데이터수집 - 전처리 - 학습데이터로 모델 학습 - 검증 데이터로 튜닐 - 최종 모델 선정 - 테스트 데이터로 최종평
모델학습: 모델이 데이터 패턴을 배우는 단계, 가중치가 계속 수정된다 .
모델 검증:학습하지않고 model.eval() 상태에서 성능만 확인 모델을 튜닝하기 위해 epoch를 몇번 돌릴지, learning rate을 얼마로 할지, dropout을 넣을지 모델저장할지에 대해 판단하기 위한 절차이다. 모델은 학습할수록 훈련 데이터에 점점 맞춰져 너무 많이 학습하면 새로운 데이터에서는 성능이 떨어지는 과적합이 발생하기 때문이다 .
모델 평가: 이 모델의 진짜 실력을 층정하기 위해 best_model.load_state_dict() 한번만 테스트한다.
ROC Curve
분계임계값을 변화시키면서 모델 성능 변화를 확인하는 그래프
모델은 예측할때 보통 확률을 내고 기준 Threshold을 50%으로 정해 긍정, 부정으로 나뉘게 된다 . 이 기준을 계속 바꿔가며 성능을 측정할 수 있고 기준을 바꿀때 모델 성능이 어떻게 변하는지 그린 그래프이다.
이 긍정중에서 맞춘 비율을 TPR이라고 부른다. 반대로 부정인데 긍정이라고 판단해 틀린 비율은 FPR이라한다.
ROC Curve가 좋은 모델이라면 이 TPR이 높고 FPR이 낮아야한다.
AUC는 ROC Curve를 숫자하나로 요약한 것으로 그래프 면적을 계산한다. 1이라면 완벽한 모델, 0.5이면 동전 던지기 수준의 랜덤 예측이라고 볼 수 있다.
AO 모델 검증 및 평가예, 예시코드를 분서해보자 ai_model_validation_evaluation_torch.ipynb
import, 난수고정.
평가지표를 계산하기위해 accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, classification_report, roc_aur_score, roc_curve를 import했다 .
accuracy_score 모데리의 전체 예측 중 올바르게 예측한 비율, 정확도
precision_score 모델이 양성이라고 예측한것중 실제로 양성인 비율을 계산하는 함수 정밀도.
recall_score실제 양성 데이터 중에서 모델이 올바르게찾아낸 비율, 재현율
f1_score 정밀도와 재현율의 조화평균을 계산하는 함수. 정밀도와 재현율을 동시에 고려해 데이터가 불균형한 경우에도 모델 성능을 효과적으로 평가할 수 있다 .
confusion_matrix실제값과 예측값을 비교하여 분류 결과를 행렬형태로 나타내는 함수. TP, FP 긍정예측, TN, FN 부정예측이 있고 모델이 어떤 유형의오류를 많이 발생시키는지 확인할 수 있다.
classification_report 정확도, 정밀도, 재현율, f1score를 한번에 출력하는 함수. 종합적으로 분석할 수있다 .
roc_aur_score roc curve 아래 면적 auc를 계산하는 함수, 값의 범위는 0~1 로 1에 가까울 수록 성능이 우수하며 양성과 음성을 얼마나 잘 구분하는지 수치로 평가할 수 있다 .
roc_curve 분류임계값을 변화시키면서 TPR, FPR 을 계산해 ROC curve를 생성하는 함수.
# ============================================================
# 1. 필요한 라이브러리 불러오기
# ============================================================
# numpy는 배열 계산을 위한 기본 라이브러리입니다.
import numpy as np
# pandas는 표 형태의 데이터를 다룰 때 사용합니다.
import pandas as pd
# matplotlib은 그래프를 그릴 때 사용합니다.
import matplotlib.pyplot as plt
# PyTorch의 핵심 라이브러리입니다.
import torch
# torch.nn은 신경망 계층, 손실함수 등을 만들 때 사용합니다.
import torch.nn as nn
# torch.optim은 모델의 가중치를 업데이트하는 최적화 알고리즘을 제공합니다.
import torch.optim as optim
# TensorDataset은 입력 데이터와 정답 데이터를 하나의 데이터셋으로 묶을 때 사용합니다.
from torch.utils.data import TensorDataset
# DataLoader는 데이터를 미니배치 단위로 나누어 모델에 공급합니다.
from torch.utils.data import DataLoader
# sklearn의 유방암 데이터셋을 불러옵니다.
from sklearn.datasets import load_breast_cancer
# train_test_split은 데이터를 학습/검증/테스트 데이터로 나눌 때 사용합니다.
from sklearn.model_selection import train_test_split
# StandardScaler는 입력 특성값을 평균 0, 표준편차 1로 표준화합니다.
from sklearn.preprocessing import StandardScaler
# 평가 지표를 계산하기 위한 함수들입니다.
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.metrics import confusion_matrix, classification_report, roc_auc_score, roc_curve
# 실행할 때마다 최대한 같은 결과가 나오도록 난수를 고정합니다.
np.random.seed(42)
# PyTorch의 난수를 고정합니다.
torch.manual_seed(42)
# GPU가 사용 가능하면 GPU를 사용하고, 아니면 CPU를 사용합니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 현재 사용 장치를 출력합니다.
print("사용 장치:", device)
데이터 불러오기.
load_breast_cancer() 데이터셋 불러오기
# ============================================================
# 2. 데이터 불러오기
# ============================================================
# Breast Cancer 데이터셋을 불러옵니다.
# 이 데이터셋은 종양이 악성인지 양성인지 분류하는 이진 분류 데이터입니다.
data = load_breast_cancer()
# 입력 데이터 X를 가져옵니다.
# X는 종양의 반지름, 질감, 면적 등 여러 개의 수치 특성으로 구성됩니다.
X = data.data
# 정답 데이터 y를 가져옵니다.
# y는 0 또는 1로 구성된 클래스 라벨입니다.
y = data.target
# 특성 이름을 확인하기 위해 DataFrame으로 변환합니다.
df = pd.DataFrame(X, columns=data.feature_names)
# 정답 컬럼을 추가합니다.
df["target"] = y
# 데이터의 앞부분 5개 행을 출력합니다.
df.head()
학습데이터, 검증 데이터, 테스트 데이터로 분리.
전체 데이터 100%
│
├─ Test 15%
│
└─ Train+Val 85%
│
├─ Validation 17.65% of 85%
│ ≈ 전체의 15%
│
└─ Train 82.35% of 85%
≈ 전체의 70%
# ============================================================
# 3. 학습 데이터, 검증 데이터, 테스트 데이터 분리
# ============================================================
# 먼저 전체 데이터를 학습+검증 데이터와 테스트 데이터로 나눕니다.
# test_size=0.15는 전체 데이터의 15%를 최종 테스트 데이터로 사용한다는 의미입니다.
# stratify=y는 클래스 비율이 나누어진 데이터에서도 최대한 유지되도록 합니다.
X_train_val, X_test, y_train_val, y_test = train_test_split(
X,
y,
test_size=0.15,
random_state=42,
stratify=y
)
# 학습+검증 데이터를 다시 학습 데이터와 검증 데이터로 나눕니다.
# 전체 기준으로 약 70% 학습, 15% 검증, 15% 테스트가 되도록 나눕니다.
X_train, X_val, y_train, y_val = train_test_split(
X_train_val,
y_train_val,
test_size=0.1765,
random_state=42,
stratify=y_train_val
)
# 각 데이터 크기를 출력합니다.
print("학습 데이터 크기:", X_train.shape)
print("검증 데이터 크기:", X_val.shape)
print("테스트 데이터 크기:", X_test.shape)
# 클래스 분포를 확인합니다.
print("학습 정답 분포:", np.bincount(y_train))
print("검증 정답 분포:", np.bincount(y_val))
print("테스트 정답 분포:", np.bincount(y_test))
입력데이터를 StandardScaler() 객체를 생성해 정규화한뒤 fit_transform., 검증과 테스트 데이터는 transform.만.
# ============================================================
# 4. 입력 데이터 표준화
# ============================================================
# StandardScaler 객체를 생성합니다.
scaler = StandardScaler()
# 학습 데이터의 평균과 표준편차를 계산하고, 학습 데이터를 표준화합니다.
# 검증/테스트 데이터 정보가 학습 과정에 섞이면 안 되므로 fit은 학습 데이터에만 적용합니다.
X_train_scaled = scaler.fit_transform(X_train)
# 검증 데이터는 학습 데이터에서 계산한 평균과 표준편차를 사용하여 변환만 합니다.
X_val_scaled = scaler.transform(X_val)
# 테스트 데이터도 학습 데이터 기준으로 변환만 합니다.
X_test_scaled = scaler.transform(X_test)
실수형인 입력데이터를 float32형인 tensor로 변환
정답데이터는 0, 1 로 tensor변환이 필요가없지만
이진분류/다중라벨분류에 사용되는 실무에서 많이 사용하는 내부적으로 sigmoid와 BCE를 한번에 계산하는 BCEWithLogistsLoss()를 사용할것이고.
이는 float형태를 요구함으로 함께 바꿔준다.
외 검증데이터, 테스트 데이터도 변환해주고
tensordataset으로 학습 입력과 정답을 하나로 묶어준다.
# ============================================================
# 5. NumPy 데이터를 PyTorch Tensor로 변환
# ============================================================
# 입력 데이터는 실수형이므로 float32 타입의 Tensor로 변환합니다.
X_train_tensor = torch.tensor(X_train_scaled, dtype=torch.float32)
# 정답 데이터는 0 또는 1이지만, BCEWithLogitsLoss를 사용할 것이므로 float32로 변환합니다.
# view(-1, 1)은 정답 모양을 [샘플 수, 1] 형태로 맞춥니다.
y_train_tensor = torch.tensor(y_train, dtype=torch.float32).view(-1, 1)
# 검증 입력 데이터를 Tensor로 변환합니다.
X_val_tensor = torch.tensor(X_val_scaled, dtype=torch.float32)
# 검증 정답 데이터를 Tensor로 변환합니다.
y_val_tensor = torch.tensor(y_val, dtype=torch.float32).view(-1, 1)
# 테스트 입력 데이터를 Tensor로 변환합니다.
X_test_tensor = torch.tensor(X_test_scaled, dtype=torch.float32)
# 테스트 정답 데이터를 Tensor로 변환합니다.
y_test_tensor = torch.tensor(y_test, dtype=torch.float32).view(-1, 1)
# TensorDataset은 입력과 정답을 하나로 묶어줍니다.
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
# DataLoader는 데이터를 batch_size 개수만큼 묶어서 모델에 넣어줍니다.
# shuffle=True는 매 epoch마다 데이터 순서를 섞어 학습 안정성을 높입니다.
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)https://standout.tistory.com/1806
손실함수 종류 loss, criterion: BCEWithLogitsLoss CrossEntropyLoss BCEWithLogitsLoss MSELoss HuberLoss
손실 함수모델이 얼마나 틀렸는지 계산하는 함수이진분류MLP, CNN, LSTMBCEWithLogitsLoss다중분류MLP, CNN, LSTMCrossEntropyLoss다중라벨분류MLP, CNN, LSTMBCEWithLogitsLoss회귀MLP, LSTMMSELoss이상치 있는 회귀MLP, LSTMHub
standout.tistory.com
분류모델을 정의한다.
nn.Module을 받아 sequential로 순차적으로 연결하며, relu로 음수는 0으로 만들고 양수는 그대로 통과시키며 , 과적합을 줄이기 위해 일부 뉴런을 무작위로 꺼주는 dropout을 쓴다 .forward. 입력데이터 x가 정의한 model을 통과하도록 정의한다. self.model
# ============================================================
# 6. PyTorch 분류 모델 정의
# ============================================================
# nn.Module을 상속받아 사용자 정의 신경망 클래스를 만듭니다.
class BinaryClassifier(nn.Module):
# __init__은 모델 구조를 정의하는 부분입니다.
def __init__(self, input_dim):
# 부모 클래스 nn.Module의 초기화 함수를 실행합니다.
super(BinaryClassifier, self).__init__()
# Sequential은 여러 계층을 순서대로 연결하는 컨테이너입니다.
self.model = nn.Sequential(
# 첫 번째 완전연결층입니다.
# input_dim개의 입력 특성을 받아 32개의 값을 출력합니다.
nn.Linear(input_dim, 32),
# ReLU는 음수는 0으로 만들고 양수는 그대로 통과시키는 활성화 함수입니다.
nn.ReLU(),
# 과적합을 줄이기 위해 일부 뉴런을 무작위로 꺼주는 Dropout입니다.
nn.Dropout(0.2),
# 두 번째 완전연결층입니다.
nn.Linear(32, 16),
# 두 번째 활성화 함수입니다.
nn.ReLU(),
# 출력층입니다.
# 이진 분류이므로 출력값은 1개입니다.
# 여기서는 Sigmoid를 붙이지 않습니다.
# BCEWithLogitsLoss가 내부적으로 Sigmoid 계산을 포함하기 때문입니다.
nn.Linear(16, 1)
)
# forward는 입력 데이터가 모델을 통과하는 흐름을 정의합니다.
def forward(self, x):
# 위에서 정의한 Sequential 모델에 입력 x를 넣고 결과를 반환합니다.
return self.model(x)
# 입력 특성 개수를 구합니다.
input_dim = X_train_tensor.shape[1]
# 모델 객체를 생성하고 device로 이동합니다.
model = BinaryClassifier(input_dim).to(device)
# 모델 구조를 출력합니다.
print(model)
앞서 언급했다 싶이 손실함수는 이진분류에서 사용하는 손실함수 BCEwidhLogistsloss를 사용한다.
lr를 수정하는지 정하는 값인 optim은 adam을 사용한다.
정의
# ============================================================
# 7. 손실함수와 최적화 알고리즘 정의
# ============================================================
# BCEWithLogitsLoss는 이진 분류에서 사용하는 손실함수입니다.
# 출력층의 raw score(logit)에 Sigmoid를 내부적으로 적용한 뒤 Binary Cross Entropy를 계산합니다.
criterion = nn.BCEWithLogitsLoss()
# Adam은 많이 사용하는 최적화 알고리즘입니다.
# lr은 learning rate, 즉 가중치를 한 번에 얼마나 수정할지 정하는 값입니다.
optimizer = optim.Adam(model.parameters(), lr=0.001)
평가함수 정의.
model.eval()
model() 예측값을 계산해 criterion 손실값을 계산,
torch.sigmoid로 0~1 사이 확률로 나누어 0.5 이상이면 1, 외 0 으로 predictions를 나눈다.
이 예측값과 y가 같은 비율을 계산한다.
# ============================================================
# 8. 평가 함수 정의
# ============================================================
# 모델의 손실과 정확도를 계산하는 함수입니다.
def evaluate_model(model, X_tensor, y_tensor):
# 모델을 평가 모드로 변경합니다.
# Dropout 같은 계층은 학습 때와 평가 때 동작이 다르므로 반드시 설정해야 합니다.
model.eval()
# 평가 시에는 기울기 계산이 필요하지 않으므로 no_grad를 사용합니다.
# 이렇게 하면 메모리를 절약하고 계산 속도도 빨라집니다.
with torch.no_grad():
# 입력 데이터와 정답 데이터를 device로 이동합니다.
X_tensor = X_tensor.to(device)
y_tensor = y_tensor.to(device)
# 모델 예측값 logit을 계산합니다.
logits = model(X_tensor)
# 손실값을 계산합니다.
loss = criterion(logits, y_tensor)
# logit에 Sigmoid를 적용하여 0~1 사이의 확률로 바꿉니다.
probabilities = torch.sigmoid(logits)
# 확률이 0.5 이상이면 1, 아니면 0으로 분류합니다.
predictions = (probabilities >= 0.5).float()
# 예측값과 실제값이 같은 비율을 계산합니다.
accuracy = (predictions == y_tensor).float().mean()
# loss와 accuracy를 Python 숫자로 변환하여 반환합니다.
return loss.item(), accuracy.item()
모델학습 및 검증.
epochs만큼 반복한다.
model.train()
train_loader, dataloader에서 batchx, batchy 단위로 꺼내 실행한다.
optimizer.zero_grad() 로 이전 미니 배치에서 계싼된 기울기를 초기화하고 모델에 입력데이터를 batch_x를 넣어 logits계산,
logits와 y로 criteriton loss 반환.
loss를 기준으로 backward(), optimizer-steop()
# ============================================================
# 9. 모델 학습 및 검증
# ============================================================
# 전체 학습 반복 횟수입니다.
epochs = 100
# epoch마다 손실과 정확도를 저장할 리스트입니다.
train_losses = []
val_losses = []
train_accuracies = []
val_accuracies = []
# 지정한 epoch 횟수만큼 반복합니다.
for epoch in range(epochs):
# 모델을 학습 모드로 변경합니다.
model.train()
# 한 epoch의 총 손실을 저장할 변수입니다.
total_train_loss = 0.0
# DataLoader에서 미니배치 단위로 데이터를 꺼냅니다.
for batch_X, batch_y in train_loader:
# 입력 데이터와 정답 데이터를 device로 이동합니다.
batch_X = batch_X.to(device)
batch_y = batch_y.to(device)
# 이전 미니배치에서 계산된 기울기를 초기화합니다.
optimizer.zero_grad()
# 모델에 입력 데이터를 넣어 예측값 logit을 계산합니다.
logits = model(batch_X)
# 예측값과 실제값 사이의 손실을 계산합니다.
loss = criterion(logits, batch_y)
# 손실값을 기준으로 역전파를 수행하여 기울기를 계산합니다.
loss.backward()
# 계산된 기울기를 사용하여 모델 가중치를 업데이트합니다.
optimizer.step()
# 현재 미니배치 손실에 샘플 수를 곱해 누적합니다.
total_train_loss += loss.item() * batch_X.size(0)
# 한 epoch의 평균 학습 손실을 계산합니다.
avg_train_loss = total_train_loss / len(train_loader.dataset)
# 학습 데이터 전체 기준 손실과 정확도를 계산합니다.
train_loss, train_acc = evaluate_model(model, X_train_tensor, y_train_tensor)
# 검증 데이터 기준 손실과 정확도를 계산합니다.
val_loss, val_acc = evaluate_model(model, X_val_tensor, y_val_tensor)
# 결과를 리스트에 저장합니다.
train_losses.append(train_loss)
val_losses.append(val_loss)
train_accuracies.append(train_acc)
val_accuracies.append(val_acc)
# 10 epoch마다 학습 상태를 출력합니다.
if (epoch + 1) % 10 == 0:
print(
f"Epoch [{epoch+1}/{epochs}] "
f"Train Loss: {train_loss:.4f}, Train Acc: {train_acc:.4f}, "
f"Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.4f}"
)
위 출력해본 학습결과평균들을 시각화
# ============================================================
# 10. 학습 곡선 시각화
# ============================================================
# 손실 그래프 크기를 설정합니다.
plt.figure(figsize=(8, 5))
# 학습 손실을 선 그래프로 그립니다.
plt.plot(train_losses, label="Train Loss")
# 검증 손실을 선 그래프로 그립니다.
plt.plot(val_losses, label="Validation Loss")
# 그래프 제목을 설정합니다.
plt.title("Train Loss vs Validation Loss")
# x축 이름을 설정합니다.
plt.xlabel("Epoch")
# y축 이름을 설정합니다.
plt.ylabel("Loss")
# 범례를 표시합니다.
plt.legend()
# 그래프를 출력합니다.
plt.show()
# 정확도 그래프 크기를 설정합니다.
plt.figure(figsize=(8, 5))
# 학습 정확도를 선 그래프로 그립니다.
plt.plot(train_accuracies, label="Train Accuracy")
# 검증 정확도를 선 그래프로 그립니다.
plt.plot(val_accuracies, label="Validation Accuracy")
# 그래프 제목을 설정합니다.
plt.title("Train Accuracy vs Validation Accuracy")
# x축 이름을 설정합니다.
plt.xlabel("Epoch")
# y축 이름을 설정합니다.
plt.ylabel("Accuracy")
# 범례를 표시합니다.
plt.legend()
# 그래프를 출력합니다.
plt.show()
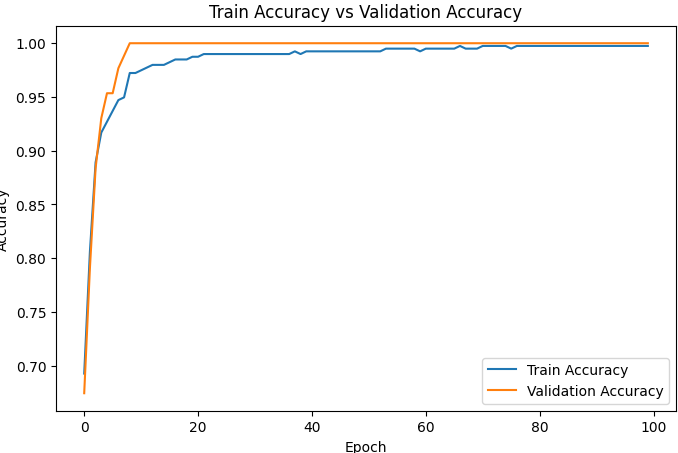
꽤 안정적이다 .
model.eval() 평가모드로 변경해 테스트 데이터로 최종 평가 .
# ============================================================
# 11. 테스트 데이터 최종 평가
# ============================================================
# 모델을 평가 모드로 변경합니다.
model.eval()
# 테스트 데이터 예측 시 기울기 계산을 하지 않습니다.
with torch.no_grad():
# 테스트 입력 데이터를 device로 이동합니다.
X_test_device = X_test_tensor.to(device)
# 테스트 데이터에 대한 logit을 계산합니다.
test_logits = model(X_test_device)
# Sigmoid를 적용해 양성 클래스일 확률로 변환합니다.
test_probabilities = torch.sigmoid(test_logits).cpu().numpy().ravel()
# 확률이 0.5 이상이면 1, 아니면 0으로 분류합니다.
test_predictions = (test_probabilities >= 0.5).astype(int)
# 실제 테스트 정답을 NumPy 배열로 변환합니다.
y_true = y_test
# 정확도를 계산합니다.
accuracy = accuracy_score(y_true, test_predictions)
# 정밀도를 계산합니다.
precision = precision_score(y_true, test_predictions)
# 재현율을 계산합니다.
recall = recall_score(y_true, test_predictions)
# F1-score를 계산합니다.
f1 = f1_score(y_true, test_predictions)
# ROC-AUC를 계산합니다.
# ROC-AUC는 0/1 예측값이 아니라 양성 클래스 확률값을 사용합니다.
auc = roc_auc_score(y_true, test_probabilities)
# 결과를 출력합니다.
print("테스트 정확도 Accuracy:", round(accuracy, 4))
print("테스트 정밀도 Precision:", round(precision, 4))
print("테스트 재현율 Recall:", round(recall, 4))
print("테스트 F1-score:", round(f1, 4))
print("테스트 ROC-AUC:", round(auc, 4))테스트 정확도 Accuracy: 0.9419
테스트 정밀도 Precision: 0.9804
테스트 재현율 Recall: 0.9259
테스트 F1-score: 0.9524
테스트 ROC-AUC: 0.9913
혼동행렬로 확인해보자.
# ============================================================
# 12. 혼동행렬 확인
# ============================================================
# 혼동행렬을 계산합니다.
# 행은 실제값, 열은 예측값을 의미합니다.
cm = confusion_matrix(y_true, test_predictions)
# 혼동행렬을 출력합니다.
print("Confusion Matrix")
print(cm)
# 혼동행렬에서 TN, FP, FN, TP를 꺼냅니다.
tn, fp, fn, tp = cm.ravel()
# 각각의 의미를 출력합니다.
print("TN: 실제 0을 0으로 맞춘 개수 =", tn)
print("FP: 실제 0을 1로 잘못 예측한 개수 =", fp)
print("FN: 실제 1을 0으로 잘못 예측한 개수 =", fn)
print("TP: 실제 1을 1로 맞춘 개수 =", tp)
# sklearn의 classification_report로 주요 평가 지표를 한 번에 확인합니다.
print("\nClassification Report")
print(classification_report(y_true, test_predictions, target_names=data.target_names))Confusion Matrix
[[31 1]
[ 4 50]]
TN: 실제 0을 0으로 맞춘 개수 = 31
FP: 실제 0을 1로 잘못 예측한 개수 = 1
FN: 실제 1을 0으로 잘못 예측한 개수 = 4
TP: 실제 1을 1로 맞춘 개수 = 50
Classification Report
precision recall f1-score support
malignant 0.89 0.97 0.93 32
benign 0.98 0.93 0.95 54
accuracy 0.94 86
macro avg 0.93 0.95 0.94 86
weighted avg 0.95 0.94 0.94 86혼동행렬이 대각선값이 높으니 성능이 좋다.
classification_report로 한번에 확인해보니
malignant 악성 테스트 데이터에 support 32개의 악성종양이 있었는데 recall97%를 찾아냈다. 모델이 악성이라고 예측한것중 89%가 실제 악성이었는데 이는 양성을 악성으로 잘못 판단한 경우가 있었다는 의미이다.
benign 양성은 support 데이터가 54개 있었는데 양성이라고 예측한 것들중 98%가 실제양성이었다 .실제 54중 93%를 올바르게 찾았으며
accuracy 전체 데이터중 94%의 정확도를 가진다 .
macro avg 악성과 양성을 동일한 비중으로 평균값을 내본다.
weighted avg 각 클래스의 데이터 갯수를 반영한 평균을 내본다.
= 이 모델은 정확도 94%를 달성했다.
특히 악성종양에 대한 재현률이 97%로 매우 높아 실제 암 환자를 놓치는 경우가 거의 없었다.
양성종양에서도 높은 정밀도 precision 98%과 재현율 recall 93%를 보여 전반적으로 우수하다 .
| Precision | 89% | 모델이 "악성"이라고 예측한 것들 | 그중 89%가 실제 악성 |
| Recall | 97% | 실제 악성 종양 32개 | 그중 97%를 찾아냄 |
| F1-score | 93% | Precision과 Recall 종합 | 두 성능을 균형 있게 평가 |
| Support | 32 | 실제 데이터 개수 | 테스트 데이터에 악성 32개 존재 |
| Precision | 98% | 모델이 "양성"이라고 예측한 것들 | 그중 98%가 실제 양성 |
| Recall | 93% | 실제 양성 종양 54개 | 그중 93%를 찾아냄 |
| F1-score | 95% | Precision과 Recall 종합 | 두 성능을 균형 있게 평가 |
| Support | 54 | 실제 데이터 개수 | 테스트 데이터에 양성 54개 존재 |
| Accuracy | 94% | 전체 86개 중 94%를 맞춤 |
| Macro Avg | 94% | 악성과 양성을 동일 비중으로 평균, 클래스가 데이터가 다르나 똑같이 취급 |
| Weighted Avg | 94% | 데이터 개수를 반영한 평균 클래스의 데이터 개수를 반영함. |
같은 기능으로 tensorflow 코드로 확인해보자. ai_model_validation_evaluation_keras.ipynb
import, 난수고정
# ============================================================
# 1. 필요한 라이브러리 불러오기
# ============================================================
# numpy는 배열 계산을 위한 기본 라이브러리입니다.
import numpy as np
# pandas는 표 형태의 데이터를 다룰 때 사용합니다.
import pandas as pd
# matplotlib은 그래프를 그릴 때 사용합니다.
import matplotlib.pyplot as plt
# TensorFlow는 딥러닝 모델을 만들고 학습할 때 사용하는 라이브러리입니다.
import tensorflow as tf
# keras는 TensorFlow 안에서 신경망 모델을 쉽게 만들 수 있도록 도와주는 API입니다.
from tensorflow import keras
# Dense는 완전연결층을 만들 때 사용합니다.
from tensorflow.keras.layers import Dense, Dropout
# Sequential은 계층을 순서대로 쌓는 모델 방식입니다.
from tensorflow.keras.models import Sequential
# EarlyStopping은 검증 성능이 더 이상 좋아지지 않으면 학습을 조기 종료합니다.
from tensorflow.keras.callbacks import EarlyStopping
# sklearn의 유방암 데이터셋을 불러옵니다.
from sklearn.datasets import load_breast_cancer
# train_test_split은 데이터를 학습/검증/테스트 데이터로 나눌 때 사용합니다.
from sklearn.model_selection import train_test_split
# StandardScaler는 입력 특성값을 평균 0, 표준편차 1로 표준화합니다.
from sklearn.preprocessing import StandardScaler
# 평가 지표를 계산하기 위한 함수들입니다.
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.metrics import confusion_matrix, classification_report, roc_auc_score, roc_curve
# 실행할 때마다 최대한 같은 결과가 나오도록 난수를 고정합니다.
np.random.seed(42)
# TensorFlow의 난수를 고정합니다.
tf.random.set_seed(42)
# TensorFlow 버전을 출력합니다.
print("TensorFlow version:", tf.__version__)
데이터를 불러오고 학습, 검증, 테스트 데이터로 분리했다 .
마찬가지로 standardscaler로 데이터 표준화.
# ============================================================
# 2. 데이터 불러오기
# ============================================================
# Breast Cancer 데이터셋을 불러옵니다.
# 이 데이터셋은 종양이 악성인지 양성인지 분류하는 이진 분류 데이터입니다.
data = load_breast_cancer()
# 입력 데이터 X를 가져옵니다.
X = data.data
# 정답 데이터 y를 가져옵니다.
y = data.target
# 데이터 확인을 위해 DataFrame으로 변환합니다.
df = pd.DataFrame(X, columns=data.feature_names)
# 정답 컬럼을 추가합니다.
df["target"] = y
# 데이터의 앞부분 5개 행을 출력합니다.
df.head()
# ============================================================
# 3. 학습 데이터, 검증 데이터, 테스트 데이터 분리
# ============================================================
# 먼저 전체 데이터를 학습+검증 데이터와 테스트 데이터로 나눕니다.
# test_size=0.15는 전체 데이터의 15%를 최종 평가용 테스트 데이터로 사용한다는 의미입니다.
X_train_val, X_test, y_train_val, y_test = train_test_split(
X,
y,
test_size=0.15,
random_state=42,
stratify=y
)
# 학습+검증 데이터를 다시 학습 데이터와 검증 데이터로 나눕니다.
# 전체 기준으로 약 70% 학습, 15% 검증, 15% 테스트가 되도록 구성합니다.
X_train, X_val, y_train, y_val = train_test_split(
X_train_val,
y_train_val,
test_size=0.1765,
random_state=42,
stratify=y_train_val
)
# 각 데이터 크기를 출력합니다.
print("학습 데이터 크기:", X_train.shape)
print("검증 데이터 크기:", X_val.shape)
print("테스트 데이터 크기:", X_test.shape)
# 클래스 분포를 확인합니다.
print("학습 정답 분포:", np.bincount(y_train))
print("검증 정답 분포:", np.bincount(y_val))
print("테스트 정답 분포:", np.bincount(y_test))
# ============================================================
# 4. 입력 데이터 표준화
# ============================================================
# StandardScaler 객체를 생성합니다.
scaler = StandardScaler()
# 학습 데이터에 대해서만 평균과 표준편차를 계산하고 변환합니다.
# 검증/테스트 데이터 정보가 학습에 섞이지 않도록 fit은 학습 데이터에만 사용합니다.
X_train_scaled = scaler.fit_transform(X_train)
# 검증 데이터는 학습 데이터 기준으로 변환만 합니다.
X_val_scaled = scaler.transform(X_val)
# 테스트 데이터도 학습 데이터 기준으로 변환만 합니다.
X_test_scaled = scaler.transform(X_test)
keras 모델을 정의해보자.
sequential() 순차적으로 모델층을 쌓는다.
dense로, activation은 relu로. 모델에 input_shape(input_dim)으로 특성 갯수를 알려줬다 .
출력층에서 activation을 sigmoid로 출력값은 0~1 사이의 확률로 바꿨다.
# ============================================================
# 5. Keras 모델 정의
# ============================================================
# 입력 특성 개수를 구합니다.
input_dim = X_train_scaled.shape[1]
# Sequential 모델은 층을 순서대로 쌓는 가장 기본적인 Keras 모델 방식입니다.
model = Sequential([
# 첫 번째 Dense 층입니다.
# units=32는 출력 뉴런 수가 32개라는 뜻입니다.
# activation='relu'는 ReLU 활성화 함수를 사용한다는 뜻입니다.
# input_shape=(input_dim,)은 입력 특성 개수를 모델에 알려주는 설정입니다.
Dense(32, activation="relu", input_shape=(input_dim,)),
# Dropout은 학습 중 일부 뉴런을 무작위로 끄는 방식입니다.
# 과적합을 줄이는 데 도움을 줍니다.
Dropout(0.2),
# 두 번째 Dense 층입니다.
Dense(16, activation="relu"),
# 출력층입니다.
# 이진 분류이므로 뉴런은 1개입니다.
# sigmoid는 출력값을 0~1 사이의 확률로 바꿉니다.
Dense(1, activation="sigmoid")
])
# 모델 구조를 요약해서 출력합니다.
model.summary()
tensorflow는 compile이 필요하다.
keras.optimizers.Adam으로 lr은 0.001를 사용한다. loss는 binartycrosstropy마찬가지로 이진 분류에서 사용하는 대표적인 손실함수를 사용한다.
binary_crossentropy와 BCEwithlogistsloss는 사실상 같은 목적의 손실함수이다 .
BCEwidthlogistsloss는 sigmoid와 binary croww entropy를 하나의 함수로 결합한 형태이고
keras에서 출력 dense에서 sigmoid로 끝내고 binary cross emtrpy를 적용했다 .
# ============================================================
# 6. 모델 컴파일
# ============================================================
# compile은 모델 학습에 필요한 손실함수, 최적화 알고리즘, 평가 지표를 설정하는 단계입니다.
model.compile(
# optimizer='adam'은 Adam 최적화 알고리즘을 사용한다는 뜻입니다.
optimizer=keras.optimizers.Adam(learning_rate=0.001),
# binary_crossentropy는 이진 분류에서 사용하는 대표적인 손실함수입니다.
loss="binary_crossentropy",
# metrics=['accuracy']는 학습 중 정확도를 함께 출력하도록 설정합니다.
metrics=["accuracy"]
)
earlystoppig 설정. val_loss 즉 검증 데이터에 손실이 일어날 경우, patience 10번의 epoch동안 val_loss가 개선되지않으면 학습을 중단시킨다.
restore_best_weights = True 가장 성능이 좋았던 epoch의 가중치로 되돌린다.
# ============================================================
# 7. EarlyStopping 설정
# ============================================================
# EarlyStopping은 검증 손실이 더 이상 좋아지지 않으면 학습을 멈추는 기능입니다.
early_stopping = EarlyStopping(
# val_loss는 검증 데이터 손실을 의미합니다.
monitor="val_loss",
# patience=10은 10번의 epoch 동안 val_loss가 개선되지 않으면 학습을 중단한다는 뜻입니다.
patience=10,
# restore_best_weights=True는 가장 성능이 좋았던 epoch의 가중치로 되돌립니다.
restore_best_weights=True
)
model.fit() 모델 학습.위에서 정의 한 earuly_stopping을 적용했다.
# ============================================================
# 8. 모델 학습 및 검증
# ============================================================
# fit은 모델을 학습시키는 함수입니다.
history = model.fit(
# 학습 입력 데이터입니다.
X_train_scaled,
# 학습 정답 데이터입니다.
y_train,
# validation_data는 학습 중 검증에 사용할 데이터를 지정합니다.
validation_data=(X_val_scaled, y_val),
# epochs는 전체 데이터를 몇 번 반복해서 학습할지 정합니다.
epochs=100,
# batch_size는 한 번에 몇 개의 샘플을 묶어서 학습할지 정합니다.
batch_size=32,
# callbacks에는 EarlyStopping 같은 부가 기능을 넣을 수 있습니다.
callbacks=[early_stopping],
# verbose=1은 학습 진행 상황을 출력한다는 의미입니다.
verbose=1
)
위학습 기록들을 시각화 .
# ============================================================
# 9. 학습 곡선 시각화
# ============================================================
# history.history에는 epoch별 손실과 정확도 기록이 저장되어 있습니다.
history_dict = history.history
# 손실 그래프 크기를 설정합니다.
plt.figure(figsize=(8, 5))
# 학습 손실을 선 그래프로 그립니다.
plt.plot(history_dict["loss"], label="Train Loss")
# 검증 손실을 선 그래프로 그립니다.
plt.plot(history_dict["val_loss"], label="Validation Loss")
# 그래프 제목을 설정합니다.
plt.title("Train Loss vs Validation Loss")
# x축 이름을 설정합니다.
plt.xlabel("Epoch")
# y축 이름을 설정합니다.
plt.ylabel("Loss")
# 범례를 표시합니다.
plt.legend()
# 그래프를 출력합니다.
plt.show()
# 정확도 그래프 크기를 설정합니다.
plt.figure(figsize=(8, 5))
# 학습 정확도를 선 그래프로 그립니다.
plt.plot(history_dict["accuracy"], label="Train Accuracy")
# 검증 정확도를 선 그래프로 그립니다.
plt.plot(history_dict["val_accuracy"], label="Validation Accuracy")
# 그래프 제목을 설정합니다.
plt.title("Train Accuracy vs Validation Accuracy")
# x축 이름을 설정합니다.
plt.xlabel("Epoch")
# y축 이름을 설정합니다.
plt.ylabel("Accuracy")
# 범례를 표시합니다.
plt.legend()
# 그래프를 출력합니다.
plt.show()
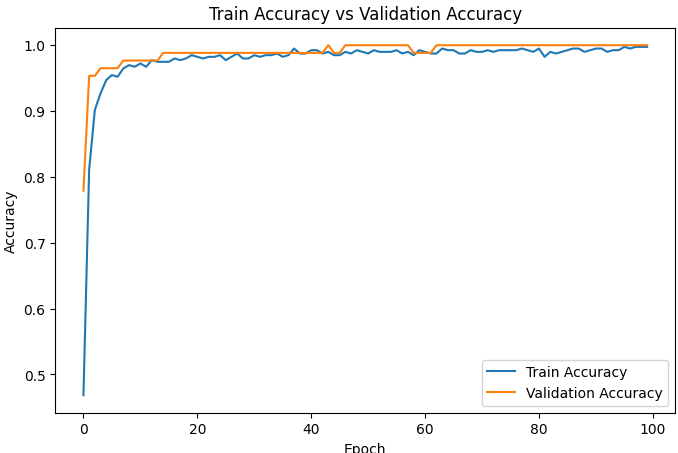
최종평가.
model.evaluate()로 테스트 데이터에 손실과 정확도를 계산한다.
model.predict() 양성 클래스일 확률을 예측하고 0.5 이상이면 1로 분류한다.
정확도, 정밀도, 재현률, f1score, roc-auc를 계산해 출력
# ============================================================
# 10. 테스트 데이터 최종 평가
# ============================================================
# evaluate는 테스트 데이터에 대한 손실과 정확도를 계산합니다.
test_loss, test_acc = model.evaluate(X_test_scaled, y_test, verbose=0)
# 테스트 손실과 정확도를 출력합니다.
print("테스트 손실:", round(test_loss, 4))
print("테스트 정확도:", round(test_acc, 4))
# predict는 각 샘플이 양성 클래스일 확률을 예측합니다.
test_probabilities = model.predict(X_test_scaled).ravel()
# 확률이 0.5 이상이면 1, 아니면 0으로 분류합니다.
test_predictions = (test_probabilities >= 0.5).astype(int)
# 정확도를 계산합니다.
accuracy = accuracy_score(y_test, test_predictions)
# 정밀도를 계산합니다.
precision = precision_score(y_test, test_predictions)
# 재현율을 계산합니다.
recall = recall_score(y_test, test_predictions)
# F1-score를 계산합니다.
f1 = f1_score(y_test, test_predictions)
# ROC-AUC를 계산합니다.
auc = roc_auc_score(y_test, test_probabilities)
# 결과를 출력합니다.
print("테스트 정확도 Accuracy:", round(accuracy, 4))
print("테스트 정밀도 Precision:", round(precision, 4))
print("테스트 재현율 Recall:", round(recall, 4))
print("테스트 F1-score:", round(f1, 4))
print("테스트 ROC-AUC:", round(auc, 4))테스트 손실: 0.1326
테스트 정확도: 0.9419
3/3 ━━━━━━━━━━━━━━━━━━━━ 0s 26ms/step
테스트 정확도 Accuracy: 0.9419
테스트 정밀도 Precision: 0.9804
테스트 재현율 Recall: 0.9259
테스트 F1-score: 0.9524
테스트 ROC-AUC: 0.9919
혼동핼렬 확인
# ============================================================
# 11. 혼동행렬 확인
# ============================================================
# 혼동행렬을 계산합니다.
cm = confusion_matrix(y_test, test_predictions)
# 혼동행렬을 출력합니다.
print("Confusion Matrix")
print(cm)
# 혼동행렬에서 TN, FP, FN, TP를 꺼냅니다.
tn, fp, fn, tp = cm.ravel()
# 각각의 의미를 출력합니다.
print("TN: 실제 0을 0으로 맞춘 개수 =", tn)
print("FP: 실제 0을 1로 잘못 예측한 개수 =", fp)
print("FN: 실제 1을 0으로 잘못 예측한 개수 =", fn)
print("TP: 실제 1을 1로 맞춘 개수 =", tp)
# 주요 분류 평가 지표를 표 형태로 출력합니다.
print("\nClassification Report")
print(classification_report(y_test, test_predictions, target_names=data.target_names))Confusion Matrix
[[31 1]
[ 4 50]]
TN: 실제 0을 0으로 맞춘 개수 = 31
FP: 실제 0을 1로 잘못 예측한 개수 = 1
FN: 실제 1을 0으로 잘못 예측한 개수 = 4
TP: 실제 1을 1로 맞춘 개수 = 50
Classification Report
precision recall f1-score support
malignant 0.89 0.97 0.93 32
benign 0.98 0.93 0.95 54
accuracy 0.94 86
macro avg 0.93 0.95 0.94 86
weighted avg 0.95 0.94 0.94 86
roc curve 시각화
roc_curve에 ytest 정답과 probabilities predict를 매개변수로 손실, 정확도를 계산.
시각화.
# ============================================================
# 12. ROC Curve 시각화
# ============================================================
# ROC Curve를 그리기 위해 FPR, TPR, Threshold를 계산합니다.
fpr, tpr, thresholds = roc_curve(y_test, test_probabilities)
# 그래프 크기를 설정합니다.
plt.figure(figsize=(8, 5))
# ROC Curve를 그립니다.
plt.plot(fpr, tpr, label=f"ROC Curve (AUC = {auc:.4f})")
# 무작위 예측 기준선을 그립니다.
plt.plot([0, 1], [0, 1], linestyle="--", label="Random Guess")
# 그래프 제목을 설정합니다.
plt.title("ROC Curve")
# x축 이름을 설정합니다.
plt.xlabel("False Positive Rate")
# y축 이름을 설정합니다.
plt.ylabel("True Positive Rate")
# 범례를 표시합니다.
plt.legend()
# 그래프를 출력합니다.
plt.show()

random guess에 비해 좋은 확률을 보이고 있다. 또 빠르게 안정화되어 잘 유지하고있다
face_churn_app을 확인해보자.


import.
Dict 타입힌트, 반환구조를 명확하게 하기 위해 딕셔너리 형태의 데이터를 명확하게 표시
joblib 머신러닝 모델 저장/불러오기에 사용된다 .
# 파일 경로를 안전하게 다루기 위해 Path 클래스를 가져옵니다.
from pathlib import Path
# 타입 힌트로 반환 구조를 명확하게 표현하기 위해 Dict를 가져옵니다.
from typing import Dict
# joblib은 scikit-learn 파이프라인 모델을 저장하고 불러올 때 사용합니다.
import joblib
# pandas는 입력값을 모델이 예측할 수 있는 표 형태 데이터로 변환하는 데 사용합니다.
import pandas as pd
사전학습된 모델 경로 정의
모델을 반복해서 읽지않도록 메모리에 캐시.
load_churn_model() 사전 학습된 고객이탈 예측 모델 로딩.
이미 로딩되어있으면 기존 객체를 반환하며 파일이 없으면 에러.
joblib로 저장된 모델을 불러와 return한다.
# 사전 학습된 고객 이탈 예측 모델 파일 경로를 정의합니다.
MODEL_PATH = Path("models/churn_model.joblib")
# 모델을 반복해서 디스크에서 읽지 않도록 메모리에 캐시하기 위한 전역 변수입니다.
_CHURN_MODEL = None
def load_churn_model():
"""사전 학습된 고객 이탈 예측 모델을 로딩합니다."""
# 전역 캐시 변수를 함수 내부에서 수정하기 위해 global 키워드를 사용합니다.
global _CHURN_MODEL
# 이미 모델이 로딩되어 있으면 기존 객체를 반환합니다.
if _CHURN_MODEL is not None:
return _CHURN_MODEL
# 모델 파일이 없으면 사용자가 학습 스크립트를 실행하도록 명확한 오류를 발생시킵니다.
if not MODEL_PATH.exists():
raise FileNotFoundError("models/churn_model.joblib 파일이 없습니다. 먼저 python train_churn_model.py를 실행하세요.")
# joblib로 저장된 scikit-learn 파이프라인 모델을 불러옵니다.
_CHURN_MODEL = joblib.load(MODEL_PATH)
# 로딩된 모델 객체를 반환합니다.
return _CHURN_MODEL
입력값을 dataframe으로 반환하는 함수정의
predict_churn 고객 정보를 받아 이탈여부와 확률을 예측하는 함수정의.
load_chrun_model() 저장된 사전 학습 모델을 불러와 datafream으로 변환한다.
model.predict_proba() 로 잔류확률, 이탈확률 형태 확률 배열 반환을 확인해 0.5 이상이면 이탈 위험 고객으로 분류한다.
라벨을 정의해 딕셔너리로 반환.
def make_input_dataframe(values: Dict[str, object]) -> pd.DataFrame:
"""Streamlit 입력값 딕셔너리를 모델 입력용 DataFrame으로 변환합니다."""
# 모델은 2차원 표 형태 입력을 기대하므로 단일 고객 입력도 리스트로 감싸 DataFrame을 생성합니다.
return pd.DataFrame([values])
def predict_churn(values: Dict[str, object]) -> Dict[str, object]:
"""고객 정보 입력값을 받아 이탈 여부와 확률을 예측합니다."""
# 저장된 사전 학습 모델을 불러옵니다.
model = load_churn_model()
# 사용자 입력 딕셔너리를 모델 입력 DataFrame으로 변환합니다.
input_df = make_input_dataframe(values)
# predict_proba는 [잔류 확률, 이탈 확률] 형태의 확률 배열을 반환합니다.
probabilities = model.predict_proba(input_df)[0]
# 이탈 클래스는 학습 데이터에서 1로 인코딩했으므로 두 번째 확률을 사용합니다.
churn_probability = float(probabilities[1])
# 확률이 0.5 이상이면 이탈 위험 고객으로 분류합니다.
prediction = int(churn_probability >= 0.5)
# 화면 표시용 한글 라벨을 만듭니다.
label = "이탈 위험" if prediction == 1 else "잔류 가능성 높음"
# 예측 결과를 딕셔너리로 반환합니다.
return {
"prediction": prediction,
"label": label,
"churn_probability": churn_probability,
"retention_probability": float(probabilities[0]),
}
즉 사전 학습된 모델을 불러와서 예측해보고 결과를 반환하는 파일 churn_service.py였다.
참고로 joblib파일은 내부적으로 숫자배열, 모델 파라미터, 구조 데이터를 바이너리 형태로 압축 저장한것이다 .
얼굴인식하는 face_auth.py를 확인해보자 .
import
cv2 를 import해 웹캡 프레임과 이미지 파일을 읽고 bgr rgb 변환을 수행하도록했다.
insightface.app의 faceanlysis를 import해 얼굴 검출, 정렬, 임베딩 추출을 한번에 수행하는 고수준 api.
# 운영체제 경로 처리를 안전하게 하기 위해 pathlib의 Path 클래스를 가져옵니다.
from pathlib import Path
# 타입 힌트를 사용하여 함수 입력과 반환값을 명확하게 표현하기 위해 가져옵니다.
from typing import Dict, Optional, Tuple
# OpenCV는 웹캠 프레임과 이미지 파일을 읽고 BGR/RGB 변환을 수행하는 데 사용합니다.
import cv2
# InsightFace의 FaceAnalysis는 얼굴 검출, 정렬, 임베딩 추출을 한 번에 수행하는 고수준 API입니다.
from insightface.app import FaceAnalysis
# NumPy는 얼굴 임베딩 벡터 저장, 정규화, 코사인 유사도 계산에 사용합니다.
import numpy as np
데이터파일 정의.
이미지 기본 폴더 정의.
동일인물 여부 판단을 위한 코사인 유사도 임계값 초기화
반복 로딩 비용을 줄이기 위한 전역 캐시 변수 초기화
# 얼굴 데이터베이스 파일이 저장될 기본 경로를 정의합니다.
FACE_DB_PATH = Path("face_db.npy")
# 등록된 얼굴 원본 이미지가 저장될 기본 폴더를 정의합니다.
FACE_IMAGE_DIR = Path("registered_faces")
# 동일 인물 여부를 판단하기 위한 기본 코사인 유사도 임계값입니다.
DEFAULT_SIMILARITY_THRESHOLD = 0.45
# InsightFace 모델 객체를 앱 전체에서 한 번만 초기화하여 반복 로딩 비용을 줄이기 위한 전역 캐시 변수입니다.
_FACE_APP: Optional[FaceAnalysis] = None
FaceAnalysis 객체를 초기화해 정의해보자.
모델이 이미 초기화되어있다면 기존객체를 반환한다.
FaceAnalysis의 name을 buffalo_l로 설정. InsightFace 라이브러리에서 buffalo_l라는 사전학습 얼굴 인식 모델을 불러와서 초기화했다.
faceAnalysis는 insightface 라이브러리의 핵심 클래스로 얼굴 검출, 특징 추출, 나이/성별을 추정한다.
buffalo_;은 모델 세트 이름으로 retinaface (얼굴 위치점찾기), arcface계열 모델 (얼굴 특징 백터 생성) , 랜드마크 모델 (눈코입위치) 가 있다 .
즉 사진을 넣으면 그 얼굴을 숫자벡터로 바꿔주는 ai모델 세트를 불러온것.
이 모델 _face_app에 ctx_id=-1로 cpu에서 실행하고 입력 이미지 크기들을 640*640으로 맞춰서 얼굴 검출을 준비 prepare하라는 의미.
face_app 반환
def get_face_app() -> FaceAnalysis:
"""InsightFace FaceAnalysis 객체를 초기화하고 반환합니다."""
# 전역 캐시 변수를 함수 내부에서 수정하기 위해 global 키워드를 사용합니다.
global _FACE_APP
# 이미 모델이 초기화되어 있다면 다시 로딩하지 않고 기존 객체를 반환합니다.
if _FACE_APP is not None:
return _FACE_APP
# buffalo_l 모델팩은 RetinaFace 기반 얼굴 검출과 ArcFace 계열 얼굴 임베딩 모델을 포함합니다.
_FACE_APP = FaceAnalysis(name="buffalo_l")
# ctx_id=-1은 CPU 실행을 의미합니다. GPU 환경이면 ctx_id=0으로 변경할 수 있습니다.
# det_size는 얼굴 검출 입력 크기이며, 클수록 작은 얼굴 검출에 유리하지만 속도는 느려질 수 있습니다.
_FACE_APP.prepare(ctx_id=-1, det_size=(640, 640))
# 초기화된 모델 객체를 반환합니다.
return _FACE_APP
ensure_dirs() None 즉 폴더가없으면 자동으로 만든다
mkdir하되 parents=T 상위폴더까지 자동생성하고 exit_ok T 이미 폴더가있어도에러를 안내도록 한다 .
저장된 얼굴 db를 불러와 Dict로 변환하고 파일이 없다면 빈 딕셔너리를 반환해 최초 실행도 오류없이 처리할 수 있도록 한다 .
db 파일을 읽는데 np.load() 저장된 numpy 파일을 로드하면서 allow_pickle T로 기본적으로 numpy는 dict를 못읽어 허용옵션을 켰다 .
isinstance() 만일 파일이 깨졌거나 이상한 데이터면 빈 db를 바니환한다.
data return
def ensure_dirs() -> None:
"""얼굴 이미지 저장 폴더를 생성합니다."""
# parents=True는 상위 폴더가 없어도 함께 만들도록 하고, exist_ok=True는 이미 있어도 오류를 내지 않습니다.
FACE_IMAGE_DIR.mkdir(parents=True, exist_ok=True)
def load_face_db() -> Dict[str, np.ndarray]:
"""저장된 얼굴 임베딩 데이터베이스를 불러옵니다."""
# 얼굴 DB 파일이 없으면 빈 딕셔너리를 반환하여 최초 실행도 오류 없이 처리합니다.
if not FACE_DB_PATH.exists():
return {}
# allow_pickle=True는 딕셔너리 형태로 저장한 NumPy 객체를 다시 읽기 위해 필요합니다.
data = np.load(FACE_DB_PATH, allow_pickle=True).item()
# 저장 파일이 손상되었거나 딕셔너리가 아니면 빈 DB로 안전하게 처리합니다.
if not isinstance(data, dict):
return {}
# 정상적으로 읽은 사용자별 임베딩 딕셔너리를 반환합니다.
return data
얼굴 db를 np.save() .npy파일로 저장한다.
opencv는 기본적으로 bgr 색상 순서를 사용함으로 rgb 순서로 변환한다.
def save_face_db(face_db: Dict[str, np.ndarray]) -> None:
"""사용자별 얼굴 임베딩 데이터베이스를 파일로 저장합니다."""
# NumPy save는 딕셔너리 객체를 npy 파일로 저장할 수 있습니다.
np.save(FACE_DB_PATH, face_db)
def bgr_to_rgb(image_bgr: np.ndarray) -> np.ndarray:
"""OpenCV BGR 이미지를 InsightFace 입력에 적합한 RGB 이미지로 변환합니다."""
# OpenCV는 기본적으로 BGR 색상 순서를 사용하므로 RGB로 변환합니다.
return cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
insightface 모델 get_face_app 를 가져온다.
opencv 이미지가 비어있으면 오류메세지를 반환한다 .
insightface는 rgb 기준으로 얼굴을 분석함으로 생상 순서를 변환한다.
app.get() 얼굴 후보 목록들을 추출한다.
검출된 faces가 없으면 사용자에게 메세지를 반환하도록 세팅.
여러 얼굴이 검출되면 max() 가장 큰 얼굴 하나를 기준으로 사용
latgest_face.embedding 가장 중요한 얼굴 1의 벡터. 임베딩을 astype(np.float) float32 형태로 꺼낸다.
임베딩은 얼굴을 숫자배영로 바꾼것.
얼굴인식에서 해심결과를 꺼내는 단계. 얼굴을 숫자 벡터로 변환한 값을 가져오는 코드.
벡터 크기를 계산해서 0이면 정규화할 수 없음으로 실패처리 .
어떤 얼굴은 값이 크고 어떤 얼굴은 값이 작으면 비교가 왜곡 될 수 있음으로 l2 정규화 embedding / ||embedding||로 길이를 1로 고정해 방향만 남기느 ㄴ것이다. 얼굴 특징을 찍었을때 거리르 버리고 방향만 비교하는것.
return 얼굴 추출이 성공했음을 알림.
def extract_embedding(image_bgr: np.ndarray) -> Tuple[Optional[np.ndarray], str]:
"""이미지에서 가장 큰 얼굴 하나의 임베딩 벡터를 추출합니다."""
# InsightFace 모델 객체를 가져옵니다.
app = get_face_app()
# OpenCV 이미지가 비어 있으면 얼굴 추출을 진행할 수 없으므로 오류 메시지를 반환합니다.
if image_bgr is None or image_bgr.size == 0:
return None, "이미지를 읽을 수 없습니다."
# InsightFace는 RGB 이미지를 기준으로 얼굴을 분석하므로 색상 순서를 변환합니다.
image_rgb = bgr_to_rgb(image_bgr)
# 이미지에서 얼굴 후보 목록을 추출합니다.
faces = app.get(image_rgb)
# 검출된 얼굴이 없으면 사용자에게 재촬영을 안내할 수 있도록 메시지를 반환합니다.
if len(faces) == 0:
return None, "얼굴을 찾지 못했습니다. 정면 얼굴이 잘 보이는 이미지로 다시 시도하세요."
# 여러 얼굴이 검출되면 로그인 보안을 위해 가장 큰 얼굴 하나를 기준으로 사용합니다.
largest_face = max(
faces,
key=lambda face: (face.bbox[2] - face.bbox[0]) * (face.bbox[3] - face.bbox[1]),
)
# InsightFace가 제공하는 embedding은 일반적으로 512차원 얼굴 특징 벡터입니다.
embedding = largest_face.embedding.astype(np.float32)
# 벡터 크기를 계산합니다. 0이면 정규화할 수 없으므로 실패 처리합니다.
norm = np.linalg.norm(embedding)
# norm이 0이면 유효하지 않은 임베딩으로 판단합니다.
if norm == 0:
return None, "얼굴 특징 벡터를 생성하지 못했습니다."
# 코사인 유사도 비교를 안정적으로 하기 위해 L2 정규화를 수행합니다.
normalized_embedding = embedding / norm
# 정상 임베딩과 성공 메시지를 반환합니다.
return normalized_embedding, "얼굴 특징 추출 성공"
ensure_dirs 저장 폴더가 없으면 생성하고
사용자 id에 숫자, 영문 _ - 만 허용하고 제거한다. "".join()으로 필터링 된 문자들을 다시 하나의 문자열로 합친다 .
저장할 이미지 파일 경로를 만들어 imwrite.
즉 id를 받아 이미지를 저장하는 함수이다 .
def save_registered_face_image(user_id: str, image_bgr: np.ndarray) -> Path:
"""등록용 얼굴 이미지를 파일로 저장합니다."""
# 저장 폴더가 없으면 생성합니다.
ensure_dirs()
# 사용자 ID에 파일 경로 특수문자가 들어오는 것을 피하기 위해 안전한 문자만 남깁니다.
safe_user_id = "".join(ch for ch in user_id if ch.isalnum() or ch in ("_", "-"))
# 저장할 이미지 파일 경로를 만듭니다.
image_path = FACE_IMAGE_DIR / f"{safe_user_id}.jpg"
# OpenCV imwrite로 BGR 이미지를 jpg 파일로 저장합니다.
cv2.imwrite(str(image_path), image_bgr)
# 저장된 경로를 반환합니다.
return image_path
사용자 id를 받아다 값이 없으면 alert.
id의 앞뒤 공백을 제거하고 이미지에서 임베딩을 추출해 실패시 alert.
얼굴 db를 불러와 id키로 하여 얼굴 임베딩을 저장하고 해당 데이터를 db파일에 저장한다 .
등록 이미지 원본도 앞서 정의한 함수 save_registered_face_image에 의해 별도 폴더에 저장한다.
def register_face(user_id: str, image_bgr: np.ndarray) -> Tuple[bool, str]:
"""사용자 ID와 얼굴 이미지를 이용해 얼굴 로그인을 등록합니다."""
# 공백만 있는 사용자 ID는 허용하지 않습니다.
if not user_id or not user_id.strip():
return False, "사용자 ID를 입력하세요."
# 입력된 사용자 ID의 앞뒤 공백을 제거합니다.
user_id = user_id.strip()
# 이미지에서 얼굴 임베딩을 추출합니다.
embedding, message = extract_embedding(image_bgr)
# 임베딩 추출에 실패하면 실패 메시지를 그대로 반환합니다.
if embedding is None:
return False, message
# 기존 얼굴 데이터베이스를 불러옵니다.
face_db = load_face_db()
# 사용자 ID를 키로 하여 얼굴 임베딩을 저장합니다.
face_db[user_id] = embedding
# 갱신된 얼굴 데이터베이스를 파일에 저장합니다.
save_face_db(face_db)
# 등록 이미지 원본도 별도 폴더에 저장하여 추후 확인할 수 있게 합니다.
save_registered_face_image(user_id, image_bgr)
# 성공 여부와 안내 메시지를 반환합니다.
return True, f"{user_id} 사용자의 얼굴 등록이 완료되었습니다."
입력값 a, b를 받는다. 이둘은 특징 벡터로.
np.dot() 내적 dor product 가 유사도를 확인할 수 있다. return.
def cosine_similarity(a: np.ndarray, b: np.ndarray) -> float:
"""두 정규화된 얼굴 임베딩 벡터의 코사인 유사도를 계산합니다."""
# 두 벡터가 이미 L2 정규화되어 있으므로 내적 값이 코사인 유사도가 됩니다.
return float(np.dot(a, b))
데이터베이스를 불러온다. 데이터가없다면 alert.
로그인 이미지에서 얼굴 임베딩을 추출하고 불가하다면 alert.
최고 유사도 값을 저장할 변수를 -1.0 매우 낮은 음수로 우선 세팅.
등록된 모든 사용자 얼굴과 로그인 얼굴을 for문으로 배교.
현재 점수가 최고 점수보다 높으면 후보를 게속해서 갱신하며 임계값 threshold 이상이면 동일인물로 판단한다.
낮으면 충분히 일치하지않는다고 alert.
def verify_face(image_bgr: np.ndarray, threshold: float = DEFAULT_SIMILARITY_THRESHOLD) -> Tuple[bool, Optional[str], float, str]:
"""로그인 시 촬영한 얼굴과 등록된 얼굴 DB를 비교합니다."""
# 저장된 얼굴 데이터베이스를 불러옵니다.
face_db = load_face_db()
# 등록된 얼굴이 하나도 없으면 로그인할 수 없으므로 실패 처리합니다.
if len(face_db) == 0:
return False, None, 0.0, "등록된 얼굴이 없습니다. 먼저 얼굴을 등록하세요."
# 로그인 이미지에서 얼굴 임베딩을 추출합니다.
embedding, message = extract_embedding(image_bgr)
# 임베딩 추출에 실패하면 실패 메시지를 반환합니다.
if embedding is None:
return False, None, 0.0, message
# 최고 유사도 사용자의 ID를 저장할 변수를 초기화합니다.
best_user_id: Optional[str] = None
# 최고 유사도 값을 저장할 변수를 매우 낮은 값으로 초기화합니다.
best_score = -1.0
# 등록된 모든 사용자 얼굴과 입력 얼굴을 비교합니다.
for user_id, registered_embedding in face_db.items():
# 현재 사용자와의 코사인 유사도를 계산합니다.
score = cosine_similarity(embedding, registered_embedding)
# 현재 점수가 최고 점수보다 높으면 최고 후보를 갱신합니다.
if score > best_score:
best_score = score
best_user_id = user_id
# 최고 유사도가 임계값 이상이면 동일 인물로 판단합니다.
if best_score >= threshold:
return True, best_user_id, best_score, "얼굴 로그인이 성공했습니다."
# 임계값 미만이면 등록된 사용자와 일치하지 않는 것으로 판단합니다.
return False, best_user_id, best_score, "등록된 얼굴과 충분히 일치하지 않습니다."
stramlit에서 업로드된 파일을 opencv bgr 파일로 변환한다. 업로드 파일이 없으면 none.
업로드된 바이트 데이터를 numpy배열로 변환해 bgr 이미지 배열로 변환해 return/
def read_uploaded_image(uploaded_file) -> Optional[np.ndarray]:
"""Streamlit 업로드 파일을 OpenCV BGR 이미지로 변환합니다."""
# 업로드 파일이 없으면 None을 반환합니다.
if uploaded_file is None:
return None
# 업로드된 바이트 데이터를 NumPy 배열로 변환합니다.
file_bytes = np.frombuffer(uploaded_file.getvalue(), dtype=np.uint8)
# OpenCV imdecode로 이미지 파일 바이트를 BGR 이미지 배열로 변환합니다.
image_bgr = cv2.imdecode(file_bytes, cv2.IMREAD_COLOR)
# 변환된 이미지를 반환합니다.
return image_bgr
ui.py를 살펴보자 .stramlit으로 웹 화면을 구성하는 코드다.
stramlit import.
loggeed_in 정보가 없으면 false로 설정.
id가 세션이 없으면 none으로 설정.
유사도 점수가 없으면 0.0으로 설정
logout 시 로그인여부를 false로 변경, id제거, 유사도 점수 초기화.
"""Streamlit 화면 구성에 필요한 UI 보조 함수를 모아 둔 모듈입니다."""
# Streamlit은 웹 화면을 구성하는 데 사용합니다.
import streamlit as st
def init_session_state() -> None:
"""로그인 상태 등 Streamlit 세션 변수를 초기화합니다."""
# 로그인 여부가 세션에 없으면 기본값 False로 생성합니다.
if "logged_in" not in st.session_state:
st.session_state.logged_in = False
# 로그인 사용자 ID가 세션에 없으면 None으로 생성합니다.
if "user_id" not in st.session_state:
st.session_state.user_id = None
# 얼굴 유사도 점수가 세션에 없으면 0.0으로 생성합니다.
if "face_score" not in st.session_state:
st.session_state.face_score = 0.0
def logout() -> None:
"""현재 로그인 세션을 초기화합니다."""
# 로그인 여부를 False로 변경합니다.
st.session_state.logged_in = False
# 사용자 ID를 제거합니다.
st.session_state.user_id = None
# 얼굴 유사도 점수를 초기화합니다.
st.session_state.face_score = 0.0
다음으로 고객이탈 예측용 사전학습 모델을 생성하는 스크립트를 살펴보자. train_chrun_model.py
import 경로관리를 위한 path클래스, 모델 저장을 위한 joblib, 숫자형 범주형 컬럼에 서로 다른 전처리를위한 columntransformer
비선형 패턴을 잘 학습하는 고객이탈 분류 모델로 randomforestclassifier 를 사용하기 위해 import
범주형 문자를 머신러닝 모델이 처리할 수 있는 숫자벡터로 변환하기 위해 onehorencoder
정규화 standardscaler
classification_report는 모델 성능을 간단히 확인 할때 쓴다.
# 경로 관리를 위해 pathlib의 Path 클래스를 가져옵니다.
from pathlib import Path
# 모델 저장을 위해 joblib을 가져옵니다.
import joblib
# NumPy는 재현 가능한 샘플 데이터 생성을 위해 사용합니다.
import numpy as np
# pandas는 학습 데이터를 표 형태로 구성하기 위해 사용합니다.
import pandas as pd
# ColumnTransformer는 숫자형과 범주형 컬럼에 서로 다른 전처리를 적용하기 위해 사용합니다.
from sklearn.compose import ColumnTransformer
# RandomForestClassifier는 비선형 패턴을 잘 학습하는 고객 이탈 분류 모델로 사용합니다.
from sklearn.ensemble import RandomForestClassifier
# Pipeline은 전처리와 모델을 하나의 객체로 묶어 저장하기 위해 사용합니다.
from sklearn.pipeline import Pipeline
# OneHotEncoder는 범주형 문자를 머신러닝 모델이 처리할 수 있는 숫자 벡터로 변환합니다.
from sklearn.preprocessing import OneHotEncoder, StandardScaler
# train_test_split은 학습/검증 데이터를 나누는 데 사용합니다.
from sklearn.model_selection import train_test_split
# classification_report는 모델 성능을 간단히 확인하기 위해 사용합니다.
from sklearn.metrics import classification_report
데이터 파일 경로 정의, 모델폴더 저장 경로 정의, 모델 저장 파일경로 정의, 모델에 사용할 숫자형 컬럼 목록 초기화. 범주형 컬럼 목록 초기화.
# 학습 데이터 파일 경로를 정의합니다.
DATA_PATH = Path("data/telco_churn_sample.csv")
# 모델 저장 폴더 경로를 정의합니다.
MODEL_DIR = Path("models")
# 모델 저장 파일 경로를 정의합니다.
MODEL_PATH = MODEL_DIR / "churn_model.joblib"
# 모델에 사용할 숫자형 컬럼 목록입니다.
NUMERIC_COLUMNS = ["tenure", "MonthlyCharges", "TotalCharges"]
# 모델에 사용할 범주형 컬럼 목록입니다.
CATEGORICAL_COLUMNS = [
"gender",
"SeniorCitizen",
"Partner",
"Dependents",
"PhoneService",
"MultipleLines",
"InternetService",
"OnlineSecurity",
"OnlineBackup",
"DeviceProtection",
"TechSupport",
"StreamingTV",
"StreamingMovies",
"Contract",
"PaperlessBilling",
"PaymentMethod",
]
난수고정.
고객 유지기간은 0~ 72 개월 범위에서 생성.
월 요금을 18~120사이의 값으로 생성
위 내용으로 총 요금 구하기.
범주형 고객 특성을 무작위로 생성.
이탈 위험 점수 기본 로짓값. -1 에서
월단위계약고객은 높이고 장기계약 고객은 낮춘다.
광케이블 인터넷 고객은 높이고 전자수표 결제고객도 높인다. 기술지원이 없는 고객도 높인다. 온라인 보안 서비스가 없는 고객도 높인다 .
가입기간이 낮을수록 낮추고
월요금이 높을 수록 높인다
로짓을 0~1 사이 확률로 변환한다.
확률을 기반으로 이탈 여부를 binomial 베르누이 시행, churn_probability를 보고 데이터들에 확률만 있고 정답은 없음으로 랜덤으로 결과값을 결정한다.
즉 확률을 기준으로 0이나 1을 랜덤하게 생성하는 코드.
def generate_sample_dataset(n_rows: int = 1200) -> pd.DataFrame:
"""IBM Telco Customer Churn 구조를 참고한 실습용 샘플 데이터를 생성합니다."""
# 난수 발생기를 고정하여 매번 동일한 학습 데이터가 생성되도록 합니다.
rng = np.random.default_rng(42)
# 고객 유지 기간을 0~72개월 범위에서 생성합니다.
tenure = rng.integers(0, 73, size=n_rows)
# 월 요금을 18~120 사이의 값으로 생성합니다.
monthly = rng.uniform(18, 120, size=n_rows).round(2)
# 총 요금은 유지 기간과 월 요금의 곱에 약간의 잡음을 더해 생성합니다.
total = np.maximum(0, tenure * monthly + rng.normal(0, 80, size=n_rows)).round(2)
# 주요 범주형 고객 특성을 무작위로 생성합니다.
df = pd.DataFrame({
"gender": rng.choice(["Male", "Female"], size=n_rows),
"SeniorCitizen": rng.choice(["0", "1"], size=n_rows, p=[0.84, 0.16]),
"Partner": rng.choice(["Yes", "No"], size=n_rows),
"Dependents": rng.choice(["Yes", "No"], size=n_rows, p=[0.3, 0.7]),
"tenure": tenure,
"PhoneService": rng.choice(["Yes", "No"], size=n_rows, p=[0.9, 0.1]),
"MultipleLines": rng.choice(["Yes", "No", "No phone service"], size=n_rows),
"InternetService": rng.choice(["DSL", "Fiber optic", "No"], size=n_rows, p=[0.35, 0.45, 0.2]),
"OnlineSecurity": rng.choice(["Yes", "No", "No internet service"], size=n_rows),
"OnlineBackup": rng.choice(["Yes", "No", "No internet service"], size=n_rows),
"DeviceProtection": rng.choice(["Yes", "No", "No internet service"], size=n_rows),
"TechSupport": rng.choice(["Yes", "No", "No internet service"], size=n_rows),
"StreamingTV": rng.choice(["Yes", "No", "No internet service"], size=n_rows),
"StreamingMovies": rng.choice(["Yes", "No", "No internet service"], size=n_rows),
"Contract": rng.choice(["Month-to-month", "One year", "Two year"], size=n_rows, p=[0.55, 0.25, 0.2]),
"PaperlessBilling": rng.choice(["Yes", "No"], size=n_rows),
"PaymentMethod": rng.choice([
"Electronic check",
"Mailed check",
"Bank transfer (automatic)",
"Credit card (automatic)",
], size=n_rows),
"MonthlyCharges": monthly,
"TotalCharges": total,
})
# 이탈 위험 점수를 만들기 위한 기본 로짓 값을 계산합니다.
logit = -1.0
# 월 단위 계약 고객은 이탈 위험을 높입니다.
logit += (df["Contract"] == "Month-to-month").astype(float) * 1.25
# 장기 계약 고객은 이탈 위험을 낮춥니다.
logit -= (df["Contract"] == "Two year").astype(float) * 1.0
# 광케이블 인터넷 고객은 높은 요금과 결합되어 이탈 위험이 커질 수 있습니다.
logit += (df["InternetService"] == "Fiber optic").astype(float) * 0.55
# 전자수표 결제 고객은 원본 Telco 데이터에서도 이탈 위험이 높은 편으로 자주 분석됩니다.
logit += (df["PaymentMethod"] == "Electronic check").astype(float) * 0.55
# 기술 지원이 없는 고객은 서비스 불만족 가능성이 높다고 가정합니다.
logit += (df["TechSupport"] == "No").astype(float) * 0.45
# 온라인 보안 서비스가 없는 고객도 이탈 위험이 높다고 가정합니다.
logit += (df["OnlineSecurity"] == "No").astype(float) * 0.35
# 가입 기간이 길수록 이탈 가능성이 낮아지도록 반영합니다.
logit -= df["tenure"] * 0.035
# 월 요금이 높을수록 이탈 가능성이 높아지도록 반영합니다.
logit += (df["MonthlyCharges"] - 65) * 0.012
# 로짓을 0~1 사이 확률로 변환합니다.
churn_probability = 1 / (1 + np.exp(-logit))
# 확률을 기준으로 이탈 여부를 샘플링합니다.
df["Churn"] = rng.binomial(1, churn_probability)
# 학습용 CSV를 반환합니다.
return df
data 폴더가 없으면 생성한다 . 있으면 읽어 사용한다 샘플 데이터를 생성한다. 생성데이터는 csv로 저장해 이후 재사용이 가능하도록 한다.
def load_or_create_dataset() -> pd.DataFrame:
"""학습 데이터가 있으면 불러오고, 없으면 샘플 데이터를 생성합니다."""
# data 폴더가 없으면 생성합니다.
DATA_PATH.parent.mkdir(parents=True, exist_ok=True)
# CSV 파일이 있으면 해당 파일을 읽어 사용합니다.
if DATA_PATH.exists():
return pd.read_csv(DATA_PATH)
# CSV 파일이 없으면 실습용 샘플 데이터를 생성합니다.
df = generate_sample_dataset()
# 생성한 데이터를 CSV로 저장하여 이후 동일한 데이터를 재사용합니다.
df.to_csv(DATA_PATH, index=False)
# 생성된 DataFrame을 반환합니다.
return df
파이프라인생성.
숫자형 컬럼은 standardscaler로 평균 0 표준편차 1로 표준화한다.
범주형 컬럼은 onehotencoder로 인코딩. handle_unkown=ignore로 없던 값이 들어와도 오류가 나지않게 처리한다.
columnTransformer로 전처리기를 하나로 묶는다.
randomforestclassfier 모델정의.
전처리와 모델을 순서대로 실행하는 파이프라인을 만든다.
return.
def build_pipeline() -> Pipeline:
"""전처리와 RandomForest 모델을 하나로 묶은 파이프라인을 생성합니다."""
# 숫자형 컬럼은 평균 0, 표준편차 1 기준으로 표준화합니다.
numeric_transformer = StandardScaler()
# 범주형 컬럼은 원-핫 인코딩하고, 학습 때 없던 값이 들어와도 오류가 나지 않게 처리합니다.
categorical_transformer = OneHotEncoder(handle_unknown="ignore")
# 컬럼 종류별 전처리기를 하나로 묶습니다.
preprocessor = ColumnTransformer(
transformers=[
("num", numeric_transformer, NUMERIC_COLUMNS),
("cat", categorical_transformer, CATEGORICAL_COLUMNS),
]
)
# RandomForest는 여러 의사결정나무를 조합하여 안정적인 분류 결과를 만드는 앙상블 모델입니다.
classifier = RandomForestClassifier(
n_estimators=250,
max_depth=9,
random_state=42,
class_weight="balanced",
)
# 전처리와 모델을 순서대로 실행하는 파이프라인을 만듭니다.
pipeline = Pipeline(steps=[("preprocess", preprocessor), ("model", classifier)])
# 완성된 파이프라인 객체를 반환합니다.
return pipeline
실행하는 main코드.
모델 저장 폴더가 없으면 생성한다 .
학습 데이터를 불러오거나 생성한다.
x 와 y를 분리한다.
8:2 비율로 나눈다.
파이프라인 생성.
model.fit()
model.predict 예측 결과 계산 및 출력.
학습이 완료된 모델을 joblib.dump() 파일로 저장
def main() -> None:
"""학습 데이터를 이용해 고객 이탈 예측 모델을 학습하고 저장합니다."""
# 모델 저장 폴더가 없으면 생성합니다.
MODEL_DIR.mkdir(parents=True, exist_ok=True)
# 학습 데이터를 불러오거나 생성합니다.
df = load_or_create_dataset()
# 입력 특성 X와 정답 y를 분리합니다.
X = df[NUMERIC_COLUMNS + CATEGORICAL_COLUMNS]
y = df["Churn"].astype(int)
# 학습 데이터와 검증 데이터를 8:2 비율로 나눕니다.
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42,
stratify=y,
)
# 전처리와 모델이 포함된 파이프라인을 생성합니다.
model = build_pipeline()
# 학습 데이터를 이용해 모델을 학습합니다.
model.fit(X_train, y_train)
# 검증 데이터에 대한 예측 결과를 계산합니다.
y_pred = model.predict(X_test)
# 검증 성능 리포트를 터미널에 출력합니다.
print(classification_report(y_test, y_pred, digits=4))
# 학습이 완료된 모델 파이프라인을 joblib 파일로 저장합니다.
joblib.dump(model, MODEL_PATH)
# 저장 위치를 출력합니다.
print(f"모델 저장 완료: {MODEL_PATH}")
파일을 직접 실행할때만 main함수를 실행하도록 설정
# 이 파일을 직접 실행할 때만 main 함수를 실행합니다.
if __name__ == "__main__":
main()
마지막으로 app.py를 분석해보자.
import
stramlit과
얼굴등록, 인증, 이미지 변환 함수를 가져온다. 앞서 확인했던 face_auth.py
고객이탈 예측 함수도 가져온다. 앞서 확인한 churn_service.
app.ui의 init_session_state, logout 세션 초기화와 로그아웃 함수를 가져온다 .
# Streamlit은 웹 애플리케이션 화면을 구성하는 프레임워크입니다.
import streamlit as st
# 얼굴 등록, 얼굴 인증, 업로드 이미지 변환 함수를 가져옵니다.
from app.face_auth import read_uploaded_image, register_face, verify_face, DEFAULT_SIMILARITY_THRESHOLD
# 고객 이탈 예측 함수를 가져옵니다.
from app.churn_service import predict_churn
# 세션 초기화와 로그아웃 함수를 가져옵니다.
from app.ui import init_session_state, logout
제목, 화면폭 설정
세션 포기화
메인제목 출력.
캡션으로 간단히 설명.
# Streamlit 페이지 제목, 아이콘, 화면 폭을 설정합니다.
st.set_page_config(page_title="Face Login + Churn Prediction", page_icon="🔐", layout="wide")
# 앱 시작 시 세션 상태를 초기화합니다.
init_session_state()
# 메인 제목을 출력합니다.
st.title("🔐 InsightFace 얼굴 로그인 + 고객 이탈 예측 서비스")
# 앱의 핵심 동작을 간단히 설명합니다.
st.caption("얼굴 등록 → 얼굴 로그인 → 로그인 후 고객 이탈 예측 기능 사용")
사이드 바에 header 출력.
logged_in 정보 st.success 표시, info로 유사도 표시.
로그아웃을 누르면 logout()
else의 경우 warning.
slider를 통해 얼굴 인증 임계값을 조정할 수 있게한다. 사실상 테스트 기능.
min, max, value, step 기본지정. help 안내문구 출력
# 사이드바에 로그인 상태를 표시합니다.
with st.sidebar:
# 사이드바 제목을 출력합니다.
st.header("사용자 상태")
# 현재 로그인 상태라면 사용자 ID와 얼굴 유사도를 표시합니다.
if st.session_state.logged_in:
st.success(f"로그인 사용자: {st.session_state.user_id}")
st.info(f"얼굴 유사도: {st.session_state.face_score:.3f}")
# 로그아웃 버튼을 누르면 세션을 초기화합니다.
if st.button("로그아웃"):
logout()
st.rerun()
else:
# 로그인 전에는 안내 메시지를 표시합니다.
st.warning("현재 로그인되지 않았습니다.")
# 얼굴 인증 임계값을 사용자가 조정할 수 있게 합니다.
threshold = st.slider(
"얼굴 인증 임계값",
min_value=0.20,
max_value=0.80,
value=DEFAULT_SIMILARITY_THRESHOLD,
step=0.01,
help="값을 높이면 보안은 강해지지만 로그인 실패가 늘 수 있습니다.",
)
logged_in이 아닐경우
얼굴 등록, 얼굴 로그인 이라는 tabs 생성.
각 서브 제목 풀력.
등롣 탭 화면에 id입력받기. camera_input으로 이미지 입력. st.file_uploader 파일업로드도 제공.
촬영이미지가 있으면 사용, 없으면 업로드 이미지를 사용하도록 한다.
등록 버튼을 누르면 read_upoload_image() opencv 이미지로 변환하되 없으면 경고. 있으면 register_fact() 얼굴 등록 함수 호출. 성공시 메세지, 실패시 메세지.
로그인탭화면에서는 마찬가지로 st.camera_input() 이미지를 입력, 파일업로드도 제공, 촬영이미지를 우선 사용한다.
로그인 버튼을 누르면 read_upload_image() opencv bgr 이미지로 변환하되 이미지가 없으면 경고, 있으면 vertify_face() 등록 얼굴 db와 입력 얼굴을 비교한다.
인증 성공시 세션 저장, else시 가장 가까운 후보와 점수를 함께 표시해준다.
로그인 후에는 고객이탈 예측 서비스를 표시한다.
subheade 표시.
chrun_form을 사용해 고객정보를 입력받고. col1, col2로 입력항목을 보기좋게했다.
기본정보 입력는 col1, 서비스 이용정보 col2
사용자가 submitted를 누르면 각 칼럼에 value매칭해predict_chrun() 추론 서비스 호출.
퍼센트 변환.
예측 결과를 라벨로 크게 표시한다.
progress 프로그래스 바로 표시한다.
if predtction이 1과 같아 이탈 위험이 높다면 전략txt 문구를 출력. else일 경우 다른 txt문구 출력.
# 로그인 전에는 얼굴 등록과 얼굴 로그인 탭을 제공합니다.
if not st.session_state.logged_in:
# 얼굴 등록 탭과 얼굴 로그인 탭을 생성합니다.
register_tab, login_tab = st.tabs(["1. 얼굴 등록", "2. 얼굴 로그인"])
# 얼굴 등록 탭 화면을 구성합니다.
with register_tab:
# 등록 섹션 제목을 출력합니다.
st.subheader("얼굴 등록")
# 등록할 사용자 ID를 입력받습니다.
user_id = st.text_input("사용자 ID", placeholder="예: user01")
# 카메라 촬영 이미지를 입력받습니다.
camera_image = st.camera_input("등록할 얼굴을 촬영하세요.")
# 파일 업로드 방식도 함께 제공합니다.
uploaded_image = st.file_uploader("또는 얼굴 이미지 파일 업로드", type=["jpg", "jpeg", "png"], key="register_upload")
# 촬영 이미지가 있으면 우선 사용하고, 없으면 업로드 이미지를 사용합니다.
selected_file = camera_image if camera_image is not None else uploaded_image
# 등록 버튼을 누르면 얼굴 등록 로직을 실행합니다.
if st.button("얼굴 등록 실행", type="primary"):
# 업로드 또는 촬영 파일을 OpenCV 이미지로 변환합니다.
image_bgr = read_uploaded_image(selected_file)
# 이미지가 없으면 경고를 표시합니다.
if image_bgr is None:
st.warning("등록할 얼굴 이미지를 촬영하거나 업로드하세요.")
else:
# 얼굴 등록 함수를 호출합니다.
ok, message = register_face(user_id, image_bgr)
# 등록 성공 시 성공 메시지를 표시합니다.
if ok:
st.success(message)
else:
# 등록 실패 시 오류 메시지를 표시합니다.
st.error(message)
# 얼굴 로그인 탭 화면을 구성합니다.
with login_tab:
# 로그인 섹션 제목을 출력합니다.
st.subheader("얼굴 로그인")
# 로그인용 카메라 촬영 이미지를 입력받습니다.
login_camera_image = st.camera_input("로그인할 얼굴을 촬영하세요.", key="login_camera")
# 로그인용 파일 업로드도 제공합니다.
login_uploaded_image = st.file_uploader("또는 로그인 얼굴 이미지 업로드", type=["jpg", "jpeg", "png"], key="login_upload")
# 촬영 이미지가 있으면 우선 사용하고, 없으면 업로드 이미지를 사용합니다.
login_selected_file = login_camera_image if login_camera_image is not None else login_uploaded_image
# 로그인 버튼을 누르면 얼굴 비교 로직을 실행합니다.
if st.button("얼굴 로그인 실행", type="primary"):
# 입력 파일을 OpenCV BGR 이미지로 변환합니다.
image_bgr = read_uploaded_image(login_selected_file)
# 이미지가 없으면 경고를 표시합니다.
if image_bgr is None:
st.warning("로그인할 얼굴 이미지를 촬영하거나 업로드하세요.")
else:
# 등록 얼굴 DB와 입력 얼굴을 비교합니다.
ok, matched_user_id, score, message = verify_face(image_bgr, threshold=threshold)
# 인증 성공 시 로그인 세션을 저장합니다.
if ok:
st.session_state.logged_in = True
st.session_state.user_id = matched_user_id
st.session_state.face_score = score
st.success(f"{message} 사용자: {matched_user_id}, 유사도: {score:.3f}")
st.rerun()
else:
# 인증 실패 시 가장 가까운 후보와 점수를 함께 표시합니다.
st.error(f"{message} 가장 가까운 사용자: {matched_user_id}, 유사도: {score:.3f}")
# 로그인 후에는 고객 이탈 예측 서비스를 표시합니다.
else:
# 고객 이탈 예측 제목을 출력합니다.
st.subheader("📊 고객 이탈 예측")
# 입력 폼을 사용하여 한 번에 고객 정보를 입력받습니다.
with st.form("churn_form"):
# 좌우 두 컬럼을 만들어 입력 항목을 보기 좋게 배치합니다.
col1, col2 = st.columns(2)
# 첫 번째 컬럼에는 기본 고객 정보와 계정 정보를 배치합니다.
with col1:
gender = st.selectbox("성별", ["Male", "Female"])
senior = st.selectbox("고령 고객 여부", ["0", "1"])
partner = st.selectbox("배우자 여부", ["Yes", "No"])
dependents = st.selectbox("부양가족 여부", ["Yes", "No"])
tenure = st.number_input("가입 기간(개월)", min_value=0, max_value=100, value=12)
contract = st.selectbox("계약 유형", ["Month-to-month", "One year", "Two year"])
paperless = st.selectbox("전자 청구서 사용", ["Yes", "No"])
payment = st.selectbox(
"결제 방식",
[
"Electronic check",
"Mailed check",
"Bank transfer (automatic)",
"Credit card (automatic)",
],
)
# 두 번째 컬럼에는 서비스 이용 정보를 배치합니다.
with col2:
phone = st.selectbox("전화 서비스", ["Yes", "No"])
multiple = st.selectbox("복수 회선", ["Yes", "No", "No phone service"])
internet = st.selectbox("인터넷 서비스", ["DSL", "Fiber optic", "No"])
security = st.selectbox("온라인 보안", ["Yes", "No", "No internet service"])
backup = st.selectbox("온라인 백업", ["Yes", "No", "No internet service"])
protection = st.selectbox("기기 보호", ["Yes", "No", "No internet service"])
tech = st.selectbox("기술 지원", ["Yes", "No", "No internet service"])
tv = st.selectbox("스트리밍 TV", ["Yes", "No", "No internet service"])
movies = st.selectbox("스트리밍 영화", ["Yes", "No", "No internet service"])
monthly = st.number_input("월 요금", min_value=0.0, max_value=300.0, value=75.0, step=1.0)
total = st.number_input("총 요금", min_value=0.0, max_value=20000.0, value=900.0, step=10.0)
# 예측 실행 버튼을 생성합니다.
submitted = st.form_submit_button("이탈 예측 실행", type="primary")
# 사용자가 예측 버튼을 누르면 모델 입력값을 만들고 예측을 수행합니다.
if submitted:
# 모델 입력 컬럼명은 학습 때 사용한 컬럼명과 동일해야 합니다.
values = {
"gender": gender,
"SeniorCitizen": senior,
"Partner": partner,
"Dependents": dependents,
"tenure": tenure,
"PhoneService": phone,
"MultipleLines": multiple,
"InternetService": internet,
"OnlineSecurity": security,
"OnlineBackup": backup,
"DeviceProtection": protection,
"TechSupport": tech,
"StreamingTV": tv,
"StreamingMovies": movies,
"Contract": contract,
"PaperlessBilling": paperless,
"PaymentMethod": payment,
"MonthlyCharges": monthly,
"TotalCharges": total,
}
# 고객 이탈 예측 서비스를 호출합니다.
result = predict_churn(values)
# 예측 확률을 퍼센트로 변환합니다.
churn_pct = result["churn_probability"] * 100
# 예측 결과 라벨을 크게 표시합니다.
st.metric("예측 결과", result["label"], f"이탈 확률 {churn_pct:.1f}%")
# 이탈 확률을 진행 막대로 표시합니다.
st.progress(result["churn_probability"])
# 이탈 위험이 높으면 관리 전략을 안내합니다.
if result["prediction"] == 1:
st.warning("이 고객은 이탈 가능성이 높습니다. 장기 계약 할인, 기술 지원 강화, 요금제 재설계를 검토하세요.")
else:
st.success("이 고객은 현재 잔류 가능성이 높습니다. 만족도 유지와 추가 서비스 제안을 검토하세요.")
'Personal > SK 네트웍스 AI 캠프' 카테고리의 다른 글
| [SK네트웍스 Family AI 캠프] 32기 8주차 회고: Day27 ~ Day31 (0) | 2026.06.20 |
|---|---|
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day31_AI 모델 검증을 통한 고도화 (0) | 2026.06.19 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day29_딥러닝 오버피팅방지기법 (0) | 2026.06.18 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day28_딥러닝 다중 퍼셉트론 (0) | 2026.06.16 |
| [SK네트웍스 Family AI 캠프] 32기 7주차 회고: Day24 ~ Day26 (0) | 2026.06.15 |



