차원
Dimension
입력변수의 개수.
사람 등록을 위해 키, 몸무게, 나이가 필요하다면 이 3개가 차원이 된다 .
x=(170,65,20)
즉 위 벡터는 3개의 요소를 가지므로 3차원 공간의 한 점이 된다.
https://standout.tistory.com/1779
입력변수의 개수 차원 Dimension, 차원의 저주 Curse of Dimensionality 와 차원축소 Dimensionality Reduction하
차원Dimension입력변수의 개수.사람 등록을 위해 키, 몸무게, 나이가 필요하다면 이 3개가 차원이 된다 .x=(170,65,20)즉 위 벡터는 3개의 요소를 가지므로 3차원 공간의 한 점이 된다. 차원의 저주Curse o
standout.tistory.com
차원축소
Dimensionality Reduction
데이터가 가지고 있는 특성의 개수(차원)을 줄이는 과정
https://standout.tistory.com/1771
가중치란?: Weight 이 특징을 얼마나 중요하게 볼것인가? 수치표현
가중치란?Weight인공지능, 인공신경망에서 입력데이터 결과에 얼마나 큰 영향을 미치는가를 나타내는 값. 인공신경망에서 각 입력 특징의 중요도를 나타내는 수지이다 .학습과정에서 지속적으로
standout.tistory.com
선형차원축소
데이터가 직선, 평면 관계를 가진다고 가정하자.
- PCA Principal Component Analysis 주성분 분석, 데이터 분산이 가장 큰 방향을 찾는다.
https://standout.tistory.com/1781
선형차원축소, PCA Principal Component Analysis: 가장 기본적인 차원축소
입력변수 개수를 차원, 차원의 저주를 보완하기위해 혹은 시각화하기위한 과정을 차원축소라고 한다 .https://standout.tistory.com/1779 입력변수의 개수 차원 Dimension, 차원의 저주 Curse of Dimensionality 와
standout.tistory.com
SVD Singular Value Decomposition
특이값 분해. PCA의 수학적 기반. 행렬하나를 분해해 사용자의 특성을 가장 중요한 정보형태로 저장해 특이값들만 남기고 나머지를 버린다. 원본정보 95%등을 유지하면서 데이터 크기를 크게 줄일 수 있다
https://standout.tistory.com/1786
중요한 정보만 추출한다: 특이값 분해 SVD, Singular Value Decomposition
SVD, Singular Value Decomposition특이값 분해하나의 행렬을 여러개의 작은 행렬로 분해해 데이터의 중요한 정보만 추출하는 선형대수 기법 원래 데이터가 1000개의 변수를 가지고있다하더라도 실제 중
standout.tistory.com
- LDA Linear Discriminant Analysis 선형판별 분석, 분산이 큰 방향을 찾는 pca와 비슷하게 차원을 줄이지만 LDA는 정답 라벨을 사용해 클래스를 가장 잘 구분하는 방향을 찾는다.
= PCA: 데이터가 넓게 퍼지는 방향, LDA 클래스가 잘 나뉘는 방향
https://standout.tistory.com/1782
선형차원축소, LDA Linear Discriminant Analysis
입력변수 개수를 차원, 차원의 저주를 보완하기위해 혹은 시각화하기위한 과정을 차원축소라고 한다 .https://standout.tistory.com/1779 입력변수의 개수 차원 Dimension, 차원의 저주 Curse of Dimensionality 와
standout.tistory.com
- t-SNE, t-distributed Stochastic Neighbor Embedding
고차원에 가까운 점은 저차원에서도 가깝게 배치하는 등으로 주로 시각화에 사용한다.
https://standout.tistory.com/1783
비선형 차원축소, t-SNE, t-distributed Stochastic Neighbor Embedding
입력변수 개수를 차원, 차원의 저주를 보완하기위해 혹은 시각화하기위한 과정을 차원축소라고 한다 .https://standout.tistory.com/1779 입력변수의 개수 차원 Dimension, 차원의 저주 Curse of Dimensionality 와
standout.tistory.com
- UMAP , Uniform Manifold Approximation and Projection
최근 많이 사용하는 t-SNE보다 빠른 큰 데이터처리가능하고 전체 구조 보존이 우수하다.
최근 t-SNE를 대체하거나 함께 사용하는 매우 인기있는 알고리즘
고차원 데이터가 어떤 저차원 구조위에 존재한다고 가정하고 그 구조를 최대한 보존하며 저차원 공간으로 투영한다 .
고차원 공간에서 누가 누구의 이웃인가? 저차원에서도 이웃끼리 배치하며 고차원 이웃관계를 저차원에서도 유지하는 것을 목표로한다. 많은 사람들이 UMAP을 개선된 t-SNE라 생각하고 이게 '맞다'는 아니지만 비슷한 용도로 사용된다.
https://standout.tistory.com/1784
비선형 차원축소, UMAP , Uniform Manifold Approximation and Projection
입력변수 개수를 차원, 차원의 저주를 보완하기위해 혹은 시각화하기위한 과정을 차원축소라고 한다 .https://standout.tistory.com/1779 입력변수의 개수 차원 Dimension, 차원의 저주 Curse of Dimensionality 와
standout.tistory.com
- Autoencoer: 딥러닝 기반 차원축소로 입력 - encode -(잠재공간)- decoder - 출력 으로 중앙의 잠재공간에 압축된 저차원이 들어간다. 784 차원 이미지를 32차원으로 줄이고 추후 복원하면서 학습과정에서 핵심특징만 남길 수 있다 .
위에서의 PCA, LDA, t-SNE, UMAP이 전통적인 차원 축소기법이라면 Autoencoer은 딥러닝 기반 차원 축소기법.
https://standout.tistory.com/1785
비선형 차원축소, 딥러닝 기반 차원 축소, Autoencoder
입력변수 개수를 차원, 차원의 저주를 보완하기위해 혹은 시각화하기위한 과정을 차원축소라고 한다 .https://standout.tistory.com/1779 입력변수의 개수 차원 Dimension, 차원의 저주 Curse of Dimensionality 와
standout.tistory.com
ICA Independent Component Analysis
차원축소계열로 분류되기도 하지만 사실 진짜 목적 신호분리로 미묘히 다르다.
독립성분 분석, PCA처럼 차원 축소가 목적이 아니라 서로 섞인 신호를 원래 독립 신호로 분리하는 것이 목적이다 .
https://standout.tistory.com/1788
비지도학습, ICA Independent Component Analysis: 신호 분리(Blind Source Separation)
ICA Independent Component Analysis독립성분 분석,PCA처럼 차원 축소가 목적이 아니라 서로 섞인 신호를 원래 독립 신호로 분리하는 것이 목적이다 .차원축소계열로 분류되기도 하지만 사실 진짜 목적 신
standout.tistory.com
NMF Non-negative Matrix Factorization
비음수 행렬 분해, 모든 데이터 값이 0 이상인 경우 사용하는 행렬 분해 기법으로 원본 행렬을 작은 행렬로 분해한다.
예로 단어행렬의 문서 여러개가 있다고 가정했을때 NMF는 이를 문서별 주제비율, 주베별 단어 비율로 분해한다. 이러한 단어등장횟수등은 음수가 될 수 없어 모든값은 0이상의 강제로 유지하게된다 .즉 해석이 쉬워진다
https://standout.tistory.com/1789
선형차원축소, 비음수 잠재요인 발견목적의 NMF Non-negative Matrix Factorization
NMF Non-negative Matrix Factorization차원축소/행렬분해 기법, 비음수 행렬 분해모든 데이터 값이 0 이상인 경우 사용하는 행렬 분해 기법원본 행렬을 여러개의 잠재요인 작은 행렬로 분해한다. 원본 데
standout.tistory.com
Isomap Isometric Mapping
비선형 차원 축소 알고리즘, PCA는 직선구조를 잘 처리한다고 했다. 동시에 구부러진 구조를 잘 표현하지 못하는데.Swiss Roll 말려있는 종이 데이터라고 했을때 2차원의 종이라 3차원으로 말려있는 형태이지만 PCA는 말려있는 상태 그대로 압축해버리니 잘 처리하지못하는데 Isomap은 종이를 평쳐 2차원으로 표현하는것으로 직선거리를 사용하지않는다는 핵심아이디어로 대신 곡면을 따라가는 거리를 사용한다. 이를 Geodesic Distance라하며 지구표면에서 서울 - 뉴욕까지의직선거리는 불가하지만 지표면 거리로는 가능하다는 이론을 상상해보길 바란다 .
https://standout.tistory.com/1790
비선형 차원축소, 직선거리를 버리고 Geodesic Distance를 사용하는 Isomap Isometric Mapping
Isomap Isometric Mapping 비선형 차원 축소 알고리즘, PCA는 직선구조를 잘 처리한다고 했다. 동시에 구부러진 구조를 잘 표현하지 못하는데.Swiss Roll 말려있는 종이 데이터라고 했을때 2차원의 종이라 3
standout.tistory.com
위 차원축소 기법을 비교해보자 .
기법지도 여부핵심 목적선형/비선형대표 활용
| PCA | 비지도 | 분산 최대 보존 | 선형 | 일반 차원 축소 |
| LDA | 지도 | 클래스 분리 | 선형 | 분류 성능 향상 |
| t-SNE | 비지도 | 이웃 관계 보존 | 비선형 | 데이터 시각화 |
| UMAP | 비지도 | 구조 보존 | 비선형 | 시각화, 전처리 |
| Autoencoder | 비지도 | 압축·복원 | 비선형 | 딥러닝 차원 축소 |
| SVD | 비지도 | 행렬 분해 | 선형 | 추천 시스템, 텍스트 |
| ICA | 비지도 | 독립 신호 분리 | 선형 | 음성, EEG |
| NMF | 비지도 | 비음수 행렬 분해 | 선형 | 토픽 모델링 |
| Isomap | 비지도 | 곡면 구조 보존 | 비선형 | 비선형 데이터 시각화 |
| PCA | 분산이 가장 큰 방향을 찾아 압축 | 가장 기본적인 차원 축소 |
| LDA | 클래스를 가장 잘 구분하는 방향을 찾음 | 분류 문제 |
| t-SNE | 비슷한 데이터끼리 가깝게 배치 | 고차원 데이터 시각화 |
| UMAP | t-SNE보다 빠르게 시각화 | 대용량 데이터 시각화 |
| SVD (TruncatedSVD) | 중요한 특이값만 남겨 압축 | 텍스트(TF-IDF), 추천 시스템 |
| Autoencoder | 신경망으로 압축 후 복원 | 이미지, 딥러닝 차원 축소 |
| ICA | 섞인 신호를 분리 | 음성, EEG(뇌파) |
| NMF | 비음수 데이터의 잠재 패턴 추출 | 토픽 모델링 |
| Isomap | 곡면 구조를 유지하며 축소 | 비선형 데이터 시각화 |
한번에 여러개를 보니 많이 헷갈리지만 요약해 아래내용으로 이해하고 넘어가보자.
실무에서는 실제로 가장 자주 보는것은 PC이다.
PCA ★★★★★
Autoencoder ★★★★☆
UMAP ★★★★☆
t-SNE ★★★★☆
SVD ★★★☆☆
LDA ★★★☆☆
NMF ★★☆☆☆
ICA ★☆☆☆☆
Isomap ★☆☆☆☆
기본기로는 아래의 내용을 기억한다 .
PCA = 정보(분산)를 최대한 보존하며 압축
LDA = 클래스를 잘 구분하도록 압축
또 시각화용으로 고차원 데이터를 2차원 그림으로 보기 좋게 만드는 것에는 아래를 기억한다.
t-SNE
UMAP
Isomap
나머지는 특수목적인데 각자 전문분야가 있다고 이해한다.
SVD→ 추천 시스템, 텍스트
NMF→ 토픽 모델링
ICA→ 음성 분리, 신호 처리
Autoencoder→ 딥러닝 기반 압축
한번더.
현 상태에서는 PCA가 무엇인지, LDA가 무엇인지, t-SNE가 뭔지만 설명할 수 있어도 충분하다.
PCA는 데이터 분산이 큰 방향을 찾아 최대한 유지하면서 차원을 줄이고,
LDA는 레이블이 있는 데이터에서 서로 다른 클래스를 가장 잘 구분할 수 있는 방향을 찾아 차원을 줄이고,
t-SNE는 고차원 공간에서 가까운 데이터들이 저차원에서도 가깝게 배치되도록해 시각화하기 위한 방법이다.
샘플코드 dimensionality_reduction_practice(차원축소실습) 를 분석해보자.
sklearn.datasets load_digits. 손글씨 숫자 데이터를 불러온다.
Scikit-learn 기본 패키지에 포함되어있지 않는 umap-learn t-SNE보다 빠른 비선형 차원축소 알고리즘 UMAP설치하고 import umap 불러온다.
sklearn.decomposition PCA 분산최대방향을 찾는 알고리즘 불러오기
sklearn.discriminant_analysis LinearDiscrinantAnalysis LDA 선형 판별 분석해 클래스 분리 최대로 하는 알고리즘 불러오기
sklearn.manifold TSNE 시각화용 비선형 차원축소 알고리즘 가져오기
sklearn.linear_model LogisticRegression 분류모델 불러오기
Autoencoder를 만들기 위해 Linear, ReLU를 제공하는 신경망계층 torch.nn, Adam과 SGD를 위한 torch.optim을 불러오고
torch.utils.data TensorDatase를 import해 입력과 정답을 묶을 수 있도록 한다.
외 imports들과 batch 단위를 공급하는 dataLoader를 불러온다.
랜덤시드 고정.
# ============================================================
# 1. 필요한 라이브러리 설치
# ============================================================
# UMAP 알고리즘을 사용하기 위한 외부 라이브러리입니다.
# Colab에서 처음 실행할 경우 설치가 필요합니다.
!pip -q install umap-learn
# ============================================================
# 2. 기본 라이브러리 불러오기
# ============================================================
# numpy는 배열, 행렬, 수치 계산에 사용하는 라이브러리입니다.
import numpy as np
# pandas는 표 형태의 데이터를 다룰 때 사용하는 라이브러리입니다.
import pandas as pd
# matplotlib은 그래프를 그릴 때 사용하는 라이브러리입니다.
import matplotlib.pyplot as plt
# ============================================================
# 3. 머신러닝 관련 라이브러리 불러오기
# ============================================================
# 손글씨 숫자 데이터셋을 불러옵니다.
from sklearn.datasets import load_digits
# 학습 데이터와 테스트 데이터를 나눕니다.
from sklearn.model_selection import train_test_split
# 데이터 표준화를 수행합니다.
from sklearn.preprocessing import StandardScaler
# PCA 차원 축소 알고리즘입니다.
from sklearn.decomposition import PCA
# LDA 차원 축소 알고리즘입니다.
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# t-SNE 차원 축소 알고리즘입니다.
from sklearn.manifold import TSNE
# 분류 성능 비교를 위한 기본 분류 모델입니다.
from sklearn.linear_model import LogisticRegression
# 정확도, 분류 리포트 평가 함수입니다.
from sklearn.metrics import accuracy_score, classification_report
# UMAP 알고리즘입니다.
import umap
# ============================================================
# 4. PyTorch 관련 라이브러리 불러오기
# ============================================================
# PyTorch 핵심 라이브러리입니다.
import torch
# 신경망 계층과 손실 함수를 제공합니다.
import torch.nn as nn
# Adam 같은 최적화 알고리즘을 제공합니다.
import torch.optim as optim
# TensorDataset은 입력과 정답 데이터를 묶고,
# DataLoader는 batch 단위로 데이터를 공급합니다.
from torch.utils.data import TensorDataset, DataLoader
# ============================================================
# 5. 랜덤 시드 고정
# ============================================================
# 매번 실행할 때 가능한 동일한 결과가 나오도록 설정합니다.
SEED = 42
np.random.seed(SEED)
torch.manual_seed(SEED)
# GPU가 있으면 GPU용 랜덤 시드도 고정합니다.
if torch.cuda.is_available():
torch.cuda.manual_seed_all(SEED)
print("라이브러리 준비 완료")
print("PyTorch version:", torch.__version__)
print("GPU 사용 가능 여부:", torch.cuda.is_available())
데이터 로드 및 데이터 구조확인
# ============================================================
# 손글씨 숫자 데이터셋 불러오기
# ============================================================
# load_digits()는 sklearn에서 제공하는 내장 데이터셋입니다.
digits = load_digits()
# X는 입력 데이터입니다.
# shape은 (샘플 수, 특성 수) 형태입니다.
X = digits.data
# y는 정답 라벨입니다.
# 각 이미지가 어떤 숫자인지 0~9 값으로 저장되어 있습니다.
y = digits.target
target_names = digits.target_names
print("X shape:", X.shape)
print("y shape:", y.shape)
print("클래스 목록:", target_names)
# DataFrame으로 변환하여 데이터 구조를 확인합니다.
df = pd.DataFrame(X, columns=[f"pixel_{i}" for i in range(X.shape[1])])
df["target"] = y
df.head()
차원축소전에 원본데이터가 어떤 이미지인지 확인한다.
for문을 통해 이미지를 출력한다. plt.inshow, plt.title에는 label을 표시한다 .이미지확인에는 눈금이 필요없으니 axis는 off.
# ============================================================
# 원본 손글씨 이미지 확인
# ============================================================
plt.figure(figsize=(10, 4))
# 앞에서부터 10개의 이미지를 출력합니다.
for i in range(10):
plt.subplot(2, 5, i + 1)
# digits.images[i]는 8x8 이미지 형태입니다.
plt.imshow(digits.images[i], cmap="gray")
# 제목에 실제 정답 숫자를 표시합니다.
plt.title(f"Label: {y[i]}")
# 이미지 확인에는 축 눈금이 필요 없으므로 제거합니다.
plt.axis("off")
plt.tight_layout()
plt.show()
학습/테스트 데이터를 분리한다.
standardscaler를 통해 데이터를 표준화한다.
# ============================================================
# 학습 데이터와 테스트 데이터 분리
# ============================================================
# test_size=0.2는 전체 데이터의 20%를 테스트 데이터로 사용한다는 의미입니다.
# stratify=y는 각 숫자 클래스 비율을 학습/테스트 데이터에 비슷하게 유지합니다.
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=SEED,
stratify=y
)
print("X_train shape:", X_train.shape)
print("X_test shape:", X_test.shape)
print("y_train shape:", y_train.shape)
print("y_test shape:", y_test.shape)# ============================================================
# 데이터 표준화
# ============================================================
# StandardScaler는 각 컬럼의 평균을 0, 표준편차를 1로 변환합니다.
scaler = StandardScaler()
# 학습 데이터에서 평균과 표준편차를 계산하고 변환합니다.
X_train_scaled = scaler.fit_transform(X_train)
# 테스트 데이터는 학습 데이터 기준 평균/표준편차로만 변환합니다.
X_test_scaled = scaler.transform(X_test)
print("표준화 전 평균:", round(X_train.mean(), 4))
print("표준화 후 평균:", round(X_train_scaled.mean(), 4))
print("표준화 후 표준편차:", round(X_train_scaled.std(), 4))
차원축소전에 이 원본데이터를 우선 logistic regression으로 정확도를 확인하자.
LogisticRegression은 분류를 위한 머신러닝 모델으로 이름에 회귀가 들어가나 실제로는 분류모델로 사용한다. 로지스틱 분류모델은 손글씨 숫자 데이터가 있다면 각 클래스의 확률을 계산해 가장높은 클래스를 선택한다. 여기 차원축소 실습에서 사용하는 이유는 원래데이터에서 차원을 줄였을때 logistic regression을 거쳐 정확도를 측정해 차원을 줄여도 분류 성능이 유지되는가를 확인 할 수 있기 때문.
LogisticRegression 모델을 만들어 fit.학습. predict로 예측을 하고 accuray_score를 계산해 출력했다.
# ============================================================
# 원본 64차원 데이터로 기준 모델 학습
# ============================================================
baseline_model = LogisticRegression(
max_iter=2000,
random_state=SEED
)
# 표준화된 원본 학습 데이터로 모델 학습
baseline_model.fit(X_train_scaled, y_train)
# 표준화된 원본 테스트 데이터로 예측
baseline_pred = baseline_model.predict(X_test_scaled)
# 정확도 계산
baseline_acc = accuracy_score(y_test, baseline_pred)
print("원본 64차원 기준 정확도:", round(baseline_acc, 4))
print(classification_report(y_test, baseline_pred))
PCA는 정답라벨을 사용하지않는 비지도학습 기반 차원축소 알고리즘이라고했다.
PCA 객체를 만들어 학습데이터는 fit_transform, 테스트 데이터는 transform.
figure, plt.scatter로 시각화해보자.
2차원 축소후 확인해보니 PCA는 시각화에는 좋지만 정보손실이 커 정확도가 떨어지는 scatter를 확인 할 수 있었다.
실무에서는 모델입력용으론 10, 20, 30차원정도를 사용하니 우리도 다시해보자 .
# ============================================================
# PCA 2차원 축소
# ============================================================
# n_components=2는 64차원 데이터를 2차원으로 줄인다는 의미입니다.
pca_2d = PCA(n_components=2, random_state=SEED)
# 학습 데이터로 PCA 축을 찾고 변환합니다.
X_train_pca_2d = pca_2d.fit_transform(X_train_scaled)
# 테스트 데이터는 학습된 PCA 축으로만 변환합니다.
X_test_pca_2d = pca_2d.transform(X_test_scaled)
print("PCA 적용 전:", X_train_scaled.shape)
print("PCA 적용 후:", X_train_pca_2d.shape)
print("PC1 설명 분산 비율:", round(pca_2d.explained_variance_ratio_[0], 4))
print("PC2 설명 분산 비율:", round(pca_2d.explained_variance_ratio_[1], 4))
print("누적 설명 분산 비율:", round(pca_2d.explained_variance_ratio_.sum(), 4))# ============================================================
# PCA 2차원 결과 시각화
# ============================================================
plt.figure(figsize=(8, 6))
scatter = plt.scatter(
X_train_pca_2d[:, 0],
X_train_pca_2d[:, 1],
c=y_train,
cmap="tab10",
s=20,
alpha=0.8
)
plt.colorbar(scatter, label="Digit label")
plt.xlabel("Principal Component 1")
plt.ylabel("Principal Component 2")
plt.title("PCA 2D Visualization")
plt.grid(True)
plt.show()# ============================================================
# PCA 20차원 축소
# ============================================================
pca_20 = PCA(n_components=20, random_state=SEED)
X_train_pca_20 = pca_20.fit_transform(X_train_scaled)
X_test_pca_20 = pca_20.transform(X_test_scaled)
print("PCA 20차원 적용 전:", X_train_scaled.shape)
print("PCA 20차원 적용 후:", X_train_pca_20.shape)
print("누적 설명 분산 비율:", round(pca_20.explained_variance_ratio_.sum(), 4))
PCA 20차원 적용 전: (1437, 64)
PCA 20차원 적용 후: (1437, 20)
누적 설명 분산 비율: 0.7899* 누적 설명 분산비율 Explained Variance Ratio 를 봐보자 .
PCA는 데이터 정보를 최대한 유지하면서 차원을 줄이는 것이라고 했다. 78%는 정보량을 100%이라고했을때 20개 주성분을 활용해 약 79% 설명할 수 있다는 의미이다
즉 현재 상태는 68% 차원을 줄였는데 정보는 79%남아있다. '꽤 괜찮다' 하지만 실무에서는 누적설명 분산비율을 90~99%를 목표로 함으로 중요정보를 많이 보존했지만 좀더 다른 방법을 찾아야 할듯하다.
20차원으로 다시 학습해보자.
위에서 분석한 누적설명 분산 비율 그래프를 그려보자.
이번엔 상당히 잘 작동했다. 원본의 정확도가 97이라면 20차원 정확도가 94%. 64차원을 20차원으로 줄이고 정확도는 크게 안떨어졌다. 사라진 21% 정보는 분류에 크게 중요하지않았다는것을 의미한다.
# ============================================================
# PCA 20차원 데이터로 분류 모델 학습
# ============================================================
pca_model = LogisticRegression(
max_iter=2000,
random_state=SEED
)
pca_model.fit(X_train_pca_20, y_train)
pca_pred = pca_model.predict(X_test_pca_20)
pca_acc = accuracy_score(y_test, pca_pred)
print("원본 64차원 기준 정확도:", round(baseline_acc, 4))
print("PCA 20차원 기준 정확도:", round(pca_acc, 4))
print(classification_report(y_test, pca_pred))# ============================================================
# PCA 누적 설명 분산 비율 그래프
# ============================================================
cumulative_variance = np.cumsum(pca_20.explained_variance_ratio_)
plt.figure(figsize=(8, 5))
plt.plot(range(1, len(cumulative_variance) + 1), cumulative_variance, marker="o")
plt.xlabel("Number of principal components")
plt.ylabel("Cumulative explained variance ratio")
plt.title("PCA Cumulative Explained Variance")
plt.grid(True)
plt.show()원본 64차원 기준 정확도: 0.9722
PCA 20차원 기준 정확도: 0.9417
precision recall f1-score support
0 1.00 0.97 0.99 36
1 0.85 0.81 0.83 36
2 0.95 1.00 0.97 35
3 1.00 0.95 0.97 37
4 0.88 1.00 0.94 36
5 0.97 0.97 0.97 37
6 0.95 0.97 0.96 36
7 1.00 0.97 0.99 36
8 0.91 0.86 0.88 35
9 0.92 0.92 0.92 36
accuracy 0.94 360
macro avg 0.94 0.94 0.94 360
weighted avg 0.94 0.94 0.94 360
이번에는 LDA로 라벨 기반 차원축소를 실습해보자.
LDA는 정답라벨을 사용한다고 했다.
PCA가 분산이 큰 방향을 찾는다면 LDA는 '클래스가 잘 구분되는 방향'을 찾는다고 했다 .
LinearDiscriminantAnalysis 객체를 만들어 마찬가지로 2차원으로 축소해보자.
학습용데이터에 fit_transform, 테스트데이터에 마찬가지로 transforn.
보면 y_train이 fit_transform에 매개변수로 추가되어있음을 확인할 수 있다
# ============================================================
# LDA 2차원 축소
# ============================================================
# LDA는 정답 라벨을 사용하므로 fit_transform에 y_train도 입력합니다.
lda_2d = LinearDiscriminantAnalysis(n_components=2)
X_train_lda_2d = lda_2d.fit_transform(X_train_scaled, y_train)
X_test_lda_2d = lda_2d.transform(X_test_scaled)
print("LDA 적용 전:", X_train_scaled.shape)
print("LDA 적용 후:", X_train_lda_2d.shape)
시각화. 확실히 같은 2차원이라도 PCA보다 나아보인다.
PCA는 데이터 정보량을 최대한 보존하는 방향을 찾기에 크래스가 무엇인지 모른다. 분산최대가 목적이지 클래스 분리가 목적이 아니라는 의미로 그저 분류자체가 목표. 기본적인 차원축소기능이라 했다.
LDA는 서로 다른 클래스를 최대한 멀리 떨어뜨리고 같은 클래스는 최대한 가깝게 모은다고 했다 .즉 정답 레이블을 사용한다는것으로 애초에 분류문제를 위해 만든 차원축소 알고리즘이기에 매우 유리하다. 그렇다고 LDA가 항상 좋은것은 아니다. PCA는 레이블 없이도 사용가능한 비지도학습이고 LDA는 레이블이 반드시 필요한 지도학습으로 고객데이터 분석시 정답클래스가 없다면 LDA는 사용불가하니 PCA를 써야한다.
아무튼간 이로 레이블 정보를 제공할시에는 같은 차원수에서도 클래스가 풜씬 더 잘 분리된다는 것을 볼 수 있었따.
# ============================================================
# LDA 2차원 결과 시각화
# ============================================================
plt.figure(figsize=(8, 6))
scatter = plt.scatter(
X_train_lda_2d[:, 0],
X_train_lda_2d[:, 1],
c=y_train,
cmap="tab10",
s=20,
alpha=0.8
)
plt.colorbar(scatter, label="Digit label")
plt.xlabel("LD1")
plt.ylabel("LD2")
plt.title("LDA 2D Visualization")
plt.grid(True)
plt.show()
참고로
차원을 마찬가지로 좀 늘려볼 수도 있을까?
LDA가 만들 수 있는 최대차원은 min(특성수 - 클래스 수 -1)이다. digists데이터셋은 클래스가 10개임으로 9차원까지만 늘릴 수 있겠다.
# ============================================================
# LDA 9차원 축소 후 분류 성능 확인
# ============================================================
lda_9 = LinearDiscriminantAnalysis(n_components=9)
X_train_lda_9 = lda_9.fit_transform(X_train_scaled, y_train)
X_test_lda_9 = lda_9.transform(X_test_scaled)
lda_model = LogisticRegression(
max_iter=2000,
random_state=SEED
)
lda_model.fit(X_train_lda_9, y_train)
lda_pred = lda_model.predict(X_test_lda_9)
lda_acc = accuracy_score(y_test, lda_pred)
print("원본 64차원 기준 정확도:", round(baseline_acc, 4))
print("PCA 20차원 기준 정확도:", round(pca_acc, 4))
print("LDA 9차원 기준 정확도:", round(lda_acc, 4))
print(classification_report(y_test, lda_pred))원본 64차원 기준 정확도: 0.9722
PCA 20차원 기준 정확도: 0.9417
LDA 9차원 기준 정확도: 0.9556
precision recall f1-score support
0 1.00 0.97 0.99 36
1 0.89 0.89 0.89 36
2 1.00 0.94 0.97 35
3 0.97 0.97 0.97 37
4 0.90 1.00 0.95 36
5 0.97 1.00 0.99 37
6 0.95 0.97 0.96 36
7 0.97 0.94 0.96 36
8 0.97 0.89 0.93 35
9 0.95 0.97 0.96 36
accuracy 0.96 360
macro avg 0.96 0.96 0.96 360
weighted avg 0.96 0.96 0.96 360
t-SNE, UMAP으로 2차원 시각화를 해보자.
t-SNE와 UMAP은 주로 고차원 데이터와 군집 구조를 2차원으로 확인할때 사용한다고 했다.
x데이터를 scaler한 후, TSNE 객체를 만들어 fit_transform해 결과 시작화했다. scatter
앞서 살펴본 LDA와 다르게 군집들이 굉장히 멀리 떨어져있다.
PCA는 '기본을 지키는 알고리즘'으로 이해하면 좋다 실제 거리와 구조를 어느정도 유지하려고한다 .
t-SNE는 가까운점은 가깝게, 멀리있는 점들의 정확한 거리는 별로 중요하지않아군집간 거리가 과장될 수 있다. t-SNE은 군집 내부를 중요하게 여긴다는 이론을 확인할 수 있었다.
# ============================================================
# t-SNE 2차원 시각화
# ============================================================
# 시각화 목적이므로 전체 데이터를 표준화해서 사용합니다.
X_scaled_all = scaler.fit_transform(X)
# t-SNE는 transform 기능이 일반적이지 않으므로 주로 전체 데이터 시각화에 사용합니다.
tsne = TSNE(
n_components=2,
perplexity=30,
learning_rate="auto",
init="pca",
random_state=SEED
)
X_tsne = tsne.fit_transform(X_scaled_all)
print("t-SNE 적용 전:", X_scaled_all.shape)
print("t-SNE 적용 후:", X_tsne.shape)# ============================================================
# t-SNE 결과 시각화
# ============================================================
plt.figure(figsize=(8, 6))
scatter = plt.scatter(
X_tsne[:, 0],
X_tsne[:, 1],
c=y,
cmap="tab10",
s=20,
alpha=0.8
)
plt.colorbar(scatter, label="Digit label")
plt.xlabel("t-SNE 1")
plt.ylabel("t-SNE 2")
plt.title("t-SNE 2D Visualization")
plt.grid(True)
plt.show()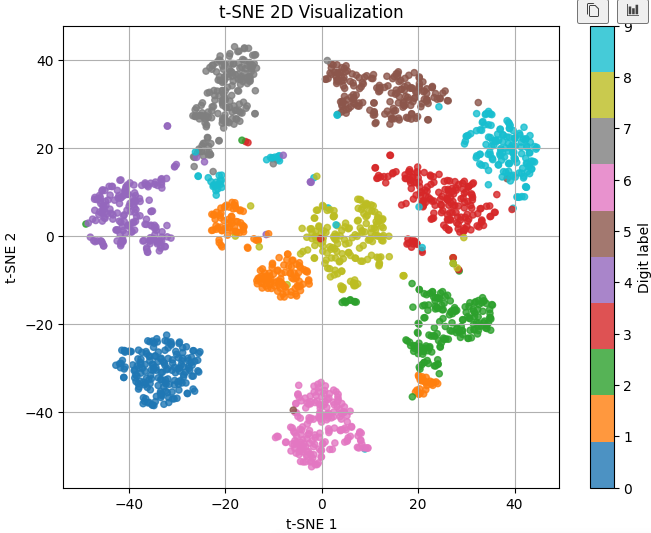
UMAP도 시각화해보자.
PCA는 정보보존이 목적이기에 군집이 어느정도 겹칠 수 있다고했다.
t-SNE는 가까운점을 가깝게 위치시킨다고 했다 .
UMAP은 데이터 연결 구조를 보존하려고 한다 . t-sne보다 군집을 '매우' 강조한다. 그로인해 엄청군집이 분리되어 보이는데 digits데이터는 원래 숫자별로 구분이 안되는 데이터라 UMAP을 적용하면 섬처럼 떨어져보인다 .UMAP도 t-SNE처럼 군집형성에 강한 알고리즘임을 확인 할 수 있었다.
# ============================================================
# UMAP 결과 시각화
# ============================================================
plt.figure(figsize=(8, 6))
scatter = plt.scatter(
X_umap[:, 0],
X_umap[:, 1],
c=y,
cmap="tab10",
s=20,
alpha=0.8
)
plt.colorbar(scatter, label="Digit label")
plt.xlabel("UMAP 1")
plt.ylabel("UMAP 2")
plt.title("UMAP 2D Visualization")
plt.grid(True)
plt.show()
autoencoder로 해보자.
autoenoder는 입력데이터를 압축한 뒤 다시 복원하는 신경망이라고 했다.
digits 픽셀값은 0~16 범위임으로 decoder마지막에 sigmoid()가 있고 sigmoid의 출력범위는 0~1 임으로 X_ae = X/16.0으로 정규화했다.
tensor로 변환해 TensorDataset,
autoencoder는 입력을 그대로 복원하는 것이 목표임으로 (x, y)rk dksls TensorDataset()를 사용해 자기 자신을 맞췄다.
batch 정보로 dataloader.
세팅완료.
# ============================================================
# Autoencoder 학습 데이터 준비
# ============================================================
# digits 픽셀 값은 0~16 범위입니다.
# Sigmoid 출력과 맞추기 위해 0~1 범위로 정규화합니다.
X_ae = X / 16.0
X_train_ae, X_test_ae, y_train_ae, y_test_ae = train_test_split(
X_ae,
y,
test_size=0.2,
random_state=SEED,
stratify=y
)
# numpy 배열을 PyTorch Tensor로 변환합니다.
X_train_tensor = torch.tensor(X_train_ae, dtype=torch.float32)
X_test_tensor = torch.tensor(X_test_ae, dtype=torch.float32)
# Autoencoder는 입력 자체를 복원하므로 입력과 정답 모두 X입니다.
train_dataset = TensorDataset(X_train_tensor, X_train_tensor)
test_dataset = TensorDataset(X_test_tensor, X_test_tensor)
# batch_size=64는 한 번에 64개씩 학습한다는 의미입니다.
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
print("Autoencoder 학습 데이터:", X_train_tensor.shape)
print("Autoencoder 테스트 데이터:", X_test_tensor.shape)
sequential로 선형적으로 encoder에서 64 - 32 차원으로 줄이고 relu이후 32-16차원으로, relu를 거쳐 16 - 2 마찬가지로 2차원으로 축소했다. 이후 decoderㄹ ㅗ다시 복원했다.
# ============================================================
# Autoencoder 모델 정의
# ============================================================
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__()
# Encoder: 64차원 입력을 2차원 잠재 벡터로 압축합니다.
self.encoder = nn.Sequential(
nn.Linear(64, 32), # 64차원 → 32차원
nn.ReLU(), # 비선형 활성화 함수
nn.Linear(32, 16), # 32차원 → 16차원
nn.ReLU(),
nn.Linear(16, 2) # 16차원 → 2차원 잠재 벡터
)
# Decoder: 2차원 잠재 벡터를 다시 64차원으로 복원합니다.
self.decoder = nn.Sequential(
nn.Linear(2, 16), # 2차원 → 16차원
nn.ReLU(),
nn.Linear(16, 32), # 16차원 → 32차원
nn.ReLU(),
nn.Linear(32, 64), # 32차원 → 64차원
nn.Sigmoid() # 출력값을 0~1 범위로 제한
)
def forward(self, x):
# 입력 데이터를 Encoder로 압축합니다.
z = self.encoder(x)
# 압축된 z를 Decoder로 복원합니다.
reconstructed = self.decoder(z)
return reconstructed, z
# GPU가 가능하면 GPU, 아니면 CPU를 사용합니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
ae_model = Autoencoder().to(device)
print(ae_model)
print("사용 장치:", device)
MELoss로 원본 입력과 복원 출력의 차이를 계산하고 optim.adam으로 최적화하되 epochs는 100을 줘보자 .
# ============================================================
# Autoencoder 학습 설정
# ============================================================
# MSELoss는 원본 입력과 복원 출력의 차이를 계산합니다.
criterion = nn.MSELoss()
# Adam은 딥러닝에서 많이 사용하는 최적화 알고리즘입니다.
optimizer = optim.Adam(ae_model.parameters(), lr=0.001)
# 전체 학습 반복 횟수입니다.
epochs = 100
train_losses = []
test_losses = []
print("학습 설정 완료")
학습모드로 전환해 for로 학습해본다 .
이어 평가한다.
# ============================================================
# Autoencoder 학습 루프
# ============================================================
for epoch in range(epochs):
# 모델을 학습 모드로 전환합니다.
ae_model.train()
train_loss_sum = 0.0
for batch_X, batch_y in train_loader:
batch_X = batch_X.to(device)
batch_y = batch_y.to(device)
# 이전 gradient를 초기화합니다.
optimizer.zero_grad()
# 복원 결과와 잠재 벡터를 얻습니다.
reconstructed, z = ae_model(batch_X)
# 복원 결과와 원본 데이터의 차이를 손실로 계산합니다.
loss = criterion(reconstructed, batch_y)
# 역전파로 gradient를 계산합니다.
loss.backward()
# 파라미터를 업데이트합니다.
optimizer.step()
train_loss_sum += loss.item()
train_loss_avg = train_loss_sum / len(train_loader)
# 모델을 평가 모드로 전환합니다.
ae_model.eval()
test_loss_sum = 0.0
with torch.no_grad():
for batch_X, batch_y in test_loader:
batch_X = batch_X.to(device)
batch_y = batch_y.to(device)
reconstructed, z = ae_model(batch_X)
loss = criterion(reconstructed, batch_y)
test_loss_sum += loss.item()
test_loss_avg = test_loss_sum / len(test_loader)
train_losses.append(train_loss_avg)
test_losses.append(test_loss_avg)
if (epoch + 1) % 10 == 0:
print(f"Epoch [{epoch+1}/{epochs}] Train Loss: {train_loss_avg:.6f} Test Loss: {test_loss_avg:.6f}")
손실그래프를 확인한다.
# ============================================================
# Autoencoder 손실 그래프
# ============================================================
plt.figure(figsize=(8, 5))
plt.plot(train_losses, label="Train Loss")
plt.plot(test_losses, label="Test Loss")
plt.xlabel("Epoch")
plt.ylabel("MSE Loss")
plt.title("Autoencoder Training Loss")
plt.legend()
plt.grid(True)
plt.show()
2차원 백터를 추출해 시각화한다.
autoencoder는 원래 pca/lda/t-sns/umap처럼 예쁘게 분리되는것이 목적이 아니다. 그들의 목적이 차원축소 + 시각화라면 autoencoder의 목적은 입력 이미지 - 압축 - 복원이 목적으로숫자 3 이미지를 다시 만들어내는것이 목표이다.
# ============================================================
# Autoencoder 2차원 잠재 벡터 추출
# ============================================================
X_all_tensor = torch.tensor(X_ae, dtype=torch.float32).to(device)
ae_model.eval()
with torch.no_grad():
reconstructed_all, latent_all = ae_model(X_all_tensor)
# Tensor를 numpy 배열로 변환합니다.
X_autoencoder_2d = latent_all.cpu().numpy()
print("Autoencoder 적용 전:", X_ae.shape)
print("Autoencoder 잠재 벡터:", X_autoencoder_2d.shape)# ============================================================
# Autoencoder 잠재 공간 시각화
# ============================================================
plt.figure(figsize=(8, 6))
scatter = plt.scatter(
X_autoencoder_2d[:, 0],
X_autoencoder_2d[:, 1],
c=y,
cmap="tab10",
s=20,
alpha=0.8
)
plt.colorbar(scatter, label="Digit label")
plt.xlabel("Latent Dimension 1")
plt.ylabel("Latent Dimension 2")
plt.title("Autoencoder 2D Latent Space")
plt.grid(True)
plt.show()
원본이미지와 복원이미지를 비교해보자 .
좀더 autoencoder가 이해된다.
# ============================================================
# 원본 이미지와 복원 이미지 비교
# ============================================================
sample_X = X_test_tensor[:10].to(device)
ae_model.eval()
with torch.no_grad():
sample_reconstructed, _ = ae_model(sample_X)
sample_original = sample_X.cpu().numpy()
sample_reconstructed = sample_reconstructed.cpu().numpy()
plt.figure(figsize=(10, 4))
for i in range(10):
# 원본 이미지
plt.subplot(2, 10, i + 1)
plt.imshow(sample_original[i].reshape(8, 8), cmap="gray")
plt.title("Orig")
plt.axis("off")
# 복원 이미지
plt.subplot(2, 10, i + 11)
plt.imshow(sample_reconstructed[i].reshape(8, 8), cmap="gray")
plt.title("Recon")
plt.axis("off")
plt.tight_layout()
plt.show()
위 실습들의 정확도를 비교해보자 .
그래프로도 비교해보자.
# ============================================================
# 결과 비교표
# ============================================================
results = pd.DataFrame({
"Method": ["Original 64D", "PCA 20D", "LDA 9D"],
"Dimension": [64, 20, 9],
"Accuracy": [baseline_acc, pca_acc, lda_acc]
})
results["Accuracy"] = results["Accuracy"].round(4)
resultsMethod Dimension Accuracy
0 Original 64D 64 0.9722
1 PCA 20D 20 0.9417
2 LDA 9D 9 0.9556# ============================================================
# 결과 비교 그래프
# ============================================================
plt.figure(figsize=(7, 5))
plt.bar(results["Method"], results["Accuracy"])
plt.ylim(0, 1.05)
plt.xlabel("Method")
plt.ylabel("Accuracy")
plt.title("Accuracy Comparison")
plt.grid(axis="y")
plt.show()
샘플코드 dimensionality_reduction 를 분석해보자 .
와인 데이터셋을 사용해 와인품질을 저품질, 중간품질, 고품질로 분류하는 목표이다 .
import
sklearn 기본패키지에 포함되어있지않은 umap-learn을 따로 install했다 .
UMAP t-SNE 보다 빠르고 대용량 데이터 처리 기능이 가능한 시각화
PCA 비지도학습 데이터 분산이 큰 방향을 찾아 차원축소한다.
LDA 클래스를 잘 구분하는 방향
t-SNE 고차원에서 가까운점은 2차원에서 가깝게 하는 데이터 시각화도구
random forest 여러개의 결정 트리를 만들어 다수결로 결과를 결정한다.
logistic regreesion 대표적인 선형 분류모델
confustion_matrix로 실제값과 예측값의 관계를 표로 출력하는 등의 외 라이브러리를 import했다.
랜덤시드 고정.
# ============================================================
# 1. 실습 환경 준비
# ============================================================
# UMAP 알고리즘을 사용하기 위한 패키지를 설치합니다.
# UMAP은 sklearn 기본 패키지에 포함되어 있지 않기 때문에 별도 설치가 필요합니다.
# -q 옵션은 설치 로그를 간단히 출력하라는 의미입니다.
!pip -q install umap-learn
# ============================================================
# 2. 기본 데이터 처리 라이브러리 불러오기
# ============================================================
# numpy는 숫자 배열, 행렬 계산, 난수 생성 등에 사용하는 핵심 수치 계산 라이브러리입니다.
# 머신러닝 데이터는 대부분 숫자 배열 형태로 처리되므로 거의 항상 사용됩니다.
import numpy as np
# pandas는 CSV, Excel 같은 표 형식 데이터를 읽고 처리하는 라이브러리입니다.
# DataFrame이라는 표 구조를 사용하여 컬럼 선택, 결측치 확인, 통계량 확인 등을 쉽게 할 수 있습니다.
import pandas as pd
# matplotlib.pyplot은 그래프를 그리는 라이브러리입니다.
# PCA, LDA, t-SNE, UMAP, Autoencoder 결과를 2차원 산점도로 시각화할 때 사용합니다.
import matplotlib.pyplot as plt
# ============================================================
# 3. 머신러닝 전처리 및 모델 관련 라이브러리 불러오기
# ============================================================
# train_test_split은 전체 데이터를 학습 데이터와 테스트 데이터로 나누는 함수입니다.
# 모델이 학습하지 않은 데이터에서도 잘 맞추는지 확인하기 위해 사용합니다.
from sklearn.model_selection import train_test_split
# StandardScaler는 각 입력 변수의 평균을 0, 표준편차를 1로 맞추는 표준화 도구입니다.
# 차원 축소 알고리즘은 변수 단위 차이에 민감하므로 표준화가 중요합니다.
from sklearn.preprocessing import StandardScaler
# PCA는 Principal Component Analysis, 즉 주성분 분석입니다.
# 정답 라벨 없이 데이터의 분산이 큰 방향을 찾아 차원을 줄이는 비지도 차원 축소 알고리즘입니다.
from sklearn.decomposition import PCA
# LDA는 Linear Discriminant Analysis, 즉 선형 판별 분석입니다.
# 정답 라벨을 사용하여 클래스가 잘 분리되는 방향으로 차원을 줄이는 지도학습 기반 차원 축소 알고리즘입니다.
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
# TSNE는 t-SNE 알고리즘입니다.
# 고차원 데이터에서 가까운 샘플들이 2차원에서도 가깝게 배치되도록 시각화하는 비선형 차원 축소 알고리즘입니다.
from sklearn.manifold import TSNE
# umap은 UMAP 알고리즘을 사용하기 위한 라이브러리입니다.
# UMAP은 t-SNE와 비슷하게 고차원 데이터를 2차원으로 시각화하지만, 보통 속도가 빠르고 대용량 데이터에 더 유리합니다.
import umap
# RandomForestClassifier는 여러 개의 의사결정나무를 결합한 앙상블 분류 모델입니다.
# 차원 축소 전후의 분류 성능을 비교하기 위해 사용합니다.
from sklearn.ensemble import RandomForestClassifier
# LogisticRegression은 선형 분류 모델입니다.
# 기준 성능 비교용으로 사용하기 좋습니다.
from sklearn.linear_model import LogisticRegression
# accuracy_score는 전체 예측 중 맞춘 비율, 즉 정확도를 계산합니다.
# classification_report는 precision, recall, f1-score 등 상세 평가 지표를 출력합니다.
# confusion_matrix는 실제 클래스와 예측 클래스의 대응 관계를 행렬로 보여줍니다.
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# ============================================================
# 4. PyTorch 딥러닝 라이브러리 불러오기
# ============================================================
# torch는 PyTorch의 핵심 라이브러리입니다.
# Tensor 생성, GPU 연산, 딥러닝 학습에 사용됩니다.
import torch
# torch.nn은 신경망 계층, 활성화 함수, 손실 함수 등을 제공합니다.
# Autoencoder 모델을 만들 때 사용합니다.
import torch.nn as nn
# torch.optim은 Adam, SGD 같은 최적화 알고리즘을 제공합니다.
# Autoencoder의 가중치를 업데이트할 때 사용합니다.
import torch.optim as optim
# TensorDataset은 입력 데이터와 정답 데이터를 하나의 데이터셋으로 묶습니다.
# DataLoader는 데이터를 batch 단위로 나누어 학습할 수 있게 해줍니다.
from torch.utils.data import TensorDataset, DataLoader
# ============================================================
# 5. 랜덤 시드 고정
# ============================================================
# 랜덤 시드를 고정하면 데이터를 나누거나 모델을 초기화할 때 가능한 한 같은 결과가 나오도록 만들 수 있습니다.
# 실습, 보고서, 수업에서는 재현성이 중요하므로 시드를 고정하는 것이 좋습니다.
SEED = 42
# numpy에서 사용하는 난수 시드를 고정합니다.
np.random.seed(SEED)
# PyTorch에서 사용하는 난수 시드를 고정합니다.
torch.manual_seed(SEED)
# torch.cuda.is_available()은 현재 환경에서 GPU 사용 가능 여부를 확인합니다.
# GPU가 있으면 "cuda", 없으면 "cpu"를 사용합니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 준비 상태를 출력합니다.
print("라이브러리 준비 완료")
print("사용 장치:", device)
데이터셋 다운로드
# ============================================================
# 인터넷에서 CSV 데이터 다운로드
# ============================================================
# UCI Machine Learning Repository에서 제공하는 Red Wine Quality 데이터셋 URL입니다.
# 이 데이터셋은 와인의 화학적 성분과 품질 점수를 포함합니다.
DATA_URL = "https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv"
# pd.read_csv()는 CSV 파일을 DataFrame으로 읽어오는 pandas 함수입니다.
# 일반 CSV는 쉼표(,)로 컬럼이 구분되지만,
# 이 데이터셋은 세미콜론(;)으로 컬럼이 구분되어 있으므로 sep=";"를 반드시 지정해야 합니다.
# 인터넷 URL을 직접 넣으면 파일을 다운로드하지 않고도 바로 읽을 수 있습니다.
df = pd.read_csv(DATA_URL, sep=";")
# head()는 데이터 앞부분 5개 행을 보여줍니다.
# 데이터를 불러온 직후에는 컬럼명과 값 형태가 올바른지 먼저 확인해야 합니다.
df.head()# ============================================================
# 데이터 기본 정보 확인
# ============================================================
# df.shape는 데이터의 행(row)과 열(column) 개수를 튜플 형태로 반환합니다.
# 예: (1599, 12)라면 1599개의 샘플과 12개의 컬럼이 있다는 의미입니다.
print("데이터 크기:", df.shape)
# df.columns.tolist()는 DataFrame의 컬럼명을 리스트로 변환합니다.
# 어떤 입력 변수가 있는지 확인할 때 사용합니다.
print("컬럼 목록:")
print(df.columns.tolist())
# df.info()는 각 컬럼의 데이터 타입, 결측치가 아닌 값의 개수, 메모리 사용량을 보여줍니다.
# 실무에서는 데이터 분석 시작 전에 반드시 확인하는 기본 정보입니다.
df.info()# ============================================================
# 기초 통계량 확인
# ============================================================
# describe()는 숫자형 컬럼의 주요 통계량을 출력합니다.
# count: 데이터 개수
# mean: 평균
# std: 표준편차
# min: 최솟값
# 25%, 50%, 75%: 사분위수
# max: 최댓값
# 이 결과를 통해 이상치나 값 범위를 대략적으로 확인할 수 있습니다.
df.describe()# ============================================================
# 결측치 확인
# ============================================================
# isnull()은 값이 비어 있으면 True, 비어 있지 않으면 False를 반환합니다.
# sum()을 붙이면 True가 1로 계산되어 컬럼별 결측치 개수를 구할 수 있습니다.
missing_values = df.isnull().sum()
# 컬럼별 결측치 개수를 출력합니다.
# 결측치가 있으면 삭제, 평균 대체, 중앙값 대체 등의 처리가 필요할 수 있습니다.
print("컬럼별 결측치 개수:")
print(missing_values)
# 전체 데이터에서 결측치가 총 몇 개인지 확인합니다.
print("전체 결측치 개수:", missing_values.sum())
quality는 3~8사이의 점수로 이를 분류하기 위해 0, 1, 2로 3개 등급으로 변환할것이다.
우선 각 quality 분포를 확인해보자. 당연한 얘기겠지만 중간단계가 꽤 많다.
# ============================================================
# quality 분포 확인
# ============================================================
# "quality"는 와인 품질 점수입니다.
# value_counts()는 값별 데이터 개수를 계산합니다.
# sort_index()는 quality 점수 순서대로 정렬합니다.
quality_counts = df["quality"].value_counts().sort_index()
# 원본 품질 점수의 분포를 출력합니다.
# 어떤 점수에 데이터가 몰려 있는지 확인할 수 있습니다.
print("원본 quality 분포:")
print(quality_counts)
# 그래프 크기를 지정합니다.
plt.figure(figsize=(7, 4))
# quality 점수별 데이터 개수를 막대그래프로 표시합니다.
# x축: quality 점수
# y축: 해당 점수의 데이터 개수
plt.bar(quality_counts.index.astype(str), quality_counts.values)
# x축 이름을 설정합니다.
plt.xlabel("Wine quality score")
# y축 이름을 설정합니다.
plt.ylabel("Count")
# 그래프 제목을 설정합니다.
plt.title("Original Quality Distribution")
# y축 기준 격자선을 표시하여 막대 높이를 보기 쉽게 합니다.
plt.grid(axis="y")
# 그래프를 출력합니다.
plt.show()원본 quality 분포:
quality
3 10
4 53
5 681
6 638
7 199
8 18
Name: count, dtype: int64
이제 3개 등급으로 ㅕㄴ환해보자.
# ============================================================
# quality 점수를 3개 등급으로 변환
# ============================================================
# 원본 quality는 3~8 사이의 숫자 점수입니다.
# 실무 분류 문제로 만들기 위해 품질 점수를 3개 클래스로 변환합니다.
# 0: low, 1: medium, 2: high
def convert_quality_to_class(q):
# quality가 4 이하이면 저품질(low)로 분류합니다.
# 낮은 품질 점수는 데이터 수가 적을 수 있으므로 클래스 불균형을 주의해야 합니다.
if q <= 4:
return 0
# quality가 5 또는 6이면 중간품질(medium)로 분류합니다.
# 실제 Wine Quality 데이터에서는 5와 6에 데이터가 많이 몰려 있습니다.
elif q <= 6:
return 1
# quality가 7 이상이면 고품질(high)로 분류합니다.
else:
return 2
# apply()는 quality 컬럼의 각 값에 convert_quality_to_class 함수를 적용합니다.
# 결과는 새 컬럼 quality_class에 저장합니다.
df["quality_class"] = df["quality"].apply(convert_quality_to_class)
# 변환된 클래스별 데이터 개수를 확인합니다.
# 클래스 분포가 지나치게 불균형하면 accuracy만으로 모델을 평가하면 안 됩니다.
print("변환된 quality_class 분포:")
print(df["quality_class"].value_counts().sort_index())
# 원본 quality와 변환된 quality_class가 어떻게 대응되는지 일부 행을 확인합니다.
df[["quality", "quality_class"]].head(10)변환된 quality_class 분포:
quality_class
0 63
1 1319
2 217
Name: count, dtype: int64quality quality_class
0 5 1
1 5 1
2 5 1
3 6 1
4 5 1
5 5 1
6 5 1
7 7 2
8 7 2
9 5 1
x에는 quality, quality_class를 제외한 특성을 y는 quality를 넣는다.
# ============================================================
# 입력 변수 X와 목표 변수 y 분리
# ============================================================
# 머신러닝 모델은 입력 데이터 X와 정답 데이터 y를 분리해서 사용합니다.
# quality는 원본 점수이고, quality_class는 변환된 정답 클래스입니다.
# 두 컬럼 모두 정답과 직접 관련되어 있으므로 입력 변수에서 제외해야 합니다.
# 만약 quality를 입력에 포함하면 정답 정보를 모델에 알려주는 데이터 누수가 발생합니다.
X = df.drop(columns=["quality", "quality_class"])
# y에는 모델이 예측해야 할 정답인 quality_class를 넣습니다.
y = df["quality_class"]
# 입력 변수 이름을 리스트로 저장합니다.
# 나중에 어떤 변수가 사용되었는지 확인하거나 중요도를 해석할 때 필요합니다.
feature_names = X.columns.tolist()
# 입력 변수 개수를 출력합니다.
print("입력 변수 개수:", X.shape[1])
# 입력 변수 목록을 출력합니다.
print("입력 변수 목록:", feature_names)
# 목표 클래스 종류를 출력합니다.
print("목표 클래스:", sorted(y.unique()))
학습데이터와 테스트 데이터를 분리한다.
데이터를 표준화한다.
# ============================================================
# 학습 데이터와 테스트 데이터 분리
# ============================================================
# train_test_split()은 전체 데이터를 학습 데이터와 테스트 데이터로 나눕니다.
# 학습 데이터는 모델을 학습시키는 데 사용하고,
# 테스트 데이터는 학습이 끝난 뒤 모델 성능을 평가하는 데 사용합니다.
X_train, X_test, y_train, y_test = train_test_split(
X, # 입력 변수 전체
y, # 정답 클래스
test_size=0.2, # 전체 데이터의 20%를 테스트 데이터로 사용
random_state=SEED, # 항상 같은 방식으로 분리되도록 랜덤 시드 고정
stratify=y # 클래스 비율을 학습/테스트 데이터에 비슷하게 유지
)
# 분리된 데이터 크기를 확인합니다.
# X_train과 y_train의 행 수가 같아야 합니다.
# X_test와 y_test의 행 수도 같아야 합니다.
print("X_train:", X_train.shape)
print("X_test:", X_test.shape)
print("y_train:", y_train.shape)
print("y_test:", y_test.shape)# ============================================================
# 데이터 표준화
# ============================================================
# StandardScaler는 각 입력 변수의 평균을 0, 표준편차를 1로 변환합니다.
# 공식:
# z = (x - 평균) / 표준편차
#
# 차원 축소 알고리즘에서 표준화가 중요한 이유:
# - PCA는 분산이 큰 방향을 찾기 때문에 값의 단위가 큰 변수가 과도하게 영향력을 가질 수 있습니다.
# - LDA도 거리와 분산 구조를 사용하므로 변수 스케일 차이가 결과에 영향을 줄 수 있습니다.
# - t-SNE, UMAP도 거리 기반 이웃 관계를 사용하므로 표준화가 중요합니다.
scaler = StandardScaler()
# 학습 데이터에는 fit_transform()을 사용합니다.
# fit 단계: 학습 데이터의 평균과 표준편차를 계산합니다.
# transform 단계: 계산된 평균과 표준편차를 이용해 학습 데이터를 변환합니다.
X_train_scaled = scaler.fit_transform(X_train)
# 테스트 데이터에는 transform()만 사용합니다.
# 테스트 데이터에서 평균과 표준편차를 새로 계산하면 테스트 데이터 정보가 전처리에 섞이는 데이터 누수가 발생합니다.
X_test_scaled = scaler.transform(X_test)
# 표준화가 잘 되었는지 평균과 표준편차를 확인합니다.
print("표준화 후 학습 데이터 평균:", round(X_train_scaled.mean(), 4))
print("표준화 후 학습 데이터 표준편차:", round(X_train_scaled.std(), 4))
randomforestclassifier 객체를 만들어 decision tree를 학습한다
축소전 데이터 기준 성능을 확인해보고자한다 .
fit. 이후 predict. accuracy_score 출력.
# ============================================================
# 원본 데이터 기준 Random Forest 모델 학습
# ============================================================
# RandomForestClassifier는 여러 개의 Decision Tree를 학습한 뒤,
# 그 결과를 투표 방식으로 결합하는 앙상블 분류 모델입니다.
# 여기서는 차원 축소 전 원본 데이터 기준 성능을 확인하기 위해 사용합니다.
baseline_rf = RandomForestClassifier(
n_estimators=300, # 만들 의사결정나무 개수입니다. 많을수록 안정적이지만 학습 시간이 늘어납니다.
random_state=SEED, # 결과 재현성을 위한 랜덤 시드입니다.
class_weight="balanced" # 클래스별 데이터 수가 다를 때 소수 클래스에 더 큰 가중치를 줍니다.
)
# fit()은 모델을 학습시키는 함수입니다.
# X_train_scaled: 표준화된 학습 입력 데이터
# y_train: 학습 정답 데이터
baseline_rf.fit(X_train_scaled, y_train)
# predict()는 학습된 모델로 테스트 데이터의 클래스를 예측합니다.
baseline_pred = baseline_rf.predict(X_test_scaled)
# accuracy_score()는 전체 테스트 데이터 중 예측이 맞은 비율을 계산합니다.
baseline_acc = accuracy_score(y_test, baseline_pred)
print("원본 데이터 기준 Random Forest 정확도:", round(baseline_acc, 4))
print()
# classification_report()는 클래스별 precision, recall, f1-score를 출력합니다.
# 클래스 불균형이 있는 경우 accuracy만 보는 것보다 이 지표들을 함께 보는 것이 좋습니다.
print(classification_report(y_test, baseline_pred, target_names=["low", "medium", "high"])).
원본 데이터 기준 Random Forest 정확도: 0.8781
precision recall f1-score support
low 0.00 0.00 0.00 13
medium 0.90 0.96 0.93 264
high 0.75 0.63 0.68 43
accuracy 0.88 320
macro avg 0.55 0.53 0.54 320
weighted avg 0.84 0.88 0.86 320
현 기준 logistic regression 모델을 학습해보자 .
logisticregression 객체를 만들어 또 fit, predict, accuray_score
및 출력.
# ============================================================
# 원본 데이터 기준 Logistic Regression 모델 학습
# ============================================================
# LogisticRegression은 선형 분류 모델입니다.
# 데이터가 선형 경계로 어느 정도 분리되는지 확인할 때 기준 모델로 사용하기 좋습니다.
baseline_lr = LogisticRegression(
max_iter=2000, # 최적화 반복 횟수입니다. 작으면 수렴하지 않을 수 있어 넉넉하게 지정합니다.
random_state=SEED, # 결과 재현성을 위한 랜덤 시드입니다.
class_weight="balanced" # 클래스 불균형을 보정합니다.
)
# 표준화된 원본 데이터로 Logistic Regression을 학습합니다.
baseline_lr.fit(X_train_scaled, y_train)
# 테스트 데이터를 예측합니다.
baseline_lr_pred = baseline_lr.predict(X_test_scaled)
# 정확도를 계산합니다.
baseline_lr_acc = accuracy_score(y_test, baseline_lr_pred)
print("원본 데이터 기준 Logistic Regression 정확도:", round(baseline_lr_acc, 4))
print()
# 클래스별 성능 지표를 출력합니다.
print(classification_report(y_test, baseline_lr_pred, target_names=["low", "medium", "high"]))원본 데이터 기준 Logistic Regression 정확도: 0.5875
precision recall f1-score support
low 0.15 0.77 0.25 13
medium 0.96 0.54 0.69 264
high 0.34 0.81 0.48 43
accuracy 0.59 320
macro avg 0.48 0.71 0.47 320
weighted avg 0.84 0.59 0.65 320
Logistric은 회귀가 들어가지만 분류모델로 직선하나로 구분 가능한 경우 성능이 좋다했다 .
random forest는 여러개 결정트리를 가진 앙상블 모델로 변수간 복잡한 관계학습이 가능하다했다 .
Wine 데이터셋이니 알코올함량, 색상강도, 폴라보노이드 등 여러 특성이 복합적으로 영향을 주니 randomforest가 유리함을 확인했다 .
PCA 객체를 만들어 마찬지로 fit_transform, transfrom
데이터 차원을 확인하고 누적설명 분산비율이 낮으면 정보손실이 크다는 말이다 .
# ============================================================
# PCA 2차원 변환
# ============================================================
# PCA(Principal Component Analysis)는 주성분 분석입니다.
# 정답 라벨 y를 사용하지 않고, 입력 데이터 X의 분산 구조만 사용합니다.
# 즉, PCA는 비지도학습 기반 차원 축소 알고리즘입니다.
# n_components=2는 원본 11차원 입력 데이터를 2개의 주성분으로 줄이겠다는 의미입니다.
# 2차원으로 줄이면 산점도 그래프로 시각화할 수 있습니다.
pca_2d = PCA(n_components=2, random_state=SEED)
# fit_transform()은 두 가지 작업을 동시에 수행합니다.
# 1. fit: 학습 데이터에서 분산이 가장 큰 방향, 즉 주성분 축을 찾습니다.
# 2. transform: 원본 데이터를 찾은 주성분 축 위로 투영하여 2차원 값으로 변환합니다.
#
# PCA의 핵심:
# - PC1: 데이터 분산을 가장 많이 설명하는 첫 번째 축
# - PC2: PC1과 직교하면서 그 다음으로 분산을 많이 설명하는 두 번째 축
X_train_pca_2d = pca_2d.fit_transform(X_train_scaled)
# 테스트 데이터는 transform()만 사용합니다.
# 학습 데이터에서 찾은 PCA 축을 기준으로 테스트 데이터를 2차원으로 변환합니다.
# 테스트 데이터에 fit_transform()을 사용하면 데이터 누수가 발생할 수 있습니다.
X_test_pca_2d = pca_2d.transform(X_test_scaled)
# PCA 적용 전후의 데이터 차원을 확인합니다.
print("PCA 적용 전:", X_train_scaled.shape)
print("PCA 2D 적용 후:", X_train_pca_2d.shape)
# explained_variance_ratio_는 각 주성분이 원본 데이터의 정보를 얼마나 설명하는지 나타냅니다.
# 예를 들어 PC1 설명 분산 비율이 0.28이면 PC1 하나가 전체 정보의 약 28%를 설명한다는 의미입니다.
print("PC1 설명 분산 비율:", round(pca_2d.explained_variance_ratio_[0], 4))
print("PC2 설명 분산 비율:", round(pca_2d.explained_variance_ratio_[1], 4))
# PC1과 PC2가 함께 설명하는 정보 비율입니다.
# 이 값이 낮으면 2차원으로 줄일 때 정보 손실이 크다는 뜻입니다.
print("누적 설명 분산 비율:", round(pca_2d.explained_variance_ratio_.sum(), 4))PCA 적용 전: (1279, 11)
PCA 2D 적용 후: (1279, 2)
PC1 설명 분산 비율: 0.2806
PC2 설명 분산 비율: 0.1755
누적 설명 분산 비율: 0.4561
시각화해보자.
PCA는 기본적인 역할을해 그룹핑에는 약하다고 했다.
# ============================================================
# PCA 2차원 시각화
# ============================================================
# PCA로 축소된 2차원 데이터는 x축 PC1, y축 PC2로 시각화할 수 있습니다.
# 이 그래프를 통해 클래스가 어느 정도 분리되는지 눈으로 확인할 수 있습니다.
plt.figure(figsize=(8, 6))
# plt.scatter()는 산점도를 그리는 함수입니다.
# X_train_pca_2d[:, 0]은 첫 번째 주성분 PC1 값입니다.
# X_train_pca_2d[:, 1]은 두 번째 주성분 PC2 값입니다.
# c=y_train은 정답 클래스에 따라 점 색상을 다르게 표시합니다.
scatter = plt.scatter(
X_train_pca_2d[:, 0],
X_train_pca_2d[:, 1],
c=y_train,
cmap="viridis",
alpha=0.7,
s=25
)
# 색상 막대를 추가하여 색이 어떤 클래스를 의미하는지 표시합니다.
plt.colorbar(scatter, label="quality_class")
# x축 이름을 설정합니다.
plt.xlabel("Principal Component 1")
# y축 이름을 설정합니다.
plt.ylabel("Principal Component 2")
# 그래프 제목을 설정합니다.
plt.title("PCA 2D Visualization - Wine Quality")
# 격자선을 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()
PCA에서는 주성분 개수를 몇개로 정할지가 중요하다 .너무 적으면 손실이 크고 많으면 차원축소효과가 없다.
PCA 에 입력변수갯수만큼을 n_comments 주성분의 갯수를 설정해보자 .
fit()
np.cumsum은 누적합을 계산한다. 주성분별 분산 비율 확인
표로도 확인.
# ============================================================
# PCA 누적 설명 분산 확인
# ============================================================
# PCA에서는 주성분 개수를 몇 개로 정할지가 중요합니다.
# 너무 적게 선택하면 정보 손실이 크고,
# 너무 많이 선택하면 차원 축소 효과가 작아집니다.
# n_components를 입력 변수 개수만큼 설정합니다.
# 이 데이터는 입력 변수가 11개이므로 최대 11개의 주성분을 만들 수 있습니다.
pca_full = PCA(n_components=X_train_scaled.shape[1], random_state=SEED)
# fit()은 PCA 주성분 축을 학습합니다.
# 여기서는 변환보다 각 주성분의 설명 분산 비율을 확인하는 것이 목적입니다.
pca_full.fit(X_train_scaled)
# explained_variance_ratio_는 주성분별 설명 분산 비율입니다.
# np.cumsum()은 누적합을 계산합니다.
# 예: [0.28, 0.17, 0.14] → [0.28, 0.45, 0.59]
cumulative_variance = np.cumsum(pca_full.explained_variance_ratio_)
# 주성분 개수별 누적 설명 분산 비율을 표로 정리합니다.
# 이 표를 보고 몇 개의 주성분을 사용할지 결정할 수 있습니다.
pca_variance_df = pd.DataFrame({
"component_count": np.arange(1, len(cumulative_variance) + 1),
"cumulative_explained_variance": cumulative_variance
})
pca_variance_dfcomponent_count cumulative_explained_variance
0 1 0.280557
1 2 0.456066
2 3 0.598114
3 4 0.705398
4 5 0.794076
5 6 0.854157
6 7 0.908541
7 8 0.949095
8 9 0.978798
9 10 0.994845
10 11 1.000000* 11개이니 정보손실이 1 로 없다. 확인해보니 7정도면 90%정도이니 7정도로 set해야될것같다고 유추할 수 있다.
차원을 대강 7개정도로 줄이면 될듯 한데 어떻게 결정할지를 알아보기 위해 그래프로 확인해보자 .
axhline으로 90%정도에 기준선을 표시해보자.
# ============================================================
# PCA 누적 설명 분산 그래프
# ============================================================
# 그래프 크기를 설정합니다.
plt.figure(figsize=(8, 5))
# x축: 주성분 개수
# y축: 누적 설명 분산 비율
# 이 그래프는 차원을 몇 개로 줄일지 결정하는 데 사용합니다.
plt.plot(
pca_variance_df["component_count"],
pca_variance_df["cumulative_explained_variance"],
marker="o"
)
# 누적 설명 분산 90% 기준선을 표시합니다.
# 실무에서는 보통 80~95% 정도의 정보를 유지하는 주성분 개수를 선택합니다.
plt.axhline(y=0.90, linestyle="--", label="90% variance")
# x축 이름입니다.
plt.xlabel("Number of PCA components")
# y축 이름입니다.
plt.ylabel("Cumulative explained variance")
# 그래프 제목입니다.
plt.title("PCA Cumulative Explained Variance")
# 범례를 표시합니다.
plt.legend()
# 격자선을 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()
6을 기준으로 분류모델을 다시 학습해보자.
fit_transform, transform,
축소된 데이터에 random forest를 학습시키자 .
정확도도 계산.
# ============================================================
# PCA 차원 축소 후 분류 모델 학습
# ============================================================
# PCA를 실제 모델 학습 전처리로 사용합니다.
# 여기서는 원본 11차원 데이터를 6차원으로 줄입니다.
# 차원을 줄이면 계산량이 줄고, 일부 노이즈가 제거될 수 있습니다.
pca_model = PCA(n_components=6, random_state=SEED)
# 학습 데이터에 대해 PCA 축을 찾고 6차원으로 변환합니다.
X_train_pca = pca_model.fit_transform(X_train_scaled)
# 테스트 데이터는 학습 데이터에서 찾은 PCA 축을 기준으로 6차원으로 변환합니다.
X_test_pca = pca_model.transform(X_test_scaled)
# 6개 주성분이 원본 데이터 정보를 얼마나 보존하는지 확인합니다.
print("PCA 6차원 누적 설명 분산:", round(pca_model.explained_variance_ratio_.sum(), 4))
# PCA로 축소된 데이터에 Random Forest를 학습합니다.
# 원본 데이터 성능과 비교하여 차원 축소가 성능에 어떤 영향을 주는지 확인합니다.
rf_pca = RandomForestClassifier(
n_estimators=300,
random_state=SEED,
class_weight="balanced"
)
# PCA 변환된 학습 데이터로 모델을 학습합니다.
rf_pca.fit(X_train_pca, y_train)
# PCA 변환된 테스트 데이터로 예측합니다.
pca_pred = rf_pca.predict(X_test_pca)
# 정확도를 계산합니다.
pca_acc = accuracy_score(y_test, pca_pred)
print("PCA 6차원 Random Forest 정확도:", round(pca_acc, 4))
print()
# 클래스별 성능을 출력합니다.
print(classification_report(y_test, pca_pred, target_names=["low", "medium", "high"]))PCA 6차원 누적 설명 분산: 0.8542
PCA 6차원 Random Forest 정확도: 0.8625
precision recall f1-score support
low 0.00 0.00 0.00 13
medium 0.88 0.97 0.92 264
high 0.70 0.49 0.58 43
accuracy 0.86 320
macro avg 0.53 0.48 0.50 320
weighted avg 0.82 0.86 0.84 320
/usr/local/lib/python3.12/dist-packages/sklearn/metrics/_classification.py:1565: UndefinedMetricWarning: Precision is ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, f"{metric.capitalize()} is", len(result))
/usr/local/lib/python3.12/dist-packages/sklearn/metrics/_classification.py:1565: UndefinedMetricWarning: Precision is ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, f"{metric.capitalize()} is", len(result))
/usr/local/lib/python3.12/dist-packages/sklearn/metrics/_classification.py:1565: UndefinedMetricWarning: Precision is ill-defined and being set to 0.0 in labels with no predicted samples. Use `zero_division` parameter to control this behavior.
_warn_prf(average, modifier, f"{metric.capitalize()} is", len(result))* 아까 원본데이터로했을때 r.f는 87% 이었다. 차원축소후 확인해보니 86% 꽤 괜찮은 값이다!
LDA도 해보자.
PCA는 분산방향을 찾는다면 LDA는 클래스를 잘 구분한다고 했다.
현재 크래스는 3개이니 최대자원은 2가 되겠다.
linearDiscriminananalysis객체를 만들어 차원 축소.
fit_transform, transform
# ============================================================
# LDA 2차원 변환
# ============================================================
# LDA(Linear Discriminant Analysis)는 선형 판별 분석입니다.
# PCA와 달리 정답 라벨 y를 사용합니다.
#
# PCA의 목적:
# - 데이터의 분산이 큰 방향을 찾음
#
# LDA의 목적:
# - 클래스들이 가장 잘 분리되는 방향을 찾음
#
# 현재 클래스는 low, medium, high 총 3개입니다.
# LDA가 만들 수 있는 최대 차원은 클래스 수 - 1입니다.
# 따라서 3개 클래스에서는 최대 2차원까지 축소할 수 있습니다.
lda_2d = LinearDiscriminantAnalysis(n_components=2)
# LDA는 지도학습 기반 차원 축소이므로 fit_transform()에 X뿐 아니라 y_train도 함께 넣습니다.
# y_train을 사용하여 클래스 간 분산은 크게, 클래스 내부 분산은 작게 만드는 축을 찾습니다.
X_train_lda_2d = lda_2d.fit_transform(X_train_scaled, y_train)
# 테스트 데이터는 학습 데이터에서 찾은 LDA 축을 기준으로 변환합니다.
X_test_lda_2d = lda_2d.transform(X_test_scaled)
# LDA 적용 전후 차원을 확인합니다.
print("LDA 적용 전:", X_train_scaled.shape)
print("LDA 적용 후:", X_train_lda_2d.shape)
시각화 scatter해보자.
분류에 강한 LDA이니 PCA보다 훨 나을것이라고 예상이 된다 .
# ============================================================
# LDA 2차원 시각화
# ============================================================
# LDA는 클래스 구분이 잘 되는 방향을 찾으므로,
# PCA보다 클래스 분리 시각화가 더 명확할 수 있습니다.
plt.figure(figsize=(8, 6))
# x축은 첫 번째 선형 판별 축 LD1입니다.
# y축은 두 번째 선형 판별 축 LD2입니다.
# 점 색상은 실제 품질 클래스입니다.
scatter = plt.scatter(
X_train_lda_2d[:, 0],
X_train_lda_2d[:, 1],
c=y_train,
cmap="viridis",
alpha=0.7,
s=25
)
# 색상과 클래스의 대응 관계를 표시합니다.
plt.colorbar(scatter, label="quality_class")
# x축 이름입니다.
plt.xlabel("LD1")
# y축 이름입니다.
plt.ylabel("LD2")
# 그래프 제목입니다.
plt.title("LDA 2D Visualization - Wine Quality")
# 격자선을 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()
차원이 축소되었으니 이제 randomforest 모델로 학습해보자.
randomforestclassfier 객체를 만들어 fit, predict, accuracy_score확인.
# ============================================================
# LDA 차원 축소 후 분류 모델 학습
# ============================================================
# LDA로 변환된 2차원 데이터를 사용해 Random Forest 모델을 학습합니다.
# 원본 11차원 데이터를 2차원으로 줄였기 때문에 학습 데이터 크기가 작아졌습니다.
rf_lda = RandomForestClassifier(
n_estimators=300,
random_state=SEED,
class_weight="balanced"
)
# LDA 변환된 학습 데이터로 모델을 학습합니다.
rf_lda.fit(X_train_lda_2d, y_train)
# LDA 변환된 테스트 데이터로 예측합니다.
lda_pred = rf_lda.predict(X_test_lda_2d)
# 정확도를 계산합니다.
lda_acc = accuracy_score(y_test, lda_pred)
print("LDA 2차원 Random Forest 정확도:", round(lda_acc, 4))
print()
# 클래스별 상세 평가 결과를 출력합니다.
print(classification_report(y_test, lda_pred, target_names=["low", "medium", "high"]))LDA 2차원 Random Forest 정확도: 0.8625
precision recall f1-score support
low 0.00 0.00 0.00 13
medium 0.89 0.95 0.92 264
high 0.73 0.56 0.63 43
accuracy 0.86 320
macro avg 0.54 0.50 0.52 320
weighted avg 0.83 0.86 0.84 320정확도는 비슷하다.
로지스틱보다 역시 r.f가 나음.
t-SNE를 사용해보자.
t-SNE는 고차원데이터를 2차원으로 시각화할때 자주사용한다했다 .
시각화목적이니 전체데이터를 사용한다 .fit_transform
TSNE 객체를 만들어 fit_transform
# ============================================================
# t-SNE 2차원 변환
# ============================================================
# t-SNE는 t-distributed Stochastic Neighbor Embedding의 약자입니다.
# 고차원 공간에서 가까운 데이터끼리의 관계를 저차원에서도 유지하려고 합니다.
#
# t-SNE의 주요 목적:
# - 분류 모델 학습용 전처리보다는 시각화
# - 고차원 데이터의 군집 구조 확인
# - 비슷한 샘플들이 실제로 가까이 모이는지 확인
# 시각화 목적이므로 전체 데이터를 사용합니다.
# 단, 실제 모델 평가용 전처리에서는 학습/테스트 분리를 먼저 고려해야 합니다.
X_scaled_all = scaler.fit_transform(X)
# TSNE 객체를 생성합니다.
tsne = TSNE(
n_components=2, # 2차원 좌표로 축소합니다.
perplexity=30, # 각 점이 고려하는 이웃 수의 개념입니다. 보통 5~50 사이를 많이 사용합니다.
learning_rate="auto",# 학습률을 자동 설정합니다.
init="pca", # 초기 배치를 PCA 결과로 시작하여 안정적인 결과를 얻습니다.
random_state=SEED # 재현성을 위한 랜덤 시드입니다.
)
# fit_transform()으로 전체 데이터를 2차원으로 변환합니다.
# t-SNE는 PCA처럼 일반적인 transform() 사용이 어렵기 때문에 주로 전체 데이터 시각화에 사용합니다.
X_tsne = tsne.fit_transform(X_scaled_all)
# 변환 전후 차원을 확인합니다.
print("t-SNE 적용 전:", X_scaled_all.shape)
print("t-SNE 적용 후:", X_tsne.shape)
scatter 시각화
# ============================================================
# t-SNE 시각화
# ============================================================
# t-SNE 결과는 2차원 좌표입니다.
# x축과 y축 자체에 물리적인 의미가 있는 것은 아닙니다.
# 중요한 것은 점들 사이의 가까움과 군집 구조입니다.
plt.figure(figsize=(8, 6))
# X_tsne[:, 0]은 t-SNE가 만든 첫 번째 2차원 좌표입니다.
# X_tsne[:, 1]은 두 번째 좌표입니다.
# c=y는 실제 품질 클래스에 따라 색상을 다르게 표시합니다.
scatter = plt.scatter(
X_tsne[:, 0],
X_tsne[:, 1],
c=y,
cmap="viridis",
alpha=0.7,
s=25
)
# 색상 막대를 표시합니다.
plt.colorbar(scatter, label="quality_class")
# x축 이름입니다.
plt.xlabel("t-SNE 1")
# y축 이름입니다.
plt.ylabel("t-SNE 2")
# 그래프 제목입니다.
plt.title("t-SNE 2D Visualization - Wine Quality")
# 격자선을 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()
훔 뭔가 점이 잘 보이게는 됫다 하지만 잘 분류되보이지는 않는다. 청록색이 특히 전영역에 섞여있다.
UMAP을 확인해보자. t-sne와 유사한 방식으로 고차원 임베딩에서 데이터시각화 대용량 데이터 시각화에 자주 사용된다고 했다 .
umap.UMAP 객체를 만들어 fit_transform, 그리고 시각화
# ============================================================
# UMAP 2차원 변환
# ============================================================
# UMAP은 Uniform Manifold Approximation and Projection의 약자입니다.
# t-SNE처럼 비선형 차원 축소와 시각화에 많이 사용됩니다.
#
# UMAP의 특징:
# - 고차원 데이터의 이웃 관계를 보존하려고 함
# - t-SNE보다 빠른 경우가 많음
# - 2차원 시각화뿐 아니라 임베딩 축소에도 사용 가능
# UMAP 객체를 생성합니다.
umap_model = umap.UMAP(
n_components=2, # 2차원으로 축소합니다.
n_neighbors=15, # 각 데이터가 주변 이웃을 몇 개까지 고려할지 정합니다.
# 값이 작으면 지역 구조를 더 강조하고, 값이 크면 전체 구조를 더 반영합니다.
min_dist=0.1, # 저차원 공간에서 점들이 얼마나 가까이 모일 수 있는지를 조절합니다.
# 값이 작으면 군집이 더 조밀하게 모일 수 있습니다.
random_state=SEED # 재현성을 위한 랜덤 시드입니다.
)
# fit_transform()으로 전체 데이터를 2차원 UMAP 좌표로 변환합니다.
# X_scaled_all은 표준화된 전체 입력 데이터입니다.
X_umap = umap_model.fit_transform(X_scaled_all)
# 변환 전후 차원을 확인합니다.
print("UMAP 적용 전:", X_scaled_all.shape)
print("UMAP 적용 후:", X_umap.shape)# ============================================================
# UMAP 시각화
# ============================================================
# UMAP 결과를 2차원 산점도로 표시합니다.
# t-SNE와 마찬가지로 x축, y축 자체의 의미보다는 점들의 배치와 군집 구조를 해석합니다.
plt.figure(figsize=(8, 6))
scatter = plt.scatter(
X_umap[:, 0], # UMAP 첫 번째 좌표
X_umap[:, 1], # UMAP 두 번째 좌표
c=y, # 실제 품질 클래스로 색상 지정
cmap="viridis",
alpha=0.7,
s=25
)
# 색상 막대를 표시합니다.
plt.colorbar(scatter, label="quality_class")
# x축 이름입니다.
plt.xlabel("UMAP 1")
# y축 이름입니다.
plt.ylabel("UMAP 2")
# 그래프 제목입니다.
plt.title("UMAP 2D Visualization - Wine Quality")
# 격자선을 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()
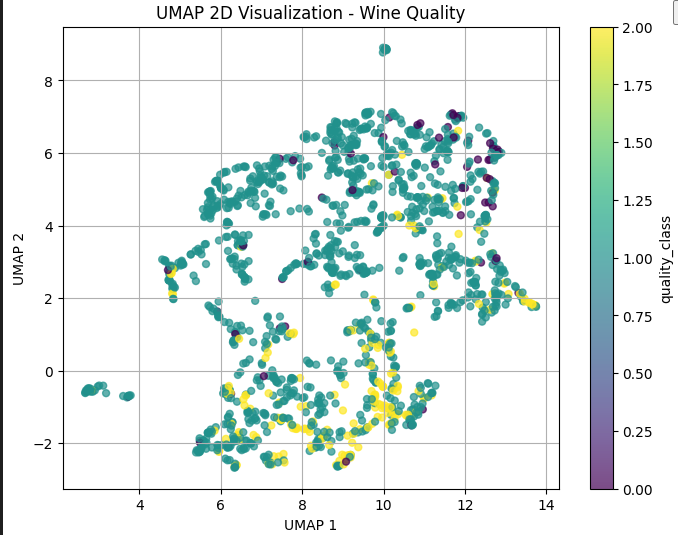
autoencoder도 적용해보자. 이것은 압축한뒤 다시 복원하도록 학습한다고 했따.
tensor 변환후 tenserDataset입력과 정답을 묶어 dataloader를 거친다.
# ============================================================
# Autoencoder 데이터 준비
# ============================================================
# Autoencoder는 입력 데이터를 압축한 뒤 다시 원본처럼 복원하도록 학습하는 신경망입니다.
# 일반 분류 모델은 X와 y가 다르지만,
# Autoencoder는 입력 X 자체를 정답으로 사용합니다.
#
# 즉, 학습 목표는 다음과 같습니다.
# 입력 X → Encoder로 압축 → Decoder로 복원 → 원본 X와 최대한 비슷하게 만들기
# numpy 배열인 X_train_scaled를 PyTorch Tensor로 변환합니다.
# dtype=torch.float32는 신경망 학습에 적합한 32비트 실수형입니다.
X_train_ae = torch.tensor(X_train_scaled, dtype=torch.float32)
# 테스트 데이터도 Tensor로 변환합니다.
X_test_ae = torch.tensor(X_test_scaled, dtype=torch.float32)
# TensorDataset은 입력과 정답을 하나로 묶어줍니다.
# Autoencoder에서는 입력과 정답이 모두 같은 X입니다.
train_dataset = TensorDataset(X_train_ae, X_train_ae)
test_dataset = TensorDataset(X_test_ae, X_test_ae)
# DataLoader는 데이터를 batch 단위로 나누어 모델에 공급합니다.
# batch_size=64는 한 번에 64개 샘플씩 학습한다는 의미입니다.
# shuffle=True는 매 epoch마다 학습 데이터 순서를 섞어 학습 안정성을 높입니다.
train_loader = DataLoader(
train_dataset,
batch_size=64,
shuffle=True
)
# 테스트 데이터는 평가용이므로 순서를 섞을 필요가 없습니다.
test_loader = DataLoader(
test_dataset,
batch_size=64,
shuffle=False
)
# Autoencoder 학습에 사용할 Tensor 크기를 확인합니다.
print("Autoencoder 학습 데이터:", X_train_ae.shape)
print("Autoencoder 테스트 데이터:", X_test_ae.shape)
wineautoencoder 함수를 설정하자 .
nn.Module를 상속받아 sequential로 신경망을 정렬한다 .decoder도 정의해 encoder, decoder를나열해 forward 함수를 정의한다.
# ============================================================
# Autoencoder 모델 정의
# ============================================================
# Autoencoder는 크게 Encoder와 Decoder로 구성됩니다.
#
# Encoder:
# - 원본 입력 데이터를 더 작은 차원의 잠재 벡터로 압축합니다.
#
# Decoder:
# - 압축된 잠재 벡터를 다시 원본 입력 형태로 복원합니다.
#
# 여기서는 11차원 와인 특성 데이터를 2차원 잠재 벡터로 압축합니다.
class WineAutoencoder(nn.Module):
def __init__(self, input_dim):
# nn.Module 부모 클래스의 초기화 함수를 실행합니다.
super(WineAutoencoder, self).__init__()
# ----------------------------------------------------
# Encoder 정의
# ----------------------------------------------------
# Encoder는 차원을 점점 줄입니다.
# input_dim → 8 → 4 → 2
# 마지막 2차원 출력이 차원 축소된 표현입니다.
self.encoder = nn.Sequential(
# 첫 번째 선형 계층입니다.
# input_dim은 입력 변수 개수입니다. 이 데이터에서는 11입니다.
# 11차원 데이터를 8차원으로 변환합니다.
nn.Linear(input_dim, 8),
# ReLU 활성화 함수입니다.
# 선형 변환만 반복하면 복잡한 비선형 구조를 학습할 수 없으므로 활성화 함수를 사용합니다.
nn.ReLU(),
# 두 번째 선형 계층입니다.
# 8차원 데이터를 4차원으로 줄입니다.
nn.Linear(8, 4),
# 다시 ReLU를 적용하여 비선형 표현력을 추가합니다.
nn.ReLU(),
# 마지막 Encoder 계층입니다.
# 4차원 데이터를 최종 2차원 잠재 벡터로 압축합니다.
# 이 2차원 값이 Autoencoder 방식의 차원 축소 결과입니다.
nn.Linear(4, 2)
)
# ----------------------------------------------------
# Decoder 정의
# ----------------------------------------------------
# Decoder는 Encoder와 반대로 차원을 점점 늘립니다.
# 2 → 4 → 8 → input_dim
# 최종 출력은 원본 입력 데이터와 같은 11차원입니다.
self.decoder = nn.Sequential(
# 2차원 잠재 벡터를 4차원으로 확장합니다.
nn.Linear(2, 4),
nn.ReLU(),
# 4차원 데이터를 8차원으로 확장합니다.
nn.Linear(4, 8),
nn.ReLU(),
# 8차원 데이터를 원본 입력 차원으로 복원합니다.
nn.Linear(8, input_dim)
)
def forward(self, x):
# 입력 x를 Encoder에 넣어 2차원 잠재 벡터 z로 압축합니다.
z = self.encoder(x)
# 잠재 벡터 z를 Decoder에 넣어 원본 차원으로 복원합니다.
reconstructed = self.decoder(z)
# 복원 결과와 잠재 벡터를 함께 반환합니다.
# reconstructed: 원본과 비교할 복원 데이터
# z: 차원 축소된 2차원 표현
return reconstructed, z
# 입력 변수 개수입니다.
# Wine Quality 데이터에서는 11개의 화학적 특성이 입력 변수입니다.
input_dim = X_train_scaled.shape[1]
# Autoencoder 모델 객체를 생성하고 CPU 또는 GPU 장치로 이동합니다.
ae_model = WineAutoencoder(input_dim).to(device)
# 모델 구조를 출력합니다.
print(ae_model)
MELoss 객체를 만들고 optim.adam를 사용해 epochs 150 만큼 학습시켜보자.
# ============================================================
# Autoencoder 학습 설정
# ============================================================
# MSELoss는 평균제곱오차 손실 함수입니다.
# Autoencoder에서는 원본 입력과 복원 결과가 얼마나 다른지 계산합니다.
#
# MSE가 작을수록:
# - 복원 결과가 원본과 비슷함
# - Encoder가 원본 정보를 잘 압축했다는 의미
criterion = nn.MSELoss()
# Adam은 딥러닝에서 자주 사용하는 최적화 알고리즘입니다.
# optimizer는 손실을 줄이도록 모델의 가중치를 업데이트합니다.
optimizer = optim.Adam(
ae_model.parameters(), # 학습할 모델 파라미터
lr=0.001 # 학습률입니다. 값이 너무 크면 불안정하고, 너무 작으면 학습이 느립니다.
)
# 전체 학습 반복 횟수입니다.
# epoch는 전체 학습 데이터를 한 번 모두 학습하는 단위입니다.
epochs = 150
# epoch별 학습 손실과 테스트 손실을 저장할 리스트입니다.
train_losses = []
test_losses = []
print("Autoencoder 학습 설정 완료")
eval() 학습시작.
손실계산 및 누적해 리스트에 저장한다.
# ============================================================
# Autoencoder 학습 루프
# ============================================================
# epochs만큼 전체 데이터를 반복 학습합니다.
for epoch in range(epochs):
# --------------------------------------------------------
# 1. 학습 모드 설정
# --------------------------------------------------------
# train()은 모델을 학습 모드로 전환합니다.
# Dropout, BatchNorm 같은 계층이 있을 경우 학습 방식으로 동작합니다.
ae_model.train()
# 한 epoch 동안의 학습 손실 합계를 저장할 변수입니다.
train_loss_sum = 0.0
# train_loader에서 batch 단위로 데이터를 꺼냅니다.
# batch_X: 입력 데이터
# batch_y: 복원 목표 데이터
# Autoencoder에서는 batch_X와 batch_y가 같은 데이터입니다.
for batch_X, batch_y in train_loader:
# 데이터를 현재 장치로 이동합니다.
# GPU가 있으면 GPU로, 없으면 CPU로 이동합니다.
batch_X = batch_X.to(device)
batch_y = batch_y.to(device)
# 이전 batch에서 계산된 gradient를 초기화합니다.
# PyTorch는 gradient를 누적하므로 매 batch마다 반드시 초기화해야 합니다.
optimizer.zero_grad()
# Autoencoder에 입력 데이터를 넣습니다.
# reconstructed: Decoder가 복원한 결과
# z: Encoder가 만든 2차원 잠재 벡터
reconstructed, z = ae_model(batch_X)
# 원본 데이터 batch_y와 복원 데이터 reconstructed의 차이를 계산합니다.
# 이 손실이 작아질수록 복원 성능이 좋아집니다.
loss = criterion(reconstructed, batch_y)
# 역전파를 수행하여 각 가중치가 손실에 미치는 영향을 계산합니다.
loss.backward()
# optimizer가 계산된 gradient를 사용하여 모델 가중치를 업데이트합니다.
optimizer.step()
# 현재 batch의 손실값을 누적합니다.
train_loss_sum += loss.item()
# 한 epoch의 평균 학습 손실을 계산합니다.
train_loss = train_loss_sum / len(train_loader)
# --------------------------------------------------------
# 2. 평가 모드 설정
# --------------------------------------------------------
# eval()은 모델을 평가 모드로 전환합니다.
# 평가 시에는 가중치를 업데이트하지 않습니다.
ae_model.eval()
# 테스트 손실 합계입니다.
test_loss_sum = 0.0
# torch.no_grad()는 gradient 계산을 비활성화합니다.
# 평가 단계에서는 gradient가 필요 없으므로 메모리 사용량과 계산량을 줄일 수 있습니다.
with torch.no_grad():
for batch_X, batch_y in test_loader:
# 테스트 batch를 장치로 이동합니다.
batch_X = batch_X.to(device)
batch_y = batch_y.to(device)
# 복원 결과와 잠재 벡터를 계산합니다.
reconstructed, z = ae_model(batch_X)
# 테스트 손실을 계산합니다.
loss = criterion(reconstructed, batch_y)
# 테스트 손실을 누적합니다.
test_loss_sum += loss.item()
# 평균 테스트 손실을 계산합니다.
test_loss = test_loss_sum / len(test_loader)
# 그래프 출력을 위해 손실값을 리스트에 저장합니다.
train_losses.append(train_loss)
test_losses.append(test_loss)
# 15 epoch마다 학습 진행 상황을 출력합니다.
# 손실이 계속 감소하면 학습이 잘 진행되고 있다는 의미입니다.
if (epoch + 1) % 15 == 0:
print(
f"Epoch [{epoch+1}/{epochs}] "
f"Train Loss: {train_loss:.6f} "
f"Test Loss: {test_loss:.6f}"
)
학습손실률 그래프 확인해보자.
# ============================================================
# Autoencoder 학습 손실 그래프
# ============================================================
# 학습 과정에서 손실이 어떻게 변하는지 확인합니다.
# Train Loss와 Test Loss가 함께 감소하면 학습이 안정적으로 진행된 것입니다.
# Train Loss만 낮고 Test Loss가 높으면 과적합 가능성이 있습니다.
plt.figure(figsize=(8, 5))
# 학습 손실 그래프입니다.
plt.plot(train_losses, label="Train Loss")
# 테스트 손실 그래프입니다.
plt.plot(test_losses, label="Test Loss")
# x축은 epoch입니다.
plt.xlabel("Epoch")
# y축은 MSE 손실값입니다.
plt.ylabel("MSE Loss")
# 그래프 제목입니다.
plt.title("Autoencoder Reconstruction Loss")
# 범례를 표시합니다.
plt.legend()
# 격자선을 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()
잠재벡터를 확인해 시각화해보자 .
# ============================================================
# Autoencoder 잠재 벡터 추출
# ============================================================
# 전체 데이터를 표준화합니다.
# 주의:
# - 여기서는 전체 데이터 시각화를 위한 목적입니다.
# - 실제 모델 평가에서는 학습 데이터로 fit한 scaler를 테스트 데이터에 transform하는 방식이 더 엄격합니다.
X_all_scaled = scaler.fit_transform(X)
# 전체 데이터를 PyTorch Tensor로 변환하고 현재 장치로 이동합니다.
X_all_tensor = torch.tensor(X_all_scaled, dtype=torch.float32).to(device)
# 모델을 평가 모드로 전환합니다.
ae_model.eval()
# gradient 계산 없이 전체 데이터의 잠재 벡터를 추출합니다.
with torch.no_grad():
# reconstructed_all: 전체 데이터의 복원 결과
# latent_all: Encoder가 만든 2차원 잠재 벡터
reconstructed_all, latent_all = ae_model(X_all_tensor)
# latent_all은 PyTorch Tensor이므로 numpy 배열로 변환합니다.
# cpu()는 GPU에 있는 Tensor를 CPU로 옮기는 함수입니다.
# numpy()는 Tensor를 numpy 배열로 변환하는 함수입니다.
X_ae_2d = latent_all.cpu().numpy()
# Autoencoder 적용 전후 차원을 확인합니다.
print("Autoencoder 적용 전:", X_all_scaled.shape)
print("Autoencoder 2차원 잠재 벡터:", X_ae_2d.shape)# ============================================================
# Autoencoder 2차원 잠재 공간 시각화
# ============================================================
# Autoencoder의 Encoder가 만든 2차원 잠재 벡터를 시각화합니다.
# 이 그래프는 신경망이 데이터를 어떤 방식으로 압축했는지 확인하는 데 사용합니다.
plt.figure(figsize=(8, 6))
scatter = plt.scatter(
X_ae_2d[:, 0], # 잠재 벡터의 첫 번째 차원
X_ae_2d[:, 1], # 잠재 벡터의 두 번째 차원
c=y, # 실제 품질 클래스로 색상을 지정
cmap="viridis",
alpha=0.7,
s=25
)
# 색상 막대를 표시합니다.
plt.colorbar(scatter, label="quality_class")
# x축 이름입니다.
plt.xlabel("Latent Dimension 1")
# y축 이름입니다.
plt.ylabel("Latent Dimension 2")
# 그래프 제목입니다.
plt.title("Autoencoder 2D Latent Space - Wine Quality")
# 격자선을 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()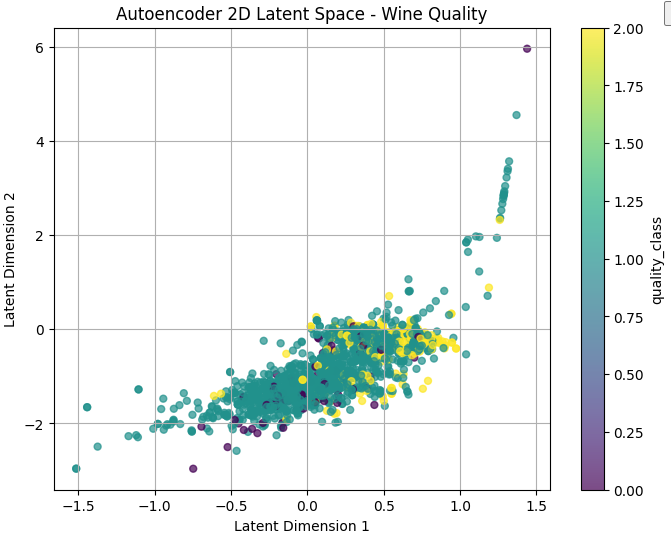
축소된 데이터로 학습
# ============================================================
# Autoencoder 2차원 데이터로 분류 모델 학습
# ============================================================
# 학습 데이터와 테스트 데이터를 Tensor로 변환합니다.
# 이미 표준화된 데이터를 사용합니다.
X_train_tensor_all = torch.tensor(X_train_scaled, dtype=torch.float32).to(device)
X_test_tensor_all = torch.tensor(X_test_scaled, dtype=torch.float32).to(device)
# 모델을 평가 모드로 전환합니다.
ae_model.eval()
# Autoencoder의 Encoder를 이용해 학습/테스트 데이터를 2차원 잠재 벡터로 변환합니다.
with torch.no_grad():
# _는 복원 결과를 사용하지 않겠다는 의미입니다.
# X_train_ae_latent는 학습 데이터의 2차원 잠재 벡터입니다.
_, X_train_ae_latent = ae_model(X_train_tensor_all)
# X_test_ae_latent는 테스트 데이터의 2차원 잠재 벡터입니다.
_, X_test_ae_latent = ae_model(X_test_tensor_all)
# PyTorch Tensor를 numpy 배열로 변환합니다.
X_train_ae_latent = X_train_ae_latent.cpu().numpy()
X_test_ae_latent = X_test_ae_latent.cpu().numpy()
# Autoencoder로 축소된 2차원 데이터를 사용하여 Random Forest를 학습합니다.
# 이 과정은 "딥러닝 기반 차원 축소 + 머신러닝 분류 모델" 구조입니다.
rf_ae = RandomForestClassifier(
n_estimators=300,
random_state=SEED,
class_weight="balanced"
)
# 2차원 잠재 벡터로 모델을 학습합니다.
rf_ae.fit(X_train_ae_latent, y_train)
# 테스트 잠재 벡터로 품질 클래스를 예측합니다.
ae_pred = rf_ae.predict(X_test_ae_latent)
# 정확도를 계산합니다.
ae_acc = accuracy_score(y_test, ae_pred)
print("Autoencoder 2차원 Random Forest 정확도:", round(ae_acc, 4))
print()
# 클래스별 성능을 출력합니다.
print(classification_report(y_test, ae_pred, target_names=["low", "medium", "high"]))Autoencoder 2차원 Random Forest 정확도: 0.85
precision recall f1-score support
low 0.00 0.00 0.00 13
medium 0.87 0.96 0.91 264
high 0.69 0.42 0.52 43
accuracy 0.85 320
macro avg 0.52 0.46 0.48 320
weighted avg 0.81 0.85 0.82 320
위 전체 성능을 비교해보자.
# ============================================================
# 결과 비교표 생성
# ============================================================
# 원본 데이터와 차원 축소 후 데이터의 분류 성능을 비교합니다.
# t-SNE와 UMAP은 주로 시각화용이므로 여기서는 성능 비교표에 포함하지 않습니다.
results = pd.DataFrame({
"method": [
"Original RF", # 원본 11차원 + Random Forest
"Original Logistic Regression", # 원본 11차원 + Logistic Regression
"PCA 6D + RF", # PCA 6차원 + Random Forest
"LDA 2D + RF", # LDA 2차원 + Random Forest
"Autoencoder 2D + RF" # Autoencoder 2차원 + Random Forest
],
"dimension": [
X_train_scaled.shape[1], # 원본 입력 차원 수
X_train_scaled.shape[1], # 원본 입력 차원 수
6, # PCA 축소 후 차원 수
2, # LDA 축소 후 차원 수
2 # Autoencoder 잠재 벡터 차원 수
],
"accuracy": [
baseline_acc, # 원본 Random Forest 정확도
baseline_lr_acc, # 원본 Logistic Regression 정확도
pca_acc, # PCA 후 정확도
lda_acc, # LDA 후 정확도
ae_acc # Autoencoder 후 정확도
]
})
# 정확도를 소수점 4자리로 반올림합니다.
results["accuracy"] = results["accuracy"].round(4)
# 결과표를 출력합니다.
results
비교그래프 출력
# ============================================================
# 결과 비교 그래프
# ============================================================
# 결과 비교표의 accuracy 값을 막대그래프로 시각화합니다.
plt.figure(figsize=(10, 5))
# x축은 방법, y축은 정확도입니다.
plt.bar(results["method"], results["accuracy"])
# 정확도는 0~1 범위이므로 y축 범위를 0~1로 설정합니다.
plt.ylim(0, 1.0)
# x축 이름입니다.
plt.xlabel("Method")
# y축 이름입니다.
plt.ylabel("Accuracy")
# 그래프 제목입니다.
plt.title("Model Accuracy Comparison")
# x축 라벨이 길기 때문에 30도 회전시켜 겹치지 않게 합니다.
plt.xticks(rotation=30, ha="right")
# y축 기준 격자선을 표시합니다.
plt.grid(axis="y")
# 그래프를 출력합니다.
plt.show()
.... 뭐 딱히 뛰어난 방법이 없는데 왜 진행했는지 잘 모르겟..
'SK 네트웍스 AI 캠프' 카테고리의 다른 글
| [SK네트웍스 Family AI 캠프] 32기 6주차 회고: Day20 ~ Day23 + 5월 종합 (0) | 2026.06.05 |
|---|---|
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day23_머신러닝 비지도학습알고리즘 (0) | 2026.06.05 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day21_머신러닝 알고리즘 및 앙상블 (0) | 2026.06.02 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day20_머신러닝 결정트리와 회귀트리 (0) | 2026.06.01 |
| [SK네트웍스 Family AI 캠프] 32기 5주차 회고: Day16 ~ Day19 (0) | 2026.05.29 |



