딥러닝 오버피팅 방지기법
실무에서는 하나의 방법만 쓰기보다 여러 방법을 함께 사용하며
이미지분류시는 보통 데이터증강 + 전이학습 + weightdecay + Earlystopping을쓰고
일반적으로는 Dropout + Batchnorm + weight decay + early stopping을 쓴다 .
데이터가 적은 경우에는 우선 데이터증강 - 전이학습 - 모델크기줄이기 - dropout 추가 - weight decay - early stopping 순으로 적용해보는것이 좋다 .
| Underfitting (언더피팅) |
모델이 학습 부족 | - 훈련 정확도 낮음 - 검증 정확도도 낮음 |
모델 복잡도 증가 | 모델이 데이터 패턴을 충분히 학습하지 못한 상태 |
| 데이터 추가 | 학습 정보 부족 보완 | |||
| 학습 시간 증가 | epoch 부족 해결 |
| Overfitting (오버피팅) |
훈련 데이터에 과적합 | - 훈련 정확도 매우 높음 - 검증 정확도 낮음 |
Dropout nn.Dropout() | 일부 뉴런을 랜덤 제거해 일반화 강화 |
| Data Augmentation ImageDataGenerator | 데이터 다양성 증가 | |||
| Early Stopping EarlyStopping() | 검증 성능 나빠지면 학습 중단 | |||
| Weight Decay (L2 규제) | 큰 가중치 패널티 부여 | |||
| Batch Normalization BatchNorm1d/2d | 학습 안정화 + 일반화 도움 | |||
| 모델 단순화 | 파라미터 감소 | |||
| 데이터 추가 | 과적합 완화 | |||
| 전이학습 (Transfer Learning) | 사전학습 모델 활용 | |||
| 교차검증 KFold() | 일반화 성능 평가 안정화 | |||
| Label Smoothing (CrossEntropyLoss(label_smoothing=)) | 정답 확신 줄여 과적합 방지 |
https://standout.tistory.com/1813
모델이 학습이 덜됬거나 과하게 됬거나: Underfitting (언더피팅), Overfitting (오버피팅)
Underfitting (언더피팅)모델이 충분히 학습되지않은 상태,아직 덜 배운상태.모델이 너무 단순하거나 학습이 부족하거나 특징이 부족할 수있다. 학습이 부족해서 발생한 언더피팅 → 더 학습하면
standout.tistory.com
최적모델 학습
일반화성능이 가장 뫂은 모델을 만드는 과정을 의미한다. 학습데이터에서, 검증데이터에서, 새로운 데이터에서 높은 정확도를 만드는 것이다 .
최적모델은 언더피팅과 오버피팅 중간지점에 존재한다 .
최적모델의 조건
1. 낮은 손실값 loss function 예측 오차가 적어야한다.
2. 높은 정확도
3. 일반화성능, 학습/검증 데이터에서 모두 정확도가 높아야한다는 의미
최적모델 학습 절차를 확인하자.
1. 데이터수집
좋은 데이터가 좋은 모델을 만든다.
대표적인 데이터셋은 이미지엔 MNIST, CIFAR-10, ImageNet
텍스트로는 IMDB, 시계열데이터로는 Airline Passenger가있다.
2. 데이터탐색
데이터 특성을 확인한다. 결측치, 이상치, 데이터분포, 클래스 불균형등을 확인한다 .
df.info()
df.describe()
df.isnull().sum()
3. 데이터 탐색 결과로 데이터 전처리를 수행한다.
정규화, 표준화..
https://standout.tistory.com/1772
머신러닝/딥러닝에서의 활성화/데이터전처리, 데이터 전처리에서 정규화(스케일링) 여러가지 방
문득 머신러닝/딥러닝을 공부하는데아래의 내용이 반복해서 나오기 시작했다. 뭔가 정리가 필요하다 .0~1 사이 숫자확률정규화스케일링SigmoidSoftmaxMinMaxScaler 활성화함수. Softmax, Sigmoid출력값을 특
standout.tistory.com
4. 데이터를 분할
보통 train 70%, 검증 15%, test 15%로 하거나
train 80%, 검증 10%, test 10%으로 한다 .
5. 모델설계
입려층, 은닉층, 출력증 구성으로 수행한다 .
nn.Sequential(
nn.Linear(784,256),
nn.ReLU(),
nn.Linear(256,128),
nn.ReLU(),
nn.Linear(128,10)
)
6. 손실함수를 선택한다.
모델이 얼마나 틀렸는지를 확인해야한다 .
회귀에서는 MSE, MAE
분류문제에서는 Binary Cross Entrorpy, Cross entropy..
https://standout.tistory.com/1806
손실함수 종류 loss, criterion: BCEWithLogitsLoss CrossEntropyLoss BCEWithLogitsLoss MSELoss HuberLoss
손실 함수모델이 얼마나 틀렸는지 계산하는 함수이진분류MLP, CNN, LSTMBCEWithLogitsLoss다중분류MLP, CNN, LSTMCrossEntropyLoss다중라벨분류MLP, CNN, LSTMBCEWithLogitsLoss회귀MLP, LSTMMSELoss이상치 있는 회귀MLP, LSTMHub
standout.tistory.com
7. 최적화 알고리즘을 선택한다 .
단순하고 느리지만 기본적인 SGD
관성을 적용해 수렴속도가 향상되는 Momemtum
학습률을 자동으로 조절해주는 RmsProp
가장 많이 사용하는 Adam Dasmw
https://standout.tistory.com/1805
최적화 알고리즘, 최적화 함수: optimizer 종류 SGD, NAG, Momentum, Adagrad, RMSprop, Adam, AdamW
optimizer는 loss를 줄이기 위해 가중치를 어떻게 업데이트 할것인가를 결정하는 알고리즘SGD가장 기본낮음NAG MomentumSGD 개선보통Adagrad희소 데이터에 강함낮음RMSpropRNN 학습에 사용보통Adam범용적으로
standout.tistory.com
8. 하리퍼파라미터 최적화
하이퍼 파라미터를 최적화시킨다.
leaning rate 너무 작은 경우 학습이 느리고 너무 큰경우는 발산되니 일반적으로 0.001로 시작한다.
batch size 일반적은 32, 64, 128, 256 값을 사용한다 .
Epoch
dropput
weight decay ...
9. 오버피팅 방지
dropout을 사용해 뉴런을 제거하거나
batchnorm으로 학습 안정화시키거나
weight decay로 가중치 크기를 제한하거나
data augmentation으로 데이터를 회전 확대 축소 좌우반전시키거나
earuly stopping으로 검증 성능이 개선되지않으면 중단시킨다 .
https://standout.tistory.com/1813
모델이 학습이 덜됬거나 과하게 됬거나: Underfitting (언더피팅), Overfitting (오버피팅)
Underfitting (언더피팅)모델이 충분히 학습되지않은 상태,아직 덜 배운상태.모델이 너무 단순하거나 학습이 부족하거나 특징이 부족할 수있다. 학습이 부족해서 발생한 언더피팅 → 더 학습하면
standout.tistory.com
10. 모델 평가
accruacy 정확도,
precision 정밀도 ,
recal 재현율,
f1score precision과 recall의 평균
실무에서 가장 많이 사용하는 위 조합을 확인해보자 .
이미지 분류
ResNet50
+
AdamW
+
CrossEntropyLoss
+
BatchNorm
+
Dropout
Data Augmentation
+
EarlyStopping
텍스트 분류
BERT
+
AdamW
+
CrossEntropyLoss
+
Weight Decay
+
EarlyStopping
시계열 예측
LSTM
+
Adam
+
MSELoss
+
EarlyStopping
딥러닝 오버피팅 방지기법 실습을 위해 예시코들르 분석해보자. deep_learning_overfitting_prevention_torch.ipynb
import.,
torch.utils.data subset 데이터셋 일부만 선택할때
torch.utils.data random_split 데이터셋을 학습용과 검증요으로 나눌때
seed 고정 .
random.seed파이썬
np.random.seed numpy
torch.manual_seed cpu 연산 난수시드
torch.cuda.manual_seed_all gpu 연산 난수시드
# ============================================================
# 1. 기본 라이브러리 불러오기
# ============================================================
# PyTorch의 핵심 패키지를 불러옵니다.
# 텐서 생성, GPU 연산, 자동 미분 기능을 사용할 수 있습니다.
import torch
# torch.nn은 신경망 계층, 활성화 함수, 손실 함수 등을 제공합니다.
import torch.nn as nn
# torch.optim은 SGD, Adam, AdamW 같은 최적화 알고리즘을 제공합니다.
import torch.optim as optim
# DataLoader는 데이터를 미니배치 단위로 모델에 공급하는 도구입니다.
# Subset은 데이터셋 일부만 선택할 때 사용합니다.
# random_split은 데이터셋을 학습용과 검증용으로 나눌 때 사용합니다.
from torch.utils.data import DataLoader, Subset, random_split
# torchvision.datasets는 Fashion-MNIST 같은 예제 이미지 데이터셋을 제공합니다.
# torchvision.transforms는 이미지 전처리와 데이터 증강 기능을 제공합니다.
from torchvision import datasets, transforms
# numpy는 평균, 배열 처리 등 수치 계산을 위해 사용합니다.
import numpy as np
# matplotlib.pyplot은 학습 결과 그래프를 그리기 위해 사용합니다.
import matplotlib.pyplot as plt
# random은 파이썬 기본 난수 생성을 제어하기 위해 사용합니다.
import random
# ============================================================
# 2. 실험 결과를 최대한 일정하게 만들기 위한 시드 고정
# ============================================================
# SEED 값은 난수 생성의 시작점을 의미합니다.
# 같은 SEED를 사용하면 데이터 분할과 초기값이 비교적 일정하게 유지됩니다.
SEED = 42
# 파이썬 random 모듈의 난수 시드를 고정합니다.
random.seed(SEED)
# numpy 난수 시드를 고정합니다.
np.random.seed(SEED)
# PyTorch CPU 연산의 난수 시드를 고정합니다.
torch.manual_seed(SEED)
# PyTorch GPU 연산의 난수 시드를 고정합니다.
torch.cuda.manual_seed_all(SEED)
# GPU가 사용 가능하면 cuda를 사용하고, 그렇지 않으면 cpu를 사용합니다.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 현재 어떤 장치에서 학습하는지 출력합니다.
print('사용 장치:', device)
데이터준비
transforms.Compose()를 사용해 여러 전처리 작업을 순서대로 하도록 지시한다.
transforms.totensor. 텐서로 변환
transforms.normalize 평균과 표준편차를 정규화
데이터증강
transform.compose()를 사용해 여러 데이터증강 작업을 순서대로 하도록 지시한다.
transforms.randomrotation 이미지 회전
transforms.randomaffine 가로세로 무작위이동으로 위치변화가 덜 민감해지도록세팅.
transform.totensor 텐서로 변환
transform.normalize. 정규화
datasets.fasionMNIST 데이터를 생성해 base_transform에 트레인용, 테스트용 저장.
datasets.fasionMNIST 데이터를 생성해데이터 증강한용으로 저장.
전체 데이터중 range(3000) 3천개만 선택해 사용한다.
Subset으로 각 full_train_basic를 small_indices만큼, 증강데이터로 full_train_aug를 small_indices만큼 잘라 사용한다.
이중 train_size = 2400, val_size = 600로 지정해 학습용으론 2400, 검증용으로 600개를 사용한다. 이 데이터 분할을 할때 결과를 일정하게 만들기 위해 시드를 설정한다.
배치는 64.
train_loader_aug, test_loader, val_loader에 dataloader 설정.
# ============================================================
# 3. 기본 전처리 정의
# ============================================================
# transforms.Compose는 여러 전처리 작업을 순서대로 묶어줍니다.
basic_transform = transforms.Compose([
# 이미지를 PyTorch 텐서로 변환합니다.
# 픽셀값은 0~255 범위에서 0~1 범위로 자동 변환됩니다.
transforms.ToTensor(),
# 입력값을 평균 0.5, 표준편차 0.5 기준으로 정규화합니다.
# 0~1 범위의 픽셀값이 대략 -1~1 범위로 변환됩니다.
transforms.Normalize((0.5,), (0.5,))
])
# ============================================================
# 4. 데이터 증강 전처리 정의
# ============================================================
# 데이터 증강은 기존 이미지를 조금씩 변형하여 새로운 데이터처럼 사용하는 기법입니다.
aug_transform = transforms.Compose([
# 이미지를 -10도에서 +10도 사이로 무작위 회전합니다.
# 모델이 회전된 이미지에도 잘 대응하도록 돕습니다.
transforms.RandomRotation(degrees=10),
# 이미지를 가로/세로 방향으로 최대 10% 정도 무작위 이동합니다.
# 모델이 물체의 위치 변화에 덜 민감해지도록 합니다.
transforms.RandomAffine(degrees=0, translate=(0.1, 0.1)),
# 증강된 이미지를 PyTorch 텐서로 변환합니다.
transforms.ToTensor(),
# 증강된 이미지도 기본 데이터와 같은 방식으로 정규화합니다.
transforms.Normalize((0.5,), (0.5,))
])
# ============================================================
# 5. Fashion-MNIST 데이터셋 다운로드 및 생성
# ============================================================
# 기본 전처리만 적용한 학습 데이터셋을 생성합니다.
full_train_basic = datasets.FashionMNIST(
root='./data', # 데이터가 저장될 폴더입니다.
train=True, # 학습용 데이터를 불러옵니다.
download=True, # 데이터가 없으면 자동 다운로드합니다.
transform=basic_transform # 기본 전처리를 적용합니다.
)
# 데이터 증강 전처리를 적용한 학습 데이터셋을 생성합니다.
full_train_aug = datasets.FashionMNIST(
root='./data', # 데이터 저장 폴더입니다.
train=True, # 학습용 데이터를 불러옵니다.
download=True, # 데이터가 없으면 자동 다운로드합니다.
transform=aug_transform # 데이터 증강 전처리를 적용합니다.
)
# 테스트 데이터셋은 최종 평가용으로 사용합니다.
# 테스트 데이터에는 데이터 증강을 적용하지 않습니다.
test_dataset = datasets.FashionMNIST(
root='./data', # 데이터 저장 폴더입니다.
train=False, # 테스트용 데이터를 불러옵니다.
download=True, # 데이터가 없으면 자동 다운로드합니다.
transform=basic_transform # 평가 데이터에는 기본 전처리만 적용합니다.
)
# ============================================================
# 6. 일부 데이터만 사용하여 오버피팅 상황 만들기
# ============================================================
# 전체 60,000개 학습 데이터 중 앞쪽 3,000개만 선택합니다.
# 데이터 수를 줄이면 모델이 학습 데이터를 외우는 현상이 더 잘 보입니다.
small_indices = list(range(3000))
# 기본 전처리 데이터셋에서 3,000개만 선택합니다.
small_basic = Subset(full_train_basic, small_indices)
# 데이터 증강 데이터셋에서도 같은 개수만 선택합니다.
small_aug = Subset(full_train_aug, small_indices)
# 3,000개 중 2,400개는 학습용으로 사용합니다.
train_size = 2400
# 3,000개 중 600개는 검증용으로 사용합니다.
val_size = 600
# 데이터 분할 결과를 일정하게 만들기 위해 PyTorch Generator에 시드를 설정합니다.
generator = torch.Generator().manual_seed(SEED)
# 기본 데이터셋을 학습용과 검증용으로 나눕니다.
train_basic, val_basic = random_split(small_basic, [train_size, val_size], generator=generator)
# 데이터 증강 데이터셋도 학습용과 검증용으로 나눕니다.
generator = torch.Generator().manual_seed(SEED)
train_aug, val_aug = random_split(small_aug, [train_size, val_size], generator=generator)
# 한 번에 모델에 입력할 데이터 개수입니다.
BATCH_SIZE = 64
# 기본 학습 데이터를 미니배치 단위로 불러오는 DataLoader입니다.
train_loader_basic = DataLoader(train_basic, batch_size=BATCH_SIZE, shuffle=True)
# 데이터 증강 학습 데이터를 미니배치 단위로 불러오는 DataLoader입니다.
train_loader_aug = DataLoader(train_aug, batch_size=BATCH_SIZE, shuffle=True)
# 검증 데이터는 순서를 섞을 필요가 없으므로 shuffle=False로 설정합니다.
val_loader = DataLoader(val_basic, batch_size=BATCH_SIZE, shuffle=False)
# 테스트 데이터도 평가용이므로 shuffle=False로 설정합니다.
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
# 학습 데이터 개수를 출력합니다.
print('\n학습 데이터 수:', len(train_basic))
# 검증 데이터 개수를 출력합니다.
print('검증 데이터 수:', len(val_basic))
# 테스트 데이터 개수를 출력합니다.
print('테스트 데이터 수:', len(test_dataset))
앞서 데이터를 적게 제한했다.
이후 모델을 일부러 과하게만들어 오버피팅을 관찰해보자.
특징을 거의 1024개로 늘렸다.
이후 모델을 하나 더 생성해보자. 이때는 batchnorm, dropout, 을 사용해 보완했다. 특징도 256으로 줄였다 .
# ============================================================
# 7. 오버피팅 관찰용 복잡한 모델 정의
# ============================================================
# nn.Module을 상속하면 PyTorch 신경망 모델 클래스를 만들 수 있습니다.
class OverfitMLP(nn.Module):
# __init__ 메서드는 모델의 계층을 정의하는 부분입니다.
def __init__(self):
# 부모 클래스인 nn.Module의 초기화 기능을 실행합니다.
super().__init__()
# nn.Sequential은 여러 계층을 순서대로 실행하는 컨테이너입니다.
self.net = nn.Sequential(
# 28x28 이미지를 784개의 숫자로 펼칩니다.
nn.Flatten(),
# 입력 784개를 1024개 특징으로 변환합니다.
# 데이터가 적은 상황에서는 이렇게 큰 계층이 오버피팅을 유발할 수 있습니다.
nn.Linear(28 * 28, 1024),
# ReLU는 음수는 0으로, 양수는 그대로 통과시키는 활성화 함수입니다.
nn.ReLU(),
# 1024개 특징을 512개 특징으로 변환합니다.
nn.Linear(1024, 512),
# 두 번째 ReLU 활성화 함수입니다.
nn.ReLU(),
# 512개 특징을 256개 특징으로 변환합니다.
nn.Linear(512, 256),
# 세 번째 ReLU 활성화 함수입니다.
nn.ReLU(),
# 256개 특징을 최종 클래스 10개 점수로 변환합니다.
nn.Linear(256, 10)
)
# forward 메서드는 입력 데이터가 모델을 통과하는 계산 흐름을 정의합니다.
def forward(self, x):
# 입력 x를 self.net에 넣고 출력 결과를 반환합니다.
return self.net(x)
# ============================================================
# 8. 오버피팅 방지 기법 적용 모델 정의
# ============================================================
# 정규화 기법이 포함된 비교 모델입니다.
class RegularizedMLP(nn.Module):
# 모델 계층을 정의합니다.
def __init__(self):
# 부모 클래스 초기화입니다.
super().__init__()
# 여러 계층을 순서대로 실행하도록 정의합니다.
self.net = nn.Sequential(
# 이미지를 1차원 벡터로 펼칩니다.
nn.Flatten(),
# 복잡한 모델보다 작은 256개 은닉 뉴런을 사용합니다.
# 모델 단순화는 오버피팅을 줄이는 기본 방법입니다.
nn.Linear(28 * 28, 256),
# BatchNorm1d는 은닉층 출력 분포를 안정화합니다.
# 학습 안정화와 약한 정규화 효과를 기대할 수 있습니다.
nn.BatchNorm1d(256),
# ReLU 활성화 함수입니다.
nn.ReLU(),
# Dropout은 학습 중 일부 뉴런을 무작위로 끕니다.
# 특정 뉴런에만 의존하는 것을 막아 오버피팅을 줄입니다.
nn.Dropout(p=0.5),
# 256개 특징을 128개 특징으로 줄입니다.
nn.Linear(256, 128),
# 두 번째 배치 정규화입니다.
nn.BatchNorm1d(128),
# 두 번째 ReLU 활성화 함수입니다.
nn.ReLU(),
# 두 번째 Dropout입니다.
nn.Dropout(p=0.3),
# 최종 10개 클래스 점수를 출력합니다.
nn.Linear(128, 10)
)
# 입력 데이터의 순전파 과정을 정의합니다.
def forward(self, x):
# 입력 x를 네트워크에 통과시켜 예측 점수를 반환합니다.
return self.net(x)
학습 함수와 평가함수 정의
학습. zero_grad로 기울기 초기화, model(images) 예측점수 계산, criterion(outputs, labels) 예측점수와 정답라벨을 비교해 손실값 계산. loss.backward() 기울기계산 optimizer.step() 파라미터 업데이트, totalloss 구하기, torch.max() 점수가 가장 높은 클래스를 예측결과로 계산. torch.max()는 값과 인덱스를 반환한다. 변수에 파이썬에서 _는 '이 값은 사용하지않겠다'라는 관례적인 변수명이다 . 점수가 중요한것이 아니라 가장 큰 점수를 가진 클래스 번호가 중요하기 때문.
예측개수 누적, 라벨 개수 누적 , 평균 손실 계산, 정확도 계산 return.
# ============================================================
# 9. 한 epoch 동안 학습하는 함수 정의
# ============================================================
def train_one_epoch(model, loader, criterion, optimizer):
# 모델을 학습 모드로 전환합니다.
# Dropout과 BatchNorm은 학습 모드와 평가 모드에서 동작이 다릅니다.
model.train()
# 한 epoch 동안의 전체 손실 합계를 저장할 변수입니다.
total_loss = 0.0
# 맞게 예측한 데이터 개수를 저장할 변수입니다.
correct = 0
# 전체 데이터 개수를 저장할 변수입니다.
total = 0
# DataLoader에서 미니배치 단위로 이미지와 정답을 꺼냅니다.
for images, labels in loader:
# 이미지를 GPU 또는 CPU 장치로 이동합니다.
images = images.to(device)
# 정답 라벨도 같은 장치로 이동합니다.
labels = labels.to(device)
# 이전 미니배치에서 계산된 기울기를 초기화합니다.
optimizer.zero_grad()
# 모델에 이미지를 입력하여 예측 점수를 계산합니다.
outputs = model(images)
# 예측 점수와 정답 라벨을 비교하여 손실값을 계산합니다.
loss = criterion(outputs, labels)
# 손실값을 기준으로 각 파라미터의 기울기를 계산합니다.
loss.backward()
# 계산된 기울기를 사용하여 모델 파라미터를 업데이트합니다.
optimizer.step()
# 현재 미니배치 손실에 데이터 개수를 곱해 누적합니다.
total_loss += loss.item() * images.size(0)
# 가장 점수가 높은 클래스를 예측 결과로 선택합니다.
_, preds = torch.max(outputs, 1)
# 예측값과 정답이 같은 개수를 누적합니다.
correct += (preds == labels).sum().item()
# 전체 데이터 개수를 누적합니다.
total += labels.size(0)
# 평균 손실을 계산합니다.
avg_loss = total_loss / total
# 정확도를 계산합니다.
accuracy = correct / total
# 평균 손실과 정확도를 반환합니다.
return avg_loss, accuracy
# ============================================================
# 10. 검증 또는 테스트를 수행하는 함수 정의
# ============================================================
def evaluate(model, loader, criterion):
# 모델을 평가 모드로 전환합니다.
# 평가 모드에서는 Dropout이 꺼지고 BatchNorm은 저장된 통계를 사용합니다.
model.eval()
# 전체 손실 합계를 저장합니다.
total_loss = 0.0
# 맞게 예측한 개수를 저장합니다.
correct = 0
# 전체 데이터 개수를 저장합니다.
total = 0
# 평가 단계에서는 기울기 계산이 필요하지 않습니다.
# torch.no_grad()를 사용하면 메모리 사용량과 계산량이 줄어듭니다.
with torch.no_grad():
# DataLoader에서 미니배치를 하나씩 가져옵니다.
for images, labels in loader:
# 이미지를 연산 장치로 이동합니다.
images = images.to(device)
# 라벨을 연산 장치로 이동합니다.
labels = labels.to(device)
# 모델 예측 점수를 계산합니다.
outputs = model(images)
# 손실값을 계산합니다.
loss = criterion(outputs, labels)
# 손실 합계를 누적합니다.
total_loss += loss.item() * images.size(0)
# 가장 높은 점수의 클래스를 예측값으로 선택합니다.
_, preds = torch.max(outputs, 1)
# 정답과 같은 예측 개수를 누적합니다.
correct += (preds == labels).sum().item()
# 전체 라벨 개수를 누적합니다.
total += labels.size(0)
# 평균 손실을 계산합니다.
avg_loss = total_loss / total
# 정확도를 계산합니다.
accuracy = correct / total
# 평균 손실과 정확도를 반환합니다.
return avg_loss, accuracy
early stopping이 포함된 전체 학습을 정의해보자.
history 세팅
early stopping에서 가장 낮은 검증 손실을 저장 inf 무한대 float값을 가져온다 검증손실을 보통 작을수록 좋고 학습과정에서 최소값을 찾고싶기 때문이다 .외 best_state, parience_counter 세팅.
epoch만큼 반복.
train_one_epoch() 위 정의한 함수 수행해 학습.
evaluate() 위 정의한 성능 평가.
학습손실, 정확도, 검증손실, 검증 정확도 기록 및 결과출력
if else문을 사용해서 patience 이상 개선되지않ㅇ므면 break. 학습을 중단시킨다.
best_state가 저장되어있다면 모델에 적용한다. model.load_state_dict()
# ============================================================
# 11. 전체 학습 함수 정의
# ============================================================
def train_model(model, train_loader, val_loader, criterion, optimizer, epochs=30, patience=None):
# epoch별 학습/검증 손실과 정확도를 저장할 딕셔너리입니다.
history = {
'train_loss': [],
'train_acc': [],
'val_loss': [],
'val_acc': []
}
# Early Stopping에서 가장 낮은 검증 손실을 저장합니다.
best_val_loss = float('inf')
# 가장 좋은 모델의 파라미터를 저장할 변수입니다.
best_state = None
# 검증 손실이 개선되지 않은 epoch 수를 세는 변수입니다.
patience_counter = 0
# 지정한 epoch 수만큼 학습을 반복합니다.
for epoch in range(1, epochs + 1):
# 한 epoch 동안 학습을 수행하고 학습 손실과 정확도를 얻습니다.
train_loss, train_acc = train_one_epoch(model, train_loader, criterion, optimizer)
# 검증 데이터로 모델 성능을 평가합니다.
val_loss, val_acc = evaluate(model, val_loader, criterion)
# 학습 손실을 기록합니다.
history['train_loss'].append(train_loss)
# 학습 정확도를 기록합니다.
history['train_acc'].append(train_acc)
# 검증 손실을 기록합니다.
history['val_loss'].append(val_loss)
# 검증 정확도를 기록합니다.
history['val_acc'].append(val_acc)
# 현재 epoch 결과를 출력합니다.
print(f'Epoch {epoch:02d} | Train Loss: {train_loss:.4f} | Train Acc: {train_acc:.4f} | Val Loss: {val_loss:.4f} | Val Acc: {val_acc:.4f}')
# Early Stopping을 사용하는 경우에만 아래 로직을 실행합니다.
if patience is not None:
# 검증 손실이 이전보다 좋아졌는지 확인합니다.
if val_loss < best_val_loss:
# 가장 좋은 검증 손실을 갱신합니다.
best_val_loss = val_loss
# 현재 모델 파라미터를 CPU 기준 딕셔너리로 복사해 저장합니다.
best_state = {k: v.cpu().clone() for k, v in model.state_dict().items()}
# 개선되었으므로 카운터를 0으로 초기화합니다.
patience_counter = 0
else:
# 개선되지 않았으므로 카운터를 1 증가시킵니다.
patience_counter += 1
# 개선되지 않은 횟수가 patience 이상이면 학습을 중단합니다.
if patience_counter >= patience:
# Early Stopping이 발생했음을 출력합니다.
print(f'Early Stopping 발생: {epoch}번째 epoch에서 학습 중단')
# 반복문을 종료합니다.
break
# Early Stopping을 사용했고 가장 좋은 모델 상태가 저장되어 있다면 복원합니다.
if best_state is not None:
# 저장된 최적 파라미터를 모델에 다시 적용합니다.
model.load_state_dict(best_state)
# 모델을 현재 장치로 이동합니다.
model.to(device)
# 학습 기록을 반환합니다.
return history
학습상태 확인
오버피팅을 관찰해볼 수 있다.
# ============================================================
# 12. 오버피팅 관찰용 모델 학습
# ============================================================
# 복잡한 MLP 모델 객체를 생성하고 GPU 또는 CPU로 이동합니다.
overfit_model = OverfitMLP().to(device)
# CrossEntropyLoss는 다중 분류 문제에서 사용하는 대표적인 손실 함수입니다.
criterion_basic = nn.CrossEntropyLoss()
# Adam 최적화 알고리즘을 사용합니다.
# 여기서는 weight_decay를 적용하지 않아 정규화 효과가 없습니다.
optimizer_basic = optim.Adam(overfit_model.parameters(), lr=0.001)
# 기준 모델을 학습합니다.
# Early Stopping 없이 30 epoch 동안 학습하여 오버피팅 경향을 관찰합니다.
history_overfit = train_model(
model=overfit_model,
train_loader=train_loader_basic,
val_loader=val_loader,
criterion=criterion_basic,
optimizer=optimizer_basic,
epochs=30,
patience=None
)Epoch 01 | Train Loss: 1.0098 | Train Acc: 0.6454 | Val Loss: 0.8607 | Val Acc: 0.6417
Epoch 02 | Train Loss: 0.5835 | Train Acc: 0.7804 | Val Loss: 0.6982 | Val Acc: 0.7300
Epoch 03 | Train Loss: 0.4993 | Train Acc: 0.8175 | Val Loss: 0.6409 | Val Acc: 0.7667
Epoch 04 | Train Loss: 0.4405 | Train Acc: 0.8375 | Val Loss: 0.6413 | Val Acc: 0.7700
Epoch 05 | Train Loss: 0.3877 | Train Acc: 0.8625 | Val Loss: 0.6021 | Val Acc: 0.7967
Epoch 06 | Train Loss: 0.3389 | Train Acc: 0.8767 | Val Loss: 0.6172 | Val Acc: 0.7933
Epoch 07 | Train Loss: 0.3582 | Train Acc: 0.8721 | Val Loss: 0.6738 | Val Acc: 0.7800
Epoch 08 | Train Loss: 0.3335 | Train Acc: 0.8833 | Val Loss: 0.6786 | Val Acc: 0.7767
Epoch 09 | Train Loss: 0.2832 | Train Acc: 0.8958 | Val Loss: 0.7495 | Val Acc: 0.7633
Epoch 10 | Train Loss: 0.2661 | Train Acc: 0.9054 | Val Loss: 0.6854 | Val Acc: 0.7850
Epoch 11 | Train Loss: 0.2611 | Train Acc: 0.9004 | Val Loss: 0.7533 | Val Acc: 0.7750
Epoch 12 | Train Loss: 0.2270 | Train Acc: 0.9158 | Val Loss: 0.7561 | Val Acc: 0.7800
Epoch 13 | Train Loss: 0.1790 | Train Acc: 0.9321 | Val Loss: 0.8028 | Val Acc: 0.7850
Epoch 14 | Train Loss: 0.1917 | Train Acc: 0.9325 | Val Loss: 0.8486 | Val Acc: 0.7850
Epoch 15 | Train Loss: 0.1585 | Train Acc: 0.9433 | Val Loss: 0.7288 | Val Acc: 0.8117
Epoch 16 | Train Loss: 0.1171 | Train Acc: 0.9579 | Val Loss: 0.8120 | Val Acc: 0.8117
Epoch 17 | Train Loss: 0.1349 | Train Acc: 0.9500 | Val Loss: 0.7954 | Val Acc: 0.8083
Epoch 18 | Train Loss: 0.1472 | Train Acc: 0.9433 | Val Loss: 0.8376 | Val Acc: 0.7883
Epoch 19 | Train Loss: 0.1523 | Train Acc: 0.9421 | Val Loss: 0.8890 | Val Acc: 0.7833
Epoch 20 | Train Loss: 0.1444 | Train Acc: 0.9496 | Val Loss: 0.8713 | Val Acc: 0.8150
Epoch 21 | Train Loss: 0.1119 | Train Acc: 0.9579 | Val Loss: 0.9100 | Val Acc: 0.7983
Epoch 22 | Train Loss: 0.1109 | Train Acc: 0.9579 | Val Loss: 1.0782 | Val Acc: 0.7850
Epoch 23 | Train Loss: 0.1312 | Train Acc: 0.9542 | Val Loss: 0.9032 | Val Acc: 0.8000
Epoch 24 | Train Loss: 0.0838 | Train Acc: 0.9688 | Val Loss: 0.9651 | Val Acc: 0.7967
Epoch 25 | Train Loss: 0.0656 | Train Acc: 0.9758 | Val Loss: 1.0247 | Val Acc: 0.8033
...
Epoch 27 | Train Loss: 0.0876 | Train Acc: 0.9717 | Val Loss: 1.1447 | Val Acc: 0.7967
Epoch 28 | Train Loss: 0.1139 | Train Acc: 0.9583 | Val Loss: 1.0357 | Val Acc: 0.8033
Epoch 29 | Train Loss: 0.0715 | Train Acc: 0.9738 | Val Loss: 1.1722 | Val Acc: 0.7783
Epoch 30 | Train Loss: 0.0402 | Train Acc: 0.9854 | Val Loss: 1.1343 | Val Acc: 0.8050
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
앞서 정의한 오버피팅 방지 모델로 다시 학습해보자 .
이때 nn.CrossEntropyLoss() 때 label_smoothing0.1 을 주면 정답라벨을 100% 확신하지 않도록 부드럽게 만든다.
# ============================================================
# 13. 오버피팅 방지 기법 적용 모델 학습
# ============================================================
# 정규화 기법이 포함된 MLP 모델을 생성하고 연산 장치로 이동합니다.
regularized_model = RegularizedMLP().to(device)
# label_smoothing=0.1은 정답 라벨을 100% 확신하지 않도록 부드럽게 만듭니다.
# 모델이 학습 데이터의 정답을 지나치게 강하게 외우는 것을 줄이는 데 도움이 됩니다.
criterion_regularized = nn.CrossEntropyLoss(label_smoothing=0.1)
# AdamW는 Adam에 Weight Decay를 안정적으로 적용하는 최적화 알고리즘입니다.
# weight_decay=0.01은 가중치가 과도하게 커지는 것을 억제합니다.
optimizer_regularized = optim.AdamW(
regularized_model.parameters(),
lr=0.001,
weight_decay=0.01
)
# 정규화 모델을 학습합니다.
# 데이터 증강 학습 로더를 사용하고, Early Stopping을 적용합니다.
history_regularized = train_model(
model=regularized_model,
train_loader=train_loader_aug,
val_loader=val_loader,
criterion=criterion_regularized,
optimizer=optimizer_regularized,
epochs=30,
patience=5
)
학습결과를 그래프로 비교해보자 .
# ============================================================
# 14. 학습 곡선 시각화 함수 정의
# ============================================================
def plot_history(history, title):
# 그래프 크기를 설정합니다.
plt.figure(figsize=(10, 4))
# 학습 손실 그래프를 그립니다.
plt.plot(history['train_loss'], label='Train Loss')
# 검증 손실 그래프를 그립니다.
plt.plot(history['val_loss'], label='Validation Loss')
# 그래프 제목을 설정합니다.
plt.title(title)
# x축 이름을 설정합니다.
plt.xlabel('Epoch')
# y축 이름을 설정합니다.
plt.ylabel('Loss')
# 범례를 표시합니다.
plt.legend()
# 격자선을 표시하여 값을 읽기 쉽게 합니다.
plt.grid(True)
# 그래프를 화면에 출력합니다.
plt.show()
# 오버피팅 관찰용 모델의 손실 변화를 출력합니다.
plot_history(history_overfit, 'Overfit Model Loss')
# 오버피팅 방지 기법 적용 모델의 손실 변화를 출력합니다.
plot_history(history_regularized, 'Regularized Model Loss')
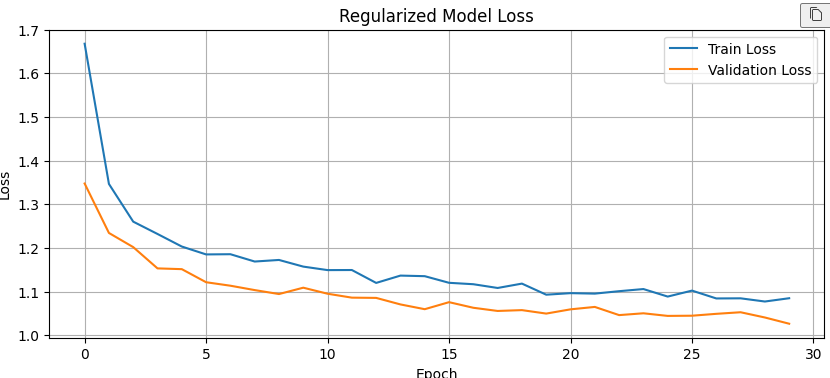
테스트 데이터로 최종비교
# ============================================================
# 15. 테스트 데이터 최종 평가
# ============================================================
# 기준 모델을 테스트 데이터로 평가합니다.
test_loss_overfit, test_acc_overfit = evaluate(overfit_model, test_loader, criterion_basic)
# 정규화 모델을 테스트 데이터로 평가합니다.
test_loss_regularized, test_acc_regularized = evaluate(regularized_model, test_loader, criterion_regularized)
# 기준 모델 테스트 결과를 출력합니다.
print(f'오버피팅 관찰용 모델 - Test Loss: {test_loss_overfit:.4f}, Test Acc: {test_acc_overfit:.4f}')
# 정규화 모델 테스트 결과를 출력합니다.
print(f'오버피팅 방지 적용 모델 - Test Loss: {test_loss_regularized:.4f}, Test Acc: {test_acc_regularized:.4f}')오버피팅 관찰용 모델 - Test Loss: 0.9939, Test Acc: 0.8137
오버피팅 방지 적용 모델 - Test Loss: 0.9788, Test Acc: 0.7728
'Personal > SK 네트웍스 AI 캠프' 카테고리의 다른 글
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day31_AI 모델 검증을 통한 고도화 (0) | 2026.06.19 |
|---|---|
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day30_AI 모델 검증 및 평가 (0) | 2026.06.19 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day28_딥러닝 다중 퍼셉트론 (0) | 2026.06.16 |
| [SK네트웍스 Family AI 캠프] 32기 7주차 회고: Day24 ~ Day26 (0) | 2026.06.15 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day27_딥러닝 모델 저장 및 활용 (0) | 2026.06.15 |



