jetbrains란?
https://standout.tistory.com/1741
JetBrains란?: IDE, 언어, 플러그인을 만드는 회사
IDE, 언어, 플러그인을 만드는 회사, 개발 생산성을 높인다.IntelliJ IDEA, PyCharm, WebStom, CLion이 대표제품. Kotlin언어개발에도 참여했다. https://www.jetbrains.com/ JetBrains: Essential tools for software developers and te
standout.tistory.com
파이참이란?
https://standout.tistory.com/1740
PyCharm, 파이참이란? : 다운 및 설치
파이참이란?JerBrains가 만든 Python 전용, 특화된 통합개발환경 IDEcommunity버전은 무료이나 웹, 데이터, db, 프레임워크에 제한이 있어 사실상 실무에서 사용하기 어렵다. Python을 학습하며 머신러닝,
standout.tistory.com
코랩이란?
https://standout.tistory.com/1742
Google Colab 코랩이란?: 클라우드 기반 Python 임시 실행환경, 간단사용법, Google docs 연결해 사용하기,
코랩이란?클라우드 기반 Python 임시 실행환경 정식이름은 Google ColabGPU/TPU 무료 사용이 가능해 딥러닝 학습, 이미지처리, 대규모 연산이 가능하다. 로컬pc보다 훨씬 강력할 수 있음..ipynb 파일을 사
standout.tistory.com
PyTorch란?
https://standout.tistory.com/1743
PyTorch란? : PyTorch는 딥러닝 계산을 수행하는 프레임워크, GPU가 필요한 까닭, 코랩 Colab에서 확인하
PyTorch는 딥러닝 계산을 수행하는 프레임워크이다.딥러닝은 행렬연산, 벡터연산, 대규모 병렬 계산을 많이한다.CPU는 소수의 강한 코어로 일반작업에 딥러닝 속도가 느리다면GPU는 수천개의 작은
standout.tistory.com
https://standout.tistory.com/1744
CNN 이란?: CNN Concolutional Neural Network 합성곱 신경망, 이미지의 특징을 자동으로 찾자!
CNN Concolutional Neural Network 합성곱 신경망이미지, 영상, 패턴인식에 사용된다. 기존 신경망은 이미지 처리에 비효율적이었다 .고양이 사진을 숫자로 펼치면 수십만개 픽셀이 되고 일반신경망은 파
standout.tistory.com
인공지능 > 머신러닝 > 딥러닝
데이터기반 인공지능 = 머신러닝
머신러닝 + 딥모델 = 딥러닝
https://standout.tistory.com/1531
인공지능, 기계학습, 딥러닝의 차이
인공지능 ⊃ 기계학습 ⊃ 딥러닝인공지능: 사람의 지능을 인공적으로 재현함.기계학습: 인공지능 연구분야 중 하나로 규칙을 찾아내는 기법딥러닝: 사람이 가르쳐주지않아도 스스로 답을 찾아
standout.tistory.com
인공지능에는 사용자가 데이터를 입력하여 해답을 도출하는 규칙기반 인공지능과
사용자가 데이터를 입력하면 컴퓨터 스스로 규칙을 만들어 해답을 도출하는 데이터 기반 인공지능이 있다.
문제해결방법에는 알고리즘 디자인 이후 프로그래밍을 해 해답을 도출하고 새로운 문제가 주어질 경우 새 알고리즘을 디자인해서 반복하는 컴퓨터 공학의 문제해결방법과
문제가 주어질 경우 데이터를 수집해 모델을 선택해 트레닝을 해 해답도출하고 새로운 문제가 주어질 경우 다시 데이터 수집을해 모델을 재학습시켜 해답을 도출시키는 머신러닝 문제 해결방법이 있다 .
https://standout.tistory.com/1529
자동화에서 자율화로 진화되는 인공지능: 추론방법, 룰베이스 와 기계학습
추론룰을 사용하여 모순되지 않는 답을 도출한다. 룰베이스 (Rule-Based)사람의 체험과 지견에 의해 얻어지는 지식규칙 기반 시스템, "만약-그러면" 규칙을 사용하여 동작 명확성, 예측 가능
standout.tistory.com
인공지능 기계학습 코딩 package
Tensorflow, keras, anaconda, pycharm
* Tensorflow안에 keras가 내장되어있어 분류가 애매하다.
머신러닝
구성요소: 데이터, 모델, 트레이닝 알고리즘
문제, 데이터, 성능지표 세가지가 주어졌을때 데이터 증가에 따라 알고리즘 성능이 향상된다면 컴퓨터가 학습하고 있다는 것이다.
머신러닝의 핵심은 컴퓨터 스스로 규칙을 찾아낸다는것
머신러닝 이해의 핵심개념으로 새로운 데이터에 대한 정답 도출 능력이 '일반화'의 척도이다. 일반화능력이 머신러닝의 핵심요소.
머신러닝 활용사례
재해의 보험 통계적 범위추정
사회범죄 집중 지역관리
선거결과의 예측
고객유형별 타깃 광고개발
신용카드 불법성 거래 감시
드론과 자율주행 자동차의 알고리즘
유전자를 이용한 질병연구
이상기후 변화의 예측
이메일의 스팸구분
에너지 소비 효율 최적화 전략
https://standout.tistory.com/1745
머신러닝이란?: 기원과 정의, 한계와 문제점
기원Machine Learning 데이터으 지능적인 행동에 따른 컴퓨터 알고리즘 개발 및 연구분야 머신러닝이란, 데이터를 이용해 컴퓨터가 스스로 규칙(패턴)을 학습하고, 이를 기반으로 예측이나 판단을
standout.tistory.com
https://standout.tistory.com/1746
데이터마이닝이란? : 데이터 속에서 사람에게 유용한 “패턴, 규칙, 의미”를 찾아내는 과정
데이터마이닝데이터 속에서 사람에게 유용한 “패턴, 규칙, 의미”를 찾아내는 과정컴퓨터를 통해 사람이 사용할 패턴을 검색하고 가르치는데 집중하여 컴퓨터의 데이터 사용법에 집중하는 머
standout.tistory.com
데이터
정형데이터: 표 형태로 정형화됨, 의사결정 나무 계열 프로그램이 적합하다.
비정형데이터: 이미지, 비디오, 텍스트, 음성, 데이터 특징이 불명확하다, 딥러닝 계열 프로그램이 적합하다
학습 알고리즘
문제해결 과정을 모아 놓은것.
https://standout.tistory.com/78
알고리즘이란?
알고리즘 해결가능한 문제를 풀기위한 절차 자료구조(선형, 배열, 리스트, 스택..)를 잘 활용해야 성능(적은시간, 적은메모리)이 좋아진다. https://ko.wikipedia.org/wiki/%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98 알
standout.tistory.com
데이터 피드백 기준 텍사노미
= 데이터가 AI에게 어떤 방식으로 피드백 되는지에 따라 머신러닝을분류한 체계
머신러닝의 분류는 지도학습, 비지도학습, 강화학습이 있으며
데이터피드백 방식으로 분류할 수 있다.
'AI가 정답을 어떻게 받느냐'가 피드백이고
지도학습이란 정답을 알려주면서 학습하는것. 비지도 학습은 정답없이 패턴만 찾고, 강화학습은 행동결과에 대한 보상으로 학습하는데 예로 게임AI가 잘했을때 점수 +, 혹은 점수 - 하는 과정으로 칭찬과 벌을 받으며 배우는것이라고 이해하자.
즉
머신러닝
- 지도학습: 정답있음
- 비지도학습: 정답없음
- 강화학습: 보상기반
기계학습
톰미첼 " 미래 경험을 통한 성능이 향상되면 기계는 자신의 경험을 활용할 수있을때마다 학습한다"
인간과 기계의 기본적인 학습과정은 유사하다. 데이터셋저장소 - 추상화개념 - 보편 일반화 - 결과평가
https://standout.tistory.com/1538
기계학습 알고리즘과 주요 기계학습 알고리즘: 선형 회귀, 의사결정 나무 모형, 딥러닝
기계학습 알고리즘데이터에서 패턴을 발견하고 학습하는 데 사용되는 다양한 기법https://standout.tistory.com/78 알고리즘이란?알고리즘 해결가능한 문제를 풀기위한 절차 자료구조(선형, 배열,
standout.tistory.com
데이터전처리
원시데이터를 분석에 적합한 형태로 변환하는 과정으로 분석/모델링 과정에서 오류를 최소화 하고 정확한 결과를 도출하는것을 목적으로 하며 아래의 작업들이 있다 .
1. 정제: 결측치 제거, 이상치 제거, 중복데이터 제거
2. 통합: 분석을 위한 여러 데이터 통합
3. 변환: 스케일링, 정규화, 범주형 데이터 인코딩
4. 데이터 축소" 차원변수 축소, 샘플링
5. 특징선택 및 생성: 표에 주요 특징 변수생성
결측치 처리
missing value 제거/대체
처리방법: 삭제, 평균 중앙값 최빈값으로 대체, 전진 후진 채우기, 임의값대체, KNN 대체, 회귀대체, 다중대체
전처리 방법 수령자료를 실행 및 분석해보자.
pip install pandas numpy seaborn scikit-learn
전처기 - null값 처리하기
titanic.isnull.sum()으로 결측치를 확인했다.
titanic.dropna()로 결측치가 있는 행을 삭제하기
age 열에 대해 nan인 값만 나이의 평균값을 기준으로 titanic['age'].fillna(titanic['age'].mean()) 채웠다.
fare열은 median() 중앙값으로 대체했다 .
embarked 열은 가장많이 나온값 mode으로, 최빈값으로 대체했다
age를 다시 ffill() 전진값으로 채우고
age를 다시 bfill() 후진값으로 채웠다.

import seaborn as sns
import pandas as pd
# Seaborn에서 제공하는 titanic 데이터셋 로드
titanic = sns.load_dataset('titanic')
# 데이터셋의 결측치 확인
print('Original Data:')
print(titanic.isnull().sum())
# 1. 결측치가 있는 행(row) 삭제
titanic_dropped = titanic.dropna()
print('\nAfter Dropping Rows with Missing Values:')
print(titanic_dropped.isnull().sum())
# 2. 평균값으로 결측치 대체 (age 열에 대해)
titanic['age_mean_filled'] = titanic['age'].fillna(titanic['age'].mean())
print('\nAfter Filling Missing Values with Mean in age Column:')
print(titanic['age_mean_filled'].isnull().sum())
# 3. 중앙값으로 결측치 대체 (fare 열에 대해)
titanic['fare_median_filled'] = titanic['fare'].fillna(titanic['fare'].median())
print('\nAfter Filling Missing Values with Median in fare Column:')
print(titanic['fare_median_filled'].isnull().sum())
# 4. 최빈값으로 결측치 대체 (embarked 열에 대해)
titanic['embarked_mode_filled'] = titanic['embarked'].fillna(titanic['embarked'].mode()[0])
print('\nAfter Filling Missing Values with Mode in embarked Column:')
print(titanic['embarked_mode_filled'].isnull().sum())
# 5. 전진 채우기 (Forward Fill) (age 열에 대해)
titanic['age_ffill'] = titanic['age'].ffill()
print('\nAfter Forward Fill in age Column:')
print(titanic['age_ffill'].isnull().sum())
# 6. 후진 채우기 (Backward Fill) (age 열에 대해)
titanic['age_bfill'] = titanic['age'].bfill()
print('\nAfter Backward Fill in age Column:')
print(titanic['age_bfill'].isnull().sum())
전처리 - 이상값 처리하기
IQR Inter Quartile Range
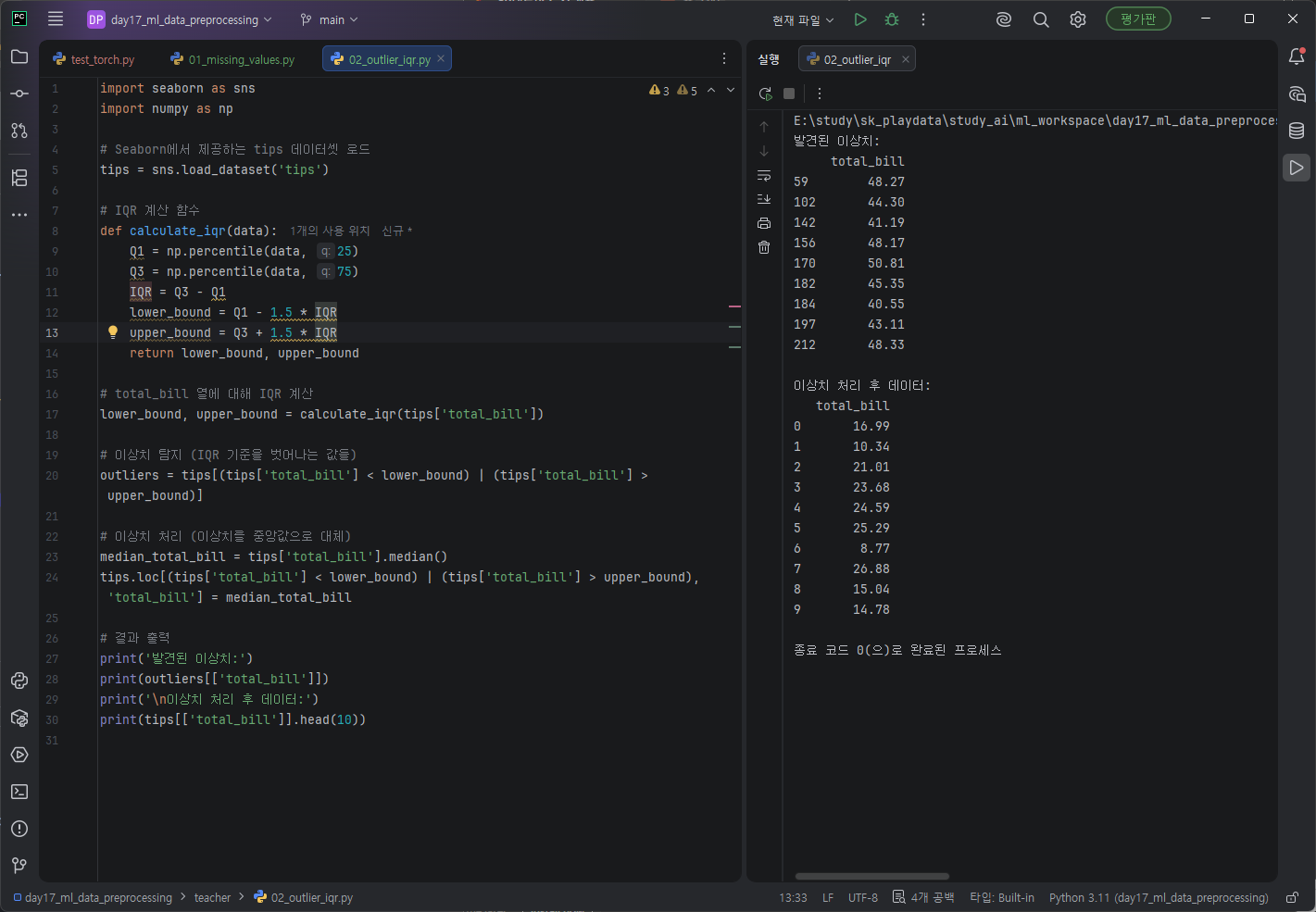
데이터를 크기순 정렬했을때 Q1는 25%, Q2는 중앙값 50%, Q3은 75%지점으로 데이터의 25% 위치값을 계산하여 Q2할당하고, 75% 위치값을 계산하여 Q3에 할당했다 . 이를 활용해 가운데 50%데이터 범위를 계산하고 1.5를 곱해 정상범위를 어느정도 여유있게 잡아놨다. 1.5는 관례적이다 .
이후 하한값과 상한값을 구했다.
total_bill에서 IQR계산함수 calculate_iqr를 실행했고 반환받은 lower_bound, upper_bound를 활용하여 기준을 벗어나는 하한값, 상한값들을 outliers에 담았다.
tips['total_bill'].median() 중앙값을 구해 해당 이상값에 반영했다.
import seaborn as sns
import numpy as np
# Seaborn에서 제공하는 tips 데이터셋 로드
tips = sns.load_dataset('tips')
# IQR 계산 함수
def calculate_iqr(data):
Q1 = np.percentile(data, 25)
Q3 = np.percentile(data, 75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
return lower_bound, upper_bound
# total_bill 열에 대해 IQR 계산
lower_bound, upper_bound = calculate_iqr(tips['total_bill'])
# 이상치 탐지 (IQR 기준을 벗어나는 값들)
outliers = tips[(tips['total_bill'] < lower_bound) | (tips['total_bill'] > upper_bound)]
# 이상치 처리 (이상치를 중앙값으로 대체)
median_total_bill = tips['total_bill'].median()
tips.loc[(tips['total_bill'] < lower_bound) | (tips['total_bill'] > upper_bound), 'total_bill'] = median_total_bill
# 결과 출력
print('발견된 이상치:')
print(outliers[['total_bill']])
print('\n이상치 처리 후 데이터:')
print(tips[['total_bill']].head(10))
전처리 - 이상치 처리하기
calculate_z_scores, z-스코어 계산 함수를 만들어 공식에따라
std() standard deviation 표준편차를 구해 data에서 평균을 빼어 표준편차로 나눠 어느정도에 위치해있는지를 확인한다.
tips['total_bill']을 calculate_z_scores 실행해 z-score를 계산하고
이 스코어가 3이상이거나 -3이하인경우 이상치 처리를 하여 median 중앙값으로 대체했다 .

import seaborn as sns
import numpy as np
# Seaborn에서 제공하는 tips 데이터셋 로드
tips = sns.load_dataset('tips')
# Z-스코어 계산 함수
def calculate_z_scores(data):
return (data - np.mean(data)) / np.std(data)
# total_bill 열에 대해 Z-스코어 계산
tips['total_bill_zscore'] = calculate_z_scores(tips['total_bill'])
# 이상치 탐지 (Z-스코어가 3 이상이거나 -3 이하인 경우)
outliers = tips[np.abs(tips['total_bill_zscore']) > 3]
# 이상치 처리 (이상치를 중앙값으로 대체)
median_total_bill = tips['total_bill'].median()
tips.loc[np.abs(tips['total_bill_zscore']) > 3, 'total_bill'] = median_total_bill
# 처리 후 Z-스코어 다시 계산
tips['total_bill_zscore'] = calculate_z_scores(tips['total_bill'])
# 결과 출력
print('발견된 이상치:')
print(outliers[['total_bill', 'total_bill_zscore']])
print('\n이상치 처리 후 데이터:')
print(tips[['total_bill', 'total_bill_zscore']].head(10))
이상값이란 비정상적으로 보이는 값을 말하고 이상치는 통계적으로 기준에 벗어난 값을 말한다.
나이가 999거나 키가 -120은 누가봐도 이상하다. 이런것들을 이상값이라하고
평균연봉이 3000~5000인데 한명 연봉이 5억이라면 통계기준에서벗어난 데이터라고 이상치라 한다. 실제 존재는 가능하다 분포상 멀리 떨어진것.
이상치는 실제 데이터일수있으나 평균을 왜곡하고 모델 성능 저하 및 학습에 불안정함으로 전처리에 포함 될 수 있다 .
z-score란 데이터가 평균에서 몇 표준편차 떨어져있는지를 말한다.
왜 +- 3을 기준으로 쓰는가?
통계의 정규분포개념에 의한것이다.
종모양 분포 = 대부분 데이터가 평균 근처에 몰려있다라는 개념
z-score = 0는 평균과 같고, 1은 표준편차 1만큼 크다. 만일 3 이상이다라는말은 평균에서 매우 멀다는 의미로 이상치일 가능성이 크다.
전처리 - 정규화 코드 min-max scaling
MinMaxScaler를 사용하면 자동으로 Min-Max 정규화(normalization)가 수행된다
scikit-learn의 전처리 도구 MinMaxScaler 라이브러리를 import했다.
min-max 스케일러를 생성하여fit_transform 데이터의 최소값, 최대값을 fit()학습해 transform() 공식적용해 변환한것.
이때 [['total_bill', 'tip']] 대괄호가 두개라는 것은 여러컬럼을 선택할때 쓴다.
위 스케일링된 결과를 [:, 0] 모든 행의 0번쨰열에 , 1번째 열, 원래 데이터 프레임에 추가했다.
다 해준다니 아주 유용하다~

import seaborn as sns
from sklearn.preprocessing import MinMaxScaler
# Seaborn에서 제공하는 tips 데이터셋 로드
tips = sns.load_dataset('tips')
# Min-Max 스케일러 생성
scaler = MinMaxScaler()
# total_bill과 tip 열에 대해 Min-Max 스케일링 적용
scaled_data = scaler.fit_transform(tips[['total_bill', 'tip']])
# 스케일링된 결과를 원래 데이터프레임에 추가
tips['total_bill_scaled'] = scaled_data[:, 0]
tips['tip_scaled'] = scaled_data[:, 1]
# 결과 출력
print(tips.head())
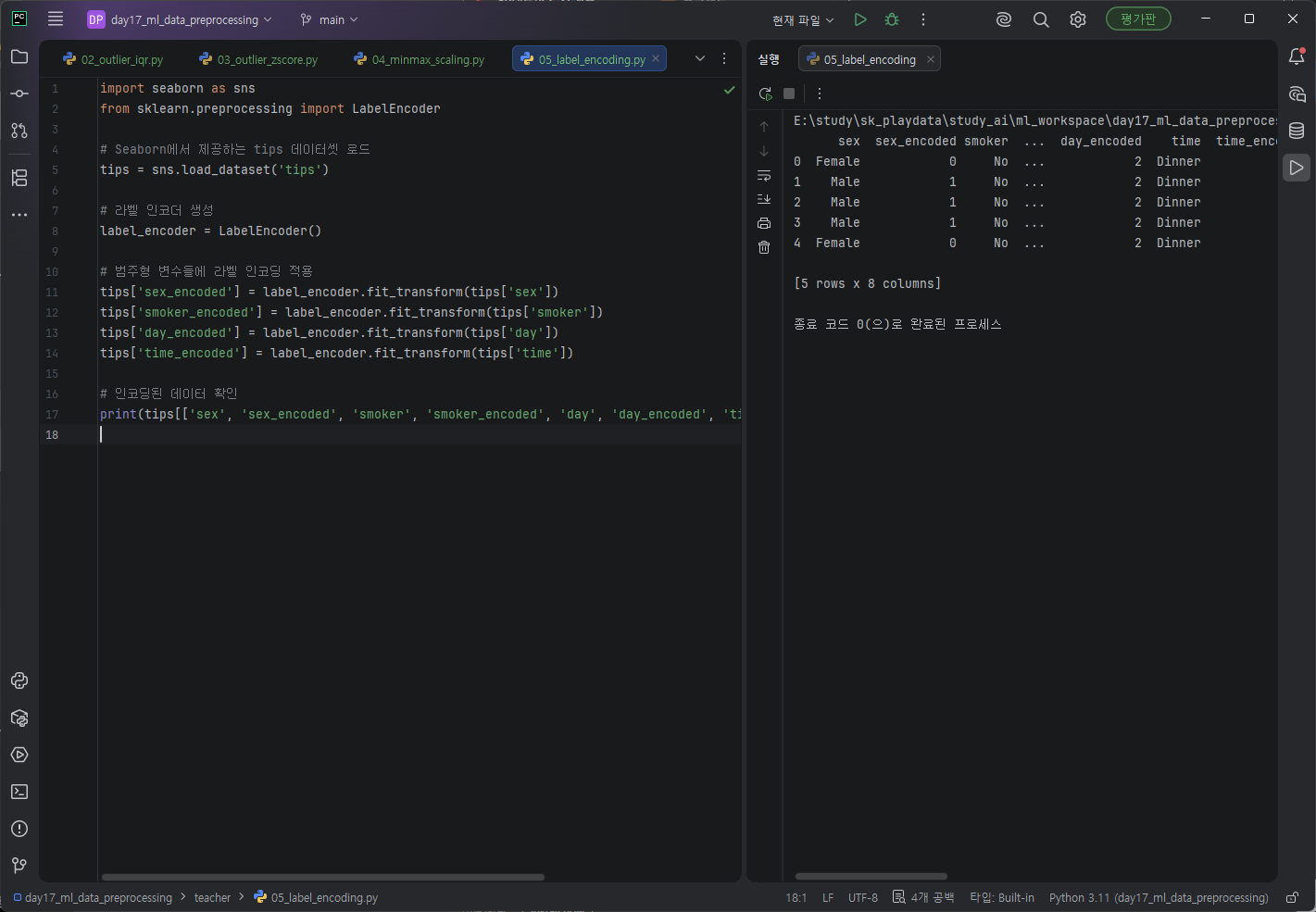
LabelEncoder를 import. Label Encoding는 문자를 숫자로 변환한다.
각 필요한 범주형 변수들에 라벨 인코딩을 적용했다.
결과확인 완료.
import seaborn as sns
from sklearn.preprocessing import LabelEncoder
# Seaborn에서 제공하는 tips 데이터셋 로드
tips = sns.load_dataset('tips')
# 라벨 인코더 생성
label_encoder = LabelEncoder()
# 범주형 변수들에 라벨 인코딩 적용
tips['sex_encoded'] = label_encoder.fit_transform(tips['sex'])
tips['smoker_encoded'] = label_encoder.fit_transform(tips['smoker'])
tips['day_encoded'] = label_encoder.fit_transform(tips['day'])
tips['time_encoded'] = label_encoder.fit_transform(tips['time'])
# 인코딩된 데이터 확인
print(tips[['sex', 'sex_encoded', 'smoker', 'smoker_encoded', 'day', 'day_encoded', 'time', 'time_encoded']].head())
지도학습
├ 선형회귀
├ 다항회귀
├ 리지회귀
└ 로지스틱 회귀
├ 로지스틱 함수(sigmoid)
└ 크로스 엔트로피 오차
지도학습
label, 정답이 있는 데이터를 학습하는 방법, 1시간동안 공부해서 50점, 5시간동안 공부해서 90점이라면 정답이 이미 존재하는것과 다름이 없다 .
선형회귀
가장 기본적인 회귀알고리즘, 연속적인 숫자를 예측한다. 선으로 분석한다 .집값, 온도, 매출 예측등에 사용된다 . y = wx + b 예측값 = 기울기*입력 + 절편
다항회귀
선형회귀의 확장버전으로 직선으로 설명이 안되는 경우 사용한다. 곡선형태의 데이터, y = ax^2 + bx + c 2차식, 3차식 등으로 곡선을 표현한다 . 공부시간이 1시간에 50, 5시간에 90, 20시간에 92점이 됬을경우 직선이 아니라 처음 급증후 완만해진는 경우가 그 예
리지회귀
선형회귀의 문제 해결 버전으로 선형회귀는 과접합의 문제가 발생할 수 있다. 훈련데이터만 너무 잘 맞춰 새로운 데이터 성능이 저하될 수 있다는 것. 리지회귀는 가중치가 너무 커지지않게 제한한다 .
로지스틱 회귀
이름은 회귀지만 실제로는 분류 알고리즘이다. 확률기반 분류로 스팸/정상, 합격/불합격, 암/정상 등이 그 예이다. 0~1 의 확률값이 출력된다 .
로지스틱 함수
로지스틱 회귀에서 사용하는 핵심 함수. 아무 숫자든 입력받아 0~1 사이 확률로 변환되며 s자 곡선이라 sigmoid함수라고 부른다. 선형회귀 결과값은 범위로 출력될 수있지만 분류문제에서는 0~1 사이 확률값이 필요하고 로지스틱 함수는 선형회귀 결과를 확률값으로 변환하는 역할을 한다 .
크로스 엔트로피 오차
로지스틱 회귀에서 사용하는 대표 손실함수로 예측이 얼마나 틀렸는지를 수치화한다 .
의사결정트리
질문을 계속하면서 답을 찾아가는 것. = 스무고개
스플리팅
나누는것. 특정 클래스만 모여있게 나누는것. 비슷한것끼리 나누는 알고리즘
의사결정 나무의 앙상블
여러 컴퓨터의 의견을 듣는 방법
여러컴퓨터, 여러 ai에게 질문을 내려 결정을 내리는것.
비지도학습
└ 클러스터링
└ K-Means
├ K값 필요
├ Elbow Method
└ 복잡한 구조(Two Moons)에 약함
비지도학습
정답(label)이 없는 데이터를 학습하는 방법
지도학습에는 입력+저장 조합이지만 비지도학습에는 입력데이터만 존재한다.
클러스터링
비지도학습의 대표 기술로 비슷한 데이터 끼리 군집으로 묶는 것으로 고객유형 분류, 뉴스 기사 그룹화 등이 있다
군집화를 위한 알고리즘에는 몇개의 그룹으로 나눌것인가 어떤 기준으로 비슷함을 판단하고 데이터 분포가 어떤 형태인가를 결정한다.
k-means 알고리즘
대표적인 군집화 알고리즘으로 데이터를 k개의 그룹으로 나누는 알고리즘이다. 중심점 K개를 생성해 가장 가까운 중심점에 데이터를 배정하고 새로운 중심을 계산하는 등의 반복 과정이다 .비스한 데이터끼리 자동으로 묶이게 되는데 학생형 고객, 직장인 고객, 고소득고객 등으로 묶일 수있다.
구현이 간단하고 속도도 빠르며 이해가 쉬우나 k값을 직접 정해야하고 극단값이 있으면 중심점이 왜곡될 수 있다 .또 데이터가 복잡한 형태에서는 성능이 저하될 수 있다 .또 초기 중심점에 따라 결과가 달라질 수 있다 .
elbow method
k값을 정하기 위한 대표 방법
k르 ㄹ증가시키면서 오차를 계산하고 그래프에서 급격히 감소하다가 완만해지는 지점을 선택한다 .이 모양이 마치 팔꿈치처럼 보여 elbos method라 부른다.
비지도학습
→ 차원축소
→ 임베딩
→ 잠재공간
→ 생성모델
pca principal component analysis 차원축소
대표적인 차원 축소 알고리즘으로 복잡한 feature를 더 적은 축으로 압축 하는 것을 말한다. 데이터 분산이 가장 큰 방향을 찾아 정보 손실을 최소화하고 중요한 특징을 유지한다는 의미.예시로 x, y, z 데이터를 2차원으로 압축을 한다는 것.
임베딩
데이터를 숫자 벡터로 변환하는 것.
컴퓨터는 문자, 이미지의 의미를 직접 이해하지 못함으로 의미를 가진 숫자 백터로 변환한다. 이로 인해 가까운 위치 벡터는 비슷한 의미다~ 하고 이해한다는 개념이다. 압축된 특징 공간인 잠재공간과 다르게 임베딩은 데이터를 백터화했다는 것에 차이가 있다 .
t-SNE t-distributed Stochastic Neighbor Embedding
차원을 축소하고 시각화하는 특화 알고리즘 이다 .가까운데이터는 가까이 유지해 저차원으로 변호나한다. pca가 선형방식으로 전체구조를 유지하되 단순압축방법으로 빠르다면 t-sne은 비선형방식으로 지역 구조를 다 유지하며 시각화에 강력하도록 작업해 느리다
잠재공간
데이터 핵심 특징만을 압축하여 표현한다. 매우 복잡한 원본 데이터 (고양이 이미지의 수만개 픽셀) 에서 실제 핵심특징(귀, 눈위치, 털패턴) 정보를압축해 작은 특징 공간에 저장하는데 이곳은 잠재공간이라 한다 .
생성모델
데이터를 새롭게 생성하는 모델로 ai그림생성, 음성생성 chat gpt 텍스트 생성이 있다 . 생성모델은 잠재공간에서 보통 데이터를 생성한다.
'수학적으로' 말고 '개념적으로' 이해할것!
머신러닝 코드 흐름
데이터 분비 - 데이터 탐색 - 데이터 전처리 - 학습(훈련) - 평가 - 예측
pandas 표형태로 데이터를 다룸
np 숫자 계산을 빠르게 하기 위함
matplotlib, seaborn 그래프 그리기 위함
sklearn 머신러닝, 모델, 데이터셋, 평가도구 제공
load_iris 데이터셋
model-selection train_test_split 데이터를 훈련용 평가용으로 나눔
standardScaler 데이터값 표준화, 전처리
randomforestclassifier 분류문제에 많이 사용하는 머신러닝 모델
accuracy_score 정확도계산
classification_report 정미리도, 재현율, f1-score 점수 출력, 평가 보고서 출력해줌
confusion_matrix 실제값과 예측값의 차이를 표로 확인
joblib 학습된 모델을 파일로 저장하고 불러오기 위한 라이브러리
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
import joblib
F1-score
정밀도와 재현율을 함께 고려한 성능 평가지표로
분류, 불균형데이터에서 많이 사용된다.
암 판별 AI가 있다고 가정했을때 실제 암환자 2명 정상 98명인데 ai가 전부 정상이라고 예측하면 정확도는 98%지만 암환자는 하나도 못찾게된다 .즉 accuracy만으로는 부족하니 precision 정밀도를 활용해 ai가 맞다고 한것중 실제로 맞은 비율을 알아야 한다.
또 recall 재현유ㅠㄹ, 실제 정답을 얼마나 잘 찾아냈는가 .
precision만 높으면 매우 조심스럽게 예측하고 recall만 높으면 다 암이라고 예측을 해버림으로 결국 둘다 중요하다 . F1-score는 이 rpresicion과 recall의 균형을 평가한다. 단순 평균이 아니라 조화평균을 사용해 둘중 하나라도 낮으면 f1-score를 크게 감소한다.
사기탐지, 암진단, 스팸메일, 이상탐지 등 불균형 데이터에 정답이 치우친 데이터에서 많이 사용한다.
jetbrains 접속 - 로그린 - 라이선스접속
https://account.jetbrains.com/licenses
압축해제
평가판인지 확인 - 도움말 - 구독관리

다른구독 활성화 - 활성화코드 - 둘중 되는것으로 사용

평가판 txt 사라졌는지 확인
load_iris() iris 데이터 불러오기
x, iris.data 꽃의 특징 데이터, y, iris.target 라벨
feature_names, target_names에 값 할당.
pd.DataFrame(x) 꽃의 특징데이터 Dataframe 생성

haed() 상위 5개 확인
print('head()-----------------------------------------')
print(df.head())head()-----------------------------------------
sepal length (cm) sepal width (cm) ... target target_names
0 5.1 3.5 ... 0 setosa
1 4.9 3.0 ... 0 setosa
2 4.7 3.2 ... 0 setosa
3 4.6 3.1 ... 0 setosa
4 5.0 3.6 ... 0 setosa
[5 rows x 6 columns]
df.shape 형태 확인
print('shape-----------------------------------------')
print('데이터크기', df.shape)shape-----------------------------------------
데이터크기 (150, 6)
info() dataframe 정보확인
print('info()-----------------------------------------')
print(df.info())info()-----------------------------------------
<class 'pandas.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal length (cm) 150 non-null float64
1 sepal width (cm) 150 non-null float64
2 petal length (cm) 150 non-null float64
3 petal width (cm) 150 non-null float64
4 target 150 non-null int64
5 target_names 150 non-null str
dtypes: float64(4), int64(1), str(1)
memory usage: 7.2 KB
None
value_counts() 품종별 갯수확인
print('value_counts()-----------------------------------------')
print(df['target_names'].value_counts())value_counts()-----------------------------------------
target_names
setosa 50
versicolor 50
virginica 50
Name: count, dtype: int64
입력데이터 x크기: (150, 4)
정답데이터 x크기: (150,)
(120, 4)
(30, 4)
한글설정
plt.rcParams['font.family'] = 'Malgun Gothic' # 맑은 고딕
plt.rcParams['axes.unicode_minus'] = False
품종별 데이터 막대그래프 그리기
sns.countplot(data=df, x='target_names')
plt.title('iris 품종별 데이터 개수')
plt.xlabel('품종')
plt.ylabel('개수')
plt.show()
타겟 이름별 pariplot 그리기
iris 3개의 품종이 feature 공간에서 어떻게 구분되는지를 시각적으로 확인할 수 있다 .
모든 변수 쌍을 전부 산점도로 그린것, 대각선에는 각 feature의 분포가 보인다 .
hue = target_names로 산점도 색을 품종 기준으로 달리한다.
각 클래스가 덩어리처럼 모여있는지 확인가능하다.
sns.pairplot(df, hue='target_names')
plt.show()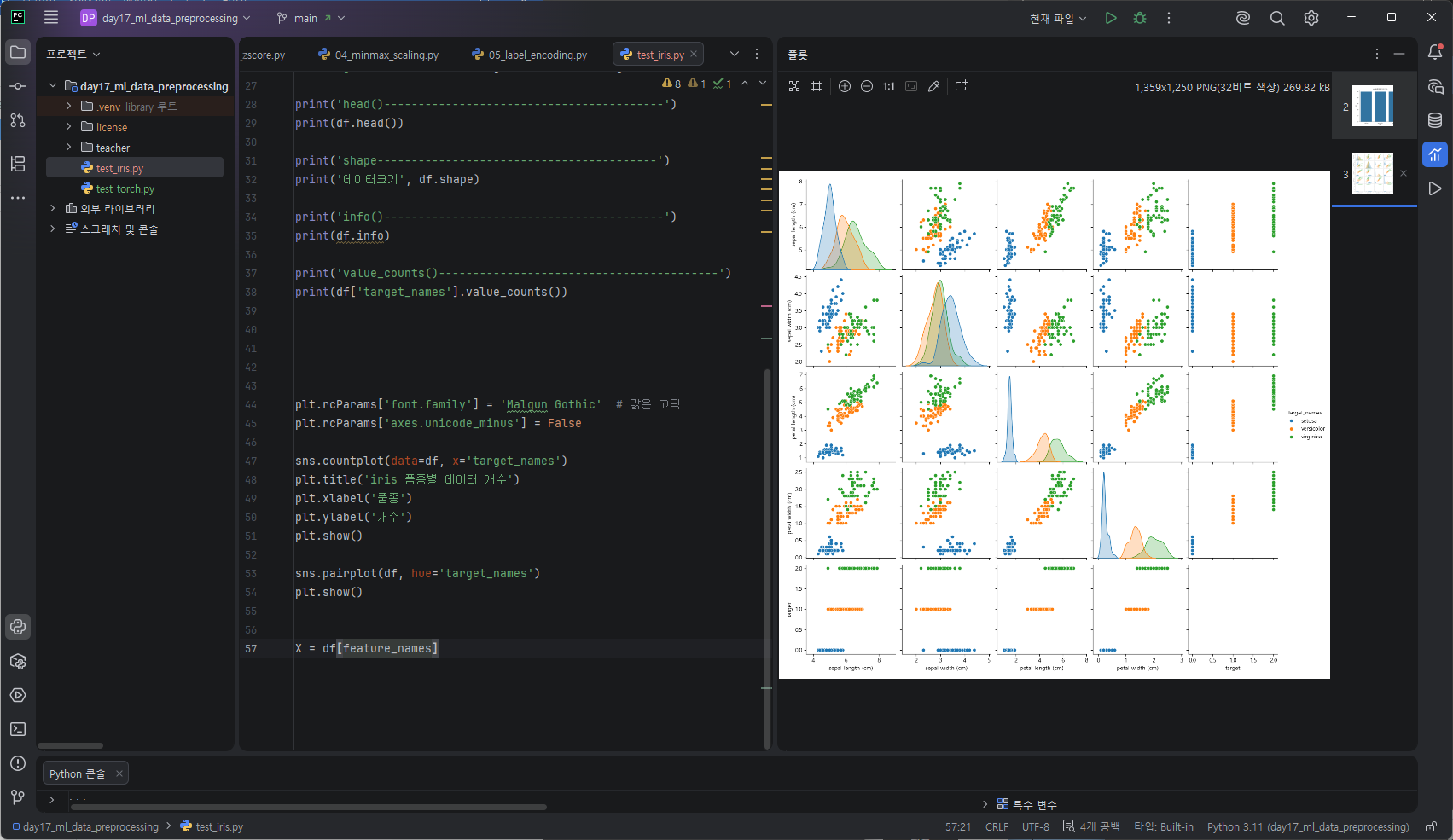
머신러닝은 기본적으로 x입력 y정답의 샘플의 수가 반드시 같아야한다.
즉 샘플의 수가 같은지, 데이터가 모델에 들어갈 수 있는 구조인지 확인하기 위해 입력데이터 크기를 확인한다.
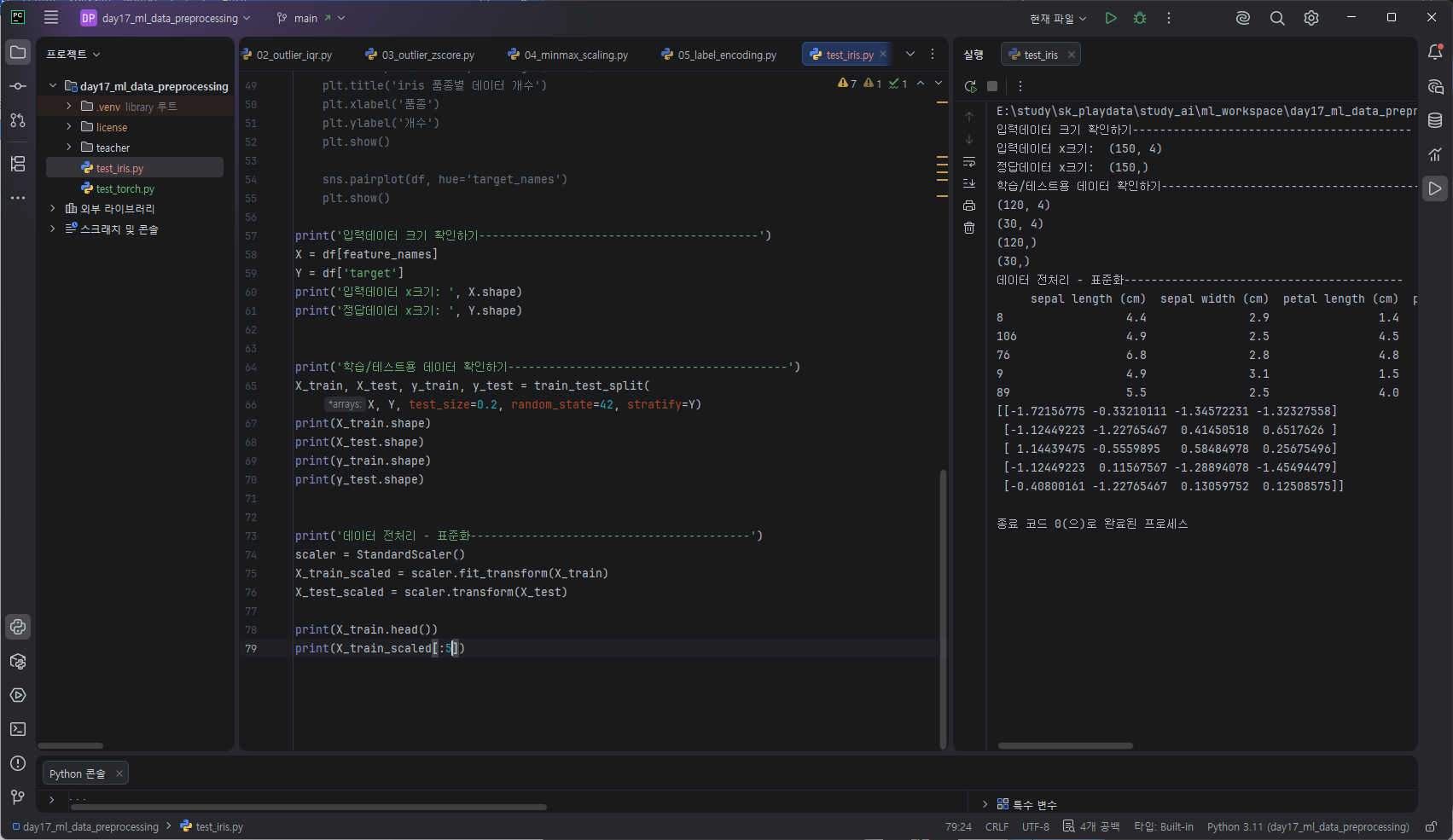
print('입력데이터 크기 확인하기-----------------------------------------')
X = df[feature_names]
Y = df['target']
print('입력데이터 x크기: ', X.shape)
print('정답데이터 x크기: ', Y.shape)
train_test_aplit() 학습용, 테스트용 데이터 만들기
학습용:모델이 공부하는 데이터
테스트용:모델이 처음보는 문제를 잘 맞히는지 확인하는 데이터
test_size 전체 데이터 중 20%를 테스트용으로 사용
random_state: 실행할때마다 같은 결과가 나오도록 고정
stratigy: 품종 비율이 학습/테스트 데이터에 비슷하게 나뉘도록 설정.
X_train, X.test, y_train, y_test = train_test_split(
X, Y, test_size=0.2, random_state=42, stratify=Y)
X_train, X_test, y_train, y_test = train_test_split(
X, Y, test_size=0.2, random_state=42, stratify=Y)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
데이터 전처리
transform시 학습데이터 기준으로만 변환해야한다. 테스트 데이터 기준으로 새로 fit하면 데이터 누수가 발생할 수 있다 .
테스트하기 좋도록 standardscaler 값의 차이가 크지않아졌다 .
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
print(X_train.head())
print(X_train_scaled[:5])데이터 전처리 - 표준화-----------------------------------------
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
8 4.4 2.9 1.4 0.2
106 4.9 2.5 4.5 1.7
76 6.8 2.8 4.8 1.4
9 4.9 3.1 1.5 0.1
89 5.5 2.5 4.0 1.3
[[-1.72156775 -0.33210111 -1.34572231 -1.32327558]
[-1.12449223 -1.22765467 0.41450518 0.6517626 ]
[ 1.14439475 -0.5559895 0.58484978 0.25675496]
[-1.12449223 0.11567567 -1.28894078 -1.45494479]
[-0.40800161 -1.22765467 0.13059752 0.12508575]]
RandomForest
여러개의 의사결정 나무를 만들고 그 결과중 투표해 최종 클래스를 결정한다.
초보자가 써도 성능이 잘나온다.
기본적으로강한 기본모델 + 평균화 효과로 튜닝 없이 안정적인 성능이 나온다.
Decision Tree 자체가 이미 강한 모델이고 규칙기반으로 데이터를 계속 쪼개 복잡한 패턴도 자동으로 학습이 가능하다.

결정트리를 100개 사용한다.
결과재현을 위한 고정값은 42로 지정한다.
fit() 모델 학습시키는 함수
model = RandomForestClassifier(
n_estimators=100,
random_state=42
)
model.fit(X_train_scaled, y_train)
predict() 새로운 데이터에 대한 정답을 예측함
'얼추' 잘맞았다 .
y_pred = model.predict(X_test_scaled)
print(y_pred)
print(y_test.values)model-----------------------------------------
[0 2 1 1 0 1 0 0 2 1 2 2 2 1 0 0 0 1 1 1 0 2 1 1 2 2 1 0 2 0]
[0 2 1 1 0 1 0 0 2 1 2 2 2 1 0 0 0 1 1 2 0 2 1 2 2 1 1 0 2 0]
accuracy_score() 정확도 확인해보자.
accuracy = accuracy_score(y_test, y_pred)
print(accuracy)
classification_report
모델을 평가해보자.
precision 예측한것중 실제로 맞은 비율
recall 실제 정답 중 모델이 맞힌 비율
f1-score precision과 recall 의 종합점수
setosa 말고는 조금씩 틀렸음을 확인할 수 있다 .
print(classification_report(y_test, y_pred, target_names=target_names)) precision recall f1-score support
setosa 1.00 1.00 1.00 10
versicolor 0.82 0.90 0.86 10
virginica 0.89 0.80 0.84 10
accuracy 0.90 30
macro avg 0.90 0.90 0.90 30
weighted avg 0.90 0.90 0.90 30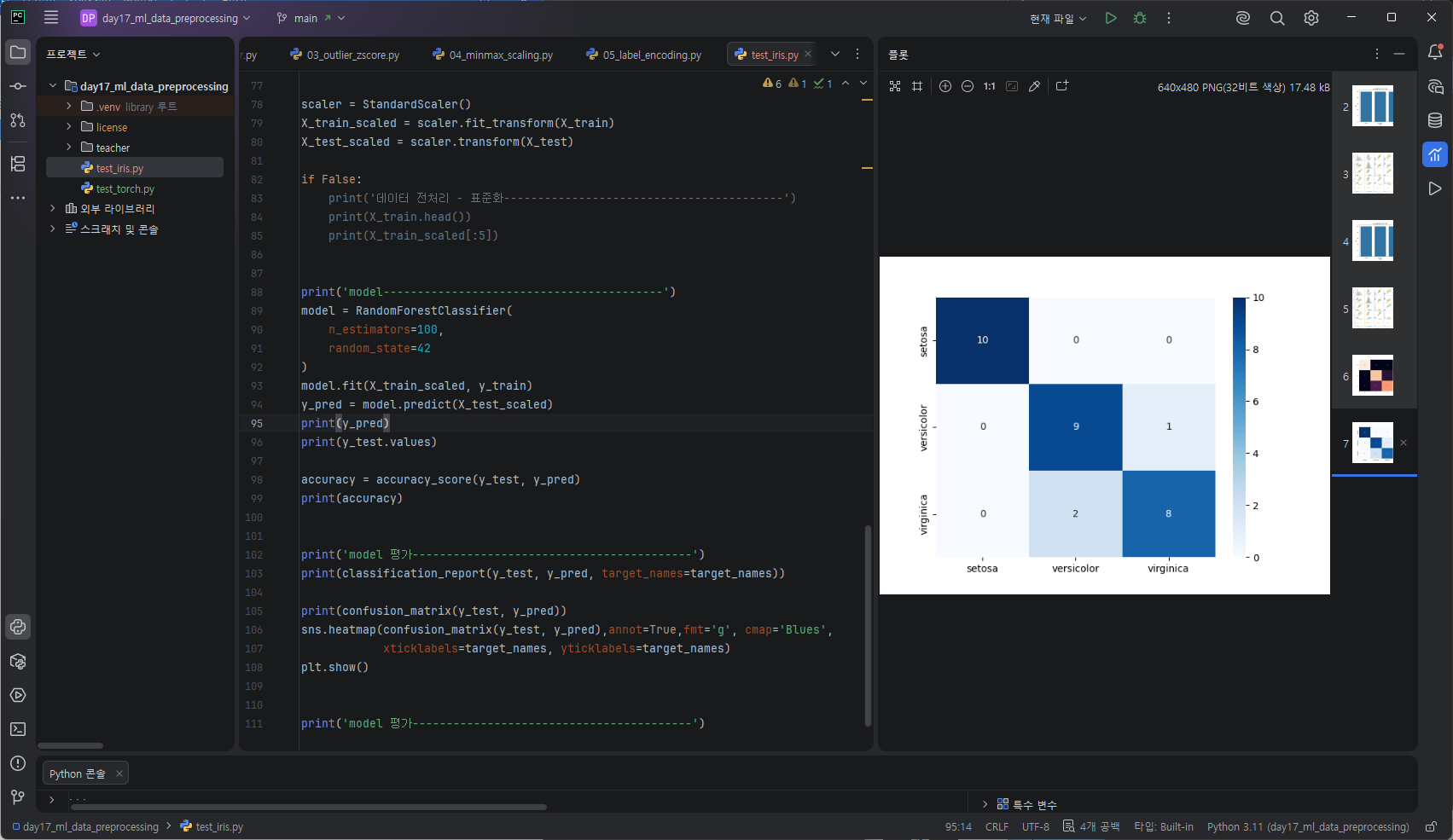
confusion Matrix 혼동행렬
분류 모델의 성능을 실제값, 예측값 기준으로 정리한 표
모델이 어디서틀리고 맞는지를 구조적으로 보여준다.
실제도 양성/음성, 예측도 양성/음성이면 정답으로 잘 맞춘 경우~ 다르면 틀리다고 이해한다.
정확도만 보고 모델 성능을 잘못 해석해 암환자를 놓칠수있다는것을 생각하면 혼동행렬의 확인은 참 중요하다.
대각선은 맞춘갯수, 나머지는 헷갈린관계.
print(confusion_matrix(y_test, y_pred))[[10 0 0]
[ 0 9 1]
[ 0 2 8]]
혼동행렬을 sns.heatmap을 활용해 표현
sns.heatmap(confusion_matrix(y_test, y_pred),annot=True,fmt='g', cmap='Blues',
xticklabels=target_names, yticklabels=target_names)
plt.show()
새로운 데이터로 예측결과 확인
똑같은 절차를 거친다 .scaled - pred
정규화를 거쳐 예측하면된다 .
StandardScaler - scaler - transform (!! train데이터만 효율성을 위해 fit_transform를 사용했었다 테스트에는 그냥 transform)
RandomForestClassifier - model - predict()
new_data = [[5.1, 3.5, 1.4, 0.2]]
new_data_scaled = scaler.transform(new_data)
new_pred = model.predict(new_data_scaled)
pred_name = target_names[new_pred[0]]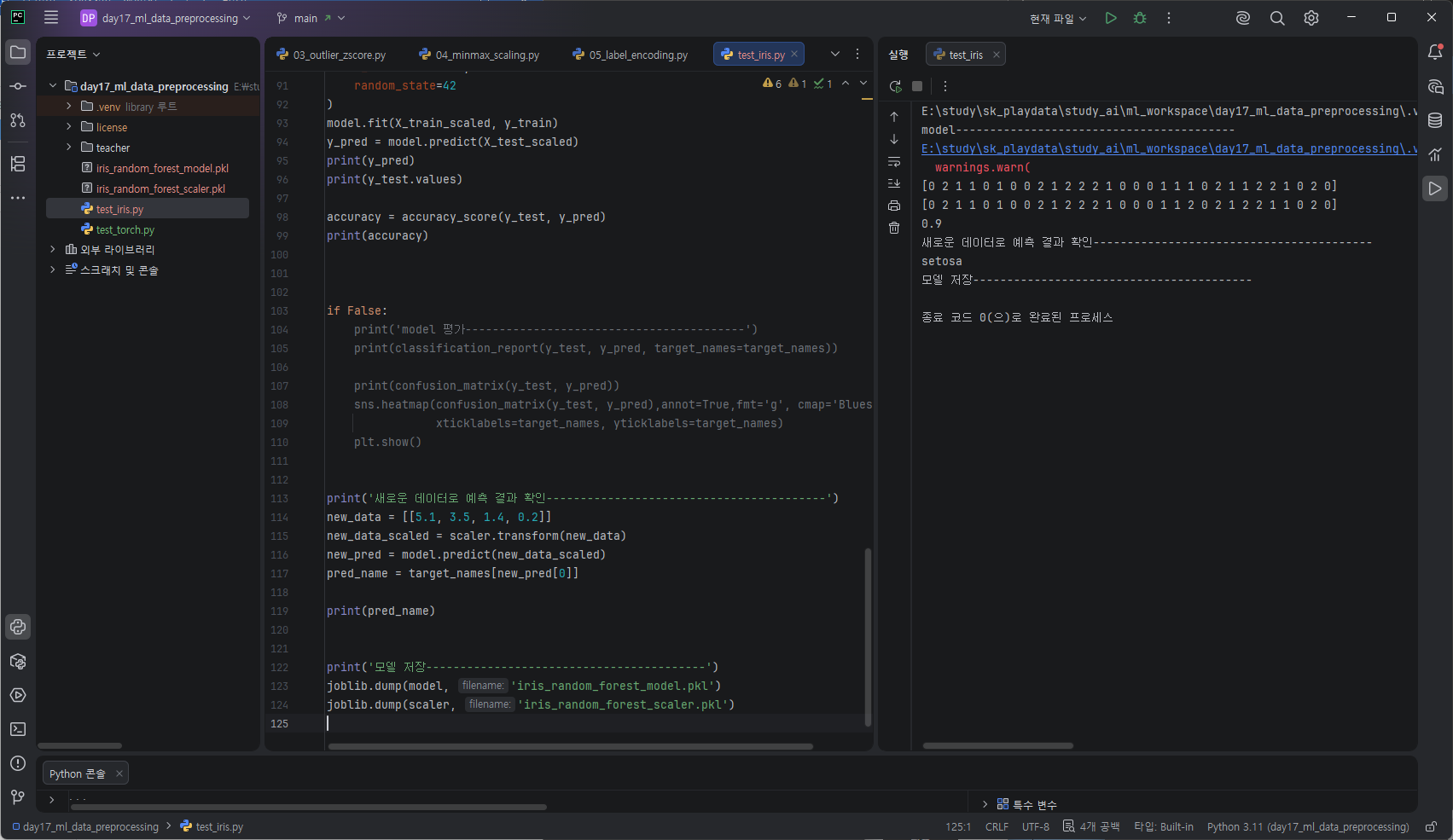
① fit: X_train의 평균, 표준편차(또는 최소/최대)를 계산
② transform: 그 통계값으로 데이터를 스케일링
완성한 모델 저장하기
pkl 객체를 저장한 pickle 파일을 의미
모델 파일의 확장자는 임의대로 지정한다.
joblib.dump(model, 'iris_random_forest_model.pkl')
joblib.dump(scaler, 'iris_random_forest_scaler.pkl')
pickle은 파이썬 객체를 파일로 저장/불러오기 하는 모듈로 .pkl의 확장자를 가진다.
pkl은 관례적인 확장자일뿐 필수가 아니며 사실 파일이름을 아무거나 가능하다. pkl, data, xyz..
컴퓨터입장에서는 확장자가 중요한게 아니라 pickle형식으로 저장됫느냐이고 내용이 pickle형식으로만 되어있으면 읽을 수 있음. pkl은 사람끼리 약속한 컨벤션과 같아 pickle파일이라는 것을 바로 알기위해, 머신러닝 모델 저장 파일이라는 의미로 많이 사용한다.
저장한 모델 불러오기
loaded_model = joblib.load('iris_random_forest_model.pkl')
loaded_scaler = joblib.load('iris_random_forest_scaler.pkl')
sample데이터로
scaled.transform해서 predict()예측해 target_names[~[0]] 으로 값을 확인한다.
이때 scaler와 model은 load된 것으로 하면되겠다.
sample = [[6.2, 3.5, 5.4, 2.3]]
sample_scaled = loaded_scaler.transform(sample)
sample_pred = loaded_model.predict(sample_scaled)
pred_name = target_names[sample_pred[0]]
print(sample_pred, pred_name)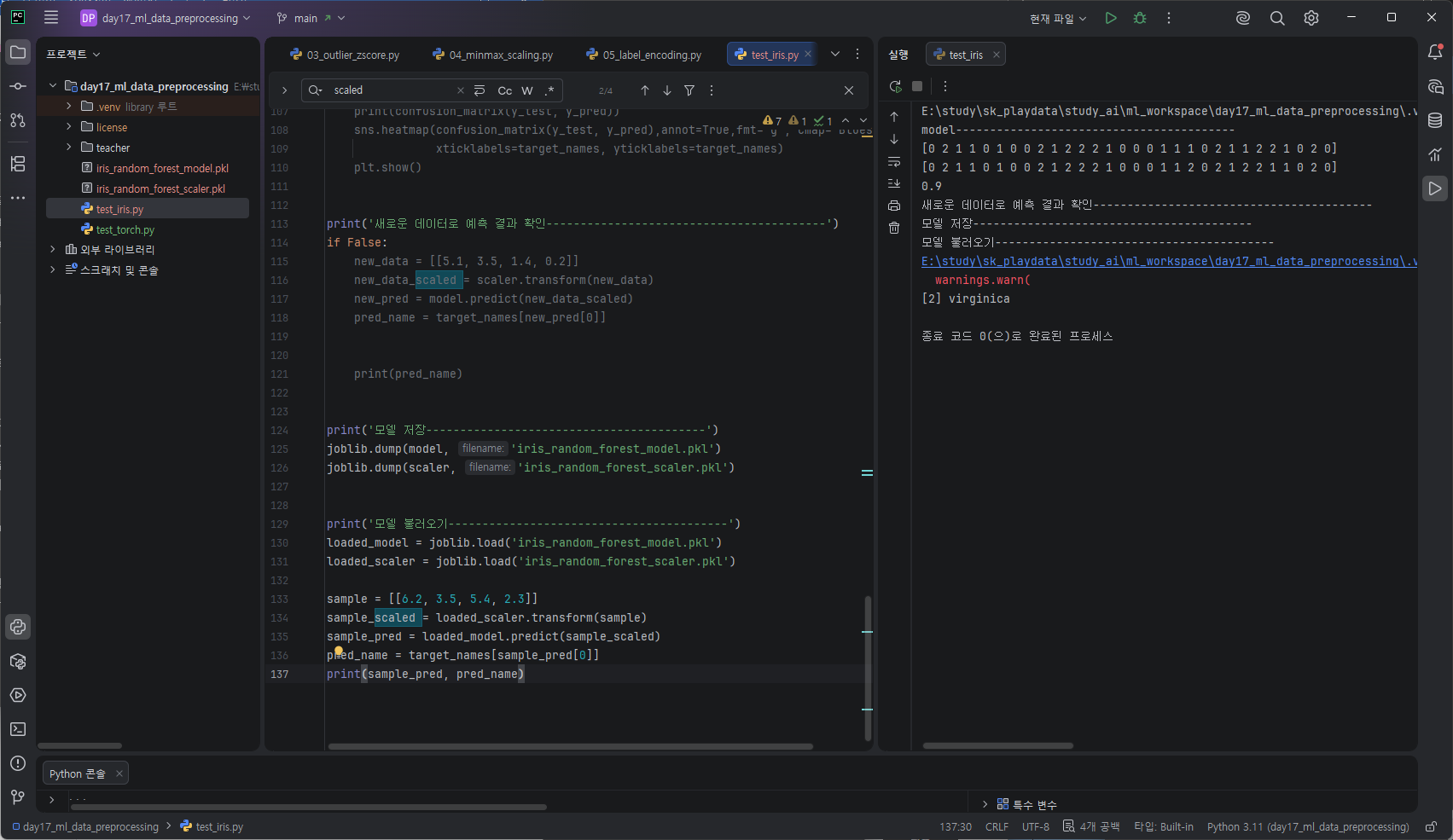
위와 같은 똑같은 절차를 torch를 사용하면 코드가 달라진다.
수령자료를 확인하자.
# ============================================================
# 1. 기본 라이브러리 불러오기
# ============================================================
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# PyTorch 핵심 라이브러리
import torch
# 신경망 모델을 만들기 위한 모듈
import torch.nn as nn
# 최적화 알고리즘을 사용하기 위한 모듈
import torch.optim as optim
# PyTorch Dataset, DataLoader 사용
from torch.utils.data import TensorDataset, DataLoader
# Iris 데이터셋
from sklearn.datasets import load_iris
# 학습용 / 테스트용 데이터 분리
from sklearn.model_selection import train_test_split
# 데이터 표준화
from sklearn.preprocessing import StandardScaler
# 평가 지표
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# ============================================================
# 2. 실행 장치 설정 - GPU 사용 가능 여부 확인
# ============================================================
# Colab에서 GPU를 켜면 cuda 사용 가능
# GPU가 없으면 CPU 사용
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("사용 장치:", device)
# ============================================================
# 3. 데이터 불러오기
# ============================================================
iris = load_iris()
# 입력 데이터
X = iris.data
# 정답 데이터
y = iris.target
feature_names = iris.feature_names
target_names = iris.target_names
df = pd.DataFrame(X, columns=feature_names)
df["target"] = y
df["target_name"] = df["target"].apply(lambda x: target_names[x])
df.head()
# ============================================================
# 4. 데이터 기본 정보 확인
# ============================================================
print("데이터 크기:", df.shape)
print("\n기초 통계량:")
print(df.describe())
print("\n품종별 개수:")
print(df["target_name"].value_counts())
# ============================================================
# 5. 데이터 시각화
# ============================================================
sns.countplot(data=df, x="target_name")
plt.title("Iris 품종별 데이터 개수")
plt.xlabel("품종")
plt.ylabel("개수")
plt.show()
sns.pairplot(df, hue="target_name")
plt.show()
# ============================================================
# 6. 입력 데이터와 정답 데이터 분리
# ============================================================
X = df[feature_names].values
y = df["target"].values
print("입력 데이터 크기:", X.shape)
print("정답 데이터 크기:", y.shape)
# ============================================================
# 7. 학습용 / 테스트용 데이터 분리
# ============================================================
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42,
stratify=y
)
print("학습용 입력 데이터:", X_train.shape)
print("테스트용 입력 데이터:", X_test.shape)
# ============================================================
# 8. 데이터 전처리 - 표준화
# ============================================================
scaler = StandardScaler()
# 학습 데이터 기준으로 평균과 표준편차 계산 후 변환
X_train_scaled = scaler.fit_transform(X_train)
# 테스트 데이터는 학습 데이터 기준으로만 변환
X_test_scaled = scaler.transform(X_test)
# ============================================================
# 9. NumPy 데이터를 PyTorch Tensor로 변환
# ============================================================
# 입력 데이터는 float32 타입으로 변환
X_train_tensor = torch.tensor(X_train_scaled, dtype=torch.float32)
X_test_tensor = torch.tensor(X_test_scaled, dtype=torch.float32)
# 정답 데이터는 CrossEntropyLoss 사용을 위해 long 타입으로 변환
y_train_tensor = torch.tensor(y_train, dtype=torch.long)
y_test_tensor = torch.tensor(y_test, dtype=torch.long)
print(X_train_tensor.shape)
print(y_train_tensor.shape)
# ============================================================
# 10. Dataset과 DataLoader 생성
# ============================================================
# TensorDataset은 입력 데이터와 정답 데이터를 하나로 묶는다
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
# DataLoader는 데이터를 batch 단위로 나누어 학습에 사용한다
train_loader = DataLoader(
train_dataset,
batch_size=16,
shuffle=True
)
# ============================================================
# 11. PyTorch 신경망 모델 정의
# ============================================================
class IrisNet(nn.Module):
def __init__(self):
super(IrisNet, self).__init__()
# 입력 특성은 4개
self.fc1 = nn.Linear(4, 16)
# 은닉층
self.fc2 = nn.Linear(16, 16)
# 출력 클래스는 3개
self.fc3 = nn.Linear(16, 3)
# 활성화 함수
self.relu = nn.ReLU()
def forward(self, x):
# 첫 번째 완전연결층
x = self.fc1(x)
x = self.relu(x)
# 두 번째 완전연결층
x = self.fc2(x)
x = self.relu(x)
# 출력층
# CrossEntropyLoss는 내부적으로 softmax를 처리하므로 여기서 softmax를 쓰지 않는다
x = self.fc3(x)
return x
# ============================================================
# 12. 모델 생성
# ============================================================
model = IrisNet().to(device)
print(model)
# ============================================================
# 13. 손실 함수와 최적화 함수 정의
# ============================================================
# 다중 분류 문제이므로 CrossEntropyLoss 사용
criterion = nn.CrossEntropyLoss()
# Adam 옵티마이저 사용
optimizer = optim.Adam(
model.parameters(),
lr=0.01
)
# ============================================================
# 14. 모델 학습
# ============================================================
epochs = 100
loss_history = []
for epoch in range(epochs):
model.train()
total_loss = 0
for batch_X, batch_y in train_loader:
batch_X = batch_X.to(device)
batch_y = batch_y.to(device)
# 이전 계산된 기울기 초기화
optimizer.zero_grad()
# 모델 예측
outputs = model(batch_X)
# 손실 계산
loss = criterion(outputs, batch_y)
# 역전파
loss.backward()
# 가중치 업데이트
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(train_loader)
loss_history.append(avg_loss)
if (epoch + 1) % 10 == 0:
print(f"Epoch [{epoch+1}/{epochs}], Loss: {avg_loss:.4f}")
# ============================================================
# 15. 학습 손실 그래프 확인
# ============================================================
plt.plot(loss_history)
plt.title("Training Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.show()
# ============================================================
# 16. 테스트 데이터 예측
# ============================================================
model.eval()
with torch.no_grad():
X_test_device = X_test_tensor.to(device)
outputs = model(X_test_device)
# 가장 큰 점수를 가진 클래스 선택
_, predicted = torch.max(outputs, 1)
y_pred = predicted.cpu().numpy()
print("예측 결과:", y_pred)
print("실제 정답:", y_test)
# ============================================================
# 17. 모델 평가
# ============================================================
accuracy = accuracy_score(y_test, y_pred)
print("모델 정확도:", accuracy)
print("모델 정확도(%):", accuracy * 100)
print(classification_report(
y_test,
y_pred,
target_names=target_names
))
# ============================================================
# 18. 혼동 행렬 확인
# ============================================================
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(
cm,
annot=True,
fmt="d",
cmap="Blues",
xticklabels=target_names,
yticklabels=target_names
)
plt.xlabel("예측값")
plt.ylabel("실제값")
plt.title("Confusion Matrix")
plt.show()
# ============================================================
# 19. 새로운 데이터 예측
# ============================================================
new_data = [[5.1, 3.5, 1.4, 0.2]]
new_data_scaled = scaler.transform(new_data)
new_data_tensor = torch.tensor(
new_data_scaled,
dtype=torch.float32
).to(device)
model.eval()
with torch.no_grad():
output = model(new_data_tensor)
_, prediction = torch.max(output, 1)
predicted_class = prediction.item()
predicted_name = target_names[predicted_class]
print("새 데이터 예측 번호:", predicted_class)
print("새 데이터 예측 품종:", predicted_name)
# ============================================================
# 20. PyTorch 모델 저장
# ============================================================
torch.save(model.state_dict(), "iris_pytorch_model.pth")
print("PyTorch 모델 저장 완료")
# ============================================================
# 21. 저장된 PyTorch 모델 불러오기
# ============================================================
loaded_model = IrisNet().to(device)
loaded_model.load_state_dict(torch.load("iris_pytorch_model.pth", map_location=device))
loaded_model.eval()
print("저장된 PyTorch 모델 불러오기 완료")
# ============================================================
# 22. 불러온 모델로 다시 예측
# ============================================================
sample = [[6.2, 3.4, 5.4, 2.3]]
sample_scaled = scaler.transform(sample)
sample_tensor = torch.tensor(
sample_scaled,
dtype=torch.float32
).to(device)
with torch.no_grad():
sample_output = loaded_model(sample_tensor)
_, sample_pred = torch.max(sample_output, 1)
print("예측 번호:", sample_pred.item())
print("예측 품종:", target_names[sample_pred.item()])
https://standout.tistory.com/1747
sklearn과 Torch: 하는일을 같은데.. sklearn과 Torch 의 코드가 다른이유
같은 코드라고 sklearn으로 구현하는 것과 Torch로 구현하는것이 줄수 자체가 다르다. 이유가 뭘까?sklearn은 자동화된 통합 api라 코드가 짧지만 pytorch는 모델구조 + 학습 루프를 직접만들기 때문에
standout.tistory.com
실습수행.
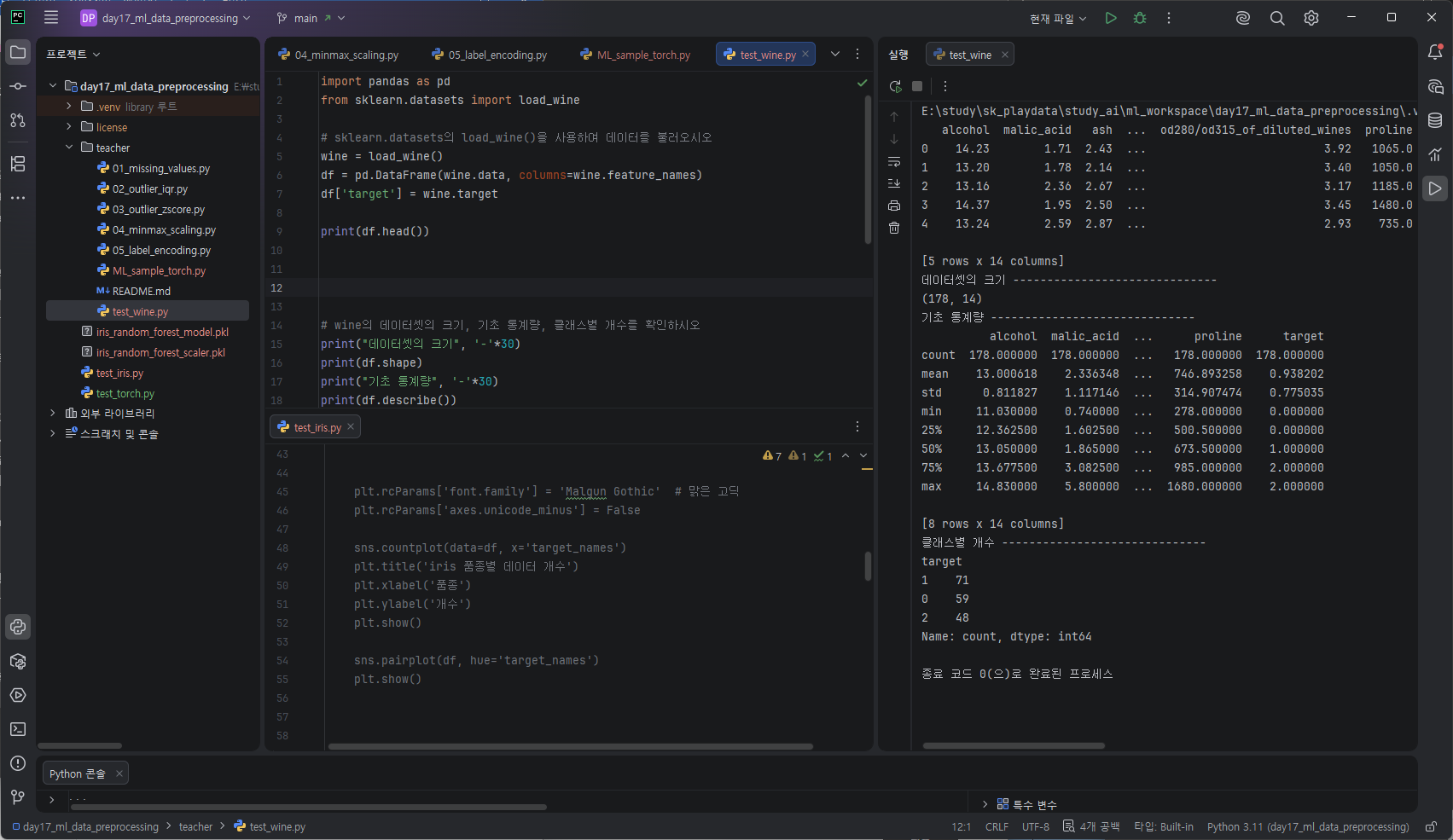
df['target_names'] = df['target'].map(
dict(zip(range(len(wine.target_names)), wine.target_names))
)sns.countplot(data=df, x='target_names', hue='target')


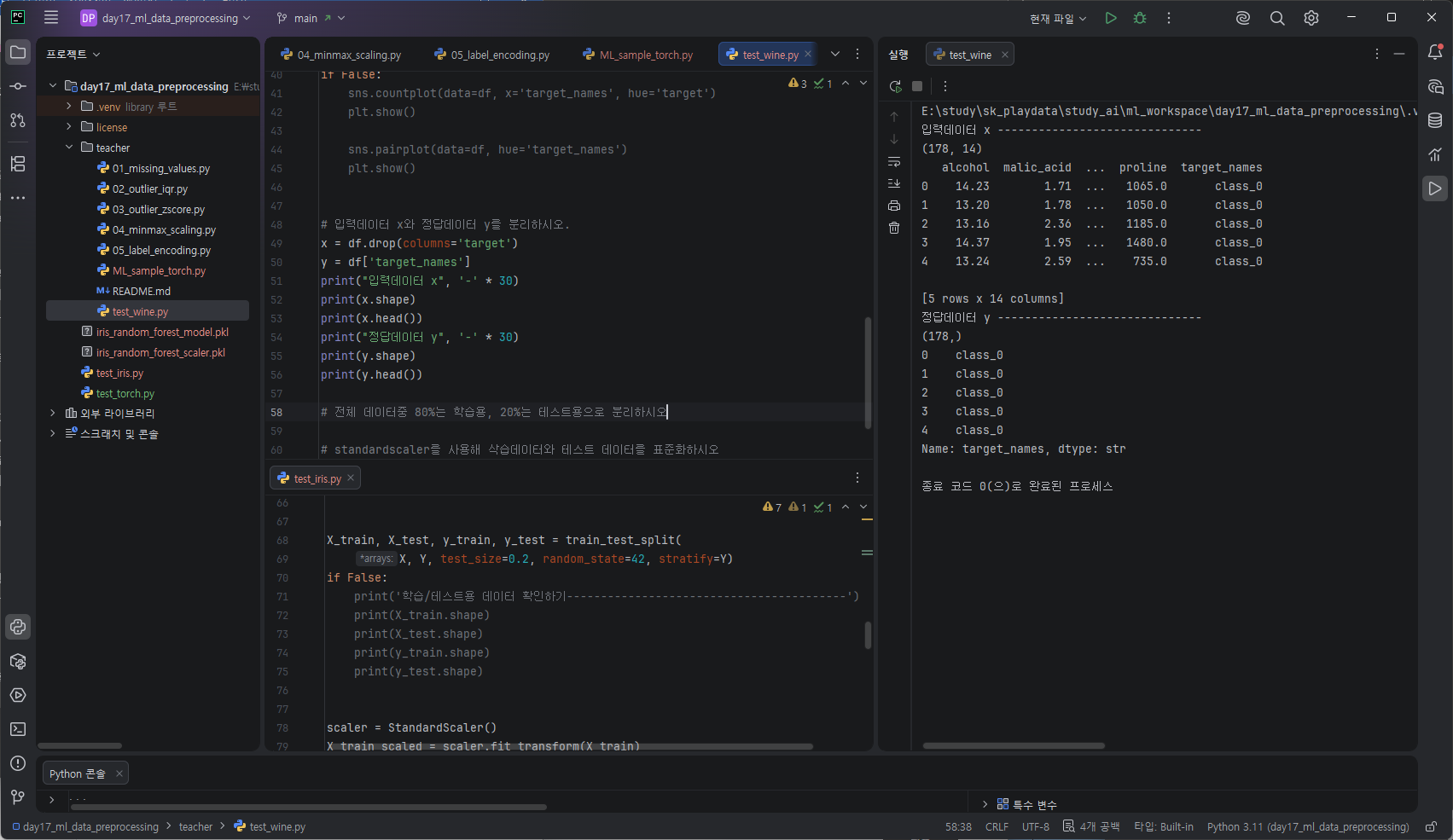
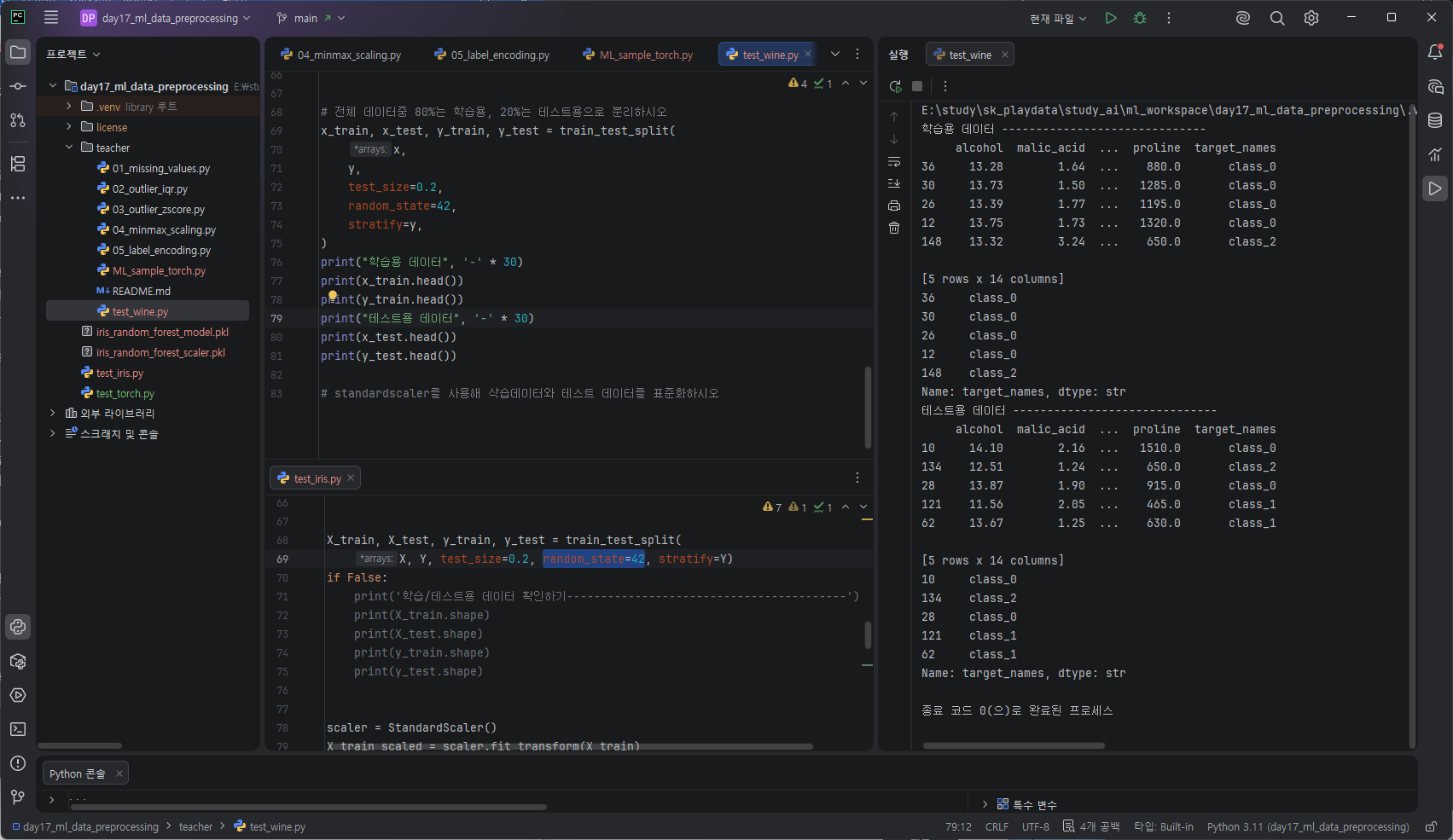



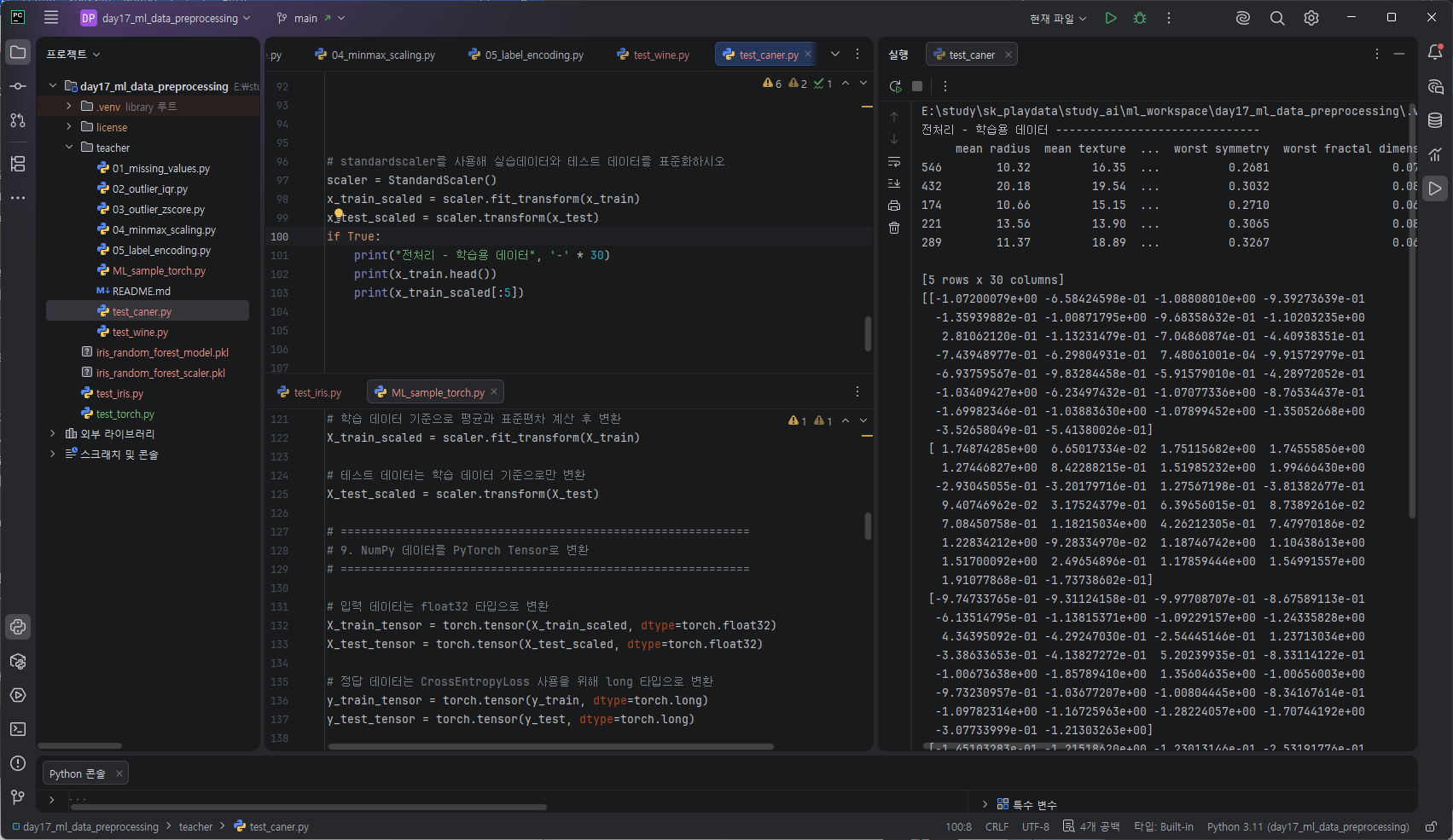
https://standout.tistory.com/1748
random_state는 왜 42일까? 또 항상 써야할까? 선택일까?
random_state=42는 선택. 하지만 거의 항상 넣는 게 맞다. 예로결과 동일해야 하는 상황 즉 과제 / 보고서, 모델 비교, 실험 재현, 디버깅시 써야하며단순 테스트 혹은 랜덤성 자체가 목적일 때는 사용
standout.tistory.com
'SK 네트웍스 AI 캠프' 카테고리의 다른 글
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day19_머신러닝 서포트백터머신 구조 (0) | 2026.05.29 |
|---|---|
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day18_머신러닝_회귀모델_분류모델 (0) | 2026.05.28 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day16_데이터 시각화 (0) | 2026.05.26 |
| [SK네트웍스 Family AI 캠프] 32기 4주차 회고: Day13 ~ Day15 (0) | 2026.05.22 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day15_데이터 전처리 (0) | 2026.05.22 |



