의사결정 트리 = 스무고개
Decision Tree
사람이 질문을 하나씩 하면서 결정을 내리는 방식과 흡사함.
루트노드(시작점), 첫번째 질문
결정노드, 데이터를 여러 그룹으로 나누기 위한 질문노드
분기, 질문이 답에 따라 이동하는 길
잎 노드, 최종결과를 나타내는 노드
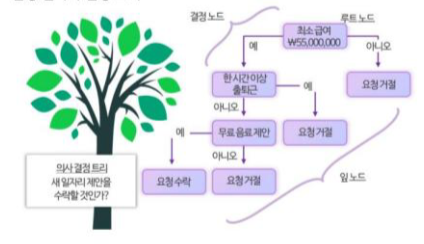
의사결정트리는 트리구조로 되어있어 사람이 보기쉽고 다른 머신러닝 모델은 결과가 나왔어도 이유를 알기 어려운 경우가 많으나 의사결정트리는 결과가 나온 이유를 쉽게 설명할 수 있고 동작 과정을 한눈에 확인 할 수 있어 , 채용 등의 결과설명이 필요한 경우 사용하기 좋다 .
가지치기
나무를 너무 복잡하게 만들지 않는 작업.
의사결정 트리는 계속해서 질문을 만들 수 있고 이때 질문을 너무 많이 분할하면 학습데이터에 딱 맞는 트리가 만들어져버린다.
'김철수인가? 이영희인가? 생일이 3월인가?'
이를 과적합이라하고 필요없는 가지를 잘라내는 것이 가지치기이다.
사전가지치기 = 조기종료
트리를 만드는 도중 미리 성장을 멈추는 방법
노드에 데이터가 10개이하이면 더이상 분할하지않거나 트리 깊이가 5이상이면 분할을 중기하는 등의 기준을 정한다.
계산이 빨라지고 트리가 너무 커지는 것을 방지한다. 다만 끝까지 가야 중요한 규칙이 보이는 경우일때 전에 멈춰 중요한 패턴을 놓칠 가능성이 있따.
사후가지치기
트리를 충분히 크게 만든 후, 별 도움이 안되는 가지를 없애 단순한 트리를 만든다. 중요한 패턴을 놓칠 가능성이 적고 적절한 크기를 판단하기 쉬우나 먼저 큰 트리를 만들어야해서 계산량이 증가한다는 단점이 있다.
사전가지치지는 언제 멈춰야하는지를 알아야하지만 미리 알기 어렵다 .보통은 사후가지치기가 더 좋은 결과를 낸다.
https://standout.tistory.com/1536
의사결정 나무 모형: 노드와 가지, 가지치기
의사결정 나무 모형데이터에서 관찰된 패턴을 기반으로 트리 구조를 생성, 노드(node)와 가지(edge)로 구성고객 세그먼테이션, 신용 점수화, 의료 진단 등 다양한 분야에서 사용된다. 의료
standout.tistory.com
https://standout.tistory.com/1538
기계학습 알고리즘과 주요 기계학습 알고리즘: 선형 회귀, 의사결정 나무 모형, 딥러닝
기계학습 알고리즘데이터에서 패턴을 발견하고 학습하는 데 사용되는 다양한 기법https://standout.tistory.com/78 알고리즘이란?알고리즘 해결가능한 문제를 풀기위한 절차 자료구조(선형, 배열,
standout.tistory.com
이처럼 데이터를 반복적으로 분할하여 트리를 구성하는 방식을 재귀적 분할이라고 한다.
의사결정 트리를 구축할때 사용되는 경험적 규칙이나 전략을 휴리스틱이라한다.
전체 문제를 작은 부분 문제로 나누어 해결하는 접근 방식을 분할 및 정복이라한다.
https://standout.tistory.com/115
마트료시카, 재귀
재귀 recursion, 자기 자신을 참조하는 것 마트료시카 인형을 연상하면 좋다. https://ko.wikipedia.org/wiki/%EC%9E%AC%EA%B7%80_(%EC%BB%B4%ED%93%A8%ED%84%B0_%EA%B3%BC%ED%95%99) 재귀 (컴퓨터 과학) - 위키백과, 우리 모두의
standout.tistory.com
트리장을 조기에 멈추는 기법을 조기중단이라한다.
트리구축 전 불필요한 가지를 제거하는 방법을 전가지 자르기, 구축한 후 가지를 제거하는 방법을 후가지 자르기라한다.
의사결정트리는 어떤 질문을 하면 가장 깔끔하게 분류될지를 찾기때문에
어떤 질문을 했을때 답에 적합한 질문으로 나뉠 수 있는지를 중시해 엔트로피를 중시한다.
https://standout.tistory.com/1766
Entropy 엔트로피란?
엔트로피 = “데이터의 혼란도 / 불확실성 / 섞임 정도”데이터가 얼마나 뒤섞여 무질서한지를 나타내는 값. 엔트로피가 높다는 의미는 데이터가 많이 섞여있고, 엔트로피가 적다는 것은 데이터
standout.tistory.com
회귀트리
의사결정트리와 다르게 회귀트리는 '합격/불합격'등이 아닌 '숫자'를 예측한다.
모델트리
일반회귀트리가 하나의 숫자(평균값 등)을 가져 값을 판단한다면 모델트리는 잎 노드마다 다른 회귀식이 존재한다. 트리는 중요한 변수를 자동으로 선택해 개발자가 직접 설계할 필요가없으며 다양한 데이터에 강하다.
모델트리는 linear regression 선형회귀보다 복잡하고 트리를 잘 나누려면 데이터가 충분해야하며 트리가 깊어지면 조건이 너무 많아져 전체 흐름을 이해하기 어렵다는 단점이 있다.
분류트리: 무엇인가?(카테고리나누기)
회귀트리: 얼마인가? (숫자 평균 등으로 판단하기)
모델트리: 구간마다 다른 공식으로 계산하기
일반 선형회귀 일반 회귀모델은 한계가 있다. 직선관계를 가장하지만 실제 데이터는 비선형 + 복잡한 관계이기 때문이다. 소득이 많다고 항상 소비가 일정하게 증가하지않는다는 이론과 같다. 트리는 분류용이지만 의사결정 트리는 조건으로 우선 데이터를 나누고 각 그룹에서 숫자를 예측하는등의 숫자 예측에도 사용이 가능하다.
샘플코드 decision_tree_torch를 분석하자.
신용대출 상환 여부를 예측하는 분류모델을 PyTorch로 구현했다.
데이터로드 - 전처리 - 학습/테스트 데이터 분리 - PyTorch 모델정의 - 학습 - 평가 - 샘플예측
import
pandas, numpy 데이터처리
torch, torch.nn, torch.optim PyTorch 모델 정의 및 학습
sklearn train/test 분리, 전처리, 평가지표
matplotlib 학습 그래프 출력
warnings 경고 숨기기
device = cuda if available else cpu: gpu사용가능 여부 설정
# ============================================================
# 1. 필요한 라이브러리 불러오기
# ============================================================
# pandas는 CSV 파일을 읽고 표 형태의 데이터를 다루기 위한 라이브러리입니다.
import pandas as pd
# numpy는 숫자 배열 계산을 빠르게 처리하기 위한 라이브러리입니다.
import numpy as np
# torch는 PyTorch의 핵심 라이브러리입니다.
# 텐서 생성, 신경망 학습, 자동 미분 등을 처리합니다.
import torch
# torch.nn은 신경망 계층, 손실 함수 등을 만들 때 사용하는 모듈입니다.
import torch.nn as nn
# torch.optim은 Adam, SGD 같은 최적화 알고리즘을 제공하는 모듈입니다.
import torch.optim as optim
# Dataset과 DataLoader는 데이터를 PyTorch 모델에 넣기 좋은 형태로 관리하는 도구입니다.
from torch.utils.data import Dataset, DataLoader
# train_test_split은 데이터를 학습용과 테스트용으로 나누는 함수입니다.
from sklearn.model_selection import train_test_split
# ColumnTransformer는 수치형/범주형 컬럼에 서로 다른 전처리를 적용할 때 사용합니다.
from sklearn.compose import ColumnTransformer
# OneHotEncoder는 문자 범주 데이터를 0과 1의 숫자 벡터로 변환합니다.
from sklearn.preprocessing import OneHotEncoder, StandardScaler, LabelEncoder
# Pipeline은 여러 전처리 단계를 하나로 묶어 실행할 때 사용합니다.
from sklearn.pipeline import Pipeline
# accuracy_score와 confusion_matrix는 모델 평가 지표를 계산합니다.
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# matplotlib은 그래프를 그리기 위한 라이브러리입니다.
import matplotlib.pyplot as plt
# random은 파이썬의 난수 생성을 제어할 때 사용합니다.
import random
# os는 파일 경로 확인 등에 사용합니다.
import os
# 경고 메시지를 줄여 출력 화면을 깔끔하게 만들기 위해 사용합니다.
import warnings
# 불필요한 경고 메시지를 숨깁니다.
warnings.filterwarnings("ignore")
# 현재 사용 가능한 장치를 확인합니다.
# Colab에서 GPU를 켜면 cuda가 출력되고, 그렇지 않으면 cpu가 출력됩니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 현재 학습에 사용할 장치를 출력합니다.
print("사용 장치:", device)
난수고정
난수를 고정하면 코드를 다시 실행해도 최대한 같은 결과가 나오도록 만 들 수 있다.
seed = 123
random, np.random, torch.manual_seed, torch.cuda.manual_seed_all.. 를 고정
torch.backends,cudnn.deterministic = true, benchmark = false로 재현성을 확보했다.
123은 난수 생성기의 시작점으로 내부적으로 123번 상태로 시작한다고 정의하고 이 숫자 seed를 사용하면 같은 random값들이 나온다 . 이 숫자는 아무 정수나 하나 정해서 사용하며 사용시 같은 숫자를 사용한다는 점만 유의하자 .
머신러닝에서는 난수가 정말 많이 사용된다. 데이터 섞기, 훈련테스트 데이터 분리, 가중치 초기화 및 dropout, mini batch 추출, 데이터 증강 등 계속 랜덤값이 생성되고 난수를 고정하지 않으면 결과는 계속해서 달라진다 .
파이썬 기본 random 라이브러리의난수를 고정하고, random.seed(123)
numpy의 난수를 고정하고, np.random.seed(123)
pytorch cpu 연산의 난수를 고정하고 torch.manual_seed(123)
gpu에서 사용하는 난수를 고정하고 torch.cuda.manual_seed_all(123)
또 난수설정 뿐만 아니라 gpu는 계산속도를 높이기 위해 여러 알고리즘 중 가장 빠른 것을 자동 선택함으로 이 알고리즘을 무엇을 쓰느냐에 따라 아주 미세하게 결과가 달라지기에 torch.backends.cudnn.deterministic = True 조금느려져도 좋으니 항상 같은 알고리즘을 사용하라고 지시한다.
또 cuDNN은 매 실행마다 속도를 테스트해서 알고리즘을 선택할 수 있다 .이또한 같은 이유로 인해 torch.backends.cudnn.benchmark = True로 고정한다 .
# ============================================================
# 2. 난수 고정
# ============================================================
# 난수를 고정하면 코드를 다시 실행해도 최대한 같은 결과가 나오도록 만들 수 있습니다.
SEED = 123
# 파이썬 random 라이브러리의 난수를 고정합니다.
random.seed(SEED)
# numpy 난수를 고정합니다.
np.random.seed(SEED)
# PyTorch CPU 연산의 난수를 고정합니다.
torch.manual_seed(SEED)
# PyTorch GPU 연산의 난수를 고정합니다.
torch.cuda.manual_seed_all(SEED)
# CUDA 연산의 재현성을 높이기 위한 설정입니다.
torch.backends.cudnn.deterministic = True
# 실행 속도 최적화보다 재현성을 우선하도록 설정합니다.
torch.backends.cudnn.benchmark = False
데이터불러오기
로컬에서 있으면 읽고 없으면 공개 geman credit 데이터셋을 다운로드한다 .
이때 만일 공개 데이터셋에서 repay컬럼이 default으로 정의되어있을 수 있다. 이땐 재정의해 코드가 잘 돌아갈 수 있도록 한다 .
# ============================================================
# 3. 데이터 불러오기
# ============================================================
# 사용한 파일 경로입니다.
local_path = "data/credit_info.csv"
# 공개 German Credit 데이터셋 주소입니다.
# Colab에서 data/credit_info.csv 파일이 없을 때 자동으로 읽어옵니다.
url = "https://raw.githubusercontent.com/stedy/Machine-Learning-with-R-datasets/master/credit.csv"
# data 폴더가 없으면 새로 생성합니다.
os.makedirs("data", exist_ok=True)
# local_path 파일이 실제로 존재하는지 확인합니다.
if os.path.exists(local_path):
# 파일이 있으면 사용자가 제공한 로컬 CSV 파일을 읽습니다.
credit_info = pd.read_csv(local_path)
else:
# 파일이 없으면 공개 URL에서 CSV 파일을 읽습니다.
credit_info = pd.read_csv(url)
# 다음 실행 때도 같은 파일을 사용할 수 있도록 data 폴더에 저장합니다.
credit_info.to_csv(local_path, index=False)
# 목표 변수를 Repay라고 사용합니다.
# 공개 데이터셋은 목표 컬럼명이 default일 수 있으므로 Repay로 바꿉니다.
if "Repay" not in credit_info.columns and "default" in credit_info.columns:
# default 컬럼명을 Repay로 변경합니다.
credit_info = credit_info.rename(columns={"default": "Repay"})
# 데이터의 앞부분 5행을 확인합니다.
credit_info.head()
데이터구조확인
데이터 크기는 1000, 21 즉 샘플수는 천개, 특성은 20개이다.
결측치, not null이 모든 컬럼에 표시되어있기때문에 nan 이 없다. 결측치 처리가 불필요함을 의미한다.
object 타입이 굉장히 많아 labelEncoder 및 one-hot encodeing 이 필요하며
int64등으로 표시된 데이터는 수치형 변수임을알 수 있ek.
# ============================================================
# 4. 데이터 구조 확인
# ============================================================
# 데이터의 행과 열 개수를 확인합니다.
print("데이터 크기:", credit_info.shape)
# 각 컬럼의 자료형과 결측치 여부를 확인합니다.
credit_info.info()
# 컬럼 이름 목록을 출력합니다.
print("\n컬럼 목록:")
print(credit_info.columns.tolist())# ============================================================
# 5. 기본 탐색
# ============================================================
# checking_balance 컬럼은 신청자의 수표 계좌 잔고 범주를 의미합니다.
# value_counts()는 R의 table()과 비슷하게 값별 개수를 세어 줍니다.
print("checking_balance 빈도:")
print(credit_info["checking_balance"].value_counts())
# savings_balance 컬럼은 신청자의 저축 계좌 잔고 범주를 의미합니다.
print("\nsavings_balance 빈도:")
print(credit_info["savings_balance"].value_counts())
# months_loan_duration은 대출 기간입니다.
# describe()는 평균, 표준편차, 최솟값, 최댓값 등을 보여줍니다.
print("\nmonths_loan_duration 요약:")
print(credit_info["months_loan_duration"].describe())
# amount는 대출 금액입니다.
print("\namount 요약:")
print(credit_info["amount"].describe())
# Repay는 상환 여부 또는 채무불이행 여부를 나타내는 목표 변수입니다.
print("\nRepay 빈도:")
print(credit_info["Repay"].value_counts())
# Repay 비율을 확인합니다.
print("\nRepay 비율:")
print(credit_info["Repay"].value_counts(normalize=True))
입력과 타겟분리
target_col를 repay로 설정하고 y에 할당하며,
x는 이 target_col를 제외한 drop 나머지 label로 지정한다.
# ============================================================
# 6. 입력 X와 정답 y 분리
# ============================================================
# 목표 컬럼명을 변수로 저장합니다.
target_col = "Repay"
# 목표 컬럼이 실제 데이터에 있는지 확인합니다.
if target_col not in credit_info.columns:
# 목표 컬럼이 없으면 에러를 발생시켜 문제 원인을 바로 알 수 있게 합니다.
raise ValueError("데이터에 Repay 컬럼이 없습니다. 목표 컬럼명을 확인하세요.")
# X는 Repay를 제외한 모든 컬럼입니다.
X = credit_info.drop(columns=[target_col])
# y는 모델이 예측해야 하는 Repay 컬럼입니다.
y = credit_info[target_col]
# LabelEncoder는 문자 라벨을 숫자 라벨로 바꿉니다.
# 예: no -> 0, yes -> 1 과 같은 방식입니다.
label_encoder = LabelEncoder()
# y 값을 숫자 형태로 변환합니다.
y_encoded = label_encoder.fit_transform(y)
# 어떤 원래 라벨이 어떤 숫자로 바뀌었는지 확인합니다.
print("라벨 매핑:")
for original_label, encoded_label in zip(label_encoder.classes_, range(len(label_encoder.classes_))):
print(f"{original_label} -> {encoded_label}")
앞서 살펴봤던 수치형, 범주형 컬럼을 확인해 분류했다.
# ============================================================
# 7. 수치형 컬럼과 범주형 컬럼 구분
# ============================================================
# 수치형 컬럼은 int64, float64 같은 숫자 자료형 컬럼입니다.
numeric_features = X.select_dtypes(include=["int64", "float64"]).columns.tolist()
# 범주형 컬럼은 object, category 같은 문자 또는 범주 자료형 컬럼입니다.
categorical_features = X.select_dtypes(include=["object", "category", "bool"]).columns.tolist()
# 수치형 컬럼 목록을 출력합니다.
print("수치형 컬럼:", numeric_features)
# 범주형 컬럼 목록을 출력합니다.
print("범주형 컬럼:", categorical_features)
train_test_split() 학습데이터 테스트 데이터를 분리했다 .
학습 80%, 테스트 20% 로 분리했다. 이때 클래스 비율을 유지하도록 stratify_encoded를 지정했다.
80, 20은 정답이 정해진 규칙이 아닌 가장 많이 사용하는 관례이며 학습데이터는 많을 수록 좋지만 테스트 데이터도 충분히 있어야 성능을 믿을 수 있음으로 90을 선택하지않고, 70:30시 평가신뢰성이 높으나 학습데이터가 감소되니 관례산 80 20 을 쓰는것.
# ============================================================
# 8. 학습 데이터와 테스트 데이터 분리
# ============================================================
# train_test_split은 데이터를 학습용과 테스트용으로 나눕니다.
# test_size=0.2는 전체 데이터의 20%를 테스트용으로 사용한다는 뜻입니다.
# 800개 학습 / 200개 테스트 분리와 같은 비율입니다.
# stratify=y_encoded는 정답 라벨 비율이 학습/테스트에 비슷하게 유지되도록 합니다.
X_train, X_test, y_train, y_test = train_test_split(
X,
y_encoded,
test_size=0.2,
random_state=SEED,
stratify=y_encoded
)
# 분리된 데이터 크기를 확인합니다.
print("X_train 크기:", X_train.shape)
print("X_test 크기:", X_test.shape)
print("y_train 크기:", y_train.shape)
print("y_test 크기:", y_test.shape)
# 학습 데이터의 클래스 비율을 확인합니다.
print("\n학습 데이터 클래스 비율:")
print(pd.Series(y_train).value_counts(normalize=True).sort_index())
# 테스트 데이터의 클래스 비율을 확인합니다.
print("\n테스트 데이터 클래스 비율:")
print(pd.Series(y_test).value_counts(normalize=True).sort_index())
전처리
현재 데이터를 보면 문자열 데이터가 많이 있다.
범주형 데이터는 숫자로 변환하기에 2,3, 1, 등이 사용되고 이는 오인될 수 있다 .이들은 서로 크기 관계가 없으니 one hor encoding으로 0과 1로 이루어진 벡터로 변환한다. 이때 학습데이터에 없던 값이 나올경우 오류가 발생할 수 있음으로 handle_unknown = ignore로 모르는 범주가 나오면 무시하도록 지정하며 이는 거의 필수옵션이다 .
수치형 데이터는 범위가 크게 다름으로 standardscaler를 사용해 평균 0, 표준편차가 1이 되도록 변환한다.
수치형과 범주형은 처리방법이 다르고 이를 한번에 처리하기 위해 columtransformer를 사용한다. 앞서 onehotencoder와 standardscaler한 내용을 합쳐주는 관리자.
학습데이터는 fit을 사용해 전처리 규칙을 학습하며 테스트 데이터틑 fit하지않는다 . transform은 fit에서 배운 규칙을 적용하는것을 의미하며 테스트 데이터에는 학습없이 이미 만들어진 규칙을 적용만 시킨다.
pytorch는 기본적으로 float32를 사용하기 때문에 결과를 numpy.float32로 변환시켰다.
# ============================================================
# 9. 전처리 파이프라인 생성
# ============================================================
# 수치형 데이터 전처리: StandardScaler로 표준화합니다.
numeric_transformer = Pipeline(
steps=[
# StandardScaler는 수치 데이터의 크기 차이를 줄여 학습을 안정적으로 만듭니다.
("scaler", StandardScaler())
]
)
# 범주형 데이터 전처리: OneHotEncoder로 숫자 벡터화합니다.
categorical_transformer = Pipeline(
steps=[
# handle_unknown="ignore"는 테스트 데이터에 학습 때 보지 못한 범주가 나와도 에러를 막습니다.
("onehot", OneHotEncoder(handle_unknown="ignore"))
]
)
# ColumnTransformer는 컬럼 종류별로 다른 전처리를 적용합니다.
preprocessor = ColumnTransformer(
transformers=[
# numeric_features 컬럼에는 numeric_transformer를 적용합니다.
("num", numeric_transformer, numeric_features),
# categorical_features 컬럼에는 categorical_transformer를 적용합니다.
("cat", categorical_transformer, categorical_features)
]
)
# fit_transform은 학습 데이터 기준으로 전처리 규칙을 학습하고 바로 변환합니다.
X_train_processed = preprocessor.fit_transform(X_train)
# transform은 학습 데이터에서 만든 규칙을 테스트 데이터에 그대로 적용합니다.
X_test_processed = preprocessor.transform(X_test)
# OneHotEncoder 결과가 희소 행렬일 수 있으므로 일반 numpy 배열로 변환합니다.
X_train_processed = X_train_processed.toarray() if hasattr(X_train_processed, "toarray") else X_train_processed
X_test_processed = X_test_processed.toarray() if hasattr(X_test_processed, "toarray") else X_test_processed
# PyTorch는 float32 자료형을 주로 사용하므로 float32로 변환합니다.
X_train_processed = X_train_processed.astype(np.float32)
X_test_processed = X_test_processed.astype(np.float32)
# 정답 라벨은 분류 문제에서 long 타입으로 사용합니다.
y_train = y_train.astype(np.int64)
y_test = y_test.astype(np.int64)
# 전처리 후 입력 특성 개수를 확인합니다.
print("전처리 후 학습 입력 크기:", X_train_processed.shape)
print("전처리 후 테스트 입력 크기:", X_test_processed.shape)
dataset 과 dataloader
pytorch는 (입력데이터x, 정답y) 한쌍씩 받아오기를 원하지만 현재 데이터는 X_train_processed , y_train와 같이 따로 존재함으로 묶어 저장할 수 잇도록 dataset, creditdataset을 사용한다 .
init()는 실행시 한번 실행되고 pytorch는 numpy가 아닌 tensor형태를 사용함으로 tensor 자료형으로 변환한다.
batch_size를 설정해 한번에 32개 데이터씩 학습하도록 지정했다.
dataloader로 dataset을 실제 학습에 사용할 수 있도록 배치를 만들어주었다 . dataloader가 없으면 하나씩 indexing으로 빼내어 써야하니 불편하기 때문이다 . dataloader는 32개씩 묶고, 자동반복하며 데이터 섞기까지 대신 해준다 .
shuffle = true 매 epoch마다 데이터 순서를 랜덤하게 섞는 속성값을 설정해 좋은고객, 좋은고객, 좋은고객, 나쁜고객, 나쁜고객 등으로 데이터가 묶여 모델이 이상하게 학습되지않도록 섞어 사용하되 마찬가지로 테스트 데이터에는 적요하지않는다.
# ============================================================
# 10. PyTorch Dataset 클래스 정의
# ============================================================
# CreditDataset은 대출 데이터를 PyTorch가 사용할 수 있는 형태로 포장하는 클래스입니다.
class CreditDataset(Dataset):
# __init__은 Dataset 객체가 만들어질 때 한 번 실행됩니다.
def __init__(self, features, labels):
# 입력 특성을 torch 텐서로 변환합니다.
self.features = torch.tensor(features, dtype=torch.float32)
# 정답 라벨을 torch 텐서로 변환합니다.
self.labels = torch.tensor(labels, dtype=torch.long)
# __len__은 데이터가 총 몇 개인지 반환합니다.
def __len__(self):
# labels의 길이가 전체 데이터 개수입니다.
return len(self.labels)
# __getitem__은 특정 번호의 데이터 1개를 반환합니다.
def __getitem__(self, idx):
# idx번째 입력 데이터와 정답 라벨을 함께 반환합니다.
return self.features[idx], self.labels[idx]
# 학습용 Dataset 객체를 생성합니다.
train_dataset = CreditDataset(X_train_processed, y_train)
# 테스트용 Dataset 객체를 생성합니다.
test_dataset = CreditDataset(X_test_processed, y_test)
# 한 번에 학습할 데이터 개수입니다.
# 32개씩 묶어서 모델에 넣습니다.
batch_size = 32
# 학습용 DataLoader를 생성합니다.
# shuffle=True는 매 epoch마다 데이터 순서를 섞어 학습 효과를 높입니다.
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 테스트용 DataLoader를 생성합니다.
# 테스트는 순서를 섞을 필요가 없으므로 shuffle=False입니다.
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 첫 번째 미니배치를 꺼내 입력과 정답 크기를 확인합니다.
sample_X, sample_y = next(iter(train_loader))
# 미니배치 입력 크기를 출력합니다.
print("미니배치 입력 크기:", sample_X.shape)
# 미니배치 정답 크기를 출력합니다.
print("미니배치 정답 크기:", sample_y.shape)
모델정의
전처리가 모두 끝났으니 실제 인공지능 신경망을 설계해보자.
creditMLP 클래스를 생성해 모델을 정의했다. MLP는 Multi layer perceptron 다중 퍼셉트론(입력층 - 은닉층1, 2,- 출력증)은 가장 기본적인 신경망이다 . 현재 입력층 - 뉴런 64개 - 뉴런 32개로 설정했다.
nn.module을 상속받아 부모 클래스를 초기화했다 .sequential을 사용해 층들을 순서대로 연결했다.
linear로 고객정보 특정을 64개 특성으로 변환시켰다. 이때 중간에 ReLU를 넣는데 이는 음수는 0으로, 양수는 그대로 표현한다. 이는 모델에 비선현성을 추가한다는 의미로 특정 조건에서는 다르게 반응하거나 특정조건에서 영향을 제거하는 등 복잡한 판단이 가능해진다.
학습중 20%를 랜덤하게 꺼버려 특정 뉴런에 의존하지 못하고 과적합을 감소하고 일반화 성능이 향상되도록 한다 .
linear로 고객정보 특정을 64로 변환시켰던것을 32개로 압축했다 .
위 정의한 self.network를 forward 입력이 들어오면 실행되도록 한다.
작성한 credirmlp class를 사용해 creditmlp 실제 모델을 생성한다.
# ============================================================
# 11. PyTorch 모델 정의
# ============================================================
# CreditMLP는 대출 상환 여부를 분류하는 신경망 모델입니다.
class CreditMLP(nn.Module):
# __init__은 모델 구조를 정의하는 부분입니다.
def __init__(self, input_dim, num_classes):
# 부모 클래스 nn.Module의 초기화 함수를 실행합니다.
super(CreditMLP, self).__init__()
# self.network는 여러 신경망 계층을 순서대로 묶은 구조입니다.
self.network = nn.Sequential(
# 첫 번째 완전연결층입니다.
# input_dim개의 입력을 받아 64개의 값으로 변환합니다.
nn.Linear(input_dim, 64),
# ReLU는 음수는 0으로, 양수는 그대로 통과시키는 활성화 함수입니다.
# 모델이 복잡한 패턴을 학습할 수 있게 도와줍니다.
nn.ReLU(),
# Dropout은 일부 뉴런을 무작위로 끄는 기법입니다.
# 과적합을 줄이는 데 도움이 됩니다.
nn.Dropout(0.2),
# 두 번째 완전연결층입니다.
# 64개의 입력을 받아 32개의 값으로 변환합니다.
nn.Linear(64, 32),
# 두 번째 ReLU 활성화 함수입니다.
nn.ReLU(),
# 마지막 출력층입니다.
# 32개의 입력을 클래스 개수만큼의 점수로 변환합니다.
nn.Linear(32, num_classes)
)
# forward는 입력 데이터가 모델을 통과하는 계산 과정을 정의합니다.
def forward(self, x):
# 입력 x를 self.network에 통과시켜 출력값을 만듭니다.
return self.network(x)
# 입력 특성 개수입니다.
input_dim = X_train_processed.shape[1]
# 분류할 클래스 개수입니다.
num_classes = len(label_encoder.classes_)
# 모델 객체를 생성하고 학습 장치(cpu 또는 cuda)로 이동합니다.
model = CreditMLP(input_dim=input_dim, num_classes=num_classes).to(device)
# 모델 구조를 출력합니다.
print(model)
손실함수와 최적화 알고리즘
손실함수란 loss function, crossentropylosee 얼마나 틀렸는지 점수매기는 채점기와 같다. 틀림을 보고 가중치를 수정할 수 있다.
다중분류에서 많이 사용하는 손실함수 crossEntropyLosee를 criterion에 할당하고.
이 loss를 보고 optimizer가 판단하여 가중치를 수정한다.
optim.adam()
model.parameters() 모델안이 모든 가중치를 받아 optim이 가중치를 얼마나 수정할지 결정해 실행하도록 지정한다. 이때 한번에 이 가중치를 얼마나 수정할것인지를 lr로 지정할 수 있다 0.001 , 0.0001, .0.01을 많이 사용한다.
# ============================================================
# 12. 손실 함수와 최적화 알고리즘 설정
# ============================================================
# CrossEntropyLoss는 다중 분류 문제에서 많이 사용하는 손실 함수입니다.
# 모델의 예측이 정답과 얼마나 다른지 숫자로 계산합니다.
criterion = nn.CrossEntropyLoss()
# Adam은 학습률을 자동으로 조정해 가며 모델 파라미터를 업데이트하는 최적화 알고리즘입니다.
optimizer = optim.Adam(
model.parameters(), # 학습할 모델 파라미터를 지정합니다.
lr=0.001 # learning rate, 즉 한 번에 얼마나 크게 수정할지 정합니다.
)
평가함수
model.eval()로 평가모드로 진입하니 dropout를 off하고 batchnorm을 고정하는 등의 상태로 만든다 .
손실값을 저장할 변수 total_loss, 맞춘개수를 저장할 correct, 전체데이터 갯수 total 를 만들고
envaluate를 정의해 평가모드로 전환하되 기울기는 현재 분류기에서 필요가없음으로 torch.no_grad()를 사용해 메모리를 절약하고 속도를 향상시킨다.
dataloader에서 batch로 꺼내와 모델과 데이터의 cpu gpu를 맞춰준다.
예측점수를 계산, 손실값을 계산, total_loss를 확인, total을 구해 평균 손실값과 정확도를 계산해 return한다 .
# ============================================================
# 13. 평가 함수 정의
# ============================================================
# evaluate 함수는 검증 또는 테스트 데이터에서 모델 성능을 계산합니다.
def evaluate(model, data_loader, criterion):
# 모델을 평가 모드로 바꿉니다.
# Dropout 같은 학습 전용 동작이 꺼집니다.
model.eval()
# 전체 손실값을 누적할 변수입니다.
total_loss = 0.0
# 맞힌 개수를 누적할 변수입니다.
correct = 0
# 전체 데이터 개수를 누적할 변수입니다.
total = 0
# 평가할 때는 기울기 계산이 필요 없으므로 no_grad를 사용합니다.
with torch.no_grad():
# DataLoader에서 미니배치 단위로 데이터를 꺼냅니다.
for batch_X, batch_y in data_loader:
# 입력 데이터를 학습 장치로 이동합니다.
batch_X = batch_X.to(device)
# 정답 라벨을 학습 장치로 이동합니다.
batch_y = batch_y.to(device)
# 모델에 입력 데이터를 넣어 예측 점수를 계산합니다.
outputs = model(batch_X)
# 예측 점수와 정답 사이의 손실값을 계산합니다.
loss = criterion(outputs, batch_y)
# 현재 미니배치 손실값에 데이터 개수를 곱해 누적합니다.
total_loss += loss.item() * batch_X.size(0)
# 가장 점수가 높은 클래스 번호를 예측값으로 선택합니다.
_, predicted = torch.max(outputs, 1)
# 전체 데이터 개수를 누적합니다.
total += batch_y.size(0)
# 예측값과 정답이 같은 개수를 누적합니다.
correct += (predicted == batch_y).sum().item()
# 평균 손실값을 계산합니다.
avg_loss = total_loss / total
# 정확도를 계산합니다.
accuracy = correct / total
# 평균 손실값과 정확도를 반환합니다.
return avg_loss, accuracy
학습루프
epochs 50으로 전체 데이터를 50번 반복학습해 보도록 한다.
model.train()으로 dropout같은 학습전용 동작을 켠다.
train_loader를 반복하며 batch 32개씩 가져와 반복한다.
pytorch는 기울기를 게속 누적하기 때문에 매 배치 마다 optimizer.zero.grid()로 기울기를 초기화한다 .
model(batch) 모델예측한다 .
loss.backward() 왜 틀렸는지를 계산한다.
optimizer,step() 실제 수정한다.
running_loss 각 배치의 손실을 계속 더해 평균을 계싼하고 torch.max, 즉 가장 큰 점수를 가진 클래스를 predicted 예측값으로 선택해 정답갯수를 계산한다., 학습손실, 정확도를계산하고 각 값을 리스트에 저장한다.
# ============================================================
# 14. 모델 학습 실행
# ============================================================
# 전체 학습 반복 횟수입니다.
epochs = 50
# 학습 과정을 저장할 리스트입니다.
train_losses = []
train_accuracies = []
test_losses = []
test_accuracies = []
# epoch 수만큼 반복 학습합니다.
for epoch in range(epochs):
# 모델을 학습 모드로 바꿉니다.
# Dropout 같은 학습 전용 동작이 켜집니다.
model.train()
# 한 epoch 동안의 손실값을 누적할 변수입니다.
running_loss = 0.0
# 한 epoch 동안 맞힌 개수를 누적할 변수입니다.
correct = 0
# 한 epoch 동안 전체 데이터 개수를 누적할 변수입니다.
total = 0
# 학습 데이터를 미니배치 단위로 반복합니다.
for batch_X, batch_y in train_loader:
# 입력 데이터를 학습 장치로 이동합니다.
batch_X = batch_X.to(device)
# 정답 라벨을 학습 장치로 이동합니다.
batch_y = batch_y.to(device)
# 이전 미니배치에서 계산된 기울기를 초기화합니다.
optimizer.zero_grad()
# 모델에 입력 데이터를 넣어 예측 점수를 계산합니다.
outputs = model(batch_X)
# 예측 결과와 실제 정답 사이의 손실값을 계산합니다.
loss = criterion(outputs, batch_y)
# 손실값을 기준으로 각 파라미터의 기울기를 계산합니다.
loss.backward()
# 계산된 기울기를 사용하여 모델 파라미터를 업데이트합니다.
optimizer.step()
# 현재 미니배치 손실값을 누적합니다.
running_loss += loss.item() * batch_X.size(0)
# 가장 큰 점수를 가진 클래스를 예측값으로 선택합니다.
_, predicted = torch.max(outputs, 1)
# 전체 데이터 개수를 누적합니다.
total += batch_y.size(0)
# 예측값과 정답이 같은 개수를 누적합니다.
correct += (predicted == batch_y).sum().item()
# 한 epoch의 평균 학습 손실값을 계산합니다.
train_loss = running_loss / total
# 한 epoch의 학습 정확도를 계산합니다.
train_acc = correct / total
# 테스트 데이터에 대한 손실값과 정확도를 계산합니다.
test_loss, test_acc = evaluate(model, test_loader, criterion)
# 그래프 출력을 위해 값을 리스트에 저장합니다.
train_losses.append(train_loss)
train_accuracies.append(train_acc)
test_losses.append(test_loss)
test_accuracies.append(test_acc)
# epoch마다 학습 결과를 출력합니다.
print(
f"Epoch [{epoch + 1:02d}/{epochs}] "
f"Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}, "
f"Test Loss: {test_loss:.4f}, Test Acc: {test_acc:.4f}"
)
그래프를 그린다.
# ============================================================
# 15. 학습 과정 그래프 출력
# ============================================================
# 그래프 크기를 지정합니다.
plt.figure(figsize=(8, 5))
# 학습 손실값 변화를 선 그래프로 표시합니다.
plt.plot(train_losses, label="Train Loss")
# 테스트 손실값 변화를 선 그래프로 표시합니다.
plt.plot(test_losses, label="Test Loss")
# 그래프 제목을 지정합니다.
plt.title("Loss 변화")
# x축 이름을 지정합니다.
plt.xlabel("Epoch")
# y축 이름을 지정합니다.
plt.ylabel("Loss")
# 범례를 표시합니다.
plt.legend()
# 그래프를 출력합니다.
plt.show()
# 새로운 그래프 크기를 지정합니다.
plt.figure(figsize=(8, 5))
# 학습 정확도 변화를 선 그래프로 표시합니다.
plt.plot(train_accuracies, label="Train Accuracy")
# 테스트 정확도 변화를 선 그래프로 표시합니다.
plt.plot(test_accuracies, label="Test Accuracy")
# 그래프 제목을 지정합니다.
plt.title("Accuracy 변화")
# x축 이름을 지정합니다.
plt.xlabel("Epoch")
# y축 이름을 지정합니다.
plt.ylabel("Accuracy")
# 범례를 표시합니다.
plt.legend()
# 그래프를 출력합니다.
plt.show()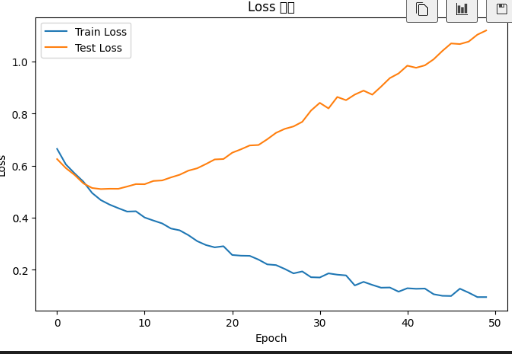

model.eval() 평가모드로 변경한다.
각 예측값과 정답을 저장할 변수를 세팅한다
with torch.nograd() 마찬가지로 가중치 수정을 하지않을것임으로 선언해 메모리를 절약하고
테스트 데이터를 반복하며 모델이 예측하고 나온 output중 큰 점수를 선택해 cpu로 이동해 각 배치마다 나온 결과를 리스트에 추가한다 .numpy배열로 바꾸어 정확도를 계산하고accuracy_score() 출력한다 .
이때 정확도만 보면 몇 %만 맞췄는지 알수있어 무엇을 잘 틀리는지 알수없음으로 confustion_matrix()를 사용해 확인한다.
# ============================================================
# 16. 테스트 데이터 전체 예측
# ============================================================
# 모델을 평가 모드로 변경합니다.
model.eval()
# 예측값을 저장할 리스트입니다.
all_predictions = []
# 실제 정답을 저장할 리스트입니다.
all_labels = []
# 테스트 과정에서는 기울기 계산이 필요 없으므로 no_grad를 사용합니다.
with torch.no_grad():
# 테스트 데이터를 미니배치 단위로 반복합니다.
for batch_X, batch_y in test_loader:
# 입력 데이터를 학습 장치로 이동합니다.
batch_X = batch_X.to(device)
# 모델 예측 점수를 계산합니다.
outputs = model(batch_X)
# 가장 점수가 높은 클래스를 예측값으로 선택합니다.
_, predicted = torch.max(outputs, 1)
# 예측값을 CPU로 옮긴 뒤 numpy 배열로 변환하여 리스트에 추가합니다.
all_predictions.extend(predicted.cpu().numpy())
# 실제 정답도 numpy 배열로 변환하여 리스트에 추가합니다.
all_labels.extend(batch_y.numpy())
# 리스트를 numpy 배열로 변환합니다.
all_predictions = np.array(all_predictions)
all_labels = np.array(all_labels)
# 정확도를 계산합니다.
test_accuracy = accuracy_score(all_labels, all_predictions)
# 테스트 정확도를 출력합니다.
print("테스트 정확도:", round(test_accuracy, 4))# ============================================================
# 17. Confusion Matrix 출력
# ============================================================
# Confusion Matrix를 계산합니다.
cm = confusion_matrix(all_labels, all_predictions)
# Confusion Matrix를 표 형태의 DataFrame으로 변환합니다.
cm_df = pd.DataFrame(
cm,
index=[f"Actual_{label}" for label in label_encoder.classes_],
columns=[f"Pred_{label}" for label in label_encoder.classes_]
)
# Confusion Matrix를 출력합니다.
cm_df
classification_report를 사용해 precision 예측한것중 맞은것, recall 실제정답중 모델이 찾아낸 비율, f1-score 앞선것들을 고려한 점수를 한번에 보여준다 .
# ============================================================
# 18. 상세 분류 리포트 출력
# ============================================================
# classification_report는 precision, recall, f1-score를 한 번에 보여줍니다.
# precision은 예측한 것 중 실제로 맞은 비율입니다.
# recall은 실제 정답 중 모델이 찾아낸 비율입니다.
# f1-score는 precision과 recall을 함께 고려한 점수입니다.
report = classification_report(
all_labels,
all_predictions,
target_names=[str(cls) for cls in label_encoder.classes_]
)
# 상세 평가 결과를 출력합니다.
print(report)
신규 데이터를 가져와 테스트한다 .
# ============================================================
# 19. 신규 대출 신청자 예측 예시
# ============================================================
# 테스트 데이터에서 첫 번째 신청자 데이터를 하나 가져옵니다.
new_applicant = X_test.iloc[[0]]
# 신규 신청자 데이터를 확인합니다.
display(new_applicant)
# 학습 데이터 기준으로 만든 전처리기를 사용하여 신규 데이터를 변환합니다.
new_applicant_processed = preprocessor.transform(new_applicant)
# 희소 행렬이면 일반 배열로 변환합니다.
new_applicant_processed = (
new_applicant_processed.toarray()
if hasattr(new_applicant_processed, "toarray")
else new_applicant_processed
)
# float32 자료형으로 변환합니다.
new_applicant_processed = new_applicant_processed.astype(np.float32)
# numpy 배열을 PyTorch 텐서로 변환합니다.
new_applicant_tensor = torch.tensor(new_applicant_processed, dtype=torch.float32).to(device)
# 모델을 평가 모드로 변경합니다.
model.eval()
# 기울기 계산 없이 예측합니다.
with torch.no_grad():
# 모델의 출력 점수를 계산합니다.
output = model(new_applicant_tensor)
# softmax는 점수를 확률처럼 해석할 수 있게 변환합니다.
probabilities = torch.softmax(output, dim=1)
# 가장 확률이 높은 클래스를 선택합니다.
predicted_class = torch.argmax(probabilities, dim=1).item()
# 숫자 라벨을 원래 문자 라벨로 되돌립니다.
predicted_label = label_encoder.inverse_transform([predicted_class])[0]
# 예측 결과를 출력합니다.
print("예측 라벨:", predicted_label)
# 클래스별 예측 확률을 출력합니다.
for label, prob in zip(label_encoder.classes_, probabilities.cpu().numpy()[0]):
print(f"{label} 확률: {prob:.4f}")
다음 샘플코드 regression_tree_torch를 분석해보자.
UCI 데이터를 사용해 와인 품질 점수를 예측하는 회귀모델을 pytorch로 구현/학습/평가한 파이프라인이다 .
import
pandas, numpy: 데이터 처리
matplotlib: 시각화
torch, torch.nn, torch.optim: PyTorch 모델과 학습
TensorDataset, DataLoader: 미니배치 학습용 데이터 관리
StandardScaler: 입력 특성 표준화
mean_absolute_error, pearsonr: 평가 지표
# ============================================================
# 1. 기본 라이브러리 불러오기
# ============================================================
# pandas는 표 형태의 데이터를 읽고 처리하기 위한 라이브러리입니다.
import pandas as pd
# numpy는 숫자 배열 계산을 빠르게 처리하기 위한 라이브러리입니다.
import numpy as np
# matplotlib은 그래프를 그리기 위한 라이브러리입니다.
import matplotlib.pyplot as plt
# torch는 PyTorch의 핵심 라이브러리입니다.
# 텐서 계산, 신경망 모델 생성, 학습 등에 사용합니다.
import torch
# torch.nn은 신경망의 층, 손실 함수 등을 만들 때 사용하는 모듈입니다.
import torch.nn as nn
# torch.optim은 모델의 가중치를 업데이트하는 최적화 알고리즘을 제공합니다.
import torch.optim as optim
# TensorDataset은 입력 데이터와 정답 데이터를 하나의 데이터셋으로 묶어 줍니다.
# DataLoader는 데이터를 미니배치 단위로 나누어 모델에 공급합니다.
from torch.utils.data import TensorDataset, DataLoader
# StandardScaler는 입력 특성의 단위를 표준화합니다.
# 평균은 0, 표준편차는 1이 되도록 바꿉니다.
from sklearn.preprocessing import StandardScaler
# mean_absolute_error는 평균절대오차 MAE를 계산합니다.
from sklearn.metrics import mean_absolute_error
# pearsonr은 실제값과 예측값 사이의 상관계수를 계산합니다.
from scipy.stats import pearsonr
# random은 파이썬 기본 난수 생성 라이브러리입니다.
import random
# 실행 결과가 매번 최대한 같게 나오도록 난수 시드를 고정합니다.
SEED = 123
# 파이썬 random 라이브러리의 난수 시드를 고정합니다.
random.seed(SEED)
# numpy의 난수 시드를 고정합니다.
np.random.seed(SEED)
# PyTorch의 CPU 난수 시드를 고정합니다.
torch.manual_seed(SEED)
# GPU를 사용할 수 있으면 GPU(cuda)를 사용하고, 없으면 CPU를 사용합니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 현재 사용 중인 연산 장치를 출력합니다.
print("현재 사용 장치:", device)
URL: UCI 화이트 와인 데이터셋
sep=';'로 구분자 처리
컬럼 이름의 공백을 _로 변경
quality 컬럼을 예측 대상으로 분리
# ============================================================
# 2. 화이트 와인 데이터 불러오기
# ============================================================
# UCI에서 제공하는 화이트 와인 품질 데이터 CSV 파일 주소입니다.
# 이 데이터는 세미콜론(;)으로 컬럼이 구분되어 있습니다.
DATA_URL = "https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv"
# pandas의 read_csv() 함수로 CSV 파일을 읽습니다.
# sep=';'는 컬럼 구분자가 쉼표가 아니라 세미콜론이라는 뜻입니다.
whitewines = pd.read_csv(DATA_URL, sep=';')
# UCI 원본 데이터는 volatile acidity처럼 공백을 포함하므로,
# 초보자가 다루기 쉽게 공백을 밑줄(_)로 바꿉니다.
whitewines.columns = [col.replace(" ", "_") for col in whitewines.columns]
# 데이터의 앞 5행을 출력하여 제대로 읽혔는지 확인합니다.
whitewines.head()
데이터 크기 및 데이터타입을 확인한다.
데이터중 quality컬럼이 얼마나 분포되엉ㅆ는지 확인한다 .
# ============================================================
# 3. 데이터 기본 정보 확인
# ============================================================
# 데이터의 행 개수와 열 개수를 출력합니다.
print("데이터 크기:", whitewines.shape)
# 각 컬럼 이름과 데이터 타입을 확인합니다.
print("\n데이터 정보:")
whitewines.info()
# 숫자형 데이터의 기본 통계량을 확인합니다.
whitewines.describe()# ============================================================
# 4. 품질 점수 분포 확인
# ============================================================
# quality 컬럼은 와인의 품질 점수입니다.
# 점수는 보통 0~10 범위로 설명되지만 실제 데이터에서는 주로 3~9 사이 값이 많습니다.
# 히스토그램을 그려 품질 점수가 어떻게 분포되어 있는지 확인합니다.
plt.figure(figsize=(8, 5))
# bins는 막대 구간 수를 의미합니다.
plt.hist(whitewines["quality"], bins=10)
# 그래프 제목을 설정합니다.
plt.title("White Wine Quality Distribution")
# x축 이름을 설정합니다.
plt.xlabel("Quality Score")
# y축 이름을 설정합니다.
plt.ylabel("Count")
# 그래프를 화면에 표시합니다.
plt.show()
# 품질 점수별 데이터 개수를 출력합니다.
print(whitewines["quality"].value_counts().sort_index())
입력/타겟을 분리한다.
X: quality를 제외한 모든 특성
y: quality
# ============================================================
# 5. 입력 X와 정답 y 분리
# ============================================================
# quality 컬럼은 예측해야 할 정답이므로 입력 데이터에서 제거합니다.
X = whitewines.drop("quality", axis=1)
# quality 컬럼만 따로 분리하여 정답 데이터로 사용합니다.
y = whitewines["quality"]
# 입력 데이터의 컬럼 이름을 확인합니다.
print("입력 특성 목록:")
print(X.columns.tolist())
# 입력 데이터 크기를 확인합니다.
print("\nX 크기:", X.shape)
# 정답 데이터 크기를 확인합니다.
print("y 크기:", y.shape)
train/test 데이터를 분리한다.
앞쪽 3749개 샘플을 훈련 데이터
나머지 1149개를 테스트 데이터
train_test_split을 섞지 않고 인덱스 기준으로 분리
# ============================================================
# 6. 훈련 데이터와 테스트 데이터 분리
# ============================================================
# 0번부터 3748번까지 총 3749개를 훈련용으로 사용합니다.
X_train = X.iloc[:3749].copy()
# 3749번부터 마지막까지 총 1149개를 테스트용으로 사용합니다.
X_test = X.iloc[3749:].copy()
# 정답 데이터도 같은 기준으로 나눕니다.
y_train = y.iloc[:3749].copy()
# 테스트 정답 데이터도 같은 기준으로 나눕니다.
y_test = y.iloc[3749:].copy()
# 훈련 데이터와 테스트 데이터의 크기를 출력합니다.
print("X_train:", X_train.shape)
print("X_test :", X_test.shape)
print("y_train:", y_train.shape)
print("y_test :", y_test.shape)
데이터표준화
standardscaler로 입력 특성을 평균 0, 평균편차 1로 변환한다.
train데이터로 fit한다.
# ============================================================
# 7. 입력 특성 표준화
# ============================================================
# StandardScaler 객체를 생성합니다.
scaler = StandardScaler()
# 훈련 데이터의 평균과 표준편차를 계산하고, 그 기준으로 훈련 데이터를 변환합니다.
X_train_scaled = scaler.fit_transform(X_train)
# 테스트 데이터는 훈련 데이터에서 계산한 평균과 표준편차로만 변환합니다.
# 테스트 데이터 기준으로 다시 fit하면 실제 평가가 왜곡될 수 있습니다.
X_test_scaled = scaler.transform(X_test)
# 표준화된 훈련 데이터의 평균이 0에 가까운지 간단히 확인합니다.
print("표준화 후 훈련 데이터 평균:", X_train_scaled.mean().round(4))
# 표준화된 훈련 데이터의 표준편차가 1에 가까운지 간단히 확인합니다.
print("표준화 후 훈련 데이터 표준편차:", X_train_scaled.std().round(4))
pytorch 모델이 잘 학습할 수 있도록 tensor형태로 변환한다.
# ============================================================
# 8. PyTorch 텐서로 변환
# ============================================================
# 입력 데이터 X_train_scaled를 float32 타입의 PyTorch 텐서로 변환합니다.
X_train_tensor = torch.tensor(X_train_scaled, dtype=torch.float32)
# 테스트 입력 데이터도 float32 텐서로 변환합니다.
X_test_tensor = torch.tensor(X_test_scaled, dtype=torch.float32)
# 정답 데이터 y_train은 1차원 Series이므로 values로 배열을 꺼냅니다.
# view(-1, 1)은 (데이터개수,) 형태를 (데이터개수, 1) 형태로 바꿉니다.
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32).view(-1, 1)
# 테스트 정답 데이터도 같은 방식으로 텐서로 변환합니다.
y_test_tensor = torch.tensor(y_test.values, dtype=torch.float32).view(-1, 1)
# 변환된 텐서의 크기를 확인합니다.
print("X_train_tensor:", X_train_tensor.shape)
print("y_train_tensor:", y_train_tensor.shape)
print("X_test_tensor :", X_test_tensor.shape)
print("y_test_tensor :", y_test_tensor.shape)
tensordataset과 dataloader로 미니배치 학습을 세팅한다.
tensordataset은 입력데이터와 정답데이터를 하나의 묶음으로 만들어준다.
# ============================================================
# 9. DataLoader 생성
# ============================================================
# TensorDataset은 입력 데이터와 정답 데이터를 하나의 묶음으로 만듭니다.
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
# batch_size는 한 번에 모델에 넣을 데이터 개수입니다.
# 예를 들어 batch_size=64이면 64개씩 나누어 학습합니다.
BATCH_SIZE = 64
# DataLoader는 데이터를 batch_size 단위로 나누어 반복해서 꺼내 줍니다.
# shuffle=True는 매 epoch마다 데이터 순서를 섞겠다는 의미입니다.
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
# DataLoader가 몇 개의 미니배치를 만드는지 확인합니다.
print("미니배치 개수:", len(train_loader))
회귀모델을 정의한다 .앞선 실습예재와 아주 흡사하다.
# ============================================================
# 10. PyTorch 회귀 모델 정의
# ============================================================
# nn.Module은 PyTorch에서 모든 신경망 모델의 기본 클래스입니다.
class WineQualityRegressor(nn.Module):
# __init__()은 모델 안에 사용할 층을 정의하는 함수입니다.
def __init__(self, input_dim):
# 부모 클래스 nn.Module의 초기화 기능을 실행합니다.
super(WineQualityRegressor, self).__init__()
# self.network는 여러 층을 순서대로 연결한 신경망입니다.
self.network = nn.Sequential(
# 첫 번째 선형층입니다.
# input_dim은 입력 특성 개수이고, 64는 출력 뉴런 개수입니다.
nn.Linear(input_dim, 64),
# ReLU는 음수는 0으로 바꾸고 양수는 그대로 통과시키는 활성화 함수입니다.
nn.ReLU(),
# Dropout은 일부 뉴런을 임시로 꺼서 과적합을 줄이는 방법입니다.
nn.Dropout(0.2),
# 두 번째 선형층입니다.
# 앞 층의 출력 64개를 받아 32개로 줄입니다.
nn.Linear(64, 32),
# 두 번째 활성화 함수입니다.
nn.ReLU(),
# 최종 출력층입니다.
# 회귀 문제이므로 최종 출력은 품질 점수 1개입니다.
nn.Linear(32, 1)
)
# forward()는 입력 데이터가 모델을 통과하는 순서를 정의합니다.
def forward(self, x):
# 입력 x를 self.network에 넣고 결과를 반환합니다.
return self.network(x)
# 입력 특성 개수는 X_train_tensor의 열 개수입니다.
input_dim = X_train_tensor.shape[1]
# 모델 객체를 생성합니다.
model = WineQualityRegressor(input_dim)
# 모델을 CPU 또는 GPU 장치로 이동합니다.
model = model.to(device)
# 모델 구조를 출력합니다.
print(model)
손실함수 mseloss와 최적화알고리즘 adam을 세팅한다.
meseloss는 평균제곱 오차로 예측값과 실제값 차이를 제곱한뒤 평균을 낸다 .
adam은 계속 반복되는데 가장 많이 사용되는 최적화 알고리즘으로 모델의 가중치를 조금씩 수정해서 손실을 줄인다 .
# ============================================================
# 11. 손실 함수와 최적화 알고리즘 설정
# ============================================================
# MSELoss는 평균제곱오차입니다.
# 예측값과 실제값의 차이를 제곱한 뒤 평균을 냅니다.
criterion = nn.MSELoss()
# Adam은 많이 사용되는 최적화 알고리즘입니다.
# 모델의 가중치를 조금씩 수정하여 손실을 줄입니다.
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 학습 반복 횟수입니다.
# epoch는 전체 훈련 데이터를 한 번 모두 학습하는 단위입니다.
EPOCHS = 200
학습루프
지정한 epoch수만큼 range 반복한다.
마찬가지로 trin모드로 진입해 배치를 for문으로 꺼내가며 배치별 zero_grad() 설정 및 예측값을 계산하고 loss.backward 손실 기준으로 각 가중치의 기울기를 계산하고 이 기울기를 이용해 optimizer.step() 가중치를 업데이트한다.
이 평균손실을 기록해 출력하며 현황을 확인한다 .
# ============================================================
# 12. 모델 학습
# ============================================================
# epoch별 평균 손실을 저장할 리스트입니다.
train_losses = []
# 지정한 epoch 수만큼 반복합니다.
for epoch in range(EPOCHS):
# model.train()은 모델을 학습 모드로 설정합니다.
# Dropout 같은 층은 학습 모드와 평가 모드에서 동작이 다릅니다.
model.train()
# 한 epoch 동안의 손실 합계를 저장할 변수입니다.
epoch_loss = 0.0
# train_loader에서 미니배치 단위로 데이터를 꺼냅니다.
for batch_X, batch_y in train_loader:
# 입력 데이터 batch_X를 CPU 또는 GPU 장치로 이동합니다.
batch_X = batch_X.to(device)
# 정답 데이터 batch_y도 같은 장치로 이동합니다.
batch_y = batch_y.to(device)
# 이전 미니배치에서 계산된 기울기를 초기화합니다.
optimizer.zero_grad()
# 모델에 입력 데이터를 넣어 예측값을 계산합니다.
predictions = model(batch_X)
# 예측값과 실제값의 차이를 손실 함수로 계산합니다.
loss = criterion(predictions, batch_y)
# 손실을 기준으로 각 가중치의 기울기를 계산합니다.
loss.backward()
# 계산된 기울기를 이용해 모델 가중치를 업데이트합니다.
optimizer.step()
# 현재 미니배치 손실에 데이터 개수를 곱해 누적합니다.
epoch_loss += loss.item() * batch_X.size(0)
# 전체 데이터 개수로 나누어 한 epoch의 평균 손실을 계산합니다.
epoch_loss = epoch_loss / len(train_loader.dataset)
# 계산된 평균 손실을 리스트에 저장합니다.
train_losses.append(epoch_loss)
# 20 epoch마다 학습 진행 상황을 출력합니다.
if (epoch + 1) % 20 == 0:
print(f"Epoch [{epoch+1:3d}/{EPOCHS}] - Train MSE Loss: {epoch_loss:.4f}")
위내용을 손실그래프로 출력해 각 학습 진행을 곡선으로 확인한다 .
# ============================================================
# 13. 학습 손실 그래프 출력
# ============================================================
# 그래프 크기를 설정합니다.
plt.figure(figsize=(8, 5))
# epoch별 손실 값을 선 그래프로 표시합니다.
plt.plot(train_losses)
# 그래프 제목을 설정합니다.
plt.title("Training Loss")
# x축 이름을 설정합니다.
plt.xlabel("Epoch")
# y축 이름을 설정합니다.
plt.ylabel("MSE Loss")
# 그래프를 화면에 표시합니다.
plt.show()
model.enval()모드로 들어와 torch.no_grad()로 테스트 예측을 수행하고 예측값과 실제값을 비교한다 .
# ============================================================
# 14. 테스트 데이터 예측
# ============================================================
# model.eval()은 모델을 평가 모드로 설정합니다.
# Dropout이 꺼지고, 평가에 적합한 방식으로 동작합니다.
model.eval()
# torch.no_grad()는 예측 중에는 기울기를 계산하지 않겠다는 의미입니다.
# 평가 시에는 가중치를 업데이트하지 않으므로 메모리를 절약할 수 있습니다.
with torch.no_grad():
# 테스트 입력 데이터를 CPU 또는 GPU 장치로 이동합니다.
X_test_device = X_test_tensor.to(device)
# 모델을 이용하여 테스트 데이터의 품질 점수를 예측합니다.
test_predictions = model(X_test_device)
# 예측 결과를 CPU로 가져오고 numpy 배열로 변환합니다.
test_predictions = test_predictions.cpu().numpy().flatten()
# 실제 정답도 numpy 배열로 변환합니다.
actual_values = y_test.values
# 예측값 앞 10개를 출력합니다.
print("예측값 앞 10개:")
print(test_predictions[:10])
# 실제값 앞 10개를 출력합니다.
print("\n실제값 앞 10개:")
print(actual_values[:10])# ============================================================
# 15. 예측값과 실제값의 요약 통계 비교
# ============================================================
# 예측값을 pandas Series로 변환하여 describe()를 사용할 수 있게 합니다.
pred_series = pd.Series(test_predictions, name="predicted_quality")
# 실제값도 pandas Series로 준비합니다.
actual_series = pd.Series(actual_values, name="actual_quality")
# 예측값의 요약 통계를 출력합니다.
print("예측값 요약 통계:")
print(pred_series.describe())
# 실제값의 요약 통계를 출력합니다.
print("\n실제값 요약 통계:")
print(actual_series.describe())
성능평가.
회귀문제에서 많이 사용하는 평가방법을 확인해보자.
분류는 '맞았다. 틀렸다'를 본다면 회귀는 숫자를 예측한다. 와인품질을 예측할때 실제 품질이 7점이라면 예측 품질 6.8과 같은 원리이다. 즉 상관계수,예측값의 증감 방향이 실제값의 증감 방향과 얼마나 비슷한가를 보는것. pearson correlation 상관계수는 -`~1로 1에 가까울 수록 양의 관계가 강하다 .
mean_absolute_error를 사용해 평균 절대오차, 실제값과 예측값 차이를 절대값으로 바꾼 뒤 평균을 낸 mae를 계산한다 .
mae 평균적으로 몇점 틀렸는가를 확인한다. mae는 작을수록 좋다 .
훈련데이터 평균으로 예측했을때 비교한다.
# ============================================================
# 16. 모델 성능 평가: 상관계수와 MAE
# ============================================================
# pearsonr()은 두 숫자 배열 사이의 상관계수를 계산합니다.
# 상관계수는 -1부터 1까지이며, 1에 가까울수록 양의 관계가 강합니다.
correlation, p_value = pearsonr(test_predictions, actual_values)
# mean_absolute_error()는 평균절대오차 MAE를 계산합니다.
# MAE는 실제값과 예측값의 차이를 절댓값으로 바꾼 뒤 평균을 낸 값입니다.
mae = mean_absolute_error(actual_values, test_predictions)
# 훈련 데이터 품질 점수의 평균을 계산합니다.
train_mean_quality = y_train.mean()
# 모든 테스트 데이터를 평균값 하나로 예측한다고 가정한 기준 모델의 MAE입니다.
baseline_predictions = np.full_like(actual_values, fill_value=train_mean_quality, dtype=np.float32)
# 기준 모델의 MAE를 계산합니다.
baseline_mae = mean_absolute_error(actual_values, baseline_predictions)
# 결과를 출력합니다.
print(f"PyTorch 모델 상관계수: {correlation:.4f}")
print(f"PyTorch 모델 MAE : {mae:.4f}")
print(f"훈련 데이터 평균값 : {train_mean_quality:.4f}")
print(f"평균값 기준 MAE : {baseline_mae:.4f}")
실제값과 예측값을 산점도로 표시해 그래프로 확인한다.
# ============================================================
# 17. 예측값과 실제값 산점도 시각화
# ============================================================
# 그래프 크기를 설정합니다.
plt.figure(figsize=(7, 7))
# 실제값과 예측값을 산점도로 표시합니다.
plt.scatter(actual_values, test_predictions, alpha=0.5)
# x축 이름을 설정합니다.
plt.xlabel("Actual Quality")
# y축 이름을 설정합니다.
plt.ylabel("Predicted Quality")
# 그래프 제목을 설정합니다.
plt.title("Actual vs Predicted Wine Quality")
# 실제값과 예측값이 완전히 같을 때의 기준선을 그립니다.
min_value = min(actual_values.min(), test_predictions.min())
max_value = max(actual_values.max(), test_predictions.max())
plt.plot([min_value, max_value], [min_value, max_value])
# 그래프를 화면에 표시합니다.
plt.show()
예측결과를 표로 확인한다 .
# ============================================================
# 18. 예측 결과 일부 확인
# ============================================================
# 실제값과 예측값을 하나의 DataFrame으로 정리합니다.
result_df = pd.DataFrame({
"actual_quality": actual_values,
"predicted_quality": test_predictions,
})
# 예측 오차를 계산합니다.
result_df["error"] = result_df["actual_quality"] - result_df["predicted_quality"]
# 절대 오차를 계산합니다.
result_df["absolute_error"] = result_df["error"].abs()
# 결과 앞 20개를 확인합니다.
result_df.head(20)
앞서 살펴본 mae를 잘 이해하기 위해 직접 코드를 구현했다 .
실제값과 예측값의 뺼셈 후 절대갑으로 바꾸고 절대값들의 평균을 계산했다 .
# ============================================================
# 19. 사용자 정의 MAE 함수 작성
# ============================================================
# WMAE라는 평균절대오차 계산 함수 구현
def WMAE(actual, predict):
# actual과 predict를 numpy 배열로 변환합니다.
actual = np.array(actual)
predict = np.array(predict)
# 실제값과 예측값의 차이를 절댓값으로 바꾼 뒤 평균을 계산합니다.
return np.mean(np.abs(actual - predict))
# 사용자 정의 함수로 MAE를 다시 계산합니다.
print("WMAE 함수로 계산한 MAE:", WMAE(actual_values, test_predictions))
회귀는 쉽게 말해 원인 x가 변하면 결과 y가 어떻게 변하는지 수식으로 표현하는 것으로 구성요소에는 우리가 예측하고 싶은 값 y 종속변수와 y를 설명하는 입력값 독립변수가 있다. 이 둘이 양수기울기를 가진다면 함께 증가하고 음수면 감소한다.
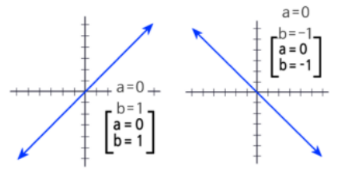
회귀에서 절편 intercept란 x=0일때의 값으로 그래프에서 y축과 만나는 지점이다.
단순선형 회귀는 기본적인 회귀로 직선하나로 데이터 관계를 설명할수있는 가장 기본적인 예측 모델이다.

실제로 우주선의 손상정도를 y라 하고 발사온도를 x라하자.
온도가 오라가면 손상이 어떻게 변하는가를 설명하는것이 회귀이다.
실제 데이터가 점이고 직선이 모델이 예측한 관계라면
회귀는 수많은 직선 중 어떤 직선이 가장 좋은지를 고려한다.
보통 최소제곱법 OLS이 사용되며 예측값과 실제값 차이의 제곱합을 최소로 만드는 직선을 찾는다.
음수/양수 상쇄를 방지하고 큰 오차를 강하게 반영시키기 위해 제곱을 한다 .
오차는 전체 모집단 기준 차이라면
잔차는 우리가 가진 표본 데이터 기준 차이를 말한다.


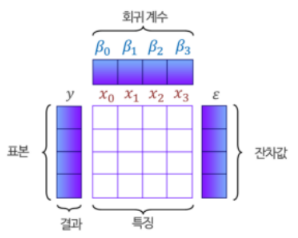
다중선형회귀
여러개의 입력변수로 하나의 결과를 예측하는 직선환장 모델으로
기존 변수가 하나였던 단순 선형회귀를 y = a + bx
변수를 여러개를 사용해 y = β0 + β1x1 + β2x2 + β3x3 + ... 다중선형회귀를 말한다.
여러개의 원인들이 하나의 결과에 영향을 준다는 의미로 집값은 평수+위치+층수+연식 등의 여러 원인이 있다는것을 연상할 수 있다 .
다중선형회귀는 x와 y가 선형관계라는 가정하에 여러 변수들을 대입해 따지지만 현실이 항상 그렇지않을 수 있다 .
또 y = β0 + β1x1 + β2x2 + ... 형태로 모델 형태를 미리 정해야하고 누락데이터문제 혹은 번주형 데이터는 처리가 불가하며 통계지식이 필요하다는 단점이 있다.
다중선형회귀는 가장 자주 쓰이는 기본 모델중 하나로 현실데이터가 대부분 원인 1개가 아니라 여러개의 합이기때문이다. 현실은 비선형이 물론 많고 복잡한 데이터에서는 트리모델 등이 더 잘 맞는 경우가 많으나 단순모델의 경우에 는 다중 선형 회귀를 많이 사용한다. 데이터가 적고 구조가 단순할때 변수영향분석, 통계보고, 논문, 경제분석 등 해석이 중요한 경우 잘 쓰일 수 있는것이다.
샘플코드 regression_model_torch.ipynb를 분석해보자.
의료비를 예측하는 pytorch 회귀모델이다.
pandas, numpy: 데이터 처리
matplotlib, seaborn: 시각화
torch, torch.nn, torch.optim: PyTorch 모델과 학습
* torch.nn은 PyTorch에서 신경망(Neural Network)을 만들기 위한 핵심 모듈
sklearn.model_selection.train_test_split, StandardScaler
sklearn.metrics: MAE, MSE, R2 등 회귀 평가 지표
# ============================================================
# 1. 기본 라이브러리 불러오기
# ============================================================
# pandas는 표 형태의 데이터를 다루기 위한 라이브러리입니다.
# CSV 파일을 읽거나, 데이터프레임을 만들 때 사용합니다.
import pandas as pd
# numpy는 수치 계산을 위한 라이브러리입니다.
# 배열 계산, 평균, 표준편차, 제곱근 계산 등에 사용합니다.
import numpy as np
# matplotlib은 그래프를 그리기 위한 라이브러리입니다.
# 히스토그램, 산점도, 학습 손실 그래프 등을 그릴 때 사용합니다.
import matplotlib.pyplot as plt
# seaborn은 matplotlib 기반의 시각화 라이브러리입니다.
# 상관관계 히트맵, 산점도 행렬 등을 쉽게 그릴 수 있습니다.
import seaborn as sns
# torch는 PyTorch의 핵심 라이브러리입니다.
# Tensor 생성, 자동미분, 신경망 학습에 사용합니다.
import torch
# torch.nn은 신경망 계층, 손실 함수 등을 제공하는 모듈입니다.
import torch.nn as nn
# torch.optim은 Adam, SGD 같은 최적화 알고리즘을 제공합니다.
import torch.optim as optim
# train_test_split은 데이터를 학습용/테스트용으로 나눌 때 사용합니다.
from sklearn.model_selection import train_test_split
# StandardScaler는 입력 변수의 평균을 0, 표준편차를 1로 맞추는 표준화 도구입니다.
from sklearn.preprocessing import StandardScaler
# 회귀 모델 평가 지표를 계산하기 위한 함수들입니다.
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
# Colab에서 실행 결과를 동일하게 만들기 위해 난수를 고정합니다.
# 난수를 고정하면 매번 실행할 때 비슷한 결과를 얻을 수 있습니다.
SEED = 42
np.random.seed(SEED)
torch.manual_seed(SEED)
# GPU가 사용 가능한 경우 GPU를 사용하고, 아니면 CPU를 사용합니다.
# Colab 메뉴: 런타임 > 런타임 유형 변경 > GPU 선택 가능
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("현재 사용 장치:", device)
파일을 여러경로에서 찾고 없으면 공개 url에서 데이터를 가져왔다.
마찬가지로 컬럼 이름을 통일했다.
# ============================================================
# 2. 데이터 불러오기
# ============================================================
# Colab에서는 파일 위치가 다를 수 있으므로 아래 순서로 데이터를 찾습니다.
# 1) /content/insurance_exp.csv
# 2) /content/data/insurance_exp.csv
# 3) 인터넷 공개 데이터셋 URL
#
# 직접 파일을 업로드하려면 Colab 왼쪽 파일 탭에 insurance_exp.csv를 업로드하면 됩니다.
from pathlib import Path
candidate_paths = [
Path("/content/insurance_exp.csv"),
Path("/content/data/insurance_exp.csv"),
Path("insurance_exp.csv"),
Path("data/insurance_exp.csv")
]
csv_path = None
# 후보 경로 중 실제 파일이 존재하는 경로를 찾습니다.
for path in candidate_paths:
if path.exists():
csv_path = path
break
if csv_path is not None:
# 사용자가 업로드한 CSV 파일을 읽습니다.
insurance_exp = pd.read_csv(csv_path)
print("로컬 CSV 파일을 읽었습니다:", csv_path)
else:
# 파일이 없으면 인터넷 공개 예제 데이터를 읽습니다.
# 이 데이터는 의료비 예측 실습에 널리 사용되는 insurance 데이터셋입니다.
url = "https://raw.githubusercontent.com/stedy/Machine-Learning-with-R-datasets/master/insurance.csv"
insurance_exp = pd.read_csv(url)
print("공개 URL에서 예제 데이터를 읽었습니다.")
# 공개 데이터셋에서는 expenses 또는 charges로 되어 있을 수 있으므로 이름을 맞춥니다.
if "charges" in insurance_exp.columns:
insurance_exp = insurance_exp.rename(columns={"charges": "expense"})
if "expenses" in insurance_exp.columns:
insurance_exp = insurance_exp.rename(columns={"expenses": "expense"})
# 공개 데이터셋에서는 smoker, region이라는 이름을 사용할 수 있으므로 이름을 맞춥니다.
if "smoker" in insurance_exp.columns:
insurance_exp = insurance_exp.rename(columns={"smoker": "smoking"})
if "region" in insurance_exp.columns:
insurance_exp = insurance_exp.rename(columns={"region": "regions"})
# 데이터의 앞부분 5개 행을 출력하여 데이터가 잘 읽혔는지 확인합니다.
insurance_exp.head()
데이터 구조를 확인했다.
데이터 크기는 1338개의 샘플과 7개의 변수로 구성된 표이다 .
범주형변수와 숫자형 데이터를 확인 할 수 있다.
결측치는 없다.
각 수치변수에 기초 통계요약을 확인해보면 의료비는 평균보다 중앙값이 높은것으로 보아 소수의 고비용 환자들이 평균을 끌어올리고 있음을 예상할 수 있다.
bmi는 평균이 30으로 의료기준 30이상이 비만이니 데이터 집단 전체가 건강리스크가 높은편임을 알 수 있다 .
age는 중앙값과 평균이 비슷한것으로 보아 특정 연령대에 치우쳐지지않고 안정적인 균형잡힌 분포임을 알 수 있다.
# ============================================================
# 3. 데이터 구조 확인
# ============================================================
# 데이터프레임의 행과 열 개수를 확인합니다.
# 예: (1338, 7)은 1338행, 7열이라는 의미입니다.
print("데이터 크기:", insurance_exp.shape)
# 각 컬럼의 자료형과 결측치 여부를 확인합니다.
# object는 문자형 또는 범주형 데이터일 가능성이 높습니다.
insurance_exp.info()
# 수치형 데이터의 요약 통계를 확인합니다.
# count: 데이터 개수
# mean: 평균
# std: 표준편차
# min: 최솟값
# 25%, 50%, 75%: 사분위수
# max: 최댓값
insurance_exp.describe()데이터 크기: (1338, 7)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1338 entries, 0 to 1337
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 age 1338 non-null int64
1 sex 1338 non-null object
2 bmi 1338 non-null float64
3 children 1338 non-null int64
4 smoking 1338 non-null object
5 regions 1338 non-null object
6 expense 1338 non-null float64
dtypes: float64(2), int64(2), object(3)
memory usage: 73.3+ KBage bmi children expense
count 1338.000000 1338.000000 1338.000000 1338.000000
mean 39.207025 30.663397 1.094918 13270.422265
std 14.049960 6.098187 1.205493 12110.011237
min 18.000000 15.960000 0.000000 1121.873900
25% 27.000000 26.296250 0.000000 4740.287150
50% 39.000000 30.400000 1.000000 9382.033000
75% 51.000000 34.693750 2.000000 16639.912515
max 64.000000 53.130000 5.000000 63770.428010
의료비만 따로 추출해 확인해보자 .
# ============================================================
# 4. 종속변수 expense 요약 통계 확인
# ============================================================
# expense는 예측하려는 대상값입니다.
# 즉, 의료보험으로 청구된 개인별 의료비입니다.
print("의료비 expense 요약 통계")
print(insurance_exp["expense"].describe())
# 평균과 중앙값을 따로 출력합니다.
# 평균이 중앙값보다 크면 오른쪽으로 긴 꼬리를 가진 분포일 가능성이 있습니다.
print("\n평균:", insurance_exp["expense"].mean())
print("중앙값:", insurance_exp["expense"].median())
의료비만 히스토그램을 만들어보자.
# ============================================================
# 5. 의료비 분포 히스토그램
# ============================================================
# 히스토그램은 데이터가 어떤 값에 많이 몰려 있는지 보여줍니다.
# 의료비 데이터는 일반적으로 오른쪽으로 긴 꼬리를 가집니다.
# 즉, 대부분은 낮거나 중간 의료비이지만 일부 사람은 매우 높은 의료비가 발생합니다.
plt.figure(figsize=(8, 5))
# bins는 막대 개수입니다.
plt.hist(insurance_exp["expense"], bins=30, edgecolor="black")
plt.title("Expense Distribution")
plt.xlabel("Expense")
plt.ylabel("Count")
plt.show()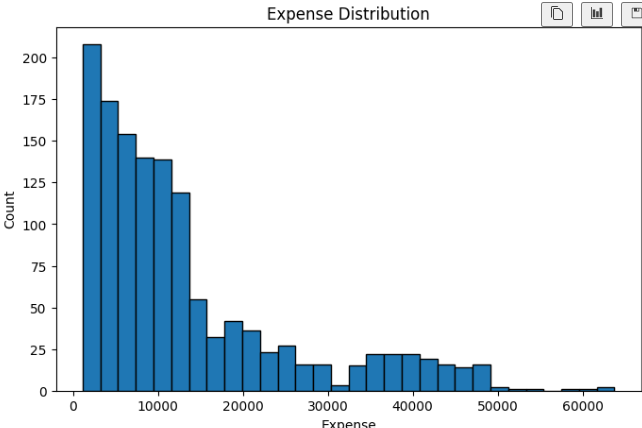
범주형 변수를 확인해보자.
# ============================================================
# 6. 범주형 변수 확인
# ============================================================
# 성별, 흡연 여부, 지역은 숫자가 아니라 문자로 표현된 범주형 변수입니다.
# 머신러닝 모델에 넣기 위해서는 나중에 숫자형으로 변환해야 합니다.
categorical_cols = []
# object 타입 컬럼은 보통 문자열/범주형 변수입니다.
for col in insurance_exp.columns:
if insurance_exp[col].dtype == "object":
categorical_cols.append(col)
print("범주형 컬럼:", categorical_cols)
# 각 범주형 컬럼의 값 개수를 확인합니다.
for col in categorical_cols:
print("\n컬럼명:", col)
print(insurance_exp[col].value_counts())
수치형도 확인해보자.
이때 변수들을 미리 설정해 리스트에 넣고 상관관계를 계산해볼 수 있다.
insureance_exp.corr() 상관관계를 확인한다.
bmi가 높을수록 expense가 증가경향이있으나 ate보다 영향력이 낮다.
children 자녀수는 거의 관련이 없다.
그 외 변수하고는 거의 독립적으로 관계자체가 없다. 약한 영향들의 합이라고 알 수 있겠다 .
# ============================================================
# 7. 수치형 변수 간 상관관계 확인
# ============================================================
# 상관계수는 두 변수 사이의 관계 강도를 나타냅니다.
# 1에 가까우면 강한 양의 관계,
# -1에 가까우면 강한 음의 관계,
# 0에 가까우면 관계가 약하다는 의미입니다.
numeric_cols = ["age", "bmi", "children", "expense"]
correlation_matrix = insurance_exp[numeric_cols].corr()
print(correlation_matrix) age bmi children expense
age 1.000000 0.109272 0.042469 0.299008
bmi 0.109272 1.000000 0.012759 0.198341
children 0.042469 0.012759 1.000000 0.067998
expense 0.299008 0.198341 0.067998 1.000000
위의 내용을 히트맵으로 확인해보자.
# ============================================================
# 8. 상관관계 히트맵 시각화
# ============================================================
# 히트맵은 상관관계를 색상으로 쉽게 확인할 수 있게 해줍니다.
# 값이 클수록 두 변수의 관계가 강합니다.
plt.figure(figsize=(7, 5))
sns.heatmap(
correlation_matrix,
annot=True, # 각 칸에 숫자 표시
fmt=".2f", # 소수점 둘째 자리까지 표시
cmap="coolwarm" # 색상 팔레트
)
plt.title("Correlation Matrix")
plt.show()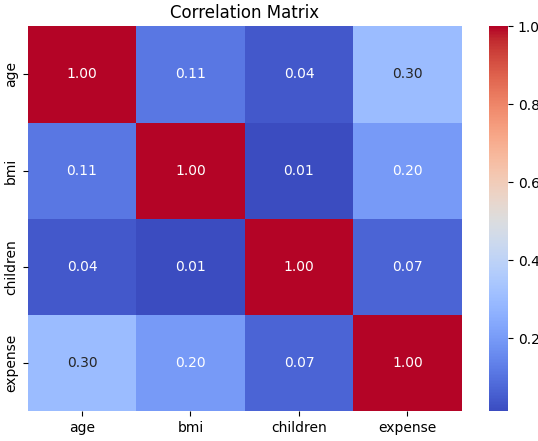
산점도로도 확인해보자 .
# ============================================================
# 9. 산점도 행렬 확인
# ============================================================
# 산점도 행렬은 여러 수치형 변수 간 관계를 한 번에 보여줍니다.
# 예를 들어 age와 expense가 함께 증가하는지,
# bmi와 expense가 어떤 관계인지 확인할 수 있습니다.
sns.pairplot(insurance_exp[numeric_cols])
plt.show()
전처리
입력변수를 지정해 리스트레 할당한다.
타겟은 expense.
get_dummies()로 범주형 데이터를 숫자로 바꿔주는 원핫인코딩을 사용한다.
# ============================================================
# 10. 기본 모델용 데이터 전처리
# ============================================================
# 기본 모델에서는 원본 변수만 사용합니다.
# 입력 변수 X와 정답 y를 분리합니다.
# X는 모델이 학습할 입력 데이터입니다.
# y는 모델이 맞혀야 하는 정답 의료비입니다.
X_basic = insurance_exp[["age", "children", "bmi", "sex", "smoking", "regions"]]
y = insurance_exp["expense"]
# get_dummies는 문자형 범주 변수를 0과 1로 변환합니다.
# 예: sex = male/female → sex_male 컬럼 생성
# drop_first=True는 기준 범주 하나를 제거하여 중복 정보를 줄입니다.
X_basic_encoded = pd.get_dummies(X_basic, drop_first=True)
print("변환 전 컬럼:")
print(X_basic.columns.tolist())
print("\n변환 후 컬럼:")
print(X_basic_encoded.columns.tolist())
X_basic_encoded.head()
학습데이터와 테스트 데이터를 분리한다 .
# ============================================================
# 11. 학습 데이터와 테스트 데이터 분리
# ============================================================
# 학습 데이터는 모델이 공부하는 데이터입니다.
# 테스트 데이터는 공부가 끝난 뒤 실력을 평가하는 데이터입니다.
#
# test_size=0.2는 전체 데이터 중 20%를 테스트용으로 사용한다는 의미입니다.
# random_state는 데이터를 나누는 방식을 고정하여 재현 가능하게 합니다.
X_train_basic, X_test_basic, y_train, y_test = train_test_split(
X_basic_encoded,
y,
test_size=0.2,
random_state=SEED
)
print("학습 입력 데이터 크기:", X_train_basic.shape)
print("테스트 입력 데이터 크기:", X_test_basic.shape)
print("학습 정답 데이터 크기:", y_train.shape)
print("테스트 정답 데이터 크기:", y_test.shape)
10-~60인 age, 15 ~50인 bmi를 모델 학습이 불안정하지않도록 standardscaler를 활용해 표준화한다.
정답y도 마찬가지로 standardscaler 로 표준화한다.
이때 마찬가지로 학습용만 입력(X)과 정답(y)을 보고 규칙을 학습, fit한다 .
# ============================================================
# 12. 데이터 표준화
# ============================================================
# 신경망은 입력 변수들의 값 범위가 크게 다르면 학습이 불안정할 수 있습니다.
# 예를 들어 age는 10~60 정도이고, bmi는 15~50 정도입니다.
# 그래서 평균 0, 표준편차 1이 되도록 표준화합니다.
#
# 주의:
# 학습 데이터에는 fit_transform을 사용합니다.
# 테스트 데이터에는 transform만 사용합니다.
# 테스트 데이터로 평균과 표준편차를 다시 계산하면 데이터 누수 문제가 발생합니다.
x_scaler_basic = StandardScaler()
X_train_basic_scaled = x_scaler_basic.fit_transform(X_train_basic)
X_test_basic_scaled = x_scaler_basic.transform(X_test_basic)
# 정답 y도 표준화합니다.
# 의료비는 값의 범위가 크기 때문에 y를 표준화하면 신경망 학습이 더 안정적입니다.
y_scaler = StandardScaler()
y_train_scaled = y_scaler.fit_transform(y_train.values.reshape(-1, 1))
y_test_scaled = y_scaler.transform(y_test.values.reshape(-1, 1))
print("X_train 표준화 후 평균:", X_train_basic_scaled.mean().round(4))
print("X_train 표준화 후 표준편차:", X_train_basic_scaled.std().round(4))
이 scaled 된 배열들을 torch.tensor 로 변환한다 .
# ============================================================
# 13. NumPy 배열을 PyTorch Tensor로 변환
# ============================================================
# PyTorch 모델은 pandas DataFrame이나 NumPy 배열을 직접 학습하지 않습니다.
# Tensor라는 PyTorch 전용 자료형으로 변환해야 합니다.
#
# dtype=torch.float32는 신경망 학습에 적합한 실수형 자료형입니다.
# to(device)는 CPU 또는 GPU로 데이터를 이동시키는 코드입니다.
X_train_basic_tensor = torch.tensor(X_train_basic_scaled, dtype=torch.float32).to(device)
X_test_basic_tensor = torch.tensor(X_test_basic_scaled, dtype=torch.float32).to(device)
y_train_tensor = torch.tensor(y_train_scaled, dtype=torch.float32).to(device)
y_test_tensor = torch.tensor(y_test_scaled, dtype=torch.float32).to(device)
print("X_train_basic_tensor 크기:", X_train_basic_tensor.shape)
print("y_train_tensor 크기:", y_train_tensor.shape)
입력층 - 은닉 - relu - 은닉 - relu - 출력층으로 모델링했다.
super().__init__() 부모 클래스 nn.Module의 초기화 기능을 실행한다.
nn.Linear(입력변수들, 64) 다음은 64, 32 다음은 32, 1 로 예측값을 출력한다 .
nn.ReLU() 활성함수를 만든다.
forward에서 이 linear과 relu를 섞어가며 나열한다. return 최종예측값 x하도록 세팅해놓는다.
# ============================================================
# 14. PyTorch 회귀 모델 클래스 정의
# ============================================================
# nn.Module은 PyTorch에서 신경망 모델을 만들 때 상속하는 기본 클래스입니다.
# 이 모델은 선형회귀를 확장한 간단한 신경망 회귀 모델입니다.
#
# 구조:
# 입력층 → 은닉층1 → ReLU → 은닉층2 → ReLU → 출력층
#
# 출력층은 의료비 예측값 1개를 출력하므로 마지막 출력 크기는 1입니다.
class ExpenseRegressionModel(nn.Module):
def __init__(self, input_dim):
# 부모 클래스 nn.Module의 초기화 기능을 실행합니다.
super().__init__()
# 첫 번째 완전연결층입니다.
# input_dim개의 입력 변수를 받아 64개의 값을 출력합니다.
self.fc1 = nn.Linear(input_dim, 64)
# 두 번째 완전연결층입니다.
# 64개의 값을 받아 32개의 값을 출력합니다.
self.fc2 = nn.Linear(64, 32)
# 마지막 출력층입니다.
# 32개의 값을 받아 의료비 예측값 1개를 출력합니다.
self.fc3 = nn.Linear(32, 1)
# ReLU 활성함수입니다.
# 음수는 0으로 만들고 양수는 그대로 통과시킵니다.
# 신경망이 비선형 관계를 학습할 수 있도록 도와줍니다.
self.relu = nn.ReLU()
def forward(self, x):
# 입력 데이터를 첫 번째 층에 통과시킵니다.
x = self.fc1(x)
# 첫 번째 층의 결과에 ReLU 활성함수를 적용합니다.
x = self.relu(x)
# 두 번째 층에 통과시킵니다.
x = self.fc2(x)
# 두 번째 층의 결과에 ReLU 활성함수를 적용합니다.
x = self.relu(x)
# 마지막 출력층에서 최종 예측값을 계산합니다.
x = self.fc3(x)
# 최종 예측값을 반환합니다.
return x
train_model 함수를 만들었다.
바로 앞서서 만들었던 신경망 expenseregressionModel 모델을 생성했다.
nn.MSELoss 손실함수를 구한다.
optimixer 가장 많이 쓰이는 최적화 방법 adam을 이용해 세팅했다.
for epoch in 으로 model.train() 반복하되 pytorch는 기본적으로 기울기를 누적함으로 optimizer.zero_grad()로 기울기를 초기화했다.
modal에 입력값을 넣었다.
criterion 손실값을 계산한다.
loss.backward 손실값을 기준으로 가중치를 계산해
optimizer.step() 계산된 기울기로 모델 파라미터를 수정한다.
현재 손실값을 리스트에 저장하고 100epoch마다 학습상황을 출력한다.
# ============================================================
# 15. 모델 학습 함수 정의
# ============================================================
# 같은 학습 코드를 기본 모델과 개선 모델에 반복해서 사용할 수 있도록 함수로 만듭니다.
def train_model(X_train_tensor, y_train_tensor, input_dim, epochs=1000, lr=0.001):
# 모델 객체를 생성합니다.
model = ExpenseRegressionModel(input_dim=input_dim).to(device)
# MSELoss는 회귀 문제에서 많이 사용하는 손실 함수입니다.
# 예측값과 실제값 차이를 제곱한 뒤 평균을 계산합니다.
criterion = nn.MSELoss()
# Adam은 많이 사용하는 최적화 알고리즘입니다.
# 모델의 가중치를 손실값이 줄어드는 방향으로 자동 수정합니다.
optimizer = optim.Adam(model.parameters(), lr=lr)
# epoch별 손실값을 저장할 리스트입니다.
loss_history = []
# 지정한 epoch 수만큼 반복 학습합니다.
for epoch in range(epochs):
# 모델을 학습 모드로 설정합니다.
model.train()
# 이전 epoch에서 계산된 기울기를 초기화합니다.
# PyTorch는 기본적으로 기울기를 누적하므로 매번 초기화해야 합니다.
optimizer.zero_grad()
# 앞먹임 단계입니다.
# 입력 데이터를 모델에 넣어 예측값을 계산합니다.
predictions = model(X_train_tensor)
# 손실값을 계산합니다.
# 예측값과 실제 정답값이 얼마나 다른지 계산합니다.
loss = criterion(predictions, y_train_tensor)
# 역전파 단계입니다.
# 손실값을 기준으로 각 가중치의 기울기를 계산합니다.
loss.backward()
# 가중치 업데이트 단계입니다.
# 계산된 기울기를 이용하여 모델 파라미터를 수정합니다.
optimizer.step()
# 현재 손실값을 리스트에 저장합니다.
loss_history.append(loss.item())
# 100 epoch마다 학습 상황을 출력합니다.
if (epoch + 1) % 100 == 0:
print(f"Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.6f}")
# 학습된 모델과 손실 기록을 반환합니다.
return model, loss_history
만든 train_model함수를 활용해 기본모델을 학습시킨다.
# ============================================================
# 16. 기본 모델 학습
# ============================================================
# 입력 변수 개수를 확인합니다.
input_dim_basic = X_train_basic_tensor.shape[1]
# 기본 모델을 학습합니다.
basic_model, basic_loss_history = train_model(
X_train_tensor=X_train_basic_tensor,
y_train_tensor=y_train_tensor,
input_dim=input_dim_basic,
epochs=1000,
lr=0.001
)
누적되 저장시켰던 손실값을 그래프로 시각화 한다.
# ============================================================
# 17. 손실값 그래프 확인
# ============================================================
# 손실값이 점점 감소하면 모델이 정상적으로 학습되고 있다는 뜻입니다.
plt.figure(figsize=(8, 5))
plt.plot(basic_loss_history)
plt.title("Basic Model Training Loss")
plt.xlabel("Epoch")
plt.ylabel("MSE Loss")
plt.show()
model.eval() 학습된 모델을 평가한다.
no_grad로 메모리 사용량을 줄이고
실제 의료비 단위로 해석하기 위해 inverse_transform으로 원래 단위로 되돌린다. 이때 reshape -1은 자동으로 차원크기를 맞추라는 의미이다 . 실제 값도 다시 numpy배열로 변환한다.
평가지료를 계산한다.
# ============================================================
# 18. 회귀 모델 평가 함수 정의
# ============================================================
# 모델 평가를 반복해서 사용할 수 있도록 함수로 만듭니다.
def evaluate_model(model, X_test_tensor, y_test_original, y_scaler, title="Model"):
# 모델을 평가 모드로 전환합니다.
# 평가 모드에서는 Dropout, BatchNorm 등이 학습 방식과 다르게 동작합니다.
model.eval()
# 평가할 때는 기울기 계산이 필요 없습니다.
# torch.no_grad()를 사용하면 메모리 사용량이 줄고 계산이 빨라집니다.
with torch.no_grad():
# 표준화된 예측값을 계산합니다.
pred_scaled = model(X_test_tensor)
# GPU Tensor일 수 있으므로 CPU로 옮긴 뒤 NumPy 배열로 변환합니다.
pred_scaled_np = pred_scaled.cpu().numpy()
# 예측값은 y 표준화가 적용된 값입니다.
# 실제 의료비 단위로 해석하기 위해 inverse_transform으로 원래 단위로 되돌립니다.
pred_original = y_scaler.inverse_transform(pred_scaled_np).reshape(-1)
# 실제값도 NumPy 배열로 변환합니다.
y_true = np.array(y_test_original)
# 평가 지표를 계산합니다.
mae = mean_absolute_error(y_true, pred_original)
mse = mean_squared_error(y_true, pred_original)
rmse = np.sqrt(mse)
r2 = r2_score(y_true, pred_original)
# 실제값과 예측값 사이의 상관계수를 계산합니다.
corr = np.corrcoef(y_true, pred_original)[0, 1]
print(f"========== {title} 평가 결과 ==========")
print(f"MAE : {mae:.2f}")
print(f"MSE : {mse:.2f}")
print(f"RMSE : {rmse:.2f}")
print(f"R2 : {r2:.4f}")
print(f"Corr : {corr:.4f}")
# 결과를 딕셔너리로 반환합니다.
return {
"prediction": pred_original,
"MAE": mae,
"MSE": mse,
"RMSE": rmse,
"R2": r2,
"Corr": corr
}# ============================================================
# 19. 기본 모델 성능 평가
# ============================================================
basic_result = evaluate_model(
model=basic_model,
X_test_tensor=X_test_basic_tensor,
y_test_original=y_test,
y_scaler=y_scaler,
title="Basic PyTorch Regression Model"
)
위값들을 시각화한다.
점 하나가 한사람의 예측결화, x측은 모델이 예측한 의료비, y축은 실제 의료비로 점이 선에 가까울수록 좋은 모델이다 .
# ============================================================
# 20. 실제값과 예측값 시각화
# ============================================================
# x축: 모델이 예측한 의료비
# y축: 실제 의료비
# 점들이 대각선에 가까울수록 예측이 정확합니다.
plt.figure(figsize=(7, 6))
plt.scatter(basic_result["prediction"], y_test, alpha=0.6)
# 대각선 기준선을 그립니다.
# 이 선은 예측값과 실제값이 완전히 같은 위치를 의미합니다.
min_value = min(basic_result["prediction"].min(), y_test.min())
max_value = max(basic_result["prediction"].max(), y_test.max())
plt.plot([min_value, max_value], [min_value, max_value], linestyle="--")
plt.title("Basic Model: Predicted vs Actual")
plt.xlabel("Predicted Expense")
plt.ylabel("Actual Expense")
plt.show()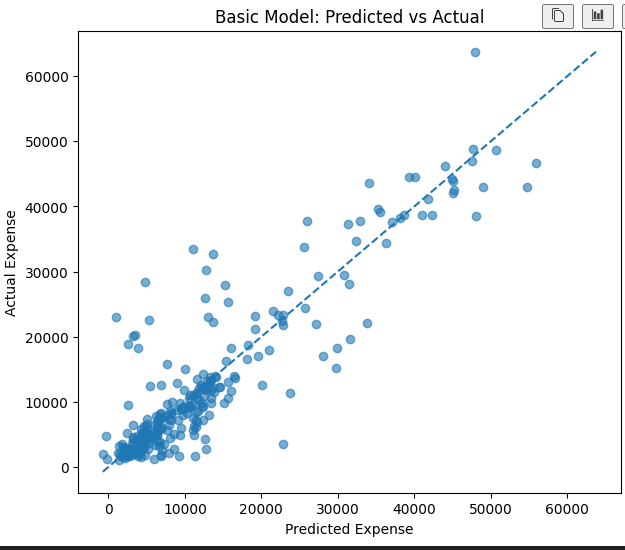
개선할 수 있는 방법을 확인해보자 .
성능을 높이기 위해 새로운 특징을 만들어 입력 데이터를 강화시키고 있다.
기존데이터도 좋지만 더 좋은 정보가 들어간 데이터로 변호나해 모델 성능을 향상시키는것.
나이가 많으면 더 아플 가능성이 증가하고 비만+흡연이면 의료비가 상승한다. 이러한 복잡한 상황은 모델이 알길이 없으니 사람이 힌트를 줄 수 있다. 나이를 제곱해 단순히 많을수록 증가가 아닌 나이가 많아질수록 의료비 증가 속도가 더 빨라지도록 가속효과를 줬다.
bmi는 33을 기준으로 단순 bmi가 아니라 위험한 비만인지 아닌지를 따로 표시하도록 했다.
smoking 변수를 추가해 위험신호를 추가했다.
이들을 다시 get_dummies 원 핫 인코딩을 한다.
# ============================================================
# 21. 개선 모델용 변수 생성
# ============================================================
# 개선 내용:
# 1) age_2 = age^2
# 2) bmi33 = bmi >= 33이면 1, 아니면 0
# 3) bmi33 * smoking 상호작용 효과 추가
insurance_exp_improved = insurance_exp.copy()
# 나이의 제곱 변수를 추가합니다.
# 나이와 의료비의 관계가 완전한 직선이 아닐 수 있으므로 비선형 효과를 반영합니다.
insurance_exp_improved["age_2"] = insurance_exp_improved["age"] ** 2
# BMI가 33 이상이면 1, 아니면 0으로 표시하는 비만 여부 변수를 만듭니다.
insurance_exp_improved["bmi33"] = np.where(insurance_exp_improved["bmi"] >= 33, 1, 0)
# 개선 모델에 사용할 입력 변수입니다.
X_improved = insurance_exp_improved[
["age", "age_2", "children", "bmi", "sex", "bmi33", "smoking", "regions"]
]
# 범주형 변수를 원-핫 인코딩합니다.
X_improved_encoded = pd.get_dummies(X_improved, drop_first=True)
print("개선 모델 입력 컬럼:")
print(X_improved_encoded.columns.tolist())
X_improved_encoded.head()
개선 모델을 따로 만들고 마찬가지로 standardscaler를 거쳐 학습용은 fit, 테스트용은 그냥 transform만.
torch.tensor로 변환후 이미 구현된 함수를 활요해 개서모델을 학습시킨다 .
# ============================================================
# 22. 개선 모델 데이터 분리 및 표준화
# ============================================================
# 기본 모델과 같은 y를 사용합니다.
# 같은 random_state를 사용하여 비교가 가능하도록 합니다.
X_train_improved, X_test_improved, y_train_improved, y_test_improved = train_test_split(
X_improved_encoded,
y,
test_size=0.2,
random_state=SEED
)
# 개선 모델용 입력 데이터 표준화 객체입니다.
x_scaler_improved = StandardScaler()
X_train_improved_scaled = x_scaler_improved.fit_transform(X_train_improved)
X_test_improved_scaled = x_scaler_improved.transform(X_test_improved)
# y는 기본 모델에서 사용한 y_scaler와 동일하게 새로 맞춰도 됩니다.
# 여기서는 학습 데이터가 동일한 분할이므로 다시 생성해도 같은 방식입니다.
y_scaler_improved = StandardScaler()
y_train_improved_scaled = y_scaler_improved.fit_transform(y_train_improved.values.reshape(-1, 1))
y_test_improved_scaled = y_scaler_improved.transform(y_test_improved.values.reshape(-1, 1))
# PyTorch Tensor로 변환합니다.
X_train_improved_tensor = torch.tensor(X_train_improved_scaled, dtype=torch.float32).to(device)
X_test_improved_tensor = torch.tensor(X_test_improved_scaled, dtype=torch.float32).to(device)
y_train_improved_tensor = torch.tensor(y_train_improved_scaled, dtype=torch.float32).to(device)
y_test_improved_tensor = torch.tensor(y_test_improved_scaled, dtype=torch.float32).to(device)
print("개선 모델 학습 데이터 크기:", X_train_improved_tensor.shape)# ============================================================
# 23. 개선 모델 학습
# ============================================================
input_dim_improved = X_train_improved_tensor.shape[1]
improved_model, improved_loss_history = train_model(
X_train_tensor=X_train_improved_tensor,
y_train_tensor=y_train_improved_tensor,
input_dim=input_dim_improved,
epochs=1000,
lr=0.001
)
손실그래프 재확인, 손실그래프는 조금 비슷해보인다 .
# ============================================================
# 24. 개선 모델 손실 그래프
# ============================================================
plt.figure(figsize=(8, 5))
plt.plot(improved_loss_history)
plt.title("Improved Model Training Loss")
plt.xlabel("Epoch")
plt.ylabel("MSE Loss")
plt.show()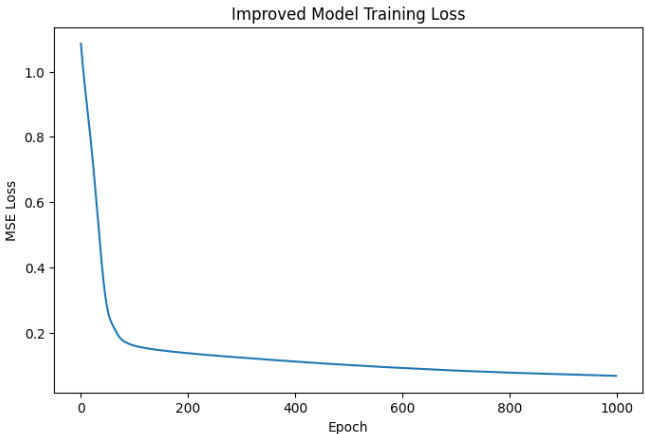
개선모델 재 성능평가 이또한 만들어놓은 함수를 활용한다 .
# ============================================================
# 25. 개선 모델 성능 평가
# ============================================================
improved_result = evaluate_model(
model=improved_model,
X_test_tensor=X_test_improved_tensor,
y_test_original=y_test_improved,
y_scaler=y_scaler_improved,
title="Improved PyTorch Regression Model"
)
기존과 개선모델을 직접 성능을 비교해보자 . 조금 더 오른것을 확인 할 수 있다
# ============================================================
# 26. 기본 모델과 개선 모델 성능 비교
# ============================================================
comparison = pd.DataFrame({
"Model": ["Basic Model", "Improved Model"],
"MAE": [basic_result["MAE"], improved_result["MAE"]],
"RMSE": [basic_result["RMSE"], improved_result["RMSE"]],
"R2": [basic_result["R2"], improved_result["R2"]],
"Correlation": [basic_result["Corr"], improved_result["Corr"]]
})
comparisonModel MAE RMSE R2 Correlation
0 Basic Model 3307.566106 5511.181704 0.804358 0.899472
1 Improved Model 3173.772789 5093.336688 0.832900 0.914050
산점도로도 다시 확인해보자 .
# ============================================================
# 27. 개선 모델 실제값과 예측값 시각화
# ============================================================
plt.figure(figsize=(7, 6))
plt.scatter(improved_result["prediction"], y_test_improved, alpha=0.6)
min_value = min(improved_result["prediction"].min(), y_test_improved.min())
max_value = max(improved_result["prediction"].max(), y_test_improved.max())
plt.plot([min_value, max_value], [min_value, max_value], linestyle="--")
plt.title("Improved Model: Predicted vs Actual")
plt.xlabel("Predicted Expense")
plt.ylabel("Actual Expense")
plt.show()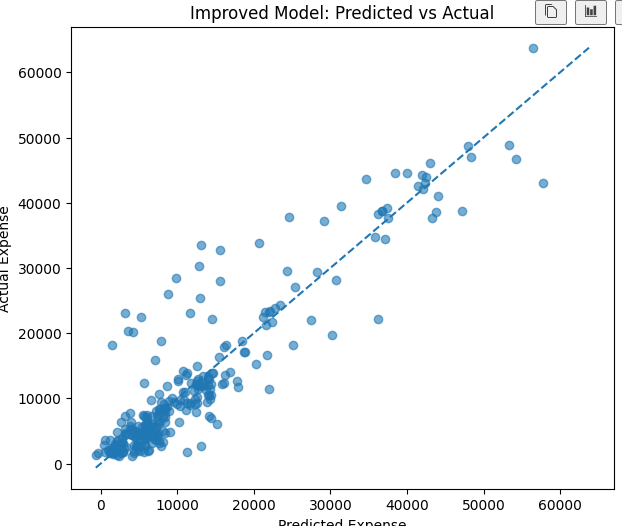
predict_new_patient 함수를 생성한다.
개선모델에서 사용한 컬럼을 정리하고
다시 전처리를 통쨰로 다시 적용하는 함수를 만들었다.
# ============================================================
# 28. 새 환자 데이터 예측 함수 만들기
# ============================================================
# predict()로 새 환자의 의료비를 예측했습니다.
# 주의:
# 새 데이터도 학습 데이터와 같은 전처리 과정을 거쳐야 합니다.
# 즉, age_2 생성, bmi33 생성, 원-핫 인코딩, 컬럼 순서 맞춤, 표준화가 필요합니다.
def predict_new_patient(model, patient_dict, train_columns, x_scaler, y_scaler):
# 딕셔너리 형태의 새 환자 정보를 데이터프레임으로 변환합니다.
patient_df = pd.DataFrame([patient_dict])
# 개선 모델에서 사용한 파생 변수를 똑같이 생성합니다.
patient_df["age_2"] = patient_df["age"] ** 2
patient_df["bmi33"] = np.where(patient_df["bmi"] >= 33, 1, 0)
# 개선 모델에서 사용한 컬럼 순서로 정리합니다.
patient_df = patient_df[
["age", "age_2", "children", "bmi", "sex", "bmi33", "smoking", "regions"]
]
# 범주형 변수를 원-핫 인코딩합니다.
patient_encoded = pd.get_dummies(patient_df, drop_first=True)
# 학습 데이터에 있던 컬럼과 새 데이터의 컬럼을 맞춥니다.
# 새 데이터에 없는 컬럼은 0으로 채웁니다.
patient_encoded = patient_encoded.reindex(columns=train_columns, fill_value=0)
# 학습 데이터 기준으로 표준화합니다.
patient_scaled = x_scaler.transform(patient_encoded)
# PyTorch Tensor로 변환합니다.
patient_tensor = torch.tensor(patient_scaled, dtype=torch.float32).to(device)
# 모델을 평가 모드로 설정합니다.
model.eval()
# 새 데이터 예측에는 기울기 계산이 필요 없습니다.
with torch.no_grad():
pred_scaled = model(patient_tensor)
# 표준화된 예측값을 실제 의료비 단위로 되돌립니다.
pred_original = y_scaler.inverse_transform(pred_scaled.cpu().numpy())
# 숫자 하나만 반환합니다.
return pred_original[0][0]
임의의 새환자를 만들어 예측하게했다.
# ============================================================
# 29. 새 환자 의료비 예측
# ============================================================
# 코드 예시 1:
# 33세, BMI 33, 자녀 2명, 남성, 비흡연, northeast 지역
patient_1 = {
"age": 33,
"children": 2,
"bmi": 33,
"sex": "male",
"smoking": "no",
"regions": "northeast"
}
pred_1 = predict_new_patient(
model=improved_model,
patient_dict=patient_1,
train_columns=X_improved_encoded.columns,
x_scaler=x_scaler_improved,
y_scaler=y_scaler_improved
)
print("환자 1 예상 의료비:", round(pred_1, 2))
다른 조건으로도 출력해보자.
# ============================================================
# 30. 추가 환자 예측 예시
# ============================================================
# 코드 예시 2:
# 33세, BMI 33, 자녀 2명, 여성, 비흡연, northeast 지역
patient_2 = {
"age": 33,
"children": 2,
"bmi": 33,
"sex": "female",
"smoking": "no",
"regions": "northeast"
}
pred_2 = predict_new_patient(
model=improved_model,
patient_dict=patient_2,
train_columns=X_improved_encoded.columns,
x_scaler=x_scaler_improved,
y_scaler=y_scaler_improved
)
print("환자 2 예상 의료비:", round(pred_2, 2))
# 코드 예시 3:
# 33세, BMI 33, 자녀 0명, 여성, 비흡연, northeast 지역
patient_3 = {
"age": 33,
"children": 0,
"bmi": 33,
"sex": "female",
"smoking": "no",
"regions": "northeast"
}
pred_3 = predict_new_patient(
model=improved_model,
patient_dict=patient_3,
train_columns=X_improved_encoded.columns,
x_scaler=x_scaler_improved,
y_scaler=y_scaler_improved
)
print("환자 3 예상 의료비:", round(pred_3, 2))
완료.
로지스틱 회귀
입력데이터를 선형으로 계산한뒤 결과를 확률로 바꿔서 분류한다.
회귀처럼 계산하지만 결과는 분류다. yes no 문제에 많이 쓰인다 .
그럼 왜 트리를 사용하지않고 굳이 로지스틱 회귀모델도 생긴걸까?
의사결정 트리는 규칙을 자동으로 만들며 데이터 공간을 계속 잘라 구역으로 나눈다 .그에 반해 로지스틱 회귀는 모든 변수를 한번에 계산해 결과를 확률로 표현하게 되는데 트리는 데이터 하나하나에 맞춘 복잡한 규칙을 생성함으로 과적합에 매우 취약하다. 로지스틱은 동시에 tree처럼 끊기는 구조가 아닌 부드러운 확률 변화로 해석이 매우 쉽고 어떤 변수가 결과에 얼마나 영향를 주는지가 명확하다. 트리는 데이터가 적으면 흔들림이 크지만 로지스틱은 비교적 안정적이다 .
로지스틱 회귀는 모든 입력에 값을 그대로 쓰지않고 시그모이드 함수를 사용하는데 0~1 사이의 확률을 말한다. 입력데이터에 가중치를 곱하고 편향을 더해서 각 클래스의 점수를 계산한다.
로지스틱 회귀는 선형모델로 1개로 끝나지만 신경망은 선형 + 비선형을 여러층 쌓은 모델이다 .
신경망이 항상 더 좋은것이 아니다. 데이터가 적거나 단순할시 망가질 수있다. 오버피팅. 훈련데이터는 완벽하게 맞추지만 새로운 데이터는 못맞추는 상태 즉 단순한 모델일경우 로지스틱 회귀는 직선평면만 가능해 과하게 외우리가 어려워오버피팅 위험이 낮다.
이 신경망과 반대되는 단순한 로지스틱 회귀를 샘플코드 iris_logistric_regression_pytorch를 분석해보자.
import
PyTorch는 신경망 모델 구성과 학습에 사용되고
sklearn은 데이터셋 로딩과 전처리 및 평가 지표 계산에 사용된다
pandas와 numpy는 데이터 처리
matplotlib은 시각화를 위한 도구로 전체 머신러닝 실습 환경을 구성한다.
cpu gpu 등 실행장치를 설정한다.
# ============================================================
# 1. 기본 라이브러리 불러오기
# ============================================================
# PyTorch 핵심 라이브러리입니다.
# Tensor 연산, GPU 연산, 모델 학습에 사용합니다.
import torch
# torch.nn은 신경망 계층, 손실 함수 등을 제공하는 모듈입니다.
import torch.nn as nn
# torch.optim은 SGD, Adam 같은 최적화 알고리즘을 제공하는 모듈입니다.
import torch.optim as optim
# sklearn.datasets는 실습용 내장 데이터셋을 제공합니다.
# load_iris()는 붓꽃 분류 실습용 Iris 데이터셋을 불러옵니다.
from sklearn.datasets import load_iris
# train_test_split은 전체 데이터를 학습용과 테스트용으로 나누는 함수입니다.
from sklearn.model_selection import train_test_split
# StandardScaler는 입력 데이터의 평균을 0, 표준편차를 1로 맞추는 표준화 도구입니다.
from sklearn.preprocessing import StandardScaler
# accuracy_score는 분류 정확도를 계산합니다.
# classification_report는 precision, recall, f1-score를 출력합니다.
# confusion_matrix는 실제값과 예측값의 교차표를 만듭니다.
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# pandas는 표 형태의 데이터를 다루기 위해 사용합니다.
import pandas as pd
# numpy는 배열 연산을 위해 사용합니다.
import numpy as np
# matplotlib은 그래프 시각화를 위해 사용합니다.
import matplotlib.pyplot as plt
print("라이브러리 불러오기 완료")# ============================================================
# 2. 실행 장치 설정
# ============================================================
# GPU 사용이 가능하면 cuda를 사용하고, 그렇지 않으면 cpu를 사용합니다.
# Google Colab에서는 런타임 유형을 GPU로 변경하면 cuda 사용이 가능합니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 현재 사용 중인 장치를 출력합니다.
print("사용 장치:", device)
iris 데이터셋 불러오기
# ============================================================
# 3. Iris 데이터셋 불러오기
# ============================================================
# load_iris() 함수로 Iris 데이터셋을 불러옵니다.
# Iris 데이터셋은 붓꽃의 꽃받침, 꽃잎 길이/너비 정보를 이용하여 품종을 분류하는 데이터셋입니다.
iris = load_iris()
# iris.data에는 입력 특성 4개가 들어 있습니다.
# 특성: sepal length, sepal width, petal length, petal width
X = iris.data
# iris.target에는 정답 클래스 번호가 들어 있습니다.
# 0: setosa, 1: versicolor, 2: virginica
y = iris.target
# 품종 이름을 저장합니다.
target_names = iris.target_names
# 특성 이름을 저장합니다.
feature_names = iris.feature_names
# 데이터를 DataFrame으로 변환하여 구조를 보기 쉽게 만듭니다.
df = pd.DataFrame(X, columns=feature_names)
# 정답 라벨 번호 컬럼을 추가합니다.
df["target"] = y
# 정답 라벨 이름 컬럼을 추가합니다.
df["species"] = [target_names[label] for label in y]
# 데이터 앞부분 5개 행을 확인합니다.
df.head()
데이터 기본정보 확인 및 학습데이터와 테스트 데이터 분리
# ============================================================
# 4. 데이터 기본 정보 확인
# ============================================================
# 데이터 크기를 출력합니다.
# X는 입력 데이터, y는 정답 라벨입니다.
print("입력 데이터 X 크기:", X.shape)
print("정답 라벨 y 크기:", y.shape)
# 특성 이름을 출력합니다.
print("특성 이름:", feature_names)
# 클래스 이름을 출력합니다.
print("클래스 이름:", target_names)
# 클래스별 데이터 개수를 확인합니다.
print("클래스별 개수:")
print(df["species"].value_counts())
# 수치형 데이터의 통계 정보를 확인합니다.
df.describe()# ============================================================
# 5. 학습 데이터와 테스트 데이터 분리
# ============================================================
# train_test_split()으로 데이터를 학습용과 테스트용으로 분리합니다.
# test_size=0.2는 전체 데이터의 20%를 테스트 데이터로 사용한다는 의미입니다.
# random_state=42는 실행할 때마다 같은 결과가 나오도록 난수 시드를 고정합니다.
# stratify=y는 각 클래스 비율이 학습/테스트 데이터에 비슷하게 유지되도록 합니다.
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42,
stratify=y
)
# 분리된 데이터 크기를 확인합니다.
print("X_train 크기:", X_train.shape)
print("X_test 크기:", X_test.shape)
print("y_train 크기:", y_train.shape)
print("y_test 크기:", y_test.shape)
standardscaler를 활용해 특성의 값이 영향을 주지않도록 평균 0 표준편차가 1이 되도록 표준화한다.
완료된 데이터를 pytorch에서 일반적으로 사용하는 실수자료형 float32로 torch.tensor 변환
# ============================================================
# 6. 입력 데이터 표준화
# ============================================================
# 로지스틱 회귀는 입력 특성의 스케일 차이에 영향을 받을 수 있습니다.
# 따라서 평균 0, 표준편차 1이 되도록 표준화합니다.
scaler = StandardScaler()
# 학습 데이터 기준으로 평균과 표준편차를 계산하고 변환합니다.
X_train_scaled = scaler.fit_transform(X_train)
# 테스트 데이터는 학습 데이터에서 계산한 평균과 표준편차를 그대로 사용하여 변환합니다.
# 테스트 데이터에 fit_transform을 사용하면 데이터 누수가 발생할 수 있습니다.
X_test_scaled = scaler.transform(X_test)
# 표준화 결과 일부를 확인합니다.
print("표준화 전 첫 번째 학습 데이터:", X_train[0])
print("표준화 후 첫 번째 학습 데이터:", X_train_scaled[0])# ============================================================
# 7. NumPy 배열을 PyTorch Tensor로 변환
# ============================================================
# 입력 데이터는 실수형 Tensor로 변환합니다.
# dtype=torch.float32는 PyTorch 모델 학습에서 가장 일반적으로 사용하는 실수 자료형입니다.
X_train_tensor = torch.tensor(X_train_scaled, dtype=torch.float32).to(device)
X_test_tensor = torch.tensor(X_test_scaled, dtype=torch.float32).to(device)
# 정답 라벨은 정수형 Tensor로 변환합니다.
# CrossEntropyLoss는 정답 라벨이 0, 1, 2 같은 정수 클래스 번호인 LongTensor여야 합니다.
y_train_tensor = torch.tensor(y_train, dtype=torch.long).to(device)
y_test_tensor = torch.tensor(y_test, dtype=torch.long).to(device)
# Tensor 크기를 확인합니다.
print("X_train_tensor:", X_train_tensor.shape)
print("X_test_tensor:", X_test_tensor.shape)
print("y_train_tensor:", y_train_tensor.shape)
print("y_test_tensor:", y_test_tensor.shape)
LogisticRegressionClassifier함수를 생성했다
nn.Module를 상속받아 초기화시킨다.
linear 선형 계층을 정의한다 .forward 함수로 예측값을 생성하여 return하도록 한다.
로지스틱 회귀는 선형층 1개로 이전 회귀모델(선형층여러개, 활성화)보다 좀더 간결한것을 확인 할 수 있다.
PyTorch 코드에서 Linear layer가 1개이고 activation(relu, sigmoid, tanh..)이 없고 출력그대로 softmax없이 logits를 반환하면 로지스틱 회귀라고 판단한다.
# ============================================================
# 8. 로지스틱 회귀 모델 클래스 정의
# ============================================================
class LogisticRegressionClassifier(nn.Module):
# Iris 다중 클래스 분류용 로지스틱 회귀 모델 클래스입니다.
# 로지스틱 회귀는 이름에 '회귀'가 들어가지만 실제로는 분류 문제에 사용하는 알고리즘입니다.
# Iris 데이터셋은 클래스가 3개이므로 출력 노드는 3개입니다.
# CrossEntropyLoss는 내부적으로 Softmax를 포함하므로 forward()에서는 Softmax를 적용하지 않습니다.
def __init__(self, input_dim, output_dim):
# 부모 클래스 nn.Module의 초기화 메서드를 실행합니다.
super().__init__()
# 선형 계층을 정의합니다.
# input_dim: 입력 특성 개수입니다. Iris 데이터셋은 특성이 4개입니다.
# output_dim: 출력 클래스 개수입니다. Iris 품종은 3개입니다.
self.linear = nn.Linear(input_dim, output_dim)
def forward(self, x):
# 입력 x를 선형 계층에 통과시켜 각 클래스에 대한 점수(logit)를 계산합니다.
# logit은 Softmax 적용 전의 원시 점수입니다.
logits = self.linear(x)
# CrossEntropyLoss가 내부에서 Softmax를 처리하므로 logits를 그대로 반환합니다.
return logits
# 입력 특성 개수는 X_train의 컬럼 수입니다.
input_dim = X_train_tensor.shape[1]
# 출력 클래스 개수는 Iris 품종 개수입니다.
output_dim = len(target_names)
# 모델 객체를 생성하고 GPU 또는 CPU로 이동합니다.
model = LogisticRegressionClassifier(input_dim=input_dim, output_dim=output_dim).to(device)
# 모델 구조를 출력합니다.
print(model)
다중 클래스 분류에서 사용하는 대표적인 손실함수 nn.CrossEntropyLoss를 생성한다.
학습률을 적용하는 adam 알고리즘을 적용한다.
# ============================================================
# 9. 손실 함수와 최적화 알고리즘 설정
# ============================================================
# CrossEntropyLoss는 다중 클래스 분류에서 사용하는 대표적인 손실 함수입니다.
# 모델 출력값은 [데이터 개수, 클래스 개수] 형태의 logits여야 합니다.
# 정답값은 [데이터 개수] 형태의 정수 클래스 번호여야 합니다.
criterion = nn.CrossEntropyLoss()
# Adam은 학습률을 적응적으로 조절하는 최적화 알고리즘입니다.
# lr은 learning rate, 즉 학습률입니다.
optimizer = optim.Adam(model.parameters(), lr=0.05)
# 학습 반복 횟수를 설정합니다.
epochs = 500
# 학습 과정의 손실값을 저장할 리스트입니다.
loss_history = []
print("손실 함수와 최적화 알고리즘 설정 완료")
모델을 학습시킨다.
# ============================================================
# 10. 모델 학습
# ============================================================
for epoch in range(epochs):
# 모델을 학습 모드로 설정합니다.
model.train()
# 이전 epoch에서 계산된 기울기를 초기화합니다.
# PyTorch는 기본적으로 기울기를 누적하므로 매 반복마다 초기화해야 합니다.
optimizer.zero_grad()
# 학습 데이터를 모델에 입력하여 예측 점수 logits를 계산합니다.
outputs = model(X_train_tensor)
# 예측값 outputs와 실제 정답 y_train_tensor 사이의 손실을 계산합니다.
loss = criterion(outputs, y_train_tensor)
# 역전파를 수행하여 각 파라미터의 기울기를 계산합니다.
loss.backward()
# 계산된 기울기를 이용하여 모델 파라미터를 업데이트합니다.
optimizer.step()
# 현재 손실값을 리스트에 저장합니다.
loss_history.append(loss.item())
# 50번마다 학습 상태를 출력합니다.
if (epoch + 1) % 50 == 0:
print(f"Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.6f}")
모델을 평가하고 표로 확인한다 .
# ============================================================
# 11. 테스트 데이터로 모델 평가
# ============================================================
# 모델을 평가 모드로 변경합니다.
model.eval()
# 평가 단계에서는 기울기 계산이 필요하지 않습니다.
# torch.no_grad()를 사용하면 메모리 사용량이 줄고 계산이 빨라집니다.
with torch.no_grad():
# 테스트 데이터를 모델에 입력하여 클래스별 점수를 계산합니다.
test_outputs = model(X_test_tensor)
# torch.max(test_outputs, 1)은 각 행에서 가장 큰 값과 그 인덱스를 반환합니다.
# 여기서 인덱스가 예측 클래스 번호입니다.
_, test_predicted = torch.max(test_outputs, dim=1)
# Tensor를 CPU로 이동한 뒤 NumPy 배열로 변환합니다.
y_pred = test_predicted.cpu().numpy()
# 실제 정답도 NumPy 배열로 준비합니다.
y_true = y_test
# 정확도를 계산합니다.
accuracy = accuracy_score(y_true, y_pred)
# 정확도를 출력합니다.
print("테스트 정확도:", accuracy)
# 실제 라벨 번호와 예측 라벨 번호를 품종 이름으로 변환합니다.
y_true_names = target_names[y_true]
y_pred_names = target_names[y_pred]
# 분류 성능 리포트를 출력합니다.
print("분류 리포트:")
print(classification_report(y_true_names, y_pred_names))
# 혼동 행렬을 출력합니다.
print("혼동 행렬:")
print(confusion_matrix(y_true_names, y_pred_names))# ============================================================
# 12. 예측 결과를 표로 확인
# ============================================================
# 테스트 데이터의 원본 입력값을 DataFrame으로 변환합니다.
result_df = pd.DataFrame(X_test, columns=feature_names)
# 실제 품종 이름을 추가합니다.
result_df["actual"] = y_true_names
# 예측 품종 이름을 추가합니다.
result_df["predicted"] = y_pred_names
# 실제값과 예측값이 같은지 여부를 추가합니다.
result_df["correct"] = result_df["actual"] == result_df["predicted"]
# 결과 앞부분을 확인합니다.
result_df.head(10)
새 데이터 예측 함수를 만들어 실행한다 .
# ============================================================
# 13. 새 데이터 예측 함수 만들기
# ============================================================
def predict_iris_species(model, scaler, new_data):
# 새 Iris 데이터를 입력받아 품종을 예측하는 함수입니다.
# model: 학습된 PyTorch 로지스틱 회귀 모델입니다.
# scaler: 학습 데이터 기준으로 fit된 StandardScaler 객체입니다.
# new_data: [sepal length, sepal width, petal length, petal width] 순서의 새 데이터입니다.
# 입력 데이터를 NumPy 배열로 변환합니다.
# reshape(1, -1)은 데이터 1개, 특성 여러 개 형태로 바꿉니다.
new_data_np = np.array(new_data).reshape(1, -1)
# 학습 때 사용한 scaler로 동일하게 표준화합니다.
new_data_scaled = scaler.transform(new_data_np)
# 표준화된 데이터를 PyTorch Tensor로 변환하고 장치로 이동합니다.
new_data_tensor = torch.tensor(new_data_scaled, dtype=torch.float32).to(device)
# 모델을 평가 모드로 설정합니다.
model.eval()
# 예측 과정에서는 기울기 계산을 하지 않습니다.
with torch.no_grad():
# 클래스별 점수 계산
output = model(new_data_tensor)
# 가장 높은 점수를 가진 클래스 번호 선택
_, predicted_class = torch.max(output, dim=1)
# 예측 클래스 번호를 CPU의 NumPy 값으로 변환합니다.
predicted_index = predicted_class.cpu().numpy()[0]
# 클래스 번호를 품종 이름으로 변환합니다.
predicted_name = target_names[predicted_index]
# 예측된 품종 이름을 반환합니다.
return predicted_name
# 예측할 새 데이터입니다.
# 순서: sepal length, sepal width, petal length, petal width
sample_data = [5.1, 3.5, 1.4, 0.2]
# 새 데이터 예측을 실행합니다.
predicted_species = predict_iris_species(model, scaler, sample_data)
# 예측 결과를 출력합니다.
print("입력 데이터:", sample_data)
print("예측 품종:", predicted_species)
학습손실을 시각화해서 확인한다
# ============================================================
# 14. 학습 손실 시각화
# ============================================================
# 그래프 크기를 설정합니다.
plt.figure(figsize=(8, 5))
# epoch별 손실값을 선 그래프로 표시합니다.
plt.plot(loss_history)
# x축 이름을 설정합니다.
plt.xlabel("Epoch")
# y축 이름을 설정합니다.
plt.ylabel("Loss")
# 그래프 제목을 설정합니다.
plt.title("Logistic Regression Training Loss")
# 격자를 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()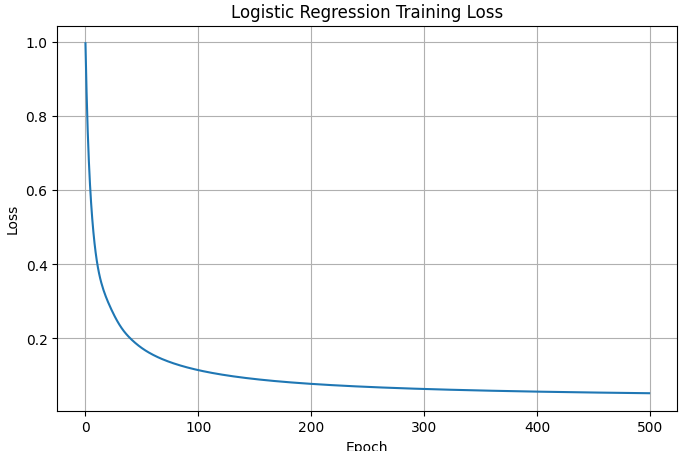
실제 분류를 확인하기 위해 산점도로도확인해본다 .
# ============================================================
# 15. 테스트 데이터 시각화
# ============================================================
# 결과 확인을 쉽게 하기 위해 꽃잎 길이와 꽃잎 너비만 사용하여 산점도를 그립니다.
# 실제 모델은 4개 특성을 모두 사용했지만, 시각화는 2차원으로 표현하기 위해 2개 특성만 사용합니다.
plt.figure(figsize=(8, 6))
# 실제 품종별로 색을 나누어 산점도를 그립니다.
for species_name in target_names:
# 해당 품종 데이터만 선택합니다.
subset = result_df[result_df["actual"] == species_name]
# petal length와 petal width를 기준으로 산점도를 그립니다.
plt.scatter(
subset["petal length (cm)"],
subset["petal width (cm)"],
label=f"Actual {species_name}",
alpha=0.7
)
# x축 이름을 설정합니다.
plt.xlabel("Petal Length (cm)")
# y축 이름을 설정합니다.
plt.ylabel("Petal Width (cm)")
# 그래프 제목을 설정합니다.
plt.title("Iris Test Data by Actual Species")
# 범례를 표시합니다.
plt.legend()
# 격자를 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()
역전파
예측이 틀렸을때 오차를 뒤로 전달하면서 각 가중치를 얼마나 바꿀지 계산한다.
정답이 1이고 예측값이 0.3이라면 모델이 많이 틀렸다는 의미다 .역전파는 단순히 틀렸다로 끝나는 것이 아니라 각 가중치에게 책임을 분배해 '어떤 가중치때문에 틀렸나?' '그 가중치는 얼마나 책임이잇나?' '어느방향으로 수정해야하나?' 핵심 3가지 질문으 가진다 .
단층신경망은 오차를 보면 바로 어느 가중치가 문제인지 알 수 있지만
다층 퍼셉트론, MLP 다층 신경망은 입력 - 은닉층 - 출력 등의 구조로 출력층은 정답과 비교가 가능하나 은닉층은 정답이 없어 어렵다 . 여기서 역전파의 아이디어 출력층 오차를 뒤로 보내면서 각층이 얼마나 기여했는지 계산하는것. 역전파 이후에는 가중치를 조금씩 수정해가며 오차를 줄이는 방향으로 이동한다.
즉 역전파는 오차가 있어야 시작되며 먼저 순전파로 예측을 해야 시작될 수 있다.
순전파(예측) - 역전파(수정) - 반복
이때 출력층은 정답이있음으로 바로 계산이 가능하고 가중치를 업데이트 할 수 있다 .
은닉층은 정답이 없어 직접 오차 계산이 불가함으로 역전파를 사용한다 .
모델이 얼마나 틀렸는지를 숫자로 나타낸 함수가 손실함수이다
MSE 계열 제곱오차 손실 큰 오차를 더 크게 반영하는 방법이라했다 .
손실함수는 모델의 틀린정도 점수이고 이 값은 경사하강법의 기준이 된다.
경사하강법은 손실을 줄이는 방향으로 가중치를 조금씩 수정하는 방법이다 .
한번에 크게 움직이면 최적값을 지나칠 수 있기 때문에 경사하강법은 유용하다 .
역전파를 정리하자면 순전파 - 손실함수 - 역전파 - 경사하강법 이 되겠다.
손실함수가 평가점수로 기준값역할을 하고
역전파가 책임분석을 해 분배하는 과정이며
경사하강법은 실제수정으로 가중치를 어떻게 바꿀지를 적용하는것으로 이해해보자 .
샘플코드 backpropagation_torch_colab을 분석해보자.
import
PyTorch 핵심 라이브러리(torch, nn, optim)
시각화용 matplotlib
난수 시드를 고정하여 학습 결과가 매번 동일하게 재현되도록 설정했다.
# ============================================================
# 1. 기본 라이브러리 불러오기
# ============================================================
# torch는 PyTorch의 핵심 라이브러리입니다.
# Tensor 생성, 자동 미분, 신경망 학습에 사용합니다.
import torch
# torch.nn은 신경망 계층, 손실 함수 등을 제공하는 모듈입니다.
import torch.nn as nn
# torch.optim은 SGD, Adam 같은 최적화 알고리즘을 제공하는 모듈입니다.
import torch.optim as optim
# matplotlib은 학습 과정의 손실값 그래프를 그릴 때 사용합니다.
import matplotlib.pyplot as plt
# 실행할 때마다 같은 결과가 나오도록 난수 시드를 고정합니다.
torch.manual_seed(42)
# 현재 사용 중인 PyTorch 버전을 확인합니다.
print("PyTorch version:", torch.__version__)
미니예제
requires_grad=True x에 대한 기울기, 미분값을 저장하도록 세팅한다.
y = x ** 2 간단한 함수를 정의 후 backward(). 식을 거꾸로 따라가면서 미분을 계산한다. forward는 앞으로계산하면서 x-> y로 y값을 얻어내지만 backward는 y를 기준으로 x가 y에 얼마나 영향을 주는지 계산한다 .
이 코드를 보면서 역전파는 복잡한 계산이아니라 체인룰임을 이해한다.
# ============================================================
# 2. Tensor와 자동 미분 기본 예제
# ============================================================
# x는 학습 대상처럼 미분값을 계산해야 하는 Tensor입니다.
# requires_grad=True는 x에 대한 기울기, 즉 미분값을 저장하겠다는 의미입니다.
x = torch.tensor(2.0, requires_grad=True)
# y = x^2 라는 간단한 함수를 정의합니다.
# x가 2이면 y는 4입니다.
y = x ** 2
# backward()는 y를 x에 대해 미분합니다.
# 수학적으로 y = x^2 이므로 dy/dx = 2x 입니다.
y.backward()
# x.grad에는 dy/dx 값이 저장됩니다.
# x=2이므로 dy/dx = 4입니다.
print("x 값:", x.item())
print("y = x^2 값:", y.item())
print("dy/dx 미분값:", x.grad.item())
앞먹임 계산
앞서한 미니예제를 좀더 현실적으로 로지스틱 회귀 1개 뉴런 형태로 확장해보자.
입력 2개 - 가중치 곱 - 합 - sigmoid - 0~1확률 출력
x = torch.tensor로 특징 2개까지 데이터를 생성했다.
y = 정답값을 만든다 .
마찬가지로 미분값을 저장하도록 세팅.
z = x @ w + b (nn.linear가 하는일을 직접 써봤다)
torch.sigmoid 시그모이드 활성함수를 적용해서 0~1 사이 값으로 출력한다 .
# ============================================================
# 3. 단일 뉴런의 앞먹임 계산
# ============================================================
# 입력값 x를 만듭니다.
# 여기서는 하나의 학습 데이터가 2개의 특성을 가진다고 가정합니다.
x = torch.tensor([[1.0, 2.0]])
# 정답값 y_true를 만듭니다.
# 이 예제에서는 정답이 1이라고 가정합니다.
y_true = torch.tensor([[1.0]])
# 가중치 w를 직접 생성합니다.
# requires_grad=True이므로 역전파 때 w의 기울기가 계산됩니다.
w = torch.tensor([[0.3], [0.7]], requires_grad=True)
# 편향 b를 직접 생성합니다.
# 편향도 학습되는 파라미터이므로 requires_grad=True로 설정합니다.
b = torch.tensor([[0.1]], requires_grad=True)
# 선형 계산을 수행합니다.
# z = x1*w1 + x2*w2 + b 입니다.
z = x @ w + b
# 시그모이드 활성함수를 적용합니다.
# sigmoid는 값을 0과 1 사이로 바꾸므로 이진 분류에서 자주 사용합니다.
y_pred = torch.sigmoid(z)
print("입력값 x:", x)
print("가중치 w:", w)
print("편향 b:", b)
print("선형 계산 z:", z.item())
print("시그모이드 예측값 y_pred:", y_pred.item())
nn.BCELoss 예측값이 0~1 사이의 확률일때 사용하는 이진 분류 손실함수로 criterion 손실값 계산 후 출력
# ============================================================
# 4. 손실 함수 계산
# ============================================================
# BCELoss는 Binary Cross Entropy Loss입니다.
# 예측값이 0~1 사이의 확률일 때 사용하는 이진 분류 손실 함수입니다.
criterion = nn.BCELoss()
# 예측값 y_pred와 정답 y_true를 비교하여 손실값을 계산합니다.
loss = criterion(y_pred, y_true)
# 손실값이 작을수록 예측이 정답에 가깝다는 의미입니다.
print("손실값 loss:", loss.item())
loss.backward 손실값을 기준으로 가중치 계산.
# ============================================================
# 5. 역전파 수행: loss.backward()
# ============================================================
# backward()는 손실값을 기준으로 w와 b의 기울기를 계산합니다.
# 이 기울기는 "손실을 줄이려면 가중치를 어느 방향으로 수정해야 하는가"를 알려줍니다.
loss.backward()
# w.grad는 손실값을 w로 미분한 값입니다.
# 각 가중치가 손실에 얼마나 영향을 주는지 나타냅니다.
print("w의 기울기 w.grad:")
print(w.grad)
# b.grad는 손실값을 b로 미분한 값입니다.
print("b의 기울기 b.grad:")
print(b.grad)
수동코드로 작성하면 이러한 형식이다 .
# ============================================================
# 6. 가중치 수동 업데이트
# ============================================================
# 학습률을 설정합니다.
# 학습률은 한 번에 가중치를 얼마나 수정할지 결정합니다.
learning_rate = 0.1
# torch.no_grad()는 이 블록 안의 계산을 자동 미분 기록에서 제외합니다.
# 가중치를 직접 수정할 때는 기울기 계산 그래프를 만들 필요가 없습니다.
with torch.no_grad():
# w에서 학습률 * 기울기를 빼서 손실이 줄어드는 방향으로 수정합니다.
w -= learning_rate * w.grad
# b도 같은 방식으로 수정합니다.
b -= learning_rate * b.grad
# 수정된 가중치와 편향을 확인합니다.
print("업데이트 후 w:")
print(w)
print("업데이트 후 b:")
print(b)
# 주의: PyTorch는 grad 값을 자동으로 0으로 초기화하지 않습니다.
# 다음 학습 전에 반드시 grad를 0으로 초기화해야 합니다.
w.grad.zero_()
b.grad.zero_()
print("초기화 후 w.grad:")
print(w.grad)
print("초기화 후 b.grad:")
print(b.grad)
실제로는 위처럼 직접 수정하지않고 optimizer를 사용한다.
nn.linear로 특정 2개를 받아 출력 1개를 만드는 선형계층.
nn.BCELoss 손실함수 생성.
SGD 경사하강법 최적화 알고리즘 optimizer 생성
x, y값 재 준비.
optimizer.zero_grad() 이전 기울기 초기화,
z=model(x) 앞먹임, 선형 계산 수행
torch.sigmoid(z) 시그모이드 활성함수 적용
criterion() 손실값 계산
loss.backwar() 역전파 계산.
optmizer.step() 파라미터 수정.
# ============================================================
# 7. nn.Linear와 optimizer를 사용한 단일 뉴런 학습
# ============================================================
# nn.Linear(2, 1)은 입력 특성 2개를 받아 출력 1개를 만드는 선형 계층입니다.
# 내부적으로 weight와 bias를 자동으로 생성합니다.
model = nn.Linear(2, 1)
# BCELoss는 이진 분류 손실 함수입니다.
criterion = nn.BCELoss()
# SGD는 가장 기본적인 경사 하강법 최적화 알고리즘입니다.
# model.parameters()는 모델 안의 모든 학습 가능한 파라미터를 의미합니다.
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 입력값과 정답값을 다시 준비합니다.
x = torch.tensor([[1.0, 2.0]])
y_true = torch.tensor([[1.0]])
# 1번 학습 과정을 직접 단계별로 확인합니다.
optimizer.zero_grad() # 이전 기울기를 초기화합니다.
z = model(x) # 앞먹임: 선형 계산을 수행합니다.
y_pred = torch.sigmoid(z) # 앞먹임: 시그모이드 활성함수를 적용합니다.
loss = criterion(y_pred, y_true) # 손실값을 계산합니다.
loss.backward() # 역전파: 각 파라미터의 기울기를 계산합니다.
# optimizer.step() 전에 기울기를 확인합니다.
print("업데이트 전 손실값:", loss.item())
for name, param in model.named_parameters():
print(name, "값:", param.data)
print(name, "기울기:", param.grad)
optimizer.step() # 계산된 기울기를 이용하여 파라미터를 수정합니다.
# optimizer.step() 후 파라미터가 바뀌었는지 확인합니다.
print("업데이트 후 파라미터")
for name, param in model.named_parameters():
print(name, "값:", param.data)
은닉층이 있을때 다중퍼셉트론을 확인해보좌.
SimpleMLP 함수 생성
init시 linear todtjd, sigmoid 생성
forward에서 은닉층 선형계층에 통과시킨 뒤 sigmoid 함수를 적용, 반복.
# ============================================================
# 8. 은닉층이 있는 다층 퍼셉트론 모델 정의
# ============================================================
# nn.Module은 PyTorch에서 신경망 모델을 만들 때 상속하는 기본 클래스입니다.
class SimpleMLP(nn.Module):
# __init__은 모델에 필요한 계층을 정의하는 부분입니다.
def __init__(self):
# 부모 클래스 nn.Module의 초기화 기능을 실행합니다.
super().__init__()
# 입력층에서 은닉층으로 가는 선형 계층입니다.
# 입력 특성 2개를 받아 은닉 뉴런 3개로 변환합니다.
self.hidden = nn.Linear(2, 3)
# 은닉층에서 출력층으로 가는 선형 계층입니다.
# 은닉 뉴런 3개를 받아 출력 1개를 만듭니다.
self.output = nn.Linear(3, 1)
# 시그모이드 활성함수입니다.
# 값을 0과 1 사이로 변환합니다.
self.sigmoid = nn.Sigmoid()
# forward는 입력 데이터가 모델 안에서 계산되는 순서를 정의합니다.
def forward(self, x):
# 입력값을 은닉층 선형 계층에 통과시킵니다.
hidden_linear = self.hidden(x)
# 은닉층 결과에 시그모이드 활성함수를 적용합니다.
hidden_output = self.sigmoid(hidden_linear)
# 은닉층 출력을 출력층 선형 계층에 통과시킵니다.
output_linear = self.output(hidden_output)
# 최종 출력에 시그모이드 활성함수를 적용합니다.
y_pred = self.sigmoid(output_linear)
# 최종 예측값을 반환합니다.
return y_pred
# 모델 객체를 생성합니다.
model = SimpleMLP()
# 모델 구조를 출력합니다.
print(model)
x, y값 세팅
nn.BCELoss 손실함수, optim.SGD() 최적화 알고리즘 세팅
앞먹임 후 손실값을 계산.
loss.backward 역전파 수행
optimizer.step() 가중치 업데이트
# ============================================================
# 9. 다층 퍼셉트론에서 기울기 확인
# ============================================================
# 입력값 1개와 정답값 1개를 준비합니다.
x = torch.tensor([[1.0, 0.0]])
y_true = torch.tensor([[1.0]])
# 손실 함수와 최적화 알고리즘을 준비합니다.
criterion = nn.BCELoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 이전 기울기를 초기화합니다.
optimizer.zero_grad()
# 앞먹임 단계: 예측값을 계산합니다.
y_pred = model(x)
# 손실값을 계산합니다.
loss = criterion(y_pred, y_true)
# 역전파 전에는 grad가 None입니다.
print("역전파 전")
for name, param in model.named_parameters():
print(name, "grad:", param.grad)
# 역전파를 수행합니다.
loss.backward()
# 역전파 후에는 각 파라미터에 기울기가 계산됩니다.
print("역전파 후")
for name, param in model.named_parameters():
print(name, "grad:")
print(param.grad)
# 계산된 기울기를 이용하여 가중치를 업데이트합니다.
optimizer.step()
print("현재 손실값:", loss.item())
print("현재 예측값:", y_pred.item())
데이터를 만들어 학습시켜보자.
# ============================================================
# 10. XOR 데이터 준비
# ============================================================
# XOR 입력 데이터입니다.
# 두 입력값이 서로 다르면 1, 같으면 0입니다.
X = torch.tensor([
[0.0, 0.0],
[0.0, 1.0],
[1.0, 0.0],
[1.0, 1.0]
])
# XOR 정답 데이터입니다.
y = torch.tensor([
[0.0],
[1.0],
[1.0],
[0.0]
])
print("입력 데이터 X:")
print(X)
print("정답 데이터 y:")
print(y)# ============================================================
# 11. XOR 학습용 다층 퍼셉트론 정의
# ============================================================
class XORNet(nn.Module):
def __init__(self):
super().__init__()
# 입력 2개를 은닉 뉴런 4개로 변환합니다.
# XOR 문제는 비선형 문제이므로 은닉층이 필요합니다.
self.hidden = nn.Linear(2, 4)
# 은닉 뉴런 4개를 출력 1개로 변환합니다.
self.output = nn.Linear(4, 1)
# 시그모이드 활성함수를 사용합니다.
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 입력층 → 은닉층 선형 계산
x = self.hidden(x)
# 은닉층 활성함수 적용
x = self.sigmoid(x)
# 은닉층 → 출력층 선형 계산
x = self.output(x)
# 출력층 활성함수 적용
x = self.sigmoid(x)
return x
# XOR 학습용 모델을 생성합니다.
model = XORNet()
# 이진 분류 손실 함수입니다.
criterion = nn.BCELoss()
# Adam은 SGD보다 안정적으로 학습되는 경우가 많은 최적화 알고리즘입니다.
optimizer = optim.Adam(model.parameters(), lr=0.1)
print(model)# ============================================================
# 12. XOR 모델 학습
# ============================================================
# 손실값 변화를 저장할 리스트입니다.
loss_history = []
# 전체 데이터를 5000번 반복 학습합니다.
# epoch는 전체 학습 데이터를 한 번 학습하는 단위입니다.
for epoch in range(5000):
# 1. 이전 epoch에서 계산된 기울기를 초기화합니다.
optimizer.zero_grad()
# 2. 앞먹임 단계: 모델에 입력 데이터를 넣어 예측값을 계산합니다.
y_pred = model(X)
# 3. 손실 함수 계산: 예측값과 정답의 차이를 계산합니다.
loss = criterion(y_pred, y)
# 4. 역전파 단계: 손실값을 기준으로 모든 가중치의 기울기를 계산합니다.
loss.backward()
# 5. 가중치 업데이트: 계산된 기울기를 이용해 가중치를 수정합니다.
optimizer.step()
# 6. 그래프를 그리기 위해 손실값을 리스트에 저장합니다.
loss_history.append(loss.item())
# 500번마다 학습 상태를 출력합니다.
if (epoch + 1) % 500 == 0:
print(f"Epoch {epoch+1:4d} | Loss: {loss.item():.6f}")
내용을 그래프로 확인
# ============================================================
# 13. 손실값 감소 그래프 확인
# ============================================================
# 그래프 크기를 설정합니다.
plt.figure(figsize=(8, 4))
# epoch별 손실값을 선 그래프로 그립니다.
plt.plot(loss_history)
# 그래프 제목을 설정합니다.
plt.title("XOR Training Loss")
# x축 이름을 설정합니다.
plt.xlabel("Epoch")
# y축 이름을 설정합니다.
plt.ylabel("Loss")
# 격자선을 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()
평가
# ============================================================
# 14. 학습된 XOR 모델 평가
# ============================================================
# 평가할 때는 기울기를 계산할 필요가 없으므로 no_grad()를 사용합니다.
with torch.no_grad():
# 학습된 모델로 예측 확률을 계산합니다.
pred_prob = model(X)
# 예측 확률이 0.5 이상이면 1, 아니면 0으로 분류합니다.
pred_class = (pred_prob >= 0.5).float()
print("예측 확률:")
print(pred_prob)
print("예측 클래스:")
print(pred_class)
print("실제 정답:")
print(y)
# 정확도를 계산합니다.
# pred_class와 y가 같은 위치의 개수를 평균으로 계산합니다.
accuracy = (pred_class == y).float().mean()
print("정확도:", accuracy.item())
'SK 네트웍스 AI 캠프' 카테고리의 다른 글
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day22_머신러닝 차원축소 및 시각화 (0) | 2026.06.04 |
|---|---|
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day21_머신러닝 알고리즘 및 앙상블 (0) | 2026.06.02 |
| [SK네트웍스 Family AI 캠프] 32기 5주차 회고: Day16 ~ Day19 (0) | 2026.05.29 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day19_머신러닝 서포트백터머신 구조 (0) | 2026.05.29 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day18_머신러닝_회귀모델_분류모델 (0) | 2026.05.28 |



