가상환경 세팅
python -m venv .venv
.\.venv\Scripts\activate
pip install numpy
pip install matplotlib

정보처리기사, 데이터준분석가, 데이터분석가
데이터 분석은 수집된 데이터를 탐색하고 가공해 의미있는 정보와 패턴을 발견해 의사결정에활용하는 과정
문제정의 - 데이터 수집 - 데이터 정제 - 데이터 분석 - 시각화 - 결과 해석 및 활용
데이터 수집 방법
db, csv/excel, 웹 크롤링, api, 센서 데이터, 로그 데이터
데이터 정제
오류 데이터나 불필요한 데이터를 처리하는 단계
결측치 처리, 이상치 제거, 중복 제거, 데이터 형식 통일
기술분석, 진단분석, 예측분석, 처방분석
https://standout.tistory.com/84
결측치, 비어있는 상태
결측치 값이 비어있는 상태 missing value 데이터가 누락되었거나, 입력되지 않은 상태를 의미 int[] numbers = {1, 2, 3, 4, 5, , 7, 8, 9, 10}; int sum = 0; int count = 0; double average = (double) sum / count; System.out.println("
standout.tistory.com
데이터시각화
Matplotlib, Seaborn, Plotly, Tableau, Power BI
정형 데이터 분석, 비정형 데이터 분석, 반정형 데이터 분석(json, xml..)
데이터분석에 사용되는 기술
프로그래밍 언어: Python, R, SQL
데이터 처리 라이브러리: Pandas, NumPy
머신러닝: Scikit-learn, TensorFLow, PyTorch
데이터베이스: MySQL, MongoDB
시각화: Matplotlib, Seaborn
데이터 분석과 AI의 관계: 데이터 수집 -> 데이터 분석 -> 머신러닝 학습 -> AI 모델 생성
좋은 데이터 분석이 좋은 AI 성능을 만든다.
CRISP-DM, Cross Industry Standard Process for Data Mining
비즈니스 이해 - 데이터 이해 - 데이터 준비 - 모델링 - 평가 - 배포, 실제로 순차적으로만 진행되지는 않는다. 성능이 낮을경우 준비단계로 이동하거나 품질문제가 발견되면 데이터 이해단계로 복귀하는 반복구조를 가진다.
체계적 분석, 성공률향상, 다양한산업적용, 재사용이 가능하나 반복작업이 많고 대규모 AI프로젝트, 딥러인 MLOps 환경에서는 추가 구조 가 필요하는 등의 세부가 부족하고 배포이후 현대 AI시스템에서는 MLOPs와 함께 사용이 필요해 운영관리가 부족하다.
실제로 머신러닝, 데이터분석, 추천시스템, 이상탐지, 고객이탈, AI 서비스, 빅데이터 분석에 활용된다.
데이터 분석 및 데이터 마이닝 프로젝트 수행의 국제 표준 프로세스6 방법론
1. Budiness Understanding
프로젝트의 목적과 해결할 문제를 정의하는 단계, 목표정의, 비즈니스 문제분석, 성공기준 설정, 데이터 분석 방향 결정
2. Data Understanding
수집된 데이터를 탐색하고 데이터 구조와 품질을 파악하는 단계, 데이터 수집, 구조확인, 시각화 이상치/결측치 탐색, 데이터 패턴 분석, 통계분석 및 EDA Exploratory Data Analysis, 시각화
3. Data Preparation
모델링에 사용할 데이터를 정제하고 가공하는 단계다. 실제 프로젝트에서 가장 많은 시간이 소요됨. 결측치 처리, 이상치 제거, 데이터 정규화, Feature Engineering, 데이터 통합, 학습용/테스트용 데이터 분리 GIGO Garbage In, Garbage Out
4. Modeling
데이터를 기반으로 머신러인 또는 통계 모델을 생성하는 단계, 알고리즘선택, 모델학습, 파라미터 튜닝, 모델 성능 비교, 선형회귀 의사결정트리 랜덤포레스트 SVM 딥러닝 클러스터링
5. Evaluation
생성된 모델이 실제 비즈니스 목적에 적합한지 검증, 정확도 평가 성능검증 과적합 여부 확인, 비즈니스 목표 충족 여부 판단, Accuacy, Precision, Recall, F1-Score, RMSE
6. Deployment
완성된 모델을 실제 서비스나 시스템에 적용하는 단계, 시스템 패포 api 서비스화, 모델 모니터링, 유지보수, 성능개선, 웹서비스 추천 시스템적용, AI 챗봇 운영, 이상탐지 시스템 적용
NumPy
2005년에 Travis Oliphant가 발표한 수치해석용 Python 패키지
다차원 행렬 자료구조인 NDArray를 지원. Ndarray 클래스의 메서드 이름이 같은 경우가 많아 처리규칙도 거의 같다.
실수, 복소수, 복소수 행렬의 원소간 연산을 지웒나느 함수, 배열간, 배열과 상수간의 연산을 지원하고 ufunc 클래스를 이용하여 만든다.
Numpy 배열을 고정된 크기를 가지고 모두 같은 자료형과 메모리를 가지나 객체 배열의 경우는 서로 다른 크기를 가질 수 있다. 배열 원소의 개수를 바꿀 수 없고 바꿀경우 배열을 지우고 새로 생성해야한다.
다차원 배열 행렬연산이 가능하다.
pip install numpy
python –m pip install --upgrade pip
Import numpy as nphttps://standout.tistory.com/1723
파이썬의 다차원 배열 NumPy, NDArray
NDArrayNumPy에서 말하는 NDArray는 보통 numpy.ndarray를 의미한다.이름 그대로 N-Dimensional Array 다차원 배열1차원은 리스트, 2차원은 표, 3차원 이상부터는 여러겹의 데이터. 이를 효율적으로 저장하는 자
standout.tistory.com
1차원 배열
데이터가 한줄로 나열된 형태. Python에는 배열이 없고 순차적으로 나열하는 배열형태의 리스트[] 혹은 튜플()이 있다.
요소 수정, 추가, 삭제가 가능하며 실제 값을 저장하는 것이 아니라 해당 객체의 레퍼런스를 관리함.
import numpy as np
one_dimensional_array = np.array([1, 2, 3, 4, 5])
print("one_dimensional_array--------------------------------")
print(one_dimensional_array)
two_dimensional_array = np.array([[1, 2, 3], [4, 5, 6]])
print("two_dimensional_array--------------------------------")
print(two_dimensional_array)
three_dimensional_array = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
print("three_dimensional_array--------------------------------")
print(three_dimensional_array)
arr[np.array([True, False...])] bool 배열 인덱싱으로 배열값 추출하기

Numpy 배열
같은 유형의 데이터만 저장할 수 있고 원소릐 개수를 바꿀수없다. array클래스를 이용하여 생성하며 Ndarray 타입을 가짐. 차원을 축 axis라 부르며 축의 개수를 rank라고 부름.
x.dtype 배열의 자료형(bool, int8, int16, int32, int64, unit8, unit16, unit32, unit64, float16, float32, flaot64, complex64, complex128), x.ndim/np.ndim(x) 배열 축의 개수, x.shape/np.shape(x) 배열의 차원크기를 튜플형식으로, x.side/np.size(x) 배열의 원소 갯수

NumPy Ndarray 다차원 배열
자료형이 같은 원소 데이터가 여러줄로 나열된 2차원 이상의 배열, 축 axis 축의 갯수 rank,
- array 리스트를 Ndarray 형태로 바꾸어줌
- arrange 시작값, 끝, 간격, dtype을 명시해 증가시키며 Ndarray를 생성
- empty 행, 열 주어진 행과 열 개수를 갖는 2차원 배열 생성, 공간만 생성하고 값을 초기화하지않아 메모리에 남아있던 쓰레기값이 들어감
- ones 행, 열 주어진 행과 열 개수를 갖는 2차원 배열 생성, 배열생성 후 모든 값을 1로 채움
- zeros 행, 열 주어진 행과 열 개수를 갖는 2차원 배열을 생성, 배열 생성 후 모든 값을 0으로 채움
- full 행, 열, 값 주어진 행과 열 개수를 갖는 2차원 배열을 생성하되 주어진 값을 할당
- eye x행, x열의 단위행렬을 생성해 대각선에는 1, 나머지는 0을 할당함.

eye와 비슷하게 identity가 있다.
기본기능은 비슷하지만, eye는 행과열을 지정할수있다거나 대각선 값을 이동시킬 수 있다는 차이가 있다.
- dtype 배열타입확인
- astype 데이터타입변경
- itemsize 배열요소 크기확인
- resize 배열의 차원 변경, 데이터 개수를 유지하고 모양만 변경해 원소개수가 반드시 같지않으면 실행되지않음.
- reshape 배열의 차원을 변경, 배열 크기 자체 변경가능하고 원소가 부족하면 반복해서 채우며 원소가 반대로 많으면 잘라냄
- 인덱스값으로 배열 요소 값 확인
- shape 차원 축 확인 및 변경

linspace 처음 ~ 끝 까지 같은 간격으로 N개 생성한다.
logspace 10^1 ~ 10^10 사이클 5개로 나눠 생성한다.
geomspace 1 ~ 10 사이를, 곱셉비율이 일정한 수열인 등비수열로 5개 생성한다.
rand 행과열 구조의 0~1 사이의 실수 난수 생성, 비슷한 비율로 나옴
randn 0~1 사이 아무 숫자나 균등히 뽑았던 rand와 다르게 0 근처 숫자가 많이 나오고 큰 숫자는 잘 안나온다. 정규분포를 따라 평균 0, 표준편차 1의 부채와 닮은 정규분포 그래프 모양을 상상하라. 0 근처 숫자가 많이 나오고 멀리갈수록 적게나온다. 행과열 구조의 근처를 중심으로 몰린 값
ranint 처음~끝 사이의 정수 난수 2개 생성
random.random 0~1 사이 실수 난수 n개 생성
random.random_sample random()과 거의 동일 원래 이름, 예전 호환성 및 이름 체계때문에 둘다 남아있다. 동일하다.
random.choice 리스트에서 랜덤하게 n개 선택
random.random_integers 처음과 끝 사이의 정수 난수 2개 생성
random.shuffle 리스트 순서를 랜덤하게 섞음
random.seed 난수 생성기준을 고정해 이후 실행할때마다 같은 결과가 나온다. 매번 같은 값을 원할경우 게속 seed. seed 안의 숫자는 큰 의미가 없으며 난수 생성기의 시작점 id와 같다. seed1 은 a패턴으로 게속나오고, seed 2면 b패턴으로 나오는것.

import numpy as np
if False:
one_dimensional_array = np.array([1, 2, 3, 4, 5])
print("one_dimensional_array--------------------------------")
print(one_dimensional_array)
two_dimensional_array = np.array([[1, 2, 3], [4, 5, 6]])
print("two_dimensional_array--------------------------------")
print(two_dimensional_array)
three_dimensional_array = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]])
print("three_dimensional_array--------------------------------")
print(three_dimensional_array)
print("type ----------------------------------------")
print(one_dimensional_array.dtype, type(one_dimensional_array))
print("axis 축, 차원크기 튜플형식, 원소갯수----------------------------------------")
print(one_dimensional_array,
one_dimensional_array.ndim,
one_dimensional_array.shape,
one_dimensional_array.size)
elif False:
print("arrange ----------------------------------------")
print(np.arange(2, 10, 2, dtype=np.int32))
print("empty ----------------------------------------")
print(np.empty(2, dtype=np.int32))
print("ones ----------------------------------------")
print(np.ones(2, dtype=np.int32))
print("zeros ----------------------------------------")
print(np.zeros(2, dtype=np.int32))
print("full ----------------------------------------")
print(np.full((2, 3), 5))
print("eye ----------------------------------------")
print(np.eye(3, dtype=np.int32))
elif False:
print("dtype and astype ----------------------------------------")
one_dimensional_array = np.array([1, 2, 3, 4, 5], dtype=np.int32)
print(one_dimensional_array.astype(np.float32))
elif False:
print("itemsize and resize and reshpe ----------------------------------------")
one_dimensional_array = np.array([1, 2, 3, 4, 5], dtype=np.int32)
print(one_dimensional_array.itemsize)
print(one_dimensional_array.resize((2, 3)))
print(one_dimensional_array.reshape((2, 3)))
elif False:
print("indexing and shape ----------------------------------------")
one_dimensional_array = np.array([1, 2, 3, 4, 5, 6], dtype=np.int32)
print(one_dimensional_array[0])
print(one_dimensional_array[1:3])
print(one_dimensional_array.shape)
one_dimensional_array.shape = (2, 3)
print(one_dimensional_array)
print(one_dimensional_array.shape)
elif False:
print("eye and identity ----------------------------------------")
print(np.identity(3, dtype=np.int32), '\n')
print(np.eye(3, dtype=np.int32), '\n')
print(np.eye(2, 4, dtype=np.int32), '\n')
print(np.eye(3, k=2, dtype=np.int32))
elif False:
print("linspace ----------------------------------------")
print(np.linspace(1, 10, 5, dtype=np.int32))
print("logspace ----------------------------------------")
print(np.logspace(1, 10, 5, dtype=np.int32))
print("geomspace ----------------------------------------")
print(np.geomspace(1, 10, 5, dtype=np.int32))
elif False:
print("rand ----------------------------------------")
print(np.random.rand(2, 2))
print("randn ----------------------------------------")
print(np.random.randn(2, 2))
print("randint ----------------------------------------")
print(np.random.randint(0, 10, 2, dtype=np.int32))
elif False:
print("random ----------------------------------------")
print(np.random.random(2))
print("random_sample ----------------------------------------")
print(np.random.random_sample(2))
print("random_choice ----------------------------------------")
print(np.random.choice([1, 2, 3, 4, 5], 2, replace=False))
elif True:
print("random_integers ----------------------------------------")
print(np.random.random_integers(0, 10, 2))
print("random_shuffle ----------------------------------------")
print(np.random.shuffle([1, 2, 3, 4, 5]))
print("random ----------------------------------------")
print(np.random.seed(1))
print(np.random.rand(2, 2))
print(np.random.seed(2))
print(np.random.rand(2, 2))
print(np.random.seed(1))
print(np.random.rand(2, 2))
NumPy 배열 연산
스칼라. 배열의 각 요소의 스칼라 값을 각각 연산함
인덱싱과 슬라이싱
배열의 행과 열, 축을 바꿀 수 있다.
유니버설 함수는 Ndarray안의 데이터를 원소별로 연산을 수행해주는 함수. 1개의 인자를 받아 값을 반환하는 유니버설 함수를 단항 유니버설 함수, 2개으 인자를 받아 잔환하는 유니버설 함수를 이항 유니버설 함수라고함.
ufunc 를 사용해 함수를 한번 불러 배열의 모든 아이템에 적용시킬 수 있다.
단항
abs 절대값, 음수를 양수로 변환한다.
sqrt 제곱근계산
square 제곱계산
exp e의 거듭제곱
log 자연로그 ln
sin 사인 값 삼각함수
cos 코사인값
tan 탄젠트 값
ceil 소수점 올림
floor소수점 버림
round반올림
sign부모반환
all모든값이 True인지 확인 0이면 False
any 하나라도 True인지 확인
isnan결측값 여부 확인
isfinite무한대 혹은 NaN이 아닌지 확인
이항
add 같은 위치 원소끼리 더하기
subtract 같은 위치 원소끼리 빼기
multiply 같은 원소 원소끼리 곱하기
divide 같은 원소 원소끼리 나누기
power 각 원소를 제곱
maximum같은 위치에서 큰 값 선택
minimum 같은 위치에서 작은 값선택
mod 나머지 선택
greater arr1 > arr2 비교해 True, False 반환
less arr1 < arr2 비교
equal 같으면 True
not_equal 다르면 True
logical_and 둘다 0 이 아니면 True, 논리 and
logical_or 하나라도 0 이 아니면 True, 논리 or

where 함수
조건을 충족하는 배열의 색인을 생성

기본 삼각함수그래프 그려보기, -5 ~ 5사이에 데이터를 50개 발생시켜 사인그래프 그리기

import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-5, 5, 50)
sin = np.sin(x)
plt.plot(x, sin, label='sin(x)')
plt.legend()
plt.show()
역삼각함수그래프 그리기

x = np.linspace(-5, 5, 50)
arcsin = np.arcsin(x)
plt.plot(x, arcsin, label='arcsin(x)')
plt.legend()
plt.show()
데이터통계
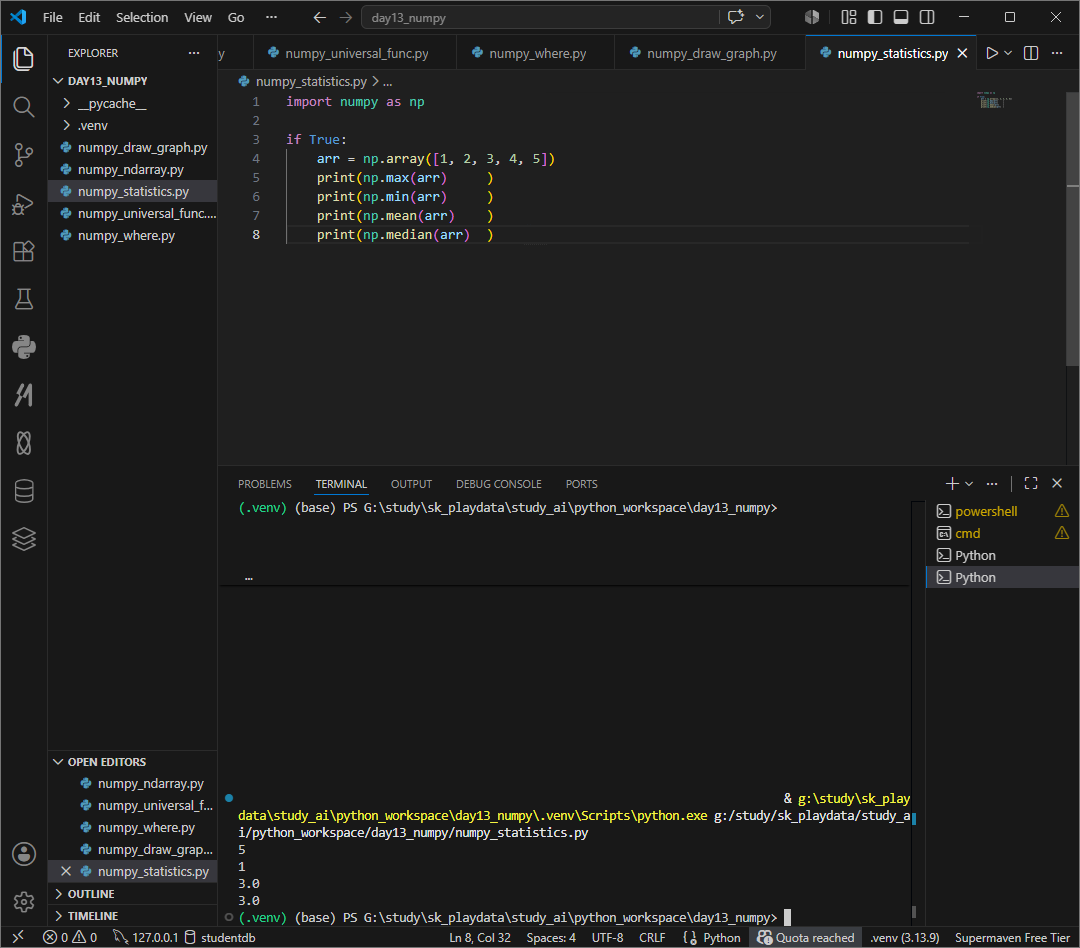
기본통계함수
max 최대
min최소
mean평균
median 중앙값
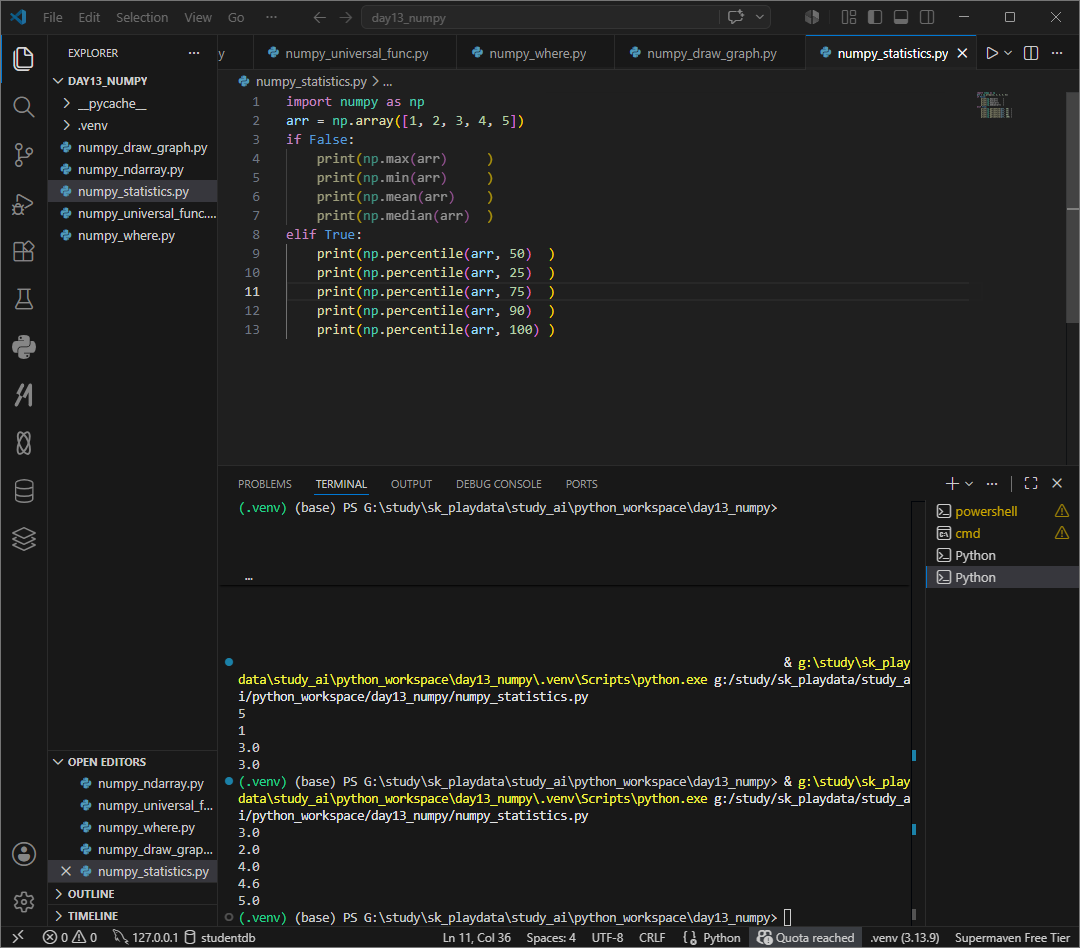
percentile 백분위
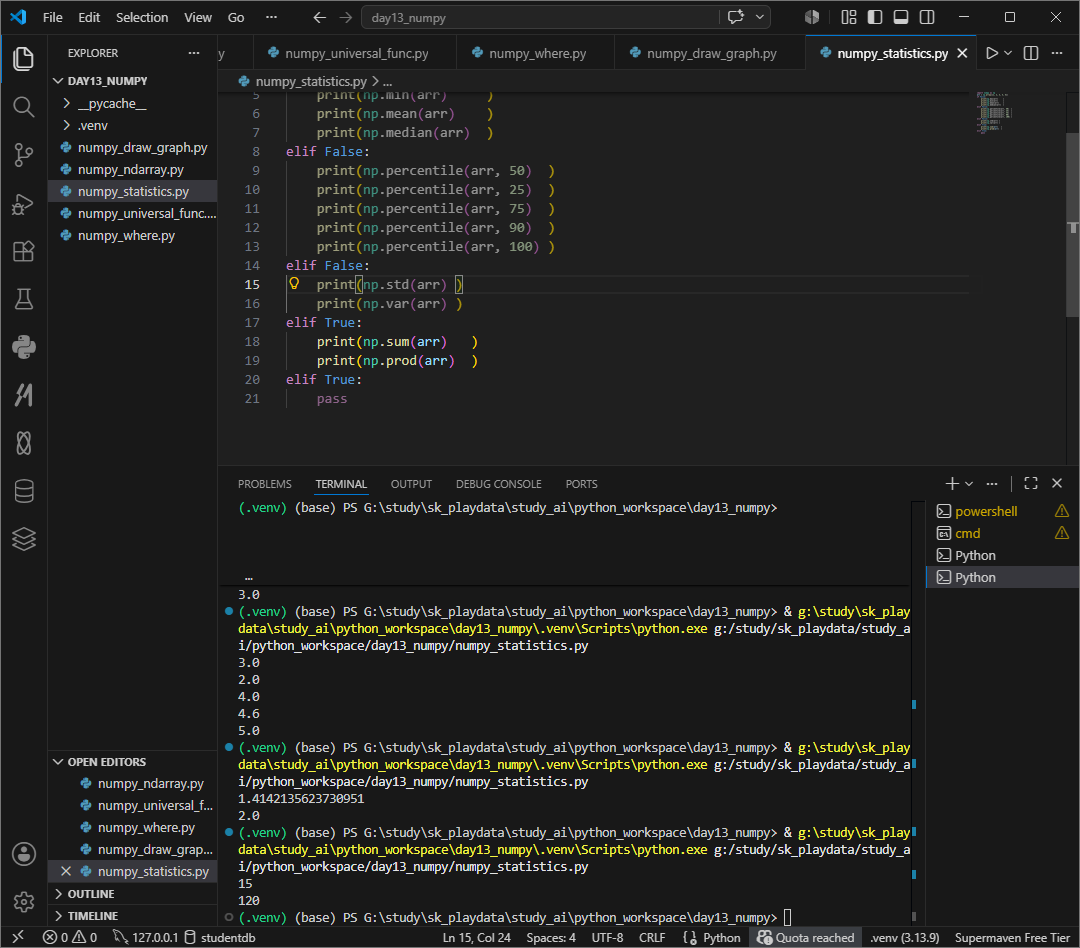
std 표준편차, 흩어진 정도
var 분산

sum 합
prod 곱
부호. +가 많을 수록 같이 증가, -가 많을수록 반대로 움직인, 0 이 많을수록 관계없음
cov 공분산, 0이면 변수변화 예측불가 숫자가 클수록 두 변수는 함께 변화하고 있음
corrcoef 상관계수,양수면 서로 증가하고 양수면 서로 감소하고 0이면 관련없음

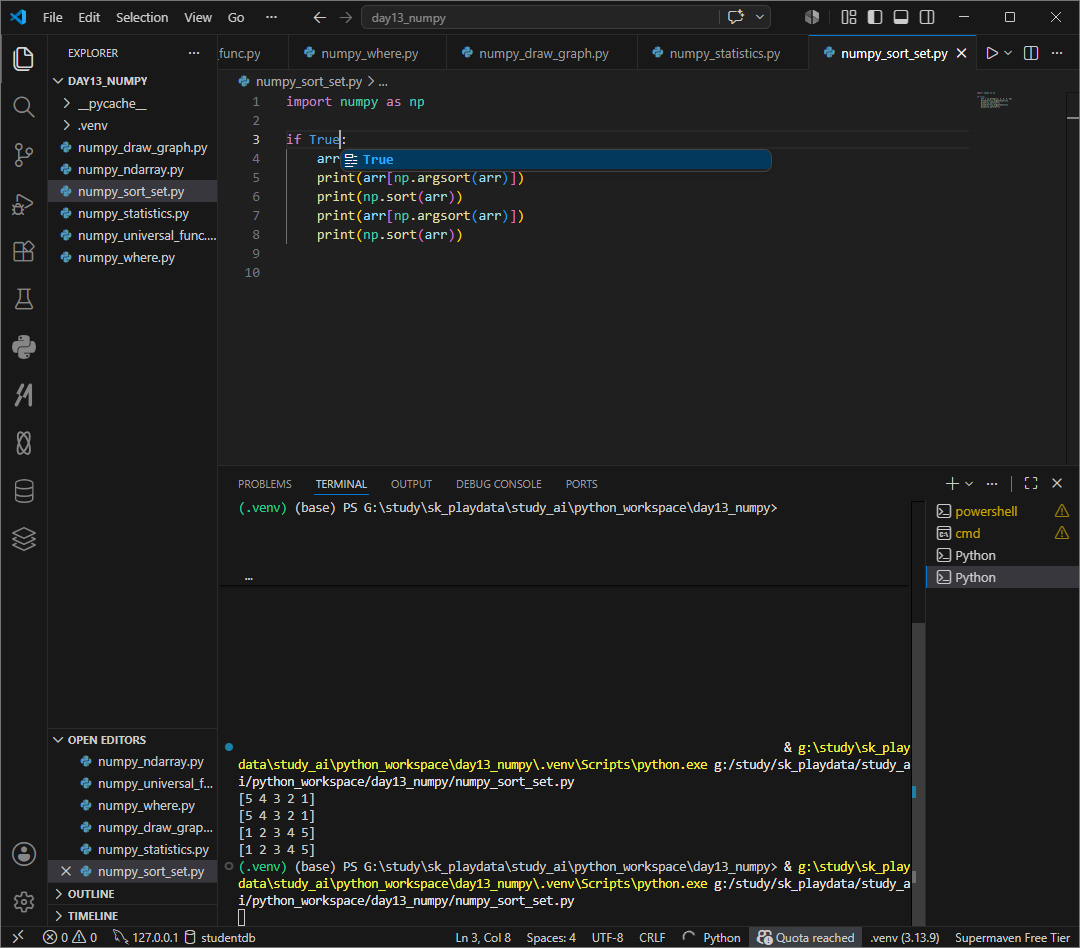
배열 정렬 sort 오름차순, argsort내림차순
집합
unique 중복제거
intersect1d 교집합
union1d 합집합
isin 배열1이 배열2를 초함하는지
setdiff1d 배열1에서 배열2를 뺀 차집합
setxor1d 합집합에서 교집합을 뺀 대칭차집합

백터와 행렬
백터: 크기뿐만 아니라 방향까지 가진 수의 집합, 벡터를 이루는 숫자 성분을 스칼라, 열 벡터와 행 벡터로 나뉜다.

행렬: 크기만 가진 행과 열로 구성된 수의 집합. 대각선을 제외한 모든 원소가 0인 행렬을 대각행령, 원소가 모두 1인 행렬을 단위행렬 또는 항등행렬, 주 대각선 기준으로 위 또는 아래의 모든 원소가 0인행렬을 삼각행렬이라함
linspace stop구간을 num 개로 균등하게 나눈 값 endpoint값이 True일때 시작과 끝을 포함해 알맞게 나누지만 False일경우 끝은 제외되어 끝 직전까지만 나눔

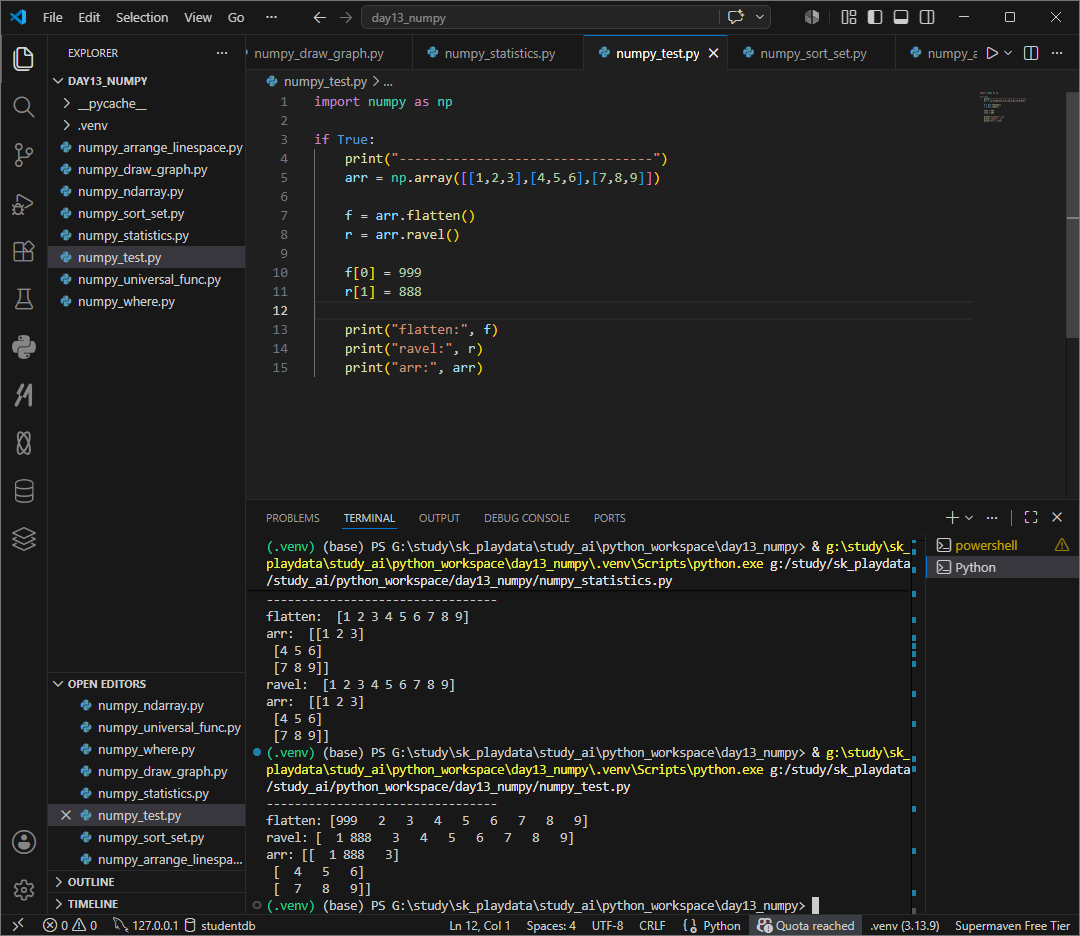
다차원 1차원으로 펴기 ravel flatten
ravel은 메모리에 참조로 원본과 연결되어 빠르고 flatten은 메모리 복사를 해 생성해 안전하다.
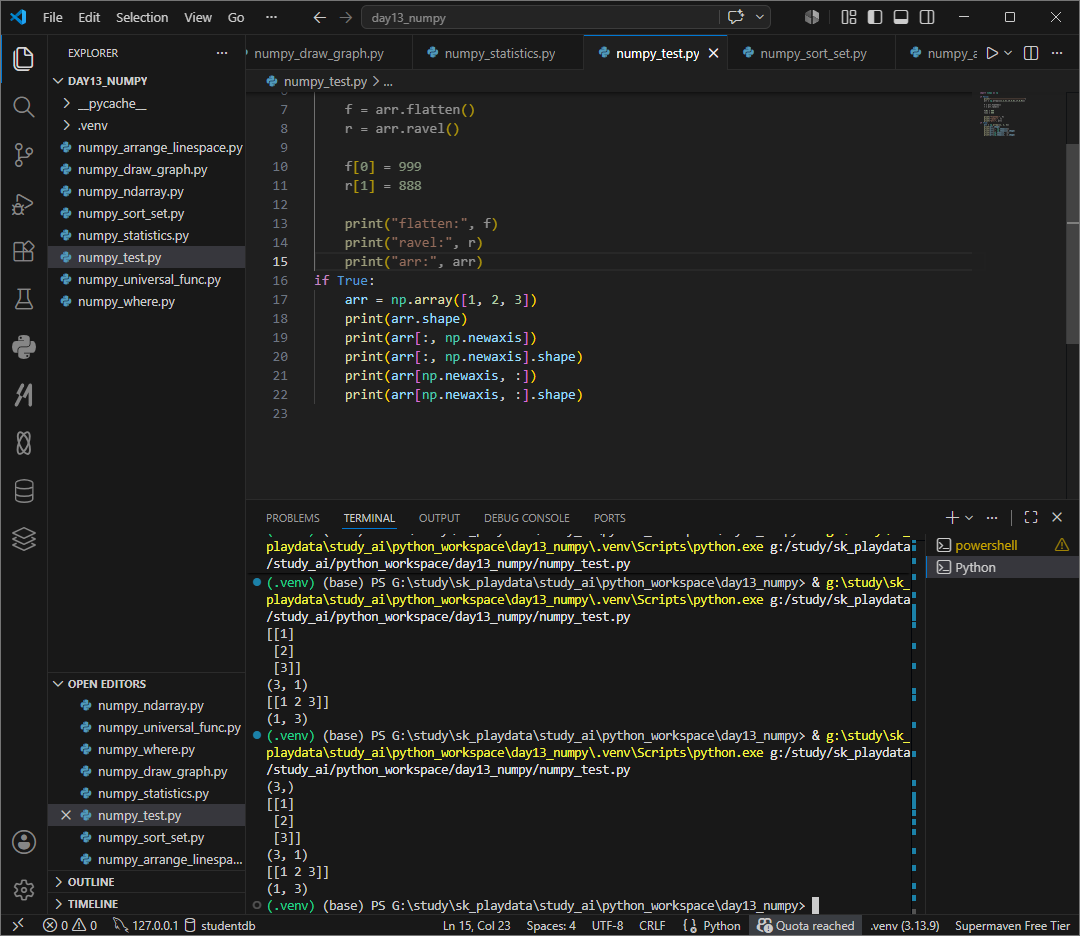
newaxis 데이터를 바꾸지않고 차원의 방향을 바꾸며 차원을 한줄씩 늘린다.
'SK 네트웍스 AI 캠프' 카테고리의 다른 글
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day15_데이터 전처리 (0) | 2026.05.22 |
|---|---|
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day14_데이터 전처리 (0) | 2026.05.21 |
| [SK네트웍스 Family AI 캠프] 32기 3주차 회고: Day8 ~ Day12 (0) | 2026.05.16 |
| SK 네트웍스 AI 캠프 - 1_프로그래밍 데이터 기초 - Day12_Web Crawling_웹크롤러 만들기 (0) | 2026.05.16 |
| SK 네트웍스 AI 캠프 - 1_프로그래밍 데이터 기초 - Day11_웹크롤링 이해와 실습 (0) | 2026.05.14 |



