PyTorch
Numpy와 PyTorch를 비교했을때 연산량이 많을 수록 성능 차이가 커진다 .
TensorFlow와 PyTorch를 비교했을때 PyTorch는 직관적이고 연구활용에 매우강한대신 배포가 약하며 디버깅이 매우쉽다.
https://standout.tistory.com/1743
PyTorch란? : PyTorch는 딥러닝 계산을 수행하는 프레임워크, GPU가 필요한 까닭, 코랩 Colab에서 확인하
PyTorch는 딥러닝 계산을 수행하는 프레임워크이다.딥러닝은 행렬연산, 벡터연산, 대규모 병렬 계산을 많이한다.CPU는 소수의 강한 코어로 일반작업에 딥러닝 속도가 느리다면GPU는 수천개의 작은
standout.tistory.com
Tensorflow
https://standout.tistory.com/1753
Temsorflow란?: 대규모 머신러닝 모델을 학습하고 배포하는데 최적화된 구조의 Google이 개발한 오픈
Google이 개발한 오픈소스 딥러닝 프레임워크, https://www.tensorflow.org/?hl=ko TensorFlow모두를 위한 엔드 투 엔드 오픈소스 머신러닝 플랫폼입니다. 도구, 라이브러리, 커뮤니티 리소스로 구성된 TensorFlow
standout.tistory.com
torch를 경험해보자.
Numpy는 단순 계산 라이브러리지만 torch는 학습계산이 가능한 라이브러리로 가장 큰 핵심은 자동미분에 있다. autograd.
numpy의 문법을 일부러 많이 배껴 문법이 거의 동일함에도
실제로 코드를 비교해보면 'grad'라는 속성이 눈에 띈다.
예측, 오차계산, 미분, 가중치수정을 수천만번 반복하는 머신러닝에게 미분을 자동으로 해주는 pytorch는 Good.
딥러닝속도와 관련되어있는 행렬계산의 속도, CPU 중심인 Numpy와 PyTorch의 GPU 연산 최적화 기능도 무시못한다.
* PyTorch는 프레임워크 이름, torch는 PyTorch의 Python 패키지 이름으로 거의 같은 의미로 사용된다.
import numpy as np
x = np.array([1,2,3])
y = x * 2import torch
x = torch.tensor([1.,2.,3.], requires_grad=True)
y = x * 2
torch의 기본 문법을 살펴보자. numpy와 아주 흡사한것을 확인 할 수 있다 .
torch.rand()
0~1 사이 균등분포 랜덤값 생성

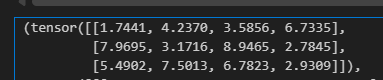
torch.randn()
정규분포 가우시안 분포 랜덤값 생성

https://standout.tistory.com/1750
정규분포 Gaussian Distribution란?
정규분포 Gaussian Distribution통계에서 가장 많이 쓰이는 확률 분포종모양 곡선으로 생긴 분포사람키를 생각하면 쉽다. 평균 키가 170cm라면 대부분 165~175 근처가 많고 130이나 220cm는 매우 적다 .즉 가
standout.tistory.com
torch.randperm()
0 ~ n-1 숫자를 랜덤으로 섞는다.

torch.randn_like()
기존 텐서와 같은 shpe으로 생성한다.

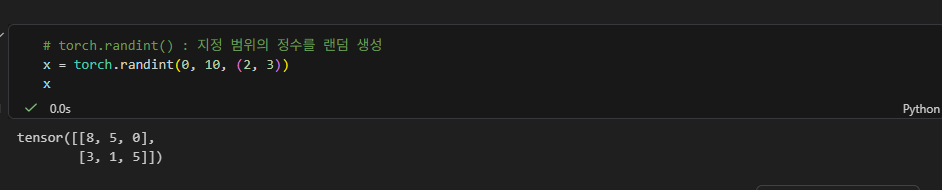
torch.randint()
0~9 정수 랜덤값 생성
torch.zeros()
전부 0 으로 행, 열 수에 맞춰 생성

torch.ones()
전부 1으로, 행, 열 수에 맞춰 생성

torch.arange()
범위를 생성한다. step설정가능

torch.FloatTensor()
(2, 3)시 garbage value, 비어있는값 등으로 float tensor를 생성하고 ([12, 35])등으로 값을 직접 입력할 수 있다.

type.as()
자료형 변환

torch.from_numpy() ,numpy()
Numpy로 만들어진 객체를 torch로 바꾸고 싶을때, torch 객체를 반대로 numpy로 바꾸고 싶을때


torch.FloatTensor() size()
float tensor를 생성. 값을 직접 주거나, 행렬 shape를 지정할 수 있다
size shape 확인


https://standout.tistory.com/1751
Tensor 텐서란?: Scalar, Vector, Matrix함께 이해하기, 물리학과 머신러닝에서의 쓰임
Tensor 텐서수학, 물리학, 머신러닝에서 사용하는 다차원 데이터 표현 개념 차원을 가진 수학적 객체, 숫자를 담는 다차원 배열스칼라, 백터, 행렬을 일반화한 개념이다. Scalar가 0차원, 5, 3.14, -2처
standout.tistory.com
to() cpu()
CPU와 GPU는 서로 다른 메모리를 사용한다. 데이터를 CPU에서 GPU메모리로 옮겨야할때가 생기게 된다.
기본적으로 CPU에 생성된 데이터를 GPU로 복사해줌. 반대로는 cpu()를 사용하면 GPU -> CPU로 다시 복사된다.

index_select()
torch.LongTensor()
특정 index선택하기
randn()로 만든 4행 3열 Tensor에서 index_select으로 0차원(행방향으로 선택, 1은 열방향임), 0번째행, 3번째행을선택했다.
long Tensor는 int64타입 tensor, 큰정수를 의미한다. 데이터 수억개일경우 작은 int범위를 뛰어넘을수있고, index이니 소숫점이 들어가면 안되기에 안전하게 torch.LongTensor()를 사용한다.
결과값은 두줄로 나온다.

Numpy에서처럼 슬라이싱도 가능하다 .

torch.BoolTensor()
masked_select()
이미지를 mask해 crop한 경험이 있을것이다. torch.BoolTensor() 객체의 값을 가져다가 True인 값만 가져 출력했다.
Numpy boolean indexing과 유사하다

torch.cat()
Tensor 합치기, dim이 0 이면 마찬가지로 행방향, 1이면 열방향이다 .

torch.stack()
새 차원을 추가하며 쌓기
실행시켜보면 x가 반복해서 [] 묶여가며 정렬된것을 볼 수 있다. dim이 0 이니 행방향.

chunk()
조각조각 갯수기준으로 분할한다.
dim이 0이면 행, 1이면 열방식으로 2개로 분할해 각각 보여주고있다.

torch.split(), torch.reshape()
앞서 chunk가 '몇 조각으로 나눌지'를 신경썼다면 split는 몇개씩 잘를지를신경쓴다 .
z1에서 dim=0 행기준으로 2줄씩 잘랐고
z1에서 dim=1 열기준으로 2문자씩 잘랐다.
torch.reshape() shape 변경

torch.squeeze(), torch.unsqueeze()
크기가 1인 차원을 제거한다 .딥러닝에서 중간에 의미없는 차원이 생길 때 제거할때 사용한다.
반대로 차원을 추가한다. dim 위치에 차원 1 을 추가했다. 딥러닝에서 batch 차원을 만들떄 주로 사용한다.
현재 Tensor가 (10, 3, 4)이고 10개의 데이터, 각데이터는 3*4의 형태라 이해한다.
unsqueeze는 0번째 위치에 크기 1짜리 차원을 추가한다는 의미이다 . 딥러닝에서는 보통 입력 shape를 (batch, channel, height, width)형태로기대하고 batch는 여러 데이터를 한번에 처리할때 GPU 병렬처리로 유용히 사용된다 . 보통 모델은 batch가 들어간 형태를 기대함으로 unsqueeze를 사용해 형태를 바꾸게 된다 .


torch.nn.init 가중치를 초기화, 신경망 weight를 초기화하는 용도이다.
unifrom_() 균등분포 초기화 예시에서 0~9 랜덤값을 사용하라고 지시했다.
normal() 정규분포 초기화, 가우시안, 정규분포기반 랜덤값 생성, 0 근처 값이 많이 나오고 큰값은 적게나오는것이 가우시안.std는 퍼짐정도로 std말고는 mean도 있다. mean 의 기본값은 0 std의 가본값은 0.2다. 기준중심 mean에서 0.2정도로 퍼져 -0.2~0.2 값들이 많이 나오게된다.
constant_() 상수값 초기화, 예시에서 전부 3.145로 초기화하라고 지시했다.
신경망은 처음에 숫자를 랜덤하게 넣고 시작한다. 이것을 '가중치 초기화'라고 하고 신경망에는 실제로 이 가중치가 많다. 문제는 처음부터 가중치가 있어야 학습이 시작될수있음으로 '첫 숫자를 어떻게넣을까?'를 고민하게된다 .전부 0일경우 모든 뉴런이 똑같이 행동해버리니 학습이 안되니 보통 작은 랜덤값으로 시작한다.
nn.init은 Tensor를 특정 방식으로 초기화하는 기능이다.



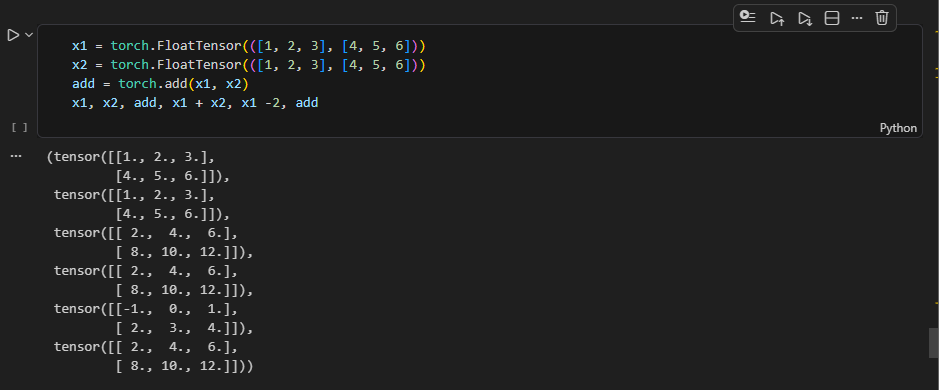
torch.add() 덧셈
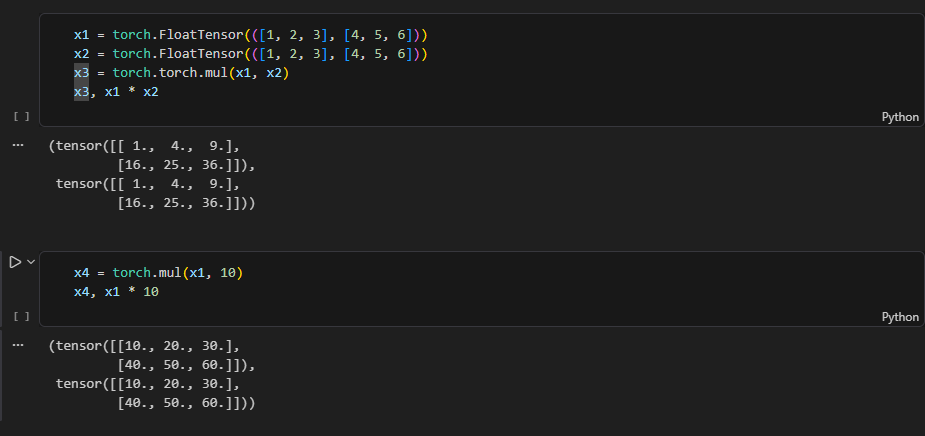
torch.mul() 곱셈
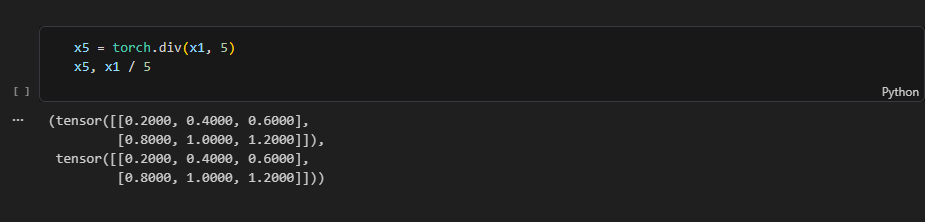
torch.div() 나눗셈
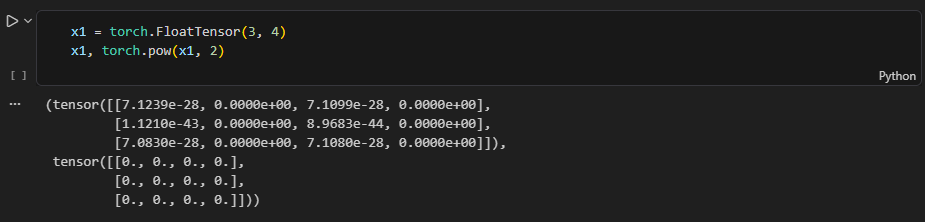
torch.pow() 제곱

exp()
차수함수 e의 거듭제곱. e는 수학상수로 값은 e ≈ 2.71828 정도 파이와같은 유명한 숫자이다 .
Tensor 각 원소에 e^x 계산한 값의 반환한다.

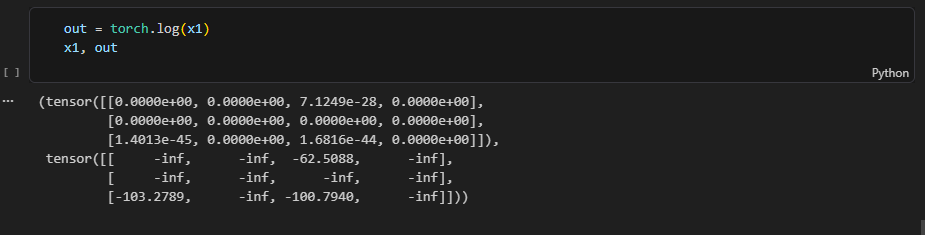
log(x)
e를 몇 제곱해야 x가 되는지
torch.mm()
행렬곱 Matrix Multiplication
! 행 * 열 이때 가운데 n이 같아야 곱해진다 .

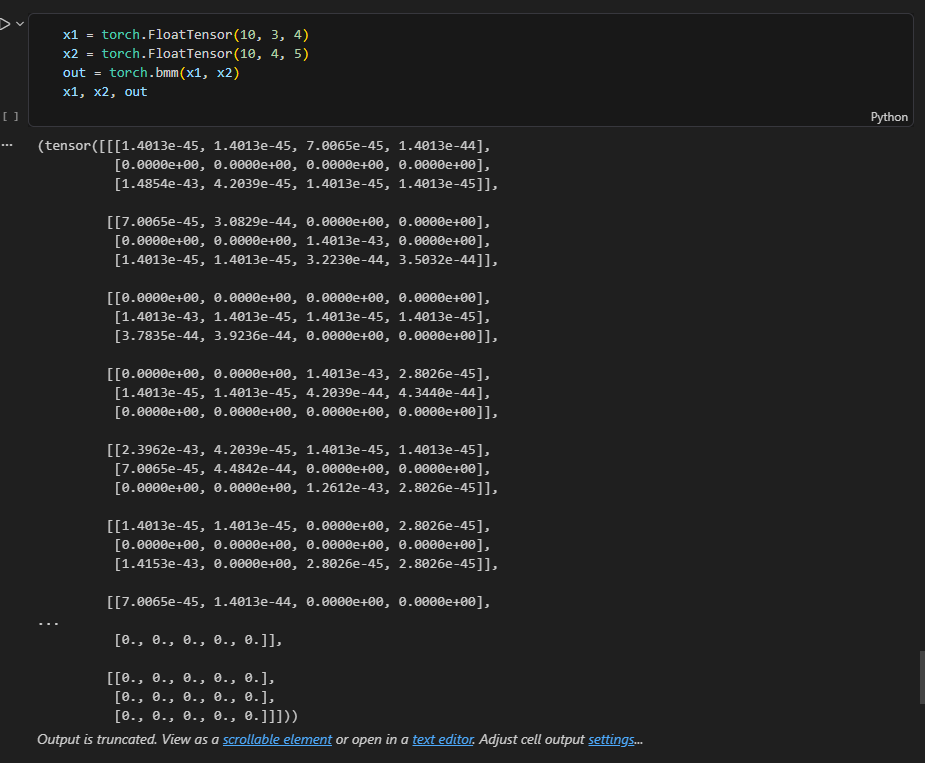
torch.bmm()
3차원의 batch 행렬곱, batch 별로 mm을 수행한다.
(행렬 A의 각 행) · (행렬 B의 각 열) = 그 결과들을 모아서 행렬 생성
torch.dot()
(같은 위치끼리 곱) + (전부 합) <- > 반대로 mm은 dot을 여러 번 해서 표(행렬)를 만든 것이다.
1차원 텐서(벡터) 전용으로, 같은 위치 원소를 곱해서 전부 더해서 1개 숫자를 반환한다.

torch.t() 전치행렬
행과 열 바꾼다.
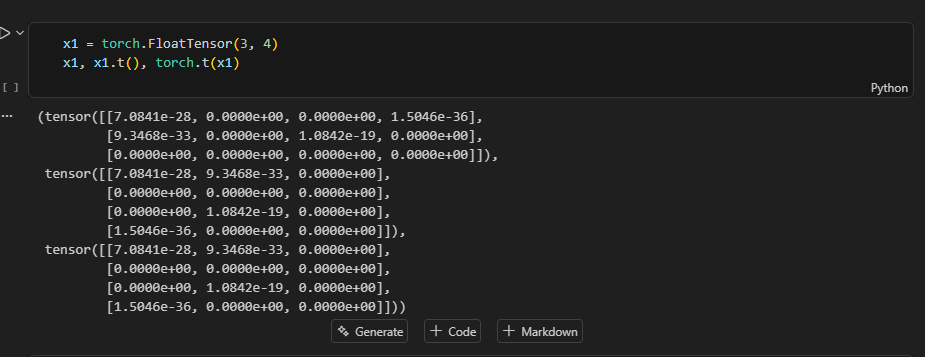
torch.transpose(a, b)
a, b차원을 교환한다 .

torch.linalog.eig()
행렬을 고유값/고유백터로 분해한다. 결과는 항상 두개.
torch.linalg.eig(x1) = (eigenvalues, eigenvectors) = ("얼마나 늘어났는가", "어느방향인가")
eigvals는 2, 1로 x방향으로는 2배, y방향으로는 1배 늘어났고.
eigenvec는 움직인 그 화살표 그 화살표 길이가 몇 배 되는지 1, 0 0, 1 이니 x y모두 고정이다 .

회귀 및 분류모델
학습데이터 - 알고리즘 선택 - 학습/모델개발 - 평가/모델평가 - 모델선정 - 운영 적용
입력값들로부터
분석알고리즘
예 측 (회귀) 유형
- 선형회귀분석
- 의사결정나무
- 인공신경망
- SVC Support Vector Classifier
- KNN K-Nearest Neighborhood
분류 유형
- 로지스틱회귀분석
- 의사결정나무
- 인공신경망
- SVC Support Vector Classifier
- KNN K-Nearest Neighborhood
로지스틱회귀모델
독립변수의 선형결합을 이용해 사건발생 여부를 예측함.
종속변수가 범주형일때 사용하는 회귀분석 모델
혼동행렬
분류모델의 성능평가를 위해 사용되는 표 예측값과 실제값간의 차이를 2차원 매트릭스로 나타냄
평가지표
정확도, 정밀도, 재현율, F1-score, 특이도, 거짓긍정률 FPR, 참긍정률 TPR
ROC 커브
임곗값에서 0~1까지 변화시켜가며 x축에는 거짓긍정률, y축에는 참 긍정률을 표시한 곡선
아래 면적을 AUC Area Under the Curve라 하며 AUC 값이 1에 가까울 수록 분류 모델의 성능이 좋다고 평가한다.
gpu 사용중인지 확인하기

import torch
import torch.nn as nn #신경망
import torch.optim as optim #최적화
from sklearn.model_selection import train_test_split #데이터셋 분리
#평가지표
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.metrics import accuracy_score, classification_report
from sklearn.preprocessing import StandardScaler, LabelEncoder #데이터 전처리
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("사용 장치:", device)
손실함수
모델이 답을 틀릴수도있다. 예측이 원래 정답과 맞지않을경우 틀린정도를 보고 오차수정을 해야한다.
이역할이 손실함수
여러 종류가 있고 MSELoss 가 있고 회귀문제에서 많이사용한다 .
'SK 네트웍스 AI 캠프' 카테고리의 다른 글
| [SK네트웍스 Family AI 캠프] 32기 5주차 회고: Day16 ~ Day19 (0) | 2026.05.29 |
|---|---|
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day19_머신러닝 서포트백터머신 구조 (0) | 2026.05.29 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day17_머신러닝 학습방법과 데이터 관리 (0) | 2026.05.27 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day16_데이터 시각화 (0) | 2026.05.26 |
| [SK네트웍스 Family AI 캠프] 32기 4주차 회고: Day13 ~ Day15 (0) | 2026.05.22 |



