다중퍼셉트론 MLP
비선형문제해결이 가능해 XOR문제를 해결하고 다양한 분류 회귀 문제에 적용이 가능하다.
딥러닝 기본 구조를 제공하여 복잡한 패턴학습이 가능하다.
데이터가 많아야 성능이 좋다. 학습시간이 길 수 있고 과적합이 발생이 가능하다.
이미지에서는 CNN 보다 비효율적이고 시계열에서는 RNN, LSTM 보다 비효율적이다 .
입력 - 순전파 forward - 예측값 생성 - 손실함수 계산 - 역전파 - 기울기 - optimiaer - 가중치 수
손글씨 숫자분류, 품질검사등의 이미지분류와,
대출심사, 신용평가, 사기탐지등의 금융,
질병진단, 환자분류등의 의료분야
불량품 판정, 예측 유지보수 등의 제조과정에서 활용된다.
https://standout.tistory.com/1528
인공지능의 역사: 기원(계산 기계 및 지능). 퍼셉트론, 인공지능의 겨울, 전문가 시스템, 신경망
로봇과 인공지능https://standout.tistory.com/881 로봇을 프로그래밍하다, Flexible Work HoldingFlexible Work Holding 로봇에 프로그래밍해 부품이 바뀌어도 다르게 움직이게 하며 차를 만드는 방식을 업그레이드
standout.tistory.com
RNN
순환신경망, 시계열 데이터를 학습하는 딥러닝 기술, 기준 시점t와 다름시점 t+1에 연결,
RNN은 시간순서대로 펼쳐서 생각한다. 동일한 가중치를 공유하는 하나의 셀을 나누어 펼처 사용하는것. 문장을 단어별로 나눠 실행하는 것과 같다.
종류는 1대 다로 이미지 한장으로 문장을 생성하거나 다대일로 영화감상을 읽고 '긍정'과같은 단어를 출력하거나. 다대다로 품사태깅 등이 이되겠다. 이는 주로 번역기와 챗봇에 주로 사용한다.
전체적으로 CNN은 한번에 전체를 보지만 rnn은 앞에서 뒤로, 순차적을 읽는다. 그러기에 rnn이 이미지에 불리하고 cnn은 문장에 분리한다.
https://standout.tistory.com/1537
딥러닝: Deep Neural Network (DNN), Convolutional Neural Network (CNN), Recurrent Neural Network (RNN)
딥러닝 (Deep Learning)이미지 인식, 자연어 처리, 음성 인식 등인공 신경망을 여러 층(layer)으로 쌓아서 구성한 모델다층 구조로 인해 복잡한 데이터 패턴을 자동으로 학습특성 추출
standout.tistory.com
LSTM기술
RNN의 문제는 기억력이 짧다는 것이다. 문장이 이어질때 '그'가 철수였음을 기억해야흐는데 문장이 길어질수록 정보가 희미해진다는 것이다 .이를 기울기 소실 문제라고 한다.
LSTM은 중요한 정보는 오래, 필요없는 정보는 버리자는 아이디어로 내부에 forget gate, input gate, output gate가 있다.이때의 긴 기억통로, cell state가 핵심이다. LSTM의 장기기억공간.
GAN
생성자가 감별자에게, 감별자가 판단하고 감별자가 진짜라고 속았을때 성공시키는 구조.
https://standout.tistory.com/1791
상대적 적대신경망 GAN게임 & 순환 일관성이 보장되는 포토샵신경망 사이클 GAN
앞서 resNet은 출력을 처음부터 만드는게 아닌 입력에서 얼마나 수정할지만 학습하는 잔차학습이라했다 .https://standout.tistory.com/1773 ResNet, 역전파를 그대로 사용하되 Residual Connection을 추가한 CNNResN
standout.tistory.com
샘플코드 optimizer_compare_torch.ipynb를 확인해보자.
TensorDataset 입력, 정답데이터를 하나의 데이터셋 객체로 묶는다.
sklearn.datasets makemoons 비선형 분류 데이터셋, 두개 초승달 모양 클래스를 가졌다.
# torch는 PyTorch의 핵심 라이브러리로, 텐서 연산과 딥러닝 모델 학습에 사용한다.
import torch
# torch.nn은 신경망 계층, 손실 함수 등을 만들 때 사용하는 모듈이다.
import torch.nn as nn
# torch.optim은 SGD, Adam, AdamW 같은 최적화 함수를 제공하는 모듈이다.
import torch.optim as optim
# TensorDataset은 입력 데이터와 정답 데이터를 하나의 데이터셋 객체로 묶기 위해 사용한다.
from torch.utils.data import TensorDataset
# DataLoader는 데이터를 미니배치 단위로 나누어 모델에 공급하기 위해 사용한다.
from torch.utils.data import DataLoader
# make_moons는 두 개의 초승달 모양 클래스를 가진 비선형 분류 데이터셋을 생성한다.
from sklearn.datasets import make_moons
# train_test_split은 데이터를 학습용 데이터와 테스트용 데이터로 나누기 위해 사용한다.
from sklearn.model_selection import train_test_split
# StandardScaler는 입력 특성의 평균을 0, 표준편차를 1에 가깝게 표준화하기 위해 사용한다.
from sklearn.preprocessing import StandardScaler
# accuracy_score는 모델의 예측 정확도를 계산하기 위해 사용한다.
from sklearn.metrics import accuracy_score
# numpy는 배열 계산과 결과 저장을 위해 사용한다.
import numpy as np
# pandas는 최적화 함수별 결과를 표 형태로 정리하기 위해 사용한다.
import pandas as pd
# matplotlib.pyplot은 손실값과 정확도 그래프를 그리기 위해 사용한다.
import matplotlib.pyplot as plt
# random은 파이썬 기본 난수 생성을 고정하기 위해 사용한다.
import random
시드고정
# seed는 난수 생성 결과를 고정하기 위한 기준 숫자이다.
seed = 42
# 파이썬 random 모듈의 난수 생성 기준을 고정한다.
random.seed(seed)
# numpy의 난수 생성 기준을 고정한다.
np.random.seed(seed)
# PyTorch CPU 연산의 난수 생성 기준을 고정한다.
torch.manual_seed(seed)
# CUDA GPU를 사용할 수 있는 경우 GPU 연산의 난수 생성 기준도 고정한다.
torch.cuda.manual_seed_all(seed)
# 현재 실행 환경에서 GPU를 사용할 수 있으면 cuda를, 사용할 수 없으면 cpu를 사용하도록 장치를 설정한다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 실제로 사용할 연산 장치를 출력한다.
print("사용 장치:", device)
make_noons() 샘플 2000개 데이터셋 생성, train_test_split, standscaler,
학습에는 fit, 테스트데이터에는 그냥 transform만.
torch.tensor변환
TensorDataset으로 학습, 정답을 묶어 DataLoder
# make_moons 함수로 샘플 2000개짜리 이진 분류 데이터셋을 생성한다.
X, y = make_moons(n_samples=2000, noise=0.25, random_state=seed)
# train_test_split으로 전체 데이터를 학습용 80%, 테스트용 20%로 나눈다.
X_train, X_test, y_train, y_test = train_test_split(
X, # 입력 데이터 전체를 전달한다.
y, # 정답 라벨 전체를 전달한다.
test_size=0.2, # 전체 데이터 중 20%를 테스트 데이터로 사용한다.
random_state=seed, # 데이터를 나누는 난수 기준을 고정한다.
stratify=y # 클래스 비율이 학습/테스트 데이터에서 비슷하게 유지되도록 한다.
)
# StandardScaler 객체를 생성하여 입력 데이터의 스케일을 맞출 준비를 한다.
scaler = StandardScaler()
# 학습 데이터 기준으로 평균과 표준편차를 계산하고, 학습 데이터를 표준화한다.
X_train = scaler.fit_transform(X_train)
# 테스트 데이터는 학습 데이터에서 계산된 평균과 표준편차를 그대로 사용하여 표준화한다.
X_test = scaler.transform(X_test)
# numpy 배열인 학습 입력 데이터를 PyTorch float32 텐서로 변환한다.
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
# numpy 배열인 테스트 입력 데이터를 PyTorch float32 텐서로 변환한다.
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
# numpy 배열인 학습 정답 데이터를 PyTorch long 텐서로 변환한다.
y_train_tensor = torch.tensor(y_train, dtype=torch.long)
# numpy 배열인 테스트 정답 데이터를 PyTorch long 텐서로 변환한다.
y_test_tensor = torch.tensor(y_test, dtype=torch.long)
# 학습 입력 텐서와 정답 텐서를 하나의 TensorDataset으로 묶는다.
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
# DataLoader를 사용하여 학습 데이터를 32개씩 미니배치로 가져오도록 설정한다.
train_loader = DataLoader(
train_dataset, # 미니배치로 나눌 학습 데이터셋을 전달한다.
batch_size=32, # 한 번의 학습 단계에서 사용할 데이터 개수를 32개로 설정한다.
shuffle=True # 매 epoch마다 데이터 순서를 섞어 학습 안정성을 높인다.
)
# 입력 데이터의 모양을 출력하여 특성 수가 2개인지 확인한다.
print("X_train shape:", X_train.shape)
# 정답 데이터의 클래스 종류를 출력하여 이진 분류 문제인지 확인한다.
print("classes:", np.unique(y_train))
nn.Module을 매개변수로 받아 클래서 생성.
nn.Sequential 순서대로 연결한 신경망
Linear, Relu 조합 입력
forward 순전파정의
# SimpleMLP 클래스는 nn.Module을 상속하여 PyTorch 신경망 모델을 정의한다.
class SimpleMLP(nn.Module):
# __init__ 메서드는 모델에 필요한 계층을 생성하는 초기화 함수이다.
def __init__(self):
# 부모 클래스인 nn.Module의 초기화 기능을 실행한다.
super().__init__()
# self.network는 여러 계층을 순서대로 연결한 신경망이다.
self.network = nn.Sequential(
# 첫 번째 Linear 계층은 입력 특성 2개를 은닉 노드 16개로 변환한다.
nn.Linear(2, 16),
# ReLU는 음수는 0으로, 양수는 그대로 통과시켜 비선형성을 추가한다.
nn.ReLU(),
# 두 번째 Linear 계층은 은닉 노드 16개를 다시 은닉 노드 16개로 변환한다.
nn.Linear(16, 16),
# 두 번째 ReLU도 모델이 복잡한 곡선 형태의 분류 경계를 학습하게 도와준다.
nn.ReLU(),
# 마지막 Linear 계층은 은닉 노드 16개를 클래스 2개의 점수로 변환한다.
nn.Linear(16, 2)
)
# forward 메서드는 입력 데이터가 모델 내부를 통과하는 순전파 과정을 정의한다.
def forward(self, x):
# 입력 x를 self.network에 통과시켜 클래스별 점수를 반환한다.
return self.network(x)
optimizer를 만들어보자. 같은 모델에서 optimizer를 바꿔가며 수행 할수있도록 if과 else를 정렬했다.
# get_optimizer 함수는 optimizer_name에 따라 서로 다른 PyTorch 최적화 함수를 생성한다.
def get_optimizer(optimizer_name, model):
# optimizer_name이 "SGD"이면 기본 SGD 최적화 함수를 사용한다.
if optimizer_name == "SGD":
# SGD는 가장 기본적인 경사하강법 계열 최적화 함수이다.
return optim.SGD(model.parameters(), lr=0.01)
# optimizer_name이 "SGD_Momentum"이면 Momentum이 추가된 SGD를 사용한다.
elif optimizer_name == "SGD_Momentum":
# momentum=0.9는 이전 업데이트 방향을 90% 정도 반영하겠다는 의미이다.
return optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
# optimizer_name이 "RMSprop"이면 RMSprop 최적화 함수를 사용한다.
elif optimizer_name == "RMSprop":
# RMSprop은 파라미터별로 학습률을 조정하여 학습을 안정화한다.
return optim.RMSprop(model.parameters(), lr=0.001)
# optimizer_name이 "Adam"이면 Adam 최적화 함수를 사용한다.
elif optimizer_name == "Adam":
# Adam은 Momentum과 RMSprop의 아이디어를 결합한 대표적인 최적화 함수이다.
return optim.Adam(model.parameters(), lr=0.001)
# optimizer_name이 "AdamW"이면 AdamW 최적화 함수를 사용한다.
elif optimizer_name == "AdamW":
# AdamW는 Adam에 weight_decay를 더 올바른 방식으로 적용하여 과적합을 줄이는 데 도움을 준다.
return optim.AdamW(model.parameters(), lr=0.001, weight_decay=0.01)
# 위 조건에 없는 이름이 들어오면 오류를 발생시킨다.
else:
# 사용자가 잘못된 최적화 함수 이름을 넣었음을 알려준다.
raise ValueError("지원하지 않는 optimizer_name입니다.")
학습 함수 정의. optimizer_name을 받고 epoch의 기본값은 50이다.
seed 고정, SimpleMLP 객체 생성, device 이동, 다중분류를 위한 nn.CrossEntropyLoss 손실함수생성.
get_optimizer , epoch만큼 학습, dataloader에서 batch입력, 정답을 하나씩 꺼내 device로 이동후
optimizer 전 zero_grad로 기울기 초기화, model() 모델 객체 SimpleMLP에 입력데이터 넣어 예측점수계산,
criteriton로 실제 정답 비교해 손실값 계산. loss.backward 손실값기준으로 가중치, 편향 업데이트.
epoch 전체 평균 손실값을 계싼해 평가모드로 전환. 이때 with.torch.nograd() 로 메모리 사용을 줄인다.
device로 데이터 이동,
torch.argmax() 가장 높은 클래스 번호를 최종예측값으로 선택해 cpu로 옮겨 numpy 변환,
accuracy_score 정확도 계산
# train_one_optimizer 함수는 하나의 최적화 함수로 모델을 학습하고 결과를 반환한다.
def train_one_optimizer(optimizer_name, epochs=50):
# 매 실험마다 같은 초기 가중치에서 시작하도록 PyTorch seed를 다시 고정한다.
torch.manual_seed(seed)
# SimpleMLP 모델 객체를 생성한다.
model = SimpleMLP()
# 모델을 CPU 또는 GPU 장치로 이동시킨다.
model = model.to(device)
# 다중 클래스 분류용 손실 함수인 CrossEntropyLoss를 생성한다.
criterion = nn.CrossEntropyLoss()
# optimizer_name에 해당하는 최적화 함수를 생성한다.
optimizer = get_optimizer(optimizer_name, model)
# epoch별 평균 손실값을 저장할 리스트를 생성한다.
loss_history = []
# epoch별 테스트 정확도를 저장할 리스트를 생성한다.
acc_history = []
# 지정한 epoch 수만큼 학습을 반복한다.
for epoch in range(epochs):
# 모델을 학습 모드로 전환한다.
model.train()
# 현재 epoch의 손실값 합계를 저장할 변수를 0으로 초기화한다.
total_loss = 0.0
# DataLoader에서 미니배치 입력과 정답을 하나씩 꺼낸다.
for batch_X, batch_y in train_loader:
# 미니배치 입력 데이터를 연산 장치로 이동시킨다.
batch_X = batch_X.to(device)
# 미니배치 정답 데이터를 연산 장치로 이동시킨다.
batch_y = batch_y.to(device)
# 이전 미니배치에서 계산된 기울기를 0으로 초기화한다.
optimizer.zero_grad()
# 모델에 입력 데이터를 넣어 클래스별 예측 점수를 계산한다.
outputs = model(batch_X)
# 예측 점수와 실제 정답을 비교하여 손실값을 계산한다.
loss = criterion(outputs, batch_y)
# 손실값을 기준으로 각 파라미터의 기울기를 계산한다.
loss.backward()
# 계산된 기울기를 사용하여 모델의 가중치와 편향을 업데이트한다.
optimizer.step()
# 현재 미니배치 손실값에 데이터 개수를 곱해 epoch 전체 손실 합계에 더한다.
total_loss += loss.item() * batch_X.size(0)
# epoch 전체 평균 손실값을 계산한다.
avg_loss = total_loss / len(train_dataset)
# 모델을 평가 모드로 전환한다.
model.eval()
# 평가 과정에서는 기울기를 계산하지 않도록 설정하여 메모리 사용량을 줄인다.
with torch.no_grad():
# 테스트 입력 데이터를 연산 장치로 이동시킨다.
test_inputs = X_test_tensor.to(device)
# 테스트 데이터에 대한 클래스별 예측 점수를 계산한다.
test_outputs = model(test_inputs)
# 가장 점수가 높은 클래스 번호를 최종 예측값으로 선택한다.
test_preds = torch.argmax(test_outputs, dim=1)
# 예측 결과를 CPU로 옮긴 뒤 numpy 배열로 변환한다.
test_preds_np = test_preds.cpu().numpy()
# 실제 정답과 예측값을 비교하여 정확도를 계산한다.
test_acc = accuracy_score(y_test, test_preds_np)
# 현재 epoch의 평균 손실값을 리스트에 저장한다.
loss_history.append(avg_loss)
# 현재 epoch의 테스트 정확도를 리스트에 저장한다.
acc_history.append(test_acc)
# 10 epoch마다 현재 학습 상태를 출력한다.
if (epoch + 1) % 10 == 0:
# optimizer 이름, epoch 번호, 손실값, 정확도를 보기 좋게 출력한다.
print(f"{optimizer_name:12s} | Epoch {epoch+1:3d}/{epochs} | Loss: {avg_loss:.4f} | Test Acc: {test_acc:.4f}")
# 학습이 끝난 뒤 손실 기록, 정확도 기록, 최종 모델을 반환한다.
return loss_history, acc_history, model
앞서 정의했던 optimizer들을 바꿔가며 for문으로 학습을 실행해보자.
# 비교할 최적화 함수 이름 목록을 만든다.
optimizer_names = ["SGD", "SGD_Momentum", "RMSprop", "Adam", "AdamW"]
# 각 최적화 함수별 학습 결과를 저장할 딕셔너리를 생성한다.
results = {}
# optimizer_names에 들어 있는 최적화 함수를 하나씩 반복한다.
for optimizer_name in optimizer_names:
# 현재 어떤 최적화 함수를 학습하는지 출력한다.
print("\n학습 시작:", optimizer_name)
# 현재 최적화 함수로 모델을 학습하고 결과를 받는다.
loss_history, acc_history, model = train_one_optimizer(optimizer_name, epochs=50)
# 현재 최적화 함수의 손실 기록, 정확도 기록, 모델을 딕셔너리에 저장한다.
results[optimizer_name] = {
"loss": loss_history,
"accuracy": acc_history,
"model": model
}
학습 시작: SGD
SGD | Epoch 10/50 | Loss: 0.3377 | Test Acc: 0.8650
SGD | Epoch 20/50 | Loss: 0.3131 | Test Acc: 0.8800
SGD | Epoch 30/50 | Loss: 0.3068 | Test Acc: 0.8800
SGD | Epoch 40/50 | Loss: 0.3004 | Test Acc: 0.8800
SGD | Epoch 50/50 | Loss: 0.2924 | Test Acc: 0.8825
학습 시작: SGD_Momentum
SGD_Momentum | Epoch 10/50 | Loss: 0.2408 | Test Acc: 0.9075
SGD_Momentum | Epoch 20/50 | Loss: 0.1509 | Test Acc: 0.9200
SGD_Momentum | Epoch 30/50 | Loss: 0.1367 | Test Acc: 0.9300
SGD_Momentum | Epoch 40/50 | Loss: 0.1373 | Test Acc: 0.9250
SGD_Momentum | Epoch 50/50 | Loss: 0.1466 | Test Acc: 0.9275
학습 시작: RMSprop
RMSprop | Epoch 10/50 | Loss: 0.2285 | Test Acc: 0.9075
RMSprop | Epoch 20/50 | Loss: 0.1569 | Test Acc: 0.9200
RMSprop | Epoch 30/50 | Loss: 0.1402 | Test Acc: 0.9250
RMSprop | Epoch 40/50 | Loss: 0.1366 | Test Acc: 0.9250
RMSprop | Epoch 50/50 | Loss: 0.1350 | Test Acc: 0.9275
학습 시작: Adam
Adam | Epoch 10/50 | Loss: 0.2577 | Test Acc: 0.9000
Adam | Epoch 20/50 | Loss: 0.1650 | Test Acc: 0.9225
...
AdamW | Epoch 20/50 | Loss: 0.1658 | Test Acc: 0.9225
AdamW | Epoch 30/50 | Loss: 0.1411 | Test Acc: 0.9275
AdamW | Epoch 40/50 | Loss: 0.1374 | Test Acc: 0.9275
AdamW | Epoch 50/50 | Loss: 0.1359 | Test Acc: 0.9275
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
표로확인
# 결과 표에 들어갈 행 데이터를 저장할 빈 리스트를 만든다.
summary_rows = []
# results 딕셔너리에서 최적화 함수 이름과 결과를 하나씩 꺼낸다.
for optimizer_name, result in results.items():
# 현재 최적화 함수의 최종 손실값과 최종 정확도를 하나의 딕셔너리로 정리한다.
summary_rows.append({
"Optimizer": optimizer_name,
"Final Loss": result["loss"][-1],
"Final Test Accuracy": result["accuracy"][-1]
})
# 리스트 형태의 결과를 pandas DataFrame으로 변환한다.
summary_df = pd.DataFrame(summary_rows)
# 정확도가 높은 순서로 결과 표를 정렬한다.
summary_df = summary_df.sort_values(by="Final Test Accuracy", ascending=False)
# 정리된 결과 표를 출력한다.
summary_dfOptimizer Final Loss Final Test Accuracy
1 SGD_Momentum 0.146551 0.9275
3 Adam 0.135741 0.9275
2 RMSprop 0.135043 0.9275
4 AdamW 0.135911 0.9275
0 SGD 0.292409 0.8825
손실값 시각화
# 그래프 크기를 가로 10, 세로 6으로 설정한다.
plt.figure(figsize=(10, 6))
# 각 최적화 함수별 손실 기록을 그래프에 그린다.
for optimizer_name, result in results.items():
# x축은 epoch, y축은 손실값이 되도록 선 그래프를 그린다.
plt.plot(result["loss"], label=optimizer_name)
# 그래프 제목을 설정한다.
plt.title("Optimizer별 Loss 변화")
# x축 이름을 설정한다.
plt.xlabel("Epoch")
# y축 이름을 설정한다.
plt.ylabel("Loss")
# 각 선이 어떤 최적화 함수인지 보여주는 범례를 표시한다.
plt.legend()
# 그래프 격자선을 표시하여 값을 읽기 쉽게 만든다.
plt.grid(True)
# 그래프를 화면에 출력한다.
plt.show()
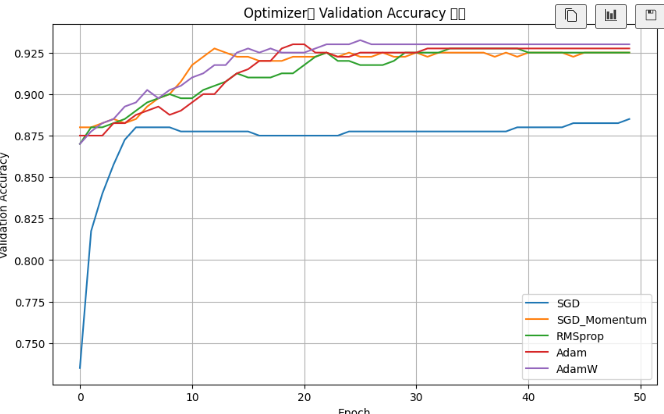
정확도 시각화
# 그래프 크기를 가로 10, 세로 6으로 설정한다.
plt.figure(figsize=(10, 6))
# 각 최적화 함수별 정확도 기록을 그래프에 그린다.
for optimizer_name, result in results.items():
# x축은 epoch, y축은 테스트 정확도가 되도록 선 그래프를 그린다.
plt.plot(result["accuracy"], label=optimizer_name)
# 그래프 제목을 설정한다.
plt.title("Optimizer별 Test Accuracy 변화")
# x축 이름을 설정한다.
plt.xlabel("Epoch")
# y축 이름을 설정한다.
plt.ylabel("Test Accuracy")
# 각 선이 어떤 최적화 함수인지 보여주는 범례를 표시한다.
plt.legend()
# 그래프 격자선을 표시하여 값을 읽기 쉽게 만든다.
plt.grid(True)
# 그래프를 화면에 출력한다.
plt.show()
같은 내용을 텐서플로우로 확인해보자. optimizer_compare_tensorflow.ipynb
import, seed에서ㅅ torch가 아닌 tf.random.set_seed를 사용했다
전처리
# tensorflow는 딥러닝 모델 생성, 학습, 평가에 사용하는 대표적인 라이브러리이다.
import tensorflow as tf
# keras는 TensorFlow 안에서 신경망 모델을 쉽게 구성할 수 있게 해주는 고수준 API이다.
from tensorflow import keras
# layers는 Dense, Input 같은 신경망 계층을 만들 때 사용한다.
from tensorflow.keras import layers
# make_moons는 두 개의 초승달 모양 클래스를 가진 비선형 분류 데이터셋을 생성한다.
from sklearn.datasets import make_moons
# train_test_split은 데이터를 학습용 데이터와 테스트용 데이터로 나누기 위해 사용한다.
from sklearn.model_selection import train_test_split
# StandardScaler는 입력 특성의 평균을 0, 표준편차를 1에 가깝게 표준화하기 위해 사용한다.
from sklearn.preprocessing import StandardScaler
# numpy는 배열 계산과 난수 고정에 사용한다.
import numpy as np
# pandas는 최적화 함수별 결과를 표 형태로 정리하기 위해 사용한다.
import pandas as pd
# matplotlib.pyplot은 손실값과 정확도 그래프를 그리기 위해 사용한다.
import matplotlib.pyplot as plt
# random은 파이썬 기본 난수 생성을 고정하기 위해 사용한다.
import random# seed는 난수 생성 결과를 고정하기 위한 기준 숫자이다.
seed = 42
# 파이썬 random 모듈의 난수 생성 기준을 고정한다.
random.seed(seed)
# numpy의 난수 생성 기준을 고정한다.
np.random.seed(seed)
# TensorFlow의 난수 생성 기준을 고정한다.
tf.random.set_seed(seed)
# 현재 TensorFlow 버전을 출력한다.
print("TensorFlow version:", tf.__version__)# make_moons 함수로 샘플 2000개짜리 이진 분류 데이터셋을 생성한다.
X, y = make_moons(n_samples=2000, noise=0.25, random_state=seed)
# train_test_split으로 전체 데이터를 학습용 80%, 테스트용 20%로 나눈다.
X_train, X_test, y_train, y_test = train_test_split(
X, # 입력 데이터 전체를 전달한다.
y, # 정답 라벨 전체를 전달한다.
test_size=0.2, # 전체 데이터 중 20%를 테스트 데이터로 사용한다.
random_state=seed, # 데이터를 나누는 난수 기준을 고정한다.
stratify=y # 클래스 비율이 학습/테스트 데이터에서 비슷하게 유지되도록 한다.
)
# StandardScaler 객체를 생성하여 입력 데이터의 스케일을 맞출 준비를 한다.
scaler = StandardScaler()
# 학습 데이터 기준으로 평균과 표준편차를 계산하고, 학습 데이터를 표준화한다.
X_train = scaler.fit_transform(X_train)
# 테스트 데이터는 학습 데이터에서 계산된 평균과 표준편차를 그대로 사용하여 표준화한다.
X_test = scaler.transform(X_test)
# TensorFlow 학습에 적합하도록 학습 입력 데이터를 float32 자료형으로 변환한다.
X_train = X_train.astype("float32")
# TensorFlow 학습에 적합하도록 테스트 입력 데이터를 float32 자료형으로 변환한다.
X_test = X_test.astype("float32")
# 정답 데이터는 sparse_categorical_crossentropy에서 사용할 수 있도록 정수형으로 유지한다.
y_train = y_train.astype("int32")
# 테스트 정답 데이터도 정수형으로 유지한다.
y_test = y_test.astype("int32")
# 입력 데이터의 모양을 출력하여 특성 수가 2개인지 확인한다.
print("X_train shape:", X_train.shape)
# 정답 데이터의 클래스 종류를 출력하여 이진 분류 문제인지 확인한다.
print("classes:", np.unique(y_train))
MLP 모델생성
nn.Sequential가 아닌 keras.sequential을 사용했으며 Dense코드에 activation 속성이 있어 코드가 간결하다.
# build_model 함수는 새로운 Keras MLP 모델을 생성한다.
def build_model():
# Sequential은 계층을 순서대로 쌓아 만드는 가장 간단한 Keras 모델 방식이다.
model = keras.Sequential([
# Input 계층은 입력 데이터의 특성 개수가 2개임을 모델에 알려준다.
layers.Input(shape=(2,)),
# 첫 번째 Dense 계층은 입력 특성 2개를 은닉 노드 16개로 변환한다.
layers.Dense(16, activation="relu"),
# 두 번째 Dense 계층은 은닉 노드 16개를 다시 은닉 노드 16개로 변환한다.
layers.Dense(16, activation="relu"),
# 마지막 Dense 계층은 클래스 2개의 점수를 출력한다.
layers.Dense(2, activation="softmax")
])
# 생성한 모델 객체를 반환한다.
return model
optimizer마찬가지로 비슷하나 keras.optimizers 호출부분이 다를뿐.
# get_optimizer 함수는 optimizer_name에 따라 서로 다른 Keras 최적화 함수를 생성한다.
def get_optimizer(optimizer_name):
# optimizer_name이 "SGD"이면 기본 SGD 최적화 함수를 사용한다.
if optimizer_name == "SGD":
# SGD는 가장 기본적인 경사하강법 계열 최적화 함수이다.
return keras.optimizers.SGD(learning_rate=0.01)
# optimizer_name이 "SGD_Momentum"이면 Momentum이 추가된 SGD를 사용한다.
elif optimizer_name == "SGD_Momentum":
# momentum=0.9는 이전 업데이트 방향을 90% 정도 반영하겠다는 의미이다.
return keras.optimizers.SGD(learning_rate=0.01, momentum=0.9)
# optimizer_name이 "RMSprop"이면 RMSprop 최적화 함수를 사용한다.
elif optimizer_name == "RMSprop":
# RMSprop은 파라미터별로 학습률을 조정하여 학습을 안정화한다.
return keras.optimizers.RMSprop(learning_rate=0.001)
# optimizer_name이 "Adam"이면 Adam 최적화 함수를 사용한다.
elif optimizer_name == "Adam":
# Adam은 Momentum과 RMSprop의 아이디어를 결합한 대표적인 최적화 함수이다.
return keras.optimizers.Adam(learning_rate=0.001)
# optimizer_name이 "AdamW"이면 AdamW 최적화 함수를 사용한다.
elif optimizer_name == "AdamW":
# AdamW는 Adam에 weight_decay를 더 올바른 방식으로 적용하여 과적합을 줄이는 데 도움을 준다.
return keras.optimizers.AdamW(learning_rate=0.001, weight_decay=0.01)
# 위 조건에 없는 이름이 들어오면 오류를 발생시킨다.
else:
# 사용자가 잘못된 최적화 함수 이름을 넣었음을 알려준다.
raise ValueError("지원하지 않는 optimizer_name입니다.")
학습함수 정의 및 학습
# train_one_optimizer 함수는 하나의 최적화 함수로 모델을 학습하고 결과를 반환한다.
def train_one_optimizer(optimizer_name, epochs=50):
# 매 실험마다 같은 초기 가중치에서 시작하도록 TensorFlow seed를 다시 고정한다.
tf.random.set_seed(seed)
# 새로운 MLP 모델을 생성한다.
model = build_model()
# optimizer_name에 해당하는 최적화 함수를 생성한다.
optimizer = get_optimizer(optimizer_name)
# 모델의 학습 방식, 손실 함수, 평가지표를 설정한다.
model.compile(
optimizer=optimizer, # 현재 실험에서 사용할 최적화 함수를 지정한다.
loss="sparse_categorical_crossentropy", # 정답이 정수 라벨일 때 사용하는 다중 분류 손실 함수이다.
metrics=["accuracy"] # 학습 중 정확도를 함께 계산하도록 설정한다.
)
# 모델을 학습한다.
history = model.fit(
X_train, # 학습 입력 데이터를 전달한다.
y_train, # 학습 정답 데이터를 전달한다.
validation_data=(X_test, y_test), # 각 epoch마다 테스트 데이터의 손실과 정확도를 계산한다.
epochs=epochs, # 전체 학습 반복 횟수를 지정한다.
batch_size=32, # 한 번에 32개 데이터씩 묶어서 학습한다.
verbose=0 # 학습 로그를 길게 출력하지 않도록 설정한다.
)
# 학습이 끝난 후 테스트 데이터로 최종 손실값과 정확도를 계산한다.
test_loss, test_acc = model.evaluate(X_test, y_test, verbose=0)
# 최적화 함수 이름, 최종 손실값, 최종 정확도를 출력한다.
print(f"{optimizer_name:12s} | Final Loss: {test_loss:.4f} | Final Test Acc: {test_acc:.4f}")
# 학습 기록과 최종 모델을 반환한다.
return history, model
# 비교할 최적화 함수 이름 목록을 만든다.
optimizer_names = ["SGD", "SGD_Momentum", "RMSprop", "Adam", "AdamW"]
# 각 최적화 함수별 학습 결과를 저장할 딕셔너리를 생성한다.
results = {}
# optimizer_names에 들어 있는 최적화 함수를 하나씩 반복한다.
for optimizer_name in optimizer_names:
# 현재 어떤 최적화 함수를 학습하는지 출력한다.
print("\n학습 시작:", optimizer_name)
# 현재 최적화 함수로 모델을 학습하고 결과를 받는다.
history, model = train_one_optimizer(optimizer_name, epochs=50)
# 현재 최적화 함수의 학습 기록과 모델을 딕셔너리에 저장한다.
results[optimizer_name] = {
"history": history,
"model": model
}
마찬가지로 결과표로 확인 및 시각화.
# 결과 표에 들어갈 행 데이터를 저장할 빈 리스트를 만든다.
summary_rows = []
# results 딕셔너리에서 최적화 함수 이름과 결과를 하나씩 꺼낸다.
for optimizer_name, result in results.items():
# Keras history 객체에서 검증 손실 기록을 가져온다.
val_loss_history = result["history"].history["val_loss"]
# Keras history 객체에서 검증 정확도 기록을 가져온다.
val_acc_history = result["history"].history["val_accuracy"]
# 현재 최적화 함수의 최종 검증 손실값과 최종 검증 정확도를 하나의 딕셔너리로 정리한다.
summary_rows.append({
"Optimizer": optimizer_name,
"Final Validation Loss": val_loss_history[-1],
"Final Validation Accuracy": val_acc_history[-1]
})
# 리스트 형태의 결과를 pandas DataFrame으로 변환한다.
summary_df = pd.DataFrame(summary_rows)
# 정확도가 높은 순서로 결과 표를 정렬한다.
summary_df = summary_df.sort_values(by="Final Validation Accuracy", ascending=False)
# 정리된 결과 표를 출력한다.
summary_dfOptimizer Final Validation Loss Final Validation Accuracy
4 AdamW 0.171209 0.9300
3 Adam 0.169679 0.9275
2 RMSprop 0.173859 0.9250
1 SGD_Momentum 0.180223 0.9250
0 SGD 0.277057 0.8850
# 그래프 크기를 가로 10, 세로 6으로 설정한다.
plt.figure(figsize=(10, 6))
# 각 최적화 함수별 검증 손실 기록을 그래프에 그린다.
for optimizer_name, result in results.items():
# history 객체에서 검증 손실 기록을 가져온다.
val_loss = result["history"].history["val_loss"]
# x축은 epoch, y축은 검증 손실값이 되도록 선 그래프를 그린다.
plt.plot(val_loss, label=optimizer_name)
# 그래프 제목을 설정한다.
plt.title("Optimizer별 Validation Loss 변화")
# x축 이름을 설정한다.
plt.xlabel("Epoch")
# y축 이름을 설정한다.
plt.ylabel("Validation Loss")
# 각 선이 어떤 최적화 함수인지 보여주는 범례를 표시한다.
plt.legend()
# 그래프 격자선을 표시하여 값을 읽기 쉽게 만든다.
plt.grid(True)
# 그래프를 화면에 출력한다.
plt.show()
# 그래프 크기를 가로 10, 세로 6으로 설정한다.
plt.figure(figsize=(10, 6))
# 각 최적화 함수별 검증 정확도 기록을 그래프에 그린다.
for optimizer_name, result in results.items():
# history 객체에서 검증 정확도 기록을 가져온다.
val_accuracy = result["history"].history["val_accuracy"]
# x축은 epoch, y축은 검증 정확도가 되도록 선 그래프를 그린다.
plt.plot(val_accuracy, label=optimizer_name)
# 그래프 제목을 설정한다.
plt.title("Optimizer별 Validation Accuracy 변화")
# x축 이름을 설정한다.
plt.xlabel("Epoch")
# y축 이름을 설정한다.
plt.ylabel("Validation Accuracy")
# 각 선이 어떤 최적화 함수인지 보여주는 범례를 표시한다.
plt.legend()
# 그래프 격자선을 표시하여 값을 읽기 쉽게 만든다.
plt.grid(True)
# 그래프를 화면에 출력한다.
plt.show()
seed, 모델생성 및 학습시 조금씩 코드가 달라진다는것을 이해한다.
특히 신경망쪽에서 코드가 줄어들었음을 이해한다.
특히 학습함수정의시 기존 epoch에 따라 for문으로 돌리던 학습을 model.fit()로 간결해짐을 이해한다.
이어서 항공 승객 수 시계열 데이터를 사용하여 과거 12개월 데이터로 다음 1개월 승객 수를 예측하는 LSTM 회귀 모델코드를 분석해보자.
airline_lstm_pytorch.ipynb
import.
학습시간을 측정하기 위해 time함수를 불러오고 데이터를 0~1 사이로 변환하는 정규화도구 Minmaxscaler
skearn.metrics maen_squared_error, 예측값과 실제값 사이 평균 제곱 오차를 계산하는 평가함수
np.set_printoptions(precision = 3, suppress=True) 소수점자리수를 3자리로 제한해 결과를 보기 쉽게한다.
시드 고정. 파라미터 기본값 설정
# 운영체제 관련 기능을 사용하기 위한 표준 라이브러리입니다.
# 예를 들어 파일이 존재하는지 확인할 때 사용합니다.
import os
# 학습 시간을 측정하기 위해 time 함수를 불러옵니다.
from time import time
# numpy는 배열 기반 수치 계산을 빠르게 처리하기 위해 사용하는 라이브러리입니다.
import numpy as np
# pandas는 CSV 파일을 읽고 표 형태의 데이터를 처리하기 위해 사용하는 라이브러리입니다.
import pandas as pd
# matplotlib.pyplot은 선 그래프, 산점도 등 기본 그래프를 그릴 때 사용하는 라이브러리입니다.
import matplotlib.pyplot as plt
# MinMaxScaler는 데이터를 0과 1 사이 범위로 변환하는 정규화 도구입니다.
from sklearn.preprocessing import MinMaxScaler
# mean_squared_error는 예측값과 실제값 사이의 평균제곱오차를 계산하는 평가 함수입니다.
from sklearn.metrics import mean_squared_error
# torch는 PyTorch의 핵심 라이브러리로 텐서 계산과 딥러닝 학습을 담당합니다.
import torch
# torch.nn은 신경망 계층, 손실 함수, 활성화 함수 등을 제공하는 모듈입니다.
import torch.nn as nn
# TensorDataset은 입력 데이터와 정답 데이터를 하나의 데이터셋으로 묶는 도구입니다.
# DataLoader는 데이터셋을 미니배치 단위로 나누어 반복적으로 공급하는 도구입니다.
from torch.utils.data import TensorDataset, DataLoader
# numpy 배열 출력 시 소수점 자릿수를 3자리로 제한하여 결과를 보기 쉽게 만듭니다.
np.set_printoptions(precision=3, suppress=True)
# numpy 난수 시드를 고정하여 매번 비슷한 실험 결과가 나오도록 합니다.
np.random.seed(42)
# PyTorch 난수 시드를 고정하여 모델 초기 가중치가 매번 비슷하게 생성되도록 합니다.
torch.manual_seed(42)
# GPU가 사용 가능하면 GPU(cuda)를 사용하고, 그렇지 않으면 CPU를 사용합니다.
# 구글 코랩에서 GPU 런타임을 켜면 cuda가 선택될 수 있습니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 현재 사용 중인 학습 장치를 출력합니다.
print("사용 장치:", device)# 과거 몇 개월의 데이터를 입력으로 사용할지 정합니다.
# 12로 설정하면 과거 12개월 승객 수를 보고 다음 1개월 승객 수를 예측합니다.
PAST_MONTHS = 12
# 전체 데이터 중 학습 데이터로 사용할 비율입니다.
# 0.8은 앞쪽 80% 데이터를 학습에 사용하고, 뒤쪽 20% 데이터를 테스트에 사용한다는 의미입니다.
TRAIN_RATIO = 0.8
# LSTM의 은닉 상태 크기입니다.
# 값이 클수록 모델이 더 복잡한 패턴을 표현할 수 있지만, 학습 시간이 늘고 과적합 위험도 증가합니다.
HIDDEN_SIZE = 300
# 입력 특성 수입니다.
# 여기서는 한 달의 승객 수 하나만 입력으로 사용하므로 1입니다.
INPUT_SIZE = 1
# 출력값 개수입니다.
# 다음 1개월 승객 수 하나를 예측하므로 1입니다.
OUTPUT_SIZE = 1
# 전체 학습 반복 횟수입니다.
# epoch는 전체 학습 데이터를 처음부터 끝까지 한 번 학습하는 단위입니다.
EPOCHS = 300
# 미니배치 크기입니다.
# 한 번의 가중치 업데이트에 사용할 샘플 개수를 의미합니다.
BATCH_SIZE = 64
# 학습률입니다.
# 모델 가중치를 한 번 수정할 때 얼마나 크게 수정할지 결정합니다.
LEARNING_RATE = 0.001
# 설정값을 확인하기 위해 출력합니다.
print("과거 입력 개월 수:", PAST_MONTHS)
print("학습 데이터 비율:", TRAIN_RATIO)
print("LSTM 은닉 상태 크기:", HIDDEN_SIZE)
print("학습 반복 횟수:", EPOCHS)
print("배치 크기:", BATCH_SIZE)
print("학습률:", LEARNING_RATE)
데이터 불러와 컬럼명 통일, 숫자형으로 변환, 결측치 행 제거
기초 데이터 크기와 통계 출력
# 사용할 CSV 파일명을 지정합니다.
# 직접 파일을 업로드한 경우에는 이 파일명이 현재 작업 폴더에 있어야 합니다.
CSV_PATH = "airline.csv"
# 로컬 파일이 없을 때 사용할 공개 데이터 주소입니다.
# 구글 코랩에서 실습할 때 파일 업로드 없이 바로 실행할 수 있도록 예비 경로로 사용합니다.
FALLBACK_URL = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/airline-passengers.csv"
# 현재 작업 폴더에 airline.csv 파일이 존재하는지 확인합니다.
if os.path.exists(CSV_PATH):
# 파일이 있으면 로컬 CSV 파일을 읽습니다.
# usecols=[1]은 두 번째 열인 승객 수만 가져오겠다는 의미입니다.
raw = pd.read_csv(CSV_PATH, header=None, usecols=[1])
else:
# 파일이 없으면 공개 CSV 주소에서 데이터를 읽습니다.
# 해당 데이터는 Month,Passengers 구조이므로 Passengers 열만 사용합니다.
raw = pd.read_csv(FALLBACK_URL, usecols=["Passengers"])
# 컬럼명을 passengers로 통일합니다.
raw.columns = ["passengers"]
# 데이터가 숫자형인지 안전하게 변환합니다.
# errors="coerce"는 숫자로 변환할 수 없는 값이 있으면 NaN으로 바꿉니다.
raw["passengers"] = pd.to_numeric(raw["passengers"], errors="coerce")
# 결측치가 있는 행을 제거합니다.
# LSTM 학습에는 숫자 데이터가 필요하므로 비어 있는 값은 제거합니다.
raw = raw.dropna().reset_index(drop=True)
# 데이터 앞부분을 출력하여 정상적으로 읽혔는지 확인합니다.
print("데이터 샘플")
print(raw.head(12))
# 전체 데이터 크기를 출력합니다.
print("전체 데이터 개수:", len(raw))
# 기초 통계량을 출력합니다.
print("기초 통계량")
print(raw.describe())데이터 샘플
passengers
0 112
1 118
2 132
3 129
4 121
5 135
6 148
7 148
8 136
9 119
10 104
11 118
전체 데이터 개수: 144
기초 통계량
passengers
count 144.000000
mean 280.298611
std 119.966317
min 104.000000
25% 180.000000
50% 265.500000
75% 360.500000
max 622.000000데이터 샘플을 보니 각 데이터는 144개, 평균 280인데 최소 104 최대 672이다. 다소 높은 평균값때문에 평균에 이상이 있어보이나
중간값은 265, mean값이 280을 보면 계속해서 passenger가 늘어나는 구조라고 이해해볼 수있겠다.
데이터 시각화
# 그래프 크기를 설정합니다.
plt.figure(figsize=(10, 4))
# 월별 승객 수를 선 그래프로 그립니다.
plt.plot(raw["passengers"].values, label="Passengers")
# 그래프 제목을 설정합니다.
plt.title("Monthly Airline Passengers")
# x축 이름을 설정합니다.
plt.xlabel("Month Index")
# y축 이름을 설정합니다.
plt.ylabel("Passengers")
# 범례를 표시합니다.
plt.legend()
# 격자선을 표시하여 값의 변화를 더 쉽게 볼 수 있게 합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()
입력값 범위가 다소 커 학습이 불안정해질수있으니 승객수를 0~1 로 변환하자.
# MinMaxScaler 객체를 생성합니다.
# 이 도구는 데이터의 최솟값을 0, 최댓값을 1로 변환합니다.
scaler = MinMaxScaler(feature_range=(0, 1))
# raw 데이터프레임의 passengers 열을 2차원 배열 형태로 변환합니다.
# MinMaxScaler는 입력을 2차원 배열 형태로 받습니다.
passenger_values = raw[["passengers"]].values
# fit_transform은 최솟값과 최댓값을 학습한 뒤 실제 정규화 변환을 수행합니다.
scaled_values = scaler.fit_transform(passenger_values)
# 정규화 결과를 데이터프레임으로 변환하여 확인하기 쉽게 만듭니다.
scaled_df = pd.DataFrame(scaled_values, columns=["scaled_passengers"])
# 정규화된 데이터 앞부분을 출력합니다.
print("정규화 데이터 샘플")
print(scaled_df.head(12))
# 정규화 데이터의 최솟값과 최댓값을 출력합니다.
print("정규화 최솟값:", scaled_values.min())
print("정규화 최댓값:", scaled_values.max())
12개월을 범위로 학습하고 정답은 그다음 달로 지정하자.
학습, 정답 데이터 분리
# 전체 샘플 개수에 학습 비율을 곱하여 학습 데이터의 마지막 인덱스를 계산합니다.
train_size = int(len(X_data) * TRAIN_RATIO)
# 앞쪽 데이터를 학습용 입력 데이터로 사용합니다.
X_train = X_data[:train_size]
# 뒤쪽 데이터를 테스트용 입력 데이터로 사용합니다.
X_test = X_data[train_size:]
# 앞쪽 정답 데이터를 학습용 정답 데이터로 사용합니다.
y_train = y_data[:train_size]
# 뒤쪽 정답 데이터를 테스트용 정답 데이터로 사용합니다.
y_test = y_data[train_size:]
# 분리된 데이터의 모양을 출력합니다.
print("X_train shape:", X_train.shape)
print("y_train shape:", y_train.shape)
print("X_test shape:", X_test.shape)
print("y_test shape:", y_test.shape)# 시계열 데이터를 입력 X와 정답 y로 변환하는 함수를 정의합니다.
def make_sequences(data, past_months):
# 입력 데이터를 저장할 리스트입니다.
X_list = []
# 정답 데이터를 저장할 리스트입니다.
y_list = []
# 전체 데이터에서 과거 입력 길이만큼 제외한 위치까지 반복합니다.
# 마지막 인덱스에서도 입력 past_months개와 다음 값 1개가 있어야 하기 때문입니다.
for i in range(len(data) - past_months):
# i 위치부터 i+past_months 전까지를 입력 데이터로 사용합니다.
X_list.append(data[i : i + past_months])
# i+past_months 위치의 값을 정답 데이터로 사용합니다.
y_list.append(data[i + past_months])
# 리스트를 numpy 배열로 변환합니다.
X_array = np.array(X_list)
# 리스트를 numpy 배열로 변환합니다.
y_array = np.array(y_list)
# 입력 배열과 정답 배열을 반환합니다.
return X_array, y_array
# 정규화된 승객 수 데이터로 시계열 입력과 정답을 생성합니다.
X_data, y_data = make_sequences(scaled_values, PAST_MONTHS)
# 생성된 입력 데이터의 모양을 출력합니다.
print("X_data shape:", X_data.shape)
# 생성된 정답 데이터의 모양을 출력합니다.
print("y_data shape:", y_data.shape)
# 첫 번째 입력 데이터와 정답 데이터를 확인합니다.
print("첫 번째 입력 데이터")
print(X_data[0].flatten())
print("첫 번째 정답 데이터")
print(y_data[0])
tensor로 변환 및 tensordataset으로 학습용, 정답 tensor를 묶어 dataloader에 세팅
# 학습용 입력 데이터를 float32 타입의 PyTorch Tensor로 변환합니다.
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
# 학습용 정답 데이터를 float32 타입의 PyTorch Tensor로 변환합니다.
y_train_tensor = torch.tensor(y_train, dtype=torch.float32)
# 테스트용 입력 데이터를 float32 타입의 PyTorch Tensor로 변환합니다.
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
# 테스트용 정답 데이터를 float32 타입의 PyTorch Tensor로 변환합니다.
y_test_tensor = torch.tensor(y_test, dtype=torch.float32)
# 학습용 입력 Tensor와 정답 Tensor를 하나의 Dataset으로 묶습니다.
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
# Dataset을 미니배치 단위로 공급하는 DataLoader를 생성합니다.
# 시계열 순서를 유지하기 위해 shuffle=False로 설정합니다.
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=False)
# Tensor 모양을 출력하여 모델 입력 형태가 올바른지 확인합니다.
print("X_train_tensor:", X_train_tensor.shape)
print("y_train_tensor:", y_train_tensor.shape)
print("X_test_tensor:", X_test_tensor.shape)
print("y_test_tensor:", y_test_tensor.shape)
nn.module을 매개변수로 클래스를 정의하자.
특성수와 은닉크기, 출력개수를 가져다가 nn.LSTM 객체를 만든다.
은닉크기와 출력개수를 사용해 nn.Linear 완전연결층을 생성한다.
activation은 sigmoid를 사용하도록한다.
forward.lstm_out, _ = self.lstm(x) 12개월 데이터를 순서대로 읽는다.
마지막 시점의 출력을 가져와 self.fc() 완전연결층에 넣어 예측값 ouput으로 반환한다.
output_actication로 output을 0~1사이로 변환해 최종 반환.
모델 객체를 생성한다.
# nn.Module을 상속받아 LSTM 회귀 모델 클래스를 정의합니다.
class AirlineLSTM(nn.Module):
# __init__ 함수는 모델에 필요한 계층을 생성하는 초기화 함수입니다.
def __init__(self, input_size, hidden_size, output_size):
# 부모 클래스인 nn.Module의 초기화 기능을 실행합니다.
super().__init__()
# 입력 특성 수를 객체 변수로 저장합니다.
self.input_size = input_size
# LSTM 은닉 상태 크기를 객체 변수로 저장합니다.
self.hidden_size = hidden_size
# 출력값 개수를 객체 변수로 저장합니다.
self.output_size = output_size
# LSTM 계층을 생성합니다.
# input_size는 한 시점에 들어오는 특성 수입니다.
# hidden_size는 LSTM이 내부적으로 기억하는 정보의 크기입니다.
# batch_first=True는 입력 형태를 (배치 크기, 시간 길이, 특성 수)로 사용한다는 뜻입니다.
self.lstm = nn.LSTM(
input_size=input_size,
hidden_size=hidden_size,
batch_first=True
)
# 완전연결층을 생성합니다.
# LSTM의 마지막 시점 출력 hidden_size개를 최종 예측값 output_size개로 변환합니다.
self.fc = nn.Linear(hidden_size, output_size)
# 출력값을 0과 1 사이로 제한하기 위한 Sigmoid 함수입니다.
# 정답 데이터가 MinMax 정규화되어 0과 1 사이에 있으므로 출력 범위도 맞춰줍니다.
self.output_activation = nn.Sigmoid()
# forward 함수는 입력 데이터가 모델 내부에서 어떤 순서로 계산되는지 정의합니다.
def forward(self, x):
# LSTM에 입력 데이터를 통과시킵니다.
# lstm_out은 모든 시점의 출력이며, 모양은 (배치 크기, 시간 길이, 은닉 크기)입니다.
# hidden과 cell 상태는 여기서는 직접 사용하지 않으므로 _로 받습니다.
lstm_out, _ = self.lstm(x)
# 모든 시점 중 마지막 시점의 출력만 가져옵니다.
# 마지막 시점 출력은 과거 12개월 정보를 순차적으로 반영한 결과입니다.
last_time_step = lstm_out[:, -1, :]
# 마지막 시점 출력을 완전연결층에 넣어 예측값 1개로 변환합니다.
output = self.fc(last_time_step)
# 예측값을 0과 1 사이로 변환합니다.
output = self.output_activation(output)
# 최종 예측값을 반환합니다.
return output
# 모델 객체를 생성합니다.
model = AirlineLSTM(
input_size=INPUT_SIZE,
hidden_size=HIDDEN_SIZE,
output_size=OUTPUT_SIZE
)
# 모델을 CPU 또는 GPU 장치로 이동합니다.
model = model.to(device)
# 모델 구조를 출력합니다.
print(model)
MSELoss 평균제곱오차 손실함수를 생성한다.
torch.optim.RMSprop 최적화 알고리즘을 생성한다 .
# 평균제곱오차 손실 함수를 생성합니다.
# 예측값과 실제값의 차이를 제곱한 뒤 평균을 내므로 회귀 문제에서 많이 사용됩니다.
criterion = nn.MSELoss()
# RMSprop 최적화 알고리즘을 생성합니다.
# model.parameters()는 학습 가능한 모든 가중치와 편향을 의미합니다.
optimizer = torch.optim.RMSprop(model.parameters(), lr=LEARNING_RATE)
# 손실 함수와 최적화 알고리즘을 출력합니다.
print("손실 함수:", criterion)
print("최적화 알고리즘:", optimizer)
epoch마다 for문으로 학습한다. zerp_grad()로 기울기 초기화 model(x) 예측값 생성, criterion(pred, y) 손실값 계산.
loss.backward기울기계산, optimizer.step() 기울기사용해 가중치 업데이트
# epoch별 평균 학습 손실을 저장할 리스트입니다.
train_losses = []
# 학습 시작 시간을 기록합니다.
start_time = time()
# 학습 시작 메시지를 출력합니다.
print("학습 시작")
# 지정한 epoch 수만큼 전체 학습 데이터를 반복 학습합니다.
for epoch in range(1, EPOCHS + 1):
# 모델을 학습 모드로 전환합니다.
# 학습 모드는 가중치 업데이트가 이루어지는 상태입니다.
model.train()
# 한 epoch 동안의 손실 합계를 저장할 변수를 0으로 초기화합니다.
epoch_loss_sum = 0.0
# DataLoader에서 미니배치 단위로 입력과 정답을 가져옵니다.
for batch_X, batch_y in train_loader:
# 입력 미니배치를 현재 학습 장치로 이동합니다.
batch_X = batch_X.to(device)
# 정답 미니배치를 현재 학습 장치로 이동합니다.
batch_y = batch_y.to(device)
# 이전 반복에서 계산된 기울기를 초기화합니다.
# PyTorch는 기울기를 자동으로 누적하므로 매 반복마다 초기화해야 합니다.
optimizer.zero_grad()
# 모델에 입력 데이터를 넣어 예측값을 계산합니다.
predictions = model(batch_X)
# 예측값과 실제 정답 사이의 손실값을 계산합니다.
loss = criterion(predictions, batch_y)
# 손실값을 기준으로 모델 가중치에 대한 기울기를 계산합니다.
loss.backward()
# 계산된 기울기를 사용하여 모델 가중치를 업데이트합니다.
optimizer.step()
# 현재 미니배치 손실에 미니배치 샘플 수를 곱해 누적합니다.
epoch_loss_sum += loss.item() * batch_X.size(0)
# 전체 학습 샘플 수로 나누어 epoch 평균 손실을 계산합니다.
epoch_loss = epoch_loss_sum / len(train_dataset)
# 계산된 평균 손실을 리스트에 저장합니다.
train_losses.append(epoch_loss)
# 첫 epoch와 50 epoch마다 학습 손실을 출력합니다.
if epoch == 1 or epoch % 50 == 0:
# 현재 학습 진행 상황을 출력합니다.
print(f"Epoch [{epoch:3d}/{EPOCHS}] - Train MSE Loss: {epoch_loss:.6f}")
# 학습 종료 시간을 기록합니다.
end_time = time()
# 전체 학습 시간을 출력합니다.
print(f"학습 완료: {end_time - start_time:.2f}초")
손실시각화
# 그래프 크기를 설정합니다.
plt.figure(figsize=(10, 4))
# epoch별 학습 손실을 선 그래프로 그립니다.
plt.plot(train_losses, label="Train MSE Loss")
# 그래프 제목을 설정합니다.
plt.title("Training Loss Curve")
# x축 이름을 설정합니다.
plt.xlabel("Epoch")
# y축 이름을 설정합니다.
plt.ylabel("MSE Loss")
# 범례를 표시합니다.
plt.legend()
# 격자선을 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()
model.eval() 평가모드 전환.
손실값 출력.
# 모델을 평가 모드로 전환합니다.
model.eval()
# 테스트 입력 Tensor를 현재 장치로 이동합니다.
X_test_device = X_test_tensor.to(device)
# 테스트 정답 Tensor를 현재 장치로 이동합니다.
y_test_device = y_test_tensor.to(device)
# 평가에서는 기울기 계산이 필요 없으므로 no_grad 영역을 사용합니다.
with torch.no_grad():
# 테스트 데이터에 대한 예측값을 계산합니다.
test_predictions = model(X_test_device)
# 테스트 데이터의 평균제곱오차 손실을 계산합니다.
test_loss = criterion(test_predictions, y_test_device)
# 테스트 손실값을 출력합니다.
print(f"테스트 MSE Loss: {test_loss.item():.6f}")
예측값, 테스트 정답, 을 cpu로 이동한뒤 numpy배열로 변환
정규화된 예측값, 실제값을 inverse_transform 원래 단위로 복원
flatten을 통해 1차원 배열로 변환
mean_squared_error 평균제곱오차를 계산해 표 출력.
# 예측 Tensor를 CPU로 이동한 뒤 numpy 배열로 변환합니다.
pred_scaled = test_predictions.detach().cpu().numpy()
# 테스트 정답 Tensor를 CPU의 numpy 배열로 변환합니다.
truth_scaled = y_test_tensor.detach().cpu().numpy()
# 정규화된 예측값을 원래 승객 수 단위로 복원합니다.
pred_original = scaler.inverse_transform(pred_scaled)
# 정규화된 실제값을 원래 승객 수 단위로 복원합니다.
truth_original = scaler.inverse_transform(truth_scaled)
# 그래프와 표 출력이 편하도록 1차원 배열로 변환합니다.
pred_original_1d = pred_original.flatten()
truth_original_1d = truth_original.flatten()
# 원래 단위 기준 평균제곱오차를 계산합니다.
original_mse = mean_squared_error(truth_original_1d, pred_original_1d)
# 원래 단위 기준 평균제곱근오차를 계산합니다.
original_rmse = np.sqrt(original_mse)
# 평가 지표를 출력합니다.
print(f"원래 승객 수 단위 MSE: {original_mse:.3f}")
print(f"원래 승객 수 단위 RMSE: {original_rmse:.3f}")
# 예측값과 실제값 일부를 표로 비교합니다.
result_df = pd.DataFrame({
"truth": truth_original_1d,
"prediction": pred_original_1d,
"error": truth_original_1d - pred_original_1d
})
# 결과 앞부분을 출력합니다.
print(result_df.head(10))원래 승객 수 단위 MSE: 2638.834
원래 승객 수 단위 RMSE: 51.370
truth prediction error
0 359.000000 386.191467 -27.191467
1 310.000000 366.431305 -56.431305
2 337.000000 362.361603 -25.361603
3 360.000000 340.182312 19.817688
4 342.000000 331.042633 10.957367
5 406.000000 343.301605 62.698395
6 396.000031 355.915588 40.084442
7 420.000031 393.940643 26.059387
8 472.000031 455.266876 16.733154
9 548.000000 497.284851 50.715149
예측결과시작화.
# 그래프 크기를 설정합니다.
plt.figure(figsize=(10, 5))
# 실제 승객 수를 선 그래프로 그립니다.
plt.plot(truth_original_1d, label="Truth")
# 모델 예측 승객 수를 선 그래프로 그립니다.
plt.plot(pred_original_1d, label="Prediction")
# 그래프 제목을 설정합니다.
plt.title("Airline Passenger Prediction")
# x축 이름을 설정합니다.
plt.xlabel("Test Month Index")
# y축 이름을 설정합니다.
plt.ylabel("Passengers")
# 범례를 표시합니다.
plt.legend()
# 격자선을 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()
예측해보자.
# 전체 정규화 데이터 중 마지막 12개월 값을 가져옵니다.
last_sequence = scaled_values[-PAST_MONTHS:]
# 모델 입력 형태인 (배치 크기, 시간 길이, 특성 수)로 변환합니다.
last_sequence_tensor = torch.tensor(last_sequence.reshape(1, PAST_MONTHS, INPUT_SIZE), dtype=torch.float32)
# 입력 Tensor를 현재 장치로 이동합니다.
last_sequence_tensor = last_sequence_tensor.to(device)
# 모델을 평가 모드로 전환합니다.
model.eval()
# 다음 달 예측에서는 기울기 계산이 필요 없으므로 no_grad를 사용합니다.
with torch.no_grad():
# 마지막 12개월 데이터를 사용하여 다음 1개월 값을 예측합니다.
next_month_scaled = model(last_sequence_tensor)
# 예측 Tensor를 CPU의 numpy 배열로 변환합니다.
next_month_scaled_np = next_month_scaled.detach().cpu().numpy()
# 정규화된 예측값을 원래 승객 수 단위로 복원합니다.
next_month_prediction = scaler.inverse_transform(next_month_scaled_np)
# 다음 1개월 예측 승객 수를 출력합니다.
print(f"다음 1개월 예측 승객 수: {next_month_prediction[0, 0]:.2f}")다음 1개월 예측 승객 수: 380.88
마찬가지로 tensorflow코드로 한번더 살펴보자.
import.
tensorflow, keras, layers를 import했다.
torch.manual_seed가 tf.fandom.set_seed로 바꿨다.
파라미터 설정
# 운영체제 관련 기능을 사용하기 위한 표준 라이브러리입니다.
# 예를 들어 현재 작업 폴더에 CSV 파일이 존재하는지 확인할 때 사용합니다.
import os
# 학습 시간을 측정하기 위해 time 함수를 불러옵니다.
# 모델 학습에 걸린 전체 시간을 확인할 때 사용합니다.
from time import time
# numpy는 배열 기반 수치 계산을 빠르게 처리하기 위해 사용하는 라이브러리입니다.
# 시계열 데이터를 입력 X와 정답 y 배열로 변환할 때 사용합니다.
import numpy as np
# pandas는 CSV 파일을 읽고 표 형태의 데이터를 처리하기 위해 사용하는 라이브러리입니다.
# 항공 승객 수 데이터를 DataFrame 형태로 불러올 때 사용합니다.
import pandas as pd
# matplotlib.pyplot은 선 그래프, 손실 그래프, 예측 결과 그래프를 그릴 때 사용하는 라이브러리입니다.
import matplotlib.pyplot as plt
# MinMaxScaler는 데이터를 0과 1 사이 범위로 변환하는 정규화 도구입니다.
# 승객 수처럼 값의 크기가 큰 데이터를 신경망이 학습하기 쉽게 바꿀 때 사용합니다.
from sklearn.preprocessing import MinMaxScaler
# mean_squared_error는 예측값과 실제값 사이의 평균제곱오차를 계산하는 평가 함수입니다.
# 원래 승객 수 단위로 복원한 뒤 모델 성능을 확인할 때 사용합니다.
from sklearn.metrics import mean_squared_error
# tensorflow는 딥러닝 모델 생성, 학습, 평가를 수행하는 대표적인 딥러닝 라이브러리입니다.
import tensorflow as tf
# keras는 TensorFlow 안에서 신경망 모델을 쉽게 구성할 수 있게 해주는 고수준 API입니다.
from tensorflow import keras
# layers는 LSTM, Dense, Input 같은 신경망 계층을 생성할 때 사용합니다.
from tensorflow.keras import layers
# numpy 배열 출력 시 소수점 자릿수를 3자리로 제한하여 결과를 보기 쉽게 만듭니다.
np.set_printoptions(precision=3, suppress=True)
# numpy 난수 시드를 고정하여 매번 비슷한 데이터 처리 결과가 나오도록 합니다.
np.random.seed(42)
# TensorFlow 난수 시드를 고정하여 모델 초기 가중치가 매번 비슷하게 생성되도록 합니다.
tf.random.set_seed(42)
# 현재 TensorFlow 버전을 출력합니다.
# 구글 코랩 또는 로컬 환경에서 TensorFlow가 정상적으로 설치되었는지 확인할 수 있습니다.
print("TensorFlow 버전:", tf.__version__)
# TensorFlow가 사용할 수 있는 GPU 목록을 확인합니다.
# GPU가 표시되면 학습 속도가 더 빨라질 수 있습니다.
print("사용 가능한 GPU:", tf.config.list_physical_devices("GPU"))# 과거 몇 개월의 데이터를 입력으로 사용할지 정합니다.
# 12로 설정하면 과거 12개월 승객 수를 보고 다음 1개월 승객 수를 예측합니다.
PAST_MONTHS = 12
# 전체 데이터 중 학습 데이터로 사용할 비율입니다.
# 0.8은 앞쪽 80% 데이터를 학습에 사용하고, 뒤쪽 20% 데이터를 테스트에 사용한다는 의미입니다.
TRAIN_RATIO = 0.8
# LSTM의 은닉 상태 크기입니다.
# 값이 클수록 모델이 더 복잡한 패턴을 표현할 수 있지만, 학습 시간이 늘고 과적합 위험도 증가합니다.
HIDDEN_SIZE = 300
# 입력 특성 수입니다.
# 여기서는 한 달의 승객 수 하나만 입력으로 사용하므로 1입니다.
INPUT_SIZE = 1
# 출력값 개수입니다.
# 다음 1개월 승객 수 하나를 예측하므로 1입니다.
OUTPUT_SIZE = 1
# 전체 학습 반복 횟수입니다.
# epoch는 전체 학습 데이터를 처음부터 끝까지 한 번 학습하는 단위입니다.
EPOCHS = 300
# 미니배치 크기입니다.
# 한 번의 가중치 업데이트에 사용할 샘플 개수를 의미합니다.
BATCH_SIZE = 64
# 학습률입니다.
# 모델 가중치를 한 번 수정할 때 얼마나 크게 수정할지 결정합니다.
LEARNING_RATE = 0.001
# 설정값을 확인하기 위해 출력합니다.
print("과거 입력 개월 수:", PAST_MONTHS)
print("학습 데이터 비율:", TRAIN_RATIO)
print("LSTM 은닉 상태 크기:", HIDDEN_SIZE)
print("입력 특성 수:", INPUT_SIZE)
print("출력값 개수:", OUTPUT_SIZE)
print("학습 반복 횟수:", EPOCHS)
print("배치 크기:", BATCH_SIZE)
print("학습률:", LEARNING_RATE)
데이터 불러오기 및 데이터 시각화
# 사용할 CSV 파일명을 지정합니다.
# 직접 파일을 업로드한 경우에는 이 파일명이 현재 작업 폴더에 있어야 합니다.
CSV_PATH = "airline.csv"
# 로컬 파일이 없을 때 사용할 공개 데이터 주소입니다.
# 구글 코랩에서 실습할 때 파일 업로드 없이 바로 실행할 수 있도록 예비 경로로 사용합니다.
FALLBACK_URL = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/airline-passengers.csv"
# 현재 작업 폴더에 airline.csv 파일이 존재하는지 확인합니다.
if os.path.exists(CSV_PATH):
# 파일이 있으면 로컬 CSV 파일을 읽습니다.
# header=None은 첫 행을 컬럼명으로 사용하지 않겠다는 의미입니다.
# usecols=[1]은 두 번째 열인 승객 수만 가져오겠다는 의미입니다.
raw = pd.read_csv(CSV_PATH, header=None, usecols=[1])
else:
# 파일이 없으면 공개 CSV 주소에서 데이터를 읽습니다.
# 해당 데이터는 Month,Passengers 구조이므로 Passengers 열만 사용합니다.
raw = pd.read_csv(FALLBACK_URL, usecols=["Passengers"])
# 컬럼명을 passengers로 통일합니다.
# 로컬 파일을 읽든 URL을 읽든 이후 코드에서 같은 컬럼명으로 처리하기 위함입니다.
raw.columns = ["passengers"]
# 데이터가 숫자형인지 안전하게 변환합니다.
# errors="coerce"는 숫자로 변환할 수 없는 값이 있으면 NaN으로 바꿉니다.
raw["passengers"] = pd.to_numeric(raw["passengers"], errors="coerce")
# 결측치가 있는 행을 제거합니다.
# LSTM 학습에는 숫자 데이터가 필요하므로 비어 있는 값은 제거합니다.
raw = raw.dropna().reset_index(drop=True)
# 데이터 앞부분을 출력하여 정상적으로 읽혔는지 확인합니다.
print("데이터 샘플")
print(raw.head(12))
# 전체 데이터 크기를 출력합니다.
print("\n전체 데이터 개수:", len(raw))
# 기초 통계량을 출력합니다.
print("\n기초 통계량")
print(raw.describe())# 그래프 크기를 설정합니다.
# figsize=(10, 4)는 가로 10, 세로 4 크기의 그래프를 의미합니다.
plt.figure(figsize=(10, 4))
# 월별 승객 수를 선 그래프로 그립니다.
# raw["passengers"].values는 승객 수 컬럼을 numpy 배열 형태로 가져옵니다.
plt.plot(raw["passengers"].values, label="Passengers")
# 그래프 제목을 설정합니다.
plt.title("Monthly Airline Passengers")
# x축 이름을 설정합니다.
plt.xlabel("Month Index")
# y축 이름을 설정합니다.
plt.ylabel("Passengers")
# 범례를 표시합니다.
plt.legend()
# 격자선을 표시하여 값의 변화를 더 쉽게 볼 수 있게 합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()
minmax 정규화 및 입력데이터, 정답데이터생성, 학습 데이터와 테스트 데이터 분리
# MinMaxScaler 객체를 생성합니다.
# feature_range=(0, 1)은 데이터의 최솟값을 0, 최댓값을 1로 변환하겠다는 의미입니다.
scaler = MinMaxScaler(feature_range=(0, 1))
# raw 데이터프레임의 passengers 열을 2차원 배열 형태로 변환합니다.
# MinMaxScaler는 입력을 반드시 2차원 배열 형태로 받습니다.
passenger_values = raw[["passengers"]].values
# fit_transform은 최솟값과 최댓값을 학습한 뒤 실제 정규화 변환을 수행합니다.
# scaled_values는 모든 승객 수가 0과 1 사이 값으로 바뀐 결과입니다.
scaled_values = scaler.fit_transform(passenger_values)
# 정규화 결과를 데이터프레임으로 변환하여 확인하기 쉽게 만듭니다.
scaled_df = pd.DataFrame(scaled_values, columns=["scaled_passengers"])
# 정규화된 데이터 앞부분을 출력합니다.
print("정규화 데이터 샘플")
print(scaled_df.head(12))
# 정규화 데이터의 최솟값과 최댓값을 출력합니다.
print("정규화 최솟값:", scaled_values.min())
print("정규화 최댓값:", scaled_values.max())# 시계열 데이터를 입력 X와 정답 y로 변환하는 함수를 정의합니다.
def make_sequences(data, past_months):
# 입력 데이터를 저장할 리스트입니다.
# 각 원소에는 과거 past_months개월의 정규화된 승객 수가 들어갑니다.
X_list = []
# 정답 데이터를 저장할 리스트입니다.
# 각 원소에는 입력 기간 바로 다음 달의 정규화된 승객 수가 들어갑니다.
y_list = []
# 전체 데이터에서 과거 입력 길이만큼 제외한 위치까지 반복합니다.
# 마지막 인덱스에서도 입력 past_months개와 다음 값 1개가 있어야 하기 때문입니다.
for i in range(len(data) - past_months):
# i 위치부터 i+past_months 전까지를 입력 데이터로 사용합니다.
# 예: i=0이면 0번째부터 11번째까지, 총 12개월이 입력입니다.
X_list.append(data[i : i + past_months])
# i+past_months 위치의 값을 정답 데이터로 사용합니다.
# 예: i=0이면 12번째 값, 즉 13번째 달 승객 수가 정답입니다.
y_list.append(data[i + past_months])
# 입력 리스트를 numpy 배열로 변환합니다.
# 최종 모양은 (샘플 수, 시간 길이, 특성 수)가 됩니다.
X_array = np.array(X_list)
# 정답 리스트를 numpy 배열로 변환합니다.
# 최종 모양은 (샘플 수, 1)가 됩니다.
y_array = np.array(y_list)
# 입력 배열과 정답 배열을 반환합니다.
return X_array, y_array
# 정규화된 승객 수 데이터로 시계열 입력과 정답을 생성합니다.
X_data, y_data = make_sequences(scaled_values, PAST_MONTHS)
# TensorFlow/Keras LSTM 입력은 기본적으로 (샘플 수, 시간 길이, 특성 수) 형태를 사용합니다.
# 현재 X_data는 이미 (샘플 수, 12, 1) 형태입니다.
print("X_data shape:", X_data.shape)
# y_data는 각 입력 시퀀스 다음 달 값이므로 (샘플 수, 1) 형태입니다.
print("y_data shape:", y_data.shape)
# 첫 번째 입력 데이터와 정답 데이터를 확인합니다.
print("첫 번째 입력 데이터")
print(X_data[0].flatten())
# 첫 번째 정답 데이터는 첫 번째 입력 다음 달의 정규화된 승객 수입니다.
print("첫 번째 정답 데이터")
print(y_data[0])
# 전체 샘플 개수에 학습 비율을 곱하여 학습 데이터의 마지막 인덱스를 계산합니다.
train_size = int(len(X_data) * TRAIN_RATIO)
# 앞쪽 데이터를 학습용 입력 데이터로 사용합니다.
# 시계열 데이터에서는 미래 데이터를 학습에 섞으면 안 되므로 순서를 유지합니다.
X_train = X_data[:train_size]
# 뒤쪽 데이터를 테스트용 입력 데이터로 사용합니다.
# 테스트 데이터는 모델이 학습하지 않은 미래 구간 역할을 합니다.
X_test = X_data[train_size:]
# 앞쪽 정답 데이터를 학습용 정답 데이터로 사용합니다.
y_train = y_data[:train_size]
# 뒤쪽 정답 데이터를 테스트용 정답 데이터로 사용합니다.
y_test = y_data[train_size:]
# TensorFlow 모델 학습에 적합하도록 입력 데이터를 float32 자료형으로 변환합니다.
X_train = X_train.astype("float32")
X_test = X_test.astype("float32")
# TensorFlow 모델 학습에 적합하도록 정답 데이터를 float32 자료형으로 변환합니다.
y_train = y_train.astype("float32")
y_test = y_test.astype("float32")
# 분리된 데이터의 모양을 출력합니다.
print("X_train shape:", X_train.shape)
print("y_train shape:", y_train.shape)
print("X_test shape:", X_test.shape)
print("y_test shape:", y_test.shape)
keras의 model.fit()은 numpy 배열을 바로 받을 수있다.
dataloader와 비슷한 역할인 tf.datadataset을 만들어보자.
tf.dataset.from_tensor_slices 입력데이터와 정답 데이터를 샘플 단위로 묶고 batch 단위로 묶는다 .(테스트 데이터도)
prefetch 로 다음 배치를 미리 준비해 학습 속도를 높이고 이때 tf.data.autofune으로 적절한 prefetch 크기를 자동으로 선택하도록 한다.
tf.data.dataset.from_tensor_slides 로 변환
# tf.data.Dataset.from_tensor_slices는 입력 데이터와 정답 데이터를 샘플 단위로 묶어 Dataset을 생성합니다.
# 각 샘플은 (과거 12개월 입력, 다음 1개월 정답) 구조를 가집니다.
train_dataset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
# batch는 데이터를 미니배치 단위로 묶습니다.
# shuffle=False는 시계열 데이터의 시간 순서를 유지하기 위한 설정입니다.
train_dataset = train_dataset.batch(BATCH_SIZE, drop_remainder=False)
# prefetch는 학습 중 다음 배치를 미리 준비하여 학습 속도를 높이는 기능입니다.
# AUTOTUNE은 TensorFlow가 적절한 prefetch 크기를 자동으로 선택하도록 합니다.
train_dataset = train_dataset.prefetch(tf.data.AUTOTUNE)
# 테스트 데이터도 TensorFlow Dataset으로 변환합니다.
# 평가와 예측 단계에서 사용할 수 있습니다.
test_dataset = tf.data.Dataset.from_tensor_slices((X_test, y_test))
# 테스트 데이터도 학습과 같은 배치 크기로 묶습니다.
test_dataset = test_dataset.batch(BATCH_SIZE, drop_remainder=False)
# 테스트 데이터도 미리 준비할 수 있도록 prefetch를 적용합니다.
test_dataset = test_dataset.prefetch(tf.data.AUTOTUNE)
# 학습 입력 데이터의 모양을 출력하여 LSTM 입력 형태가 올바른지 확인합니다.
print("X_train:", X_train.shape)
# 학습 정답 데이터의 모양을 출력합니다.
print("y_train:", y_train.shape)
# 테스트 입력 데이터의 모양을 출력합니다.
print("X_test:", X_test.shape)
# 테스트 정답 데이터의 모양을 출력합니다.
print("y_test:", y_test.shape)
LSTM 모델정의.
keras.seuential 이후 lauers.input에 받을 입력데이터 설정
layer.lstm으로 모델정의
layer.dense 레이어는 sigmoid로 설정
마찬가지로 nn.module, nn.LSTM, sigmoid, forward 등을 사용했던 pytorch보다 코드가 간결하다.
# keras.Sequential은 여러 계층을 순서대로 쌓는 가장 간단한 모델 생성 방식입니다.
model = keras.Sequential([
# Input 계층은 모델이 받을 입력 데이터의 모양을 정의합니다.
# shape=(PAST_MONTHS, INPUT_SIZE)는 한 샘플이 12개월 길이이고, 각 월마다 특성 1개를 가진다는 뜻입니다.
layers.Input(shape=(PAST_MONTHS, INPUT_SIZE)),
# LSTM 계층은 시계열 데이터의 시간적 흐름을 학습하는 순환 신경망 계층입니다.
# units=HIDDEN_SIZE는 LSTM 은닉 상태 크기를 300으로 설정한다는 의미입니다.
# return_sequences=False는 모든 시점의 출력을 반환하지 않고 마지막 시점의 출력만 반환한다는 뜻입니다.
layers.LSTM(units=HIDDEN_SIZE, return_sequences=False),
# Dense 계층은 LSTM이 만든 마지막 시점의 정보를 최종 예측값 1개로 변환합니다.
# activation="sigmoid"는 출력값을 0과 1 사이로 제한합니다.
# 정답 데이터가 MinMaxScaler로 0과 1 사이로 정규화되어 있으므로 출력 범위도 맞춰줍니다.
layers.Dense(OUTPUT_SIZE, activation="sigmoid")
])
# 모델 구조를 출력합니다.
# 각 계층의 출력 모양과 학습 가능한 파라미터 수를 확인할 수 있습니다.
model.summary()
최적화 알고리즘 설정 keras.optimizers.RMSprop()
손실함수 설정해 model.compile시 push.
# RMSprop 최적화 알고리즘을 생성합니다.
# RMSprop은 과거 기울기 제곱의 이동 평균을 사용하여 파라미터별 학습률을 조정합니다.
optimizer = keras.optimizers.RMSprop(learning_rate=LEARNING_RATE)
# 손실 함수 이름을 문자열로 지정합니다.
# "mse"는 Mean Squared Error, 즉 평균제곱오차를 의미합니다.
loss_function = "mse"
# 모델의 학습 설정을 compile 메서드로 지정합니다.
# Keras에서는 compile 단계에서 optimizer, loss, metrics를 연결합니다.
model.compile(
optimizer=optimizer, # 모델 가중치를 업데이트할 최적화 알고리즘을 지정합니다.
loss=loss_function, # 예측값과 실제값의 차이를 계산할 손실 함수를 지정합니다.
metrics=["mse"] # 학습 과정에서 MSE 지표를 함께 기록하도록 설정합니다.
)
# 손실 함수와 최적화 알고리즘을 출력합니다.
print("손실 함수:", loss_function)
print("최적화 알고리즘:", optimizer)
학습.
model.fit()
# 학습 시작 시간을 기록합니다.
start_time = time()
# 학습 시작 메시지를 출력합니다.
print("학습 시작")
# model.fit은 Keras 모델을 학습시키는 대표 메서드입니다.
# 여기서는 tf.data.Dataset으로 만든 train_dataset을 입력으로 사용합니다.
history = model.fit(
train_dataset, # 미니배치 단위로 구성된 학습 데이터셋입니다.
epochs=EPOCHS, # 전체 학습 데이터를 몇 번 반복해서 학습할지 지정합니다.
verbose=1 # 학습 진행 상황을 epoch마다 출력합니다.
)
# 학습 종료 시간을 기록합니다.
end_time = time()
# 전체 학습 시간을 출력합니다.
print(f"학습 완료: {end_time - start_time:.2f}초")
# history 객체에는 epoch별 손실값과 지표가 저장되어 있습니다.
# 이후 손실 그래프를 그릴 때 사용합니다.
print("저장된 학습 기록 키:", history.history.keys())학습 시작
Epoch 1/300
2/2 ━━━━━━━━━━━━━━━━━━━━ 2s 52ms/step - loss: 0.0729 - mse: 0.0729
Epoch 2/300
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 55ms/step - loss: 0.0653 - mse: 0.0653
Epoch 3/300
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 77ms/step - loss: 0.0606 - mse: 0.0606
Epoch 4/300
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 59ms/step - loss: 0.0571 - mse: 0.0571
Epoch 5/300
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 50ms/step - loss: 0.0542 - mse: 0.0542
Epoch 6/300
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 47ms/step - loss: 0.0518 - mse: 0.0518
Epoch 7/300
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 55ms/step - loss: 0.0497 - mse: 0.0497
Epoch 8/300
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 52ms/step - loss: 0.0479 - mse: 0.0479
Epoch 9/300
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 51ms/step - loss: 0.0462 - mse: 0.0462
Epoch 10/300
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 48ms/step - loss: 0.0446 - mse: 0.0446
Epoch 11/300
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 47ms/step - loss: 0.0431 - mse: 0.0431
Epoch 12/300
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 58ms/step - loss: 0.0415 - mse: 0.0415
...
Epoch 300/300
2/2 ━━━━━━━━━━━━━━━━━━━━ 0s 51ms/step - loss: 0.0042 - mse: 0.0042
학습 완료: 44.36초
저장된 학습 기록 키: dict_keys(['loss', 'mse'])
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
시각화
# history.history["loss"]에는 epoch별 학습 손실값이 리스트로 저장되어 있습니다.
train_losses = history.history["loss"]
# 그래프 크기를 설정합니다.
plt.figure(figsize=(10, 4))
# epoch별 학습 손실을 선 그래프로 그립니다.
plt.plot(train_losses, label="Train MSE Loss")
# 그래프 제목을 설정합니다.
plt.title("Training Loss Curve")
# x축 이름을 설정합니다.
plt.xlabel("Epoch")
# y축 이름을 설정합니다.
plt.ylabel("MSE Loss")
# 범례를 표시합니다.
plt.legend()
# 격자선을 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()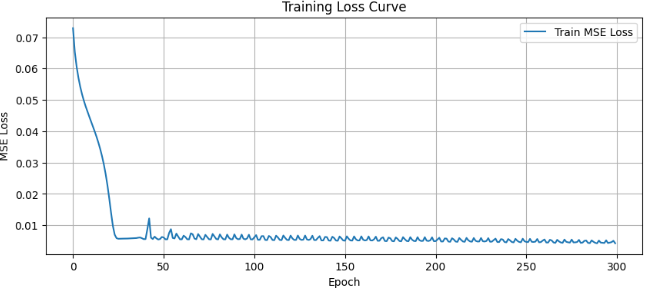
모델 평가
# model.evaluate는 테스트 데이터에 대한 손실값과 지표를 계산합니다.
# 반환값은 compile에서 지정한 loss와 metrics 순서에 따라 나옵니다.
test_loss, test_mse = model.evaluate(test_dataset, verbose=0)
# 테스트 손실값을 출력합니다.
print(f"테스트 MSE Loss: {test_loss:.6f}")
# 테스트 지표로 계산된 MSE도 출력합니다.
print(f"테스트 MSE Metric: {test_mse:.6f}")
원래 단위로 복원해 출력
# model.predict는 입력 데이터에 대한 예측값을 계산합니다.
# X_test는 (샘플 수, 12, 1) 형태의 테스트 입력 데이터입니다.
test_predictions = model.predict(X_test, verbose=0)
# 예측 결과는 이미 numpy 배열 형태입니다.
# pred_scaled는 0과 1 사이로 정규화된 예측값입니다.
pred_scaled = test_predictions
# truth_scaled는 0과 1 사이로 정규화된 실제 정답값입니다.
truth_scaled = y_test
# 정규화된 예측값을 원래 승객 수 단위로 복원합니다.
# scaler.inverse_transform은 MinMaxScaler가 적용되기 전의 숫자 범위로 되돌립니다.
pred_original = scaler.inverse_transform(pred_scaled)
# 정규화된 실제값을 원래 승객 수 단위로 복원합니다.
truth_original = scaler.inverse_transform(truth_scaled)
# 그래프와 표 출력이 편하도록 1차원 배열로 변환합니다.
pred_original_1d = pred_original.flatten()
# 실제값도 1차원 배열로 변환합니다.
truth_original_1d = truth_original.flatten()
# 원래 단위 기준 평균제곱오차를 계산합니다.
# 값이 작을수록 실제 승객 수와 예측 승객 수의 차이가 작다는 의미입니다.
original_mse = mean_squared_error(truth_original_1d, pred_original_1d)
# 원래 단위 기준 평균제곱근오차를 계산합니다.
# RMSE는 MSE에 제곱근을 씌운 값이라 실제 승객 수 단위로 해석하기 쉽습니다.
original_rmse = np.sqrt(original_mse)
# 평가 지표를 출력합니다.
print(f"원래 승객 수 단위 MSE: {original_mse:.3f}")
print(f"원래 승객 수 단위 RMSE: {original_rmse:.3f}")
# 예측값과 실제값 일부를 표로 비교합니다.
# error는 실제값에서 예측값을 뺀 값입니다.
result_df = pd.DataFrame({
"truth": truth_original_1d,
"prediction": pred_original_1d,
"error": truth_original_1d - pred_original_1d
})
# 결과 앞부분을 출력합니다.
print(result_df.head(10))
결과시각화
# 그래프 크기를 설정합니다.
plt.figure(figsize=(10, 5))
# 실제 승객 수를 선 그래프로 그립니다.
plt.plot(truth_original_1d, label="Truth")
# 모델 예측 승객 수를 선 그래프로 그립니다.
plt.plot(pred_original_1d, label="Prediction")
# 그래프 제목을 설정합니다.
plt.title("Airline Passenger Prediction")
# x축 이름을 설정합니다.
plt.xlabel("Test Month Index")
# y축 이름을 설정합니다.
plt.ylabel("Passengers")
# 범례를 표시합니다.
plt.legend()
# 격자선을 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()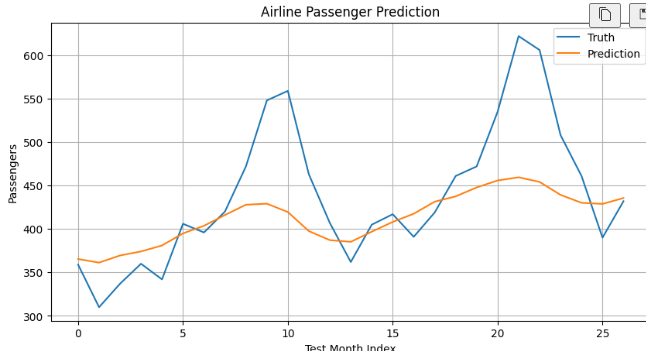
pytorch가 훨씬 나았다.
데이터로 예측해보자.
# 전체 정규화 데이터 중 마지막 12개월 값을 가져옵니다.
# 이 값들이 가장 최근 12개월 승객 수라고 볼 수 있습니다.
last_sequence = scaled_values[-PAST_MONTHS:]
# 모델 입력 형태인 (배치 크기, 시간 길이, 특성 수)로 변환합니다.
# 배치 크기는 1개, 시간 길이는 12개월, 특성 수는 1개입니다.
last_sequence_input = last_sequence.reshape(1, PAST_MONTHS, INPUT_SIZE).astype("float32")
# 마지막 12개월 데이터를 사용하여 다음 1개월 값을 예측합니다.
# 결과는 정규화된 0~1 범위의 값입니다.
next_month_scaled = model.predict(last_sequence_input, verbose=0)
# 정규화된 예측값을 원래 승객 수 단위로 복원합니다.
next_month_prediction = scaler.inverse_transform(next_month_scaled)
# 다음 1개월 예측 승객 수를 출력합니다.
print(f"다음 1개월 예측 승객 수: {next_month_prediction[0, 0]:.2f}")다음 1개월 예측 승객 수: 440.07
PyTorch가 TensorFLow보다 더 정확하진않다.
같은 모델, 같은 데이터, 같은 하리퍼파라미터를 쓰면 결과는 거의 비슷해야하지만 꽤 다르다.
왜일까..?
두개의 코드를 다시 비교해봤다.
데이터 생성
데이터 분할
모델 구조
손실함수
옵티마이저
학습 방식
평가 방식
모두 사실상 동일하다.


현 상태에서는 TensorFLow LSTM과 Pytorch의 LSTM의 내부 구현 차이가 가장 유력하다.
TensorFLow의 LSTM에는 기본적으로 recurrent_initializer='orthogonal', unit_forget_bias=True가 들어간다.
Pytorch는 uniform이 초기화되고 forget gate bias 기본값이 다르다.
큰데이터셋이 아닌 작은 데이터셋, 144개의 데이터에서 초기 가중치 차이 하나로도 생각보다 차이가 클 수 있다.
결론은 lSTM내부가 조금 다를것이다~ 라고 예상..
추가로 IMDB 영화 리뷰 감성분석 LSTM 코드를 분석해보자. 비교적 최신코드이다.
import
이때 tensorflow.keras.datasets imdb, tensorflow.keras,preprocessing.sequence pad_sequence를 import했는데 데이터셋 로더만 시퀀스만 가져왔을뿐 실제 모델 학습과 신경망 구현은 pytorch로만 작성했다.
IMDB 데이터셋은 KEras에서 바로 제공하고 이렇게 불러오는게 쉽기 때문. 한줄이면 자동 다운로드해 모두 다른 리뷰길이를 LSTM에 넣으려면 길이를 맞춰야함으로 sequence만 가져다 쓴것.
데이터 전처리만 kerras기능을 사용하는 경우가 많다.
# PyTorch의 핵심 패키지입니다. 텐서 연산, GPU 연산, 신경망 학습의 기본 기능을 제공합니다.
import torch
# torch.nn은 신경망 계층, 손실함수, 활성화 함수 등을 제공하는 모듈입니다.
import torch.nn as nn
# torch.optim은 AdamW, SGD 같은 최적화 알고리즘을 제공하는 모듈입니다.
import torch.optim as optim
# Dataset은 사용자 정의 데이터셋을 만들 때 상속받는 기본 클래스입니다.
# DataLoader는 데이터를 미니배치 단위로 모델에 공급하는 도구입니다.
from torch.utils.data import Dataset, DataLoader
# numpy는 배열 처리와 데이터 변환에 사용합니다.
import numpy as np
# matplotlib은 학습 손실과 정확도 그래프를 그리는 데 사용합니다.
import matplotlib.pyplot as plt
# sklearn.metrics는 혼동행렬, F1 점수, 정확도 계산에 사용합니다.
from sklearn.metrics import confusion_matrix, f1_score, accuracy_score
# time은 학습 시간을 측정하는 데 사용합니다.
from time import time
# os는 운영체제에 따라 DataLoader 작업자 수를 안전하게 설정하는 데 사용합니다.
import os
# IMDB 데이터셋 로더와 pad_sequences만 사용합니다.
# 모델 학습과 신경망 구현은 PyTorch로만 작성합니다.
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 현재 PyTorch 버전을 출력합니다.
print("PyTorch version:", torch.__version__)
# GPU 사용 가능 여부를 출력합니다.
print("CUDA available:", torch.cuda.is_available())
파라미터 설정
데이터 준비 import햇던 imdb.load_data.
# 실험 결과를 최대한 재현 가능하게 만들기 위해 난수 시드를 고정합니다.
SEED = 111
# PyTorch CPU 연산의 난수 시드를 고정합니다.
torch.manual_seed(SEED)
# GPU가 있는 경우 GPU 난수 시드도 고정합니다.
torch.cuda.manual_seed_all(SEED)
# 사용할 최대 단어 개수입니다. 가장 자주 등장하는 상위 10000개 단어만 사용합니다.
NUM_WORDS = 10000
# 각 영화 리뷰의 최대 길이입니다. 길이가 80보다 길면 자르고, 짧으면 0으로 채웁니다.
MAX_LEN = 80
# 단어 하나를 몇 차원 벡터로 표현할지 정합니다.
EMBED_DIM = 30
# LSTM 은닉 상태의 차원 수입니다.
HIDDEN_DIM = 100
# LSTM 계층 수입니다.
NUM_LAYERS = 1
# 학습 반복 횟수입니다. 실습 시간을 고려해 기본값은 10으로 설정했습니다.
EPOCHS = 10
# 한 번에 모델에 입력할 리뷰 개수입니다.
BATCH_SIZE = 128
# 학습률입니다.
LEARNING_RATE = 0.001
# Dropout 비율입니다. 과적합을 줄이기 위해 일부 뉴런을 무작위로 비활성화합니다.
DROPOUT = 0.3
# GPU가 있으면 GPU를 사용하고, 없으면 CPU를 사용합니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Windows 환경에서 DataLoader 오류를 줄이기 위해 작업자 수를 조절합니다.
NUM_WORKERS = 2 if os.name != "nt" else 0
# GPU 사용 시 데이터를 더 빠르게 복사할 수 있도록 설정합니다.
PIN_MEMORY = True if torch.cuda.is_available() else False
# 현재 사용할 장치를 출력합니다.
print("사용 장치:", device)# IMDB 데이터셋을 불러옵니다.
# num_words=NUM_WORDS는 가장 자주 등장하는 상위 NUM_WORDS개 단어만 사용한다는 의미입니다.
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=NUM_WORDS)
# 원본 학습 입력 데이터의 모양을 출력합니다.
print("학습용 입력 데이터 모양:", X_train.shape)
# 원본 학습 정답 데이터의 모양을 출력합니다.
print("학습용 정답 데이터 모양:", y_train.shape)
# 원본 평가 입력 데이터의 모양을 출력합니다.
print("평가용 입력 데이터 모양:", X_test.shape)
# 원본 평가 정답 데이터의 모양을 출력합니다.
print("평가용 정답 데이터 모양:", y_test.shape)
# 첫 번째 리뷰의 숫자 시퀀스를 출력합니다.
print("첫 번째 영화 리뷰 숫자 시퀀스:")
print(X_train[0])
# 첫 번째 리뷰의 단어 개수를 출력합니다.
print("첫 번째 리뷰 단어 수:", len(X_train[0]))
# 첫 번째 리뷰의 정답 라벨을 출력합니다.
print("첫 번째 리뷰 감성 라벨:", y_train[0])# 첫 10개 리뷰의 길이를 출력하는 함수를 정의합니다.
def show_review_lengths(data, title):
# 출력 제목을 표시합니다.
print(title)
# 앞에서부터 10개 리뷰를 확인합니다.
for i in range(10):
# i번째 리뷰의 길이를 출력합니다.
print(f"리뷰 {i}: {len(data[i])}개 단어")
# 길이 정리 전 학습 데이터의 리뷰 길이를 확인합니다.
show_review_lengths(X_train, "길이 정리 전 첫 10개 리뷰 길이")
위에서 import한 pad_sequences를 사용해 max_lien을 통일한다 .
# 리뷰 길이를 MAX_LEN으로 통일합니다.
# truncating='post'는 길이가 긴 리뷰의 뒤쪽을 자른다는 의미입니다.
# padding='post'는 길이가 짧은 리뷰의 뒤쪽을 0으로 채운다는 의미입니다.
X_train = pad_sequences(X_train, maxlen=MAX_LEN, truncating="post", padding="post")
# 평가 데이터도 학습 데이터와 같은 방식으로 길이를 맞춥니다.
X_test = pad_sequences(X_test, maxlen=MAX_LEN, truncating="post", padding="post")
# 길이 정리 후 학습 데이터의 리뷰 길이를 확인합니다.
show_review_lengths(X_train, "길이 정리 후 첫 10개 리뷰 길이")
# 길이 정리 후 최종 데이터 모양을 출력합니다.
print("학습 입력 최종 모양:", X_train.shape)
print("평가 입력 최종 모양:", X_test.shape)길이 정리 전 첫 10개 리뷰 길이
리뷰 0: 218개 단어
리뷰 1: 189개 단어
리뷰 2: 141개 단어
리뷰 3: 550개 단어
리뷰 4: 147개 단어
리뷰 5: 43개 단어
리뷰 6: 123개 단어
리뷰 7: 562개 단어
리뷰 8: 233개 단어
리뷰 9: 130개 단어
길이 정리 후 첫 10개 리뷰 길이
리뷰 0: 80개 단어
리뷰 1: 80개 단어
리뷰 2: 80개 단어
리뷰 3: 80개 단어
리뷰 4: 80개 단어
리뷰 5: 80개 단어
리뷰 6: 80개 단어
리뷰 7: 80개 단어
리뷰 8: 80개 단어
리뷰 9: 80개 단어
학습 입력 최종 모양: (25000, 80)
평가 입력 최종 모양: (25000, 80)
IMDB 데이터셋 리뷰는 실제 단어로 저장되어있지않고 숫자로 저장되어있다. 이 숫자 시퀀스를 단어로 되돌릴 수 있다.
# 단어를 숫자로 바꿔주는 원본 사전을 불러옵니다.
word_to_id = imdb.get_word_index()
# 숫자를 단어로 바꿔주는 반대 사전을 만듭니다.
id_to_word = {value: key for key, value in word_to_id.items()}
# 전체 단어 사전 크기를 출력합니다.
print("전체 단어 사전 크기:", len(word_to_id))
# 특정 단어가 몇 번째 번호인지 확인합니다.
print("단어 'virus'의 번호:", word_to_id.get("virus"))
# 특정 번호가 어떤 단어인지 확인합니다.
print("3310번 단어:", id_to_word.get(3310))
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json
1641221/1641221 ━━━━━━━━━━━━━━━━━━━━ 1s 1us/step
전체 단어 사전 크기: 88584
단어 'virus'의 번호: 3310
3310번 단어: virus
위 사전 변수를 활용해서 숫자로 된 리뷰들을 단어로 복원하는 함수를 정의하자.
# 숫자로 된 리뷰를 단어로 복원하는 함수를 정의합니다.
def decode_review(encoded_review, id_to_word):
# 복원된 단어들을 저장할 리스트를 만듭니다.
decoded_words = []
# 리뷰 안의 숫자 토큰을 하나씩 반복합니다.
for token_id in encoded_review:
# 0은 패딩 값이므로 <PAD>로 표시합니다.
if token_id == 0:
decoded_words.append("<PAD>")
else:
# IMDB 데이터셋은 특수 토큰 때문에 실제 단어 인덱스와 3 정도 차이가 있습니다.
decoded_words.append(id_to_word.get(token_id - 3, "???"))
# 단어 리스트를 공백으로 연결하여 하나의 문자열로 반환합니다.
return " ".join(decoded_words)
# 첫 번째 학습 리뷰를 단어 형태로 복원합니다.
decoded_text = decode_review(X_train[0], id_to_word)
# 복원된 리뷰를 출력합니다.
print("첫 번째 리뷰 복원 결과:")
print(decoded_text)
# 첫 번째 리뷰의 정답 라벨을 출력합니다.
print("정답 라벨:", y_train[0], "(0=부정, 1=긍정)")첫 번째 리뷰 복원 결과:
??? this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert ??? is an amazing actor and now the same being director ??? father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as
정답 라벨: 1 (0=부정, 1=긍정)
dataset과 dataloader를 사용해 데이터 하나를 꺼내고 dataloader를 dataset에서 가져와 미니배치로 모델에 전달하도록 해보자
# 영화 리뷰 데이터셋을 PyTorch Dataset 형태로 정의합니다.
class IMDBReviewDataset(Dataset):
# 데이터셋을 초기화하는 메서드입니다.
def __init__(self, texts, labels):
# 리뷰 숫자 시퀀스를 long 타입 텐서로 변환합니다.
# Embedding 계층은 정수 인덱스를 입력으로 받기 때문에 long 타입이 필요합니다.
self.texts = torch.tensor(texts, dtype=torch.long)
# 정답 라벨을 float 타입 텐서로 변환합니다.
# BCEWithLogitsLoss는 이진 분류에서 float 라벨을 사용합니다.
self.labels = torch.tensor(labels, dtype=torch.float32)
# 데이터셋의 전체 샘플 개수를 반환합니다.
def __len__(self):
return len(self.texts)
# 특정 인덱스의 샘플 하나를 반환합니다.
def __getitem__(self, idx):
return self.texts[idx], self.labels[idx]
# 학습용 Dataset을 생성합니다.
train_dataset = IMDBReviewDataset(X_train, y_train)
# 평가용 Dataset을 생성합니다.
test_dataset = IMDBReviewDataset(X_test, y_test)
# 학습용 DataLoader를 생성합니다.
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=NUM_WORKERS, pin_memory=PIN_MEMORY)
# 평가용 DataLoader를 생성합니다.
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=NUM_WORKERS, pin_memory=PIN_MEMORY)
# 첫 번째 배치를 꺼내 데이터 모양을 확인합니다.
batch_texts, batch_labels = next(iter(train_loader))
print("배치 입력 모양:", batch_texts.shape)
print("배치 라벨 모양:", batch_labels.shape)
모델 정의.
LSTM기반 감성분석 모델을 정의하는것이다.
nn.Embedding()으로 단어번호를 밀집 벡터로 바꾼다. 숫자 자체에는 단어 의미가 들어있지않다. embedding은 각 단어 번호를 의미를 가진 벡터로 바꾼다. 사과가 1이고, 자동차가 4라고해서 자동차가 사과보다 4배 중요한것도 아니다. 그러기에 각 단어에 차원을 추가해 처음에는 랜덤이지만 학습하면서 비슷한 문맥에서 자주등장하면 벡터도 비슷해지며 단어들끼리가 가까워진다 .그러기에 단어번호가 의미있는 실수벡터가 되는것.
# LSTM 기반 감성분석 모델을 정의합니다.
class SentimentLSTM(nn.Module):
# 모델 계층을 초기화합니다.
def __init__(self, num_words, embed_dim, hidden_dim, num_layers, dropout):
# 부모 클래스 nn.Module의 초기화 메서드를 실행합니다.
super().__init__()
# 단어 번호를 밀집 벡터로 바꾸는 임베딩 계층입니다.
self.embedding = nn.Embedding(num_embeddings=num_words, embedding_dim=embed_dim, padding_idx=0)
# 리뷰 문장의 순서 정보를 학습하는 LSTM 계층입니다.
self.lstm = nn.LSTM(
input_size=embed_dim,
hidden_size=hidden_dim,
num_layers=num_layers,
batch_first=True,
dropout=dropout if num_layers > 1 else 0.0
)
# 과적합을 줄이기 위한 Dropout 계층입니다.
self.dropout = nn.Dropout(p=dropout)
# LSTM이 만든 문장 표현을 이진 분류 점수 1개로 바꾸는 출력층입니다.
self.fc = nn.Linear(in_features=hidden_dim, out_features=1)
# 순전파 계산을 정의합니다.
def forward(self, x):
# 입력 x의 모양은 [배치크기, 문장길이]입니다.
embedded = self.embedding(x)
# LSTM에 넣어 순서 정보를 학습합니다.
lstm_out, (hidden, cell) = self.lstm(embedded)
# 마지막 시점의 출력만 사용하여 전체 문장을 대표하는 벡터로 사용합니다.
last_output = lstm_out[:, -1, :]
# Dropout을 적용하여 과적합을 줄입니다.
dropped = self.dropout(last_output)
# 최종 이진 분류 logit을 계산합니다.
logits = self.fc(dropped)
# BCEWithLogitsLoss에 맞추기 위해 sigmoid를 적용하지 않은 logit을 반환합니다.
return logits.squeeze(1)
# 모델 객체를 생성합니다.
model = SentimentLSTM(NUM_WORDS, EMBED_DIM, HIDDEN_DIM, NUM_LAYERS, DROPOUT)
# 모델을 GPU 또는 CPU로 이동합니다.
model = model.to(device)
# 모델 구조를 출력합니다.
print(model)
# 더미 입력을 생성하여 모델 출력 모양을 확인합니다.
dummy_input = torch.zeros((4, MAX_LEN), dtype=torch.long).to(device)
with torch.no_grad():
dummy_output = model(dummy_input)
print("더미 출력 모양:", dummy_output.shape)
손실함수 생성
# 이진 분류에 적합한 손실함수를 생성합니다.
criterion = nn.BCEWithLogitsLoss()
# AdamW 최적화 알고리즘을 생성합니다.
optimizer = optim.AdamW(model.parameters(), lr=LEARNING_RATE, weight_decay=1e-4)
# 학습률 스케줄러를 생성합니다. 일정 에포크마다 학습률을 줄여 더 안정적으로 수렴하도록 합니다.
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.5)
학습함수, 평가함수 정의
enumerate로 하나씩 가져와 zero_grrad, model(), criterion, loss.backward, optimizer.step()
확률이 0.5이상 이하로 구분한다 .
# 한 에포크 동안 모델을 학습하는 함수를 정의합니다.
def train_one_epoch(model, dataloader, criterion, optimizer, device):
# 모델을 학습 모드로 전환합니다.
model.train()
running_loss = 0.0
correct = 0
total = 0
# DataLoader에서 미니배치를 하나씩 가져옵니다.
for batch_idx, (texts, labels) in enumerate(dataloader):
# 리뷰 시퀀스와 정답 라벨을 학습 장치로 이동합니다.
texts = texts.to(device)
labels = labels.to(device)
# 이전 배치에서 계산된 기울기를 초기화합니다.
optimizer.zero_grad(set_to_none=True)
# 모델에 리뷰를 입력하여 logit을 계산합니다.
logits = model(texts)
# logit과 정답 라벨을 비교해 손실값을 계산합니다.
loss = criterion(logits, labels)
# 손실값을 기준으로 역전파를 수행합니다.
loss.backward()
# 계산된 기울기를 사용하여 모델 가중치를 업데이트합니다.
optimizer.step()
# 현재 배치 손실에 배치 크기를 곱해 누적합니다.
running_loss += loss.item() * texts.size(0)
# logit을 sigmoid 확률로 변환하고 0.5 기준으로 분류합니다.
preds = (torch.sigmoid(logits) >= 0.5).float()
# 예측이 정답과 일치한 개수를 누적합니다.
correct += (preds == labels).sum().item()
total += labels.size(0)
# 일정 배치마다 현재 손실을 출력합니다.
if (batch_idx + 1) % 50 == 0:
print(f" batch {batch_idx + 1:03d}/{len(dataloader):03d} | loss: {loss.item():.4f}")
return running_loss / total, correct / total
# 모델을 평가하는 함수를 정의합니다.
def evaluate(model, dataloader, criterion, device):
# 모델을 평가 모드로 전환합니다.
model.eval()
running_loss = 0.0
correct = 0
total = 0
all_preds = []
all_labels = []
# 평가 중에는 기울기 계산이 필요 없으므로 no_grad를 사용합니다.
with torch.no_grad():
for texts, labels in dataloader:
# 데이터를 평가 장치로 이동합니다.
texts = texts.to(device)
labels = labels.to(device)
# 모델에 리뷰를 입력하여 logit을 계산합니다.
logits = model(texts)
# 손실값을 계산합니다.
loss = criterion(logits, labels)
running_loss += loss.item() * texts.size(0)
# 확률이 0.5 이상이면 긍정, 아니면 부정으로 예측합니다.
preds = (torch.sigmoid(logits) >= 0.5).float()
correct += (preds == labels).sum().item()
total += labels.size(0)
# 예측값과 정답값을 CPU로 이동해 저장합니다.
all_preds.append(preds.cpu())
all_labels.append(labels.cpu())
all_preds = torch.cat(all_preds).numpy().astype(int)
all_labels = torch.cat(all_labels).numpy().astype(int)
return running_loss / total, correct / total, all_preds, all_labels
학습시작 및 시각화
# 학습 기록을 저장할 딕셔너리를 생성합니다.
history = {"train_loss": [], "train_acc": [], "test_loss": [], "test_acc": []}
# 학습 시작 시간을 기록합니다.
start_time = time()
# 지정한 에포크 수만큼 학습을 반복합니다.
for epoch in range(EPOCHS):
print(f"Epoch {epoch + 1}/{EPOCHS}")
# 한 에포크 동안 학습을 수행합니다.
train_loss, train_acc = train_one_epoch(model, train_loader, criterion, optimizer, device)
# 평가 데이터를 사용해 현재 모델 성능을 측정합니다.
test_loss, test_acc, _, _ = evaluate(model, test_loader, criterion, device)
# 학습률 스케줄러를 한 단계 진행합니다.
scheduler.step()
# 결과를 기록합니다.
history["train_loss"].append(train_loss)
history["train_acc"].append(train_acc)
history["test_loss"].append(test_loss)
history["test_acc"].append(test_acc)
# 현재 에포크 결과를 출력합니다.
print(f"train_loss: {train_loss:.4f} | train_acc: {train_acc * 100:.2f}% | test_loss: {test_loss:.4f} | test_acc: {test_acc * 100:.2f}%")
# 전체 학습 시간을 출력합니다.
end_time = time()
print(f"총 학습 시간: {end_time - start_time:.1f}초")# x축에 사용할 에포크 번호를 생성합니다.
epochs_range = range(1, EPOCHS + 1)
# 손실 그래프를 그립니다.
plt.figure(figsize=(8, 5))
plt.plot(epochs_range, history["train_loss"], marker="o", label="Train Loss")
plt.plot(epochs_range, history["test_loss"], marker="o", label="Test Loss")
plt.title("Loss Curve")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.grid(True)
plt.show()
# 정확도 그래프를 그립니다.
plt.figure(figsize=(8, 5))
plt.plot(epochs_range, history["train_acc"], marker="o", label="Train Accuracy")
plt.plot(epochs_range, history["test_acc"], marker="o", label="Test Accuracy")
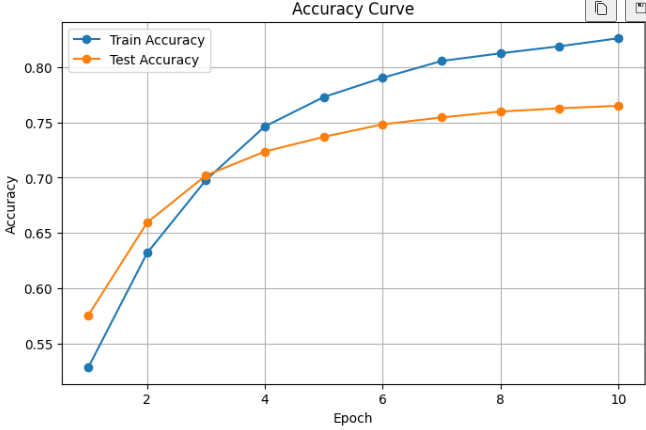
plt.title("Accuracy Curve")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.grid(True)
plt.show()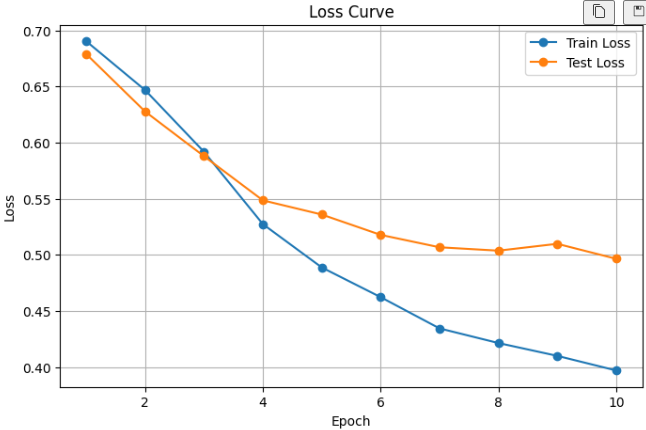
최종평가
# 평가 데이터 전체에 대해 최종 성능을 계산합니다.
final_loss, final_acc, final_preds, final_labels = evaluate(model, test_loader, criterion, device)
# 최종 평가 지표를 출력합니다.
print(f"최종 평가 손실: {final_loss:.4f}")
print(f"최종 평가 정확도: {final_acc * 100:.2f}%")
# F1 점수를 계산하고 출력합니다.
f1 = f1_score(final_labels, final_preds, average="binary")
print(f"최종 F1 점수: {f1 * 100:.2f}%")
# 혼동행렬을 계산하고 출력합니다.
cm = confusion_matrix(final_labels, final_preds)
print("혼동행렬:")
print(cm)
# 혼동행렬의 의미를 출력합니다.
print("혼동행렬 해석:")
print("[[실제 부정-예측 부정, 실제 부정-예측 긍정],")
print(" [실제 긍정-예측 부정, 실제 긍정-예측 긍정]]")최종 평가 손실: 0.4965
최종 평가 정확도: 76.49%
최종 F1 점수: 76.06%
혼동행렬:
[[9782 2718]
[3160 9340]]
혼동행렬 해석:
[[실제 부정-예측 부정, 실제 부정-예측 긍정],
[실제 긍정-예측 부정, 실제 긍정-예측 긍정]]
혼동행렬 시각화
# 혼동행렬을 시각화합니다.
plt.figure(figsize=(5, 4))
plt.imshow(cm, interpolation="nearest")
plt.title("Confusion Matrix")
plt.colorbar()
label_names = ["Negative", "Positive"]
tick_marks = np.arange(len(label_names))
plt.xticks(tick_marks, label_names)
plt.yticks(tick_marks, label_names)
# 각 칸에 숫자를 표시합니다.
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
plt.text(j, i, str(cm[i, j]), ha="center", va="center")
plt.ylabel("True Label")
plt.xlabel("Predicted Label")
plt.tight_layout()
plt.show()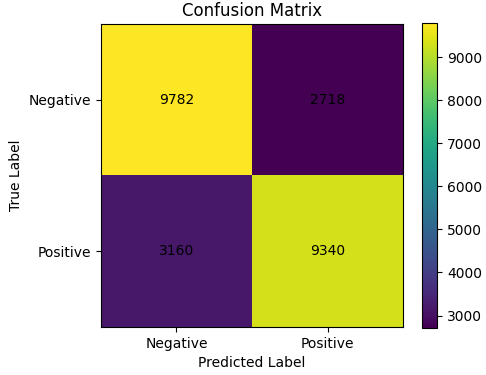
예측해보자.
# 확인할 평가 데이터 인덱스를 지정합니다.
sample_idx = 5
# 선택한 샘플 리뷰를 가져옵니다.
sample_text = torch.tensor(X_test[sample_idx], dtype=torch.long).unsqueeze(0).to(device)
# 선택한 샘플의 정답 라벨을 가져옵니다.
sample_label = y_test[sample_idx]
# 모델을 평가 모드로 전환합니다.
model.eval()
# 예측할 때는 기울기 계산이 필요 없으므로 no_grad를 사용합니다.
with torch.no_grad():
# 모델이 샘플 리뷰에 대한 logit을 계산합니다.
sample_logit = model(sample_text)
# logit을 sigmoid 확률로 변환합니다.
sample_prob = torch.sigmoid(sample_logit).item()
# 확률이 0.5 이상이면 1, 아니면 0으로 예측합니다.
sample_pred = 1 if sample_prob >= 0.5 else 0
# 샘플 리뷰를 단어로 복원합니다.
sample_review_text = decode_review(X_test[sample_idx], id_to_word)
# 샘플 리뷰와 결과를 출력합니다.
print("샘플 리뷰:")
print(sample_review_text)
print("정답 라벨:", sample_label, "(0=부정, 1=긍정)")
print(f"모델의 긍정 확률: {sample_prob:.4f}")
print("모델 예측:", sample_pred, "(0=부정, 1=긍정)")
학습된 모델은 mode.state_dict()로 저장하는 것이 일반적이다.
같은 모델 구조를 만든뒤 저장된 가중치를 불러와 다시 사용할 수 있기 때문이다 .
# 모델 가중치를 저장할 파일 이름을 지정합니다.
MODEL_PATH = "imdb_sentiment_lstm_adamw.pth"
# 모델의 학습된 가중치만 저장합니다.
torch.save(model.state_dict(), MODEL_PATH)
print("모델 가중치 저장 완료:", MODEL_PATH)
# 같은 구조의 새 모델 객체를 생성합니다.
loaded_model = SentimentLSTM(NUM_WORDS, EMBED_DIM, HIDDEN_DIM, NUM_LAYERS, DROPOUT)
# 저장된 가중치를 새 모델에 불러옵니다.
loaded_model.load_state_dict(torch.load(MODEL_PATH, map_location=device))
# 새 모델을 현재 장치로 이동하고 평가 모드로 전환합니다.
loaded_model = loaded_model.to(device)
loaded_model.eval()
print("모델 가중치 불러오기 완료")
마찬가지로 tensorflow도 확인해보자.
import
tensorflow.keras layers, tensorflow.keras.datasets imdb, tensorflow.keras.preprocessing,sequence pad_sequences 를 임포트했다.
# os는 운영체제 관련 기능을 사용할 때 필요한 표준 라이브러리입니다.
# 여기서는 파일 저장 경로를 다룰 때 사용할 수 있습니다.
import os
# time은 학습 시간을 측정하기 위해 사용하는 표준 라이브러리입니다.
# 학습 시작 시간과 종료 시간을 기록하여 전체 학습 시간을 계산합니다.
from time import time
# numpy는 숫자 배열을 효율적으로 처리하는 라이브러리입니다.
# 모델 예측 결과, 정답 배열, 혼동행렬 처리 등에 사용합니다.
import numpy as np
# matplotlib.pyplot은 그래프를 그리는 라이브러리입니다.
# 학습 손실, 정확도, 혼동행렬 시각화에 사용합니다.
import matplotlib.pyplot as plt
# confusion_matrix는 실제 라벨과 예측 라벨을 비교하여 혼동행렬을 계산합니다.
from sklearn.metrics import confusion_matrix
# f1_score는 정밀도와 재현율을 함께 고려한 F1 점수를 계산합니다.
from sklearn.metrics import f1_score
# accuracy_score는 실제 라벨과 예측 라벨을 비교하여 정확도를 계산합니다.
from sklearn.metrics import accuracy_score
# tensorflow는 딥러닝 모델 생성, 학습, 평가를 수행하는 대표적인 라이브러리입니다.
import tensorflow as tf
# keras는 TensorFlow 안에서 신경망 모델을 쉽게 만들 수 있게 해주는 고수준 API입니다.
from tensorflow import keras
# layers는 Embedding, LSTM, Dense, Dropout 같은 신경망 계층을 만들 때 사용합니다.
from tensorflow.keras import layers
# imdb는 TensorFlow/Keras에서 제공하는 IMDB 영화 리뷰 데이터셋 로더입니다.
from tensorflow.keras.datasets import imdb
# pad_sequences는 길이가 서로 다른 리뷰 문장을 같은 길이로 맞추기 위해 사용합니다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
# numpy 출력 옵션을 설정합니다.
# suppress=True는 아주 작은 값이 과학적 표기법으로 과도하게 표시되는 것을 줄여줍니다.
np.set_printoptions(precision=3, suppress=True)
# 현재 TensorFlow 버전을 출력하여 실행 환경을 확인합니다.
print("TensorFlow version:", tf.__version__)
# 현재 TensorFlow에서 인식하는 GPU 장치 목록을 출력합니다.
# GPU가 표시되면 학습이 더 빠르게 실행될 수 있습니다.
print("사용 가능한 GPU:", tf.config.list_physical_devices("GPU"))
파라미터 설정
# 실험 결과를 최대한 비슷하게 재현하기 위해 난수 시드를 고정합니다.
SEED = 111
# numpy 난수 시드를 고정합니다.
# 데이터 처리 과정에서 난수가 사용될 경우 같은 결과가 나오도록 돕습니다.
np.random.seed(SEED)
# TensorFlow 난수 시드를 고정합니다.
# 모델 초기 가중치와 학습 과정의 난수성을 어느 정도 고정할 수 있습니다.
tf.random.set_seed(SEED)
# 사용할 최대 단어 개수입니다.
# IMDB 데이터에서 가장 자주 등장하는 상위 10000개 단어만 사용합니다.
NUM_WORDS = 10000
# 각 영화 리뷰의 최대 길이입니다.
# 길이가 80보다 긴 리뷰는 잘라내고, 짧은 리뷰는 0으로 채워 길이를 맞춥니다.
MAX_LEN = 80
# 단어 하나를 몇 차원 벡터로 표현할지 정합니다.
# 예를 들어 EMBED_DIM=30이면 단어 하나가 30개 숫자로 구성된 벡터가 됩니다.
EMBED_DIM = 30
# LSTM 은닉 상태의 차원 수입니다.
# 값이 클수록 더 복잡한 문장 패턴을 표현할 수 있지만 학습 시간이 길어지고 과적합 위험도 커집니다.
HIDDEN_DIM = 100
# LSTM 계층 수입니다.
# 이 TensorFlow 기본 변환 코드에서는 1개 LSTM 계층을 사용합니다.
NUM_LAYERS = 1
# 학습 반복 횟수입니다.
# 전체 학습 데이터를 처음부터 끝까지 한 번 학습하는 과정을 1 epoch라고 합니다.
EPOCHS = 10
# 한 번에 모델에 입력할 리뷰 개수입니다.
# 배치 크기가 너무 크면 메모리를 많이 사용하고, 너무 작으면 학습이 불안정할 수 있습니다.
BATCH_SIZE = 128
# 학습률입니다.
# 모델 가중치를 한 번 업데이트할 때 얼마나 크게 수정할지 결정합니다.
LEARNING_RATE = 0.001
# Dropout 비율입니다.
# 학습 중 일부 뉴런을 무작위로 비활성화하여 과적합을 줄이는 데 사용합니다.
DROPOUT = 0.3
# AdamW에서 사용할 가중치 감쇠 값입니다.
# 가중치가 지나치게 커지는 것을 막아 과적합을 줄이는 데 도움을 줍니다.
WEIGHT_DECAY = 1e-4
# 설정값을 출력하여 현재 실습 조건을 확인합니다.
print("SEED:", SEED)
print("NUM_WORDS:", NUM_WORDS)
print("MAX_LEN:", MAX_LEN)
print("EMBED_DIM:", EMBED_DIM)
print("HIDDEN_DIM:", HIDDEN_DIM)
print("NUM_LAYERS:", NUM_LAYERS)
print("EPOCHS:", EPOCHS)
print("BATCH_SIZE:", BATCH_SIZE)
print("LEARNING_RATE:", LEARNING_RATE)
print("DROPOUT:", DROPOUT)
print("WEIGHT_DECAY:", WEIGHT_DECAY)
데이터 준비 및 리뷰 데이터 확인
# IMDB 데이터셋을 불러옵니다.
# num_words=NUM_WORDS는 가장 자주 등장하는 상위 NUM_WORDS개 단어만 사용한다는 의미입니다.
# 반환값은 학습 데이터와 평가 데이터로 나뉘어 있습니다.
(X_train, y_train), (X_test, y_test) = imdb.load_data(num_words=NUM_WORDS)
# 원본 학습 입력 데이터의 모양을 출력합니다.
# IMDB 원본 데이터는 리뷰마다 길이가 달라 dtype=object 형태로 저장됩니다.
print("학습용 입력 데이터 모양:", X_train.shape)
# 원본 학습 정답 데이터의 모양을 출력합니다.
print("학습용 정답 데이터 모양:", y_train.shape)
# 원본 평가 입력 데이터의 모양을 출력합니다.
print("평가용 입력 데이터 모양:", X_test.shape)
# 원본 평가 정답 데이터의 모양을 출력합니다.
print("평가용 정답 데이터 모양:", y_test.shape)
# 첫 번째 리뷰의 숫자 시퀀스를 출력합니다.
# 각 숫자는 단어 사전에 등록된 특정 단어 번호를 의미합니다.
print("\n첫 번째 영화 리뷰 숫자 시퀀스:")
print(X_train[0])
# 첫 번째 리뷰의 단어 개수를 출력합니다.
# 아직 길이 맞추기 전이므로 리뷰마다 길이가 서로 다를 수 있습니다.
print("첫 번째 리뷰 단어 수:", len(X_train[0]))
# 첫 번째 리뷰의 정답 라벨을 출력합니다.
# 0은 부정, 1은 긍정을 의미합니다.
print("첫 번째 리뷰 감성 라벨:", y_train[0])# 첫 10개 리뷰의 길이를 출력하는 함수를 정의합니다.
def show_review_lengths(data, title):
# 출력 제목을 표시합니다.
print(title)
# 앞에서부터 10개 리뷰를 확인합니다.
for i in range(10):
# i번째 리뷰의 길이를 출력합니다.
# 길이 맞추기 전에는 리뷰마다 단어 개수가 다르게 출력될 수 있습니다.
print(f"리뷰 {i}: {len(data[i])}개 단어")
# 길이 정리 전 학습 데이터의 리뷰 길이를 확인합니다.
show_review_lengths(X_train, "\n길이 정리 전 첫 10개 리뷰 길이")
import한 pad_sequences()를 활용해 로 데이터를 max_len 길이를 맞춘다.
tensorflow에 맞춰 자료형을 int32로 변환, 정답라벨은 flost32로 변환한다 .
# 리뷰 길이를 MAX_LEN으로 통일합니다.
# truncating="post"는 길이가 긴 리뷰의 뒤쪽 단어를 잘라낸다는 의미입니다.
# padding="post"는 길이가 짧은 리뷰의 뒤쪽에 0을 채운다는 의미입니다.
X_train = pad_sequences(
X_train, # 길이를 맞출 학습 리뷰 데이터입니다.
maxlen=MAX_LEN, # 모든 리뷰를 MAX_LEN 길이로 맞춥니다.
truncating="post", # 긴 리뷰는 뒤쪽을 잘라냅니다.
padding="post" # 짧은 리뷰는 뒤쪽에 0을 채웁니다.
)
# 평가 데이터도 학습 데이터와 같은 방식으로 길이를 맞춥니다.
X_test = pad_sequences(
X_test, # 길이를 맞출 평가 리뷰 데이터입니다.
maxlen=MAX_LEN, # 모든 리뷰를 MAX_LEN 길이로 맞춥니다.
truncating="post", # 긴 리뷰는 뒤쪽을 잘라냅니다.
padding="post" # 짧은 리뷰는 뒤쪽에 0을 채웁니다.
)
# TensorFlow 모델 학습에 적합하도록 입력 데이터를 int32 자료형으로 변환합니다.
# Embedding 계층은 정수 단어 번호를 입력으로 받습니다.
X_train = X_train.astype("int32")
X_test = X_test.astype("int32")
# 정답 라벨을 float32 자료형으로 변환합니다.
# binary_crossentropy는 0.0 또는 1.0 형태의 실수 라벨을 사용할 수 있습니다.
y_train = y_train.astype("float32")
y_test = y_test.astype("float32")
# 길이 정리 후 학습 데이터의 리뷰 길이를 확인합니다.
show_review_lengths(X_train, "\n길이 정리 후 첫 10개 리뷰 길이")
# 길이 정리 후 최종 데이터 모양을 출력합니다.
print("\n학습 입력 최종 모양:", X_train.shape)
print("평가 입력 최종 모양:", X_test.shape)
# 정답 데이터 모양도 출력합니다.
print("학습 정답 최종 모양:", y_train.shape)
print("평가 정답 최종 모양:", y_test.shape)
마찬가지로 단어 사전을 확인한다 .
# 단어를 숫자로 바꿔주는 원본 사전을 불러옵니다.
# 예를 들어 "good"이라는 단어가 특정 숫자 번호에 연결되어 있습니다.
word_to_id = imdb.get_word_index()
# 숫자를 단어로 바꿔주는 반대 사전을 만듭니다.
# 원래 사전이 {단어: 번호} 형태이므로 {번호: 단어} 형태로 뒤집습니다.
id_to_word = {value: key for key, value in word_to_id.items()}
# 전체 단어 사전 크기를 출력합니다.
print("전체 단어 사전 크기:", len(word_to_id))
# 특정 단어가 몇 번째 번호인지 확인합니다.
print("단어 'virus'의 번호:", word_to_id.get("virus"))
# 특정 번호가 어떤 단어인지 확인합니다.
print("3310번 단어:", id_to_word.get(3310))
단어로 복원하는 함수정의
# 숫자로 된 리뷰를 단어로 복원하는 함수를 정의합니다.
def decode_review(encoded_review, id_to_word):
# 복원된 단어들을 저장할 리스트를 만듭니다.
decoded_words = []
# 리뷰 안의 숫자 토큰을 하나씩 반복합니다.
for token_id in encoded_review:
# 0은 패딩 값이므로 <PAD>로 표시합니다.
if token_id == 0:
decoded_words.append("<PAD>")
else:
# IMDB 데이터셋은 특수 토큰 때문에 실제 단어 인덱스와 약간 차이가 있습니다.
# 일반적으로 token_id - 3을 사용하면 원래 단어에 더 가깝게 복원됩니다.
decoded_words.append(id_to_word.get(int(token_id) - 3, "???"))
# 단어 리스트를 공백으로 연결하여 하나의 문자열로 반환합니다.
return " ".join(decoded_words)
# 첫 번째 학습 리뷰를 단어 형태로 복원합니다.
decoded_text = decode_review(X_train[0], id_to_word)
# 복원된 리뷰를 출력합니다.
print("첫 번째 리뷰 복원 결과:")
print(decoded_text)
# 첫 번째 리뷰의 정답 라벨을 출력합니다.
print("\n정답 라벨:", y_train[0], "(0=부정, 1=긍정)")
tensorflow용 dataset을 만든다. from_tensor_slices()를 통해 샘플단위로 묶어주고
shuffle() 로 순서를 섞어 모델이 순서에 의존하지않도록 한다 .
배치생성
prefetch() 다음 배치 미리 분비해 학습속도를 높인다.
# 학습용 TensorFlow Dataset을 생성합니다.
# from_tensor_slices는 X_train과 y_train을 샘플 단위로 묶어줍니다.
train_dataset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
# shuffle은 학습 데이터 순서를 섞어 모델이 데이터 순서에 과하게 의존하지 않도록 합니다.
# buffer_size는 섞을 때 사용할 데이터 범위를 의미합니다.
train_dataset = train_dataset.shuffle(buffer_size=len(X_train), seed=SEED)
# batch는 데이터를 BATCH_SIZE개씩 묶어 미니배치를 만듭니다.
# 미니배치 단위로 학습하면 전체 데이터를 한 번에 학습하는 것보다 메모리를 적게 사용합니다.
train_dataset = train_dataset.batch(BATCH_SIZE)
# prefetch는 학습 중 다음 배치를 미리 준비하여 학습 속도를 높이는 기능입니다.
# AUTOTUNE은 TensorFlow가 적절한 값을 자동으로 선택하게 합니다.
train_dataset = train_dataset.prefetch(tf.data.AUTOTUNE)
# 평가용 TensorFlow Dataset을 생성합니다.
# 평가 데이터는 섞지 않습니다. 섞지 않아도 평가 결과에는 영향이 없습니다.
test_dataset = tf.data.Dataset.from_tensor_slices((X_test, y_test))
# 평가 데이터도 학습과 같은 배치 크기로 묶습니다.
test_dataset = test_dataset.batch(BATCH_SIZE)
# 평가 데이터도 미리 준비할 수 있도록 prefetch를 적용합니다.
test_dataset = test_dataset.prefetch(tf.data.AUTOTUNE)
# 학습 데이터셋에서 첫 번째 배치를 하나 꺼냅니다.
sample_batch_texts, sample_batch_labels = next(iter(train_dataset))
# 배치 입력 모양을 출력합니다.
# 모양은 [배치크기, 문장길이]입니다.
print("배치 입력 모양:", sample_batch_texts.shape)
# 배치 정답 모양을 출력합니다.
# 모양은 [배치크기]입니다.
print("배치 정답 모양:", sample_batch_labels.shape)
# 첫 번째 배치의 라벨 일부를 출력합니다.
print("배치 라벨 일부:", sample_batch_labels[:10].numpy())
keras.sequential() 객체를 만들어
layers.input() 만들기
embedding으로 의미있는 숫자로 만든다.
layers.LSTM 계층 만들고
layers.dropout()로 뉴런을 무작위 비활성화해 과적합을 줄인다 .
layers.dense, 레이어만들고 activation은 sigmoid로 지정한다.
# TensorFlow/Keras의 Sequential API를 사용하여 LSTM 감성분석 모델을 정의합니다.
# Sequential은 계층을 순서대로 쌓는 가장 간단한 모델 생성 방식입니다.
model = keras.Sequential([
# Input 계층은 모델이 받을 입력 데이터의 모양을 정의합니다.
# 리뷰 하나는 MAX_LEN개의 단어 번호로 구성되므로 입력 shape은 (MAX_LEN,)입니다.
layers.Input(shape=(MAX_LEN,)),
# Embedding 계층은 정수 단어 번호를 밀집 벡터로 변환합니다.
# input_dim=NUM_WORDS는 단어 사전 크기를 의미합니다.
# output_dim=EMBED_DIM은 단어 하나를 EMBED_DIM차원 벡터로 표현한다는 의미입니다.
# mask_zero=True는 패딩 값 0을 실제 단어가 아닌 값으로 처리하도록 알려줍니다.
layers.Embedding(
input_dim=NUM_WORDS,
output_dim=EMBED_DIM,
mask_zero=True
),
# LSTM 계층은 단어 순서 정보를 학습합니다.
# units=HIDDEN_DIM은 LSTM이 출력할 은닉 벡터 크기를 의미합니다.
# return_sequences=False는 모든 시점의 출력을 반환하지 않고 마지막 출력만 반환한다는 뜻입니다.
layers.LSTM(
units=HIDDEN_DIM,
return_sequences=False
),
# Dropout 계층은 학습 중 일부 뉴런을 무작위로 비활성화하여 과적합을 줄입니다.
layers.Dropout(rate=DROPOUT),
# Dense 출력층은 LSTM이 만든 문장 표현을 긍정 확률 1개로 변환합니다.
# sigmoid는 출력값을 0과 1 사이 확률값으로 바꿉니다.
layers.Dense(
units=1,
activation="sigmoid"
)
])
# 모델 구조를 출력합니다.
# 각 계층의 출력 모양과 학습 가능한 파라미터 수를 확인할 수 있습니다.
model.summary()
keras.optimizers.adamw최적화알고리즘 설정
keras.losses.binarycrossentropy 손실함수 생성
keras.metrics.binaryaccuracy 정확도 지표 생성
model.compile()
# AdamW 최적화 알고리즘을 생성합니다.
# learning_rate는 가중치를 한 번 업데이트할 때 얼마나 크게 움직일지 정합니다.
# weight_decay는 가중치가 지나치게 커지는 것을 막아 과적합을 줄이는 데 도움을 줍니다.
optimizer = keras.optimizers.AdamW(
learning_rate=LEARNING_RATE,
weight_decay=WEIGHT_DECAY
)
# 이진 분류 손실 함수를 생성합니다.
# from_logits=False는 모델 출력이 sigmoid를 거친 확률값이라는 뜻입니다.
loss_function = keras.losses.BinaryCrossentropy(from_logits=False)
# 정확도 지표를 생성합니다.
# BinaryAccuracy는 예측 확률을 threshold=0.5 기준으로 0 또는 1로 바꾼 뒤 정확도를 계산합니다.
binary_accuracy = keras.metrics.BinaryAccuracy(threshold=0.5)
# 모델의 학습 방식을 compile로 설정합니다.
# Keras에서는 compile 단계에서 optimizer, loss, metrics를 연결합니다.
model.compile(
optimizer=optimizer, # 손실을 줄이기 위해 사용할 최적화 알고리즘입니다.
loss=loss_function, # 예측값과 실제값의 차이를 계산할 손실 함수입니다.
metrics=[binary_accuracy] # 학습 중 함께 확인할 평가 지표입니다.
)
# 설정된 손실 함수와 최적화 알고리즘을 출력합니다.
print("손실 함수:", loss_function)
print("최적화 알고리즘:", optimizer)
model.fit() 학습 및 시각화
# 학습 시작 시간을 기록합니다.
start_time = time()
# 학습 시작 메시지를 출력합니다.
print("학습 시작")
# model.fit은 Keras 모델을 학습시키는 대표 메서드입니다.
# validation_data를 지정하면 각 epoch마다 평가 데이터 성능도 함께 계산합니다.
history = model.fit(
train_dataset, # 미니배치 단위로 구성된 학습 데이터셋입니다.
validation_data=test_dataset, # 각 epoch마다 성능을 확인할 평가 데이터셋입니다.
epochs=EPOCHS, # 전체 학습 데이터를 몇 번 반복해서 학습할지 지정합니다.
verbose=1 # epoch별 학습 로그를 출력합니다.
)
# 학습 종료 시간을 기록합니다.
end_time = time()
# 전체 학습 시간을 출력합니다.
print(f"\n총 학습 시간: {end_time - start_time:.1f}초")
# history 객체 안에 저장된 기록 이름을 출력합니다.
print("학습 기록 키:", history.history.keys())# x축에 사용할 epoch 번호를 생성합니다.
epochs_range = range(1, EPOCHS + 1)
# history에서 학습 손실값 리스트를 가져옵니다.
train_loss = history.history["loss"]
# history에서 평가 손실값 리스트를 가져옵니다.
test_loss = history.history["val_loss"]
# BinaryAccuracy 지표 이름은 TensorFlow 버전에 따라 binary_accuracy 또는 binary_accuracy_1처럼 달라질 수 있습니다.
# 따라서 history 키 중에서 accuracy가 포함된 이름을 찾아 사용합니다.
accuracy_keys = [key for key in history.history.keys() if "accuracy" in key and not key.startswith("val_")]
# 평가 정확도 키도 같은 방식으로 찾습니다.
val_accuracy_keys = [key for key in history.history.keys() if key.startswith("val_") and "accuracy" in key]
# 첫 번째 정확도 키를 학습 정확도 키로 사용합니다.
train_acc_key = accuracy_keys[0]
# 첫 번째 평가 정확도 키를 평가 정확도 키로 사용합니다.
test_acc_key = val_accuracy_keys[0]
# history에서 학습 정확도 리스트를 가져옵니다.
train_acc = history.history[train_acc_key]
# history에서 평가 정확도 리스트를 가져옵니다.
test_acc = history.history[test_acc_key]
# 손실 그래프를 그리기 위해 그래프 크기를 설정합니다.
plt.figure(figsize=(8, 5))
# epoch별 학습 손실을 선 그래프로 그립니다.
plt.plot(epochs_range, train_loss, marker="o", label="Train Loss")
# epoch별 평가 손실을 선 그래프로 그립니다.
plt.plot(epochs_range, test_loss, marker="o", label="Test Loss")
# 그래프 제목을 설정합니다.
plt.title("Loss Curve")
# x축 이름을 설정합니다.
plt.xlabel("Epoch")
# y축 이름을 설정합니다.
plt.ylabel("Loss")
# 범례를 표시합니다.
plt.legend()
# 격자선을 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()
# 정확도 그래프를 그리기 위해 그래프 크기를 설정합니다.
plt.figure(figsize=(8, 5))
# epoch별 학습 정확도를 선 그래프로 그립니다.
plt.plot(epochs_range, train_acc, marker="o", label="Train Accuracy")
# epoch별 평가 정확도를 선 그래프로 그립니다.
plt.plot(epochs_range, test_acc, marker="o", label="Test Accuracy")
# 그래프 제목을 설정합니다.
plt.title("Accuracy Curve")
# x축 이름을 설정합니다.
plt.xlabel("Epoch")
# y축 이름을 설정합니다.
plt.ylabel("Accuracy")
# 범례를 표시합니다.
plt.legend()
# 격자선을 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()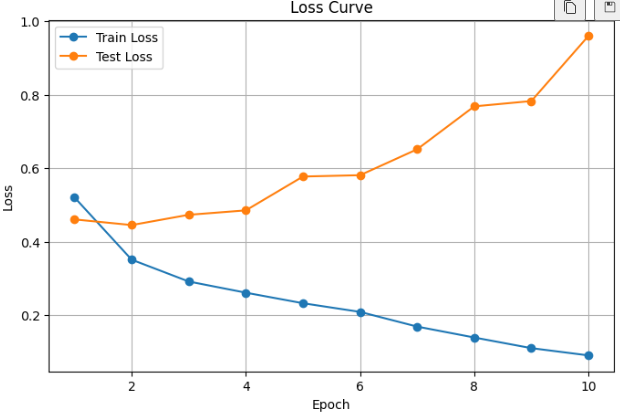

평가.
# model.evaluate는 평가 데이터에 대한 손실값과 정확도를 계산합니다.
# 반환값은 compile에서 지정한 loss와 metrics 순서에 따라 나옵니다.
eval_results = model.evaluate(test_dataset, verbose=0)
# 첫 번째 반환값은 손실값입니다.
final_loss = eval_results[0]
# 두 번째 반환값은 BinaryAccuracy입니다.
final_acc = eval_results[1]
# 최종 평가 손실을 출력합니다.
print(f"최종 평가 손실: {final_loss:.4f}")
# 최종 평가 정확도를 출력합니다.
print(f"최종 평가 정확도: {final_acc * 100:.2f}%")
평가데이터에 대한 평가
# model.predict는 평가 입력 데이터에 대한 예측 확률을 계산합니다.
# 출력값은 긍정 클래스일 확률입니다.
final_probs = model.predict(X_test, batch_size=BATCH_SIZE, verbose=0)
# 예측 확률을 1차원 배열로 변환합니다.
final_probs = final_probs.reshape(-1)
# 확률이 0.5 이상이면 긍정 1, 미만이면 부정 0으로 변환합니다.
final_preds = (final_probs >= 0.5).astype("int32")
# 실제 라벨도 정수형 1차원 배열로 변환합니다.
final_labels = y_test.astype("int32").reshape(-1)
# sklearn으로 정확도를 다시 계산합니다.
# model.evaluate 결과와 같은 의미이며, 직접 예측 배열을 확인하는 용도입니다.
sklearn_acc = accuracy_score(final_labels, final_preds)
# F1 점수를 계산합니다.
# F1은 정밀도와 재현율을 함께 고려하는 지표입니다.
f1 = f1_score(final_labels, final_preds, average="binary")
# 혼동행렬을 계산합니다.
# 행은 실제 라벨, 열은 예측 라벨을 의미합니다.
cm = confusion_matrix(final_labels, final_preds)
# sklearn으로 계산한 정확도를 출력합니다.
print(f"sklearn 기준 정확도: {sklearn_acc * 100:.2f}%")
# F1 점수를 출력합니다.
print(f"최종 F1 점수: {f1 * 100:.2f}%")
# 혼동행렬을 출력합니다.
print("\n혼동행렬:")
print(cm)
# 혼동행렬의 의미를 출력합니다.
print("\n혼동행렬 해석:")
print("[[실제 부정-예측 부정, 실제 부정-예측 긍정],")
print(" [실제 긍정-예측 부정, 실제 긍정-예측 긍정]]")
혼동행렬 시각화
# 혼동행렬 그래프 크기를 설정합니다.
plt.figure(figsize=(5, 4))
# 혼동행렬을 이미지 형태로 표시합니다.
plt.imshow(cm, interpolation="nearest")
# 그래프 제목을 설정합니다.
plt.title("Confusion Matrix")
# 오른쪽에 색상 막대를 표시합니다.
plt.colorbar()
# x축과 y축에 표시할 클래스 이름을 정의합니다.
label_names = ["Negative", "Positive"]
# 클래스 위치 인덱스를 생성합니다.
tick_marks = np.arange(len(label_names))
# x축 눈금 이름을 설정합니다.
plt.xticks(tick_marks, label_names)
# y축 눈금 이름을 설정합니다.
plt.yticks(tick_marks, label_names)
# 혼동행렬 각 칸에 숫자를 표시합니다.
for i in range(cm.shape[0]):
# 열 방향으로 반복합니다.
for j in range(cm.shape[1]):
# j는 x축 위치, i는 y축 위치입니다.
# str(cm[i, j])는 해당 칸의 개수를 문자열로 바꾼 값입니다.
plt.text(j, i, str(cm[i, j]), ha="center", va="center")
# y축 이름을 설정합니다.
plt.ylabel("True Label")
# x축 이름을 설정합니다.
plt.xlabel("Predicted Label")
# 그래프 요소가 겹치지 않도록 자동 정렬합니다.
plt.tight_layout()
# 그래프를 출력합니다.
plt.show()
샘플데이터로 ㅎ확인
# 확인할 평가 데이터 인덱스를 지정합니다.
sample_idx = 5
# 선택한 샘플 리뷰를 가져옵니다.
# model.predict에 넣기 위해 배치 차원을 추가합니다.
sample_text = X_test[sample_idx:sample_idx + 1]
# 선택한 샘플의 정답 라벨을 가져옵니다.
sample_label = int(y_test[sample_idx])
# 모델이 샘플 리뷰에 대한 긍정 확률을 예측합니다.
sample_prob = model.predict(sample_text, verbose=0)[0, 0]
# 확률이 0.5 이상이면 1, 아니면 0으로 예측합니다.
sample_pred = 1 if sample_prob >= 0.5 else 0
# 샘플 리뷰를 단어로 복원합니다.
sample_review_text = decode_review(X_test[sample_idx], id_to_word)
# 샘플 리뷰와 결과를 출력합니다.
print("샘플 리뷰:")
print(sample_review_text)
# 정답 라벨을 출력합니다.
print("\n정답 라벨:", sample_label, "(0=부정, 1=긍정)")
# 모델이 계산한 긍정 확률을 출력합니다.
print(f"모델의 긍정 확률: {sample_prob:.4f}")
# 모델 예측 결과를 출력합니다.
print("모델 예측:", sample_pred, "(0=부정, 1=긍정)")
직접 작성한 문장으로 재수행
# 직접 입력한 영어 문장을 모델 입력 형태로 변환하는 함수를 정의합니다.
def encode_custom_review(text, word_to_id, max_len):
# 입력 문장을 소문자로 변환합니다.
# IMDB 단어 사전은 대부분 소문자 기준으로 구성되어 있습니다.
text = text.lower()
# 마침표와 쉼표 같은 간단한 문장부호를 공백으로 바꿉니다.
# 복잡한 전처리는 아니지만 기본 실습에서는 충분합니다.
for punctuation in [".", ",", "!", "?", ":", ";", "(", ")", "\"", "'"]:
text = text.replace(punctuation, " ")
# 공백을 기준으로 문장을 단어 리스트로 나눕니다.
words = text.split()
# 단어들을 IMDB 단어 번호로 변환할 리스트를 만듭니다.
encoded = []
# 단어를 하나씩 반복합니다.
for word in words:
# IMDB 데이터셋은 실제 단어 번호에 특수 토큰 오프셋 3을 더해 사용하는 구조입니다.
token_id = word_to_id.get(word, 2) + 3
# NUM_WORDS보다 작은 번호만 사용합니다.
# 학습 때 상위 NUM_WORDS개 단어만 사용했기 때문입니다.
if token_id < NUM_WORDS:
encoded.append(token_id)
else:
# 사전에 없거나 너무 드문 단어는 2번 토큰으로 처리합니다.
# 일반적으로 2는 unknown에 가까운 의미로 사용됩니다.
encoded.append(2)
# pad_sequences로 길이를 max_len에 맞춥니다.
encoded_padded = pad_sequences(
[encoded], # pad_sequences는 여러 문장 목록을 입력으로 받으므로 리스트로 감쌉니다.
maxlen=max_len, # 모델 입력 길이와 같은 길이로 맞춥니다.
truncating="post", # 긴 문장은 뒤쪽을 자릅니다.
padding="post" # 짧은 문장은 뒤쪽에 0을 채웁니다.
)
# TensorFlow Embedding 계층 입력에 적합하도록 int32로 변환합니다.
return encoded_padded.astype("int32")
# 직접 예측할 긍정 리뷰 예시입니다.
custom_review = "This movie was very good and I really enjoyed the story"
# 직접 작성한 문장을 숫자 시퀀스로 변환합니다.
custom_encoded = encode_custom_review(custom_review, word_to_id, MAX_LEN)
# 모델이 직접 작성한 문장의 긍정 확률을 예측합니다.
custom_prob = model.predict(custom_encoded, verbose=0)[0, 0]
# 0.5 기준으로 최종 클래스를 결정합니다.
custom_pred = 1 if custom_prob >= 0.5 else 0
# 입력 문장을 출력합니다.
print("입력 문장:", custom_review)
# 긍정 확률을 출력합니다.
print(f"긍정 확률: {custom_prob:.4f}")
# 최종 예측 결과를 출력합니다.
print("예측 결과:", custom_pred, "(0=부정, 1=긍정)")
마찬가지로 모델을 저장해보자.
model.save(), tensorflow는 .keras 형태로 저장할 수 있다.
불러올때는 keras.models.load_model()을 사용한다 .
# 모델을 저장할 파일 이름을 지정합니다.
# .keras는 TensorFlow/Keras에서 권장하는 최신 모델 저장 형식입니다.
MODEL_PATH = "imdb_sentiment_lstm_adamw.keras"
# 학습된 모델 전체를 저장합니다.
# 모델 구조와 학습된 가중치가 함께 저장됩니다.
model.save(MODEL_PATH)
# 모델 저장 완료 메시지를 출력합니다.
print("모델 저장 완료:", MODEL_PATH)
# 저장된 모델을 다시 불러옵니다.
# custom_objects 없이도 기본 Keras 계층과 AdamW는 일반적으로 정상적으로 불러올 수 있습니다.
loaded_model = keras.models.load_model(MODEL_PATH)
# 모델 불러오기 완료 메시지를 출력합니다.
print("모델 불러오기 완료")
# 불러온 모델로 샘플 하나를 다시 예측하여 정상 작동 여부를 확인합니다.
loaded_sample_prob = loaded_model.predict(sample_text, verbose=0)[0, 0]
# 불러온 모델의 예측 확률을 출력합니다.
print(f"불러온 모델의 샘플 긍정 확률: {loaded_sample_prob:.4f}")
앞서 gen에 대해 알아봤었다 마치 포토샵과같은 능력을 가졌는데 코드로 한번 확인해보자 . dc_gan_MNIST_pytorch.ipynb
https://standout.tistory.com/1791
상대적 적대신경망 GAN게임 & 순환 일관성이 보장되는 포토샵신경망 사이클 GAN
앞서 resNet은 출력을 처음부터 만드는게 아닌 입력에서 얼마나 수정할지만 학습하는 잔차학습이라했다 .https://standout.tistory.com/1773 ResNet, 역전파를 그대로 사용하되 Residual Connection을 추가한 CNNResN
standout.tistory.com
import
torchvision.datasets에 MNIST 데이터셋을 제공한다 .
torchvision.transforms 이미지 전처리 기능을 제공한다.
torchvision..utrils 이미지 그리드 저장과 시각화에 사용한다.
# PyTorch의 핵심 패키지입니다.
# 텐서 연산, GPU 연산, 딥러닝 모델 학습에 사용합니다.
import torch
# torch.nn은 신경망 계층, 활성화 함수, 손실함수 등을 제공합니다.
import torch.nn as nn
# torch.optim은 Adam, AdamW, SGD 같은 최적화 알고리즘을 제공합니다.
import torch.optim as optim
# DataLoader는 데이터를 미니배치 단위로 나누어 모델에 공급합니다.
from torch.utils.data import DataLoader
# torchvision.datasets는 MNIST 같은 이미지 데이터셋을 제공합니다.
from torchvision.datasets import MNIST
# torchvision.transforms는 이미지 전처리 기능을 제공합니다.
import torchvision.transforms as transforms
# torchvision.utils는 이미지 그리드 저장과 시각화에 사용합니다.
import torchvision.utils as vutils
# matplotlib은 생성된 이미지를 화면에 출력하는 데 사용합니다.
import matplotlib.pyplot as plt
# os는 폴더 생성과 파일 경로 처리에 사용합니다.
import os
# glob은 특정 패턴에 맞는 파일을 찾는 데 사용합니다.
import glob
# time은 학습 시간을 측정하는 데 사용합니다.
from time import time
# PyTorch 버전을 출력합니다.
print("PyTorch version:", torch.__version__)
# CUDA 사용 가능 여부를 출력합니다.
print("CUDA available:", torch.cuda.is_available())
파라미터 설정
이때 기존 출력 이미지를 제거해 새 학습 결과만 남기도록 설정한다.
# 실험 결과를 최대한 재현 가능하게 만들기 위해 난수 시드를 고정합니다.
SEED = 1234
# CPU 연산의 난수 시드를 고정합니다.
torch.manual_seed(SEED)
# GPU가 있는 경우 GPU 난수 시드도 고정합니다.
torch.cuda.manual_seed_all(SEED)
# 전체 학습 반복 횟수입니다.
# 실습에서는 5 정도로 시작하고, 더 좋은 이미지를 얻으려면 20 이상으로 늘릴 수 있습니다.
EPOCHS = 5
# 한 번에 학습할 이미지 개수입니다.
# 너무 크면 메모리를 많이 사용하고, 너무 작으면 학습이 불안정할 수 있습니다.
BATCH_SIZE = 128
# 생성자에 입력할 노이즈 벡터의 차원입니다.
# 생성자는 이 노이즈를 바탕으로 이미지를 만듭니다.
NOISE_DIM = 100
# MNIST 이미지는 흑백 이미지이므로 채널 수는 1입니다.
IMAGE_CHANNELS = 1
# 생성할 이미지 크기입니다.
# MNIST는 28x28 이미지입니다.
IMAGE_SIZE = 28
# Adam 최적화 알고리즘의 학습률입니다.
LEARNING_RATE = 0.0002
# Adam 최적화 알고리즘의 beta1 값입니다.
# DC-GAN에서는 0.5를 자주 사용합니다.
BETA1 = 0.5
# 학습 결과 이미지를 저장할 폴더입니다.
OUTPUT_DIR = "dcgan_output"
# 출력 폴더를 생성합니다.
os.makedirs(OUTPUT_DIR, exist_ok=True)
# 기존 출력 이미지를 삭제하여 새 학습 결과만 남깁니다.
for file_path in glob.glob(os.path.join(OUTPUT_DIR, "*.png")):
# 기존 PNG 파일을 삭제합니다.
os.remove(file_path)
# GPU가 가능하면 GPU를 사용하고, 그렇지 않으면 CPU를 사용합니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 현재 사용할 장치를 출력합니다.
print("사용 장치:", device)
데이터준비.
transforms.Compose([]) 전처리 규칙을 정의한다.
이미지를 ToTensor(), Normalize(maen = 0.5, std = 0.5)로 픽셀 범위를 정규화할것이다.
데이터셋 생성, dataloader 생성.
# MNIST 이미지에 적용할 전처리 규칙을 정의합니다.
transform = transforms.Compose([
# PIL 이미지를 PyTorch 텐서로 변환합니다.
transforms.ToTensor(),
# 이미지 픽셀 범위를 [0, 1]에서 [-1, 1]로 변환합니다.
transforms.Normalize(mean=(0.5,), std=(0.5,))
])
# MNIST 학습 데이터셋을 생성합니다.
train_dataset = MNIST(
root="./mnist", # 데이터셋 저장 위치입니다.
train=True, # 학습용 데이터를 사용합니다.
download=True, # 데이터가 없으면 자동으로 다운로드합니다.
transform=transform # 위에서 정의한 전처리를 적용합니다.
)
# 학습용 DataLoader를 생성합니다.
train_loader = DataLoader(
dataset=train_dataset, # 사용할 데이터셋입니다.
batch_size=BATCH_SIZE, # 한 배치에 포함할 이미지 개수입니다.
shuffle=True, # 매 에포크마다 데이터를 섞습니다.
num_workers=0, # Windows와 Colab에서 안전하게 동작하도록 0으로 둡니다.
pin_memory=torch.cuda.is_available() # GPU 사용 시 데이터 전송 효율을 높입니다.
)
# 학습 데이터 개수를 출력합니다.
print("학습 데이터 개수:", len(train_dataset))
# 첫 번째 배치를 가져옵니다.
real_images, _ = next(iter(train_loader))
# 첫 번째 배치의 이미지 모양을 출력합니다.
print("배치 이미지 모양:", real_images.shape)
정규화된 이미지를 화면에서 보기위해서 0, 1 범위로 되돌리는 함수를 설정한다.
vutils.make_grid() 여러 이미지를 하나의 격자 이미지로 합친다.
grid.permute() 이미지 형식을 matplotlib 형식으로 바꾼다. 순서를 바꿔준것. 채널, 높이, 너비를 높이, 너비 채널로.
plt설정
출력
# 정규화된 이미지를 화면에 보기 위해 [0, 1] 범위로 되돌리는 함수입니다.
def show_image_grid(images, title="Image Grid"):
# 이미지 텐서를 CPU로 이동합니다.
images = images.detach().cpu()
# 여러 이미지를 하나의 격자 이미지로 합칩니다.
grid = vutils.make_grid(images[:25], nrow=5, normalize=True)
# PyTorch 이미지 형식 [채널, 높이, 너비]를 matplotlib 형식 [높이, 너비, 채널]로 바꿉니다.
np_grid = grid.permute(1, 2, 0).numpy()
# 그림 크기를 지정합니다.
plt.figure(figsize=(6, 6))
# 이미지를 출력합니다.
plt.imshow(np_grid)
# 제목을 표시합니다.
plt.title(title)
# 축 눈금을 숨깁니다.
plt.axis("off")
# 이미지를 화면에 표시합니다.
plt.show()
# 실제 MNIST 이미지 일부를 출력합니다.
show_image_grid(real_images, title="Real MNIST Images")
생성자 모델을 설계하자. Generator()
nn.module을 매개변수로 nn.Sequential 순차적으로 수행한다.
nn.ConvTranspose2d() 전치합성곱, GAN 생성자에서 작은 노이즈를 큰 이미지로 키울때 사용한다. conv가 이미지를 줄이는 연산이라면 convtranspose는 이미지를 키우는 연산. 100채널을 256 개의 특징 채널로 확장한다.
kernel_size() 필터 7개.
stride = 1 한칸씩 이동하겠다. 이동간격으로 1일수록 천천히, 정밀하게한다 .
padding 테두리 추가업음
배치로 256개를 받아 정규화한다. gan은 생성자와 판별자의 경쟁으로 학습이 매우 불안정해 gradient 흔들림이 크기 때문에 batchnorn을 사용한다.
relu 비선형성 추가
nn.conv2 feature는 줄이고 해상도를 2배 즐가시킨다 . 더 구체적으로 구조를 생성한다는 의미
nn.Tanh()로 출력값을 -1, 1로 제한했다. 입력 이미지들이 정규화됬기때문에 출력도 맞춰야 학습이 안정화되기때문이다.
forward 순전파 과정. 감별자에게 return한다.
# DC-GAN 생성자 모델을 정의합니다.
class Generator(nn.Module):
# 생성자에서 사용할 계층을 초기화합니다.
def __init__(self, noise_dim=100, image_channels=1):
# 부모 클래스 nn.Module의 초기화 메서드를 실행합니다.
super().__init__()
# 생성자는 ConvTranspose2d를 사용해 작은 노이즈를 큰 이미지로 확대합니다.
self.net = nn.Sequential(
# 입력 노이즈 [B, 100, 1, 1]을 [B, 256, 7, 7] 특징맵으로 확장합니다.
nn.ConvTranspose2d(
in_channels=noise_dim,
out_channels=256,
kernel_size=7,
stride=1,
padding=0,
bias=False
),
# 256개 특징맵의 분포를 안정화합니다.
nn.BatchNorm2d(256),
# 음수는 0으로 만들고 양수는 통과시켜 비선형성을 추가합니다.
nn.ReLU(inplace=True),
# [B, 256, 7, 7]을 [B, 128, 14, 14]로 확대합니다.
nn.ConvTranspose2d(
in_channels=256,
out_channels=128,
kernel_size=4,
stride=2,
padding=1,
bias=False
),
# 128개 특징맵의 분포를 안정화합니다.
nn.BatchNorm2d(128),
# 비선형성을 추가합니다.
nn.ReLU(inplace=True),
# [B, 128, 14, 14]를 [B, 64, 28, 28]로 확대합니다.
nn.ConvTranspose2d(
in_channels=128,
out_channels=64,
kernel_size=4,
stride=2,
padding=1,
bias=False
),
# 64개 특징맵의 분포를 안정화합니다.
nn.BatchNorm2d(64),
# 비선형성을 추가합니다.
nn.ReLU(inplace=True),
# [B, 64, 28, 28]을 [B, 1, 28, 28] 이미지로 변환합니다.
nn.Conv2d(
in_channels=64,
out_channels=image_channels,
kernel_size=3,
stride=1,
padding=1,
bias=False
),
# 출력 픽셀 범위를 [-1, 1]로 맞춥니다.
nn.Tanh()
)
# 생성자의 순전파 과정을 정의합니다.
def forward(self, z):
# 노이즈 z를 생성자 네트워크에 통과시켜 가짜 이미지를 생성합니다.
return self.net(z)
이번에는 감별자 모델을 정의해보자.
nn.sequential 순차적 실행
nn.conv2d 특징맵으로 압축
gan 감별자에서는 relu보다 leakrelu를 많이 사용한다 .
nn.conv2d 다시 압축
nn.batchnorm2d() 특징맵의 분포를 안정화한다.
nn.leakrelu 통과.
다시 nn.conv2d, batchnorm2d, 다시 conv2d()
forward, out.view(-1)로 텐서모양을 1차원으로 펼쳐 손실함수에 맞춘다.
# DC-GAN 감별자 모델을 정의합니다.
class Discriminator(nn.Module):
# 감별자에서 사용할 계층을 초기화합니다.
def __init__(self, image_channels=1):
# 부모 클래스 nn.Module의 초기화 메서드를 실행합니다.
super().__init__()
# 감별자는 Conv2d를 사용해 이미지를 점점 작은 특징맵으로 압축합니다.
self.net = nn.Sequential(
# 입력 이미지 [B, 1, 28, 28]을 [B, 64, 14, 14] 특징맵으로 변환합니다.
nn.Conv2d(
in_channels=image_channels,
out_channels=64,
kernel_size=4,
stride=2,
padding=1,
bias=False
),
# GAN 감별자에서는 ReLU보다 LeakyReLU를 자주 사용합니다.
nn.LeakyReLU(negative_slope=0.2, inplace=True),
# [B, 64, 14, 14]를 [B, 128, 7, 7]로 압축합니다.
nn.Conv2d(
in_channels=64,
out_channels=128,
kernel_size=4,
stride=2,
padding=1,
bias=False
),
# 128개 특징맵의 분포를 안정화합니다.
nn.BatchNorm2d(128),
# 음수도 일부 통과시켜 기울기 소실을 줄입니다.
nn.LeakyReLU(negative_slope=0.2, inplace=True),
# [B, 128, 7, 7]을 [B, 256, 4, 4]로 변환합니다.
nn.Conv2d(
in_channels=128,
out_channels=256,
kernel_size=3,
stride=2,
padding=1,
bias=False
),
# 256개 특징맵의 분포를 안정화합니다.
nn.BatchNorm2d(256),
# 비선형성을 추가합니다.
nn.LeakyReLU(negative_slope=0.2, inplace=True),
# [B, 256, 4, 4]를 [B, 1, 1, 1]로 변환하여 최종 logit을 만듭니다.
nn.Conv2d(
in_channels=256,
out_channels=1,
kernel_size=4,
stride=1,
padding=0,
bias=False
)
)
# 감별자의 순전파 과정을 정의합니다.
def forward(self, x):
# 이미지를 감별자 네트워크에 통과시켜 logit을 계산합니다.
out = self.net(x)
# 출력 모양 [B, 1, 1, 1]을 [B]로 펼쳐 손실함수와 비교하기 쉽게 만듭니다.
return out.view(-1)
가중치 초기화 함수정의.
conv 계층 초기화, batchnorm 가중치와 평향 초기화.
생성자, 감별자 객체 생성
ㅅㅐㅇ성자, 감별자 가중치 초기화
더미 노이즈 생성해 테스트
# DC-GAN 논문에서 자주 사용하는 가중치 초기화 함수를 정의합니다.
def weights_init(module):
# 현재 계층의 클래스 이름을 문자열로 가져옵니다.
classname = module.__class__.__name__
# 합성곱 계층이면 정규분포로 가중치를 초기화합니다.
if classname.find("Conv") != -1:
# 평균 0, 표준편차 0.02의 정규분포로 가중치를 초기화합니다.
nn.init.normal_(module.weight.data, 0.0, 0.02)
# 배치 정규화 계층이면 가중치와 편향을 초기화합니다.
elif classname.find("BatchNorm") != -1:
# 배치 정규화의 scale 파라미터를 평균 1, 표준편차 0.02로 초기화합니다.
nn.init.normal_(module.weight.data, 1.0, 0.02)
# 배치 정규화의 bias 파라미터를 0으로 초기화합니다.
nn.init.constant_(module.bias.data, 0)
# 생성자 객체를 생성합니다.
generator = Generator(NOISE_DIM, IMAGE_CHANNELS).to(device)
# 감별자 객체를 생성합니다.
discriminator = Discriminator(IMAGE_CHANNELS).to(device)
# 생성자 가중치를 초기화합니다.
generator.apply(weights_init)
# 감별자 가중치를 초기화합니다.
discriminator.apply(weights_init)
# 생성자 구조를 출력합니다.
print(generator)
# 감별자 구조를 출력합니다.
print(discriminator)
# 더미 노이즈를 생성합니다.
dummy_noise = torch.randn(4, NOISE_DIM, 1, 1).to(device)
# 더미 이미지 생성을 테스트합니다.
with torch.no_grad():
dummy_fake = generator(dummy_noise)
dummy_score = discriminator(dummy_fake)
# 생성자 출력 모양을 출력합니다.
print("생성자 출력 모양:", dummy_fake.shape)
# 감별자 출력 모양을 출력합니다.
print("감별자 출력 모양:", dummy_score.shape)
최적화알고리즘 설정
criterion nn.BECEWidhLogitsLoss()
# BCEWithLogitsLoss는 감별자의 logit 출력과 정답 라벨을 비교합니다.
criterion = nn.BCEWithLogitsLoss()
# 생성자 전용 Adam 최적화 알고리즘을 생성합니다.
g_optimizer = optim.Adam(
generator.parameters(), # 생성자의 파라미터를 업데이트 대상으로 지정합니다.
lr=LEARNING_RATE, # 생성자 학습률을 지정합니다.
betas=(BETA1, 0.999) # DC-GAN에서 자주 사용하는 Adam beta 값을 지정합니다.
)
# 감별자 전용 Adam 최적화 알고리즘을 생성합니다.
d_optimizer = optim.Adam(
discriminator.parameters(), # 감별자의 파라미터를 업데이트 대상으로 지정합니다.
lr=LEARNING_RATE, # 감별자 학습률을 지정합니다.
betas=(BETA1, 0.999) # DC-GAN에서 자주 사용하는 Adam beta 값을 지정합니다.
)
# 생성 이미지 변화를 비교하기 위해 고정 노이즈를 생성합니다.
fixed_noise = torch.randn(25, NOISE_DIM, 1, 1, device=device)
생성이미지를 저장하고 출력하는 함수 정의
vutils.save_image(),
# 생성 이미지를 저장하고 출력하는 함수를 정의합니다.
def save_generated_images(epoch, generator, fixed_noise, output_dir):
# 생성자를 평가 모드로 전환합니다.
generator.eval()
# 이미지 생성에는 기울기 계산이 필요 없으므로 no_grad를 사용합니다.
with torch.no_grad():
# 고정 노이즈로 가짜 이미지를 생성합니다.
fake_images = generator(fixed_noise).detach().cpu()
# 생성된 이미지를 PNG 파일로 저장할 경로를 만듭니다.
save_path = os.path.join(output_dir, f"epoch_{epoch:03d}.png")
# 생성된 이미지를 5x5 그리드로 저장합니다.
vutils.save_image(
fake_images, # 저장할 이미지 텐서입니다.
save_path, # 저장 경로입니다.
nrow=5, # 한 줄에 5개 이미지를 배치합니다.
normalize=True # [-1, 1] 이미지를 보기 좋게 [0, 1]로 변환합니다.
)
# 저장된 이미지를 화면에도 출력합니다.
show_image_grid(fake_images, title=f"Generated Images - Epoch {epoch}")
# 저장 경로를 반환합니다.
return save_path
GAN 학습 함수 정의 for문으로 epoch만큰 돌고있고 감별자 먼저 학습하고 다음 generator를 학습한다.
# GAN을 학습하는 함수를 정의합니다.
def train_gan(generator, discriminator, train_loader, criterion, g_optimizer, d_optimizer, epochs, device):
# 학습 시작 시간을 기록합니다.
start_time = time()
# 손실 기록을 저장할 리스트를 생성합니다.
g_losses = []
d_losses = []
# 지정한 에포크 수만큼 반복합니다.
for epoch in range(1, epochs + 1):
# 생성자를 학습 모드로 전환합니다.
generator.train()
# 감별자를 학습 모드로 전환합니다.
discriminator.train()
# 에포크 단위 생성자 손실 합계를 초기화합니다.
epoch_g_loss = 0.0
# 에포크 단위 감별자 손실 합계를 초기화합니다.
epoch_d_loss = 0.0
# 배치 개수를 초기화합니다.
batch_count = 0
# DataLoader에서 실제 이미지를 미니배치 단위로 가져옵니다.
for batch_idx, (real_images, _) in enumerate(train_loader):
# 실제 이미지를 학습 장치로 이동합니다.
real_images = real_images.to(device)
# 현재 배치 크기를 가져옵니다.
current_batch_size = real_images.size(0)
# 진짜 이미지의 정답 라벨을 1로 만듭니다.
real_labels = torch.ones(current_batch_size, device=device)
# 가짜 이미지의 정답 라벨을 0으로 만듭니다.
fake_labels = torch.zeros(current_batch_size, device=device)
# =========================
# 1단계: 감별자 학습
# =========================
# 감별자 기울기를 초기화합니다.
d_optimizer.zero_grad(set_to_none=True)
# 감별자가 진짜 이미지를 보고 출력한 logit을 계산합니다.
real_logits = discriminator(real_images)
# 진짜 이미지를 진짜로 맞히는 손실을 계산합니다.
d_real_loss = criterion(real_logits, real_labels)
# 생성자 입력용 무작위 노이즈를 생성합니다.
noise = torch.randn(current_batch_size, NOISE_DIM, 1, 1, device=device)
# 생성자가 가짜 이미지를 만듭니다.
fake_images = generator(noise)
# 감별자가 가짜 이미지를 보고 출력한 logit을 계산합니다.
# detach()를 사용하여 감별자 학습 중 생성자 가중치는 업데이트되지 않게 합니다.
fake_logits = discriminator(fake_images.detach())
# 가짜 이미지를 가짜로 맞히는 손실을 계산합니다.
d_fake_loss = criterion(fake_logits, fake_labels)
# 감별자의 전체 손실은 진짜 손실과 가짜 손실의 합입니다.
d_loss = d_real_loss + d_fake_loss
# 감별자 손실을 기준으로 역전파를 수행합니다.
d_loss.backward()
# 감별자 파라미터를 업데이트합니다.
d_optimizer.step()
# =========================
# 2단계: 생성자 학습
# =========================
# 생성자 기울기를 초기화합니다.
g_optimizer.zero_grad(set_to_none=True)
# 생성자가 만든 가짜 이미지를 감별자에 다시 넣습니다.
gen_logits = discriminator(fake_images)
# 생성자는 가짜 이미지를 진짜로 판별받는 것이 목표이므로 라벨을 1로 둡니다.
g_loss = criterion(gen_logits, real_labels)
# 생성자 손실을 기준으로 역전파를 수행합니다.
g_loss.backward()
# 생성자 파라미터를 업데이트합니다.
g_optimizer.step()
# 현재 배치의 생성자 손실을 누적합니다.
epoch_g_loss += g_loss.item()
# 현재 배치의 감별자 손실을 누적합니다.
epoch_d_loss += d_loss.item()
# 배치 개수를 증가시킵니다.
batch_count += 1
# 일정 배치마다 학습 상태를 출력합니다.
if (batch_idx + 1) % 100 == 0:
print(
f"Epoch [{epoch}/{epochs}] "
f"Batch [{batch_idx + 1}/{len(train_loader)}] "
f"D Loss: {d_loss.item():.4f} "
f"G Loss: {g_loss.item():.4f}"
)
# 에포크 평균 생성자 손실을 계산합니다.
avg_g_loss = epoch_g_loss / batch_count
# 에포크 평균 감별자 손실을 계산합니다.
avg_d_loss = epoch_d_loss / batch_count
# 평균 생성자 손실을 기록합니다.
g_losses.append(avg_g_loss)
# 평균 감별자 손실을 기록합니다.
d_losses.append(avg_d_loss)
# 에포크 결과를 출력합니다.
print(f"\nEpoch {epoch}/{epochs} 완료 | D Loss: {avg_d_loss:.4f} | G Loss: {avg_g_loss:.4f}")
# 현재 에포크의 생성 이미지를 저장하고 출력합니다.
save_path = save_generated_images(epoch, generator, fixed_noise, OUTPUT_DIR)
# 저장 경로를 출력합니다.
print("생성 이미지 저장:", save_path)
# 학습 종료 시간을 기록합니다.
end_time = time()
# 전체 학습 시간을 출력합니다.
print(f"\n총 학습 시간: {end_time - start_time:.1f}초")
# 손실 기록을 반환합니다.
return g_losses, d_losses
학습실행
train_gain() 점점 숫자가 깨끗해지는지를 확인해보자.
# GAN 학습을 실행합니다.
g_losses, d_losses = train_gan(
generator=generator, # 학습할 생성자입니다.
discriminator=discriminator, # 학습할 감별자입니다.
train_loader=train_loader, # MNIST 학습 데이터 로더입니다.
criterion=criterion, # 손실함수입니다.
g_optimizer=g_optimizer, # 생성자 최적화 알고리즘입니다.
d_optimizer=d_optimizer, # 감별자 최적화 알고리즘입니다.
epochs=EPOCHS, # 학습 에포크 수입니다.
device=device # 학습 장치입니다.
)

위 손실 그래프 확인
# 에포크 번호를 생성합니다.
epochs_range = range(1, EPOCHS + 1)
# 손실 그래프를 그릴 그림을 생성합니다.
plt.figure(figsize=(8, 5))
# 생성자 손실 그래프를 그립니다.
plt.plot(epochs_range, g_losses, marker="o", label="Generator Loss")
# 감별자 손실 그래프를 그립니다.
plt.plot(epochs_range, d_losses, marker="o", label="Discriminator Loss")
# 그래프 제목을 지정합니다.
plt.title("DC-GAN Loss Curve")
# x축 이름을 지정합니다.
plt.xlabel("Epoch")
# y축 이름을 지정합니다.
plt.ylabel("Loss")
# 범례를 표시합니다.
plt.legend()
# 격자를 표시합니다.
plt.grid(True)
# 그래프를 출력합니다.
plt.show()
새로운 무작위 노이즈를 넣어 재 생성해보자.
# 생성할 이미지 개수를 지정합니다.
num_generate = 25
# 새로운 무작위 노이즈를 생성합니다.
new_noise = torch.randn(num_generate, NOISE_DIM, 1, 1, device=device)
# 생성자를 평가 모드로 전환합니다.
generator.eval()
# 이미지 생성에는 기울기 계산이 필요 없으므로 no_grad를 사용합니다.
with torch.no_grad():
# 새로운 노이즈로 가짜 이미지를 생성합니다.
generated_images = generator(new_noise)
# 생성된 이미지를 화면에 출력합니다.
show_image_grid(generated_images, title="New Generated Images")
마찬가지로 저장하고 불러와보자 .
# 생성자 가중치를 저장할 파일 이름입니다.
GENERATOR_PATH = "dcgan_generator.pth"
# 감별자 가중치를 저장할 파일 이름입니다.
DISCRIMINATOR_PATH = "dcgan_discriminator.pth"
# 생성자 가중치를 저장합니다.
torch.save(generator.state_dict(), GENERATOR_PATH)
# 감별자 가중치를 저장합니다.
torch.save(discriminator.state_dict(), DISCRIMINATOR_PATH)
# 저장 완료 메시지를 출력합니다.
print("생성자 저장 완료:", GENERATOR_PATH)
# 저장 완료 메시지를 출력합니다.
print("감별자 저장 완료:", DISCRIMINATOR_PATH)
# 같은 구조의 새 생성자 모델을 생성합니다.
loaded_generator = Generator(NOISE_DIM, IMAGE_CHANNELS).to(device)
# 저장된 생성자 가중치를 불러옵니다.
loaded_generator.load_state_dict(torch.load(GENERATOR_PATH, map_location=device))
# 불러온 생성자를 평가 모드로 전환합니다.
loaded_generator.eval()
# 불러오기 완료 메시지를 출력합니다.
print("생성자 모델 불러오기 완료")'Personal > SK 네트웍스 AI 캠프' 카테고리의 다른 글
| [SK네트웍스 Family AI 캠프] 32기 7주차 회고: Day24 ~ Day26 (0) | 2026.06.15 |
|---|---|
| SK 네트웍스 AI 캠프 - 3_딥러닝 - Day27_딥러닝 모델 저장 및 활용 (0) | 2026.06.15 |
| SK 네트웍스 AI 캠프 - 3_딥러닝 - Day26_딥러닝 네트워크 신경망 알고리즘 계층 (1) | 2026.06.14 |
| SK 네트웍스 AI 캠프 - 3_딥러닝 - Day25_딥러닝 네트워크 신경망 알고리즘 계층 구조 (0) | 2026.06.12 |
| SK 네트웍스 AI 캠프 - 3 _딥러닝 - Day24_딥러닝개념_프레임워크설치 (0) | 2026.06.08 |



