTreeClassifier
decisiontreeclassifier 객체를 만들어
adaboostclassifier 객체를 만든다. base_tree 기준으로 n_estimators 모델의 갯수를 정한다.
leaning_rate는 각 약한 모델의 영향력을 조절한다.
random_state= seed로 결과대현을 위해 난수를 곶ㅇ한다.
마찬가지로 fit.
# ============================================================
# 추가 2. AdaBoost 모델 생성 및 학습
# ============================================================
# AdaBoost에서 사용할 기본 의사결정트리를 생성합니다.
# max_depth=1은 한 번만 분기하는 매우 단순한 트리를 의미합니다.
# 이런 단순한 트리를 여러 개 연결하여 강한 모델을 만듭니다.
base_tree = DecisionTreeClassifier(
max_depth=1,
random_state=SEED
)
# scikit-learn 버전에 따라 파라미터 이름이 estimator 또는 base_estimator로 다를 수 있습니다.
# Colab의 최신 버전에서는 estimator를 사용합니다.
try:
# 최신 scikit-learn 방식입니다.
ensemble_model = AdaBoostClassifier(
estimator=base_tree,
# n_estimators는 순차적으로 만들 약한 모델의 개수입니다.
n_estimators=200,
# learning_rate는 각 약한 모델의 영향력을 조절합니다.
learning_rate=0.5,
# random_state는 결과 재현을 위해 난수를 고정합니다.
random_state=SEED
)
except TypeError:
# 예전 scikit-learn 방식입니다.
ensemble_model = AdaBoostClassifier(
base_estimator=base_tree,
n_estimators=200,
learning_rate=0.5,
random_state=SEED
)
# fit은 학습 데이터와 정답을 사용하여 AdaBoost 모델을 학습합니다.
ensemble_model.fit(X_train_processed, y_train)
# 학습이 끝났음을 출력합니다.
print("AdaBoost 모델 학습 완료")
성능을 평가한다.
# ============================================================
# 추가 3. AdaBoost 예측 및 성능 평가
# ============================================================
# 학습된 AdaBoost 모델에 테스트 데이터를 넣어 예측값을 생성합니다.
ada_predictions = ensemble_model.predict(X_test_processed)
# 실제 정답 y_test와 예측값을 비교하여 정확도를 계산합니다.
ada_accuracy = accuracy_score(y_test, ada_predictions)
# 정확도를 출력합니다.
print("AdaBoost 테스트 정확도:", round(ada_accuracy, 4))
# Confusion Matrix를 계산합니다.
ensemble_cm = confusion_matrix(y_test, ada_predictions)
# Confusion Matrix를 보기 좋은 표 형태로 변환합니다.
ensemble_cm_df = pd.DataFrame(
ensemble_cm,
index=[f"Actual_{label}" for label in label_encoder.classes_],
columns=[f"Pred_{label}" for label in label_encoder.classes_]
)
# Confusion Matrix를 출력합니다.
display(ensemble_cm_df)
# precision, recall, f1-score를 포함한 상세 평가 결과를 출력합니다.
print(classification_report(
y_test,
ada_predictions,
target_names=[str(cls) for cls in label_encoder.classes_]
))
기존모델과의 성능을 비교한다 .
# ============================================================
# 추가 4. 기존 PyTorch 모델과 AdaBoost 성능 비교
# ============================================================
# 성능 비교 결과를 저장할 리스트를 만듭니다.
comparison_rows = []
# 기존 PyTorch MLP 정확도가 있으면 비교표에 추가합니다.
if baseline_accuracy is not None:
# 기존 PyTorch 모델의 이름과 정확도를 저장합니다.
comparison_rows.append({"Model": "PyTorch MLP", "Accuracy": baseline_accuracy})
# 이번에 학습한 앙상블 모델의 이름과 정확도를 저장합니다.
comparison_rows.append({"Model": "AdaBoost", "Accuracy": ada_accuracy})
# 리스트를 표 형태의 DataFrame으로 변환합니다.
comparison_df = pd.DataFrame(comparison_rows)
# 정확도가 높은 모델이 위에 오도록 정렬합니다.
comparison_df = comparison_df.sort_values(by="Accuracy", ascending=False).reset_index(drop=True)
# 정확도 값을 소수점 네 자리까지 보기 좋게 반올림합니다.
comparison_df["Accuracy"] = comparison_df["Accuracy"].round(4)
# 성능 비교표를 출력합니다.
display(comparison_df)
# 그래프 크기를 지정합니다.
plt.figure(figsize=(7, 4))
# 모델별 정확도를 막대그래프로 표시합니다.
plt.bar(comparison_df["Model"], comparison_df["Accuracy"])
# 그래프 제목을 지정합니다.
plt.title("모델별 테스트 정확도 비교")
# x축 이름을 지정합니다.
plt.xlabel("모델")
# y축 이름을 지정합니다.
plt.ylabel("정확도")
# y축 범위를 0부터 1까지로 지정합니다.
plt.ylim(0, 1)
# 각 막대 위에 정확도 값을 표시합니다.
for index, value in enumerate(comparison_df["Accuracy"]):
# text는 그래프에 글자를 표시하는 함수입니다.
plt.text(index, value + 0.01, str(value), ha="center")
# 그래프를 출력합니다.
plt.show()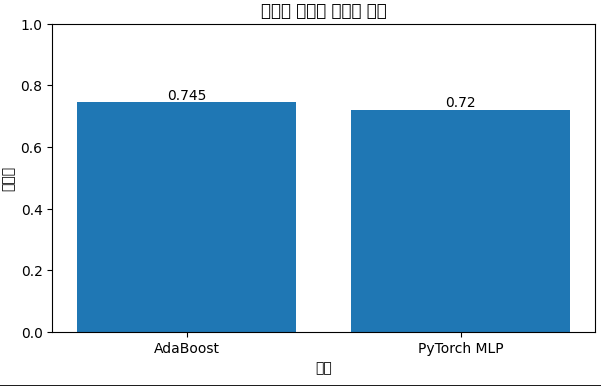
대표앙상블
Bagging(Random Forest): 여러 트리를 병렬로 만들어 투표.
Random Forest: Bagging에서 특정중요한 변수를 트리 대부분에서 써버리면 비슷해져 다양한 의견을 듣지 못하고 전부 비슷한 내용만 알게 된다 .이때 사용할 특성을 랜덤으로 제한해서 보완한것을 말함.
Boosting: bagging은 트리들이 동시에 학습했으나 Boostring은 앞 모델이 틀린 문제를 뒤 모델이 집중적으로공부한다 .
AdaBoost : 최초의 Boostinㅎ 알고리즘으로 틀린문제에 가중치를 준다. 틀린데이터를 중요데이터로 인식하는것.
Gradient Boosting: AdaBoost는 틀린데이터 찾기라면 Gradient Boosting은 오차 자체를 학습해 실제값이 100이고 예측값이 80이었다면 오차값 20을 줄이는 방향으로 학습해 성능이 점점 좋아진다. XGBoost, LightGBM, CatBoost 모두 같은 계열
샘플코드 decision_tree_torch_gradient_boostring_added 를 분석해보자.
마찬가지로 import
# ============================================================
# 1. 필요한 라이브러리 불러오기
# ============================================================
# pandas는 CSV 파일을 읽고 표 형태의 데이터를 다루기 위한 라이브러리입니다.
import pandas as pd
# numpy는 숫자 배열 계산을 빠르게 처리하기 위한 라이브러리입니다.
import numpy as np
# torch는 PyTorch의 핵심 라이브러리입니다.
# 텐서 생성, 신경망 학습, 자동 미분 등을 처리합니다.
import torch
# torch.nn은 신경망 계층, 손실 함수 등을 만들 때 사용하는 모듈입니다.
import torch.nn as nn
# torch.optim은 Adam, SGD 같은 최적화 알고리즘을 제공하는 모듈입니다.
import torch.optim as optim
# Dataset과 DataLoader는 데이터를 PyTorch 모델에 넣기 좋은 형태로 관리하는 도구입니다.
from torch.utils.data import Dataset, DataLoader
# train_test_split은 데이터를 학습용과 테스트용으로 나누는 함수입니다.
from sklearn.model_selection import train_test_split
# ColumnTransformer는 수치형/범주형 컬럼에 서로 다른 전처리를 적용할 때 사용합니다.
from sklearn.compose import ColumnTransformer
# OneHotEncoder는 문자 범주 데이터를 0과 1의 숫자 벡터로 변환합니다.
from sklearn.preprocessing import OneHotEncoder, StandardScaler, LabelEncoder
# Pipeline은 여러 전처리 단계를 하나로 묶어 실행할 때 사용합니다.
from sklearn.pipeline import Pipeline
# accuracy_score와 confusion_matrix는 모델 평가 지표를 계산합니다.
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# matplotlib은 그래프를 그리기 위한 라이브러리입니다.
import matplotlib.pyplot as plt
# random은 파이썬의 난수 생성을 제어할 때 사용합니다.
import random
# os는 파일 경로 확인 등에 사용합니다.
import os
# 경고 메시지를 줄여 출력 화면을 깔끔하게 만들기 위해 사용합니다.
import warnings
# 불필요한 경고 메시지를 숨깁니다.
warnings.filterwarnings("ignore")
# 현재 사용 가능한 장치를 확인합니다.
# Colab에서 GPU를 켜면 cuda가 출력되고, 그렇지 않으면 cpu가 출력됩니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 현재 학습에 사용할 장치를 출력합니다.
print("사용 장치:", device)
난수고정
# ============================================================
# 2. 난수 고정
# ============================================================
# 난수를 고정하면 코드를 다시 실행해도 최대한 같은 결과가 나오도록 만들 수 있습니다.
SEED = 123
# 파이썬 random 라이브러리의 난수를 고정합니다.
random.seed(SEED)
# numpy 난수를 고정합니다.
np.random.seed(SEED)
# PyTorch CPU 연산의 난수를 고정합니다.
torch.manual_seed(SEED)
# PyTorch GPU 연산의 난수를 고정합니다.
torch.cuda.manual_seed_all(SEED)
# CUDA 연산의 재현성을 높이기 위한 설정입니다.
torch.backends.cudnn.deterministic = True
# 실행 속도 최적화보다 재현성을 우선하도록 설정합니다.
torch.backends.cudnn.benchmark = False
데이터셋 준비 및 데이터 구조확인, 데이터 기본탐색
# ============================================================
# 3. 데이터 불러오기
# ============================================================
# 사용한 파일 경로입니다.
local_path = "data/credit_info.csv"
# 공개 German Credit 데이터셋 주소입니다.
# Colab에서 data/credit_info.csv 파일이 없을 때 자동으로 읽어옵니다.
url = "https://raw.githubusercontent.com/stedy/Machine-Learning-with-R-datasets/master/credit.csv"
# data 폴더가 없으면 새로 생성합니다.
os.makedirs("data", exist_ok=True)
# local_path 파일이 실제로 존재하는지 확인합니다.
if os.path.exists(local_path):
# 파일이 있으면 사용자가 제공한 로컬 CSV 파일을 읽습니다.
credit_info = pd.read_csv(local_path)
else:
# 파일이 없으면 공개 URL에서 CSV 파일을 읽습니다.
credit_info = pd.read_csv(url)
# 다음 실행 때도 같은 파일을 사용할 수 있도록 data 폴더에 저장합니다.
credit_info.to_csv(local_path, index=False)
# 목표 변수를 Repay라고 사용합니다.
# 공개 데이터셋은 목표 컬럼명이 default일 수 있으므로 Repay로 바꿉니다.
if "Repay" not in credit_info.columns and "default" in credit_info.columns:
# default 컬럼명을 Repay로 변경합니다.
credit_info = credit_info.rename(columns={"default": "Repay"})
# 데이터의 앞부분 5행을 확인합니다.
credit_info.head()# ============================================================
# 4. 데이터 구조 확인
# ============================================================
# 데이터의 행과 열 개수를 확인합니다.
print("데이터 크기:", credit_info.shape)
# 각 컬럼의 자료형과 결측치 여부를 확인합니다.
credit_info.info()
# 컬럼 이름 목록을 출력합니다.
print("\n컬럼 목록:")
print(credit_info.columns.tolist())
# ============================================================
# 5. 기본 탐색
# ============================================================
# checking_balance 컬럼은 신청자의 수표 계좌 잔고 범주를 의미합니다.
# value_counts()는 R의 table()과 비슷하게 값별 개수를 세어 줍니다.
print("checking_balance 빈도:")
print(credit_info["checking_balance"].value_counts())
# savings_balance 컬럼은 신청자의 저축 계좌 잔고 범주를 의미합니다.
print("\nsavings_balance 빈도:")
print(credit_info["savings_balance"].value_counts())
# months_loan_duration은 대출 기간입니다.
# describe()는 평균, 표준편차, 최솟값, 최댓값 등을 보여줍니다.
print("\nmonths_loan_duration 요약:")
print(credit_info["months_loan_duration"].describe())
# amount는 대출 금액입니다.
print("\namount 요약:")
print(credit_info["amount"].describe())
# Repay는 상환 여부 또는 채무불이행 여부를 나타내는 목표 변수입니다.
print("\nRepay 빈도:")
print(credit_info["Repay"].value_counts())
# Repay 비율을 확인합니다.
print("\nRepay 비율:")
print(credit_info["Repay"].value_counts(normalize=True))
입력데이터와 정답데이터를 분리한다. labelencoder로 문자라벨을 숫자라벨로 바꾸고 fit한다.
# ============================================================
# 6. 입력 X와 정답 y 분리
# ============================================================
# 목표 컬럼명을 변수로 저장합니다.
target_col = "Repay"
# 목표 컬럼이 실제 데이터에 있는지 확인합니다.
if target_col not in credit_info.columns:
# 목표 컬럼이 없으면 에러를 발생시켜 문제 원인을 바로 알 수 있게 합니다.
raise ValueError("데이터에 Repay 컬럼이 없습니다. 목표 컬럼명을 확인하세요.")
# X는 Repay를 제외한 모든 컬럼입니다.
X = credit_info.drop(columns=[target_col])
# y는 모델이 예측해야 하는 Repay 컬럼입니다.
y = credit_info[target_col]
# LabelEncoder는 문자 라벨을 숫자 라벨로 바꿉니다.
# 예: no -> 0, yes -> 1 과 같은 방식입니다.
label_encoder = LabelEncoder()
# y 값을 숫자 형태로 변환합니다.
y_encoded = label_encoder.fit_transform(y)
# 어떤 원래 라벨이 어떤 숫자로 바뀌었는지 확인합니다.
print("라벨 매핑:")
for original_label, encoded_label in zip(label_encoder.classes_, range(len(label_encoder.classes_))):
print(f"{original_label} -> {encoded_label}")
수치형 커리럼과 범주형 컬럼을 구분한다.
# ============================================================
# 7. 수치형 컬럼과 범주형 컬럼 구분
# ============================================================
# 수치형 컬럼은 int64, float64 같은 숫자 자료형 컬럼입니다.
numeric_features = X.select_dtypes(include=["int64", "float64"]).columns.tolist()
# 범주형 컬럼은 object, category 같은 문자 또는 범주 자료형 컬럼입니다.
categorical_features = X.select_dtypes(include=["object", "category", "bool"]).columns.tolist()
# 수치형 컬럼 목록을 출력합니다.
print("수치형 컬럼:", numeric_features)
# 범주형 컬럼 목록을 출력합니다.
print("범주형 컬럼:", categorical_features)
학습데이터와 테스트 데이터를 분리한다.
# ============================================================
# 8. 학습 데이터와 테스트 데이터 분리
# ============================================================
# train_test_split은 데이터를 학습용과 테스트용으로 나눕니다.
# test_size=0.2는 전체 데이터의 20%를 테스트용으로 사용한다는 뜻입니다.
# 800개 학습 / 200개 테스트 분리와 같은 비율입니다.
# stratify=y_encoded는 정답 라벨 비율이 학습/테스트에 비슷하게 유지되도록 합니다.
X_train, X_test, y_train, y_test = train_test_split(
X,
y_encoded,
test_size=0.2,
random_state=SEED,
stratify=y_encoded
)
# 분리된 데이터 크기를 확인합니다.
print("X_train 크기:", X_train.shape)
print("X_test 크기:", X_test.shape)
print("y_train 크기:", y_train.shape)
print("y_test 크기:", y_test.shape)
# 학습 데이터의 클래스 비율을 확인합니다.
print("\n학습 데이터 클래스 비율:")
print(pd.Series(y_train).value_counts(normalize=True).sort_index())
# 테스트 데이터의 클래스 비율을 확인합니다.
print("\n테스트 데이터 클래스 비율:")
print(pd.Series(y_test).value_counts(normalize=True).sort_index())
전처리 pipeline을 만들어 standardscler, onehotencoder, columntranformer로 수치형을 평준화, 범주형을 숫자로, 컬럼 종류별로 다른 전처리를 적용한다.
위 전처리 규칙을 학습용 데이터에 fit.하고 float32 형으로 변환한다.
정답라벨은 int64 long 타입으로 변환한다
# ============================================================
# 9. 전처리 파이프라인 생성
# ============================================================
# 수치형 데이터 전처리: StandardScaler로 표준화합니다.
numeric_transformer = Pipeline(
steps=[
# StandardScaler는 수치 데이터의 크기 차이를 줄여 학습을 안정적으로 만듭니다.
("scaler", StandardScaler())
]
)
# 범주형 데이터 전처리: OneHotEncoder로 숫자 벡터화합니다.
categorical_transformer = Pipeline(
steps=[
# handle_unknown="ignore"는 테스트 데이터에 학습 때 보지 못한 범주가 나와도 에러를 막습니다.
("onehot", OneHotEncoder(handle_unknown="ignore"))
]
)
# ColumnTransformer는 컬럼 종류별로 다른 전처리를 적용합니다.
preprocessor = ColumnTransformer(
transformers=[
# numeric_features 컬럼에는 numeric_transformer를 적용합니다.
("num", numeric_transformer, numeric_features),
# categorical_features 컬럼에는 categorical_transformer를 적용합니다.
("cat", categorical_transformer, categorical_features)
]
)
# fit_transform은 학습 데이터 기준으로 전처리 규칙을 학습하고 바로 변환합니다.
X_train_processed = preprocessor.fit_transform(X_train)
# transform은 학습 데이터에서 만든 규칙을 테스트 데이터에 그대로 적용합니다.
X_test_processed = preprocessor.transform(X_test)
# OneHotEncoder 결과가 희소 행렬일 수 있으므로 일반 numpy 배열로 변환합니다.
X_train_processed = X_train_processed.toarray() if hasattr(X_train_processed, "toarray") else X_train_processed
X_test_processed = X_test_processed.toarray() if hasattr(X_test_processed, "toarray") else X_test_processed
# PyTorch는 float32 자료형을 주로 사용하므로 float32로 변환합니다.
X_train_processed = X_train_processed.astype(np.float32)
X_test_processed = X_test_processed.astype(np.float32)
# 정답 라벨은 분류 문제에서 long 타입으로 사용합니다.
y_train = y_train.astype(np.int64)
y_test = y_test.astype(np.int64)
# 전처리 후 입력 특성 개수를 확인합니다.
print("전처리 후 학습 입력 크기:", X_train_processed.shape)
print("전처리 후 테스트 입력 크기:", X_test_processed.shape)
특성과 정답들을 torch.tensor로 변환하는 class를 만든다.
학습용, 테스트용 dataset 객체를 생성한다.
batch 값을 설정하여 dataloader 객체를 생성한다.
# ============================================================
# 10. PyTorch Dataset 클래스 정의
# ============================================================
# CreditDataset은 대출 데이터를 PyTorch가 사용할 수 있는 형태로 포장하는 클래스입니다.
class CreditDataset(Dataset):
# __init__은 Dataset 객체가 만들어질 때 한 번 실행됩니다.
def __init__(self, features, labels):
# 입력 특성을 torch 텐서로 변환합니다.
self.features = torch.tensor(features, dtype=torch.float32)
# 정답 라벨을 torch 텐서로 변환합니다.
self.labels = torch.tensor(labels, dtype=torch.long)
# __len__은 데이터가 총 몇 개인지 반환합니다.
def __len__(self):
# labels의 길이가 전체 데이터 개수입니다.
return len(self.labels)
# __getitem__은 특정 번호의 데이터 1개를 반환합니다.
def __getitem__(self, idx):
# idx번째 입력 데이터와 정답 라벨을 함께 반환합니다.
return self.features[idx], self.labels[idx]
# 학습용 Dataset 객체를 생성합니다.
train_dataset = CreditDataset(X_train_processed, y_train)
# 테스트용 Dataset 객체를 생성합니다.
test_dataset = CreditDataset(X_test_processed, y_test)
# 한 번에 학습할 데이터 개수입니다.
# 32개씩 묶어서 모델에 넣습니다.
batch_size = 32
# 학습용 DataLoader를 생성합니다.
# shuffle=True는 매 epoch마다 데이터 순서를 섞어 학습 효과를 높입니다.
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 테스트용 DataLoader를 생성합니다.
# 테스트는 순서를 섞을 필요가 없으므로 shuffle=False입니다.
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 첫 번째 미니배치를 꺼내 입력과 정답 크기를 확인합니다.
sample_X, sample_y = next(iter(train_loader))
# 미니배치 입력 크기를 출력합니다.
print("미니배치 입력 크기:", sample_X.shape)
# 미니배치 정답 크기를 출력합니다.
print("미니배치 정답 크기:", sample_y.shape)
신경말모델 class을 생성한다.
nn.sequential은 신경망 층을 순서대로 연결해주는 컨데이너이다
linear, relu, dropout를 사용한다.
forward로 신경망을 통과하도록 지시한다.
신경망 모델 객체를 생성하고 완료후 device 학습자이로 이동한다 .
# ============================================================
# 11. PyTorch 모델 정의
# ============================================================
# CreditMLP는 대출 상환 여부를 분류하는 신경망 모델입니다.
class CreditMLP(nn.Module):
# __init__은 모델 구조를 정의하는 부분입니다.
def __init__(self, input_dim, num_classes):
# 부모 클래스 nn.Module의 초기화 함수를 실행합니다.
super(CreditMLP, self).__init__()
# self.network는 여러 신경망 계층을 순서대로 묶은 구조입니다.
self.network = nn.Sequential(
# 첫 번째 완전연결층입니다.
# input_dim개의 입력을 받아 64개의 값으로 변환합니다.
nn.Linear(input_dim, 64),
# ReLU는 음수는 0으로, 양수는 그대로 통과시키는 활성화 함수입니다.
# 모델이 복잡한 패턴을 학습할 수 있게 도와줍니다.
nn.ReLU(),
# Dropout은 일부 뉴런을 무작위로 끄는 기법입니다.
# 과적합을 줄이는 데 도움이 됩니다.
nn.Dropout(0.2),
# 두 번째 완전연결층입니다.
# 64개의 입력을 받아 32개의 값으로 변환합니다.
nn.Linear(64, 32),
# 두 번째 ReLU 활성화 함수입니다.
nn.ReLU(),
# 마지막 출력층입니다.
# 32개의 입력을 클래스 개수만큼의 점수로 변환합니다.
nn.Linear(32, num_classes)
)
# forward는 입력 데이터가 모델을 통과하는 계산 과정을 정의합니다.
def forward(self, x):
# 입력 x를 self.network에 통과시켜 출력값을 만듭니다.
return self.network(x)
# 입력 특성 개수입니다.
input_dim = X_train_processed.shape[1]
# 분류할 클래스 개수입니다.
num_classes = len(label_encoder.classes_)
# 모델 객체를 생성하고 학습 장치(cpu 또는 cuda)로 이동합니다.
model = CreditMLP(input_dim=input_dim, num_classes=num_classes).to(device)
# 모델 구조를 출력합니다.
print(model)
손실함수, 최적화 알고리즘를 지정한다.
crossentroyloss(), 모델의 예측이 정답과 얼마나 다른지 숫자로 계산한다.
optim.adam 학습률을조정해가면 모데 파라미털ㄹ 업데이트 하는 최적화 알고리즘을 생성한다.
# ============================================================
# 12. 손실 함수와 최적화 알고리즘 설정
# ============================================================
# CrossEntropyLoss는 다중 분류 문제에서 많이 사용하는 손실 함수입니다.
# 모델의 예측이 정답과 얼마나 다른지 숫자로 계산합니다.
criterion = nn.CrossEntropyLoss()
# Adam은 학습률을 자동으로 조정해 가며 모델 파라미터를 업데이트하는 최적화 알고리즘입니다.
optimizer = optim.Adam(
model.parameters(), # 학습할 모델 파라미터를 지정합니다.
lr=0.001 # learning rate, 즉 한 번에 얼마나 크게 수정할지 정합니다.
)
평가함수를 정의한다 .
# ============================================================
# 13. 평가 함수 정의
# ============================================================
# evaluate 함수는 검증 또는 테스트 데이터에서 모델 성능을 계산합니다.
def evaluate(model, data_loader, criterion):
# 모델을 평가 모드로 바꿉니다.
# Dropout 같은 학습 전용 동작이 꺼집니다.
model.eval()
# 전체 손실값을 누적할 변수입니다.
total_loss = 0.0
# 맞힌 개수를 누적할 변수입니다.
correct = 0
# 전체 데이터 개수를 누적할 변수입니다.
total = 0
# 평가할 때는 기울기 계산이 필요 없으므로 no_grad를 사용합니다.
with torch.no_grad():
# DataLoader에서 미니배치 단위로 데이터를 꺼냅니다.
for batch_X, batch_y in data_loader:
# 입력 데이터를 학습 장치로 이동합니다.
batch_X = batch_X.to(device)
# 정답 라벨을 학습 장치로 이동합니다.
batch_y = batch_y.to(device)
# 모델에 입력 데이터를 넣어 예측 점수를 계산합니다.
outputs = model(batch_X)
# 예측 점수와 정답 사이의 손실값을 계산합니다.
loss = criterion(outputs, batch_y)
# 현재 미니배치 손실값에 데이터 개수를 곱해 누적합니다.
total_loss += loss.item() * batch_X.size(0)
# 가장 점수가 높은 클래스 번호를 예측값으로 선택합니다.
_, predicted = torch.max(outputs, 1)
# 전체 데이터 개수를 누적합니다.
total += batch_y.size(0)
# 예측값과 정답이 같은 개수를 누적합니다.
correct += (predicted == batch_y).sum().item()
# 평균 손실값을 계산합니다.
avg_loss = total_loss / total
# 정확도를 계산합니다.
accuracy = correct / total
# 평균 손실값과 정확도를 반환합니다.
return avg_loss, accuracy
모델학습을 실행한다.
epoch만큼 반복한다 .
optiizer.zero_grad()이전 배치에서 계산된 기울기를 초기화하고
criterion 손실값을 계산해 loss.backward() 각파라미터 기울기르 계산해 optimizer.step() 수정한다.
평균학습 손실값을 계산, 정확도를 계산해 저장한다 .
# ============================================================
# 14. 모델 학습 실행
# ============================================================
# 전체 학습 반복 횟수입니다.
epochs = 50
# 학습 과정을 저장할 리스트입니다.
train_losses = []
train_accuracies = []
test_losses = []
test_accuracies = []
# epoch 수만큼 반복 학습합니다.
for epoch in range(epochs):
# 모델을 학습 모드로 바꿉니다.
# Dropout 같은 학습 전용 동작이 켜집니다.
model.train()
# 한 epoch 동안의 손실값을 누적할 변수입니다.
running_loss = 0.0
# 한 epoch 동안 맞힌 개수를 누적할 변수입니다.
correct = 0
# 한 epoch 동안 전체 데이터 개수를 누적할 변수입니다.
total = 0
# 학습 데이터를 미니배치 단위로 반복합니다.
for batch_X, batch_y in train_loader:
# 입력 데이터를 학습 장치로 이동합니다.
batch_X = batch_X.to(device)
# 정답 라벨을 학습 장치로 이동합니다.
batch_y = batch_y.to(device)
# 이전 미니배치에서 계산된 기울기를 초기화합니다.
optimizer.zero_grad()
# 모델에 입력 데이터를 넣어 예측 점수를 계산합니다.
outputs = model(batch_X)
# 예측 결과와 실제 정답 사이의 손실값을 계산합니다.
loss = criterion(outputs, batch_y)
# 손실값을 기준으로 각 파라미터의 기울기를 계산합니다.
loss.backward()
# 계산된 기울기를 사용하여 모델 파라미터를 업데이트합니다.
optimizer.step()
# 현재 미니배치 손실값을 누적합니다.
running_loss += loss.item() * batch_X.size(0)
# 가장 큰 점수를 가진 클래스를 예측값으로 선택합니다.
_, predicted = torch.max(outputs, 1)
# 전체 데이터 개수를 누적합니다.
total += batch_y.size(0)
# 예측값과 정답이 같은 개수를 누적합니다.
correct += (predicted == batch_y).sum().item()
# 한 epoch의 평균 학습 손실값을 계산합니다.
train_loss = running_loss / total
# 한 epoch의 학습 정확도를 계산합니다.
train_acc = correct / total
# 테스트 데이터에 대한 손실값과 정확도를 계산합니다.
test_loss, test_acc = evaluate(model, test_loader, criterion)
# 그래프 출력을 위해 값을 리스트에 저장합니다.
train_losses.append(train_loss)
train_accuracies.append(train_acc)
test_losses.append(test_loss)
test_accuracies.append(test_acc)
# epoch마다 학습 결과를 출력합니다.
print(
f"Epoch [{epoch + 1:02d}/{epochs}] "
f"Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}, "
f"Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.4f}"
)
위내용을 그래프로 출력
# ============================================================
# 15. 학습 과정 그래프 출력
# ============================================================
# 그래프 크기를 지정합니다.
plt.figure(figsize=(8, 5))
# 학습 손실값 변화를 선 그래프로 표시합니다.
plt.plot(train_losses, label="Train Loss")
# 테스트 손실값 변화를 선 그래프로 표시합니다.
plt.plot(test_losses, label="Test Loss")
# 그래프 제목을 지정합니다.
plt.title("Loss 변화")
# x축 이름을 지정합니다.
plt.xlabel("Epoch")
# y축 이름을 지정합니다.
plt.ylabel("Loss")
# 범례를 표시합니다.
plt.legend()
# 그래프를 출력합니다.
plt.show()
# 새로운 그래프 크기를 지정합니다.
plt.figure(figsize=(8, 5))
# 학습 정확도 변화를 선 그래프로 표시합니다.
plt.plot(train_accuracies, label="Train Accuracy")
# 테스트 정확도 변화를 선 그래프로 표시합니다.
plt.plot(test_accuracies, label="Test Accuracy")
# 그래프 제목을 지정합니다.
plt.title("Accuracy 변화")
# x축 이름을 지정합니다.
plt.xlabel("Epoch")
# y축 이름을 지정합니다.
plt.ylabel("Accuracy")
# 범례를 표시합니다.
plt.legend()
# 그래프를 출력합니다.
plt.show()
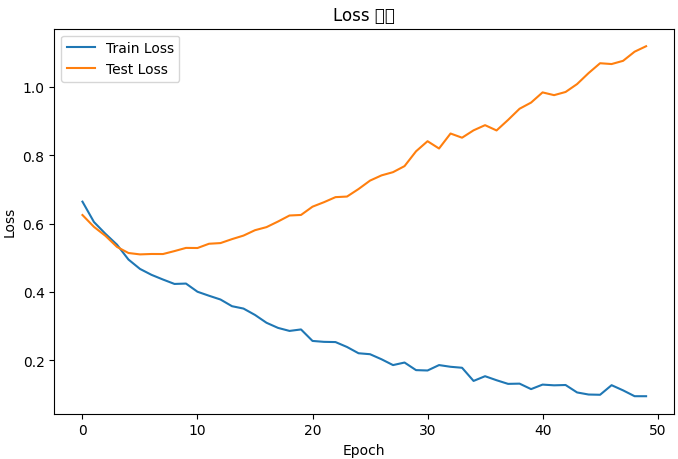

accurancy_score 평가한다.
confusion_matrix 계산해 출력한다.
classification_report 상세리포트를 출력한다.
# ============================================================
# 16. 테스트 데이터 전체 예측
# ============================================================
# 모델을 평가 모드로 변경합니다.
model.eval()
# 예측값을 저장할 리스트입니다.
all_predictions = []
# 실제 정답을 저장할 리스트입니다.
all_labels = []
# 테스트 과정에서는 기울기 계산이 필요 없으므로 no_grad를 사용합니다.
with torch.no_grad():
# 테스트 데이터를 미니배치 단위로 반복합니다.
for batch_X, batch_y in test_loader:
# 입력 데이터를 학습 장치로 이동합니다.
batch_X = batch_X.to(device)
# 모델 예측 점수를 계산합니다.
outputs = model(batch_X)
# 가장 점수가 높은 클래스를 예측값으로 선택합니다.
_, predicted = torch.max(outputs, 1)
# 예측값을 CPU로 옮긴 뒤 numpy 배열로 변환하여 리스트에 추가합니다.
all_predictions.extend(predicted.cpu().numpy())
# 실제 정답도 numpy 배열로 변환하여 리스트에 추가합니다.
all_labels.extend(batch_y.numpy())
# 리스트를 numpy 배열로 변환합니다.
all_predictions = np.array(all_predictions)
all_labels = np.array(all_labels)
# 정확도를 계산합니다.
test_accuracy = accuracy_score(all_labels, all_predictions)
# 테스트 정확도를 출력합니다.
print("테스트 정확도:", round(test_accuracy, 4))# ============================================================
# 17. Confusion Matrix 출력
# ============================================================
# Confusion Matrix를 계산합니다.
cm = confusion_matrix(all_labels, all_predictions)
# Confusion Matrix를 표 형태의 DataFrame으로 변환합니다.
cm_df = pd.DataFrame(
cm,
index=[f"Actual_{label}" for label in label_encoder.classes_],
columns=[f"Pred_{label}" for label in label_encoder.classes_]
)
# Confusion Matrix를 출력합니다.
cm_df# ============================================================
# 18. 상세 분류 리포트 출력
# ============================================================
# classification_report는 precision, recall, f1-score를 한 번에 보여줍니다.
# precision은 예측한 것 중 실제로 맞은 비율입니다.
# recall은 실제 정답 중 모델이 찾아낸 비율입니다.
# f1-score는 precision과 recall을 함께 고려한 점수입니다.
report = classification_report(
all_labels,
all_predictions,
target_names=[str(cls) for cls in label_encoder.classes_]
)
# 상세 평가 결과를 출력합니다.
print(report)
신규데이터로 예측한다.
# ============================================================
# 19. 신규 대출 신청자 예측 예시
# ============================================================
# 테스트 데이터에서 첫 번째 신청자 데이터를 하나 가져옵니다.
new_applicant = X_test.iloc[[0]]
# 신규 신청자 데이터를 확인합니다.
display(new_applicant)
# 학습 데이터 기준으로 만든 전처리기를 사용하여 신규 데이터를 변환합니다.
new_applicant_processed = preprocessor.transform(new_applicant)
# 희소 행렬이면 일반 배열로 변환합니다.
new_applicant_processed = (
new_applicant_processed.toarray()
if hasattr(new_applicant_processed, "toarray")
else new_applicant_processed
)
# float32 자료형으로 변환합니다.
new_applicant_processed = new_applicant_processed.astype(np.float32)
# numpy 배열을 PyTorch 텐서로 변환합니다.
new_applicant_tensor = torch.tensor(new_applicant_processed, dtype=torch.float32).to(device)
# 모델을 평가 모드로 변경합니다.
model.eval()
# 기울기 계산 없이 예측합니다.
with torch.no_grad():
# 모델의 출력 점수를 계산합니다.
output = model(new_applicant_tensor)
# softmax는 점수를 확률처럼 해석할 수 있게 변환합니다.
probabilities = torch.softmax(output, dim=1)
# 가장 확률이 높은 클래스를 선택합니다.
predicted_class = torch.argmax(probabilities, dim=1).item()
# 숫자 라벨을 원래 문자 라벨로 되돌립니다.
predicted_label = label_encoder.inverse_transform([predicted_class])[0]
# 예측 결과를 출력합니다.
print("예측 라벨:", predicted_label)
# 클래스별 예측 확률을 출력합니다.
for label, prob in zip(label_encoder.classes_, probabilities.cpu().numpy()[0]):
print(f"{label} 확률: {prob:.4f}")
마찬가지로 여기까지가 기본 코드였다.
gradient boosting 을 적용해보자. 앞모델이 남긴 오차를 다음 모델이 게속 줄여나가는 기법이라했다.
import
sklearn.ensemble gradientBoostringclassifier 를 import한다.
# ============================================================
# 추가 1. 앙상블 평가에 필요한 라이브러리 불러오기
# ============================================================
# pandas는 성능 비교표를 만들 때 사용합니다.
import pandas as pd
# numpy는 배열 계산에 사용합니다.
import numpy as np
# matplotlib은 성능 비교 그래프를 그릴 때 사용합니다.
import matplotlib.pyplot as plt
# accuracy_score는 정확도를 계산합니다.
from sklearn.metrics import accuracy_score
# confusion_matrix는 실제값과 예측값의 관계를 표로 정리합니다.
from sklearn.metrics import confusion_matrix
# classification_report는 precision, recall, f1-score를 한 번에 출력합니다.
from sklearn.metrics import classification_report
# 기존 PyTorch MLP 모델의 정확도가 저장되어 있는지 확인합니다.
# 위쪽 기존 코드를 순서대로 실행했다면 test_accuracy 변수가 존재합니다.
if "test_accuracy" in globals():
# 기존 PyTorch 모델의 정확도를 baseline_accuracy 변수에 저장합니다.
baseline_accuracy = test_accuracy
else:
# 기존 모델 평가 셀을 실행하지 않은 경우를 대비하여 None으로 둡니다.
baseline_accuracy = None
# 기존 모델 정확도를 확인합니다.
print("기존 PyTorch MLP 테스트 정확도:", baseline_accuracy)
# GradientBoostingClassifier는 오차를 줄이는 방향으로 모델을 순차적으로 추가하는 앙상블 모델입니다.
from sklearn.ensemble import GradientBoostingClassifier
gradientboostringclassifier 객체를 만든다 .
n_estimator트리갯수를 정의한다.
learning_rate 각 트리가 최종예측에 반영되는 크기를 조절한다. 값이 작으면 더 천천히 학습한다.
max-dept로 트리릐 최대깊이를 정한다 .
subsample로 각 단계에서 학습 데이터의 특정 %만 사용하여 과적합을 줄이고 성능을 높인다 .
ramdon_state = seed로 난수를 고정한다.
fit.
# ============================================================
# 추가 2. Gradient Boosting 모델 생성 및 학습
# ============================================================
# GradientBoostingClassifier를 생성합니다.
ensemble_model = GradientBoostingClassifier(
# n_estimators는 순차적으로 추가할 트리 개수입니다.
n_estimators=200,
# learning_rate는 각 트리가 최종 예측에 반영되는 크기를 조절합니다.
# 값이 작으면 더 천천히 학습하고, 일반적으로 트리 개수를 더 많이 사용합니다.
learning_rate=0.05,
# max_depth는 각 트리의 최대 깊이입니다.
# 너무 깊으면 학습 데이터에 과하게 맞을 수 있으므로 적절히 제한합니다.
max_depth=3,
# subsample=0.8은 각 단계에서 학습 데이터의 80%만 사용한다는 뜻입니다.
# 이 설정은 과적합을 줄이고 일반화 성능을 높이는 데 도움이 될 수 있습니다.
subsample=0.8,
# random_state는 결과 재현을 위해 난수를 고정합니다.
random_state=SEED
)
# fit은 전처리된 학습 데이터와 정답을 이용하여 Gradient Boosting을 학습합니다.
ensemble_model.fit(X_train_processed, y_train)
# 학습이 끝났음을 출력합니다.
print("Gradient Boosting 모델 학습 완료")
predict 로 예측값을 생성한다.
accuracy_score를 사용해 정확도를 계산해 출력한다 .
confusion_matrix를 활용해 표형태로 변환해 출력한다.
classification_report로 상세평가결과를 출력한다
# ============================================================
# 추가 3. Gradient Boosting 예측 및 성능 평가
# ============================================================
# 학습된 Gradient Boosting 모델에 테스트 데이터를 넣어 예측값을 생성합니다.
gb_predictions = ensemble_model.predict(X_test_processed)
# 실제 정답 y_test와 예측값을 비교하여 정확도를 계산합니다.
gb_accuracy = accuracy_score(y_test, gb_predictions)
# 정확도를 출력합니다.
print("Gradient Boosting 테스트 정확도:", round(gb_accuracy, 4))
# Confusion Matrix를 계산합니다.
ensemble_cm = confusion_matrix(y_test, gb_predictions)
# Confusion Matrix를 보기 좋은 표 형태로 변환합니다.
ensemble_cm_df = pd.DataFrame(
ensemble_cm,
index=[f"Actual_{label}" for label in label_encoder.classes_],
columns=[f"Pred_{label}" for label in label_encoder.classes_]
)
# Confusion Matrix를 출력합니다.
display(ensemble_cm_df)
# precision, recall, f1-score를 포함한 상세 평가 결과를 출력합니다.
print(classification_report(
y_test,
gb_predictions,
target_names=[str(cls) for cls in label_encoder.classes_]
))
기존모델과 gradient boosting 의 성능을 비교한다 .
# ============================================================
# 추가 4. 기존 PyTorch 모델과 Gradient Boosting 성능 비교
# ============================================================
# 성능 비교 결과를 저장할 리스트를 만듭니다.
comparison_rows = []
# 기존 PyTorch MLP 정확도가 있으면 비교표에 추가합니다.
if baseline_accuracy is not None:
# 기존 PyTorch 모델의 이름과 정확도를 저장합니다.
comparison_rows.append({"Model": "PyTorch MLP", "Accuracy": baseline_accuracy})
# 이번에 학습한 앙상블 모델의 이름과 정확도를 저장합니다.
comparison_rows.append({"Model": "Gradient Boosting", "Accuracy": gb_accuracy})
# 리스트를 표 형태의 DataFrame으로 변환합니다.
comparison_df = pd.DataFrame(comparison_rows)
# 정확도가 높은 모델이 위에 오도록 정렬합니다.
comparison_df = comparison_df.sort_values(by="Accuracy", ascending=False).reset_index(drop=True)
# 정확도 값을 소수점 네 자리까지 보기 좋게 반올림합니다.
comparison_df["Accuracy"] = comparison_df["Accuracy"].round(4)
# 성능 비교표를 출력합니다.
display(comparison_df)
# 그래프 크기를 지정합니다.
plt.figure(figsize=(7, 4))
# 모델별 정확도를 막대그래프로 표시합니다.
plt.bar(comparison_df["Model"], comparison_df["Accuracy"])
# 그래프 제목을 지정합니다.
plt.title("모델별 테스트 정확도 비교")
# x축 이름을 지정합니다.
plt.xlabel("모델")
# y축 이름을 지정합니다.
plt.ylabel("정확도")
# y축 범위를 0부터 1까지로 지정합니다.
plt.ylim(0, 1)
# 각 막대 위에 정확도 값을 표시합니다.
for index, value in enumerate(comparison_df["Accuracy"]):
# text는 그래프에 글자를 표시하는 함수입니다.
plt.text(index, value + 0.01, str(value), ha="center")
# 그래프를 출력합니다.
plt.show()
헷갈리니 다시 정리해보자 .
앙상블
├─ Bagging 계열
│ └─ Random Forest
│
├─ Boosting 계열
│ ├─ AdaBoost
│ ├─ Gradient Boosting
│ ├─ XGBoost
│ ├─ LightGBM
│ └─ CatBoost
│
└─ Voting 계열
└─ 여러 모델 결과를 단순 투표
Bagging은 여러 트리를 병렬로 만들오 투표하는것.
이때 사용할 특성을 랜덤으로 제한해 중요한 변수만 내내 쓰지 못하게 하는것이 Random Forest. 얘가 대표모델
boosting은 bagging과 다르게 앞 모델이 틀린 문제를 뒤 모델이 집중적으로 공부하는것.
이때 대표모델 중 adaboost, gradientboosting이있다.
adaboost는 최초의 boosting 알고리즘으로 틀린문제에 가중치를 준다 .
gradient boostring 은 오차값을 구해 이를 줄이는 방식으로 학습한다.
신경망이란?
ANN Artificial Neural Network
인간의 뇌속 뉴런이 동작하는 방식을 흉내낸 머신러닝
사람외 뇌가 수상돌기(신호입력 ) - 세포체 (신호계산 ) - 결과출력인것을
컴퓨터로 입력값, 가중치, 모두더함, 활성함수, 출력으로 흉내냄
- 가중치는 모든 입력이 똑같이 중요하지않으니 중요도를 부여하는것.
- 활성함수는 합계만 계산하면 단순 선형모델이 되니 sigmoid, relu 등을 사용해 확률 혹은 음수를 0 으로 바꾸는것.

단층 신경망은 입력과 출력층,
다층 신경망은 은닉층이 추가된다 .
기존 모델의 선형회귀, 로지스틱 회귀로 단순 관계만 학습하는것보다 신경망으로 은닉층, 복잡한 계산을 추가하면복잡한 문제가 가능해진다 .

순전파 forward propagation 신경망 계산과정, 순서대로 계산
역전파 back progagation 오차를 구해내 이용해 가중치 수정, 얼마나 수정할지를 알려준다 .
학습률: 가중치를 얼마나 수정할지를 결정
경사하강법: 어느방향으로 움직일지를 결정해 오차를 최소화. 오차 함수의 최솟값을 찾는 과정.
샘플데이터 ann_torch를 분석해보자 .
import
random, np.random.seed, torch.manual_seed, torch.cuda.manual_seed_all 난수설정
torch.device 확인
# PyTorch, pandas, numpy, matplotlib 등 필요한 라이브러리를 불러옵니다.
# torch는 신경망 모델 생성, 텐서 연산, 학습에 사용하는 핵심 라이브러리입니다.
# pandas는 CSV 파일을 표 형태 데이터프레임으로 읽고 처리하는 데 사용합니다.
# numpy는 수치 계산과 상관계수 계산에 사용합니다.
# matplotlib은 학습 손실 그래프를 그리는 데 사용합니다.
# os는 파일 경로 존재 여부를 확인하는 데 사용합니다.
import os
import random
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
# Google Colab에서 파일 업로드 기능을 사용하기 위해 files 모듈을 불러옵니다.
# 로컬 PC에 있는 concrete_stg.csv 파일을 Colab 실행 환경으로 업로드할 때 사용합니다.
from google.colab import files
# 실행 결과를 동일하게 재현하기 위해 난수 시드를 고정합니다.
# 신경망의 초기 가중치와 데이터 처리 과정에서 발생할 수 있는 무작위성을 일정하게 만듭니다.
SEED = 12345
# Python 기본 random 모듈의 난수 시드를 고정합니다.
random.seed(SEED)
# numpy의 난수 시드를 고정합니다.
np.random.seed(SEED)
# PyTorch CPU 연산의 난수 시드를 고정합니다.
torch.manual_seed(SEED)
# GPU가 사용 가능한 경우 GPU 연산의 난수 시드도 고정합니다.
torch.cuda.manual_seed_all(SEED)
# Colab 런타임에서 GPU가 있으면 cuda를 사용하고, 없으면 cpu를 사용합니다.
# device는 이후 텐서와 모델을 어느 장치에서 계산할지 지정하는 변수입니다.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 현재 사용 중인 연산 장치를 출력합니다.
print('사용 장치:', device)
데이터가져오기
# concrete_stg.csv 파일 경로를 지정합니다.
# Colab에 직접 업로드하면 현재 작업 폴더에 concrete_stg.csv 이름으로 저장됩니다.
CSV_PATH = 'concrete_stg.csv'
# 파일이 현재 작업 폴더에 없는 경우 업로드 창을 실행합니다.
# 업로드 창에서 concrete_stg.csv 파일을 선택해야 합니다.
if not os.path.exists(CSV_PATH):
print('concrete_stg.csv 파일을 업로드하세요.')
uploaded = files.upload()
# 업로드된 파일 목록에서 첫 번째 파일명을 가져옵니다.
uploaded_filename = list(uploaded.keys())[0]
# 업로드한 파일명이 concrete_stg.csv와 다르면 CSV_PATH를 실제 업로드 파일명으로 변경합니다.
CSV_PATH = uploaded_filename
# pandas의 read_csv()로 CSV 파일을 데이터프레임으로 읽습니다.
# 데이터프레임은 행과 열로 구성된 표 형태의 데이터 구조입니다.
concrete_stg = pd.read_csv(CSV_PATH)
# 데이터의 처음 5행을 출력하여 열 이름과 값의 형태를 확인합니다.
display(concrete_stg.head())
# 데이터 행 개수, 열 개수, 결측치, 자료형을 확인합니다.
# 신경망에 넣기 전에 모든 입력값이 숫자형인지 확인하는 단계입니다.
concrete_stg.info()
데이터 기본분석
# 데이터의 기초 통계량을 확인합니다.
# count는 데이터 개수, mean은 평균, std는 표준편차입니다.
# min과 max는 각 열의 최솟값과 최댓값입니다.
display(concrete_stg.describe())
# 모델 입력에 사용할 특성 열 이름을 리스트로 지정합니다.
# 이 8개 열은 콘크리트 강도를 예측하기 위한 입력 변수입니다.
feature_cols = ['cement', 'slag', 'ash', 'water', 'superplastic', 'coarseagg', 'fineagg', 'age']
# 모델이 예측해야 하는 목표 열 이름을 지정합니다.
# strength는 콘크리트 강도 값입니다.
target_col = 'strength'
# 필요한 열이 데이터에 모두 존재하는지 확인합니다.
# 누락된 열이 있으면 파일 구조가 예상과 다르므로 오류를 발생시킵니다.
required_cols = feature_cols + [target_col]
missing_cols = [col for col in required_cols if col not in concrete_stg.columns]
if missing_cols:
raise ValueError(f'CSV 파일에 다음 열이 없습니다: {missing_cols}')
min_max_normalize 함수르르 만들어 min() max()를 구하고 만일 이가 같은경우 0으로 반환하며 min-max 정규화 공식을 직접 구현했다.
각 데이터프레임의 각 열에 min_max_normalize를 app;y한다.
# Min-Max 정규화 함수를 정의합니다.
# 각 열의 값을 0과 1 사이 범위로 변환합니다.
# 신경망은 입력값의 범위가 비슷할 때 더 안정적으로 학습됩니다.
def min_max_normalize(series):
# 열의 최솟값을 구합니다.
min_value = series.min()
# 열의 최댓값을 구합니다.
max_value = series.max()
# 최댓값과 최솟값이 같으면 나눗셈이 불가능하므로 0으로 채운 열을 반환합니다.
if max_value == min_value:
return pd.Series(np.zeros(len(series)), index=series.index)
# Min-Max 정규화 공식입니다.
# 현재값에서 최솟값을 뺀 뒤, 최댓값과 최솟값의 차이로 나눕니다.
return (series - min_value) / (max_value - min_value)
# 전체 데이터프레임의 각 열에 Min-Max 정규화를 적용합니다.
# apply()는 데이터프레임의 열 단위로 함수를 적용합니다.
concrete_stg_norm = concrete_stg.apply(min_max_normalize)
# 정규화된 strength 값의 기초 통계량을 확인합니다.
# min은 0, max는 1에 가까운 값이어야 합니다.
print('정규화된 strength 통계량')
display(concrete_stg_norm[target_col].describe())
# 원본 strength 값의 기초 통계량을 확인합니다.
# 원래 강도 값의 범위와 정규화 후 범위를 비교하기 위한 출력입니다.
print('원본 strength 통계량')
display(concrete_stg[target_col].describe())
정규화된 데이터에서 훈련데이터, 테스트 데이터를 나눈다.
훈련 테스트 데이터, 정답데이터를 numpy배열로 변환한뒤 tensor로 변환한다 .
# 정규화된 데이터에서 앞 780개 행을 훈련 데이터로 사용합니다.
train_df = concrete_stg_norm.iloc[:780].copy()
# 정규화된 데이터에서 781번째 행부터 1030번째 행까지를 테스트 데이터로 사용합니다.
# Python의 iloc는 끝 인덱스를 포함하지 않으므로 780:1030으로 지정합니다.
test_df = concrete_stg_norm.iloc[780:1030].copy()
# 훈련 입력 데이터를 numpy 배열로 변환합니다.
# astype(np.float32)는 PyTorch에서 사용하기 적합한 32비트 실수형으로 변환합니다.
X_train_np = train_df[feature_cols].values.astype(np.float32)
# 훈련 정답 데이터를 numpy 배열로 변환합니다.
# reshape(-1, 1)은 출력값을 2차원 형태로 만들어 모델 출력 모양과 맞춥니다.
y_train_np = train_df[target_col].values.astype(np.float32).reshape(-1, 1)
# 테스트 입력 데이터를 numpy 배열로 변환합니다.
X_test_np = test_df[feature_cols].values.astype(np.float32)
# 테스트 정답 데이터를 numpy 배열로 변환합니다.
y_test_np = test_df[target_col].values.astype(np.float32).reshape(-1, 1)
# numpy 배열을 PyTorch 텐서로 변환하고 연산 장치로 이동합니다.
# 텐서는 PyTorch에서 사용하는 다차원 숫자 배열입니다.
X_train = torch.tensor(X_train_np).to(device)
y_train = torch.tensor(y_train_np).to(device)
X_test = torch.tensor(X_test_np).to(device)
y_test = torch.tensor(y_test_np).to(device)
# 훈련 데이터와 테스트 데이터의 모양을 출력합니다.
# 입력 데이터는 행 개수 x 입력 특성 개수 형태입니다.
print('X_train:', X_train.shape)
print('y_train:', y_train.shape)
print('X_test:', X_test.shape)
print('y_test:', y_test.shape)
신경망 클래스 concreateANN 를 정의한다.
init으로 nn.Module상속받은기능을 초기화한다.
hiddenlayer수만큼 for문으로 돌며 은닉층을 생성하고 linear 은닉노드를 추가한다.
activation = sigmoid일경우 layer에 sigmoid 함수 를 append한다
activation = softplus일경우 layer에 softplus 함수를 append한다
마지막 출력게층을 추가한다.
sequential 순서대로 수행하는 모델로 묶는다.
(*layers)와 같이 *는 리스트 요소를 하나씩 꺼내서 전달하는 unpacking 연산자.
forward로 위 모델을 통과하도록 지시한다.
# 신경망 모델 클래스를 정의합니다.
# nn.Module을 상속하면 PyTorch 학습 모델로 사용할 수 있습니다.
class ConcreteANN(nn.Module):
# 생성자에서는 입력 크기, 은닉층 구조, 활성화 함수를 받습니다.
def __init__(self, input_dim, hidden_layers, activation='sigmoid'):
# 부모 클래스 nn.Module의 초기화 기능을 실행합니다.
super().__init__()
# 신경망 계층들을 순서대로 담을 리스트를 생성합니다.
layers = []
# 첫 번째 계층의 입력 크기는 입력 변수 개수입니다.
prev_dim = input_dim
# hidden_layers 리스트에 들어 있는 은닉 노드 수를 하나씩 사용하여 은닉층을 만듭니다.
for hidden_dim in hidden_layers:
# 선형 계층은 입력값에 가중치와 바이어스를 적용합니다.
layers.append(nn.Linear(prev_dim, hidden_dim))
# activation 값에 따라 활성화 함수를 선택합니다.
# sigmoid는 출력을 0과 1 사이로 압축하는 함수입니다.
if activation == 'sigmoid':
layers.append(nn.Sigmoid())
# softplus는 log(1 + exp(x)) 형태의 부드러운 비선형 함수입니다.
elif activation == 'softplus':
layers.append(nn.Softplus())
# 지원하지 않는 활성화 함수명이 들어오면 오류를 발생시킵니다.
else:
raise ValueError('activation은 sigmoid 또는 softplus만 사용할 수 있습니다.')
# 다음 계층의 입력 크기는 현재 은닉층의 출력 크기와 같습니다.
prev_dim = hidden_dim
# 마지막 출력 계층을 추가합니다.
# 회귀 문제이므로 출력 노드는 strength 예측값 1개입니다.
layers.append(nn.Linear(prev_dim, 1))
# 리스트에 담긴 계층들을 순서대로 실행하는 Sequential 모델로 묶습니다.
self.network = nn.Sequential(*layers)
# forward는 입력 데이터가 모델을 통과하는 계산 과정을 정의합니다.
def forward(self, x):
# 입력 x를 network에 넣어 예측값을 반환합니다.
return self.network(x)
sigmoid와 softplus는 은닉층의 활성화함수로 쓰인다.
활설화함수를 아쓰면 linear + linear + linear 깊게 쌓여도 의미가없다.
직선 중간에는 sigmoid, softplus, relu, tanh같은 비선형 함수가 들어가 직선을 곡선으로 만들고 이 곡선이 복잡한 곡선으로 만들어지면서 복잡한 패턴을 학습할 수 있다 .
sigmode와 softplus 모두 둘 모두 입력값을 변형하는 활성화 함수.
sigmode는 숫자를 0~1사이값으로 압축한다 .
softplus는 음수는 작게, 양수는 거의 그대로 통과시킨다 .
softplus를 미분하면 sigmoid가 나온다 . softplus는 sigmode와 비교했을때 경사하강법이 좀더 부들럽게 동작한다. relu의 부드러운 버전
학습함수를 정의한다.
nn.MSELoss 손실함수를 생성한다.
optim.adam 손실을 줄이는 방식으로 가중치를 업데이트하도록 한다 .
epoch만큼 반복학습한다 .
model.train() 모드전환
optimizer.zero_grad 기울기 초기화
model(x) 예측값 계산
criterion 손실계산
loss.backward 가중치 기울기 계산
optimizer,step() 업데이트
손실값들을 저장해 출력
# 모델 학습 함수를 정의합니다.
# model은 학습할 신경망입니다.
# epochs는 전체 훈련 데이터를 몇 번 반복해서 학습할지 정합니다.
# lr은 학습률이며, 가중치를 한 번에 얼마나 조정할지 결정합니다.
def train_model(model, X_train, y_train, epochs=5000, lr=0.01, print_every=500):
# 모델을 지정한 연산 장치로 이동합니다.
model = model.to(device)
# 평균제곱오차 손실 함수를 생성합니다.
# 회귀 예측에서 예측값과 실제값의 차이를 제곱하여 평균한 값입니다.
criterion = nn.MSELoss()
# Adam 최적화 알고리즘을 생성합니다.
# optimizer는 손실을 줄이는 방향으로 모델의 가중치를 업데이트합니다.
optimizer = optim.Adam(model.parameters(), lr=lr)
# epoch별 손실값을 저장할 리스트입니다.
loss_history = []
# 지정한 epoch 횟수만큼 학습을 반복합니다.
for epoch in range(1, epochs + 1):
# 모델을 학습 모드로 전환합니다.
model.train()
# 이전 반복에서 계산된 기울기를 초기화합니다.
optimizer.zero_grad()
# 훈련 입력 데이터를 모델에 넣어 예측값을 계산합니다.
y_pred = model(X_train)
# 예측값과 실제값 사이의 손실을 계산합니다.
loss = criterion(y_pred, y_train)
# 손실값을 기준으로 각 가중치의 기울기를 계산합니다.
loss.backward()
# 계산된 기울기를 이용해 가중치를 업데이트합니다.
optimizer.step()
# 현재 epoch의 손실값을 Python 숫자로 변환하여 저장합니다.
loss_history.append(loss.item())
# print_every 간격마다 학습 진행 상황을 출력합니다.
if epoch % print_every == 0 or epoch == 1:
print(f'Epoch {epoch:5d} | Loss: {loss.item():.6f}')
# 학습이 완료된 모델과 손실 이력을 반환합니다.
return model, loss_history
# 평가 함수를 정의합니다.
# 테스트 데이터에 대한 예측값, 실제값과의 상관계수, MSE를 계산합니다.
def evaluate_model(model, X_test, y_test):
# 모델을 평가 모드로 전환합니다.
model.eval()
# 평가 단계에서는 기울기를 계산하지 않습니다.
# 불필요한 메모리 사용을 줄이고 예측 속도를 높입니다.
with torch.no_grad():
# 테스트 입력 데이터를 모델에 넣어 예측값을 계산합니다.
pred = model(X_test)
# 테스트 손실값을 계산합니다.
mse = nn.MSELoss()(pred, y_test).item()
# 예측값 텐서를 CPU로 이동한 뒤 numpy 배열로 변환합니다.
pred_np = pred.cpu().numpy().reshape(-1)
# 실제값 텐서를 CPU로 이동한 뒤 numpy 배열로 변환합니다.
true_np = y_test.cpu().numpy().reshape(-1)
# 예측값과 실제값의 피어슨 상관계수를 계산합니다.
# 1에 가까울수록 예측값과 실제값이 같은 방향으로 강하게 움직입니다.
corr = np.corrcoef(pred_np, true_np)[0, 1]
# 예측값, 상관계수, 평균제곱오차를 반환합니다.
return pred_np, corr, mse
# 손실 그래프를 그리는 함수를 정의합니다.
def plot_loss(loss_history, title):
# 그래프 크기를 지정합니다.
plt.figure(figsize=(8, 4))
# epoch별 손실값을 선 그래프로 표시합니다.
plt.plot(loss_history)
# 그래프 제목을 지정합니다.
plt.title(title)
# x축 이름을 지정합니다.
plt.xlabel('Epoch')
# y축 이름을 지정합니다.
plt.ylabel('MSE Loss')
# 그래프 격자를 표시합니다.
plt.grid(True)
# 그래프를 화면에 출력합니다.
plt.show()
입력변수갯수 계산.
은닉노드가 1인 concreateANN 단순 신경망 모델 생성 sigmoid로. 확인
학습한뒤 손실률 확인. 및 그래프 출력.
evaluate_model 평가 후 출력
# 입력 변수 개수를 계산합니다.
# feature_cols에 8개 입력 변수가 있으므로 input_dim은 8입니다.
input_dim = len(feature_cols)
# 은닉 노드 1개를 가진 단순 신경망 모델을 생성합니다.
model1 = ConcreteANN(input_dim=input_dim, hidden_layers=[1], activation='sigmoid')
# 모델 구조를 출력합니다.
print(model1)
# 모델1을 학습합니다.
# epochs와 lr은 실행 환경에 따라 조정할 수 있습니다.
model1, loss1 = train_model(model1, X_train, y_train, epochs=5000, lr=0.01, print_every=500)
# 모델1의 손실 변화를 그래프로 확인합니다.
plot_loss(loss1, 'Model 1: hidden node 1')
# 테스트 데이터로 모델1을 평가합니다.
pred1, corr1, mse1 = evaluate_model(model1, X_test, y_test)
# 모델1의 평가 결과를 출력합니다.
print(f'Model 1 상관계수: {corr1:.4f}')
print(f'Model 1 테스트 MSE: {mse1:.6f}')
이번에는 은닉노드가 5개인 신경망 모델을 생성해 마찬가지로 학습후 그래프로 확인및 평가
# 은닉 노드 5개를 가진 신경망 모델을 생성합니다.
# 은닉 노드가 늘어나면 입력 변수 사이의 복잡한 비선형 관계를 더 잘 표현할 수 있습니다.
model2 = ConcreteANN(input_dim=input_dim, hidden_layers=[5], activation='sigmoid')
# 모델 구조를 출력합니다.
print(model2)
# 모델2를 학습합니다.
# 은닉 노드 수가 증가했기 때문에 모델1보다 더 많은 패턴을 학습할 수 있습니다.
model2, loss2 = train_model(model2, X_train, y_train, epochs=8000, lr=0.01, print_every=800)
# 모델2의 손실 변화를 그래프로 확인합니다.
plot_loss(loss2, 'Model 2: hidden nodes 5')
# 테스트 데이터로 모델2를 평가합니다.
pred2, corr2, mse2 = evaluate_model(model2, X_test, y_test)
# 모델2의 평가 결과를 출력합니다.
print(f'Model 2 상관계수: {corr2:.4f}')
print(f'Model 2 테스트 MSE: {mse2:.6f}')
이번에는 softplus로 은닉층 5개, 두번째은닉층 5개를 만들어 학습후 손실변화 그래프 확인 및 평가.
# 은닉층 2개와 Softplus 활성화 함수를 사용하는 신경망 모델을 생성합니다.
# hidden_layers=[5, 5]는 첫 번째 은닉층 5개 노드, 두 번째 은닉층 5개 노드를 의미합니다.
# activation='softplus'는 사용자 정의 softplus 함수 log(1 + exp(x))에 대응합니다.
model3 = ConcreteANN(input_dim=input_dim, hidden_layers=[5, 5], activation='softplus')
# 모델 구조를 출력합니다.
print(model3)
# 모델3을 학습합니다.
# 계층이 깊어지면 표현력은 증가하지만 학습 시간이 더 길어질 수 있습니다.
model3, loss3 = train_model(model3, X_train, y_train, epochs=10000, lr=0.005, print_every=1000)
# 모델3의 손실 변화를 그래프로 확인합니다.
plot_loss(loss3, 'Model 3: hidden layers [5, 5] + Softplus')
# 테스트 데이터로 모델3을 평가합니다.
pred3, corr3, mse3 = evaluate_model(model3, X_test, y_test)
# 모델3의 평가 결과를 출력합니다.
print(f'Model 3 상관계수: {corr3:.4f}')
print(f'Model 3 테스트 MSE: {mse3:.6f}')
위 3 모델을 비교해 표로 정리출력
mse는 mean squared error 평균제곱 오차 .예측값과 실제값의 차이를 측정하는 지표로 적을 수록 좋다 .
# 세 모델의 평가 결과를 하나의 표로 정리합니다.
# 상관계수는 높을수록 좋고, 테스트 MSE는 낮을수록 좋습니다.
results_df = pd.DataFrame({
'model': [
'Model 1: hidden node 1',
'Model 2: hidden nodes 5',
'Model 3: hidden layers [5, 5] + Softplus'
],
'correlation': [corr1, corr2, corr3],
'test_mse': [mse1, mse2, mse3]
})
# 결과 표를 출력합니다.
display(results_df)model correlation test_mse
0 Model 1: hidden node 1 0.799515 0.014928
1 Model 2: hidden nodes 5 0.928621 0.005688
2 Model 3: hidden layers [5, 5] + Softplus 0.925631 0.005891
모델이 어떤데이터에서 어떤값을 예측햇는지 확인
# 실제값과 예측값 일부를 비교하는 데이터프레임을 만듭니다.
# 모델이 테스트 데이터에서 어떤 값을 예측했는지 직접 확인할 수 있습니다.
compare_df = pd.DataFrame({
'actual_strength_norm': y_test.cpu().numpy().reshape(-1),
'pred_model1': pred1,
'pred_model2': pred2,
'pred_model3': pred3
})
# 앞쪽 10개 행만 출력합니다.
display(compare_df.head(10))actual_strength_norm pred_model1 pred_model2 pred_model3
0 0.471160 0.564312 0.480991 0.463695
1 0.362402 0.324807 0.298219 0.298962
2 0.229226 0.218026 0.287898 0.263729
3 0.030522 0.033114 -0.012388 0.007074
4 0.546904 0.556454 0.674926 0.620956
5 0.389062 0.566815 0.473141 0.462745
6 0.261866 0.556599 0.417840 0.448157
7 0.381089 0.533306 0.367153 0.404835
8 0.486359 0.620419 0.641714 0.655730
9 0.380217 0.524960 0.553055 0.713472
위의 관계를 산점도로확인
점들이 대각선에 가까울수록 예측이 실제값과 잘 맞음
# 실제값과 예측값의 관계를 산점도로 확인합니다.
# 점들이 대각선 형태에 가까울수록 예측이 실제값과 잘 맞는 것입니다.
plt.figure(figsize=(6, 6))
plt.scatter(compare_df['actual_strength_norm'], compare_df['pred_model3'], alpha=0.7)
plt.xlabel('Actual strength normalized')
plt.ylabel('Predicted strength normalized')
plt.title('Model 3 Prediction vs Actual')
plt.grid(True)
plt.show()
앞서 min_max_normarlize로 정규화된 값들을 원래값으로 되돌리는 함수 정의
원래단위로 실제값 예측값 비교표를 재생성
# 정규화된 예측값을 원래 strength 단위로 되돌리는 함수를 정의합니다.
# 원래 단위로 복원하면 콘크리트 강도를 실제 수치 범위에서 해석할 수 있습니다.
def inverse_min_max(normalized_values, original_series):
# 원본 strength의 최솟값을 구합니다.
min_value = original_series.min()
# 원본 strength의 최댓값을 구합니다.
max_value = original_series.max()
# 정규화 복원 공식입니다.
# normalized * (max - min) + min 형태로 원래 단위 값을 계산합니다.
return normalized_values * (max_value - min_value) + min_value
# 테스트 실제값을 원래 strength 단위로 복원합니다.
actual_strength_original = inverse_min_max(compare_df['actual_strength_norm'].values, concrete_stg[target_col])
# 모델3 예측값을 원래 strength 단위로 복원합니다.
pred_strength_original = inverse_min_max(compare_df['pred_model3'].values, concrete_stg[target_col])
# 원래 단위의 실제값과 예측값을 비교하는 표를 만듭니다.
original_compare_df = pd.DataFrame({
'actual_strength': actual_strength_original,
'predicted_strength_model3': pred_strength_original
})
# 앞쪽 10개 행만 출력합니다.
display(original_compare_df.head(10))actual_strength predicted_strength_model3
0 40.150002 39.550774
1 31.420000 26.327673
2 20.730000 23.499548
3 4.780000 2.897852
4 46.229996 52.174171
5 33.559998 39.474510
6 23.350000 38.303581
7 32.919998 34.826118
8 41.370003 54.965424
9 32.849998 59.600418
model은 은닉노드를 1개를 사용한 가장 단순한 신경망이었다 .
model2는 5개.
model3은 은닉층 2개와 softplus 활성화함수를 사용했다.
테스트 mse가 낮고 상관계수가 높은 모델일수록 예측 성능이 좋다고 해석할 수 있다.
'SK 네트웍스 AI 캠프' 카테고리의 다른 글
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day23_머신러닝 비지도학습알고리즘 (0) | 2026.06.05 |
|---|---|
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day22_머신러닝 차원축소 및 시각화 (0) | 2026.06.04 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day20_머신러닝 결정트리와 회귀트리 (0) | 2026.06.01 |
| [SK네트웍스 Family AI 캠프] 32기 5주차 회고: Day16 ~ Day19 (0) | 2026.05.29 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day19_머신러닝 서포트백터머신 구조 (0) | 2026.05.29 |



