dtype은 배열에서의 저장되는 값의 종류, type은 객체의 타입

접두사로도 dtype을 지정할 수 있다.
f float
U 유니코드문

None 없다 .
NaN 숫자가 아니다.
inf, nan 무한대와, 숫자가 아닌
numpy에서 무한대를 표현하기 위해 infinity, not a number의 줄임말
1을 0으로 나누는 경우, 0에 대한 로그값등의 결과가 np.inf로 표시, 0을 0으로 나누는 경우 np.nan이 표시됨
e를 무한대로 작은 수만큼 제곱하는 등의 계산은 0에 가까워지는 결과를 낳는다.
np.inf 무한대
-np.inf -무한대
exp(x) 자연상수 e를 x제곱
log(x) e를 몇번 곱해야 x가 되는지

dot()
행렬 * 백터
각 행과 벡터를 곱해서 더하기
첫번째행에 1, 2, 3 이 있다. 벡터라 10, 20, 30이니 같은 위치끼리 곱하면 10, 40, 90 더하면 140
두번째는 320, 세번째는 500.
https://standout.tistory.com/1727
np.dot()에서 왜 1차원배열이 세로벡터처럼 계산될까?
여기서 x는 1차원배열이었는데 np.dor하는순간 왜 세로벡터처럼 계산될까? 행렬곱의 규칙 때문이다. 이를 수학에서는 엄격히 구분하지만 NumPy의 1차원 배열은 방향이 없는 벡터이고, dot 연산 시 자
standout.tistory.com
: = all
A[행, 열]임으로 A[:, 0]의 의미는 모든 all 행에서 0열만 가져오기라고 해석한다.
dot()시 numpy가 자동으로 '알아서' 배치해 계산하기 때문에 안전히 직접 열을 행벡터로 바꾸어 계산할 수 도 있다.

i8 8바이트 정수형 int64
(3, 4) 3행 4열 표를
(2, 3, 4) 2개
ones() 1로 채워 만든다.

u4 유니코드 문자열 최대 4글자 저장한다.
zeros_like()
ones_like()
기존 배열의 shape과 dtype를 유지한채 0 또는 1로 채운다.
zero의 경우, 문자열일경우 공란 '' 으로 띄워진다. ones도 마찬가지로 '1' 문자열로 return하고 있다.

숫자 사이의 차이가 일정하느냐, 숫자 사이의 비율이 일정하느냐
linespace() 시작 끝 사이를 일정한 간격으로 숫자생성, 0부터 100까지를 5구간으로 나눈값 = 덧셈간격이 일정한 배열
logspace() 10배, 100배 같은 로그 증가로 숫자생성, 10의 0.1제곱(1.26), 10의 1제곱(10)까지를 10개로 나눈값 = 몇배씩 커지는 간격이 일정한 배열
linespace와 logspace는 숫자범위를 자동생성하는 용도로 쓰이며,
linespace는 그래프, 좌표, 데이터 샘플링, 이미지 처리 등 일정간격으로 데이터를 보고싶을때 쓰며 일정 간격으로 눈금긋기같은 느낌의 작업이 가능하다.
logspcae()는 엄청 작은값 ~ 엄청 큰 값을 다룰때 쓰는데, 과학, 주파수 분석, 머신러닝, 전자공학, 로그 그래프 등 주파수를 배수 단위로 잘라 보거나 학습률을 10배씩 줄여가며 실험하거나등의 규모 차이를 비교하는 등의 작업이 가능하다.
크기가 다른 행렬의 곱셈시 * 는 에러가 난다.
*는 같은 위치끼리 곱하기 때문이다.

이때 dot으로 계산을 할 수 있으나 앞행렬의 열(가로)수와 뒤 행렬의 행(세로)수가 같아야한다.
이를 @로도 표현한다.
c는
987
654
라면
A는
123
456
789
(2, 3) * (3, 3) 인데 가운데숫자가 같으면 산수가 가능하다는 것이다. (2*3)으로 C의 행 * A의 열이 계산된다.
(9, 8, 7) * (1, 4, 7)이 된다. 즉 앞이 열이 3개, 뒤의 행이 3개 이런식으로 수가 같으면 계산이 된다는것.

https://standout.tistory.com/1728
numpy dot() @, (A*B) * (C*D) 가운데 있는 숫자 B와 C가 같으면 계산이 된다 : 왜 크기가 다른 행렬의 곱
왜 이렇게 계산할까?이는 행렬이 왜 존재하느냐와 연결된다.행렬은 '변환'을 표현하기 위해 만들어졌다.단순한 숫자놀이가 아닌 여러계산을 한번에 처리하기 위한 방식이다.백터가 숫자의 묶음
standout.tistory.com
all() 전부다 True인가

스칼라와 벡터의 곱셈시 브로드캐스팅되어 산수된다.
https://standout.tistory.com/1729
NumPy Broadcasting 브로드캐스팅 (feat.네트워크에서의 Broadcasting)
브로드캐스팅네트워크에서의 브로드캐스팅과 여기서의 브로드캐스팅이 다르다. 브로드캐스팅이 '하나를 여러 대상에게 퍼뜨린다'라는 느낌이 있다면네트워크의 브로드캐스팅은 한 장비가 같
standout.tistory.com
linalg linear algrbra = 선형대수 = NumPy안에 있는 행렬 계산 도구모음
linalg.solve
선형 연립방적식
여러 미지수를 가진 방정식을 동시에 푸는것.
x + y = 5
2x + y = 8
이 두식을 동시에 만족하는 x, y를 찾는다는 의미.
실제로 찾기위해 둘쨰식 - 첫째식을해 x값을 찾고 이후 y값을 찾을 수 있다 .
이를 NumPy에서 한다면?
np.linalg.inv()
solve와 똑같지만 inv는 공식자체를 전부 계산한다고 생각하면 된다. 역행렬 전체를 계산해서 느리고 오차도 생긴다.
NumPy 공식느낌도 연립방정식은 답만 바로 구해버리는 slove를 쓰라고 권장함.
연립방정식에서 중요한것은 '식이 서로 독립적인가'이다. 두식이 서로 다른 정보를 주어 x y 를 정확히 구할 수 있는가인데
식이 같아버리면 (혹은 A식에 2를 곱한것마냥 B식이 정보가없다면) 새로운 정보가 아니다. 식이 두개같아보이는데, 실제로는 같은 식이다 보니 정확한 하나의 답을 결정에 불가능이라 판단되는 것이다. 이때 det이 0 이된다.
이과정을 역행렬이라한다.
np.linalg.det()
역행렬, 원래대로 돌리는 것.
무언가를 확대했다면 축소하는 연산으로 이 연립방정식을 풀 수 있는가? 를 확인하는 용도로 많이 쓰인다.
0이 아니면 역행렬이 존해하고 solve가 가능하며 해가 하나로 결정된다고 볼 수 있다.

A = np.array([
[2, 1], [1, 3]
])
B = np.array([7000, 9000])
result1 = np.linalg.solve(A, B)
result2 = np.linalg.inv(A) @ B
print(np.linalg.det(A))
print(result1)
print(result2)
hstack horizontal stack 가로로 붙이기
ar1이
[
[1 1 1]
[1 1 1]
]ar2가
[
[0 0 0]
[0 0 0]
]라면
그대로 가로로 붙인것과같이 반환된다.
[
[1 1 1] [0 0 0]
[1 1 1] [0 0 0]
]이런느낌.. 즉
[111000],[111000]
vstack vertical stack 세로로 붙이기
ar1이
[
[1 1 1]
[1 1 1]
]ar2가
[
[0 0 0]
[0 0 0]
]라면 위아래로 붙인듯 반환된다.
또 위아래로 붙인바람에 행이 늘어났다는점이 추가로 다름을 인식해보자.
[1 1 1]
[1 1 1]
[0 0 0]
[0 0 0]
dstack depth stack 깊이방향으로 붙이기
ar1이
[
[1 1 1]
[1 1 1]
]ar2가
[
[0 0 0]
[0 0 0]
]라면 같은 위치끼리 한세트로 묶는다고 생각해보자.
[
[ [1 0] [1 0] [1 0] ]
[ [1 0] [1 0] [1 0] ]
]
-r row방향으로 붙이기 1차원이라면 이어 붙이고 2차원에서는 행이 추가된다.
c_ hstack과 비슷해보이지만 colum 방향연결이다.

stack
새 axis 축을 어디에 끼워넣는냐 조건이 붙는다는게 다른점
axis 0 배열 자세를 쌓음, 1일경우 row를 기준으로, 2일경우 원소를 기준으로 쌓

위
hstack vstack dstack
r_ c_
stack
은 비슷해보이고 뭔가 연관되어보이지만,
stack은 무조건 새로운 축을 추가하고
hstack vstack dstack은 축 기준으로 붙이기 concatenate
r_ c_는 row col 방향으로 단순히 이어 붙인다는 점에서 정의가 조금씩 다르다.
물론 stack(axis=2)과 dstack은 완전히 같은 개념이긴하다. 거의 동일함.
tile() 배열을 지정한 횟수만큼 복사해 연결

meshgrid() 좌표생성하기 위한 계산용 매트릭스
그래프를 그리거나 표를 작성하려면 2차원 영역에 대한 그리드포인트가 필요하다.
arange() 일정간격으로 숫자배열을 만드는 함수
(0,0) (1,0) (2,0) (3,0) (4,0)
(0,1) (1,1) (2,1) (3,1) (4,1)
(0,2) (1,2) (2,2) (3,2) (4,2)
2x = 10이라면 우리는 x=10 / 2를 하겠지만
행렬에는 나누기가 없음으로 역행렬을 사용하는데
A⁻¹ · (A · x) = A⁻¹ · b 양쪽에 -행렬을 곱해버려서 x를 구하는 것이다.
A⁻¹ = “A를 되돌리는 행렬”
b를 A⁻¹이라는 “되돌리기 연산”에 넣는 것
solve = inv + dot
사실상 위에 배열 A와 b는 4x + 3y = 23, 3x + 2y = 16와 같다.
이것을 행렬로 쓰면 A - x = b
a*x=b 를 직접푸는 알고리즘 solve로는 바로 풀렸지만 inv 와 dot을 이용하여 선형방정식을 풀어봤다.
연립방정식은 항상 이렇게 생긴다. A - x = b 그리고 우리는 x를 구하고 싶다.
x = np.dot(np.linalg.inv(A), b)
invA = np.linalg.inv(A) x= np.dot(invA, b)
위 두개의 식은 같다.
dot은 앞서 곱한다고 했다. inv는 역행렬을계산한 뒤에 b와 행렬곱 dot를 진행한다. 휴...이해하기 너무 어렵다 아득바득 이래저래 이해해봤다 담엔 좀더 나아지길 바란다.

allclose 해가 올바른지 확인한다.

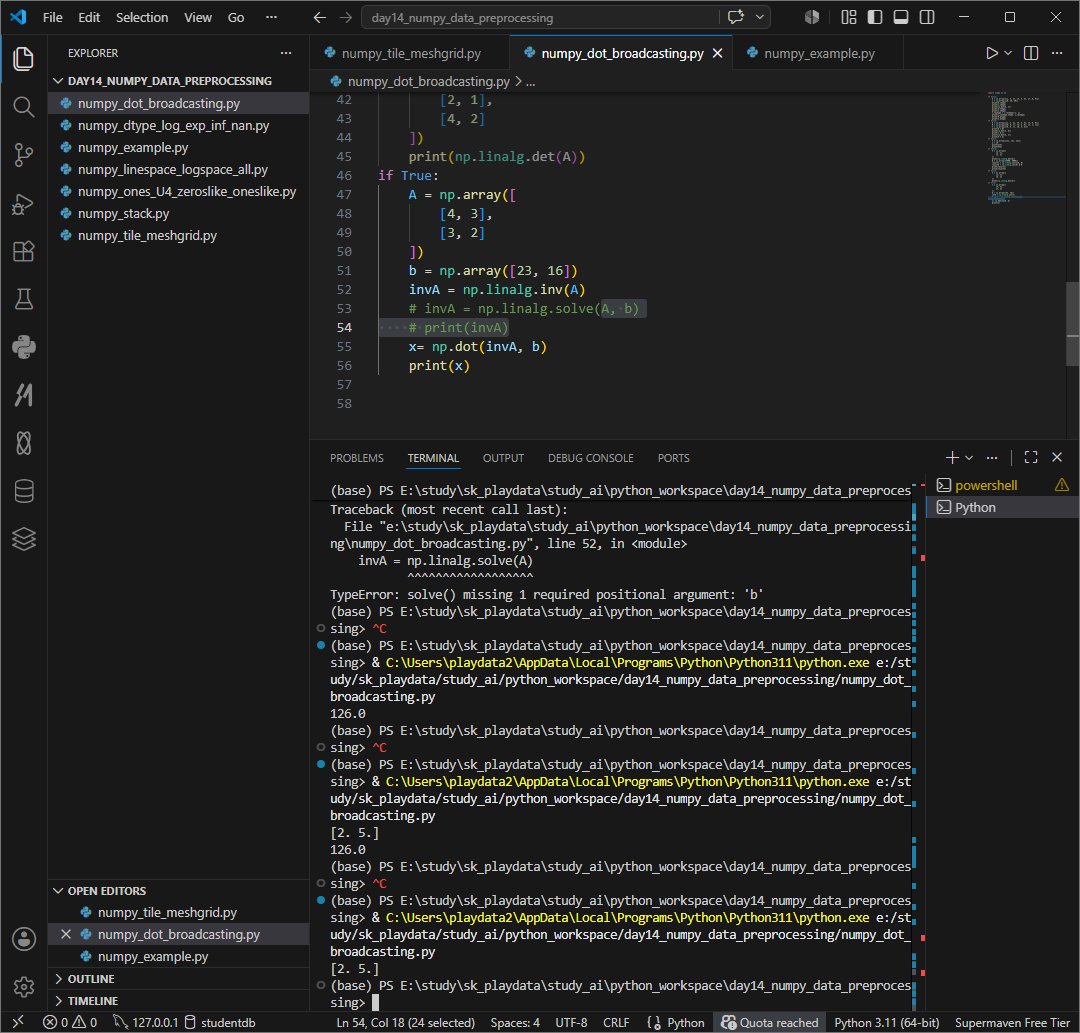
lstsq least squares 최소제곱 해
위는 선형방정식의 개수와 미지수의 개수가 같았다.
그런데 선형방정식의 개수와 미지수의 개수가 다르면 어떻게 할까?
미지수는 3개인데 식은 2개일경우 해가 딱 하나로 정확히 정해지지않는 구조가된다.
이럴때는 정확히 못맞출바에 가장 가까운 해를 찾는다.
이때의 allclose는 a.x가 b와 '거의같은지'를 확인 할 수 있다.
이는 근사값으로 False일경우 오차가 크다 라고 인지하면 되겠다.

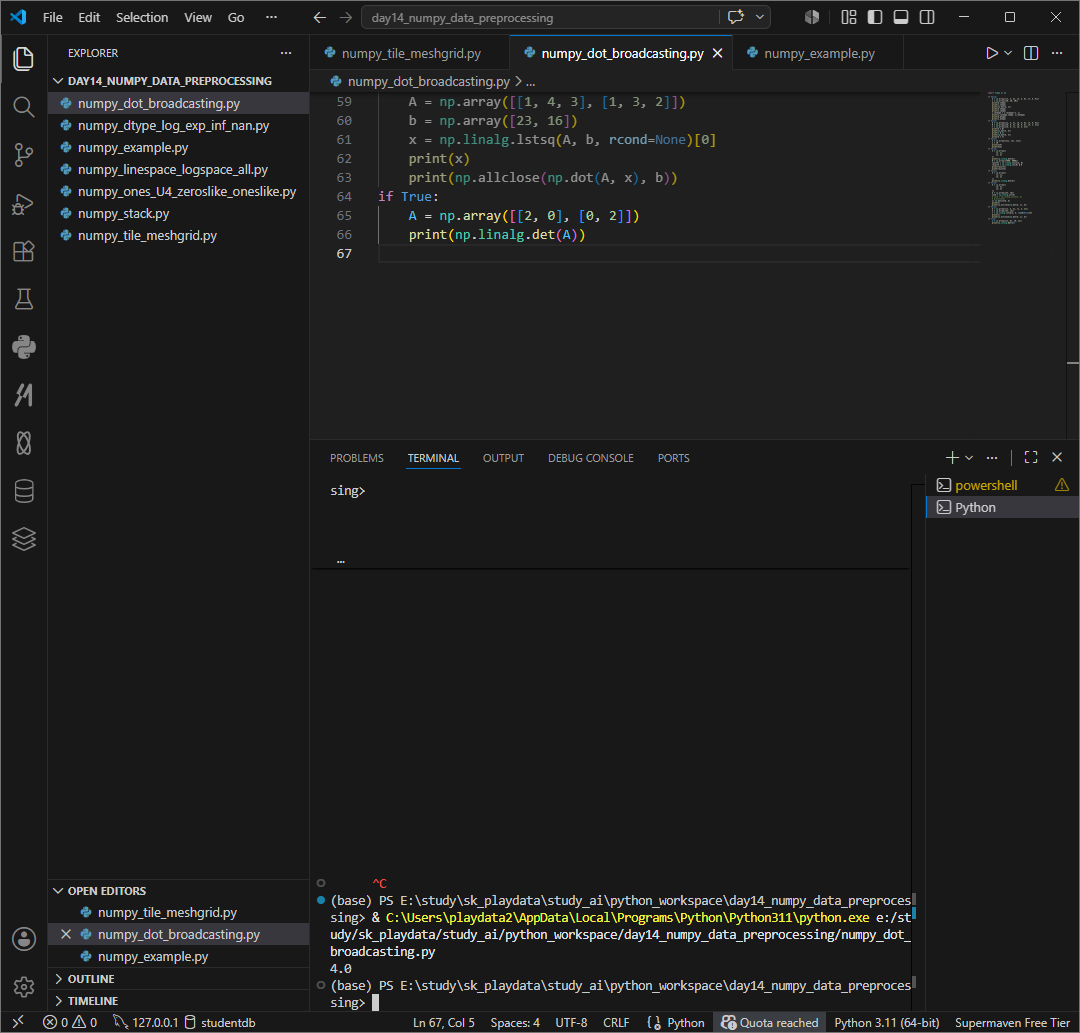
det 행렬식 구하기 determinant
면적이 얼마나 변하는가에 따른 의미가 있다. 점이동이 아니라 도형전체가 얼마나 늘어났는지에 비율이다.
0보다 작다면 공간이 뒤집혔다는것. 0보다 크다면 방향이 유지된다는 뜻이다.
0일경우 역행렬이 없고 0이 아닐경우 역행렬이 존재한다는 의미.
아래의 예시를 봐보자. 2,0 에서 0,2가 됬다면 x축이 2에서 0으로, y축이 0 에서 2로 2*2면적이 4배가 확대되었다는 의미
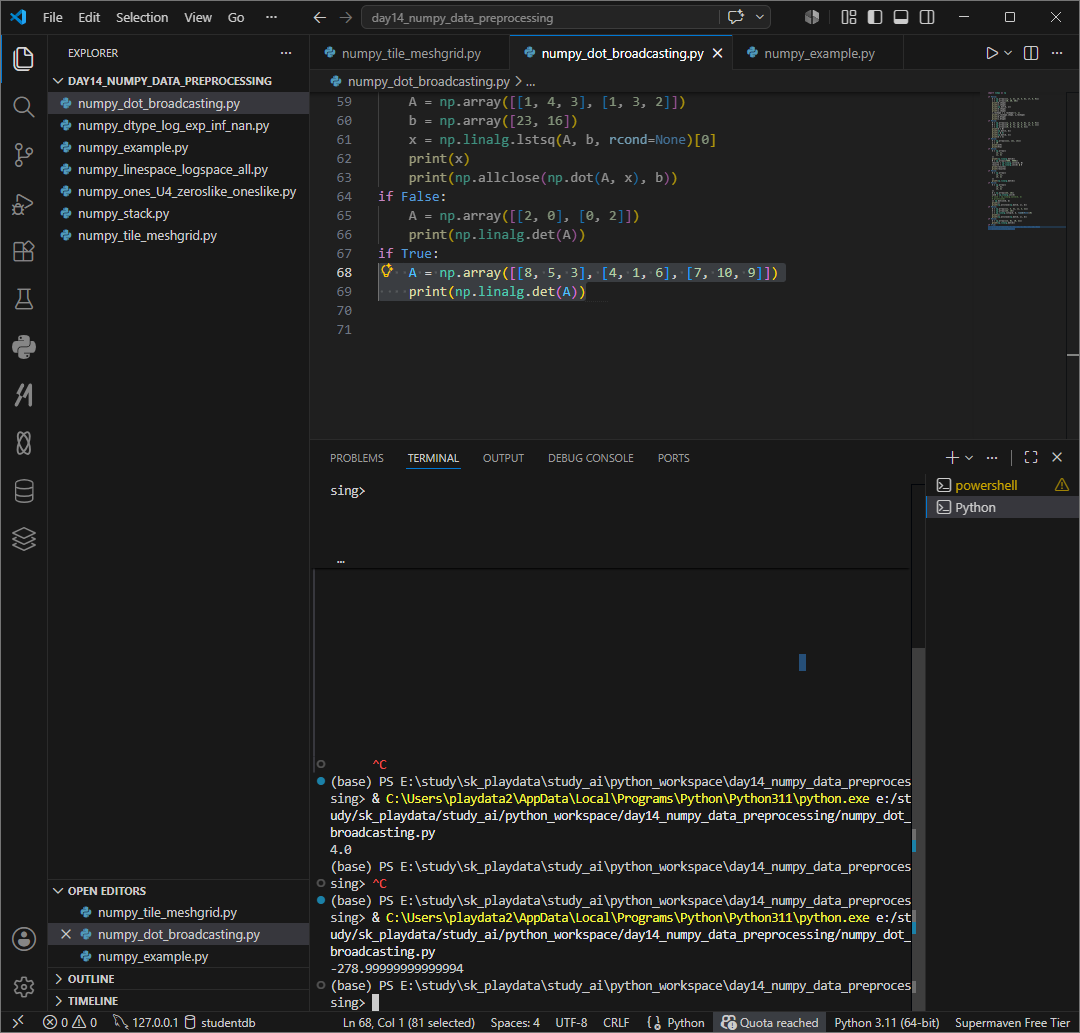
3차 정사각행렬
행렬식은 한 행을 기준으로 2*2 det 3개를 합친것으로 이해해보자.
A = [[8, 5, 3],
[4, 1, 6],
[7,10, 9]]8기준으로는 1열이 제거되며
[[1, 6],
[10, 9]]1×9 - 6×10 = 9 - 60 = -51
5기준으로 하면 2열이 제거되며
[[4, 6],
[7, 9]]4×9 - 6×7 = 36 - 42 = -63기준으로 하면 3열이 제거되며
[[4, 1],
[7,10]]4×10 - 1×7 = 40 - 7 = 33
부호규칙을 적용하면
det =
8×(-51)
- 5×(-6)
+ 3×(33)-408 + 30 + 99 = -279첫줄 문자 * 그 위치를 제외한 2*2 det들의 합으로 이해하면된다 .
2x2 det는 면적이라면 3x3 det는 부피이다. det은 공간이 얼마나 찌그러지거나 늘어나는지를 본다.
= 이 행렬이 3차원 공간에서 부피를 약 279배로 변형시키되 방향이 뒤집혔다. = 1*1*1 정육면체가 이변환을 거치면 부피가 279배가 된다.
0 공간이 눌려 2d 1d 로 붕괴
양수 방향유지
음수 방향 뒤집힘
등수표시계를 만들어보자.
각 학생의 점수에서 argsort(), 값을 기준으로 오름차순으로 정렬한뒤 그 값들의 원래 위치를 반환한다.
[9 8 7 6 5 3 2 1 0 4]
[4 0 1 2 3 5 6 7 8 9] = 1등은 4번째에, 2등은 0번째에 있다....
argsort()[::-1] 그 배열을 뒤집어 1등부터 나열한다.
np.empty_like(score) 그 score의 배열 수만큼이 빈 배열 rank를 만들고
np.arange(1, 11) -> [1,2,3,4,5,6,7,8,9,10] 1등 ~ 10등 번호표를 만들어
rank의 아까만들어놓은 빈 배열에 desc_index [4 0 1 2 3 5 6 7 8 9] 즉 rank[4]번쨰칸에 등수를 넣겠다~
[2,3,4,5,1,6,7,8,9,10]

워낙 헷갈렸으니 다시 정리해보자.
inv 되돌리기 역행렬 = A를 되돌리는 행렬, x를 구하고 싶을때 변환을 취소하는 도구
dot 행렬곱= 행렬끼리 곱하기 = 좌표변환, 벡터계산, 신경망계산, 선형대수 기본연산 = 곱셈엔진
solve 연립방정식 풀기 = 연립방정식 바로풀기 inv보다 더 추천됨
lstsq 방정식 가장 비슷하게 풀기 = 식이 부족하거나 데이터분석, 회귀분석, ai ml에 사용 = 근사정답찾기
det 행렬성질확인 = 행렬이 공간을 얼마나 늘리거나 줄이고 뒤집는지 확인
inv 되돌리기 역행렬 = A를 되돌리는 행렬, x를 구하고 싶을때 변환을 취소하는 도구
import numpy as np
A = np.array([[4, -2],
[2, 3]])
b = np.array([6, 7])
A_inv = np.linalg.inv(A)
x = np.dot(A_inv, b)
print(x)4x-2y=6
2x+3y=7를 만족하는 해
x=2, y=1
[2. 1.]
dot 행렬곱= 행렬끼리 곱하기 = 좌표변환, 벡터계산, 신경망계산, 선형대수 기본연산 = 곱셈엔진
import numpy as np
A = np.array([[1, 2],
[3, 4]])
x = np.array([10, 20])
print(np.dot(A, x))[50 110]백터 x를 행렬 A로 변환한 결과
1×10 + 2×20 = 50
3×10 + 4×20 = 110
solve 연립방정식 풀기 = 연립방정식 바로풀기 inv보다 더 추천됨
import numpy as np
A = np.array([[2, 1],
[1, 3]])
b = np.array([8, 13])
x = np.linalg.solve(A, b)
print(x)[2.2 3.6]2(2.2)+3.6 = 8
2.2+3(3.6)=13
x=2.2
y=3.6를 의미한다.
lstsq 방정식 가장 비슷하게 풀기 = 식이 부족하거나 데이터분석, 회귀분석, ai ml에 사용 = 근사정답찾기
import numpy as np
A = np.array([[1, 1],
[1, 2],
[1, 3]])
b = np.array([2, 2.5, 3.5])
x = np.linalg.lstsq(A, b, rcond=None)[0]
print(x)[1.16666667 0.75]절편(직선이 시작하는 y의 위치 = x가 0 일때 y의 값)과 기울기, 데이터 점들을 가장 잘 설명하는 직선을 찾는것.
데이터를 가장 잘 설명하는 직선, y = 1.166 + 0.75x
det 행렬성질확인 = 행렬이 공간을 얼마나 늘리거나 줄이고 뒤집는지 확인
import numpy as np
A = np.array([[2, 0],
[0, 2]])
print(np.linalg.det(A))4.02차원 면적을 4배 확대했다는 의미
고생했다 수포자
pandas에 대해 배워보자.
pip install numpy
pip install pandas
pip install matplotlib
pandas와 series
pandas는 데이터 분석을 위한 Series와 DataFrame을 준비하기 위해 사용하는 모듈
Series는 1차원 리스트 혹은 배열에 인덱스로 라벨을 추가지정한것. 생성시 인덱스 라벨을 생략할 수 있고 생략시 0으로 시작한다.

pandas에서는 series와 dataframe 이 가장 중요한 두개다.
series는 한줄 1차원 세로한줄, dataframe은 2차원으로 엑셀표와 같다.
series는 index와 value,
dataframe은 index와 label, data가 되겠다 .
Dataframe 안에 series가 여러개 들어있다고 보면된다.
dataframe 2차원 배열만들기, 행렬 매트릭스
dict 자료형에 컬럼 나열순서를 재배치하려할때 dataframe을 이용할 수 있다. 칼럼라벨을 준비해 표형태로
pd.DataFrame(data, columns=columns, index=index) columns 라벨을 생략하면 사전구성대로 프레임이 구성된다.


data = {
'2022': [12350000, 5430000, 3440000, 2800000],
'2023': [12351000, 5431000, 3441000, 2810000],
'2024': [12352000, 5432000, 3442000, 2820000],
'2025': [12353000, 5433000, 3443000, 2830000],
'지역 ': ['서울', '부산', '인천', '대구'],
'2015~2019 증가율': [0.0283, 0.0163, 0.0982, 0.0141]
}
print(pd.DataFrame(data))
columns = ['지역', '2022', '2023', '2024', '2025', '2015~2019 증가율']
index = ['서울', '부산', '인천', '대구']
df = pd.DataFrame(data, columns=columns, index=index)
print(df)
dataframe 생성시 행과 열 인덱스 라벨 모두 생략할 수 있다.

dataframe 은 데이터 파일 입풀력 기능을 제공한다.


반대로 파일을 읽어와서 DataFrame에 저장
이때 csv 파일에 첫문자 , 때문에 unnamed가 나오게된다.
index_col를 정해주면 첫번째 컬럼을 index로 사용하면서 해결됨

Series 클래스
s.index 인덱스 라벨 확인
s.values data확인

s.name 타이틀
s.index.name 라벨 이름 을 지정할 수 있다

Series에서의 연산은 data 즉 values에만 연산이 허용된다.

Series도 인덱싱이 가능하다.
iloc integer location, 숫자 위치기반 접근
loc location 위치접근
라벨으로 접근

이 Series의 인덱싱을 활용하여 특정 데이터들을 선택할 수 있다.
해당 인덱싱으로 시리즈형태로 반환됨.
해당 라벨 위치로 시리즈 형태로 반환됨

활용, 조건부 인덱싱
e4 = × 10⁴를 의미. 즉 3,000,000 큰숫자를 짧게 쓸때 이용한다.
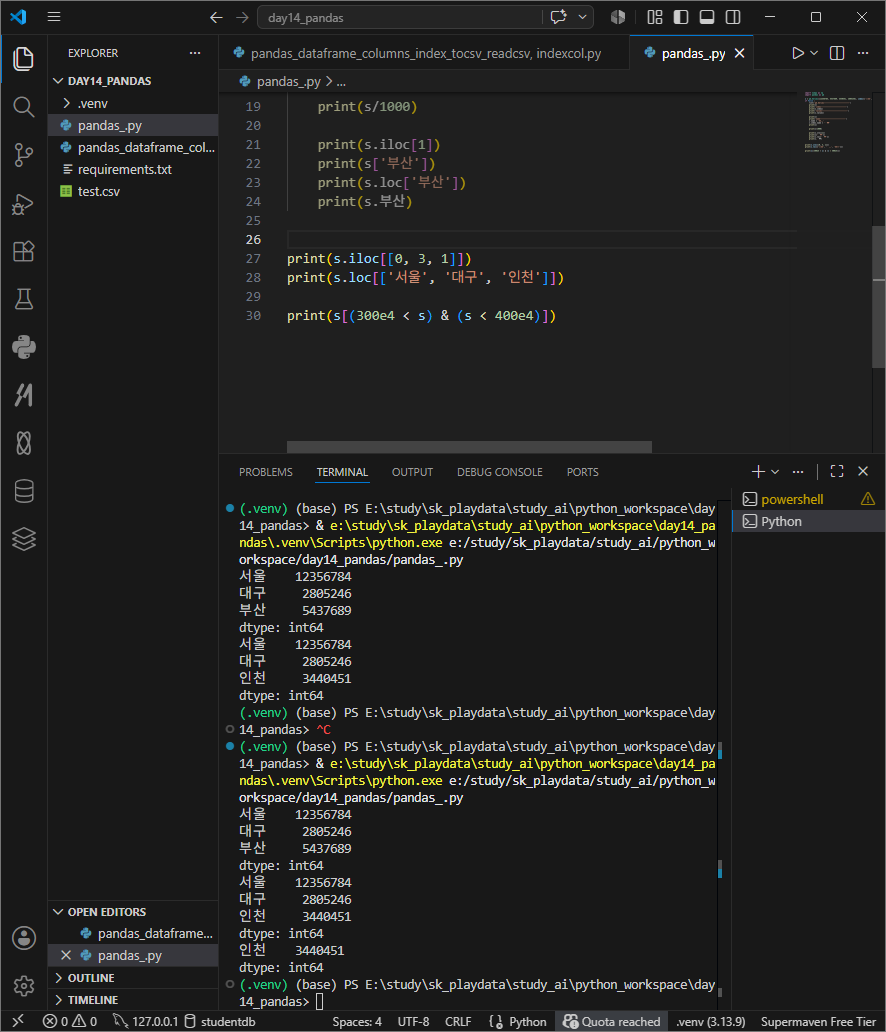
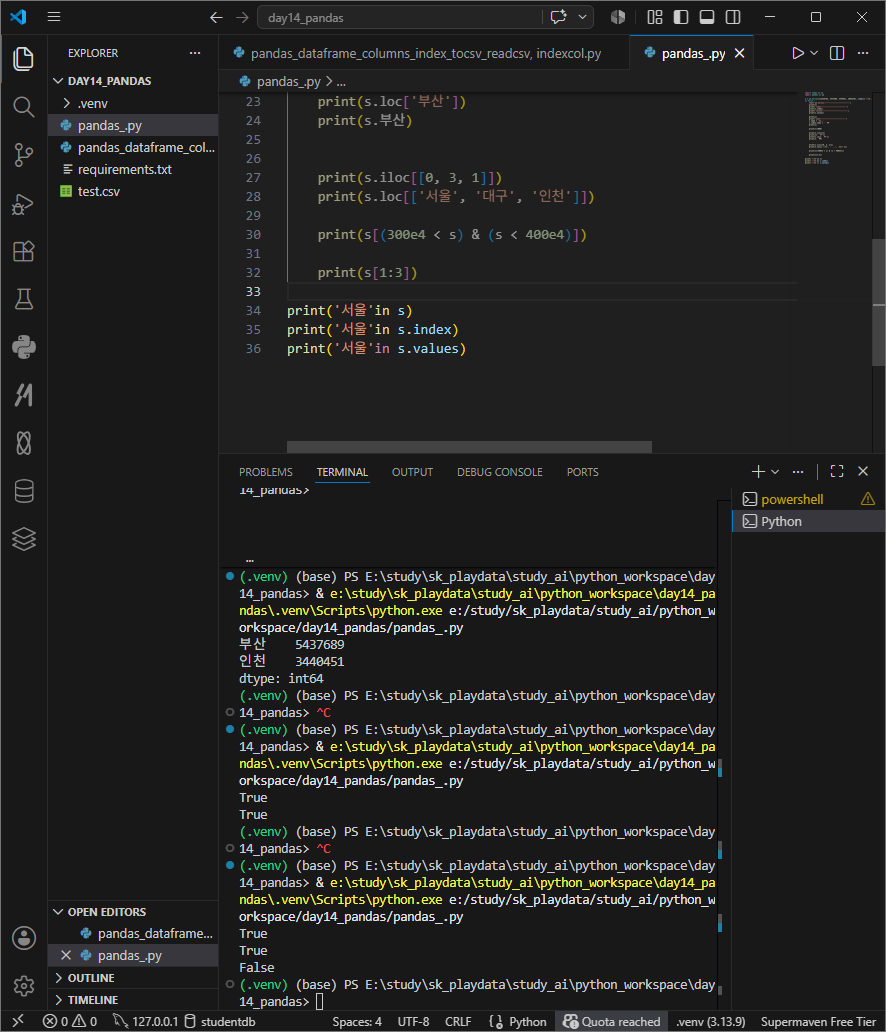
활용 인덱싱으로 슬라이싱

~ in 검색
for문의 활용

'SK 네트웍스 AI 캠프' 카테고리의 다른 글
| [SK네트웍스 Family AI 캠프] 32기 4주차 회고: Day13 ~ Day15 (0) | 2026.05.22 |
|---|---|
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day15_데이터 전처리 (0) | 2026.05.22 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day13_데이터 분석 개념 및 라이브러리 (0) | 2026.05.21 |
| [SK네트웍스 Family AI 캠프] 32기 3주차 회고: Day8 ~ Day12 (0) | 2026.05.16 |
| SK 네트웍스 AI 캠프 - 1_프로그래밍 데이터 기초 - Day12_Web Crawling_웹크롤러 만들기 (0) | 2026.05.16 |



