비지도학습
정답이 없는 레이블로 내부 패턴, 구조, 관계를 스스로 찾아내는 머신러닝 기법.
주로 비슷한 데이터끼리 그룹으로 묶는 군집화, 많은 특성을 적은 특성으로 압축하는 차원축소, 함께 발생하는 패턴발견의 연관규칙 분석, 정상패턴에서 벗어난 데이터의 발견 이상치 탐지에 사용된
https://standout.tistory.com/1533
기계학습과 기계학습의 분야: 지도학습/비지도학습/강화학습
기계학습과 기계학습의 분야 기계학습이란?인공지능(AI)의 한 분야데이터와 통계적 모델링 기법을 사용하여 컴퓨터 시스템이 스스로 학습할 수 있게 만드는 기술https://standout.tistory.com/1529 자동
standout.tistory.com
군집화 Clustering
가장 대표적인 비지도학습, 비슷한데이터는 같은 그룹으로.
K-Means 가장 많이 사용되는 군집화 알고리즘. K 중심점 Centroid를 선택해 각 데이터를 가까운 중심점에 배정해 평균계산, 중심정 이동하는 과정을 반복한다. 구현이 쉽고 계산이 빠르나 K를 미리 지정해야하고 이상치에 민감하다는 단점이 있다.

계층형 군집화 Hierarchical Clustering
데이터를 트리 구조로 군집화한다.
Agglomerative 아래에서 위로 소규모군집, 큰군집, 최종군집으로 군집화한다.
Divisive 위에서 아래로 전제데이터 - 군집분할 - 세부군집으로 군집화한다 .
덴다이어그램 확인.

https://standout.tistory.com/1778
Diagram 다이어그램 종류별 용어정리: Graph, Chart, Tree, Dendrogram
Diagram 그림 전반을 부르는 일반 용어특정알고리즘이 아닌 모든 시각화그림을 통칭하는 말이다. Flowchart 순서도, Neural Network 구조그림, Bar Chart, Scatter plot, Dendrogram, Tree 구조 등이 예시가 된다. Diagr
standout.tistory.com
DBSCAN 밀도 기반 군집화
데이터가 뺵빽하게 모여 있는 구간을 하나의 군집으로 보는 아이디어. 반경 e안에 MinPts 이상 데이터가 있으면 군집이라고 이해함.
- Epsilon 이웃범위반경
- MinPts 최소 몇개가 모여야 군집인가.
DBSCAN은 데이터를 3개로 나뉜다. Core Point 중심, Border Point 경계점, Noice 어디에서 속하지않는 이상치.
군집 개수를 몰라도되며 이상치를 자동으로 제거하는 큰 장점이 있지만 e, MinPts 설정이 어렵고 밀도 차이가 큰 데이터에 약하다.
빽빽한곳은 군집으로 인식하고 듬성한 곳은 무시한다는것.
연관규칙 분석 Associatrion Rule Mining
데이터에서 함께 나타나는 패턴을 찾는다. '빵을 사는 사람은 우유도 자주사고, 맥주는 사는 사람은 기저귀도 자주산다'
Apriori 알고리즘, 가장 유명한 연관 규칙 분석 알고리즘 자주 등장하는 항목 집합을 먼저 찾아 규칙을 찾고 지지도 support 지지도(항목이 함께 등장한 비율), 신뢰도/향상도(둘을 함께 살 확률), 를 통해 사용자에게 상품을 추천할 수 있음을 연상해보자.
이상치 탐지 Anomaly Detection
정상 패턴과 다른 데이터 찾기,
이상치를 분리해버리는 Isolation Forest, 정상영역을 생성해 관리하는 One-Class SVM 가 있다.
Isolation Forest 현재 가장 많이 사용하는 이상치는 쉽게 분리된다는 아이디어로 혼자 떨어져있는 이상치를쉽게 분리할 수 있다는 의미로 접근한다. 빠르고 대용량이 가능하며 구현이 쉽다.
One-Class SVM 정상데이터만 학습한다. 학습후에 정상영역을 만들고 새 데이터가 영역안에 위치할경우 정상으로 인식한다느 ㄴ아이디어.
현재까지의 알고리즘을 전체적으로 비교해보자 .
| K-Means | 군집화 | 비슷한 것끼리 묶기 |
| Hierarchical | 군집화 | 트리 구조로 묶기 |
| DBSCAN | 군집화 | 밀집된 곳 찾기 |
| PCA | 차원 축소 | 정보 유지하며 압축 |
| t-SNE | 시각화 | 비슷한 점 가까이 배치 |
| UMAP | 시각화 | 빠르고 대용량 가능 |
| Apriori | 연관 규칙 | 함께 발생하는 패턴 찾기 |
| Isolation Forest | 이상치 탐지 | 튀는 데이터 찾기 |
| One-Class SVM | 이상치 탐지 | 정상 영역 밖 찾기 |
| Autoencoder | 딥러닝 비지도학습 | 압축 후 복원 학습 |
장바구니 연관규칙을 출력하는 샘플코드 torch_association_rules를 분석해보자.
itertools combinations 여러아이템, 조합을 만들때 사용한다.
# ============================================================
# 1. Google Colab 실행 환경 확인
# ============================================================
# sys는 현재 파이썬 실행 환경 정보를 확인할 때 사용하는 기본 모듈입니다.
import sys
# os는 파일 경로 확인, 폴더 생성, 파일 존재 여부 확인 등에 사용하는 기본 모듈입니다.
import os
# itertools는 여러 아이템 조합을 만들 때 사용하는 표준 라이브러리입니다.
# 예: 우유, 빵, 버터 중 2개씩 묶는 모든 조합 생성
from itertools import combinations
# urllib.request는 인터넷 URL에서 파일을 내려받을 때 사용하는 표준 라이브러리입니다.
import urllib.request
# pandas는 표 형태의 데이터를 다루기 위한 대표적인 라이브러리입니다.
import pandas as pd
# numpy는 수치 계산을 위한 라이브러리이며, 데이터 변환 보조 용도로 사용합니다.
import numpy as np
# torch는 PyTorch 라이브러리이며, 텐서 기반 수치 연산에 사용합니다.
import torch
# matplotlib.pyplot은 그래프를 그릴 때 사용하는 라이브러리입니다.
import matplotlib.pyplot as plt
# 현재 파이썬 버전을 출력하여 Colab 환경을 확인합니다.
print("Python version:", sys.version)
# 현재 설치된 PyTorch 버전을 출력합니다.
print("PyTorch version:", torch.__version__)
# GPU 사용 가능 여부를 확인합니다.
# 이 실습은 데이터가 작아서 CPU만으로도 충분하지만, Colab 환경 점검용으로 출력합니다.
print("CUDA available:", torch.cuda.is_available())
데이터파이 준비 및 간단분석
데이터를 for line in f 로 읽어 strip()로 줄 끝의 줄바꿈, 양끝 공백 등을 제거한다.
line이 "" 빈 줄이라면 건너뛴다.
line에는 .split(', ')를 사용해 아이템 이름을 분리한다 .
item.strip() for item in item if item.strip() ! = "" items에서 item이름에서 .strip() 공백을 제거하고 빈문자열이 아닐경우에만 추가하자.
# ============================================================
# 2. 데이터 파일 준비
# ============================================================
# Colab에서는 로컬 data 폴더가 없을 수 있으므로, 아래 코드는 두 가지 방식을 지원합니다.
# 1) 사용자가 직접 shop_groceries.csv를 업로드한 경우
# 2) 파일이 없으면 인터넷의 공개 grocery 데이터 예제를 내려받는 경우
# Colab 작업 폴더 안에 data 폴더를 생성합니다.
os.makedirs("data", exist_ok=True)
# 실습에서 사용할 CSV 파일 경로를 지정합니다.
DATA_PATH = "data/shop_groceries.csv"
# 공개 예제 grocery 데이터 URL입니다.
# 각 행은 하나의 장바구니 거래이며, 쉼표로 구매 물품들이 구분되어 있습니다.
DATA_URL = "https://raw.githubusercontent.com/stedy/Machine-Learning-with-R-datasets/master/groceries.csv"
# 파일이 이미 존재하는지 확인합니다.
if not os.path.exists(DATA_PATH):
# 파일이 없으면 공개 URL에서 다운로드합니다.
print("CSV 파일이 없어 공개 grocery 데이터를 다운로드합니다.")
urllib.request.urlretrieve(DATA_URL, DATA_PATH)
else:
# 파일이 있으면 기존 파일을 그대로 사용합니다.
print("기존 CSV 파일을 사용합니다:", DATA_PATH)
# 준비된 파일 경로를 출력합니다.
print("데이터 파일 경로:", DATA_PATH)# ============================================================
# 3. 거래 데이터 읽기
# ============================================================
# transactions 리스트는 전체 거래 데이터를 저장합니다.
# 각 원소는 한 번의 장보기에서 구매한 아이템 이름들의 리스트입니다.
transactions = []
# CSV 파일을 한 줄씩 직접 읽습니다.
# grocery 데이터는 일반적인 표 형태가 아니라, 한 줄이 하나의 거래를 의미합니다.
with open(DATA_PATH, "r", encoding="utf-8") as f:
# 파일의 모든 줄을 반복합니다.
for line in f:
# strip()은 줄 끝의 줄바꿈 문자와 양끝 공백을 제거합니다.
line = line.strip()
# 빈 줄은 거래 데이터가 아니므로 건너뜁니다.
if line == "":
continue
# split(",")은 쉼표 기준으로 아이템 이름을 분리합니다.
# 예: "milk,bread" -> ["milk", "bread"]
items = line.split(",")
# 각 아이템 이름에서 양쪽 공백을 제거하고, 빈 문자열은 제외합니다.
items = [item.strip() for item in items if item.strip() != ""]
# 한 거래 안에서 같은 아이템이 중복될 수 있으므로 set으로 중복 제거 후 다시 list로 바꿉니다.
items = list(set(items))
# 정리된 거래를 전체 transactions 리스트에 추가합니다.
transactions.append(items)
# 전체 거래 수를 계산합니다.
num_transactions = len(transactions)
# 전체 아이템 목록을 만들기 위해 모든 거래의 아이템을 하나의 set에 모읍니다.
all_items = sorted(set(item for transaction in transactions for item in transaction))
# 전체 고유 아이템 수를 계산합니다.
num_items = len(all_items)
# 거래 수와 아이템 수를 출력합니다.
print("전체 거래 수:", num_transactions)
print("전체 고유 아이템 수:", num_items)
# 처음 5개 거래를 확인합니다.
print("처음 5개 거래:")
for i, transaction in enumerate(transactions[:5], start=1):
print(f"거래 {i}:", transaction)
item_to_idx 에 아이템 이름을 열번호로 바꾸기위해 인덱스+값을 동시에 꺼내주는 enumerate를 사용한다.
idx_to_item에 index를 다시 아이템 이름으로 바꾸도록 세팅한다.
torch.zero로 거래수*아이템수의 행렬을 생성한다.
for로 순회하며 아이템이름을 enumerate한 번호로 바꾼뒤 아이템을 구매했음으로 1로 표시한다.
# ============================================================
# 4. 거래 데이터를 one-hot 희소 행렬 형태로 변환
# ============================================================
# item_to_idx는 아이템 이름을 열 번호로 바꾸기 위한 딕셔너리입니다.
# 예: {'whole milk': 0, 'yogurt': 1, ...}
item_to_idx = {item: idx for idx, item in enumerate(all_items)}
# idx_to_item은 열 번호를 다시 아이템 이름으로 바꾸기 위한 딕셔너리입니다.
idx_to_item = {idx: item for item, idx in item_to_idx.items()}
# torch.zeros()로 거래 수 x 아이템 수 크기의 행렬을 생성합니다.
# 값이 0이면 해당 거래에서 그 아이템을 사지 않았다는 뜻입니다.
# 값이 1이면 해당 거래에서 그 아이템을 샀다는 뜻입니다.
X = torch.zeros((num_transactions, num_items), dtype=torch.float32)
# 각 거래를 순회하면서 구매한 아이템 위치에 1을 표시합니다.
for row_idx, transaction in enumerate(transactions):
# 현재 거래 안의 각 아이템을 반복합니다.
for item in transaction:
# 아이템 이름을 열 번호로 변환합니다.
col_idx = item_to_idx[item]
# 해당 거래(row_idx)에서 해당 아이템(col_idx)을 구매했으므로 1로 표시합니다.
X[row_idx, col_idx] = 1.0
# 생성된 one-hot 행렬의 크기를 확인합니다.
print("one-hot 행렬 크기:", X.shape)
# 처음 5개 거래와 처음 10개 아이템 열만 잘라서 확인합니다.
print("처음 5개 거래 x 처음 10개 아이템 행렬:")
print(X[:5, :10])
# 처음 10개 아이템 이름을 출력합니다.
print("처음 10개 아이템 이름:")
print(all_items[:10])one-hot 행렬 크기: torch.Size([9835, 169])
처음 5개 거래 x 처음 10개 아이템 행렬:
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]])
처음 10개 아이템 이름:
['Instant food products', 'UHT-milk', 'abrasive cleaner', 'artif. sweetener', 'baby cosmetics', 'baby food', 'bags', 'baking powder', 'bathroom cleaner', 'beef']
support 컬럼은 지지도, 전체 거래중 특정 아이템이 등장한 거래의 비율이다
item_support_tenser에 x의 mean 값을 부여한다. 배열로 바꾸어 출력한다.
우유를 다들 꽤 많이먹는다.
# ============================================================
# 5. 아이템 빈도와 지지도 계산
# ============================================================
# 지지도(support)는 전체 거래 중 특정 아이템이 등장한 거래의 비율입니다.
# 예: 전체 100건 중 우유가 25건이면 우유의 support는 25 / 100 = 0.25입니다.
# X.mean(dim=0)은 각 열의 평균을 계산합니다.
# one-hot 값이 0 또는 1이므로 평균은 곧 각 아이템의 거래 비율, 즉 지지도입니다.
item_support_tensor = X.mean(dim=0)
# torch 텐서를 pandas DataFrame으로 변환하기 위해 numpy 배열로 바꿉니다.
item_support = item_support_tensor.numpy()
# 아이템별 지지도 표를 만듭니다.
item_freq_df = pd.DataFrame({
"item": all_items,
"support": item_support,
"count": (item_support_tensor * num_transactions).to(torch.int64).numpy()
})
# 지지도 기준으로 내림차순 정렬합니다.
item_freq_df = item_freq_df.sort_values("support", ascending=False).reset_index(drop=True)
# 상위 10개 아이템을 출력합니다.
item_freq_df.head(10)item support count
0 whole milk 0.255516 2513
1 other vegetables 0.193493 1902
2 rolls/buns 0.183935 1809
3 soda 0.174377 1714
4 yogurt 0.139502 1372
5 bottled water 0.110524 1087
6 root vegetables 0.108998 1072
7 tropical fruit 0.104931 1032
8 shopping bags 0.098526 969
9 sausage 0.093950 923
support_01_df 변수에 item support가 0.1 이상인 아템을 할당하고 시각화한다 .
# ============================================================
# 6. 지지도 0.1 이상 아이템 시각화
# ============================================================
# support가 0.1 이상인 아이템만 선택합니다.
support_01_df = item_freq_df[item_freq_df["support"] >= 0.1]
# 그래프 크기를 지정합니다.
plt.figure(figsize=(10, 5))
# 막대그래프를 그립니다.
# x축은 아이템 이름, y축은 지지도입니다.
plt.bar(support_01_df["item"], support_01_df["support"])
# x축 라벨을 45도 회전시켜 긴 아이템 이름이 겹치지 않게 합니다.
plt.xticks(rotation=45, ha="right")
# 그래프 제목을 지정합니다.
plt.title("Items with support >= 0.1")
# x축 이름을 지정합니다.
plt.xlabel("Item")
# y축 이름을 지정합니다.
plt.ylabel("Support")
# 그래프 요소가 화면에서 잘리지 않도록 자동 정렬합니다.
plt.tight_layout()
# 그래프를 출력합니다.
plt.show()
이번엔 top30_df변수에 head(30)를 할당해 30 위까지를 출력한다.
# ============================================================
# 7. 상위 30개 아이템 빈도 시각화
# ============================================================
# 지지도 상위 30개 아이템만 선택합니다.
top30_df = item_freq_df.head(30)
# 그래프 크기를 지정합니다.
plt.figure(figsize=(14, 6))
# 상위 30개 아이템의 지지도를 막대그래프로 출력합니다.
plt.bar(top30_df["item"], top30_df["support"])
# x축 라벨을 회전시켜 가독성을 높입니다.
plt.xticks(rotation=60, ha="right")
# 그래프 제목을 지정합니다.
plt.title("Top 30 item frequencies")
# x축 이름을 지정합니다.
plt.xlabel("Item")
# y축 이름을 지정합니다.
plt.ylabel("Support")
# 그래프 여백을 자동 조정합니다.
plt.tight_layout()
# 그래프를 출력합니다.
plt.show()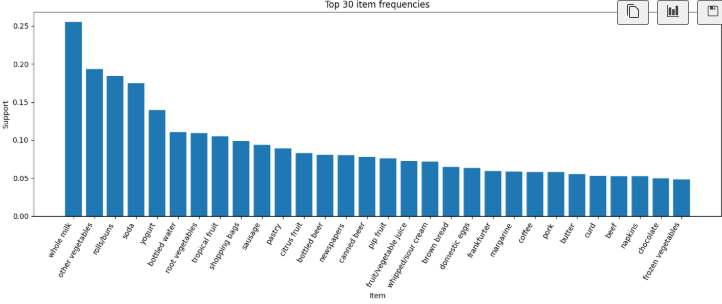
그래프 크기를 figure 가로 12, 세로 13로 설정하고 처음5 거래를 선택해 배열로 변환해 출력한다.
이번엔 seed 난수를 고정하되 랜덤 200개 거래를 시각화한다.
규칙이 뚜렷하고 세로로 같이 밝으면 같이 많이 팔려 추천시스템을 쓸만한 데이터인지 확인해볼 수 있다.
# ============================================================
# 8. 거래-아이템 희소 행렬 시각화
# ============================================================
# 처음 5개 거래의 one-hot 행렬을 이미지로 표시합니다.
plt.figure(figsize=(12, 3))
# imshow()는 행렬 값을 색으로 표시합니다.
# 1은 구매한 아이템, 0은 구매하지 않은 아이템을 의미합니다.
plt.imshow(X[:5].numpy(), aspect="auto")
# 그래프 제목을 지정합니다.
plt.title("Sparse transaction matrix: first 5 transactions")
# x축은 아이템 열 번호입니다.
plt.xlabel("Item index")
# y축은 거래 번호입니다.
plt.ylabel("Transaction index")
# 색상 막대를 표시합니다.
plt.colorbar(label="Purchased: 1 / Not purchased: 0")
# 그래프를 출력합니다.
plt.show()
# 200개 거래를 무작위로 뽑기 위해 난수 시드를 고정합니다.
torch.manual_seed(42)
# 전체 거래 번호 중 200개를 무작위로 선택합니다.
sample_indices = torch.randperm(num_transactions)[:200]
# 선택된 200개 거래의 one-hot 행렬을 이미지로 표시합니다.
plt.figure(figsize=(12, 6))
# 200개 거래와 전체 아이템 열의 희소 행렬을 시각화합니다.
plt.imshow(X[sample_indices].numpy(), aspect="auto")
# 그래프 제목을 지정합니다.
plt.title("Sparse transaction matrix: random 200 transactions")
# x축은 아이템 열 번호입니다.
plt.xlabel("Item index")
# y축은 무작위 샘플 거래 번호입니다.
plt.ylabel("Sample transaction index")
# 색상 막대를 표시합니다.
plt.colorbar(label="Purchased: 1 / Not purchased: 0")
# 그래프를 출력합니다.
plt.show()
calculate_itemset_supprt함수를 만들어 특정 아이템 조합이 전체 거래에서 얼마나 자주 함께 등장하는지 계산한다.
전체 거래에서 : 수령한 item_indices를 selected해 selected.prod() 한 거래안에서 선택 아이템들이 모두 1인지 확인한다. 또 이를 평균을 계산해 return한다.
테스트로 상위 2개 head(2) 아이템이 함께 등장하는 비율을 계산해 return 해본다 .
# ============================================================
# 9. itemset 지지도 계산 함수 정의
# ============================================================
# 이 함수는 특정 아이템 조합이 전체 거래에서 얼마나 자주 함께 등장하는지 계산합니다.
# 예: ['whole milk', 'yogurt']가 전체 거래 중 몇 %에서 함께 등장하는지 계산합니다.
def calculate_itemset_support(X, item_indices):
# item_indices는 계산할 아이템들의 열 번호 리스트입니다.
# 예: [10, 25]는 10번 아이템과 25번 아이템을 의미합니다.
item_indices = list(item_indices)
# X[:, item_indices]는 전체 거래에서 해당 아이템 열들만 선택합니다.
selected = X[:, item_indices]
# selected.prod(dim=1)은 한 거래 안에서 선택 아이템들이 모두 1인지 확인합니다.
# 모두 구매했으면 1, 하나라도 구매하지 않았으면 0이 됩니다.
both_purchased = selected.prod(dim=1)
# 평균을 계산하면 전체 거래 중 해당 itemset이 등장한 비율이 됩니다.
support = both_purchased.mean().item()
# 계산된 지지도를 반환합니다.
return support
# 테스트: 지지도 상위 2개 아이템이 함께 등장하는 비율을 계산합니다.
test_items = item_freq_df.head(2)["item"].tolist()
# 아이템 이름을 열 번호로 변환합니다.
test_indices = [item_to_idx[item] for item in test_items]
# 두 아이템의 동시 등장 지지도를 계산합니다.
test_support = calculate_itemset_support(X, test_indices)
# 결과를 출력합니다.
print("테스트 아이템:", test_items)
print("동시 등장 지지도:", test_support)
최소 support 지지도와 최소 confience 신뢰도를 추해 최소 지지도 이상인 아이템만 frequent_single_items에 할당한다.
frequent_itemsets 리스트를 초기화한다.
for문으로 위 frequent_single_items 를 돌며 지지도를 가져와 리스트에 저장한다.
for문으로 아이템 조합을 생성해 MIN_LEN = 2 만큼 돌려 frequent_single_items에서 python의 combination 함수를 이용해서 가능한모든 상품 k조합을 생성한다.
calculate_itemset_support 앞서 만들어놓은 두 제품의 조합이 얼마나 자주 등장하는지를 계산해 이중 최소 지지도 조건 MIN_SUPPORT을 만족하는 itemsets만 저장해 출력한다.
# ============================================================
# 10. Torch 기반 간단 Apriori 후보 itemset 생성
# ============================================================
# 여기서는 2개, 3개, 4개 아이템 조합까지 계산합니다.
# 데이터가 크면 모든 조합 계산이 오래 걸리므로, 먼저 최소 지지도를 만족하는 단일 아이템만 후보로 사용합니다.
# 최소 지지도입니다.
MIN_SUPPORT = 0.007
# 최소 신뢰도입니다.
MIN_CONFIDENCE = 0.25
# 규칙을 만들 최소 itemset 길이입니다.
# minlen = 2는 최소 2개 이상의 아이템으로 규칙을 만들겠다는 의미입니다.
MIN_LEN = 2
# 최대 itemset 길이입니다.
# 4개 아이템 규칙까지 확인하므로 4로 둡니다.
MAX_LEN = 4
# 단일 아이템 중 최소 지지도 이상인 아이템만 후보로 선택합니다.
frequent_single_items = [
item_to_idx[row.item]
for row in item_freq_df.itertuples(index=False)
if row.support >= MIN_SUPPORT
]
# 후보 단일 아이템 수를 출력합니다.
print("최소 지지도 이상 단일 아이템 수:", len(frequent_single_items))
# frequent_itemsets 딕셔너리는 itemset 튜플을 key, 지지도를 value로 저장합니다.
# 예: {(10, 25): 0.04}
frequent_itemsets = {}
# 1개 아이템 지지도도 규칙 계산의 분모로 필요하므로 저장합니다.
for item_idx in frequent_single_items:
# itemset은 항상 튜플 형태로 저장합니다.
itemset = (item_idx,)
# 이미 계산된 단일 아이템 지지도를 가져옵니다.
support = item_support_tensor[item_idx].item()
# 딕셔너리에 저장합니다.
frequent_itemsets[itemset] = support
# 2개부터 MAX_LEN개까지 아이템 조합을 생성합니다.
for k in range(2, MAX_LEN + 1):
# 현재 길이 k의 frequent itemset 개수를 세기 위한 변수입니다.
count_k = 0
# 최소 지지도를 만족하는 단일 아이템들에서 k개 조합을 생성합니다.
for itemset in combinations(frequent_single_items, k):
# 현재 itemset의 지지도를 torch 연산으로 계산합니다.
support = calculate_itemset_support(X, itemset)
# 최소 지지도 조건을 만족하는 itemset만 저장합니다.
if support >= MIN_SUPPORT:
# itemset을 정렬된 튜플로 저장합니다.
frequent_itemsets[tuple(sorted(itemset))] = support
# 현재 길이의 빈발 itemset 수를 1 증가시킵니다.
count_k += 1
# 길이별 빈발 itemset 수를 출력합니다.
print(f"길이 {k} 빈발 itemset 수:", count_k)
# 전체 저장된 빈발 itemset 수를 출력합니다.
print("전체 빈발 itemset 수:", len(frequent_itemsets))
generate_rules 함수를 만들어 연관규칙 rules를 생성해보자.
'우유, 빵'이라는 빈발 항목집합이 발견되었다면 우유 - 빵, 빵 - 우유와 같은 규칙을 만들어 서로의 구매 패턴을 분석하는 과정이다 .
itemset를 돌려 range(1, n_items)로 항목에서의 경우의 수를 따져
combinations 여러아이템, 조합을 만들어
tuple로 sorted, rhs에서는 lhs를 제외한다.
이 둘의 지지도를 가져와 신뢰도를 계산한다.
이때 min_confidence 최소 신뢰도 이상인 규칙만 저장해 confidence/rhs_support 로 향상도 lift를 계산해 규칙이 우연히 발생한것인지 실제 관련성이 있는지를 평가하며 confidence가 0.8이고 support가 0.4라면 2로 구매확률이 일반고객보다 2배 높다는 의미가 된다.
아이템 번호를 다시 이름으로 변환해 rules에 할당하고 출력한다 .
rules_df 에 generate_rules로 최소조신뢰도조건을 적용해 앞서 만든 함수를 활용하고
규칙의 수와 규칙들을 head(7)만큼 확인한다 .
# ============================================================
# 11. 연관규칙 생성 함수 정의
# ============================================================
# 연관규칙은 A -> B 형태입니다.
# 예: {root vegetables} -> {whole milk}
# support(A -> B) = A와 B가 함께 등장한 거래 비율
# confidence(A -> B) = A를 산 거래 중 B도 산 거래 비율 = support(A ∪ B) / support(A)
# lift(A -> B) = confidence(A -> B) / support(B)
# lift가 1보다 크면 A를 샀을 때 B를 살 가능성이 일반적인 B 구매 가능성보다 높다는 의미입니다.
def generate_rules(frequent_itemsets, min_confidence=0.25):
# 생성된 규칙들을 저장할 리스트입니다.
rules = []
# 빈발 itemset 하나씩 반복합니다.
for itemset, itemset_support in frequent_itemsets.items():
# 규칙은 최소 2개 이상의 아이템이 있어야 만들 수 있습니다.
if len(itemset) < 2:
continue
# itemset 안의 아이템 개수입니다.
n_items = len(itemset)
# 왼쪽 조건부 antecedent의 길이를 1부터 n_items-1까지 바꿔가며 규칙을 만듭니다.
for lhs_len in range(1, n_items):
# itemset에서 lhs_len개를 뽑아 왼쪽 조건부 후보를 만듭니다.
for lhs in combinations(itemset, lhs_len):
# lhs는 규칙의 왼쪽입니다.
lhs = tuple(sorted(lhs))
# rhs는 전체 itemset에서 lhs에 없는 나머지 아이템입니다.
rhs = tuple(sorted(set(itemset) - set(lhs)))
# lhs 지지도를 가져옵니다.
lhs_support = frequent_itemsets.get(lhs)
# rhs 지지도를 가져옵니다.
rhs_support = frequent_itemsets.get(rhs)
# lhs 또는 rhs 지지도가 없으면 규칙 계산이 불가능하므로 건너뜁니다.
if lhs_support is None or rhs_support is None:
continue
# confidence = support(lhs ∪ rhs) / support(lhs)
confidence = itemset_support / lhs_support
# confidence가 최소 신뢰도 이상인 규칙만 저장합니다.
if confidence >= min_confidence:
# lift = confidence / support(rhs)
lift = confidence / rhs_support
# lhs 아이템 번호를 아이템 이름으로 변환합니다.
lhs_items = tuple(idx_to_item[idx] for idx in lhs)
# rhs 아이템 번호를 아이템 이름으로 변환합니다.
rhs_items = tuple(idx_to_item[idx] for idx in rhs)
# 하나의 규칙 정보를 딕셔너리로 저장합니다.
rules.append({
"lhs": lhs_items,
"rhs": rhs_items,
"support": itemset_support,
"confidence": confidence,
"lift": lift,
"lhs_support": lhs_support,
"rhs_support": rhs_support,
"rule_length": len(itemset)
})
# 규칙 리스트를 pandas DataFrame으로 변환합니다.
return pd.DataFrame(rules)
# 최소 신뢰도 조건을 적용하여 규칙을 생성합니다.
rules_df = generate_rules(frequent_itemsets, MIN_CONFIDENCE)
# 보기 좋게 lhs와 rhs를 문자열로 바꾼 열을 추가합니다.
rules_df["rule"] = rules_df.apply(
lambda row: "{" + ", ".join(row["lhs"]) + "} -> {" + ", ".join(row["rhs"]) + "}",
axis=1
)
# 생성된 규칙 수를 출력합니다.
print("생성된 연관규칙 수:", len(rules_df))
# 처음 7개 규칙을 확인합니다.
rules_df[["rule", "support", "confidence", "lift", "rule_length"]].head(7)생성된 연관규칙 수: 366
rule support confidence lift rule_length
0 {other vegetables} -> {whole milk} 0.074835 0.386758 1.513634 2
1 {whole milk} -> {other vegetables} 0.074835 0.292877 1.513634 2
2 {rolls/buns} -> {whole milk} 0.056634 0.307905 1.205032 2
3 {yogurt} -> {whole milk} 0.056024 0.401603 1.571735 2
4 {bottled water} -> {whole milk} 0.034367 0.310948 1.216940 2
5 {root vegetables} -> {whole milk} 0.048907 0.448694 1.756031 2
6 {tropical fruit} -> {whole milk} 0.042298 0.403101 1.577595 2
if rules_df이 있다면 규칙 길이별 개수를, 요약통계를 계산해 describe, 출력한다.
support와 confidence와 lift가 들어있는 reules_df에서는 366개의 연관규칙이 전체적으로 어떤 특성을 가지는지 알려준다.
support 평균적으로 규칙 상품 조합이 전체거래의 약 1.29%에서 발생했다.
confidence 평균적으로 A를 구매한 고객중 37%가 B도 구매했다 .
lift A를 구매한 사람은 일반고객보다 B를 약 2배 더 자주 구매했다는사실을 알 수 있다.
이때 lift에서 min이 0.99로 거의 1인데 생성된 규칙중에 별 의미없는 규칙도 일부 포함되어있음을 알 수 있다 .
# ============================================================
# 12. 연관규칙 요약
# ============================================================
# 규칙이 하나 이상 생성되었는지 확인합니다.
if len(rules_df) > 0:
# 규칙 길이별 개수를 계산합니다.
length_summary = rules_df["rule_length"].value_counts().sort_index()
# 규칙 품질 지표의 요약 통계를 계산합니다.
metric_summary = rules_df[["support", "confidence", "lift"]].describe()
# 규칙 길이별 개수를 출력합니다.
print("규칙 길이별 개수")
print(length_summary)
# 지지도, 신뢰도, 향상도 요약 통계를 출력합니다.
print("규칙 품질 지표 요약")
display(metric_summary)
else:
# 규칙이 없으면 기준을 낮추라는 안내를 출력합니다.
print("생성된 규칙이 없습니다. MIN_SUPPORT 또는 MIN_CONFIDENCE 값을 낮춰 보세요.")support confidence lift
count 366.000000 366.000000 366.000000
mean 0.012900 0.373716 2.023483
std 0.008807 0.093310 0.557360
min 0.007016 0.250000 0.993237
25% 0.008134 0.295998 1.607848
50% 0.009659 0.354851 1.913470
75% 0.013726 0.441174 2.344046
max 0.074835 0.638889 4.454258
lift가 클수록 lhs와 rhs의 연관성이 강하다고 해석할 수 있으니 내림차순으로 정렬해 출력해보자.
# ============================================================
# 13. lift 기준 상위 규칙 확인
# ============================================================
# lift가 큰 규칙일수록 lhs와 rhs의 연관성이 강하다고 해석할 수 있습니다.
# 단, support가 너무 낮은 규칙은 우연일 수 있으므로 함께 확인해야 합니다.
# lift 기준으로 내림차순 정렬합니다.
top_lift_rules = rules_df.sort_values("lift", ascending=False).reset_index(drop=True)
# 상위 10개 규칙을 출력합니다.
top_lift_rules[["rule", "support", "confidence", "lift"]].head(10)rule support confidence lift
0 {root vegetables, tropical fruit} -> {other ve... 0.007016 0.333333 4.454258
1 {root vegetables, yogurt} -> {other vegetables... 0.007829 0.303150 4.050919
2 {herbs} -> {root vegetables} 0.007016 0.431250 3.956477
3 {berries} -> {whipped/sour cream} 0.009049 0.272171 3.796885
4 {other vegetables, tropical fruit, whole milk}... 0.007016 0.410714 3.768073
5 {beef, other vegetables} -> {root vegetables} 0.007931 0.402062 3.688692
6 {other vegetables, tropical fruit} -> {pip fruit} 0.009456 0.263456 3.482649
7 {tropical fruit, yogurt} -> {other vegetables,... 0.007626 0.260417 3.479889
8 {beef, whole milk} -> {root vegetables} 0.008033 0.377990 3.467851
9 {other vegetables, pip fruit} -> {tropical fruit} 0.009456 0.361868 3.448613
또 찾고싶은 아이템이 있다면 rules_df 에 lhs, rhs에 apply() 할당해 규칙리스트에서 조회해볼 수도 있다 .
# ============================================================
# 14. 특정 아이템이 포함된 규칙 검색: berries
# ============================================================
# lhs 또는 rhs 중 어느 쪽이든 berries가 포함된 규칙을 찾습니다.
# 찾고 싶은 아이템 이름을 지정합니다.
TARGET_ITEM = "berries"
# lhs 또는 rhs 튜플 안에 TARGET_ITEM이 들어 있는지 검사합니다.
berry_rules = rules_df[
rules_df["lhs"].apply(lambda items: TARGET_ITEM in items) |
rules_df["rhs"].apply(lambda items: TARGET_ITEM in items)
].copy()
# lift 기준으로 정렬합니다.
berry_rules = berry_rules.sort_values("lift", ascending=False).reset_index(drop=True)
# berries 관련 규칙 수를 출력합니다.
print(f"'{TARGET_ITEM}' 포함 규칙 수:", len(berry_rules))
# 관련 규칙을 출력합니다.
berry_rules[["rule", "support", "confidence", "lift"]].head(20)
위 내용들을 해석하는 코드를 만들어보자 .
# ============================================================
# 15. 규칙 해석 예시
# ============================================================
# 가장 lift가 높은 규칙 하나를 선택합니다.
if len(top_lift_rules) > 0:
# 첫 번째 행을 가져옵니다.
best_rule = top_lift_rules.iloc[0]
# 규칙 문자열을 가져옵니다.
rule_text = best_rule["rule"]
# 지지도를 가져옵니다.
support = best_rule["support"]
# 신뢰도를 가져옵니다.
confidence = best_rule["confidence"]
# 향상도를 가져옵니다.
lift = best_rule["lift"]
# 해석 결과를 출력합니다.
print("선택 규칙:", rule_text)
print(f"지지도 support = {support:.4f}")
print(f"신뢰도 confidence = {confidence:.4f}")
print(f"향상도 lift = {lift:.4f}")
print()
print("해석:")
print(f"- 전체 거래 중 이 규칙의 왼쪽과 오른쪽 아이템이 함께 등장한 비율은 약 {support*100:.2f}%입니다.")
print(f"- 왼쪽 아이템을 구매한 거래 중 오른쪽 아이템도 함께 구매한 비율은 약 {confidence*100:.2f}%입니다.")
print(f"- lift가 {lift:.2f}이므로, 왼쪽 아이템 구매 시 오른쪽 아이템 구매 가능성이 일반적인 경우보다 약 {lift:.2f}배 높다고 볼 수 있습니다.")
else:
# 규칙이 없을 때 출력합니다.
print("해석할 규칙이 없습니다.")선택 규칙: {root vegetables, tropical fruit} -> {other vegetables, whole milk}
지지도 support = 0.0070
신뢰도 confidence = 0.3333
향상도 lift = 4.4543
해석:
- 전체 거래 중 이 규칙의 왼쪽과 오른쪽 아이템이 함께 등장한 비율은 약 0.70%입니다.
- 왼쪽 아이템을 구매한 거래 중 오른쪽 아이템도 함께 구매한 비율은 약 33.33%입니다.
- lift가 4.45이므로, 왼쪽 아이템 구매 시 오른쪽 아이템 구매 가능성이 일반적인 경우보다 약 4.45배 높다고 볼 수 있습니다.
클러스터링 Clustering
지도학습은 정답 label이있다. 이 라벨을 맞추는 것이 목표가 된다.
반면 클러스터링은 비지도학습의 대표적인 기법으로정답이 없고 비슷한것들끼리 묶어보자가 목표이다 .
그러기에 거리 Distance가 중요하다 .가까우면 같은 군집, 멀면 다른 군집으로 분류가 가능하기 때문이다 .그래서 거리계산이 핵심이다 .
거리계산방법
- 유클리드거리: 두점의 직선거리, 클러스터링에서 가장 많이 사용한다.
- 고차원 거리: 실제 데이터는 2차원이 아니라 Iris 데이터만 봐도 꽃받침 길이, 꽃받침 너비, 꽃잎길이, 꽃잎 너비 등의 4차원 데이터이다. 이에 따른 확장 거리공식.
- K-Means
가장 많이 쓰는 군집화 K개의 그룹을 만들어 중심정생성, 가까운 중심점으로 배정한다.
- 계층적 클러스터링 Hierarchical Vlustering K-Means는 최종결과만 준다면 계층형 클러스터링은 어떻게 합쳐졌는지 과정까지 dendrogram으로 보여준다.
계층적 클러스터링은 거리기준이 있다 .
- single linkage로 점 하나만 가까워도 합치는데 빠른대신에 사슬모양 군집이 생성될 수 있다.
- complete linkage 가장 먼점 기준 군집전체가 가까워야한다.
- average linkage 평균거리 사용한다. single linkage와 complete linkage의 중간이라 볼 수 있다 .
* 사슬현상 Chaning Effect: 데이터가 길게 늘어서있을때 인접한 점들끼리만 가까우면 게속 연결되어 긴 군집이 되어버린다. 즉 실제로는 여러 그룹일수도있는데도 하나의 군집으로 묶일 수 있다는 것.
DBSCAN Density-Based Spatial Clustering 밀도기반 군집화
밀도를 기준으로 군집을 찾는 알고리즘.
K-Means에서는 K를 미리 알아야하지만 DBSCAN에서는 몰라도 된다 eps반경으로 min_samples 반경 안 최소 데이터수에 따라 core인지 아닌지 판단해 corepoint를 생성하는 것. 이때 중심점을 core point, 군집경계를 border point, 어디에도 속하지않음을 noise point, 이상치라 한다 .즉 DBSCAN은 군집화를 하면서 이상치 탐지를 동시에 수행한다고 보겠다.
평가하기, 실루엣 계수 silhouette score
군집이 잘 되었는지 평가하는 점수로 같은 군집과 평균거리는 작을수록 좋고 가장 가까운 다른 군집 거리는 멀수록 좋다. 이를 공식으로해 0을 경계로하고 1에 가까울수록 매우 좋은 군집, -1에 가까울수록 잘못 군집화되었다고 판단할 수 있도록 한다.
샘플코드 uci_iris_torch_kmeans_clustering_colab을 분석해보자.
import
클러스터 내부 응집도와 군집간 분리도를 평가하기 위해
sklearn.metrics silhouette_score, adjusted_rand_score, normalized_mutual_info_score를 사용한다.
난수고정 및 장치출력.
# 표 형태의 데이터를 읽고 처리하기 위해 pandas를 불러옵니다.
import pandas as pd
# 배열 계산과 난수 처리를 위해 numpy를 불러옵니다.
import numpy as np
# 텐서 계산과 K-Means 직접 구현을 위해 PyTorch를 불러옵니다.
import torch
# 그래프 시각화를 위해 matplotlib의 pyplot을 불러옵니다.
import matplotlib.pyplot as plt
# 클러스터 내부 응집도와 군집 간 분리도를 평가하기 위해 silhouette_score를 불러옵니다.
from sklearn.metrics import silhouette_score
# 실제 라벨과 클러스터 결과의 일치 정도를 평가하기 위해 adjusted_rand_score를 불러옵니다.
from sklearn.metrics import adjusted_rand_score
# 실제 라벨과 클러스터 결과가 공유하는 정보량을 평가하기 위해 normalized_mutual_info_score를 불러옵니다.
from sklearn.metrics import normalized_mutual_info_score
# GPU가 사용 가능하면 GPU를 사용하고, 아니면 CPU를 사용하도록 연산 장치를 설정합니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# PyTorch 난수 결과를 고정하여 같은 코드를 다시 실행해도 비슷한 결과가 나오도록 합니다.
torch.manual_seed(42)
# NumPy 난수 결과도 고정하여 실험 재현성을 높입니다.
np.random.seed(42)
# 현재 선택된 연산 장치를 출력합니다.
print("사용 장치:", device)
데이터셋 다운로드 및 데이터 구조확인
# UCI Machine Learning Repository에 공개된 Iris 데이터셋 원본 CSV 주소를 지정합니다.
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# 원본 CSV 파일에는 컬럼명이 없으므로 사용할 컬럼명을 직접 리스트로 작성합니다.
columns = [
"sepal_length", # 꽃받침 길이(cm)를 의미하는 수치형 특성입니다.
"sepal_width", # 꽃받침 너비(cm)를 의미하는 수치형 특성입니다.
"petal_length", # 꽃잎 길이(cm)를 의미하는 수치형 특성입니다.
"petal_width", # 꽃잎 너비(cm)를 의미하는 수치형 특성입니다.
"species" # 붓꽃 품종 이름을 의미하는 문자열 라벨입니다.
]
# 인터넷 URL에서 CSV 데이터를 읽어 pandas DataFrame으로 저장합니다.
df = pd.read_csv(url, names=columns)
# 혹시 빈 줄이나 결측 행이 포함된 경우를 대비하여 결측값이 있는 행을 제거합니다.
df = df.dropna()
# 데이터가 정상적으로 읽혔는지 처음 5개 행을 확인합니다.
df.head()# 데이터의 행과 열 개수를 출력합니다.
print("데이터 크기:", df.shape)
# 각 컬럼의 자료형과 결측값 여부를 확인합니다.
print("\n데이터 정보:")
print(df.info())
# 품종별 데이터 개수를 확인합니다.
print("\n품종별 개수:")
print(df["species"].value_counts())
# 수치형 특성들의 평균, 표준편차, 최솟값, 최댓값 등을 확인합니다.
df.describe()
k-means에 사용할 k들을 추출하는것. 수치형 특성 컬럼만 선택했다.
품종명을 숫자라벨로 바꾸기위해 enumerate를 사용했다.
이로써 입력특성 데이터와 평가용 라벨이 분리되었다.
tensor 텐서로 변환.
# K-Means 클러스터링에 사용할 수치형 특성 컬럼만 선택합니다.
feature_cols = ["sepal_length", "sepal_width", "petal_length", "petal_width"]
# 선택한 특성들을 NumPy 배열로 변환하고, PyTorch 연산에 적합하도록 float32 타입으로 변환합니다.
X_np = df[feature_cols].values.astype(np.float32)
# 품종명을 숫자 라벨로 바꾸기 위한 매핑 딕셔너리를 생성합니다.
label_map = {name: idx for idx, name in enumerate(sorted(df["species"].unique()))}
# 실제 품종 라벨을 숫자 배열로 변환합니다.
y_true = df["species"].map(label_map).values
# 입력 데이터를 PyTorch 텐서로 변환하고 CPU 또는 GPU 장치로 이동합니다.
X = torch.tensor(X_np, dtype=torch.float32, device=device)
# 입력 텐서의 크기를 출력합니다.
print("입력 텐서 크기:", X.shape)
# 품종명과 숫자 라벨의 매핑 관계를 출력합니다.
print("라벨 매핑:", label_map)
데이터표준화
특성들의 단위와 크기를 맞춰 특성이 지나치게 큰영향을 주는것을 막아보자.
표준화 공식을 사용하면 평균을 0, 표준편차를 1로 맞출 수 있다 .
앞서 나눴던데이터중 특성의 평균, 표준편차를 계산하되 표준편차가 0일때 작은 값을적용해서 x_scaled 변수에 할당한다.
# 각 특성별 평균을 계산합니다.
mean = X.mean(dim=0, keepdim=True)
# 각 특성별 표준편차를 계산합니다.
std = X.std(dim=0, keepdim=True)
# 표준편차가 0일 때 나눗셈 오류가 발생하지 않도록 작은 값을 준비합니다.
eps = 1e-8
# 표준화 공식 z = (x - 평균) / 표준편차를 적용합니다.
X_scaled = (X - mean) / (std + eps)
# 표준화 후 각 특성의 평균이 0에 가까운지 확인합니다.
print("표준화 후 평균:", X_scaled.mean(dim=0))
# 표준화 후 각 특성의 표준편차가 1에 가까운지 확인합니다.
print("표준화 후 표준편차:", X_scaled.std(dim=0))표준화 후 평균: tensor([-4.7247e-07, -3.1312e-07, 9.4970e-08, 1.0530e-07])
표준화 후 표준편차: tensor([1., 1., 1., 1.])
K-Means 라이브러리를 사용할 수 있지만
from sklearn.cluster import KMeans
kmeans = KMeans(
n_clusters=3,
random_state=42
)
labels = kmeans.fit_predict(X)
학습목적으로 PyTorch로 직접 구현해보자.
torch_kmeans함수를 만들자.
random_indices 변수에 샘플들중 k개를 random 무작위로 선택해 초기 중심점 인덱스로 사용하기로하자.
위 k개의 샘플들을 중심점 random_indices으로 clone 복사하고 이 random 중심점이 안정될때까지 max_iters번 for돌린다.
torch.cdist()로 각 샘플과 중심점 사이의 유클리드 거리를 계산해
torch.argmin() 가장 가까운 min 중심점 번호에 label들을 배정해 labels에 할당한다.
k번 for문으로 돌려 new_centroids에 배정된 labels들을 선택해 새 중심점으로 사용 할당하되 샘플이 하나도 없다면 기존 중심점을 유지하도록 한다.
이 생성된 new_centroids 리스트들을 torch.stack으로 하나의 torch로 변환해
centroids 중심점에 갱신한다.
이전 중심점과 새 중심점 사이의 거리를 torch.norm으로 계산한다. (진행상황을 보기위한 코드)
final_distances에 이 centroids 중심점을 기준으로 각 x샘플과 torch.cdist()사이거리를 다시 계산해 torch.argmin() 가까운 min 중심점을 기준으로 클러스터 라벨로 지정해 이 라벨과 중심점을 return한다.
# PyTorch 텐서 연산만으로 K-Means 알고리즘을 직접 구현합니다.
def torch_kmeans(X, k=3, max_iters=100, tol=1e-4):
# 전체 샘플 개수를 가져옵니다.
n_samples = X.shape[0]
# 전체 샘플 중 k개를 무작위로 선택하여 초기 중심점 인덱스로 사용합니다.
random_indices = torch.randperm(n_samples, device=X.device)[:k]
# 선택된 샘플을 초기 중심점으로 복사합니다.
centroids = X[random_indices].clone()
# 중심점이 안정될 때까지 최대 max_iters번 반복합니다.
for iteration in range(max_iters):
# 각 샘플과 각 중심점 사이의 유클리드 거리를 계산합니다.
distances = torch.cdist(X, centroids)
# 각 샘플을 가장 가까운 중심점 번호에 배정합니다.
labels = torch.argmin(distances, dim=1)
# 새 중심점들을 저장할 리스트를 만듭니다.
new_centroids = []
# 각 클러스터 번호에 대해 중심점을 다시 계산합니다.
for cluster_id in range(k):
# 현재 클러스터에 배정된 샘플만 선택합니다.
cluster_points = X[labels == cluster_id]
# 클러스터에 샘플이 하나도 없는 경우 기존 중심점을 유지합니다.
if cluster_points.shape[0] == 0:
new_centroids.append(centroids[cluster_id])
# 클러스터에 샘플이 있으면 해당 샘플들의 평균을 새 중심점으로 사용합니다.
else:
new_centroids.append(cluster_points.mean(dim=0))
# 리스트 형태의 중심점들을 하나의 텐서로 변환합니다.
new_centroids = torch.stack(new_centroids)
# 이전 중심점과 새 중심점 사이의 전체 이동 거리를 계산합니다.
shift = torch.norm(new_centroids - centroids)
# 중심점을 새 값으로 갱신합니다.
centroids = new_centroids
# 10회마다 중심점 이동 거리를 출력하여 학습 진행 상황을 확인합니다.
if iteration % 10 == 0:
print(f"반복 {iteration:03d} | 중심점 이동 거리: {shift.item():.6f}")
# 중심점 이동 거리가 매우 작으면 수렴했다고 판단하고 반복을 종료합니다.
if shift < tol:
print(f"수렴 완료: {iteration + 1}회 반복")
break
# 최종 중심점 기준으로 각 샘플과 중심점 사이의 거리를 다시 계산합니다.
final_distances = torch.cdist(X, centroids)
# 최종적으로 가장 가까운 중심점 번호를 클러스터 라벨로 지정합니다.
final_labels = torch.argmin(final_distances, dim=1)
# 최종 클러스터 라벨과 중심점을 반환합니다.
return final_labels, centroids
위 만들어놓는 torch_kmeans() 함수를 활용해 클러스터링을 실행해보자.
# Iris 데이터셋은 실제 품종이 3개이므로 실습에서는 클러스터 개수를 3으로 설정합니다.
k = 3
# 표준화된 데이터를 이용하여 PyTorch K-Means 클러스터링을 실행합니다.
cluster_labels_tensor, centroids = torch_kmeans(X_scaled, k=k, max_iters=100, tol=1e-4)
# 평가와 시각화를 위해 클러스터 라벨을 CPU의 NumPy 배열로 변환합니다.
cluster_labels = cluster_labels_tensor.cpu().numpy()
# 최종 중심점을 CPU의 NumPy 배열로 변환하여 출력합니다.
print("\n최종 중심점:")
print(centroids.cpu().numpy())
# 각 클러스터에 몇 개의 샘플이 배정되었는지 계산합니다.
unique_clusters, cluster_counts = np.unique(cluster_labels, return_counts=True)
# 클러스터별 샘플 수를 출력합니다.
print("\n클러스터별 샘플 수:")
for c, count in zip(unique_clusters, cluster_counts):
print(f"클러스터 {c}: {count}개")반복 000 | 중심점 이동 거리: 1.657920
수렴 완료: 10회 반복
최종 중심점:
[[-0.80332804 1.3313134 -1.2818892 -1.2062225 ]
[ 0.56909657 -0.36478066 0.68877673 0.66101205]
[-1.3148565 -0.34468785 -1.1410047 -1.12991 ]]
클러스터별 샘플 수:
클러스터 0: 32개
클러스터 1: 96개
클러스터 2: 22개
결과를 평가하자.
앞서 import했던 silhouette_score, adjusted_rand_score, normalized_mutual_info_score를 출력한다.
# 라벨 없이 클러스터 품질을 평가하는 Silhouette Score를 계산합니다.
sil_score = silhouette_score(X_scaled.cpu().numpy(), cluster_labels)
# 실제 품종 라벨과 클러스터 결과의 일치 정도를 ARI로 평가합니다.
ari_score = adjusted_rand_score(y_true, cluster_labels)
# 실제 품종 라벨과 클러스터 결과의 정보 공유 정도를 NMI로 평가합니다.
nmi_score = normalized_mutual_info_score(y_true, cluster_labels)
# Silhouette Score를 출력합니다.
print(f"Silhouette Score: {sil_score:.4f}")
# Adjusted Rand Index를 출력합니다.
print(f"Adjusted Rand Index: {ari_score:.4f}")
# Normalized Mutual Information을 출력합니다.
print(f"Normalized Mutual Information: {nmi_score:.4f}")Silhouette Score: 0.4787
Adjusted Rand Index: 0.4290
Normalized Mutual Information: 0.5874
SVD 기반의 PCA로 2차원으로 차원축소를해보자.
# PCA는 평균이 제거된 데이터를 기준으로 분산이 큰 방향을 찾으므로 평균 중심화를 수행합니다.
X_centered = X_scaled - X_scaled.mean(dim=0, keepdim=True)
# PyTorch의 특이값 분해 함수를 사용하여 주성분 방향을 계산합니다.
U, S, Vh = torch.linalg.svd(X_centered, full_matrices=False)
# 가장 큰 분산을 설명하는 상위 2개의 주성분 방향을 선택합니다.
components_2d = Vh[:2].T
# 4차원 데이터를 2차원 주성분 공간으로 투영합니다.
X_pca_2d = X_centered @ components_2d
# matplotlib에서 사용할 수 있도록 CPU의 NumPy 배열로 변환합니다.
X_pca_2d_np = X_pca_2d.cpu().numpy()
# 변환된 데이터의 크기를 출력합니다.
print("PCA 변환 후 크기:", X_pca_2d_np.shape)
산점도로 시각화하자.
# 클러스터링 결과를 2차원 산점도로 시각화합니다.
plt.figure(figsize=(8, 6))
# 각 클러스터별로 점을 나누어 그립니다.
for cluster_id in range(k):
# 현재 클러스터에 속한 샘플만 선택합니다.
mask = cluster_labels == cluster_id
# 첫 번째 주성분과 두 번째 주성분을 좌표로 사용하여 산점도를 그립니다.
plt.scatter(
X_pca_2d_np[mask, 0],
X_pca_2d_np[mask, 1],
label=f"Cluster {cluster_id}",
alpha=0.8
)
# 그래프 제목을 설정합니다.
plt.title("PyTorch K-Means Clustering Result on UCI Iris Dataset")
# x축 이름을 설정합니다.
plt.xlabel("Principal Component 1")
# y축 이름을 설정합니다.
plt.ylabel("Principal Component 2")
# 범례를 표시합니다.
plt.legend()
# 격자를 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()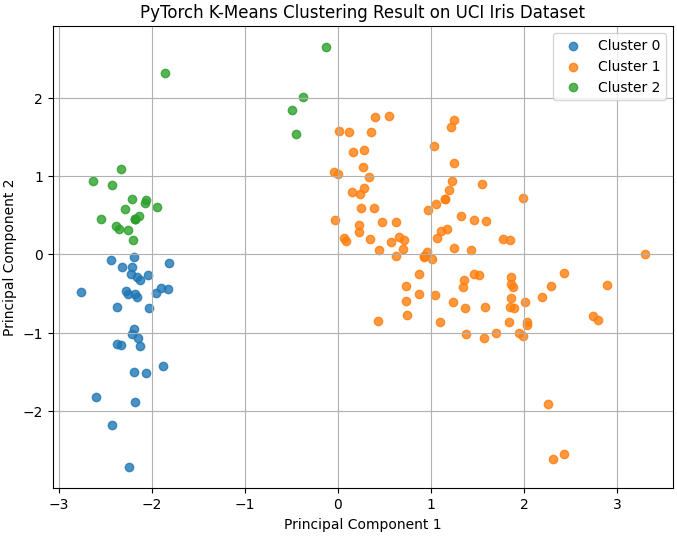
실제 정답과 클러스터 결과를 비교해보자 .
# 원본 데이터프레임을 복사하여 결과 확인용 데이터프레임을 만듭니다.
result_df = df.copy()
# 각 샘플의 클러스터 번호를 새 컬럼으로 추가합니다.
result_df["cluster"] = cluster_labels
# 실제 품종과 클러스터 번호의 관계를 교차표로 확인합니다.
cross_tab = pd.crosstab(result_df["species"], result_df["cluster"])
# 교차표를 출력합니다.
cross_tabcluster 0 1 2
species
Iris-setosa 32 0 18
Iris-versicolor 0 46 4
Iris-virginica 0 50 0
k값도 비교해보자.
# 비교할 클러스터 개수 목록을 만듭니다.
k_values = list(range(2, 7))
# 각 K값의 Silhouette Score를 저장할 리스트를 만듭니다.
silhouette_scores = []
# K값을 2부터 6까지 바꾸면서 클러스터링을 반복합니다.
for current_k in k_values:
# 현재 K값으로 PyTorch K-Means를 실행합니다.
labels_tensor, _ = torch_kmeans(X_scaled, k=current_k, max_iters=100, tol=1e-4)
# 평가 지표 계산을 위해 클러스터 라벨을 NumPy 배열로 변환합니다.
labels_np = labels_tensor.cpu().numpy()
# 현재 K값의 Silhouette Score를 계산합니다.
score = silhouette_score(X_scaled.cpu().numpy(), labels_np)
# 계산된 점수를 리스트에 저장합니다.
silhouette_scores.append(score)
# 현재 K값과 점수를 출력합니다.
print(f"K={current_k}, Silhouette Score={score:.4f}")반복 000 | 중심점 이동 거리: 0.705029
수렴 완료: 2회 반복
K=2, Silhouette Score=0.5802
반복 000 | 중심점 이동 거리: 1.144167
수렴 완료: 6회 반복
K=3, Silhouette Score=0.4554
반복 000 | 중심점 이동 거리: 0.985700
수렴 완료: 7회 반복
K=4, Silhouette Score=0.4179
반복 000 | 중심점 이동 거리: 1.052744
수렴 완료: 6회 반복
K=5, Silhouette Score=0.3535
반복 000 | 중심점 이동 거리: 2.649440
반복 010 | 중심점 이동 거리: 0.036695
수렴 완료: 16회 반복
K=6, Silhouette Score=0.3486
k값별 silhouette score변화를 시각화하자.
# K값별 Silhouette Score 변화를 선 그래프로 시각화합니다.
plt.figure(figsize=(8, 5))
# x축은 K값, y축은 Silhouette Score로 선 그래프를 그립니다.
plt.plot(k_values, silhouette_scores, marker="o")
# 그래프 제목을 설정합니다.
plt.title("Silhouette Score by Number of Clusters")
# x축 이름을 설정합니다.
plt.xlabel("Number of Clusters K")
# y축 이름을 설정합니다.
plt.ylabel("Silhouette Score")
# x축 눈금을 K값 목록으로 지정합니다.
plt.xticks(k_values)
# 격자를 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()
'SK 네트웍스 AI 캠프' 카테고리의 다른 글
| SK 네트웍스 AI 캠프 - 3 _딥러닝 - Day24_딥러닝개념_프레임워크설치 (0) | 2026.06.08 |
|---|---|
| [SK네트웍스 Family AI 캠프] 32기 6주차 회고: Day20 ~ Day23 + 5월 종합 (0) | 2026.06.05 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day22_머신러닝 차원축소 및 시각화 (0) | 2026.06.04 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day21_머신러닝 알고리즘 및 앙상블 (0) | 2026.06.02 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day20_머신러닝 결정트리와 회귀트리 (0) | 2026.06.01 |



