머신러닝 전체흐름
데이터수집 - 데이터전처리 - 특징선택/추출(컬럼선택) - 모델선택(알고리즘) - 학습 - 평가 - 예측 - 배포 및 모니터링
머신러닝에는 지도학습, 비지도학습, 준비도학습, 강화학습이있다.
1. 지도학습: 분류, 회귀
정답이있는데이터로 학습하는것.
- 분류 Classification
Logistic Regression
K-Nearest Neighbors (KNN)
Naive Bayes
Decision Tree
Random Forest
Support Vector Machine (SVM)
Neural Network
-회귀 Regression
Linear Regression
Ridge / Lasso Regression
Support Vector Regression (SVR)
Decision Tree Regressor
Random Forest Regressor
Neural Network (Regression)
2. 비지도학습: 군집화, 차원축소, 연관규칙
정답이 없는 데이터를 학습해 데이터 구조/패턴을 발견
- 군집화
-K-Means
Hierarchical
Clustering
DBSCAN
Gaussian Mixture
Model (GMM)
- 차원축소
PCA
t-SNE
UMAP
Autoencoder
- 연관규칙
Apriori
FP-Growth
3. 준지도학습
4. 강화학습
좀더 상세히 알아보자.
- 분류 Classification
Logistic Regression:
확률기반 분류 알고리즘으로 출력값 0~1에 따라 분류한다.
시그모이드라는 함수를 사용함.

빠르고해석이 쉽지만 복잡한 비선형에 한계가 있다 .
"스팸일 확률 0.92"
K-Nearest Neighbors (KNN)
가장 가까운 K개의 데이터를 보고 분류한다.
유클리드 거리함수를 사용함.

직관적이고 구현이 쉬우나 데이터많으면 느리고 값을 표준화시키는 standerd scale영향이 크다.
"주변 5개중 4개가 고양이면 고양이로 분류"
Naive Bayes
베이즈정리 공식을 사용한다.
속도가 빠르고 텍스트 분류에 강하나 복잡한 패턴을 만나면 제대로 작동이 안되고 모든것이 독립적이라고 생각한다는 가정이 현실적이지 않다는 단점이 있다 . Native 순진한.
"단어 무료, 당첨, 지금 이라는 단어가 있을때 스팸일 확률을 계산한다." 즉 현실에서는 이 단어들이 서로 영향이 있으나 Naive Bayessms 서로 독립적이라고 가정해 서로 관련이있는데 무시하거나 복잡한 패턴이 약하고 정확도에 한계가 있다는것.

Decision Tree
질문을 반복하면서 데이터 를 분류하는 트리구조
스무고개처럼 동작한다.
해석이 쉽고 시각화가 가능하나 과접합이 쉽고 데이터 변화에 민감하다. 트리구조이기때문에 새로운 데이터가 발생하면 index가 바뀌니 root가 바뀌고 질문에서 답을 찾아가는 경로가 바뀌기 때문이다.
Random Forest
여러개의 Decision Tree를 만들어 투표로 결정한다. = 앙상블개념이 적용
성능이 우수하고 과적합이 감소되나 모델이 크고 해석이 어려울 수 있다 .
* 앙상블:여러개 알고리즘을 합쳐서 처리한다

*클래스는 객체지향 이론이 아닌 카테고리를 의미한다.
Neural Network, ANN Artificial Neural Network
머신러닝에서는 ANN이라 부른다. 인간신경망을 모방한 모델.
입력층, 은닉층, 출력증의 구조로 input데이터를일고, 결과를 출력하는 레이어, hidden 레이어가 은닉층
복잡한 패턴을 학습할때 좋아 높은 성능을 가지나 데이터를 많이 필요하고 학습비용이 크다.
오늘 경험해볼 Support Vector Machine (SVM)에 대해서는 알아보는 김에 깊게 알아보자.
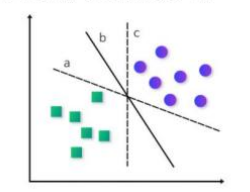
두 클래스를 가장 잘 나누는 경계를 찾는다. 이 경계를 초평면이라고한다. 마진이 최대화시킨다는것. 마진이 여백이니 경계를 최대화시킨다란 의미겠다. = 최대마진 초평면
고차원에 강하다. 3차원 4차원에 강하고 일반화가 우수하나 차원이 많아지니 속도가 느리고 튜닝이 어렵다.
의료분야에서 암이나 유전병 생체정보학분야에서 유전자 발현데이터분류하거나 텍스트범주화 문서속의 언어식별 및 주제별 문서 분류, 연소엔진의 고장 보안 결함 또는 지진등에 자주사용된다.
초평면 경계 데이터의 유사한 클래스값으로 그룹을 분할해
직선 또는 평면으로 분리한다. = 선형적 분리기능
초평면은 재선중에서 선택하며, 2차원에서는 선, 3차원에서는 면으로 한다 .
클래스를 선형적으로 분리가능할경우에 마진을 찾기 쉬워진다 .데이터에 가장 바깥에 위치한 바깥경계는 컨벡스 헐 convex hull이라한다.

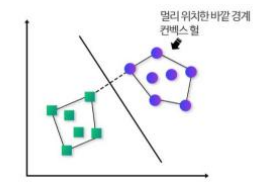
데이터셋에 변수간 관계가 비선형이라면 어떻할까?
비선형 '커널'을 사용하면 고차원 공간의 매핑 능력을 포함한다.
비선형관계에서 갑자기 선형적인 관계로 표시됨 비선형적인 데이터 관계일때 문제가 생긴다. 직선이 아니라 s자커브로 하면좋겟지만 직선, 면만 되기때문에 비선형 공간 커널을 사용한다 .
비선형공간커널 svm은 분류, 숫자문제에 사용되며 과적합이 쉽게 발생되지않고 신경망을 사용하는 것보다 쉽고 정확도가 높다.
해석하기 어려운 복잡한 블랙박스 모델을 생성한다는것이 단점. 직선으로 구분이 안된다면 차원을 바꿔서 공간을 비틀어 구분하게 해버린다는것. 이때 실제로 차원을 계산하면 너무 무거워 커널 트릭이라고 해서 차원을 올린것처럼 계산만 흉내낸 기술을 사용한다.


샘플예제를 분석해보자.
결정경계를 hyperplane이라고 하고 이 경계를 잘 찾게끔하는 알고리즘이 svm이다.
RBFFeatureSVMClassifier Random Fourier Features + svm 구조로 RBF 커널효과를 PyTorch에서 근사한 구조.
문자를 분류할때 이 알파벳과 단어가 섞여 문장이 되는 데이터들은 직선으로 분리가 불가능하다. RBF 커널을 사용해 데이터를 고차원공간으로 변환해 선형분리가 가능하게 만든다. 이는 가까운점은 높은 유사도, 먼점은 낮은 유사도이다라는 의미의 수식을 사용한다. 진짜 RBF커널은 계산량이 매우크고 데이터가 많으면 느려지지만 할수없이 쓴다. 이를 해결하기위해 Random Fourier Featurs RBF커널을 근사하여 원본을 입력하면 랜덤 고차원 변환을 시키고 새로운 feature 공간을 만들어 linear svm을 적용한다.
무엇을 import했는지 살펴보자.
torch pytorch 핵심라이브러리
torch.nn 모델계층, 손실함수
torch.nn.functional 활성화, 손실함수
torch.utils.data dataset, dataloader를 제공해 데이터를 미니배치로 나누어 학습. 샘플몇개를 만들어 학습시킨다는것. 훈련할때마다 샘플로 몇개 뽑아다 학습시키면 계속 똑같은 데이터로 훈련하지 않으니 과적합을 방지할 수 있다 .배치의 효과
pandas csv파일열어 표 형테 데이터프레임으로 다룸
numpy 수치계산 배열처리
matplotlib.pyplot 그래프
sklearn.preprocessing from labelencoder, standardscler 문자가 대문자 같은 범주등을 문자는 기계가 해석을 못하니 숫자로 0~25 변환하는 것이게 encoder scler는 값들을 표준화시키는것.
sklearn.metrics confusion_matrix, classification_report, accuracy_score 성능평가
os 파일경로 존재여부
urlib.request 인터넷에서 데이터를 내려받기 위해
random 기본난수생성
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
cuda가 avilable하면 사용하고, 불가하면 cpu를 사용한다 . 기본이 gpu
# ============================================================
# 0. 실습 환경 확인
# ============================================================
# torch는 PyTorch의 핵심 라이브러리입니다.
# 텐서 연산, 자동 미분, 신경망 모델 작성에 사용합니다.
import torch
# torch.nn은 PyTorch에서 모델 계층, 손실 함수 등을 제공하는 모듈입니다.
import torch.nn as nn
# torch.nn.functional은 활성화 함수, 손실 함수 등을 함수 형태로 제공합니다.
import torch.nn.functional as F
# torch.utils.data는 Dataset, DataLoader를 제공하여 데이터를 미니배치로 나누어 학습할 수 있게 합니다.
from torch.utils.data import TensorDataset, DataLoader
# pandas는 CSV 파일을 읽고 표 형태 데이터프레임으로 다루기 위해 사용합니다.
import pandas as pd
# numpy는 수치 계산 및 배열 처리를 위해 사용합니다.
import numpy as np
# matplotlib은 학습 결과 그래프를 그리기 위해 사용합니다.
import matplotlib.pyplot as plt
# sklearn의 LabelEncoder는 문자 A~Z 같은 범주형 라벨을 0~25 숫자로 변환합니다.
from sklearn.preprocessing import LabelEncoder, StandardScaler
# sklearn의 confusion_matrix, classification_report는 분류 성능 평가에 사용합니다.
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
# os는 파일 경로 존재 여부를 확인하기 위해 사용합니다.
import os
# urllib.request는 Colab에서 데이터 파일이 없을 때 인터넷에서 데이터를 내려받기 위해 사용합니다.
import urllib.request
# random은 파이썬 기본 난수 생성을 제어하기 위해 사용합니다.
import random
# 실행 장치를 설정합니다.
# GPU가 있으면 cuda, 없으면 cpu를 사용합니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 현재 사용 중인 장치를 출력합니다.
print("사용 장치:", device)
seed, random.seed(seed) 파이썬 기본
np.random.seed(seed) 이건 넘파이용
torch.manual_seed(seed) 토치용
torch. cuda.manual_seed_all(seed)
랜덤값 고정시킨다 .시드고정. 같은 코드를 여러번 실행해도 0보다 큰 정수면 된다. 가능한 비슷한 결과가나오도록 고정한것.
gpu가 사용가능한 경우 gpu난수시드도 고정한다.
*seed 머신이 공부하는 환경을 일정하게 맞춰주는것. 매번 다른 조건에서 공부하지않도록 도와준다 .사람이 조용한곳, 싞러운곳, 문제순서가 다르면 결과가 들쭉날쭉하듯 랜덤요소를 비슷하게 하고 학습하게 하면 결과를 안정적으로 재현이가능하겠다 .물론 안정적으로 결과를 재현하려는 목적이지 성능을 무조건 올리는 기능은 아니다.
딥러닝은 내부적으로 랜덤값을 많이 사용한다. 이때 가중치 초기값 랜덤, 데이터섞고, dropout, 연산등등 때문에 같은 코드라도 실행할때마다 결과가 달라질 수 있다. 이때 시드를 고정하면 랜덤패턴을 최대한 동일하게 맞춰 정확도가 안정적으로 비슷하게 재현될 수 있는것. 실험결과를 다시 재현하면서 비교하기 쉽게 만들려고하는.
# ============================================================
# 1. 재현 가능한 실험을 위한 시드 고정
# ============================================================
# 같은 코드를 여러 번 실행해도 가능한 한 비슷한 결과가 나오도록 난수 시드를 고정합니다.
SEED = 12345
# 파이썬 random 모듈의 난수 시드를 고정합니다.
random.seed(SEED)
# numpy 난수 시드를 고정합니다.
np.random.seed(SEED)
# PyTorch CPU 난수 시드를 고정합니다.
torch.manual_seed(SEED)
# GPU가 사용 가능한 경우 GPU 난수 시드도 고정합니다.
if torch.cuda.is_available():
torch.cuda.manual_seed_all(SEED)
print("난수 시드 고정 완료:", SEED)
사용할 데이터 폴더경로를 지정하고, csv 파일명과 path.join을해 해당경로에 해당 파일이 있는지를 검사하고 not일 경우 urllib.request.urlretrieve로 인터넷에서 다운로드한다. 이때 데이터셋은 header가 없음으로 직접 지정해야한다. 이를 pandas dataFrame으로 읽어 to_csv로 저장한다.
# ============================================================
# 2. 데이터 파일 준비
# ============================================================
# Colab에서 사용할 데이터 폴더 경로를 지정합니다.
DATA_DIR = "/content/data"
# 데이터 폴더가 없으면 생성합니다.
os.makedirs(DATA_DIR, exist_ok=True)
# 사용할 CSV 파일 경로를 지정합니다.
csv_path = os.path.join(DATA_DIR, "opt_letterdata.csv")
# CSV 파일이 없는 경우 UCI Letter Recognition 데이터를 내려받습니다.
if not os.path.exists(csv_path):
# UCI Letter Recognition 데이터셋 URL입니다.
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/letter-recognition/letter-recognition.data"
# 임시 원본 데이터 파일 경로입니다.
raw_path = os.path.join(DATA_DIR, "letter-recognition.data")
# 인터넷에서 데이터를 다운로드합니다.
urllib.request.urlretrieve(url, raw_path)
# UCI 데이터셋은 헤더가 없으므로 컬럼명을 직접 지정합니다.
columns = [
"letter", "x_box", "y_box", "width", "height", "onpix", "x_bar", "y_bar",
"x2bar", "y2bar", "xybar", "x2ybr", "xy2br", "x_ege", "xegvy",
"y_ege", "yegvx"
]
# CSV 파일을 pandas DataFrame으로 읽습니다.
df_raw = pd.read_csv(raw_path, header=None, names=columns)
# CSV 파일 형태로 저장합니다.
df_raw.to_csv(csv_path, index=False)
print("데이터 다운로드 및 CSV 저장 완료:", csv_path)
else:
print("기존 CSV 파일 사용:", csv_path)
# CSV 파일을 pandas DataFrame으로 읽습니다.
df = pd.read_csv(csv_path)
# 데이터 앞부분 5개 행을 출력하여 구조를 확인합니다.
df.head()https://standout.tistory.com/1755
UCI Machine Learning Repository란? : 머신러닝 커뮤니케이션, 가장 유명한 데이터셋 저장소, 머신러닝 연
UCI Machine Learning Repository미국 University of California, Irvine에서 운영, 현재 689데이터셋을 제공하고있음. 머신러닝 커뮤니케이션 사이트머신러닝 공부할때 가장 유명한 데이터셋 저장소, 머신러닝 연
standout.tistory.com
df.shpe로 행과열의 개수를 확인하고 info()를 실행해서 각 컬럼의 자료형과 결측치 여부를 확인한다. value.sounts.sort_index()를 통해 정답라벨의 종류와 갯수를 확인했다. 모두 2만개이니 결측치는 없는 것을 확인 할 수 있었다.
# ============================================================
# 3. 데이터 구조 확인
# ============================================================
# 데이터 행과 열의 개수를 확인합니다.
print("데이터 크기:", df.shape)
# 각 컬럼의 자료형과 결측치 여부를 확인합니다.
print("\n데이터 정보:")
print(df.info())
# 정답 라벨인 letter 컬럼의 종류와 개수를 확인합니다.
print("\n문자 라벨 개수:")
print(df["letter"].value_counts().sort_index())데이터 크기: (20000, 17)
데이터 정보:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20000 entries, 0 to 19999
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 letter 20000 non-null object
1 x_box 20000 non-null int64
2 y_box 20000 non-null int64
3 width 20000 non-null int64
4 height 20000 non-null int64
5 onpix 20000 non-null int64
6 x_bar 20000 non-null int64
7 y_bar 20000 non-null int64
8 x2bar 20000 non-null int64
9 y2bar 20000 non-null int64
10 xybar 20000 non-null int64
11 x2ybr 20000 non-null int64
12 xy2br 20000 non-null int64
13 x_ege 20000 non-null int64
14 xegvy 20000 non-null int64
15 y_ege 20000 non-null int64
16 yegvx 20000 non-null int64
...
X 787
Y 786
Z 734
Name: count, dtype: int64
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
letter가 정답변수이고 나머지를 입력특징으로 사용해야하니 y_text에 letter.value를 할당하고 앞서 확인한 label_encoder.fit_transform()를 사용해 a~z를 정수라벨로 전환했다 .
df.drop(letter).value로 나머지 컬럼을 x로 할당했다 .
* # sklearn의 LabelEncoder는 문자 A~Z 같은 범주형 라벨을 0~25 숫자로 변환합니다.
from sklearn.preprocessing import LabelEncoder, StandardScaler
tensor가 기본적으로 float텐서를 사용하니 .astype(np.float32)로 입력데이터를 float으로 변환했다.
y는 정수형으로 astype(np.int64)로 변환했는데 pytorch 분류 손실함수는 클래스 타입을 long타입으로 받기 때문이다 .
클래스의 갯수를 len()가져다 할당하고
아까 shpe가 데이터 크기: (20000, 17)였다 .x.shape에 1번째라는것은 17 - 1 (letter하나 drop) = 16을 할당했다는소리. 정답으로 지정한 열을 제외한 특징갯수를 할당한것.
# ============================================================
# 4. 입력 X와 정답 y 분리
# ============================================================
# letter 컬럼은 정답 라벨이므로 y로 사용합니다.
y_text = df["letter"].values
# letter를 제외한 나머지 컬럼들은 입력 특징 X로 사용합니다.
X = df.drop(columns=["letter"]).values
# LabelEncoder는 A~Z 문자를 0~25 정수 라벨로 변환합니다.
label_encoder = LabelEncoder()
# 문자 라벨을 숫자 라벨로 변환합니다.
y = label_encoder.fit_transform(y_text)
# 입력 데이터 X를 실수형 float32로 변환합니다.
# PyTorch 모델은 일반적으로 float32 텐서를 사용합니다.
X = X.astype(np.float32)
# 정답 데이터 y를 정수형 int64로 변환합니다.
# PyTorch의 분류 손실 함수는 클래스(category) 라벨을 long 타입으로 받습니다.
y = y.astype(np.int64)
# 클래스 개수를 계산합니다.
num_classes = len(label_encoder.classes_)
# 입력 특징 개수를 계산합니다.
num_features = X.shape[1]
print("입력 특징 수:", num_features)
print("클래스 수:", num_classes)
print("클래스 목록:", label_encoder.classes_)입력 특징 수: 16
클래스 수: 26
클래스 목록: ['A' 'B' 'C' 'D' 'E' 'F' 'G' 'H' 'I' 'J' 'K' 'L' 'M' 'N' 'O' 'P' 'Q' 'R'
'S' 'T' 'U' 'V' 'W' 'X' 'Y' 'Z']
아까 확인했던 데이터 데이터 크기: (20000, 17) 2만중 슬라이싱을 통해 데이터를 나눠 할당했다 .
# ============================================================
# 5. 훈련 데이터와 테스트 데이터 분리
# ============================================================
# 앞 16000개 행을 훈련 데이터로 사용합니다.
X_train = X[:16000]
# 앞 16000개 행의 라벨을 훈련 정답으로 사용합니다.
y_train = y[:16000]
# 16001번째 이후 행을 테스트 데이터로 사용합니다.
X_test = X[16000:]
# 16001번째 이후 라벨을 테스트 정답으로 사용합니다.
y_test = y[16000:]
print("훈련 X:", X_train.shape)
print("훈련 y:", y_train.shape)
print("테스트 X:", X_test.shape)
print("테스트 y:", y_test.shape)훈련 X: (16000, 16)
훈련 y: (16000,)
테스트 X: (4000, 16)
테스트 y: (4000,)
데이터 정규화. svm은 경계와 거리개념을 사용하는 알고리즘임으로 입력특징의 스케일이 굉장히 중요하다 . 스케일이란 값의 범위. 따라서 평균이 0이고 표준편차가 1이 되도록 표준화해야한다. 이때 훈련 데이터로만 fit, 테스트 데이터는 훈련데이터 기준으로 transform해야 테스트 데이터 정보가 학습에 새어 들어가지 않는다. 둘다 fit하면 모델작업시 데이터가 새어들어간다.
standardscaler.fit_transform()로 평균을 0, 표준편차를 1로 변환한다.
해당 numpy배열과 정답, 테스트 입력, 테스트 정답을 torch.tensor로 변환했다.
* fit은 데이터 기준을 학습하는 과정.
평균과 표준편차를 계산한 기준값을 내부에 저장하며 학습 하게 되는데
모듈이 원래 보면 안되는 테스트 데이터의 평균.분포 정보를 미리알게되어데이터 누수발생으로 시험보기전에정답경향을 미리 본 느낌이나 다름이 없어 미리 참고해버리는 상태가 되어버리기 때문에기준학습을 위해 fit, 그 기준으로 변환하기 위해 transform하나 테스트에는 사용하지않는다.
# ============================================================
# 6. 표준화 전처리
# ============================================================
# StandardScaler는 각 특징을 평균 0, 표준편차 1로 변환합니다.
scaler = StandardScaler()
# 훈련 데이터의 평균과 표준편차를 학습하고 동시에 변환합니다.
X_train_scaled = scaler.fit_transform(X_train)
# 테스트 데이터는 훈련 데이터에서 학습한 평균과 표준편차로만 변환합니다.
X_test_scaled = scaler.transform(X_test)
# numpy 배열을 PyTorch 텐서로 변환합니다.
X_train_tensor = torch.tensor(X_train_scaled, dtype=torch.float32)
# 훈련 정답도 PyTorch 텐서로 변환합니다.
y_train_tensor = torch.tensor(y_train, dtype=torch.long)
# 테스트 입력을 PyTorch 텐서로 변환합니다.
X_test_tensor = torch.tensor(X_test_scaled, dtype=torch.float32)
# 테스트 정답을 PyTorch 텐서로 변환합니다.
y_test_tensor = torch.tensor(y_test, dtype=torch.long)
print("PyTorch 텐서 변환 완료")
print(X_train_tensor.shape, y_train_tensor.shape)PyTorch 텐서 변환 완료
torch.Size([16000, 16]) torch.Size([16000])
위 입력텐서와 정답텐서를 하나의 데이터셋으로 묶고 tensordataset
batch_sizw 단위로 나누어 모델에 공급한다. 한번에 16000개중 256개씩 샘플링해 학습시킨다 . 이렇게 하면 연산속도가 빨라지고 같은 데이터로 훈련하는게 아니니 외우질 못해 과적합이 잘 안생긴다 . 이때 shuffle을 true로 해 매 epoch 훈련때마다 데이터 순서를 섞어가며 학습 안정성을 높인다. 모두 과적합을 막기 위한 조치.
샘플이 63개 나왔음을 확인 할 수 있었다.
미니배치 개수: 63# ============================================================
# 7. DataLoader 생성
# ============================================================
# TensorDataset은 입력 텐서와 정답 텐서를 하나의 데이터셋으로 묶어줍니다.
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
# DataLoader는 데이터를 batch_size 단위로 나누어 모델에 공급합니다.
train_loader = DataLoader(
train_dataset, # 학습에 사용할 데이터셋입니다.
batch_size=256, # 한 번에 256개 샘플씩 학습합니다.
shuffle=True # 매 epoch마다 데이터 순서를 섞어 학습 안정성을 높입니다.
)
print("미니배치 개수:", len(train_loader))미니배치 개수: 63
다중 클래스 분류시작. 클래스마다 하나의 점수를 계산해 가장 큰 점수를 가진 클래스를 예측한다.
class MultiClassHingeLoss(nn.Module):로 class를 직접 만들어 nn.Module을 상속받아 Pytorch 손실함수 클래스를 만들었다.
svm은 거리경계선이 중요하다. 이는 클래스 점수가 다른 클래스보다 최소한 얼마나 커야 하는지를 의미한다. 이 수치 margin을 init생성할때 1.0을 줬다.
forward() 입력이 들어왔을때 모델이 어떻게 계산할지 정의하는 pytorch 모델생성의 핵심함수
bathsize에 데이터갯수, correct_scores에 정답 클래스 점수만 뽑아 왔다
correct_scores, target는 각 샘플의 정답 클래스를 저장하기 때문에 항상 길이가 batch_size이고 torch.arange(batch_size)도 자동으로같은 길이가 된다. arange는 순서대로 숫자를 생성하는 함수이니 torch.arrange(batch_size)는 행 인덱스를 만들었고 targets는 각 샘플의 정답 클래스 번호를 가지니 이 형태로 score에서 각 샘플의 정답 점수만 가져온것이다. 도 .view(-1, 1)은 shape을 바꾸겠다는 의미인데 현재 correct_score모양은 1차원이다. 하지만 이 svm에서 하고 싶은 계산은 score - correct_score이고 score는 다차원이다 . (3, 3) 등과 같은 형태일것이라는 거다. 우리는 아래처럼 계산을 하고싶기때문에 shape을 변경한것. 그리고 앞에 -1는 pytorch가 자동으로 행을 계산하라는 의미이다 .
[
[2.5,0.3,1.2] - 2.5,
[0.1,3.0,2.0] - 2.0,
[1.5,0.2,4.1] - 0.2
]
loss는 단순한 점수표가 아니라 모델을 수정하기 위한 신호라고 이해해보자 .
모델은 결국 점수를 출력한다.고양이 사진을 보고 각 클래스가 점수를 매길것이고 고양이라는 의미의 클래스 점수가 가장 높게 나올것이란 말이다. 하지만 그냥 '맞다'라는 것을 만족하기에는 차이가 너무 작으니 모델이 확신이 떨어진다. 개의 점수가 4.5이고 고양이점수가 4.6일때 marigin을 더하면 0.9로 손실계산, loss가발생한다. '아직 부족해!'라고 생각하는것에 대한 증거자료라 할까 모델에게 아직이야, 점수가 적어 라고 알려주는 기준점이다.
* [[0, 1, 2], [0, 1, 2]]
pythorch의 고급 인덱싱이다각 위치를 짝으로 접근하는것.
svm은 margin을 구하는 방법이나 다름이 없고, svm은 클래스 점수가 다른 클래스 점수보다 충분히 크게 만드는것이 목표이다 .정답점수 > 오답점수라는 단순한 관점이 아니라 정답점수 >= 오답점수 + margin을 원하는 것.
이것을 수학적으로쓰면 max(0, score - score + margin)이 된다. 이것을 loss값으로 이해한다.
svm은 오답클래스와 정답 클래스를 비교하는 것이 목적인데 사실상 코드에서는 모든 클래스에 대해 계산됨으로 정답 클래스까지 포함해 계산될 수 있다 .그리고 이 비교는 자기자신과 비교하면 항상 같기 때문에 의미가없고 항상 1이 나온다 .그런데 손실이 게속 1이 생기면 이상함으로 모델이 loss를 0으로만들 수 없으니 정답 위치는 제거하는 것이다.
앞서 확인했던 고급 인덱싱을 활용해서 해당 targets부분에서는 0으로 리셋해주자.
# ============================================================
# 8. 다중 클래스 SVM 손실 함수 정의
# ============================================================
class MultiClassHingeLoss(nn.Module):
# nn.Module을 상속하여 PyTorch 손실 함수 클래스를 만듭니다.
def __init__(self, margin=1.0):
# 부모 클래스 초기화입니다.
super().__init__()
# margin은 정답 클래스 점수가 다른 클래스보다 최소한 얼마나 커야 하는지를 의미합니다.
self.margin = margin
def forward(self, scores, targets):
# scores: 모델이 출력한 클래스별 점수, 크기 [batch_size, num_classes]
# targets: 실제 정답 클래스 번호, 크기 [batch_size]
# 배치 데이터 개수를 가져옵니다.
batch_size = scores.size(0)
# 각 샘플의 정답 클래스 점수만 뽑아냅니다.
correct_scores = scores[torch.arange(batch_size), targets].view(-1, 1)
# SVM hinge loss 계산식입니다.
# 정답이 아닌 클래스 점수 - 정답 클래스 점수 + margin 이 0보다 크면 손실이 발생합니다.
margins = torch.clamp(scores - correct_scores + self.margin, min=0.0)
# 정답 클래스 자체에 대한 margin은 손실에서 제외해야 하므로 0으로 만듭니다.
margins[torch.arange(batch_size), targets] = 0.0
# 모든 샘플과 클래스에 대한 평균 손실을 반환합니다.
loss = margins.sum(dim=1).mean()
return loss
LinearSVMClassifier 함수를 만들어
pytorch의 nn.module를 상속했다. nn.linear로 특징, 클래스수로 선형계층으로 변환하고
forward를 통해 score를 만드는 함수, 카테고리별 점수를 만든다. self.linear(x)를 넣어 score를 반환한다.
# ============================================================
# 9. 선형 SVM 모델 클래스 정의
# ============================================================
class LinearSVMClassifier(nn.Module):
# nn.Module을 상속하여 PyTorch 모델 클래스를 작성합니다.
def __init__(self, input_dim, num_classes):
# 부모 클래스 초기화입니다.
super().__init__()
# 선형 계층입니다.
# 입력 특징 수 input_dim을 클래스 수 num_classes 점수로 변환합니다.
self.linear = nn.Linear(input_dim, num_classes)
def forward(self, x):
# forward는 모델이 입력 x를 받아 출력 scores를 만드는 함수입니다.
# 여기서 scores는 확률이 아니라 클래스(category)별 점수입니다.
scores = self.linear(x)
# 계산된 클래스별 점수를 반환합니다.
return scores
학습함수
위에서 구한 loss를 가지고 모델을 어떻게 학습시킬지를 분석해보자. 계속 사용하게될 train_model 반복문 함수.
이 함수는 학습신경망 model, 학습데이터 train_loader, 손실함수, criterion, weight 수정알고리즘 optimizer를 가지고 epochs 전체 데이터 반복횟수는 30, L2규제 강도는 0.0 으로 맞췄다 .
loss_histroy[]에 epoch마다 평균 lodd를 저장해 loss가 줄어드는지 확인할것이다 .
moel.train() 모델 학습모드로 전환한다.
epoch마다 반복한다. 이 함수에서는 30번 반복한다는 의미가 될것이다. 이 안에서 미니배치를 반복한다. 앞서 미니배치를 정의했었다. 데이터를 한번에 다 넣지않고 나눠 학습한다는 의미. 다중 for문.
device(앞서 확인했다. gpu가 될수도, cpu가 될수도있다 .)로 데이터를 이동시킨다.
pytorch는 이전 배치를 누적하는데 이것을 제거했다 .기울기가 게속 쌓이지않고 독립적으로 돌려가며 학습하기 위함이다.
입력데이터를 model() 모델에넣는다.
loss를 계한한다.
L2는 weight가 너무 커지는걸 방지한다.
loss는 분류오차이고 모델은 성능을 높이려고 가중치를 너무 크게 만들 수도 있다.
이때 가중치가 너무 크면 벌점을 주자는 의미로 L2개념이 있다. model.parameters() 모델안의 모든 가중치를 가져와 각 가중치 param을 제곱하고 torch.sum 제곱한 값을 모두 더한다. 즉 모든 가중치의 제곱합을 계산하는것.
그리고 loss, loss에 이 제곱합 벌점을 추가한다.
최종 손실은 원래손실뿐만 아니라 가중치벌점을 더해 큰 손실을 얻게된다. L2_lambda는 결국 벌점 강도이고 작으면 약하게, 크면 강하게 규제한다.
optimizer는 loss를 줄이는 방향으로만 움직이고 모델은 정답도 맞춰야하고 가중치도 너무 크면 안된다는 동시목표가 생긴다. 약간 덜 정확하더라도 가중치가 지나치게 큰 모델은 피한다는것.
이제 이 loss.backward()를 실행하여 loss를 줄이기 위해 어떤 weight를 얼마나 수정해야하는가, 기울기를 계산시킨다. 이것을 gradient라는게 한다.
실제로 optimizer.strp()계산된 기울기를 이용해서 모델 파라미터를 업데이트하고
loss를 기록하고,
평균 오차도 계산하여 기록을 저장한다.
# ============================================================
# 10. 모델 학습 함수 정의
# ============================================================
def train_model(model, train_loader, criterion, optimizer, epochs=30, l2_lambda=0.0):
# model: 학습할 PyTorch 모델입니다.
# train_loader: 미니배치 단위로 데이터를 공급하는 DataLoader입니다.
# criterion: 손실 함수입니다.
# optimizer: 모델 파라미터를 업데이트하는 최적화 알고리즘입니다.
# epochs: 전체 데이터를 몇 번 반복 학습할지 정합니다.
# l2_lambda: SVM의 C와 반대 성격에 가까운 L2 규제 강도입니다.
# epoch별 평균 손실을 저장할 리스트입니다.
loss_history = []
# 모델을 학습 모드로 전환합니다.
model.train()
# 지정된 epoch 수만큼 반복합니다.
for epoch in range(epochs):
# 한 epoch 동안의 손실 합계를 저장합니다.
total_loss = 0.0
# DataLoader에서 미니배치 데이터를 하나씩 꺼냅니다.
for batch_X, batch_y in train_loader:
# 입력 데이터를 GPU 또는 CPU 장치로 이동합니다.
batch_X = batch_X.to(device)
# 정답 데이터를 GPU 또는 CPU 장치로 이동합니다.
batch_y = batch_y.to(device)
# 이전 배치에서 계산된 기울기를 초기화합니다.
optimizer.zero_grad()
# 모델에 입력 데이터를 넣어 클래스별 점수를 계산합니다.
scores = model(batch_X)
# SVM hinge loss를 계산합니다.
loss = criterion(scores, batch_y)
# L2 규제 항을 추가합니다.
# SVM은 마진 최대화를 위해 가중치 크기를 제어하는 규제를 사용합니다.
if l2_lambda > 0:
l2_norm = sum(torch.sum(param ** 2) for param in model.parameters())
loss = loss + l2_lambda * l2_norm
# 손실에 대한 기울기를 자동 계산합니다.
loss.backward()
# 계산된 기울기를 이용해 모델 파라미터를 업데이트합니다.
optimizer.step()
# 현재 배치 손실을 누적합니다.
total_loss += loss.item()
# 한 epoch의 평균 손실을 계산합니다.
avg_loss = total_loss / len(train_loader)
# 평균 손실을 리스트에 저장합니다.
loss_history.append(avg_loss)
# 5 epoch마다 학습 상황을 출력합니다.
if (epoch + 1) % 5 == 0:
print(f"Epoch [{epoch+1}/{epochs}], Loss: {avg_loss:.4f}")
# 학습 손실 기록을 반환합니다.
return loss_history
평가함수정의
model.eval() 평가모드로 바꿨다.
no.grad로 기울기 계산하지말고 클래스별 점수를 출력해 가장 높은 arg.max 클래스번호를 예측값으로 선택해서
정확도를 계산해 정확도와 예측값을 반환했다 .
# ============================================================
# 11. 평가 함수 정의
# ============================================================
def evaluate_model(model, X_tensor, y_tensor):
# model: 평가할 PyTorch 모델입니다.
# X_tensor: 평가 입력 데이터입니다.
# y_tensor: 실제 정답 데이터입니다.
# 모델을 평가 모드로 전환합니다.
model.eval()
# 평가에서는 기울기를 계산할 필요가 없으므로 no_grad를 사용합니다.
with torch.no_grad():
# 입력 데이터를 장치로 이동합니다.
X_tensor = X_tensor.to(device)
# 모델이 클래스별 점수를 출력합니다.
scores = model(X_tensor)
# 가장 높은 점수를 가진 클래스 번호를 예측값으로 선택합니다.
preds = torch.argmax(scores, dim=1)
# 예측값을 CPU numpy 배열로 변환합니다.
preds_np = preds.cpu().numpy()
# 실제 정답도 numpy 배열로 변환합니다.
y_np = y_tensor.cpu().numpy()
# 정확도를 계산합니다.
acc = accuracy_score(y_np, preds_np)
# 정확도와 예측 결과를 반환합니다.
return acc, preds_np
선형 svm 학습을 시작한다.
앞서 만든것들을 실제로 연결하는 것이다 .
LinearSVMClassifier 객체를 생성해 특징갯수, 클래스 개수를 할당해주고
margin은 1.0으로 정답점수는 오답보다 최소 1이상 크게 명령했다. 앞서 우리가 만든 손실함수 MultiClassHingeLoss를 활용해 객체를 생성했다.
torch.optin.adam 을 사용해 파라미터를 업데이트했다. optimizer란 weight 수정 담당, adam이 하는 일은 loss.backward() 로 gradient가 계산되면 gredient를 이용해서 weight를 얼마나 수정할지를 결정하는 것. 이때 모델 안의 학습가능한 weight들, 그리고 학습률 weight를 얼마나 크게 수정할지를 결정하는 값을 들려 보내주며 실행하라하는것.
위에서 만든 train_model 로 각 값을 넣어 epochs를 50으로 주고, l2규제강도는 12-4를 주고 학습시켰다.
# ============================================================
# 12. 선형 SVM 모델 생성 및 학습
# ============================================================
# 선형 SVM 모델 객체를 생성합니다.
linear_svm = LinearSVMClassifier(
input_dim=num_features, # 입력 특징 개수입니다.
num_classes=num_classes # 분류할 클래스 개수입니다.
).to(device)
# 다중 클래스 hinge loss 객체를 생성합니다.
criterion = MultiClassHingeLoss(margin=1.0)
# Adam optimizer를 사용하여 모델 파라미터를 업데이트합니다.
optimizer = torch.optim.Adam(
linear_svm.parameters(), # 학습할 모델 파라미터입니다.
lr=0.01 # 학습률입니다.
)
# 선형 SVM 모델을 학습합니다.
linear_loss_history = train_model(
model=linear_svm, # 학습할 모델입니다.
train_loader=train_loader, # 훈련 데이터 로더입니다.
criterion=criterion, # SVM 손실 함수입니다.
optimizer=optimizer, # 최적화 알고리즘입니다.
epochs=50, # 전체 데이터를 50번 반복 학습합니다.
l2_lambda=1e-4 # L2 규제 강도입니다.
)
이제 평가해보자.
학습된 모델 linear_svm에게 테스트 x_test_tensor, y_test_tensor 데이터를 넣어 evaluate_model 성능을 평가한다.
정확도를 출력한다 .
숫자 예측값을 문자레벨로 label_encoder.inverse_transform() 다시 복원해 출력해본다.
# ============================================================
# 13. 선형 SVM 평가
# ============================================================
# 테스트 데이터로 선형 SVM 모델 성능을 평가합니다.
linear_acc, linear_preds = evaluate_model(linear_svm, X_test_tensor, y_test_tensor)
# 정확도를 출력합니다.
print(f"선형 SVM 테스트 정확도: {linear_acc:.4f}")
# 숫자 예측값을 문자 라벨로 다시 변환합니다.
linear_pred_letters = label_encoder.inverse_transform(linear_preds)
# 예측 결과 일부를 출력합니다.
print("예측 문자 일부:", linear_pred_letters[:20])
모델의 평과를 지표로 표현해보자. 리포트
실행..
혼동행렬이 출력된다. confusion_matrix에서 대각선으로 표현되고 나머지가 0인 경우에 정확도가 높다는 소리다 .
현재 보면 정확도가 높긴한데 조금씩 정확하지않은 값들이 보인다 .
# ============================================================
# 14. 선형 SVM 혼동 행렬 및 분류 리포트
# ============================================================
# 혼동 행렬을 계산합니다.
cm_linear = confusion_matrix(y_test, linear_preds)
# 혼동 행렬을 DataFrame으로 변환하여 보기 쉽게 만듭니다.
cm_linear_df = pd.DataFrame(
cm_linear,
index=label_encoder.classes_,
columns=label_encoder.classes_
)
# 혼동 행렬을 출력합니다.
cm_linear_dfA B C D E F G H I J ... Q R S T U V W X Y Z
A 137 0 0 2 0 0 0 0 0 1 ... 2 2 4 0 1 0 1 0 3 1
B 0 102 0 1 0 3 0 2 3 2 ... 3 7 8 0 0 0 0 0 0 0
C 0 0 101 0 5 1 7 0 0 0 ... 0 0 0 3 4 1 0 0 0 0
D 0 11 0 134 0 0 0 3 0 1 ... 1 3 2 2 0 0 0 0 0 1
E 0 6 2 0 108 1 11 0 0 0 ... 2 3 3 5 0 0 0 3 0 4
F 0 1 1 1 2 110 4 2 0 1 ... 0 0 2 13 0 0 1 1 5 0
G 0 1 30 1 0 1 61 6 0 0 ... 34 6 5 0 0 3 0 0 0 0
H 0 1 1 7 0 1 2 64 0 2 ... 2 15 0 4 8 5 0 2 1 0
I 0 0 0 5 0 6 0 0 126 5 ... 1 0 6 0 0 0 0 10 1 2
J 7 0 0 4 0 4 0 0 8 114 ... 3 0 3 0 0 0 0 0 0 4
K 1 2 4 2 1 0 4 1 0 0 ... 0 21 1 1 1 0 0 2 0 0
L 0 1 2 4 1 0 2 0 0 0 ... 10 1 5 0 0 0 0 7 1 0
M 5 1 0 1 0 0 0 1 0 0 ... 0 3 0 0 2 0 1 0 0 0
N 3 0 0 3 0 0 0 8 0 0 ... 0 2 0 1 1 3 2 0 2 0
O 3 0 5 3 0 0 8 47 0 1 ... 3 2 0 3 0 0 4 2 0 0
P 0 1 0 2 0 21 3 0 0 1 ... 1 1 1 1 0 0 1 0 10 0
Q 4 2 4 1 0 0 3 7 0 3 ... 109 0 17 0 0 1 1 1 0 0
R 1 12 0 3 0 0 2 1 0 1 ... 1 123 0 0 0 0 0 1 0 0
S 0 12 0 1 6 2 3 1 0 1 ... 5 2 84 2 0 0 0 4 4 22
T 1 0 0 0 2 10 5 0 0 0 ... 0 2 4 110 2 0 0 2 11 2
U 1 0 1 1 0 0 1 4 0 0 ... 0 0 0 0 143 0 6 0 0 0
V 0 1 0 0 0 2 0 1 0 0 ... 0 4 0 0 0 111 4 0 9 0
W 1 0 0 0 0 0 0 1 0 0 ... 0 0 0 0 0 1 117 0 0 0
X 0 1 0 5 3 0 2 0 6 0 ... 2 0 8 3 0 0 0 118 2 0
Y 0 0 0 4 0 5 0 0 1 0 ... 2 0 0 3 1 4 0 3 121 0
Z 0 2 0 1 5 1 0 0 0 13 ... 3 0 9 6 0 0 0 2 0 114
26 rows × 26 columns
분류리포트로 출력해보자.
각 맞히는 확률이 나온다. a를 맞추는 정확도가 젤 높아보인다 .
# ============================================================
# 15. 선형 SVM 분류 리포트 출력
# ============================================================
# precision, recall, f1-score를 포함한 분류 성능 리포트를 출력합니다.
print(classification_report(
y_test,
linear_preds,
target_names=label_encoder.classes_
)) precision recall f1-score support
A 0.84 0.88 0.86 156
B 0.65 0.75 0.70 136
C 0.67 0.71 0.69 142
D 0.72 0.80 0.76 167
E 0.81 0.71 0.76 152
F 0.65 0.72 0.69 153
G 0.52 0.37 0.43 164
H 0.43 0.42 0.43 151
I 0.88 0.76 0.82 165
J 0.78 0.77 0.78 148
K 0.59 0.70 0.64 146
L 0.74 0.75 0.75 157
M 0.82 0.83 0.82 144
N 0.77 0.77 0.77 166
O 0.56 0.40 0.46 139
P 0.88 0.71 0.79 168
Q 0.59 0.65 0.62 168
R 0.62 0.76 0.69 161
S 0.52 0.52 0.52 161
T 0.70 0.73 0.71 151
U 0.88 0.85 0.86 168
V 0.86 0.82 0.84 136
W 0.85 0.84 0.84 139
...
accuracy 0.71 4000
macro avg 0.71 0.71 0.71 4000
weighted avg 0.71 0.71 0.71 4000
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
71%이니 보완을 좀 해야할듯하다. 성능 개선 단계. 이때 위에서 봤던 RBF 커널 효과를 구현해보자.
RBFFeatureSVMClassifier 클래스 생성
init시 rbf_dim을 512 로 차원설정 + 무작위 방향 벡터 w를 생성한다 . 이 w는 register_buffer로 학습은 안하지만 모델과 함께 저장된다. rff는 랜덤 변환자체는 고정하고 선형 분류만 학습하기 때문이다 .
b를 생성해 무작위 위상을 만들고 cos변환 다양성을 위해 사용한다.
입력데이터 x에 무작위 행렬 w와 위상 b를 적용한 뒤 cos 변환을 수행하여 비선형 특징공간으로 변환했다.
변환된 특징은 linear 계층으로 전달되어서 각 클래스의 점수를 계산한다.
# ============================================================
# 16. RBF 특징 근사 + SVM 모델 클래스 정의
# ============================================================
class RBFFeatureSVMClassifier(nn.Module):
# Random Fourier Features로 RBF 커널 효과를 근사하는 SVM 모델입니다.
def __init__(self, input_dim, num_classes, rbf_dim=512, gamma=0.1):
# 부모 클래스 초기화입니다.
super().__init__()
# rbf_dim은 RBF 근사 특징의 차원 수입니다.
self.rbf_dim = rbf_dim
# gamma는 RBF 커널의 영향 범위를 조절합니다.
# gamma가 크면 가까운 점에만 강하게 반응하고, 작으면 넓게 반응합니다.
self.gamma = gamma
# Random Fourier Features에서 사용할 무작위 가중치 W입니다.
# RBF 커널 근사를 위해 정규분포에서 샘플링합니다.
W = torch.randn(input_dim, rbf_dim) * np.sqrt(2 * gamma)
# 학습되지 않는 버퍼로 등록합니다.
# 모델과 함께 device 이동은 되지만 optimizer가 업데이트하지 않습니다.
self.register_buffer("W", W)
# 무작위 위상 b입니다.
b = 2 * np.pi * torch.rand(rbf_dim)
# b도 학습되지 않는 버퍼로 등록합니다.
self.register_buffer("b", b)
# 변환된 RBF 근사 특징을 클래스 점수로 바꾸는 선형 계층입니다.
self.linear = nn.Linear(rbf_dim, num_classes)
def rbf_features(self, x):
# 입력 x를 Random Fourier Features로 변환합니다.
# x @ W + b를 계산합니다.
projection = x @ self.W + self.b
# cos 변환을 적용하여 비선형 특징을 만듭니다.
z = torch.cos(projection)
# 특징 크기를 안정적으로 맞추기 위해 sqrt(2 / rbf_dim)를 곱합니다.
z = z * np.sqrt(2.0 / self.rbf_dim)
# 변환된 특징을 반환합니다.
return z
def forward(self, x):
# 입력 x를 RBF 근사 특징으로 변환합니다.
z = self.rbf_features(x)
# 변환된 특징으로 클래스별 점수를 계산합니다.
scores = self.linear(z)
# 클래스별 점수를 반환합니다.
return scores
RbF 커널 느낌을 흉내낸 SVM 모델을 만들고 학습해보자.
num_features 특징갯수를 input_dim에 할당했다.
num_classes 클래스 갯수를 num_classes에 할당했다.
rbf_dim=1024, 데이터를 더 복잡한 공간으로 확장했다.
*데이터는 단순한 직선으론 잘 구분되지않고 rbf 특징을 1024개 만들어, 1024차원 공간으로 보낸다. 구겨진 종이를 펼쳐 직선으로 자르기 위함으로 볼 수 있는데 이 1024란 숫자는 너무 작으면 표현력이 부족하고 너무 크면 메모리 연산이 증가하고과적합이 가능해 적절한 값을 선택하게 된다. 보통 256, 512, 1024, 2048값을 많이 사용한다.
gamma는 0.05를 줬다. rbf 커널 영향범위 조절값으로 얼마나 세밀하게 구분할지를 정하는 값이다. 이 값이 작으면 넓고 부드러운 경계로 보고 크면 아주 세세하게본다.
*gamma는 rbf 커널에서 하나의 데이터가 주변에 얼마나 큰 영향을 미치는가를 결정하는 값이다 .rbf커널은 가까운 데이터끼리 비슷하게 보고 먼데이터느 ㄴ다르게 보는데 gamma가 이 영향범위를 조절한다. 이 gamma는 보통 너무 작지도, 크지도 않은 중간 값을 자주사용하고 주로 0.001의 매우 부드러운 값, 0.01~0.1 많이 사용하는 범위, 1이상(매우민감하나 과적합위험증가한다)값을 사용한다.
다음 가중치를 어떻게 수정할지 결정하는 알고리즘인 adam을 사용해 optimizer를 생성했다. adam은 딥러닝에서 가장 많이 사용하는 최적화 알고리즘으로 모델의 오차 즉 loss를 줄이기 위해 가중치 weight를 어떻게 수정할지 계산하는 것이다.
가중치는 머신러닝이라 딥러닝에서 각 입력값이 결과에 얼마나 중요한지를 나타내는 값으로 공부시간, 출석률, 과제점수가 있다면 모델은 각 항목의 중요도를 다르게 본다 .공부시간에는 0.7, 출석률엔 0.2 과제점수에는 0.1 정도 부여할 수 있겠다면 이 숫자들이 바로 가중치
예측 - 오차계산 - 가중치 수정 - 다시 예측
가중치를 얼마나, 어느 방향으로 바꿀지를 결정하는 것이 optimizer이고 adam은 현재 기울기, 기울기평균, 변화량을 함꼐 고려해 효율적으로 가중치를 업데이트해 학습속도가 빠르고 안정적으로 만든다. 이떄 lr는 학습률로 얼마나 크게 수정할지를 나타낸다 .너무 크면 불안정할 수 있고 너무 작으면 학습이 느릴 수 있다.
이제 앞서 작성한 모델학습 함수정의한 train_model으로 학습해보자.
# ============================================================
# 17. RBF 특징 SVM 모델 생성 및 학습
# ============================================================
# RBF 특징 SVM 모델 객체를 생성합니다.
rbf_svm = RBFFeatureSVMClassifier(
input_dim=num_features, # 원본 입력 특징 개수입니다.
num_classes=num_classes, # 클래스 개수입니다.
rbf_dim=1024, # RBF 근사 특징 차원입니다.
gamma=0.05 # RBF 영향 범위 조절값입니다.
).to(device)
# RBF 모델용 optimizer를 생성합니다.
rbf_optimizer = torch.optim.Adam(
rbf_svm.parameters(), # 학습할 파라미터입니다.
lr=0.01 # 학습률입니다.
)
# RBF 특징 SVM 모델을 학습합니다.
rbf_loss_history = train_model(
model=rbf_svm, # 학습할 모델입니다.
train_loader=train_loader, # 훈련 데이터 로더입니다.
criterion=criterion, # SVM hinge loss입니다.
optimizer=rbf_optimizer, # 최적화 알고리즘입니다.
epochs=50, # 전체 데이터를 50번 반복 학습합니다.
l2_lambda=1e-4 # L2 규제 강도입니다.
)Epoch [5/50], Loss: 1.2472
Epoch [10/50], Loss: 1.0050
Epoch [15/50], Loss: 0.9528
Epoch [20/50], Loss: 0.9303
Epoch [25/50], Loss: 0.9325
Epoch [30/50], Loss: 0.9302
Epoch [35/50], Loss: 0.9418
Epoch [40/50], Loss: 0.9345
Epoch [45/50], Loss: 0.9434
Epoch [50/50], Loss: 0.9353
다시평가해보자.
# ============================================================
# 18. RBF 특징 SVM 평가
# ============================================================
# 테스트 데이터로 RBF 특징 SVM 모델 성능을 평가합니다.
rbf_acc, rbf_preds = evaluate_model(rbf_svm, X_test_tensor, y_test_tensor)
# 정확도를 출력합니다.
print(f"RBF 특징 SVM 테스트 정확도: {rbf_acc:.4f}")
# 숫자 예측값을 문자 라벨로 다시 변환합니다.
rbf_pred_letters = label_encoder.inverse_transform(rbf_preds)
# 예측 결과 일부를 출력합니다.
print("예측 문자 일부:", rbf_pred_letters[:20])RBF 특징 SVM 테스트 정확도: 0.9127
예측 문자 일부: ['U' 'N' 'V' 'X' 'N' 'H' 'E' 'Y' 'C' 'E' 'N' 'B' 'G' 'L' 'G' 'W' 'M' 'D'
'Y' 'R']
혼동행렬도 다시 확인해보자. 카테고리가 26개다보니 다중 클래스기때문에 svm이 성능이 떨어진것이고 이것을 개선한것이다.
확연히 나아졌다.
# ============================================================
# 19. RBF 특징 SVM 혼동 행렬
# ============================================================
# 혼동 행렬을 계산합니다.
cm_rbf = confusion_matrix(y_test, rbf_preds)
# 혼동 행렬을 DataFrame으로 변환합니다.
cm_rbf_df = pd.DataFrame(
cm_rbf,
index=label_encoder.classes_,
columns=label_encoder.classes_
)
# 혼동 행렬을 출력합니다.
cm_rbf_dfA B C D E F G H I J ... Q R S T U V W X Y Z
A 147 0 0 0 0 0 0 0 0 0 ... 0 1 1 0 0 0 1 1 4 1
B 0 128 0 0 0 0 0 2 0 1 ... 0 2 2 0 0 0 0 1 0 0
C 0 0 132 0 5 0 1 0 0 0 ... 1 0 0 0 1 0 0 0 0 0
D 0 8 0 156 0 0 0 1 0 0 ... 0 1 0 0 1 0 0 0 0 0
E 0 2 3 0 132 0 6 0 0 0 ... 0 2 1 0 0 0 0 3 0 3
F 0 1 0 0 3 143 0 2 0 1 ... 0 0 0 0 0 0 0 0 0 0
G 0 1 14 3 1 0 129 3 0 0 ... 4 3 0 0 1 0 2 1 0 0
H 0 1 1 5 0 0 2 132 0 0 ... 1 2 0 0 0 0 0 1 1 0
I 0 1 3 2 0 5 0 0 140 4 ... 0 0 3 0 0 0 0 6 0 0
J 0 0 0 0 2 0 0 0 1 141 ... 0 0 2 0 0 0 0 1 0 0
K 0 0 0 1 0 0 0 4 0 0 ... 0 5 0 0 1 0 0 4 0 0
L 0 1 2 0 2 0 1 2 0 0 ... 1 0 2 0 0 0 0 4 0 0
M 0 1 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
N 0 0 0 2 0 0 0 4 0 0 ... 0 0 0 0 0 0 0 0 1 0
O 1 0 3 2 0 0 0 0 0 1 ... 3 2 0 0 0 0 4 0 0 0
P 0 3 0 4 1 17 0 3 0 0 ... 3 0 0 0 0 0 0 0 4 0
Q 3 2 0 1 0 0 0 1 0 0 ... 157 0 0 0 0 0 0 0 0 0
R 0 4 1 2 0 0 0 6 0 0 ... 0 141 0 0 0 0 0 0 0 0
S 0 5 0 0 1 0 1 0 0 0 ... 0 0 151 0 0 0 0 1 0 1
T 0 1 0 0 0 1 0 2 0 0 ... 0 1 2 141 0 0 0 1 2 0
U 0 1 0 0 0 0 0 1 0 0 ... 0 0 0 0 162 0 2 0 0 0
V 0 2 0 0 0 0 0 1 0 0 ... 1 0 0 1 0 127 3 0 1 0
W 0 0 0 0 0 0 0 1 0 0 ... 0 0 0 0 0 0 135 0 1 0
X 0 1 0 2 2 0 0 0 0 0 ... 0 0 0 0 2 0 0 149 0 0
Y 0 0 0 0 0 1 0 0 0 1 ... 0 0 0 1 1 2 0 1 138 0
Z 0 0 0 0 1 0 0 0 0 2 ... 0 0 3 2 0 0 0 1 0 148
26 rows × 26 columns
리포트로도 출력해보자.
# ============================================================
# 20. RBF 특징 SVM 분류 리포트 출력
# ============================================================
# precision, recall, f1-score를 포함한 분류 성능 리포트를 출력합니다.
print(classification_report(
y_test,
rbf_preds,
target_names=label_encoder.classes_
)) precision recall f1-score support
A 0.97 0.94 0.96 156
B 0.79 0.94 0.86 136
C 0.83 0.93 0.88 142
D 0.87 0.93 0.90 167
E 0.88 0.87 0.87 152
F 0.86 0.93 0.89 153
G 0.92 0.79 0.85 164
H 0.80 0.87 0.84 151
I 0.99 0.85 0.92 165
J 0.93 0.95 0.94 148
K 0.92 0.90 0.91 146
L 0.98 0.90 0.94 157
M 0.95 0.99 0.97 144
N 0.94 0.92 0.93 166
O 0.91 0.88 0.90 139
P 1.00 0.78 0.88 168
Q 0.92 0.93 0.93 168
R 0.88 0.88 0.88 161
S 0.90 0.94 0.92 161
T 0.97 0.93 0.95 151
U 0.96 0.96 0.96 168
V 0.98 0.93 0.96 136
W 0.92 0.97 0.94 139
...
accuracy 0.91 4000
macro avg 0.92 0.91 0.91 4000
weighted avg 0.92 0.91 0.91 4000
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
loss시각화를 해보자.
모델이 안정적이면 그래프에 흔들림이 많이 없다 .
주황색그래프, 테스트에 대한 로스가 더 낮다는것은 문제를 잘 푼다는 의미로 기출문제를 외운게 아니라는 의미
# ============================================================
# 21. 학습 손실 그래프
# ============================================================
# 그래프 크기를 설정합니다.
plt.figure(figsize=(10, 5))
# 선형 SVM 손실 곡선을 그립니다.
plt.plot(linear_loss_history, label="Linear SVM Loss")
# RBF 특징 SVM 손실 곡선을 그립니다.
plt.plot(rbf_loss_history, label="RBF Feature SVM Loss")
# 그래프 제목을 설정합니다.
plt.title("SVM Training Loss")
# x축 이름을 설정합니다.
plt.xlabel("Epoch")
# y축 이름을 설정합니다.
plt.ylabel("Hinge Loss")
# 범례를 표시합니다.
plt.legend()
# 격자선을 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()
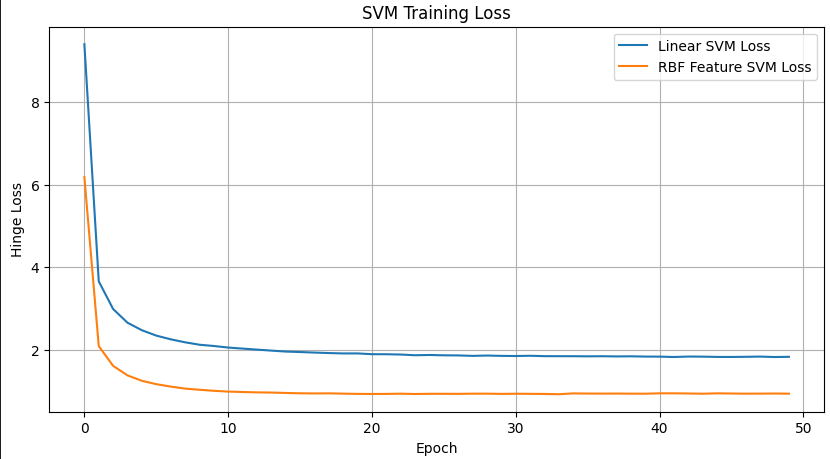
위 두개이 정확도를 비교해보자.
# ============================================================
# 22. 선형 SVM과 RBF 특징 SVM 성능 비교
# ============================================================
# 결과를 DataFrame으로 정리합니다.
result_df = pd.DataFrame({
"Model": ["Linear SVM", "RBF Feature SVM"],
"Test Accuracy": [linear_acc, rbf_acc]
})
# 결과를 출력합니다.
result_dfModel Test Accuracy
0 Linear SVM 0.71175
1 RBF Feature SVM 0.91275
이 둘의 예측결과 샘플도 비교해보자.
U를 svm은 w로, rbf는 U로 분류한 등의 더 나은 결과값을 내고있다는것을 직접적으로 확인해볼 수 있따.
# ============================================================
# 23. 예측 결과 샘플 비교
# ============================================================
# 실제 문자 라벨을 복원합니다.
true_letters = label_encoder.inverse_transform(y_test)
# 비교할 샘플 개수를 지정합니다.
sample_count = 30
# 실제값, 선형 SVM 예측값, RBF SVM 예측값을 표로 정리합니다.
compare_df = pd.DataFrame({
"Actual": true_letters[:sample_count],
"Linear_SVM_Pred": linear_pred_letters[:sample_count],
"RBF_Feature_SVM_Pred": rbf_pred_letters[:sample_count]
})
# 비교 결과를 출력합니다.
compare_dfActual Linear_SVM_Pred RBF_Feature_SVM_Pred
0 U W U
1 N N N
2 V R V
3 I X X
4 N N N
5 H H H
6 E E E
7 Y Y Y
8 G G C
9 E E E
10 N N N
11 B I B
12 G G G
13 L L L
14 E G G
15 G M W
16 M M M
17 D D D
18 Y F Y
19 R R R
20 P P P
21 D D D
22 E E E
23 W W W
24 D D D
25 Q S Q
26 R R R
27 G G G
28 Y Y Y
29 R R K
최근접 이웃 KNN 알고리즘
앞서서 간단히 알아봤던 KNN을 상세히 알아보자 .
KNN은 레이블이 없는 예시를 유사한 클래스로 할당 및 분류하는 것으로 현재 결론을 위해 과거 경험을 적용하는 회상능력을 적용한다.
K-Nearest Neighbors (KNN)
가장 가까운 K개의 데이터를 보고 분류한다.
유클리드 거리함수를 사용함.
직관적이고 구현이 쉬우나 데이터많으면 느리고 값을 표준화시키는 standerd scale영향이 크다.
"주변 5개중 4개가 고양이면 고양이로 분류"
분류시 일반적 특징과 타깃 클래스간의 관계가 복잡하다 .간단히 맞다, 아니다로 분류되는 세상이 아니란 소리.
또 이해하기 어렵거나 유사한 클래스유형이 생각보다 많아 동질적인 경향으로 분류할때가 많아 현재 분석의 문제점을 해결하기 위해 KNN을 사용한다 .
개념정의가 어렵고 데이터에 노이즈가 많거나 그룹간 구분이 없고 이웃 알고리즘 클래스 경계를 식별하기 어려울때 사용하는게 좋다 .svm으로 잘 안되면 knn으로 바꾸는것이 방법이 될수있단 소리
k-NN k-nearest neighbors 알고리즘
아래의 산포도를 만들기 위해 어떻게할까?
단순하고 효율적이며 분포영역이 영향을 받지않고 훈련이 신속하나 모델 생성없이 특징과 클래스간 관계이해능력이 부족하다. 다른 의미로 분류 진행단계가 느리다. 또 적합한 k선택 과정이 필요하다. 이웃몇개를 추출할것인가 란 의미. 명목적 특징과 누락된 데이터 용도로 추가적인 처리가 필요하다.
여러 카테고리로 분류되잇고 훈련된 데이터셋이 필요하고.. 정답이 없어도된다. 유사도로 분류기준으로 하기 때문이다. 가장 근접한 k개의 레코드를 검색해 레이블이 없는 테스트 인스턴스도 k개의 최근접 이웃이 많은 클래스에 배정된다.
경계가 애매한 경우엔 토마토가 과일로 들어갈수도있고 그렇다. 거리유사도를 측정해 , 거리함수, 유클리드거리 혹은 두인스턴스 사이 유사도 측정하는 함수를 통해 분류한다 .
k가 커질수록 편향이 감소되지만 분산이 커지고 k가 작아지면 반대로된다. 모두 장단점이 있음
knn알고리즘을 pytorch가 지원하지않다 직접 구현해야한다.



샘플 코드를 분석해보자.
import부분은 위와 아주 유사하다.
머신러닝은 import하는 조합들이 대개 비슷하다.
# ============================================================
# 0. 기본 라이브러리 불러오기
# ============================================================
# PyTorch는 텐서 연산과 GPU 연산을 지원하는 딥러닝/수치연산 라이브러리입니다.
import torch
# pandas는 표 형태의 데이터를 다루기 위한 라이브러리입니다.
import pandas as pd
# numpy는 배열 계산을 위한 라이브러리입니다.
import numpy as np
# matplotlib은 그래프를 그리기 위한 라이브러리입니다.
import matplotlib.pyplot as plt
# sklearn의 breast cancer 데이터셋은 R 코드의 Wisconsin 유방암 데이터와 같은 계열의 실습 데이터입니다.
from sklearn.datasets import load_breast_cancer
# 정확도, 혼동행렬, 분류 리포트를 계산하기 위한 평가 도구입니다.
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 실행 장치를 설정합니다.
# GPU가 있으면 cuda를 사용하고, 없으면 cpu를 사용합니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 현재 사용하는 실행 장치를 출력합니다.
print("사용 장치:", device)
Wisconsin Breast Cancer 데이터셋을 sklearn에서 불러왔다. 이 데이터는 참고로 종양의 반지름, 질감, 면적 등 수치형 특징을 포함한다.
DataFrame으로 변환한다 .
정답인 종속변수 y를 만들어 series로 변환한다.
target이라는 값을 series로 만드는 이유는 데이터 분석 구조를 맞추기 위한것으로 x의 차원에 맞추기위해
양성, 음성의 라벨을 0, 1로 바꾼다. map이라는 함수를 사용하면 label이랑 동일한 효과를 낸다 .
또 계산을 위해 문자라벨들을 숫자 라벨로 변환했다 .
데이터를 우선 확인해보자.
# ============================================================
# 1. Wisconsin Breast Cancer 데이터셋 불러오기
# ============================================================
# sklearn에서 유방암 진단 데이터셋을 불러옵니다.
# 이 데이터셋은 종양의 반지름, 질감, 면적 등 수치형 특징을 포함합니다.
breast = load_breast_cancer()
# 독립변수 X를 DataFrame으로 변환합니다.
# breast.data에는 모델 입력으로 사용할 수치형 특징들이 들어 있습니다.
X_df = pd.DataFrame(breast.data, columns=breast.feature_names)
# 종속변수 y를 Series로 변환합니다.
# sklearn 데이터셋에서는 target 값이 0 또는 1로 제공됩니다.
y_series = pd.Series(breast.target, name="diagnosis_raw")
# sklearn의 target 이름을 확인합니다.
# 일반적으로 0은 malignant, 1은 benign입니다.
print("sklearn target_names:", breast.target_names)
# 라벨을 Benignant / Malevolent 형태로 맞춥니다.
# sklearn에서는 0=malignant, 1=benign이므로, 여기서는 0/1을 다시 매핑합니다.
# Benignant는 양성, Malevolent는 악성이라는 학습용 이름으로 사용합니다.
y_label = y_series.map({1: "Benignant", 0: "Malevolent"})
# PyTorch 계산을 위해 문자열 라벨을 숫자 라벨로 변환합니다.
# Benignant -> 0, Malevolent -> 1
y_encoded = y_label.map({"Benignant": 0, "Malevolent": 1}).values
# 전체 데이터 크기를 확인합니다.
print("입력 데이터 크기:", X_df.shape)
print("라벨 데이터 크기:", y_encoded.shape)
# 데이터 앞부분을 확인합니다.
display(X_df.head())
# 라벨 분포를 확인합니다.
print("라벨 분포:")
print(y_label.value_counts())
# 라벨 비율을 확인합니다.
print("라벨 비율(%):")
print(round(y_label.value_counts(normalize=True) * 100, 2))sklearn target_names: ['malignant' 'benign']
입력 데이터 크기: (569, 30)
라벨 데이터 크기: (569,)
mean radius mean texture mean perimeter mean area mean smoothness mean compactness mean concavity mean concave points mean symmetry mean fractal dimension ... worst radius worst texture worst perimeter worst area worst smoothness worst compactness worst concavity worst concave points worst symmetry worst fractal dimension
0 17.99 10.38 122.80 1001.0 0.11840 0.27760 0.3001 0.14710 0.2419 0.07871 ... 25.38 17.33 184.60 2019.0 0.1622 0.6656 0.7119 0.2654 0.4601 0.11890
1 20.57 17.77 132.90 1326.0 0.08474 0.07864 0.0869 0.07017 0.1812 0.05667 ... 24.99 23.41 158.80 1956.0 0.1238 0.1866 0.2416 0.1860 0.2750 0.08902
2 19.69 21.25 130.00 1203.0 0.10960 0.15990 0.1974 0.12790 0.2069 0.05999 ... 23.57 25.53 152.50 1709.0 0.1444 0.4245 0.4504 0.2430 0.3613 0.08758
3 11.42 20.38 77.58 386.1 0.14250 0.28390 0.2414 0.10520 0.2597 0.09744 ... 14.91 26.50 98.87 567.7 0.2098 0.8663 0.6869 0.2575 0.6638 0.17300
4 20.29 14.34 135.10 1297.0 0.10030 0.13280 0.1980 0.10430 0.1809 0.05883 ... 22.54 16.67 152.20 1575.0 0.1374 0.2050 0.4000 0.1625 0.2364 0.07678
5 rows × 30 columns
라벨 분포:
diagnosis_raw
Benignant 357
Malevolent 212
Name: count, dtype: int64
라벨 비율(%):
diagnosis_raw
Benignant 62.74
Malevolent 37.26
Name: proportion, dtype: float64
또 describe(), 요약 통계를 확인해보자.
평균분포를 보니 mean 차이가 꽤 간다. 전체적으로 수치 차이가 크다 . 값이 차이가 크면 모델의 학습이 불안정하다 .값의 범위가 크면 그렇다. 이때 스케일링이 필요하겠다~ 라고 이해한다. KNN은 거리 기반 알고리즘이고 특징 값의 범위가 크면 거리계산이 특정 컬럼에 치우칠 수 있다. area값이 수백이고 smoothness값은 0.x범위일경우가 그렇다.
# ============================================================
# 2. 주요 특징 요약 확인
# ============================================================
# radius_mean, area_mean, texture_mean 요약 통계를 확인했습니다.
# sklearn 데이터셋의 컬럼명은 mean radius, mean area, mean texture입니다.
selected_columns = ["mean radius", "mean area", "mean texture"]
# 선택한 주요 특징들의 통계 정보를 출력합니다.
print("주요 특징 요약 통계:")
display(X_df[selected_columns].describe())mean radius mean area mean texture
count 569.000000 569.000000 569.000000
mean 14.127292 654.889104 19.289649
std 3.524049 351.914129 4.301036
min 6.981000 143.500000 9.710000
25% 11.700000 420.300000 16.170000
50% 13.370000 551.100000 18.840000
75% 15.780000 782.700000 21.800000
max 28.110000 2501.000000 39.280000
앞서 우리는 scale를 사용해왓는데 거리기반에서는 min-max를 사용한다. 데이터를 0~1 사이의 값으로 변환하는 것.
공식은 (값 - 최소값) / (최대값 - 최소값)이다 .값은 나중에 되돌리면된다 .모든 값에 적용해야한다. 모든값의 편차가 큼으로.
각 컬럼별 최소값과 최댓값을 계산한다.
최대값과 최솟값이 같은 경우 0으로 나누기 되어 에러가 터질 수 있으니 작은 값을 더한다.
이제 모든 컬럼을 변환하고 return하자.
샘플데이터로 테스트해보자 .값 단위가 달라도 상대적인 위치가 같으면 정규화 결과는 같아야한다.
만든 함수를 이용해 실행해봤다.
0~ 1값으롭 ㅕㄴ환됬다 .
# ============================================================
# 3. Min-Max 정규화 함수 정의
# ============================================================
# Min-Max 정규화는 데이터를 0~1 범위로 변환합니다.
# 공식: (값 - 최소값) / (최대값 - 최소값)
def min_max_normalize(df):
# 각 컬럼별 최소값을 계산합니다.
min_value = df.min()
# 각 컬럼별 최대값을 계산합니다.
max_value = df.max()
# 최대값과 최소값이 같은 경우 0으로 나누는 문제가 생길 수 있으므로 작은 값을 더합니다.
eps = 1e-8
# 모든 컬럼을 0~1 범위로 변환합니다.
normalized_df = (df - min_value) / (max_value - min_value + eps)
# 정규화된 DataFrame을 반환합니다.
return normalized_df
# 샘플 데이터 정규화 테스트입니다.
# 값의 단위가 달라도 상대적 위치가 같으면 정규화 결과가 같아집니다.
sample_1 = pd.Series([11, 12, 13, 14, 15])
sample_2 = pd.Series([100, 200, 300, 400, 500])
print("sample_1 정규화 결과:")
print(min_max_normalize(sample_1))
print("sample_2 정규화 결과:")
print(min_max_normalize(sample_2))sample_1 정규화 결과:
0 0.00
1 0.25
2 0.50
3 0.75
4 1.00
dtype: float64
sample_2 정규화 결과:
0 0.00
1 0.25
2 0.50
3 0.75
4 1.00
dtype: float64
zscore 표준화 평균이 0, 표준편차가 1이 되도록 한다 .
컬럼별 평균과 표준편차를 계산해서
0인경우 나누는 문제가 생길테니 작은 값을 더한다. 0.00001을 더한다는 의미 일단 0이 안되게한단 소리다
공식을 활용해서 z-score로 변환해 return했다.
# ============================================================
# 4. Z-score 표준화 함수 정의
# ============================================================
# Z-score 표준화는 평균 0, 표준편차 1이 되도록 변환합니다.
# 공식: (값 - 평균) / 표준편차
def z_score_standardize(df):
# 각 컬럼별 평균을 계산합니다.
mean_value = df.mean()
# 각 컬럼별 표준편차를 계산합니다.
std_value = df.std()
# 표준편차가 0인 경우 0으로 나누는 문제가 생길 수 있으므로 작은 값을 더합니다.
eps = 1e-8
# 모든 컬럼을 Z-score 형태로 변환합니다.
standardized_df = (df - mean_value) / (std_value + eps)
# 표준화된 DataFrame을 반환합니다.
return standardized_df
KNN은 거리기반 알고리즘이니 min-max 정규화를 적용한다. 앞서 작성한것 적용.
mean area 컬럼의 통계를 확인하며 정규화가 잘됫는지 확인해보자.
데이터를 평균 기준으로 얼마나 떨어져있는지 단위로 바꿔주는 정규화 방법, 즉 평균에서 얼마나 멀리 있는지 표준화해서 보여주는 z-score 또한 준비해 통계를 확인하자
출력값을 확인해보면 0과 1 사이의 값으로 잘 보완이 되었다 .z-score로도 확인해보니 잘나왔다 .
# ============================================================
# 5. 데이터 정규화 적용
# ============================================================
# KNN은 거리 기반 알고리즘이므로 먼저 Min-Max 정규화를 적용합니다.
X_minmax_df = min_max_normalize(X_df)
# 정규화가 잘 되었는지 mean area 컬럼의 통계를 확인합니다.
print("Min-Max 정규화 후 mean area 요약:")
display(X_minmax_df["mean area"].describe())
# Z-score 표준화 데이터도 비교 실험을 위해 준비합니다.
X_zscore_df = z_score_standardize(X_df)
# 표준화가 잘 되었는지 mean area 컬럼의 통계를 확인합니다.
print("Z-score 표준화 후 mean area 요약:")
display(X_zscore_df["mean area"].describe())mean area
count 569.000000
mean 0.216920
std 0.149274
min 0.000000
25% 0.117413
50% 0.172895
75% 0.271135
max 1.000000
dtype: float64mean area
count 5.690000e+02
mean -8.553985e-16
std 1.000000e+00
min -1.453164e+00
25% -6.666089e-01
50% -2.949274e-01
75% 3.631877e-01
max 5.245913e+00
dtype: float64
앞선 예제와 똑같이 슬라이싱 방식으로 훈련, 테스트 데이터를 분리한다 .
값들도 min-max, z-score 기준으로도 분리한다 .
# ============================================================
# 6. 훈련 데이터와 테스트 데이터 분리 함수
# ============================================================
# 앞쪽 468개는 훈련용, 나머지 101개는 테스트용으로 분리합니다.
def split_like_r_code(X_df_scaled, y_encoded):
# 앞쪽 468개 행을 훈련 데이터로 사용합니다.
X_train = X_df_scaled.iloc[:468].values
# 469번째부터 마지막까지를 테스트 데이터로 사용합니다.
X_test = X_df_scaled.iloc[468:569].values
# 앞쪽 468개 라벨을 훈련 라벨로 사용합니다.
y_train = y_encoded[:468]
# 469번째부터 마지막까지의 라벨을 테스트 라벨로 사용합니다.
y_test = y_encoded[468:569]
# 분리된 데이터를 반환합니다.
return X_train, X_test, y_train, y_test
# Min-Max 정규화 데이터 기준으로 분리합니다.
X_train_minmax, X_test_minmax, y_train, y_test = split_like_r_code(X_minmax_df, y_encoded)
# Z-score 표준화 데이터 기준으로도 분리합니다.
X_train_zscore, X_test_zscore, _, _ = split_like_r_code(X_zscore_df, y_encoded)
# 데이터 크기를 확인합니다.
print("X_train_minmax:", X_train_minmax.shape)
print("X_test_minmax:", X_test_minmax.shape)
print("y_train:", y_train.shape)
print("y_test:", y_test.shape)
X_train_minmax: (468, 30)
X_test_minmax: (101, 30)
y_train: (468,)
y_test: (101,)
torch를 사용할 것이기 때문에 numpy를 float으로 변환한다. z-score도, label도,
KNN은 loss를 안하지만 비교와 투표처리를 위해 정수라벨이 필요하다. KNN은 새로운 데이터가 들어오면 가까운 k개를 찾아 label을 보고 다수결로 결정하는 투표 모델이고 문자열이면 비교가 느려 voting 계산이 어려워 정수로 변환했다 .
# ============================================================
# 7. NumPy 배열을 PyTorch Tensor로 변환
# ============================================================
# KNN 거리 계산에는 실수형 입력 텐서를 사용합니다.
# dtype=torch.float32는 PyTorch에서 가장 일반적으로 사용하는 실수 자료형입니다.
X_train_minmax_tensor = torch.tensor(X_train_minmax, dtype=torch.float32).to(device)
X_test_minmax_tensor = torch.tensor(X_test_minmax, dtype=torch.float32).to(device)
# Z-score 버전도 Tensor로 변환합니다.
X_train_zscore_tensor = torch.tensor(X_train_zscore, dtype=torch.float32).to(device)
X_test_zscore_tensor = torch.tensor(X_test_zscore, dtype=torch.float32).to(device)
# 라벨은 정수형 Tensor로 변환합니다.
# KNN에서는 직접 손실함수 학습을 하지 않지만, 비교와 투표 처리를 위해 정수 라벨이 필요합니다.
y_train_tensor = torch.tensor(y_train, dtype=torch.long).to(device)
y_test_tensor = torch.tensor(y_test, dtype=torch.long).to(device)
# Tensor 크기를 확인합니다.
print("X_train_minmax_tensor:", X_train_minmax_tensor.shape)
print("X_test_minmax_tensor:", X_test_minmax_tensor.shape)
print("y_train_tensor:", y_train_tensor.shape)
print("y_test_tensor:", y_test_tensor.shape)X_train_minmax_tensor: torch.Size([468, 30])
X_test_minmax_tensor: torch.Size([101, 30])
y_train_tensor: torch.Size([468])
y_test_tensor: torch.Size([101])
KNN은 가중치를 반복적으로 학습하지 않는다. 그저 데이터를 저장하고 테스트 데이터와 훈련데이터 사이의 거리를 계산하는 게으른 학습일뿐이다 .
이 KNN, 분류기 함수를 정의해보자.
nn.module모델과 달리 상속도 받지않았다는걸 서을 볼 수 있다 신경망을 안쓴다는 의미. 학습할 가중치가없다 .fit메서드는 데이터를 저장하는 역할만 수행한다. k, 예측시 참고할 이웃갯수, 훈련데이터 , 훈련라벨변수를 초기화한다 .
fit에는 입력값하고 정답만 들어가 selft를 반환했다. fit은 실제 학습을 하지않고 거리계산에 사용할 훈련데이터와 라벨을 그대로 저장하는 역할만 한다.
predict로 넘어가자. fit이 호출되었는지 먼저 확인하고 . torch.cdist로 두 집합 사이의 유클리드 거리를 계산하는 함수를 활용해 값을 얻어낸다. torch.cdist 로 테스트 데이터와 모든 훈련 데이터간 거리를 계산해 가장 가까운 k개이웃을 선택한다.
선택한 이웃들의 라벨을 torch.bincount()로 ㅌ표해 가장 많이 나온 클래스를 최종 예측값으로결정한다.
# ============================================================
# 8. PyTorch 기반 KNN 분류기 클래스 정의
# ============================================================
class TorchKNNClassifier:
# TorchKNNClassifier는 PyTorch Tensor 연산으로 직접 구현한 KNN 분류기입니다.
# 일반적인 nn.Module 모델과 달리 KNN은 학습할 가중치가 없습니다.
# 따라서 fit() 메서드는 훈련 데이터를 저장하는 역할만 수행합니다.
def __init__(self, k=23):
# k는 예측할 때 참고할 가까운 이웃의 개수입니다.
# 원본 R 코드에서는 469개의 제곱근에 가까운 홀수인 23을 사용했습니다.
self.k = k
# 훈련 데이터와 훈련 라벨을 저장할 변수를 초기화합니다.
self.X_train = None
self.y_train = None
def fit(self, X_train, y_train):
# fit()은 KNN에서 실제 가중치 학습을 수행하지 않습니다.
# 대신 예측 시 거리 계산에 사용할 훈련 데이터를 저장합니다.
self.X_train = X_train
# 각 훈련 데이터의 정답 라벨도 함께 저장합니다.
self.y_train = y_train
# 메서드 체이닝이 가능하도록 자기 자신을 반환합니다.
return self
def predict(self, X_test):
# predict()는 테스트 데이터에 대한 클래스를 예측합니다.
# 먼저 fit()이 호출되었는지 확인합니다.
if self.X_train is None or self.y_train is None:
raise ValueError("먼저 fit(X_train, y_train)을 호출해야 합니다.")
# torch.cdist()는 두 Tensor 집합 사이의 유클리드 거리를 한 번에 계산합니다.
# 결과 shape: [테스트 데이터 개수, 훈련 데이터 개수]
distances = torch.cdist(X_test, self.X_train, p=2)
# 각 테스트 데이터마다 거리가 가장 가까운 k개의 훈련 데이터 인덱스를 찾습니다.
# largest=False는 가장 작은 거리부터 선택한다는 의미입니다.
nearest_indices = torch.topk(distances, k=self.k, dim=1, largest=False).indices
# 가까운 이웃들의 라벨을 가져옵니다.
# shape: [테스트 데이터 개수, k]
nearest_labels = self.y_train[nearest_indices]
# 각 테스트 데이터마다 k개 이웃의 라벨 중 가장 많이 등장한 클래스를 선택합니다.
predictions = []
# 테스트 데이터별로 반복합니다.
for labels in nearest_labels:
# torch.bincount()는 클래스 라벨별 등장 횟수를 계산합니다.
# minlength=2는 Benignant/Malevolent 두 클래스를 모두 고려하기 위한 설정입니다.
vote_counts = torch.bincount(labels, minlength=2)
# 가장 많이 등장한 라벨을 예측 결과로 선택합니다.
# 동점이면 더 작은 클래스 번호가 선택됩니다.
pred = torch.argmax(vote_counts)
# 예측 결과를 리스트에 추가합니다.
predictions.append(pred)
# 예측 결과 리스트를 하나의 Tensor로 변환합니다.
predictions = torch.stack(predictions)
# 최종 예측 Tensor를 반환합니다.
return predictions
def score(self, X_test, y_test):
# score()는 테스트 데이터에 대한 정확도를 계산합니다.
# 먼저 예측값을 계산합니다.
y_pred = self.predict(X_test)
# 예측값과 실제값이 같은지 비교합니다.
correct = (y_pred == y_test).float()
# 전체 중 맞은 비율을 계산합니다.
accuracy = correct.mean().item()
# 정확도를 반환합니다.
return accuracy
객체를 생성해 k값은 23값을 주고
훈련데이터를 모델에 저장해 예측을 수행하며 정확도를 계산했다.
정확도는 98. 성능이 아주 좋다.
# ============================================================
# 9. Min-Max 정규화 데이터로 KNN 모델 생성 및 예측
# ============================================================
# k=23인 KNN 분류기 객체를 생성합니다.
knn_model = TorchKNNClassifier(k=23)
# 훈련 데이터를 모델에 저장합니다.
knn_model.fit(X_train_minmax_tensor, y_train_tensor)
# 테스트 데이터에 대해 예측을 수행합니다.
y_pred_tensor = knn_model.predict(X_test_minmax_tensor)
# 정확도를 계산합니다.
accuracy = knn_model.score(X_test_minmax_tensor, y_test_tensor)
# Tensor를 CPU의 NumPy 배열로 변환합니다.
y_pred = y_pred_tensor.cpu().numpy()
y_true = y_test_tensor.cpu().numpy()
# 정확도를 출력합니다.
print(f"Min-Max 정규화 + K=23 정확도: {accuracy:.4f}")Min-Max 정규화 + K=23 정확도: 0.9802
리포트 출력해보자.
# ============================================================
# 10. 혼동행렬과 분류 리포트 출력
# ============================================================
# 숫자 라벨을 문자열 라벨로 변환하기 위한 클래스 이름입니다.
class_names = ["Benignant", "Malevolent"]
# 혼동행렬을 계산합니다.
# 행은 실제 클래스, 열은 예측 클래스입니다.
cm = confusion_matrix(y_true, y_pred)
# 혼동행렬을 DataFrame으로 보기 좋게 변환합니다.
cm_df = pd.DataFrame(
cm,
index=["Actual_" + name for name in class_names],
columns=["Pred_" + name for name in class_names]
)
# 혼동행렬을 출력합니다.
print("혼동행렬:")
display(cm_df)
# precision, recall, f1-score 등을 포함한 분류 리포트를 출력합니다.
print("분류 리포트:")
print(classification_report(y_true, y_pred, target_names=class_names))Pred_Benignant Pred_Malevolent
Actual_Benignant 77 0
Actual_Malevolent 2 22
분류 리포트:
precision recall f1-score support
Benignant 0.97 1.00 0.99 77
Malevolent 1.00 0.92 0.96 24
accuracy 0.98 101
macro avg 0.99 0.96 0.97 101
weighted avg 0.98 0.98 0.98 101
minmax정규화랑 zscore 표준화도비교해보자
# ============================================================
# 11. Z-score 표준화 데이터로 KNN 모델 평가
# ============================================================
# Z-score 표준화 데이터용 KNN 모델을 생성합니다.
knn_zscore_model = TorchKNNClassifier(k=23)
# 표준화된 훈련 데이터를 저장합니다.
knn_zscore_model.fit(X_train_zscore_tensor, y_train_tensor)
# 표준화된 테스트 데이터에 대해 예측합니다.
y_pred_zscore_tensor = knn_zscore_model.predict(X_test_zscore_tensor)
# 정확도를 계산합니다.
zscore_accuracy = knn_zscore_model.score(X_test_zscore_tensor, y_test_tensor)
# 결과를 출력합니다.
print(f"Z-score 표준화 + K=23 정확도: {zscore_accuracy:.4f}")
# 예측 결과를 NumPy 배열로 변환합니다.
y_pred_zscore = y_pred_zscore_tensor.cpu().numpy()
# 혼동행렬을 계산합니다.
cm_zscore = confusion_matrix(y_true, y_pred_zscore)
# 혼동행렬을 DataFrame으로 변환합니다.
cm_zscore_df = pd.DataFrame(
cm_zscore,
index=["Actual_" + name for name in class_names],
columns=["Pred_" + name for name in class_names]
)
# 혼동행렬을 출력합니다.
print("Z-score 표준화 혼동행렬:")
display(cm_zscore_df)Z-score 표준화 + K=23 정확도: 0.9802
Z-score 표준화 혼동행렬:
Pred_Benignant Pred_Malevolent
Actual_Benignant 77 0
Actual_Malevolent 2 22
k값 에 따른 정확도를 비교해보자.
# ============================================================
# 12. 다양한 k 값에 따른 성능 비교
# ============================================================
# 실험한 k 값 목록입니다.
k_values = [1, 5, 11, 15, 21, 23, 27]
# 결과를 저장할 리스트입니다.
results = []
# 각 k 값에 대해 반복 실험합니다.
for k in k_values:
# 현재 k 값으로 KNN 모델을 생성합니다.
model = TorchKNNClassifier(k=k)
# Min-Max 정규화된 훈련 데이터를 저장합니다.
model.fit(X_train_minmax_tensor, y_train_tensor)
# 테스트 데이터에 대해 예측합니다.
pred_tensor = model.predict(X_test_minmax_tensor)
# 정확도를 계산합니다.
acc = model.score(X_test_minmax_tensor, y_test_tensor)
# 예측 결과를 NumPy 배열로 변환합니다.
pred = pred_tensor.cpu().numpy()
# 혼동행렬을 계산합니다.
cm_current = confusion_matrix(y_true, pred)
# 결과 리스트에 저장합니다.
results.append({
"k": k,
"accuracy": acc,
"confusion_matrix": cm_current
})
# 현재 k 값의 결과를 출력합니다.
print(f"k={k:2d}, accuracy={acc:.4f}")k= 1, accuracy=0.9307
k= 5, accuracy=0.9703
k=11, accuracy=0.9802
k=15, accuracy=0.9802
k=21, accuracy=0.9802
k=23, accuracy=0.9802
k=27, accuracy=0.9802
위내용을 표로, 시각화도 해보자.
# ============================================================
# 13. k 값별 정확도 결과표 만들기
# ============================================================
# results 리스트에서 k와 accuracy만 추출하여 DataFrame으로 만듭니다.
results_df = pd.DataFrame([
{"k": item["k"], "accuracy": item["accuracy"]}
for item in results
])
# 정확도 기준으로 내림차순 정렬한 결과를 출력합니다.
print("k 값별 정확도:")
display(results_df.sort_values(by="accuracy", ascending=False))k accuracy
2 11 0.980198
4 21 0.980198
3 15 0.980198
5 23 0.980198
6 27 0.980198
1 5 0.970297
0 1 0.930693
# ============================================================
# 14. k 값별 정확도 시각화
# ============================================================
# 그래프 크기를 설정합니다.
plt.figure(figsize=(8, 5))
# k 값에 따른 정확도를 선 그래프로 표시합니다.
plt.plot(results_df["k"], results_df["accuracy"], marker="o")
# x축 이름을 설정합니다.
plt.xlabel("k value")
# y축 이름을 설정합니다.
plt.ylabel("Accuracy")
# 그래프 제목을 설정합니다.
plt.title("KNN Accuracy by k Value")
# x축 눈금을 k 값 목록으로 설정합니다.
plt.xticks(k_values)
# 격자선을 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()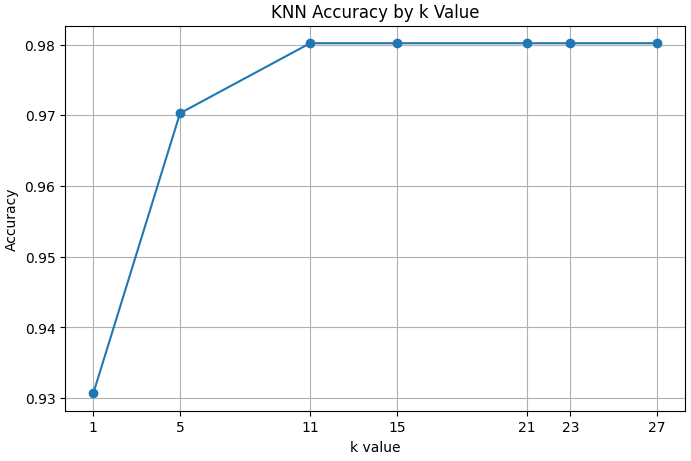
모델은 준비된듯하니 새 데이터로 실행해보자.
x_df의 468이 테스트 데이터 첫번째였으니 그것을 뽑아다가 value값만 처리해 tensor로 바꾸고 모델에 적용해 predict, 예측했다
라벨을 다시 문자로 전환하고
확인한다.
# ============================================================
# 15. 새 데이터 예측 예제
# ============================================================
# 여기서는 테스트 데이터 첫 번째 샘플을 새 데이터처럼 사용합니다.
# 실제 프로젝트에서는 병원 검사 결과로 얻은 30개 수치형 특징이 들어와야 합니다.
new_data_original = X_df.iloc[[468]]
# 새 데이터는 훈련에 사용한 전체 데이터 기준 Min-Max 정규화 방식과 동일하게 변환해야 합니다.
# 여기서는 교육용 간단 구현을 위해 앞에서 만든 X_minmax_df의 같은 행을 사용합니다.
new_data_scaled = X_minmax_df.iloc[[468]].values
# NumPy 배열을 PyTorch Tensor로 변환합니다.
new_data_tensor = torch.tensor(new_data_scaled, dtype=torch.float32).to(device)
# k=23 모델로 새 데이터를 예측합니다.
new_pred_tensor = knn_model.predict(new_data_tensor)
# 예측 숫자 라벨을 가져옵니다.
new_pred_label = int(new_pred_tensor.cpu().numpy()[0])
# 숫자 라벨을 문자열 라벨로 변환합니다.
new_pred_name = class_names[new_pred_label]
# 실제 라벨도 확인합니다.
actual_label = class_names[int(y_encoded[468])]
# 결과를 출력합니다.
print("새 데이터 예측 결과:", new_pred_name)
print("실제 정답:", actual_label)새 데이터 예측 결과: Malevolent
실제 정답: Malevolent
나이브 베이즈
앞서서 간단히 살펴봤었다 .
Naive Bayes
베이즈정리 공식을 사용한다.
속도가 빠르고 텍스트 분류에 강하나 복잡한 패턴을 만나면 제대로 작동이 안되고
모든것이 독립적이라고 생각한다는 가정이 현실적이지 않다는 단점이 있다 .
Native 순진한.
"단어 무료, 당첨, 지금 이라는 단어가 있을때 스팸일 확률을 계산한다."
즉 현실에서는 이 단어들이 서로 영향이 있으나
Naive Bayessms 서로 독립적이라고 가정해 서로 관련이있는데
무시하거나 복잡한 패턴이 약하고 정확도에 한계가 있다는것.
베이지안 기법의 확률
사건 발생한 횟수를 전체 횟수로 나눈 값.
100개 이메일 중에서 10개가 스팸일 경우 받은 메세지가 스팸일 확률을 추정하는 처리방식
0.1이라면 발생가능한 확률데이터, 0.9라면 발생가능성이 없는 확률데이터가 되겠다. 당연한 얘기지만 합산했을때 1이 나와야한다.
샘플 예제를 분석해보자.
import
# ============================================================
# 0. 기본 라이브러리 불러오기
# ============================================================
# 운영체제 경로와 파일 존재 여부를 확인하기 위한 표준 라이브러리입니다.
import os
# 웹에서 데이터 파일을 다운로드하기 위한 라이브러리입니다.
import requests
# zip 압축 파일을 해제하기 위한 표준 라이브러리입니다.
import zipfile
# 문자열 데이터를 다루기 위한 표준 라이브러리입니다.
import io
# 숫자 계산과 배열 처리를 위한 라이브러리입니다.
import numpy as np
# 표 형태의 데이터를 다루기 위한 라이브러리입니다.
import pandas as pd
# 그래프 시각화를 위한 라이브러리입니다.
import matplotlib.pyplot as plt
# PyTorch 핵심 라이브러리입니다.
import torch
# PyTorch 모델 클래스를 만들기 위한 모듈입니다.
import torch.nn as nn
# 텍스트를 문서-단어 행렬로 변환하기 위한 클래스입니다.
from sklearn.feature_extraction.text import CountVectorizer
# 데이터셋을 훈련용과 테스트용으로 분리하기 위한 함수입니다.
from sklearn.model_selection import train_test_split
# 모델 평가를 위한 지표 함수들입니다.
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 실행 장치를 설정합니다.
# GPU가 있으면 cuda를 사용하고, 없으면 cpu를 사용합니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 실습 결과를 재현하기 위해 난수 시드를 고정합니다.
np.random.seed(42)
torch.manual_seed(42)
print("사용 장치:", device)
마찬가지로 UCI에서 데이터를 가져왔다.
zipfile.zipfile()를 사용해 압축해제라고 header는 안보이게하고, label을 직접 부여했다.
# ============================================================
# 1. SMS Spam Collection 데이터셋 다운로드 및 로드
# ============================================================
# UCI SMS Spam Collection 데이터셋 zip 파일 주소입니다.
# Colab에서 직접 다운로드하여 실습할 수 있도록 구성했습니다.
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/00228/smsspamcollection.zip"
# 다운로드한 zip 파일을 저장할 경로입니다.
zip_path = "smsspamcollection.zip"
# 압축 해제 후 생성되는 원본 텍스트 파일명입니다.
data_file = "SMSSpamCollection"
# 데이터 파일이 아직 없을 때만 다운로드를 수행합니다.
if not os.path.exists(data_file):
# 웹 주소로부터 zip 파일을 요청합니다.
response = requests.get(url)
# 요청이 실패하면 에러를 발생시킵니다.
response.raise_for_status()
# 다운로드한 바이너리 내용을 zip 파일로 저장합니다.
with open(zip_path, "wb") as f:
f.write(response.content)
# zip 파일을 현재 작업 폴더에 압축 해제합니다.
with zipfile.ZipFile(zip_path, "r") as z:
z.extractall(".")
# 데이터 파일은 탭으로 label과 text가 구분되어 있습니다.
# header=None은 첫 줄을 컬럼명으로 보지 않겠다는 의미입니다.
sms_df = pd.read_csv(
data_file,
sep=" ",
header=None,
names=["label", "text"],
encoding="latin-1"
)
# 데이터 앞부분을 확인합니다.
print(sms_df.head())
# 전체 데이터 크기를 확인합니다.
print("데이터 크기:", sms_df.shape)
# ham/spam 개수를 확인합니다.
print(sms_df["label"].value_counts())
# ham/spam 비율을 확인합니다.
print(sms_df["label"].value_counts(normalize=True)) label text
0 ham Go until jurong point, crazy.. Available only ...
1 ham Ok lar... Joking wif u oni...
2 spam Free entry in 2 a wkly comp to win FA Cup fina...
3 ham U dun say so early hor... U c already then say...
4 ham Nah I don't think he goes to usf, he lives aro...
데이터 크기: (5572, 2)
label
ham 4825
spam 747
Name: count, dtype: int64
label
ham 0.865937
spam 0.134063
Name: proportion, dtype: float64
ham은 0 spam은 1로 라벨링을 했다.
text 데이터를 뽑아 테스트 데이터에 할당하고
정답데이터도 숫자로 변환된 target 라벨을 부여했다.
# ============================================================
# 2. 문자열 라벨을 숫자 라벨로 변환
# ============================================================
# ham은 정상 문자이므로 0, spam은 스팸 문자이므로 1로 변환합니다.
sms_df["target"] = sms_df["label"].map({"ham": 0, "spam": 1})
# 변환 결과를 확인합니다.
print(sms_df[["label", "target", "text"]].head())
# 입력 데이터 X는 SMS 문장입니다.
X_text = sms_df["text"].values
# 정답 데이터 y는 숫자로 변환된 라벨입니다.
y = sms_df["target"].values label target text
0 ham 0 Go until jurong point, crazy.. Available only ...
1 ham 0 Ok lar... Joking wif u oni...
2 spam 1 Free entry in 2 a wkly comp to win FA Cup fina...
3 ham 0 U dun say so early hor... U c already then say...
4 ham 0 Nah I don't think he goes to usf, he lives aro...
훈련데이터와 테스트데이터를 분리한다 .
stratify=y를 적용하면 ham/spam비율을 비슷하게 유지한다.
# ============================================================
# 3. 훈련 데이터와 테스트 데이터 분리
# ============================================================
# test_size=0.25는 전체 데이터의 25%를 테스트 데이터로 사용한다는 의미입니다.
# stratify=y는 훈련/테스트 데이터의 클래스 비율을 원본과 비슷하게 유지합니다.
X_train_text, X_test_text, y_train, y_test = train_test_split(
X_text,
y,
test_size=0.25,
random_state=42,
stratify=y
)
# 분리된 데이터 크기를 확인합니다.
print("훈련 문장 수:", len(X_train_text))
print("테스트 문장 수:", len(X_test_text))
# 훈련 데이터의 클래스 비율을 확인합니다.
print("훈련 라벨 비율:")
print(pd.Series(y_train).value_counts(normalize=True).sort_index())
# 테스트 데이터의 클래스 비율을 확인합니다.
print("테스트 라벨 비율:")
print(pd.Series(y_test).value_counts(normalize=True).sort_index())훈련 문장 수: 4179
테스트 문장 수: 1393
훈련 라벨 비율:
0 0.865997
1 0.134003
Name: proportion, dtype: float64
테스트 라벨 비율:
0 0.865757
1 0.134243
Name: proportion, dtype: float64
countvectorizer를 통해 소문자로 변환, 영어 불용어 제거, 영문자 2개이상 단어만 사용, 최소 7개 문서이상에 등장한 단어만사용해 단어 출현여부만 0/1로 기록하도록 했다 .
훈련데이터로 단어사전을 학습해 문서 - 단어 행렬을 만들어보고 출력해봤다.
# ============================================================
# 4. 텍스트를 문서-단어 행렬로 변환
# ============================================================
# CountVectorizer는 텍스트 문장을 숫자 행렬로 바꾸는 도구입니다.
# binary=True는 단어 빈도 수가 아니라 단어 출현 여부만 0/1로 저장하겠다는 의미입니다.
# Bernoulli Naive Bayes는 단어가 등장했는지 여부를 사용하므로 binary=True가 적합합니다.
vectorizer = CountVectorizer(
lowercase=True, # 모든 문자를 소문자로 변환합니다.
stop_words="english", # 영어 불용어를 제거합니다.
token_pattern=r"(?u)\b[a-zA-Z][a-zA-Z]+\b", # 영문자 2글자 이상 단어만 사용합니다.
min_df=7, # 최소 7개 문서 이상에 등장한 단어만 사용합니다.
binary=True # 단어 출현 여부만 0/1로 기록합니다.
)
# 훈련 데이터로 단어 사전을 학습하고 문서-단어 행렬을 만듭니다.
X_train_sparse = vectorizer.fit_transform(X_train_text)
# 테스트 데이터는 훈련 데이터에서 만든 단어 사전을 기준으로 변환합니다.
X_test_sparse = vectorizer.transform(X_test_text)
# 생성된 단어 목록을 가져옵니다.
feature_names = vectorizer.get_feature_names_out()
# 문서-단어 행렬의 크기를 확인합니다.
print("훈련 DTM 크기:", X_train_sparse.shape)
print("테스트 DTM 크기:", X_test_sparse.shape)
print("사용 단어 수:", len(feature_names))
print("단어 예시:", feature_names[:30])훈련 DTM 크기: (4179, 883)
테스트 DTM 크기: (1393, 883)
사용 단어 수: 883
단어 예시: ['abiola' 'able' 'abt' 'ac' 'account' 'actually' 'add' 'address' 'aft'
'afternoon' 'age' 'ago' 'ah' 'aha' 'aight' 'alex' 'alright' 'amp' 'angry'
'ans' 'answer' 'anymore' 'anytime' 'apply' 'ard' 'asap' 'ask' 'askd'
'asked' 'asking']
마찬가지로 형을 바꿔주고 tensor로 변환한다.
# ============================================================
# 5. NumPy 배열과 PyTorch Tensor로 변환
# ============================================================
# sparse matrix를 NumPy dense array로 변환합니다.
# 각 값은 단어가 없으면 0, 있으면 1입니다.
X_train_np = X_train_sparse.toarray().astype(np.float32)
X_test_np = X_test_sparse.toarray().astype(np.float32)
# y 라벨을 NumPy 배열로 변환합니다.
y_train_np = y_train.astype(np.int64)
y_test_np = y_test.astype(np.int64)
# NumPy 배열을 PyTorch Tensor로 변환합니다.
# X는 실수형 float32로 변환합니다.
X_train_tensor = torch.tensor(X_train_np, dtype=torch.float32).to(device)
X_test_tensor = torch.tensor(X_test_np, dtype=torch.float32).to(device)
# y는 클래스 번호이므로 정수형 long으로 변환합니다.
y_train_tensor = torch.tensor(y_train_np, dtype=torch.long).to(device)
y_test_tensor = torch.tensor(y_test_np, dtype=torch.long).to(device)
# Tensor 크기를 확인합니다.
print("X_train_tensor:", X_train_tensor.shape)
print("X_test_tensor:", X_test_tensor.shape)
print("y_train_tensor:", y_train_tensor.shape)
print("y_test_tensor:", y_test_tensor.shape)X_train_tensor: torch.Size([4179, 883])
X_test_tensor: torch.Size([1393, 883])
y_train_tensor: torch.Size([4179])
y_test_tensor: torch.Size([1393])
스팸분류에서는 단어빈도보다 단어 존재여부가 중요하다 .
각 단어에 출현여부를 보고 0/1로 분류한다.
Bernoulli Naive Bayes 핵심원리는 '단어조합이면 spam일 확률이 얼마나 되는가'를 계산한다고 보면 된다 .
TorchBernoulliNaiveBayes 함수생성
nn.Module를 상속받아 fit, forward, predict같은 구조를 사용할 수 있게 만들었다 .
init()로 모델 내부에 필요한 변수들을 준비한다 .단어갯수, 분류클래스수(ham과 spam밖에 없으니 2개가 되겠다), lapace 스무딩값.
나이브 베이즈에서는 각 단어의 확률을 전부 곱해서 최종확률을 계산하기 때문에 다른 단어가 아무리 스팸스러워도 전체 결과가 0이 되버리는 결과를 가지게된다. 이를 방지하기 위해 '한번도 안나왓다고 확률이 0이라고 단정하지않기위해' 모든 단어 등장 횟수에 작은 값을 더한다 .
spam 데이터에서 한번도 안나왔다면 0, 그런데 확률을 곱하면 전체가 0이 되어버린다. 그래서 + alpa하는 것.
register_buffer()로 class_log_prior 즉 spam/ham비율, feature_log_prob spam에서 특정단어가 등장할 확률, feature_log_neg_prob_ 반대로 등장하지 않을 확률을 학습 파라미터는 아니지만 모델 내부에 저장해놓는다 . Bernoulli는 없음도 중요하게 보기때문이다.
fir()실제학습시작.
with torch.nograd()이때 딥러닝하지않고 통계계산만한다. 즉 gradient 추적이 필요없기 때문에 해제.
y가 라벨, c가 현재 보고싶은 클래스 번호로 y = [0, 0, 1, 1], c = 1 라면 [False, False, True, True]가된다. 또 x가 X = [
"hello",
"meeting",
"free money",
"win lottery"
]라면 mask 값에 따라 버리고 선택하게 되는데 spam데이터만 남게 할 수 있는것이다. 즉 문서에서 특정 단어가 몇번 나왔는지, 따로 세야하기 때문에 클래스별 spam데이터만 모으기, ham 데이터만 모으는 작업을 하는 것 완료
클래스 문서수를 구한다.
단어 등장 횟수도 구한다.
이 문서들을 tensor화한다.
torch.stack()로 각 클래스 단어 등장 횟수들을 합친다.
클래스에 사전확률을 계산한다. 전체에 비해 각 클래스 단어의 합만큼 등장한것의 %을 구하는 것.
그 다음 조건 확률을 계산한다. Bernoulli NB 공식과 라플라스 스무딩을 추가해서 보다 정확하게. 이때 2*alpha는 spam ham 두개값이 없으니 2로 지정했다.분자만 alpha하면 전체 확률 합에 이상이 생기기 때문에 분모를 같이 보정했다 .
forward()에서는 단어가 존재/비존재인 경우 로그 확률을 모두 합산해 클래스별 점수를 계산한다.
predict는 가장 높은 로그점수를 가진 클래스를 선택하고 preddict_proba()는 softmax로 확률을 반환한다.
# ============================================================
# 6. PyTorch 기반 Bernoulli Naive Bayes 모델 클래스 정의
# ============================================================
class TorchBernoulliNaiveBayes(nn.Module):
"""
PyTorch Tensor 연산으로 구현한 Bernoulli Naive Bayes 분류기입니다.
Bernoulli Naive Bayes는 각 단어의 출현 여부를 0/1로 보고 분류합니다.
예를 들어 특정 SMS에 'free'라는 단어가 있으면 1, 없으면 0으로 표현합니다.
"""
def __init__(self, num_features, num_classes=2, laplace=0.0):
"""
모델 초기화 메서드입니다.
Parameters
----------
num_features : int
단어 사전의 크기입니다. 즉, DTM의 컬럼 수입니다.
num_classes : int
분류할 클래스 개수입니다. 여기서는 ham/spam 2개입니다.
laplace : float
라플라스 스무딩 값입니다. 0이면 스무딩을 사용하지 않습니다.
"""
# nn.Module의 초기화 기능을 실행합니다.
super().__init__()
# 입력 특성 수를 저장합니다.
self.num_features = num_features
# 클래스 개수를 저장합니다.
self.num_classes = num_classes
# 라플라스 스무딩 값을 저장합니다.
self.laplace = laplace
# 클래스 사전확률 log P(class)를 저장할 버퍼입니다.
# register_buffer는 학습 파라미터는 아니지만 모델과 함께 device 이동/저장이 되도록 합니다.
self.register_buffer("class_log_prior_", torch.zeros(num_classes))
# 단어 등장 조건부확률 log P(word=1 | class)를 저장합니다.
self.register_buffer("feature_log_prob_", torch.zeros(num_classes, num_features))
# 단어 미등장 조건부확률 log P(word=0 | class)를 저장합니다.
self.register_buffer("feature_log_neg_prob_", torch.zeros(num_classes, num_features))
def fit(self, X, y):
"""
나이브 베이즈 확률을 계산하는 학습 메서드입니다.
X : shape = [문서 수, 단어 수]
단어 출현 여부가 0 또는 1로 들어있는 Tensor입니다.
y : shape = [문서 수]
각 문서의 정답 클래스 번호입니다.
"""
# 기울기 계산이 필요 없는 확률 계산 과정입니다.
with torch.no_grad():
# 각 클래스별 문서 개수를 담을 리스트입니다.
class_count_list = []
# 각 클래스별 단어 출현 개수를 담을 리스트입니다.
feature_count_list = []
# 클래스 0부터 num_classes-1까지 반복합니다.
for c in range(self.num_classes):
# 현재 클래스 c에 해당하는 문서만 True가 되는 마스크를 만듭니다.
class_mask = (y == c)
# 현재 클래스에 속한 문서만 선택합니다.
X_c = X[class_mask]
# 현재 클래스의 문서 개수를 계산합니다.
class_count = X_c.shape[0]
# 현재 클래스에서 각 단어가 등장한 문서 수를 계산합니다.
# Bernoulli 방식이므로 단어 빈도 합이 아니라 0/1 출현 횟수 합입니다.
feature_count = X_c.sum(dim=0)
# 결과를 리스트에 저장합니다.
class_count_list.append(class_count)
feature_count_list.append(feature_count)
# 클래스별 문서 개수를 Tensor로 변환합니다.
class_count_tensor = torch.tensor(
class_count_list,
dtype=torch.float32,
device=X.device
)
# 클래스별 단어 출현 개수를 Tensor로 쌓습니다.
feature_count_tensor = torch.stack(feature_count_list, dim=0)
# 전체 문서 수를 계산합니다.
total_count = class_count_tensor.sum()
# 클래스 사전확률 P(class)를 로그로 계산합니다.
# 로그를 사용하는 이유는 많은 확률을 곱할 때 값이 0에 가까워지는 언더플로를 막기 위해서입니다.
self.class_log_prior_ = torch.log(class_count_tensor / total_count)
# 라플라스 스무딩 값을 Tensor 계산에 사용할 수 있도록 변수로 둡니다.
alpha = self.laplace
# Bernoulli Naive Bayes의 조건부확률을 계산합니다.
# P(word=1 | class) = (해당 클래스에서 단어가 등장한 문서 수 + alpha) / (해당 클래스 문서 수 + 2*alpha)
# 2*alpha를 더하는 이유는 Bernoulli 값이 0 또는 1 두 가지 경우를 갖기 때문입니다.
prob = (feature_count_tensor + alpha) / (class_count_tensor.view(-1, 1) + 2 * alpha)
# laplace=0일 때 어떤 단어 확률이 정확히 0 또는 1이 되면 log(0) 문제가 발생할 수 있습니다.
# 아주 작은 값 eps로 확률 범위를 제한하여 계산 오류를 방지합니다.
eps = 1e-12
prob = torch.clamp(prob, eps, 1.0 - eps)
# 단어가 등장할 로그확률 log P(word=1 | class)를 저장합니다.
self.feature_log_prob_ = torch.log(prob)
# 단어가 등장하지 않을 로그확률 log P(word=0 | class)를 저장합니다.
self.feature_log_neg_prob_ = torch.log(1.0 - prob)
# fit 후 자기 자신을 반환하면 sklearn과 비슷한 사용 방식이 가능합니다.
return self
def forward(self, X):
"""
각 클래스에 대한 로그확률 점수를 계산합니다.
반환값 shape = [문서 수, 클래스 수]
"""
# 단어가 존재하는 경우의 로그확률 합입니다.
# X가 1이면 log P(word=1 | class)가 반영됩니다.
positive_log_prob = X @ self.feature_log_prob_.T
# 단어가 존재하지 않는 경우의 로그확률 합입니다.
# 1-X가 1이면 log P(word=0 | class)가 반영됩니다.
negative_log_prob = (1.0 - X) @ self.feature_log_neg_prob_.T
# 클래스 사전확률과 조건부확률을 더하여 최종 로그 점수를 계산합니다.
log_scores = self.class_log_prior_ + positive_log_prob + negative_log_prob
# 각 문서에 대한 클래스별 로그 점수를 반환합니다.
return log_scores
def predict(self, X):
"""
가장 로그확률이 큰 클래스를 예측합니다.
"""
# forward()를 호출하여 클래스별 로그 점수를 계산합니다.
log_scores = self.forward(X)
# dim=1 방향에서 가장 큰 값을 가진 클래스 번호를 선택합니다.
predicted_class = torch.argmax(log_scores, dim=1)
# 예측 클래스 번호를 반환합니다.
return predicted_class
def predict_proba(self, X):
"""
클래스별 예측 확률을 반환합니다.
"""
# 클래스별 로그 점수를 계산합니다.
log_scores = self.forward(X)
# 로그 점수를 softmax에 넣어 확률 형태로 변환합니다.
probabilities = torch.softmax(log_scores, dim=1)
# 클래스별 확률을 반환합니다.
return probabilities
라플라스 스무딩 없이학습해보자.
feature개수를 기준으로 모델 구조를 걸정하고 클래스 수를 2로 지정했다.
laplace를 0.0으로 지정해서 스무딩없이 순수한 빈도기반 확률을 사용하도록했다 .
fit()을 호출하면 클래스별 문서수와 단어 출현정보를 이용해 사전확률과 조건부 확률이 계산되 모델내부에 저장되고
학습이 끝난후 출력하면 사전확률을 확인할 수 있다 .
마지막으로 exp()를 해 로그 확률을 일반 확률로 변환해 해석가능하게 해보자.
# ============================================================
# 7. 라플라스 스무딩 없는 Naive Bayes 모델 학습
# ============================================================
# 입력 특성 수는 문서-단어 행렬의 컬럼 수입니다.
num_features = X_train_tensor.shape[1]
# ham/spam 2개 클래스 분류이므로 num_classes=2입니다.
num_classes = 2
# laplace=0.0은 라플라스 스무딩을 사용하지 않는 설정입니다.
nb_model = TorchBernoulliNaiveBayes(
num_features=num_features,
num_classes=num_classes,
laplace=0.0
).to(device)
# fit() 메서드로 클래스별 사전확률과 단어별 조건부확률을 계산합니다.
nb_model.fit(X_train_tensor, y_train_tensor)
# 모델 내부에 저장된 클래스 사전확률을 확인합니다.
print("클래스 로그 사전확률 log P(class):")
print(nb_model.class_log_prior_)
# 확률로 변환해서 해석하기 쉽게 출력합니다.
print("클래스 사전확률 P(class):")
print(torch.exp(nb_model.class_log_prior_))클래스 로그 사전확률 log P(class):
tensor([-0.1439, -2.0099])
클래스 사전확률 P(class):
tensor([0.8660, 0.1340])
테스트 데이터 예측 평가.
# ============================================================
# 8. 테스트 데이터 예측 및 평가
# ============================================================
# 평가 단계에서는 기울기 계산이 필요 없으므로 torch.no_grad()를 사용합니다.
with torch.no_grad():
# 테스트 데이터의 예측 클래스 번호를 계산합니다.
y_pred_tensor = nb_model.predict(X_test_tensor)
# 클래스별 예측 확률도 계산합니다.
y_proba_tensor = nb_model.predict_proba(X_test_tensor)
# Tensor를 CPU의 NumPy 배열로 변환합니다.
y_pred = y_pred_tensor.cpu().numpy()
y_proba = y_proba_tensor.cpu().numpy()
# 정확도를 계산합니다.
accuracy = accuracy_score(y_test_np, y_pred)
# 혼동행렬을 계산합니다.
cm = confusion_matrix(y_test_np, y_pred)
# 평가 결과를 출력합니다.
print("정확도 Accuracy:", accuracy)
print("혼동행렬 Confusion Matrix:")
print(cm)
# 클래스 이름을 지정합니다.
target_names = ["ham", "spam"]
# 정밀도, 재현율, F1-score를 출력합니다.
print("분류 리포트 Classification Report:")
print(classification_report(y_test_np, y_pred, target_names=target_names))정확도 Accuracy: 0.9806173725771715
혼동행렬 Confusion Matrix:
[[1202 4]
[ 23 164]]
분류 리포트 Classification Report:
precision recall f1-score support
ham 0.98 1.00 0.99 1206
spam 0.98 0.88 0.92 187
accuracy 0.98 1393
macro avg 0.98 0.94 0.96 1393
weighted avg 0.98 0.98 0.98 1393
혼동행렬 시각화
# ============================================================
# 9. 혼동행렬 시각화
# ============================================================
# 그래프 크기를 설정합니다.
plt.figure(figsize=(5, 4))
# 혼동행렬을 이미지 형태로 표시합니다.
plt.imshow(cm)
# 그래프 제목을 설정합니다.
plt.title("Confusion Matrix - Naive Bayes")
# x축과 y축 눈금 이름을 설정합니다.
plt.xticks([0, 1], target_names)
plt.yticks([0, 1], target_names)
# x축과 y축 라벨을 설정합니다.
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
# 각 칸에 숫자를 표시합니다.
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
plt.text(j, i, cm[i, j], ha="center", va="center")
# 색상 막대를 표시합니다.
plt.colorbar()
# 그래프를 출력합니다.
plt.show()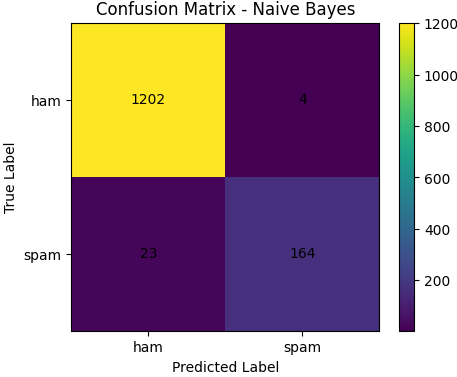
학습 및 평가 .
# ============================================================
# 10. 라플라스 스무딩 적용 모델 학습 및 평가
# ============================================================
# laplace=0.1은 개선 실험입니다.
nb_model_laplace = TorchBernoulliNaiveBayes(
num_features=num_features,
num_classes=num_classes,
laplace=0.1
).to(device)
# 라플라스 스무딩을 적용하여 모델을 학습합니다.
nb_model_laplace.fit(X_train_tensor, y_train_tensor)
# 테스트 데이터 예측을 수행합니다.
with torch.no_grad():
y_pred_laplace_tensor = nb_model_laplace.predict(X_test_tensor)
y_proba_laplace_tensor = nb_model_laplace.predict_proba(X_test_tensor)
# Tensor를 NumPy 배열로 변환합니다.
y_pred_laplace = y_pred_laplace_tensor.cpu().numpy()
y_proba_laplace = y_proba_laplace_tensor.cpu().numpy()
# 정확도와 혼동행렬을 계산합니다.
accuracy_laplace = accuracy_score(y_test_np, y_pred_laplace)
cm_laplace = confusion_matrix(y_test_np, y_pred_laplace)
# 결과를 출력합니다.
print("라플라스 스무딩 적용 정확도 Accuracy:", accuracy_laplace)
print("라플라스 스무딩 적용 혼동행렬:")
print(cm_laplace)
print("라플라스 스무딩 적용 분류 리포트:")
print(classification_report(y_test_np, y_pred_laplace, target_names=target_names))라플라스 스무딩 적용 정확도 Accuracy: 0.9834888729361091
라플라스 스무딩 적용 혼동행렬:
[[1202 4]
[ 19 168]]
라플라스 스무딩 적용 분류 리포트:
precision recall f1-score support
ham 0.98 1.00 0.99 1206
spam 0.98 0.90 0.94 187
accuracy 0.98 1393
macro avg 0.98 0.95 0.96 1393
weighted avg 0.98 0.98 0.98 1393
전후 성능을 비교해보자.
# ============================================================
# 11. 스무딩 전후 성능 비교
# ============================================================
# 스무딩 전 오분류 개수를 계산합니다.
error_count = np.sum(y_test_np != y_pred)
# 스무딩 후 오분류 개수를 계산합니다.
error_count_laplace = np.sum(y_test_np != y_pred_laplace)
# 비교 결과를 DataFrame으로 정리합니다.
comparison_df = pd.DataFrame({
"model": ["Naive Bayes laplace=0.0", "Naive Bayes laplace=0.1"],
"accuracy": [accuracy, accuracy_laplace],
"error_count": [error_count, error_count_laplace]
})
# 비교표를 출력합니다.
print(comparison_df)
# 정확도 막대그래프를 그립니다.
plt.figure(figsize=(7, 4))
plt.bar(comparison_df["model"], comparison_df["accuracy"])
plt.ylim(0.9, 1.0)
plt.ylabel("Accuracy")
plt.title("Naive Bayes Accuracy Comparison")
plt.xticks(rotation=15)
plt.show() model accuracy error_count
0 Naive Bayes laplace=0.0 0.980617 27
1 Naive Bayes laplace=0.1 0.983489 23

새 문자 예측 함수를 만든다.
# ============================================================
# 12. 새 문자 메시지 예측 함수 만들기
# ============================================================
def predict_sms(model, messages):
"""
새로운 SMS 문장을 ham/spam으로 예측하는 함수입니다.
Parameters
----------
model : TorchBernoulliNaiveBayes
학습된 나이브 베이즈 모델입니다.
messages : list[str]
예측할 SMS 문장 리스트입니다.
"""
# 학습 때 사용한 vectorizer로 새 문장을 같은 단어 사전 기준으로 변환합니다.
X_new_sparse = vectorizer.transform(messages)
# sparse matrix를 dense NumPy 배열로 변환합니다.
X_new_np = X_new_sparse.toarray().astype(np.float32)
# NumPy 배열을 PyTorch Tensor로 변환합니다.
X_new_tensor = torch.tensor(X_new_np, dtype=torch.float32).to(device)
# 예측을 수행합니다.
with torch.no_grad():
pred_tensor = model.predict(X_new_tensor)
proba_tensor = model.predict_proba(X_new_tensor)
# Tensor 결과를 NumPy 배열로 변환합니다.
pred = pred_tensor.cpu().numpy()
proba = proba_tensor.cpu().numpy()
# 숫자 라벨을 문자 라벨로 변환하기 위한 딕셔너리입니다.
label_map = {0: "ham", 1: "spam"}
# 결과를 저장할 리스트입니다.
results = []
# 각 메시지별 예측 결과를 정리합니다.
for msg, p, prob in zip(messages, pred, proba):
results.append({
"message": msg,
"predicted_label": label_map[int(p)],
"ham_probability": prob[0],
"spam_probability": prob[1]
})
# 결과를 DataFrame으로 반환합니다.
return pd.DataFrame(results)
# 예측할 새 SMS 문장 예시입니다.
new_messages = [
"Congratulations! You won a free ticket. Call now to claim your prize.",
"Are we still meeting for lunch tomorrow?",
"URGENT! Your mobile number has been selected for a cash reward.",
"Please call me when you arrive home."
]
# 라플라스 스무딩을 적용한 모델로 예측합니다.
result_df = predict_sms(nb_model_laplace, new_messages)
# 예측 결과를 출력합니다.
print(result_df)
message predicted_label \
0 Congratulations! You won a free ticket. Call n... spam
1 Are we still meeting for lunch tomorrow? ham
2 URGENT! Your mobile number has been selected f... spam
3 Please call me when you arrive home. ham
ham_probability spam_probability
0 6.146169e-10 1.000000e+00
1 9.999995e-01 5.039859e-07
2 5.846606e-08 1.000000e+00
3 9.999050e-01 9.500382e-05
클래스별 주요단어를 확인한다.
# ============================================================
# 13. 클래스별 주요 단어 확인
# ============================================================
# 라플라스 모델에서 단어 등장 조건부확률 log P(word=1 | class)를 가져옵니다.
feature_log_prob = nb_model_laplace.feature_log_prob_.detach().cpu().numpy()
# 로그확률을 일반 확률로 변환합니다.
feature_prob = np.exp(feature_log_prob)
# spam 클래스는 1번 클래스입니다.
spam_word_prob = feature_prob[1]
# ham 클래스는 0번 클래스입니다.
ham_word_prob = feature_prob[0]
# spam에서 확률이 높은 단어 인덱스 상위 20개를 찾습니다.
top_spam_idx = np.argsort(spam_word_prob)[-20:][::-1]
# ham에서 확률이 높은 단어 인덱스 상위 20개를 찾습니다.
top_ham_idx = np.argsort(ham_word_prob)[-20:][::-1]
# 결과를 표로 정리합니다.
top_words_df = pd.DataFrame({
"top_spam_words": feature_names[top_spam_idx],
"spam_probability": spam_word_prob[top_spam_idx],
"top_ham_words": feature_names[top_ham_idx],
"ham_probability": ham_word_prob[top_ham_idx]
})
# 주요 단어 표를 출력합니다.
print(top_words_df)
top_spam_words spam_probability top_ham_words ham_probability
0 free 0.221528 just 0.057499
1 txt 0.210818 ll 0.055012
2 ur 0.153695 ok 0.053631
3 claim 0.144770 gt 0.051144
4 text 0.139414 lt 0.050591
5 mobile 0.137629 got 0.049486
6 www 0.135844 know 0.046447
7 stop 0.134059 come 0.045618
8 reply 0.132274 good 0.045342
9 won 0.101928 day 0.041750
10 prize 0.101928 ur 0.041197
11 send 0.096573 like 0.040092
12 just 0.096573 want 0.036223
13 cash 0.093002 love 0.036223
14 uk 0.093002 time 0.036223
15 new 0.093002 home 0.034842
16 win 0.091217 sorry 0.032355
17 urgent 0.085862 going 0.032079
18 service 0.078722 need 0.031526
19 com 0.078722 lor 0.030974
휴...
'SK 네트웍스 AI 캠프' 카테고리의 다른 글
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day20_머신러닝 결정트리와 회귀트리 (0) | 2026.06.01 |
|---|---|
| [SK네트웍스 Family AI 캠프] 32기 5주차 회고: Day16 ~ Day19 (0) | 2026.05.29 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day18_머신러닝_회귀모델_분류모델 (0) | 2026.05.28 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day17_머신러닝 학습방법과 데이터 관리 (0) | 2026.05.27 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day16_데이터 시각화 (0) | 2026.05.26 |



