어제 마지막에 경험해봤던 pandas series를 잠시 복습해보자.
https://standout.tistory.com/1730
SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day14_데이터 전처리
dtype은 배열에서의 저장되는 값의 종류, type은 객체의 타입 접두사로도 dtype을 지정할 수 있다. f floatU 유니코드문 None 없다 .NaN 숫자가 아니다. inf, nan 무한대와, 숫자가 아닌numpy에서 무한대를 표
standout.tistory.com
Series
순차적인 1차원 형태의 데이터
Pandas Series를 이용하여 생성
리스트, 딕셔너리, Numpy 배열이 인자로 들어갈 수 있음.
인덱스 0부터 시작
레이블이 반드시 필요하지않다. 레이블 기반 인덱싱을 지원한다.
통계 메서드 사용시 자동으로 누락된 데이터 제외시킨다.
서로 다른 길이의 Series 객체와의 연산이 가능함.
딕셔너리 객체를 series로.
pandas에서는 데이터를 다루기 쉽게하기 위해 Series나 Dataframe 형태로 변환해 사용한다. dict는 그저 형태일 뿐이고 pandas기능( 인덱싱, 통계, 필터링)을 제대로 쓸수없다.

이번엔 dataframe

색인객체 Index
series혹은 dataframe의 데이터를 rdbms의 기본키와 유사하게 식별하는 객체
각행과 열의 이름과 메타데이터(축의 이름..)등을 저장하는 객체
변경이 불가능하나 reindex명령을 이용한 변경은 가능하고 ndarray로 순서가있고 슬라이싱이 가능하며 중복을 허용해 해당 중복값 선택시 해당 모든 항목이 선택됨

index관련 정보확인
size 크기확인 shape 세입확인, dtype 자료형확인 values 값출력 tolist 리스트변환 in 값 존재여부확인 get_loc 위치검색 [:]슬라이싱

append 색인개체로 새로운 색인만들기

insert 지정된 위치에 색인이 추가된 새로운 색인 만들기
위 append에서는 '색인개체'로 apend했으나 insert에서는 '요소'를 하나 추가함으로 형태가 다름을 이해하자.

union합집합
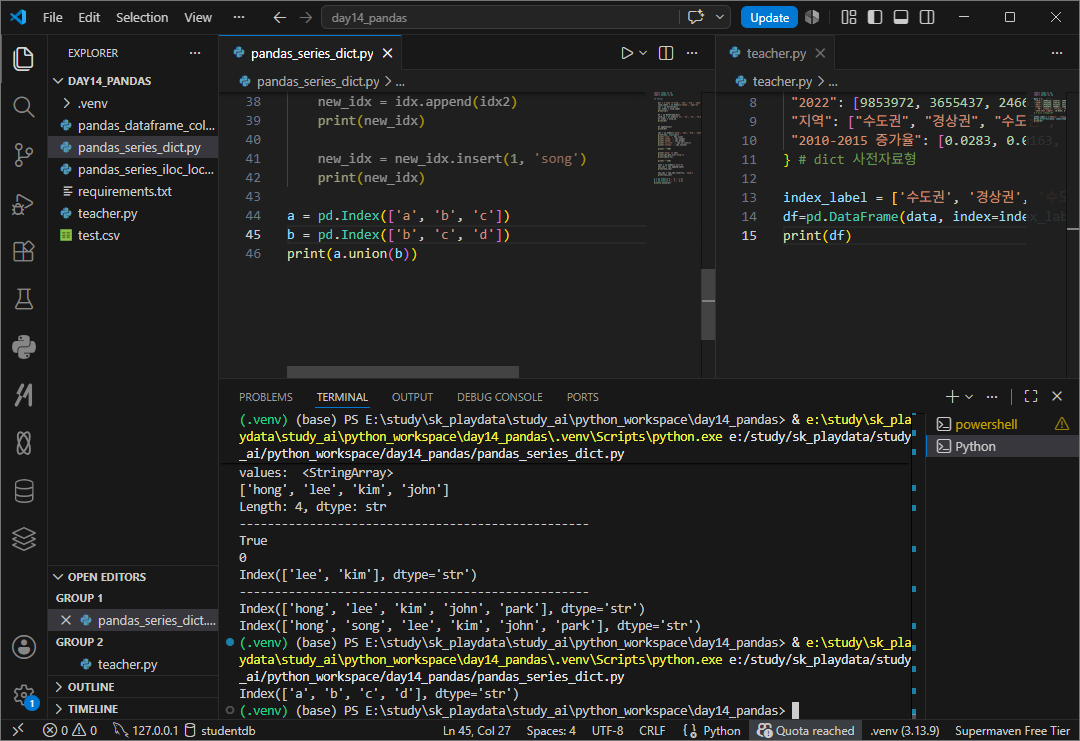
intersection 교집합
difference 차집합

sort_values 정렬
is_unique 중복된 색인이있는지
isin 색인이 존재하는지 불리언배열로, 중복허용하여 출력

위 is_unique와 조금 다르게 unique는 '중복제거된색인'을 반환한다.

drop 지정된 값이 삭재된 새로운 색인
delte 지정된 취치에 값이 삭제된 새로운 색인

is_monotonic_increasing 오름차순인가
is_monotonic_decreasing 내림차순인가

DATAFRAME에 행과 열을 추가해보자 이때 갯수를 잘 출력해보고 진행하다 '수'가 맞지않으면 에러남
dataframe 행 추가하기
df.loc[라벨이름] = [데이터]
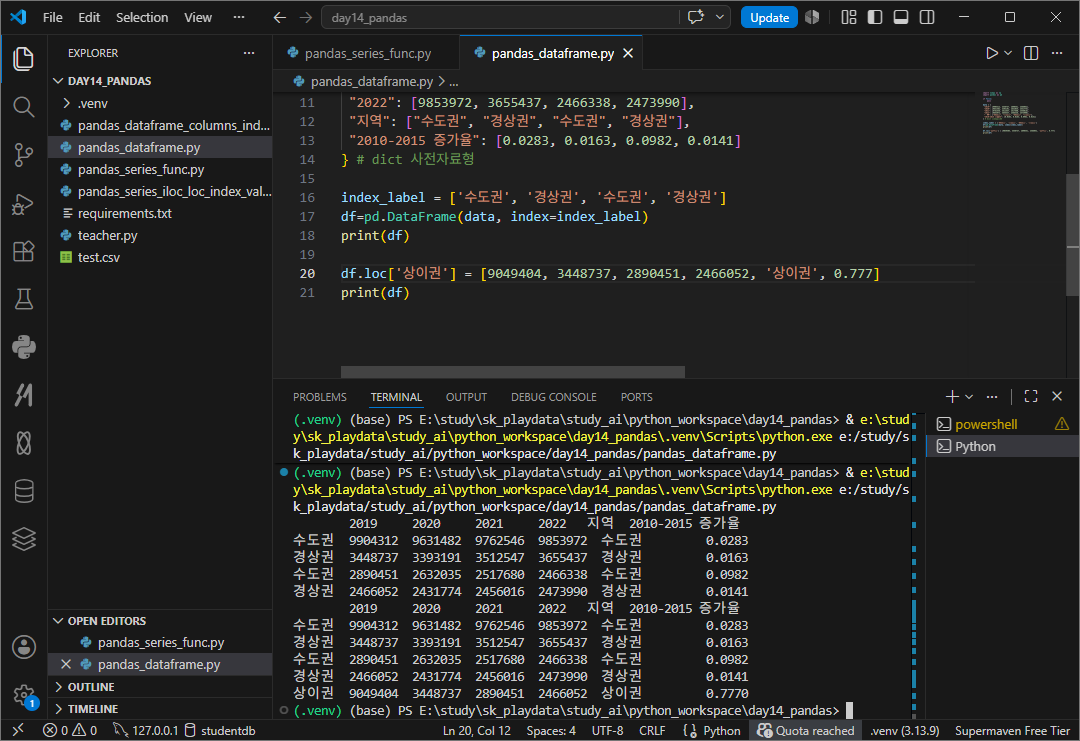
열 추가하기
df[열이름] = [데이터~]

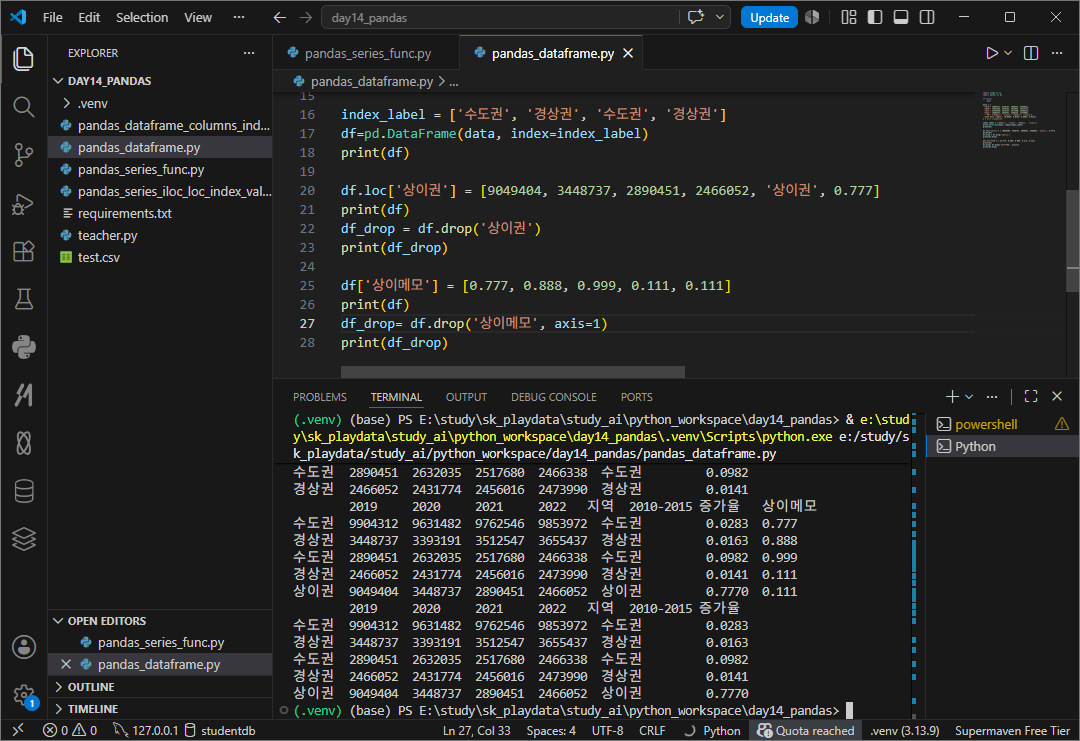
행과 열을 다시 삭제해보자 .
단 이때 '그 객체에서 삭제하거나 변경되는 것이 아닌 새로운 객체를 생성해 반환'한다
df.drop(행라벨이름)
df.drop(열라벨이름, axis=1)
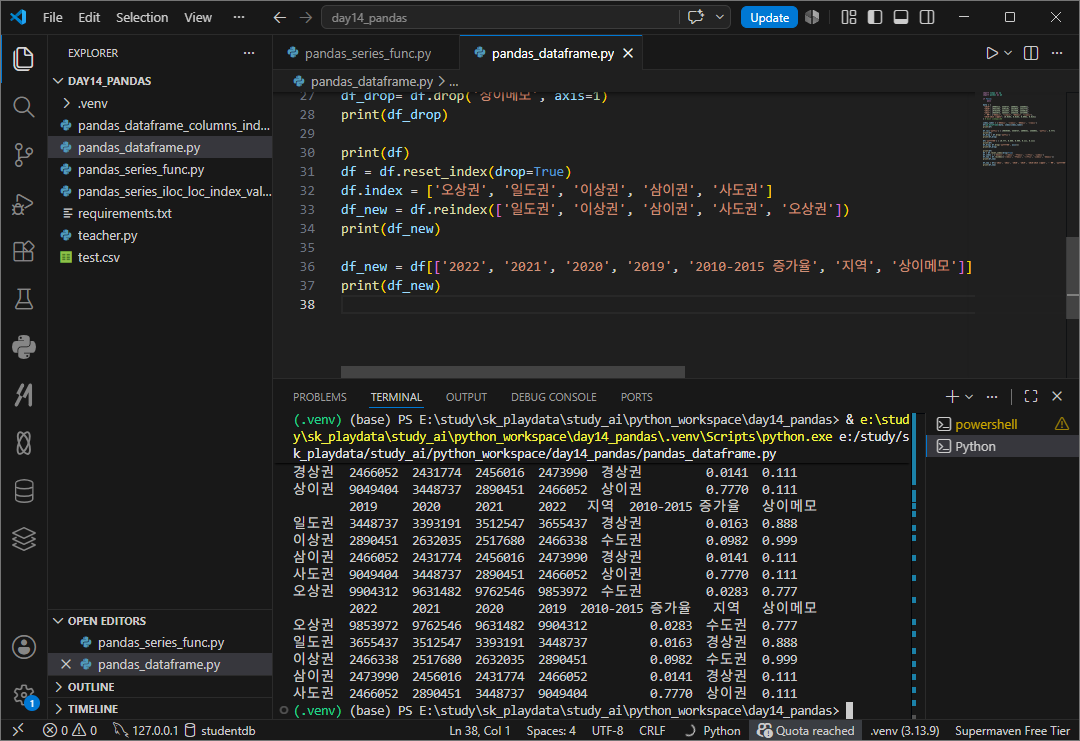
행 순서바꾸기
라벨이 중복값이 있으면 reindex할 수 없다.
reset_index 초기화
df.index = [] 재지정
df.reindex 행 위치 바꾸기

열 순서바꾸기
df[ [원하는 순서 쓰기] ]
df.transpose() 열과 행 위치 바꾸기

통계
평균값: 자료 전체를 대표하는 값, 중심경향치중 하나
중간값: 주어진 값을 크기순 정렬시 가장 중앙에 위치하는 값
최빈값: 가장 빈번히 관찰되는 값
최솟값
최댓값
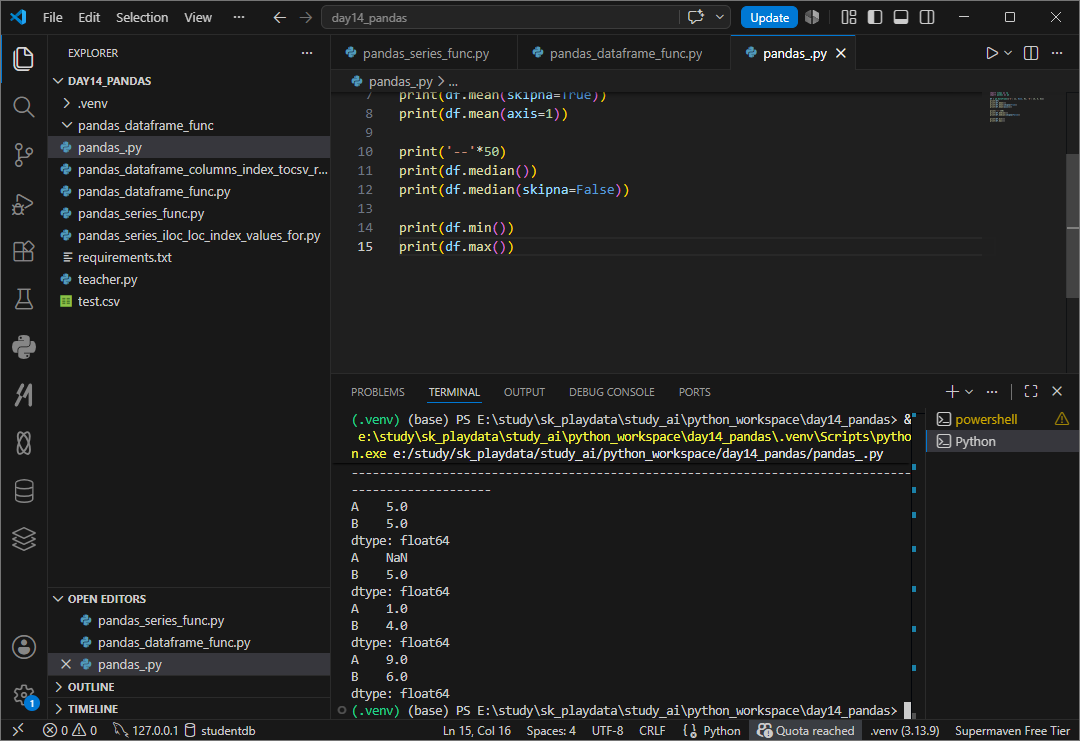
mean 평균값 구하기
mean(skipna = True) 열단위 평균값구하기
mean(axis = 1) 행단위 평균값 구하기

median()
median( skipna= false)
none값이 있을때 넘어갈것인가(기본값 true) 인식해 산술하지않을것인가

min최솟값
max 최댓값
표준편차: 평균을 중심으로 얼마나 퍼져있는지를 나타내는 대표적인 수치, 0에 가까우면 데이터가 평균 근처에 집중되어있음을 의미
분산: 값들이 흩어진 정도를 계산하는 지표, 평균과 차이를 제곱한것.
공분산: 두변수의 상관정도, 양수이면 두 변수가 같이 상승하는 경향을 보임
std() 표준편차
각 평균 - 값 뺀것들을 모두 더해서 명별로 나눔

분산 var
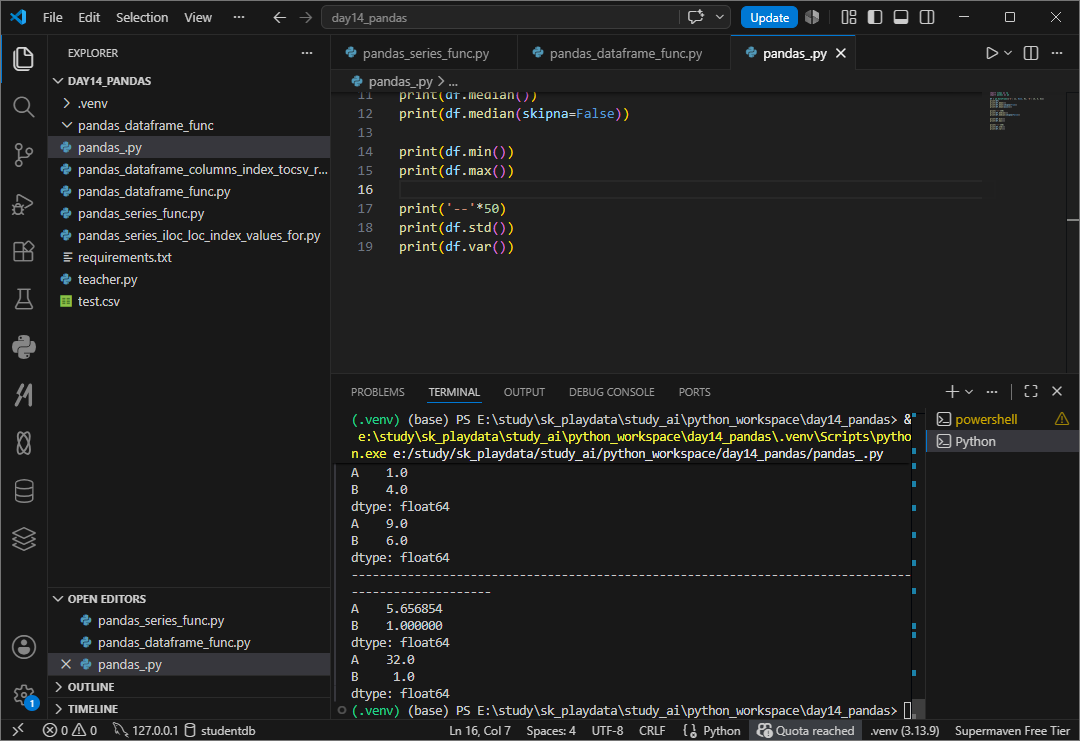
공분산 cov
0이면 관련없고 양수면 같이 상승한다.

상관계수: 연속형 열간의 연관성에 대한 측도. 두 변수간의 연관정도를 나타낼 뿐 인과관계를 나타내는 것은 아님. 종류에는 피어슨, 켄달, 스피어만이 있고 대표적으로 사용되는 상관계수는 피어슨임. -1 ~ 1 의 값을 가지고 양수일경우 양의 상관관계, 음수일경우 음의 상관관계.
- 피어슨: 선형적인 관계가 있는지 판단하는데 사용. 0에 가깝더라도 선형적인 관계가 낮을 뿐이지 서로 유의미한 관계를 갖지않는다는 말이 아님. -1에 가까울수록 음의 선형적인 상관관계를 가지고 1에 가까울수록 양의 선형적인 상관관계
- 스피어만: 다니조성을 평가하기 위해 사용 두연속 변수가 정규분포를 심각하게 벗어나거나 순위척도 자료일때 사용 두 변수의 값을 각각 제일 큰값을 1, 두번째 큰값을 2.. 변환후 변환된 값들 간의 피어슨 상관계수를 구함.
- 켄달: 두 변수간의 순위를 비교하여 연관성을 계산. 두 연속 변수가 정규분포를 심각하게 벗어나거나 순위척도 자료일때 사용. 단조성을 판단하기 위해 사용
상관계수, 두데이터가 얼마나 같이 움직이는가. corr(method = 'pearson')
1 -> 완전 비례
0 -> 관계 없음
-1 -> 완전 반비례

피어쓴은 실제 숫자값기준에서의 선형관계를 구했다.
'국어가 점수가 높으면 영어도 잘하는가?'의 직선관계를 잘 잡는다.
스피어만은 값자체보다 순위기준으로 몇등이고 순서가 같이 움직이는가? 국어에서 4순위면 영어도 4순윈가를 잘본다.
완전히 동일하면 1이 나온다.

켄달은 스피어만보다 엄격하다. 쌍마다 방향이 일치하는지를 본다.
스피어만은 전체적으로 순위 흐름으로 '국어랑 영어순위가 비슷한지'를 보지만
켄달은 '모든 학생들 쌍 관계로 국어랑 영어순위가 비슷한지'를 본다.
scipy Sci + Py = Scientific Python
pearson, spearman 일부는 pandas/numpy만으로 처리 가능하지만, kendall 사용시 내부적으로 scipy가 필요하다
pip install scipy
C:\Users\playdata2\AppData\Local\Programs\Python\Python311\python.exe -m pip install scipy

series 데이터 산술 연산하기
개별 원소의 숫자를 각각 계산한다.
객체 + 사칙연산 + 숫자

객체 + 사칙연산 + 객체
두 series 객체간 연산은 동일한 index끼리 연산을 수행한다.
이때 이 객체의 크기 또는 index가 일치하지않는 경우 연산이 불가하고 크기가 다른경우에는 작은 series에서 해당 결과값은 nan으로 나온다.

이때 add()함수를 사용하여 fill_value 속성을 0을 준다면 수행이 가능하다.

외 sub 뺄셈, mul 곱셈, div 나눗셈

dataframe도 같은방법으로 산술할 수 있다 .

https://standout.tistory.com/1731
seaborn 파이썬 데이터 시각화 라이브러리 (feat.matplotlib)
seaborn파이썬 데이터 시각화 라이브러리matplotlib를 더 예쁘고 쉽게 사용할 수 있다. https://seaborn.pydata.org/ seaborn: statistical data visualization — seaborn 0.13.2 documentationseaborn: statistical data visualizationseaborn.
standout.tistory.com
그룹연산
복잡한데이터를 특정기준을 적용하여 그룹별로 연산하다.
데이터 집계, 변환, 필터링에 효율적이다.
groupby 그룹핑
numeric_only= true 숫자만 계산

agg 함수, 사용자정의함수를 그룹객체에 여러개 적용해 집계 연산처리가 가능하다.
이때 mean, min 등과 같은 pandas가 이미 지원하는 내장함수하면 굳이 함수를 쓰지않고 명시한 해주어도 된다.
goup객체.agg(사용자정의함수)

key: list 형식으로 다중 그루핑도 가능하다.

함수매핑
series또는 dataframe의 개별원소를 특정 함수에 일대일로 대응시키는 과정.
개별원소 함수매핑 apply
산술시 '형'이 맞지않으면 에러나믕로 주의 . 컬럼을 중심으로 함수를 대입함 fate 승선요금에서 -10 해 표시함.
+ lambda식도지원함

개별 원소 함수매핑
applymap() 매핑함수에 dataframe의 모든 ㅜ언소를 하나씩 입ㄺ해 반환값을 돌려받음
applymap → deprecated(사라짐/비권장)된다. 또 현재는 map이 권장된다.
pandas 버전에 따라 에러로 뱉어낼 수있음

appy시 축을 지정할 수 있따.
axis = 0 열
axis = 1 행

pipe()
결국은 apply agg map pipe 모두 함수호출이다. 차이가 있다면 map은 series레벨, apply는 series, dataframe레벨, agg는 집계요약통계 전용, pipe는 df 자체를 통째로 넘겨 입출력의 구조(dataframe)이 유지되며 함수의 흐름을 정리한다.

누락데이터
데이터품질에 좌우되기때문에 제거하거나 다른 값으로 대체해야한다.
info()로 확인

유일한 값별 갯수를 구할 수 있는 value_counts()
각 행이 전체에서 얼마나 잘 나오는지 비율로 계산할 수 있다 .
normalize=True 개수 → 비율
sort=False 정렬 안 함
dropna=True NaN 제외

value_counts()
컬럼별도 가능

fillna() 함수
NaN 을 원하는 값으로 바꿀 때 사용
print(df3)
print(df3.apply(lambda x: x.value_counts(), axis=0).fillna(0.0).astype(int))

fillna를 활용해 null값을 평균값으로 대체해 데이터를 보완할 수 도 있을것이다.

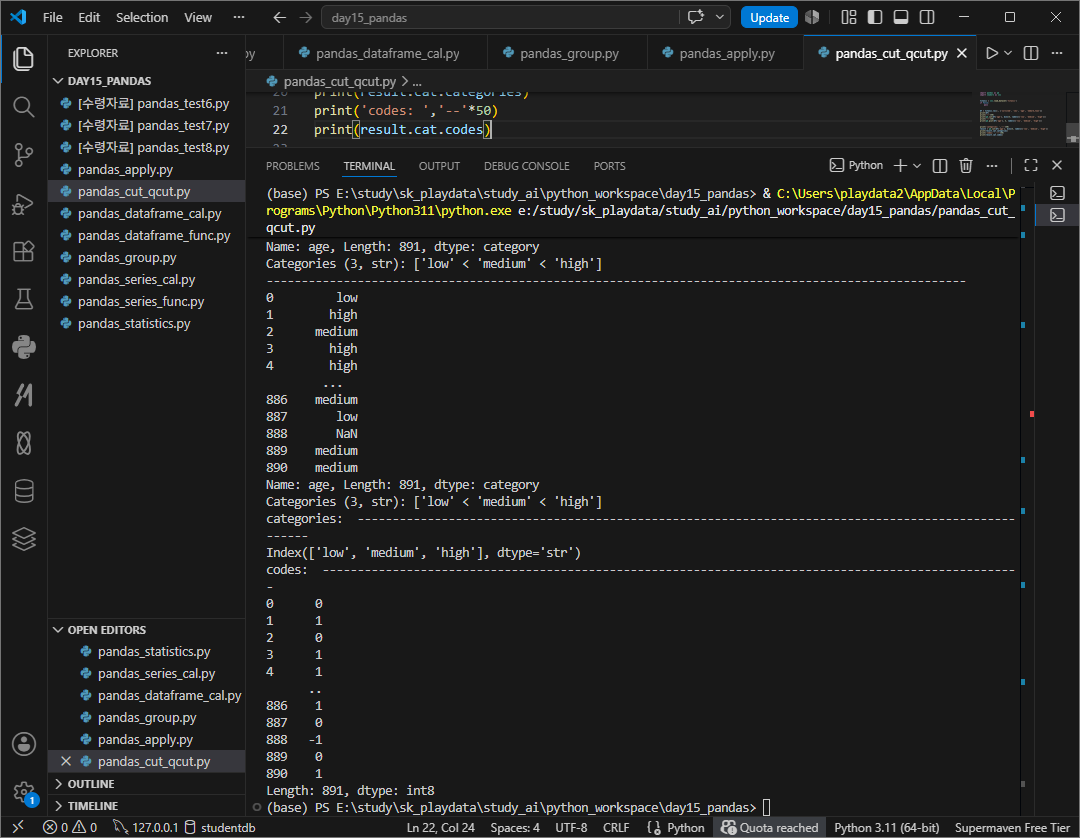
cut() 함수 : 실수값을 경계선으로 지정하는 경우에 사용 (분류)
age 값을 low / medium / high 범위로 자동 분류한 것

cut은 나이 범위를 균등하게 3등분해서 low, medium, high를 보인다면
qcut은 전체 사람을 3등분해서 low, medium, high를 본다.

cut, qcut은 단순한 문자열이 아니라 Categorical 타입니다.
문자열처럼 보이지만 내부적으론 category 자료형이란건데 category의 종류엔 low, medium, hight의 종류가 있고
순서가 존재한다. 또 code는 내부 저장방식이다.
사용자에게 low, medium, high 라고 알리지만 실제론 code형식으로 저장된다.
메모리 절약이 되고 정렬이 가능하고 속도가 빠르기 때문이다. nan은 catrgory에는 값이 없어 -1이 된다 .
isnull + sum 함수를 융합하여 누락데이터 개수를 확인 할 수 도 있다 .
cut, qcut은 단순한 문자열이 아니라 Categorical 타입니다. 문자열처럼 보이지만 내부적으론 category 자료형이란건데 category의 종류엔 low, medium, hight의 종류가 있고 순서가 존재한다. 또 code는 내부 저장방식이다. 사용자에게 low, medium, high 라고 알리지만 실제론 code형식으로 저장된다. 메모리 절약이 되고 정렬이 가능하고 속도가 빠르기 때문이다. nan은 catrgory에는 값이 없어 -1이 된다 .

dropna(subset = ['컬럼명' '원하는행 또는 열 값'])
null값을 확인해보니 유독 age와 deck 정보에 null이 너무 많아 해당 열또는 행을 삭제해야 데이터가 정확해질것이라고 판단된다면 dropna.

dropna()
만일 null자체를 허용하고싶지않아 모두 지워버린다면?
매개변수없게~

ffill() bfill()
embark_town에도 누락데이터가있다.
이때 '승선도시'가 저장된 embark_town은 이웃하는 데이터끼리 유사성을 가질 확률이 높다.
id 1, 2, 3, 4, 5중 3이 '서울'이 누락됬을때 1, 2, 4, 5 가 서울이면 서울일 가능성이 높지않을까~ 하는 판단을 해보자.
원래 fillna의 method로 실행됬엇다. F는 앞 데이터로, b는 뒤 데이터로.
지금은 update되서 단독함수처럼 ffill(), bfill()를 쓰면된다.

duplicated()
중복된 행이 있는지 점검 할 수 있다.
특정 열을 검색하고 싶다면 duplicated(['컬럼명'])
특정 열을 검색하고 첫번째값은 false, 두번째는 true하고싶다면 first,
첫번쨰값을 true, 두번쨰부터 false하고싶다면 last
다 살리고 싶다면 False
duplicated(['컬럼명'], first)

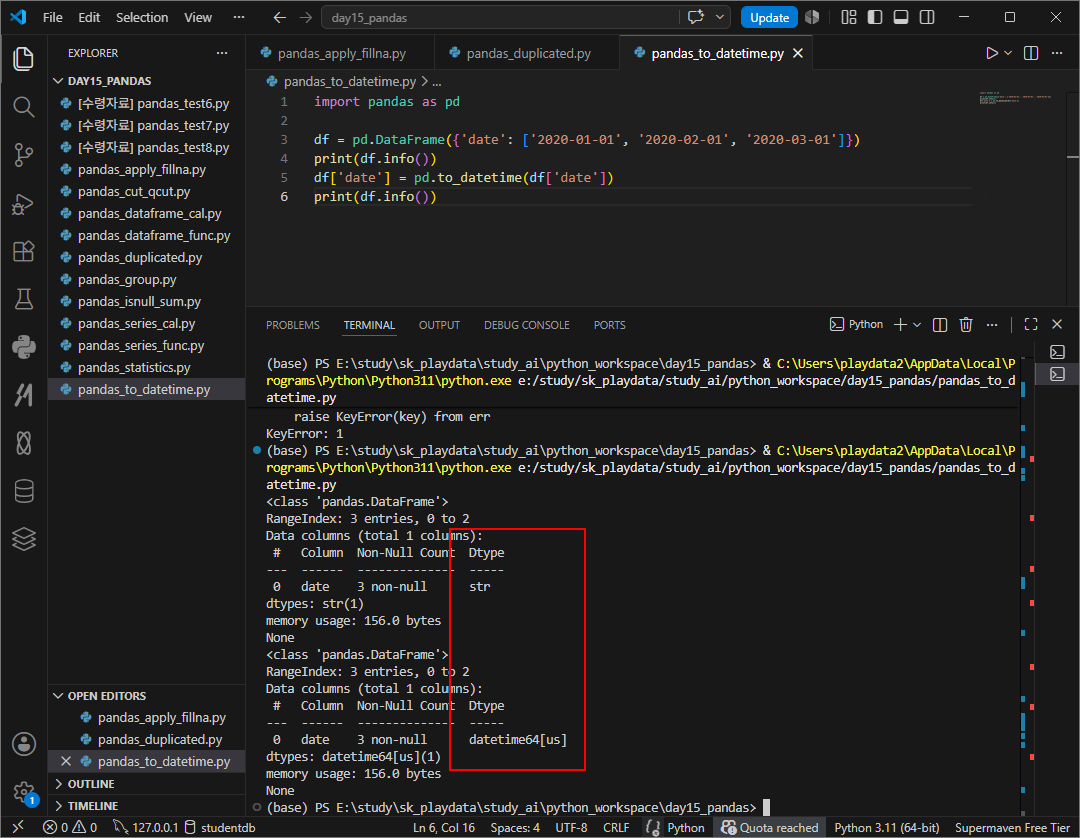
to_datetime
날짜 형식의 문자열을 datetime으로 변환
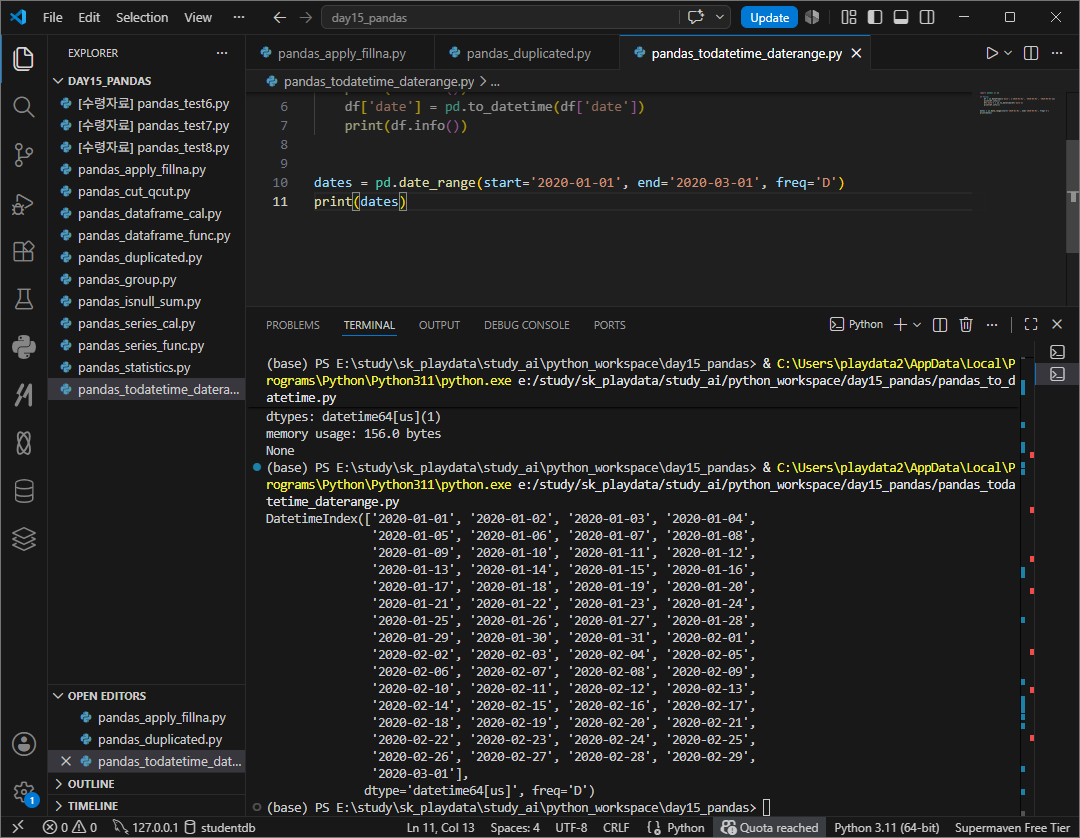
date_range
일정간격으로 시간 데이터를 생성
freq 시간간격설정: D일별 w주별 ms 월별시작일 m 월별말일 h시간별 t분멸 s초별
tz 시간대 설정
period_range
일정한 간격으로 시간데이터를 생성
periods 기간의 수를 지정
이때 periods를 쓸땐 end를 쓰면 기간에 맞춰 출력하다가 수가 안맞을 수 있지않은가?
즉 start end period는 함께할 수 없다.

matplotlib를 보자.
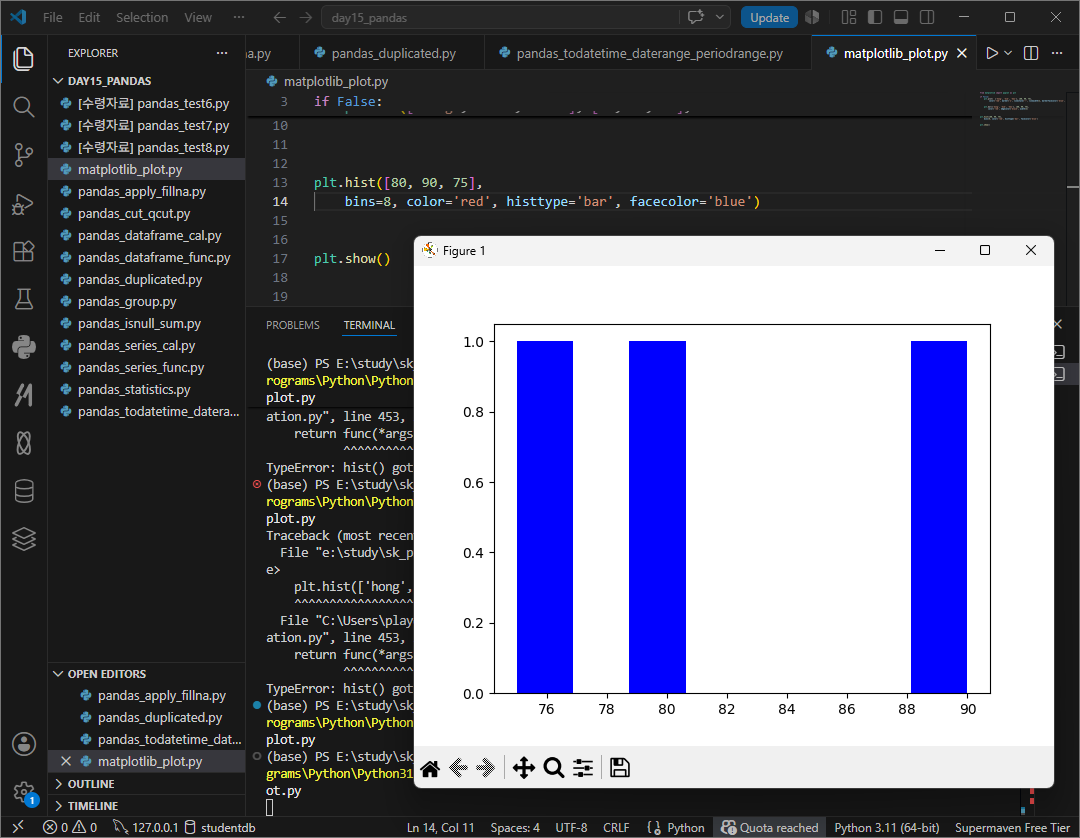
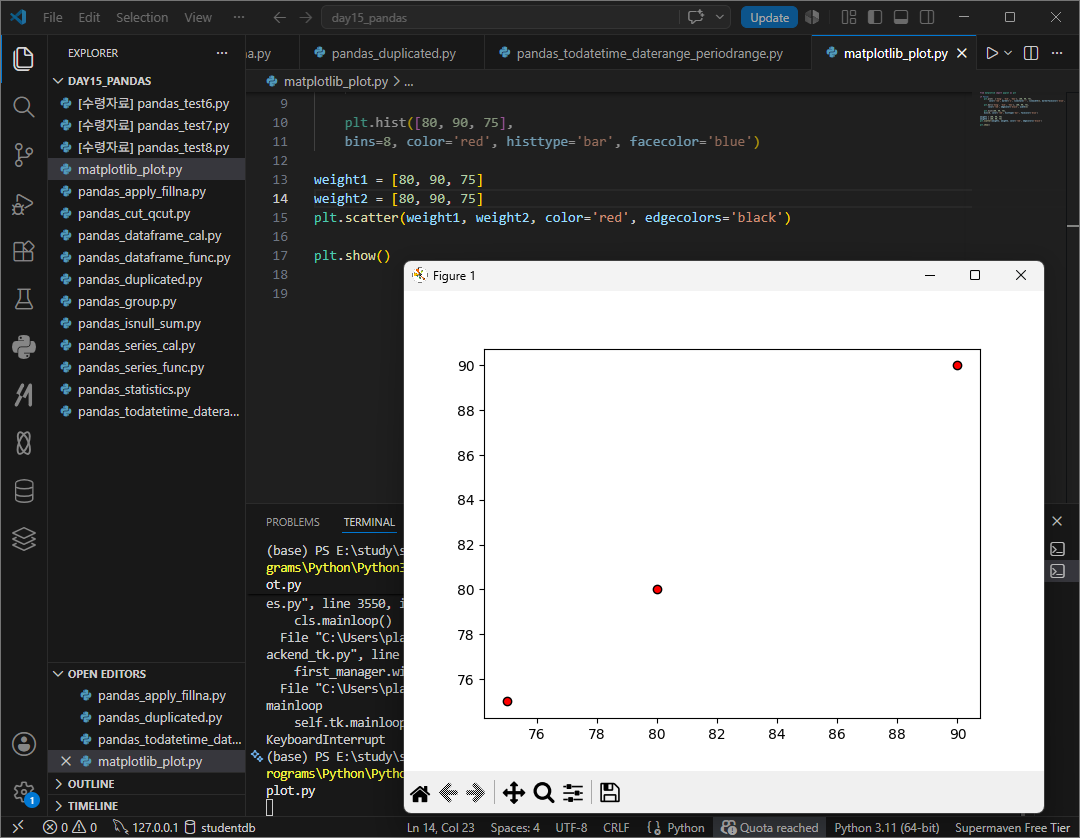
pyplot.plot(x축값, y축값, color, linestyle, marker, markerfacecolor, markersize, linewidth)
앞서 우리는 seaborn과 다르게 matplotlib는 하나하나 디자인을 지정해 주어야한다고 했었다.

외 막대그래프는 bar,

히스토그램은 hist
선점도 그래프는 scatter
# 인터넷 상의 데이터베이스 자료 읽어오기
# 추가 설치 필요 : pandas-datareader (임포트시 모듈명 : pandas_datareader)
# 데이터베이스 자료 제공하는 사이트 확인 필요함 (유료 사이트 주의)
https://pandas-datareader.readthedocs.io/en/latest/
'SK 네트웍스 AI 캠프' 카테고리의 다른 글
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day16_데이터 시각화 (0) | 2026.05.26 |
|---|---|
| [SK네트웍스 Family AI 캠프] 32기 4주차 회고: Day13 ~ Day15 (0) | 2026.05.22 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day14_데이터 전처리 (0) | 2026.05.21 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day13_데이터 분석 개념 및 라이브러리 (0) | 2026.05.21 |
| [SK네트웍스 Family AI 캠프] 32기 3주차 회고: Day8 ~ Day12 (0) | 2026.05.16 |



