언어모델은 규칙 기반 시스템과 통계적 언어모델에서 현재는 Transformer 기반의 대규모 언어모델로 발전했다 .
Transformer 아키텍처는 문장 속 단어들 사이의 관계와 중요도를 계산하는 Attention 매커니즘을 사용한다.
방대한 데이터를 미리 학습하는 사전학습 방식을 적용해 다양한 작업에서 높은 성능을 제공한다.
https://standout.tistory.com/1846
Attention 메커니즘만을 이용하여 문장을 처리하는 딥러닝 모델 Transformer (feat.Self-Attention, Multi-Head A
Transformer란? Attention 메커니즘만을 이용하여 문장을 처리하는 딥러닝 모델기존의 RNN, LSTM, GRU는 단어를 순서대로 처리했지만, Transformer는 모든 단어를 동시에 처리(병렬 처리)할 수 있도록 설계되
standout.tistory.com
언어모델에는 자기회귀 방식으로 다음 단어를 예측해 문장을 생성하는 챗봇과 대화형 AI 시스템에 주로 사용되는 GPT,
양방향 문맥을 동시에 이해하는 텍스트분류, 감정분석, 질의응답등 자연어 이해에 강점을 가지는 BERT
https://standout.tistory.com/1848
자연어 처리에서 사용하는 대표적인 딥러닝 모델: DNN, CNN , RNN , LSTM , GRU , Seq2Seq , Attention, Transforme
자연어 처리에서 사용하는 대표적인 딥러닝 모델 DNN (Deep Neural Network)가장 기본적인 딥러닝 모델 여러개의 은닉층을 가진 인공신경망, 여러층을 거쳐 특징을 추출한 후 결과를 예측한다. NLP에서
standout.tistory.com
https://standout.tistory.com/1865
BERT란? 구글이 2018년에 공개한 33억 단어에 대해 약 4일간 학습시킨 사전 훈련된 언어 모델
BERT 구글이 2018년에 공개한 사전 훈련된 언어 모델33억 단어에 대해 약 4일간 학습시킨 언어 모델위키피디아의 25억개 단어와 북코퍼스의 8억개 레이블이 없는 데이터를 이용하여 사전 훈련됨레
standout.tistory.com
외 T5, ELECTRA, CLIP, DALL-E와 같은 모델이 등장했다.
이러한 모델들은 텍스트 뿐아니라 이미지, 영상, 음성 등 다양한 데이터를 함께 처리할 수 있다.
CLIP과 DALL·E는 멀티모달 모델
-CLIP (Contrastive Language–Image Pre-training)
텍스트와 이미지를 함께 학습해 두 데이터의 의미를 연결한다. 이미지와 가장 잘 맞는 문장을 찾고, 문장과 가장 잘 맞는 이미지를 찾거나 이미지 검색, 이미지 분류, 이미지와 텍스트의 의미를 비교할 수 있다.
-DALL·E
사용자가 자연어로 원하는 장면을 입력하면 그 내용을 바탕으로 새로운 이미지를 생성한다.
https://standout.tistory.com/1871
멀티모달 모델, OpenAI가 개발한 CLIP과 DALL·E
CLIP과 DALL·E는 멀티모달 모델 -CLIP (Contrastive Language–Image Pre-training)OpenAI가 개발한 멀티모달 AI 모델텍스트와 이미지를 함께 학습해 두 데이터의 의미를 연결한다. 이미지와 가장 잘 맞는 문장을
standout.tistory.com
T5와 ELECTRA는 자연어 처리(NLP) 모델
-T5 (Text-To-Text Transfer Transformer)
모든 자연어 처리 문제를 텍스트를 입력받아 텍스트를 출력하는(Text-to-Text) 방식으로 해결하도록 설계
번역, 문서요약, 질의응답, 문장생성완성을 하나의 모델로 수행할 수 있다 .
-ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately)
Google이 개발한 언어모델로, 기존 BERT보다 학습 효율을 크게 향상시킨 모델
BERT는 일부 단어를 가리고(Masked Language Modeling) 이를 예측하는 방식으로 학습하지만, ELECTRA는 문장 속 단어가 원래 단어인지, 다른 단어로 교체된 것인지 판별하는 방식으로 학습한다.
https://standout.tistory.com/1872
자연어 처리(NLP) 모델, Google이 개발한 언어모델 T5와 ELECTRA
T5와 ELECTRA는 자연어 처리(NLP) 모델 -T5 (Text-To-Text Transfer Transformer)Google이 개발한 자연어 처리 모델모든 자연어 처리 문제를 텍스트를 입력받아 텍스트를 출력하는(Text-to-Text) 방식으로 해결하도록
standout.tistory.com
정
| T5 | 자연어 처리(NLP) | 모든 NLP 작업을 텍스트 입력→텍스트 출력 방식으로 수행 |
| ELECTRA | 자연어 처리(NLP) | 교체된 단어를 판별하는 방식으로 효율적인 학습 수행 |
| CLIP | 멀티모달 | 텍스트와 이미지를 함께 이해하고 연결 |
| DALL·E | 멀티모달 | 텍스트를 기반으로 새로운 이미지를 생성 |
전이학습
학습한 지식을 다른 관련 작업에 재사용하는 머신러닝 기
https://standout.tistory.com/1813
모델이 학습이 덜됬거나 과하게 됬거나: Underfitting (언더피팅), Overfitting (오버피팅)과 해결방법 -
Underfitting (언더피팅)모델이 충분히 학습되지않은 상태,아직 덜 배운상태.모델이 너무 단순하거나 학습이 부족하거나 특징이 부족할 수있다. 학습이 부족해서 발생한 언더피팅 → 더 학습하면
standout.tistory.com
파인튜닝(Fine-Tuning)
사전학습된 모델에 새로운 데이터를 추가해 목적에 맞게 다시 학습시키는 과정.
일반적인 언어 지식을 의료 법률 금융 등 특정 산업의 전문지식으로 확장할 수 있다.
https://standout.tistory.com/1873
파인튜닝(Fine-Tuning): 전이학습시 사전학습된 모델에 새로운 데이터를 추가해 목적에 맞게 다시
파인튜닝(Fine-Tuning)전이학습시 사전학습된 모델에 새로운 데이터를 추가해 목적에 맞게 다시 학습시키는 과정. 일반적인 언어 지식을 의료 법률 금융 등 특정 산업의 전문지식으로 확장할 수 있
standout.tistory.com
Hugging Face
최신 AI 모델을 쉽게 사용할 수 있도록 PyTorch, TensorFlow 프레임워크를 지원한다.
복잡한 모델도 몇줄의 코드만으로 사용할 수 있다.
https://standout.tistory.com/1874
최신 AI 모델을 쉽게 사용하는 Hugging Face: Model Hub, Transformers 라이브러리, Datasets
Hugging Face최신 AI 모델을 쉽게 사용할 수 있도록 PyTorch, TensorFlow 프레임워크를 지원한다. 복잡한 모델도 몇줄의 코드만으로 사용할 수 있다. 특히 NLP, 이미지 모델, 생성형 AI를 다루는 표준 도구처
standout.tistory.com
프롬프트 엔지니어링 Prompt Engineering
프롬프트 엔지니어링(Prompt Engineering)AI에게 원하는 결과를 얻기 위해 입력(프롬프트)을 효과적으로 작성하는 기법
| Zero-shot | 0개 | 설명만으로 작업 수행 | 가장 간단하고 빠름 | 복잡한 작업에서는 결과가 불안정할 수 있음 |
| One-shot | 1개 | 예시 1개를 보고 같은 방식으로 수행 | 원하는 형식이나 스타일을 알려주기 쉬움 | 예시가 하나뿐이라 패턴 전달이 제한적일 수 있음 |
| Few-shot | 2개 이상 | 여러 예시를 보고 패턴을 학습하여 수행 | 형식, 문체, 규칙을 가장 잘 따르는 경향이 있음 | 프롬프트가 길어지고 토큰을 더 많이 사용함 |
https://standout.tistory.com/1875
프롬프트 엔지니어링 Prompt Engineering: AI에게 원하는 결과를 얻기 위해 입력(프롬프트)을 효과적으
프롬프트 엔지니어링 Prompt Engineering프롬프트만 잘작성해도 원하는 결과를 얻을 수 있다. 프롬프트 엔지니어링(Prompt Engineering) AI에게 원하는 결과를 얻기 위해 입력(프롬프트)을 효과적으로 작성
standout.tistory.com
RAG(Retrieval-Augmented Generation)
기업은 범용 언어모델을 그대로 사용하는 것이 아니라 사내 문서, 정보, 고객데이터 등을 추가해 기업전용 AI시스템을 구축하며 LLM은 이때 존재하지않는 정보를 생성하는 환각 Hallucination문제가 발생할 수 있다. 이를 해결하기 위해 외부 문서를 검색한 후 검색 결과를 바탕으로 답변을 생성하는 RAG 기법을 사용한다.
https://standout.tistory.com/1876
RAG(Retrieval-Augmented Generation)와 LLM의 Hallucination(환각): 외부 문서를 검색한 후 검색 결과를 바탕으
RAG(Retrieval-Augmented Generation)기업은 범용 언어모델을 그대로 사용하는 것이 아니라 사내 문서, 정보, 고객데이터 등을 추가해 기업전용 AI시스템을 구축하며 LLM은 이때 존재하지않는 정보를 생성
standout.tistory.com
Seq2Seq
입력 시퀀스(Sequence)를 다른 출력 시퀀스로 변환하는 딥러닝 모델이다.
순서가 있는 데이터를 입력받아, 또 다른 순서가 있는 데이터를 출력하는 모델
주로 LSTM나 GRU기반으로 구성된다.
기존의 언어 인식, 분류, 판단 기능을 넘어 문장을 새롭게 생성하거나 요약하는 생성형 모델
입력 → Encoder → Context Vector → Decoder → 출력
Encoder는 입력 문장을 읽어 하나의 벡터(Context Vector)로 압축한다.
Context Vector는 입력 문장의 의미를 압축한 벡터 , 벡터 하나에 문장의 의미를 저장한다.
Decoder는 Context Vector를 이용하여 문장을 생성한다.
Context Vector 하나에 입력 문장의 모든 정보를 압축해야 한다는 점이 문제점으로 문장이 길어질수록 모든 의미를 담아야 하므로
앞부분 정보가 손실되고, 긴 문장에서 번역 품질이 떨어진다.정보 병목(Information Bottleneck).
https://standout.tistory.com/1844
입력과 출력의 길이가 달라도 처리할 수 있는 모델 Seq2Seq , 정보 병목(Information Bottleneck) (feat. Atte
Seq2Seq (Sequence to Sequence) 입력 시퀀스(Sequence)를 다른 출력 시퀀스로 변환하는 딥러닝 모델이다. 순서가 있는 데이터를 입력받아, 또 다른 순서가 있는 데이터를 출력하는 모델주로 LSTM나 GRU기반으
standout.tistory.com
Attention
기계번역에서 현재 단어 하나만 보는게 아니라 주변 단어 전체를 함께 고려해 번역하는것이 Seq2Seq 모델의 가장 큰 개선점이었다.
Query, Key, Value 세가지 벡터를 이용해 현재 필요한 정보가 무엇인지를 계산해 모든 정보를 동일하게 기억하려고 하지않는다. 사람이 메모할때 중요한 내용만 적는것과 같은 매커니즘.
Attemtion을 도입하면 긴문장을 처리할수있고 문맥 유지 능력ㅇ이 향상되는 효과가있다.
https://standout.tistory.com/1846
Attention 메커니즘만을 이용하여 문장을 처리하는 딥러닝 모델 Transformer (feat.Self-Attention, Multi-Head A
Transformer란? Attention 메커니즘만을 이용하여 문장을 처리하는 딥러닝 모델기존의 RNN, LSTM, GRU는 단어를 순서대로 처리했지만, Transformer는 모든 단어를 동시에 처리(병렬 처리)할 수 있도록 설계되
standout.tistory.com
Transformer
기존 RNN과 LSTM은 이전 정보를 얼마나 유지할 것인지에 초점을 맞추었다.
인코딩 과정에서 어떤 정보에 집중할지 어떤 정보를 덜 중요하게 볼지를 스스로 학습한다.
문맥에 따라 정보의 중요도를 조절하여 필요한 정보는 강조하고 덜 중요한 정보는 약화시키는 유연한 처리가 가능하다.
https://standout.tistory.com/1846
Attention 메커니즘만을 이용하여 문장을 처리하는 딥러닝 모델 Transformer (feat.Self-Attention, Multi-Head A
Transformer란? Attention 메커니즘만을 이용하여 문장을 처리하는 딥러닝 모델기존의 RNN, LSTM, GRU는 단어를 순서대로 처리했지만, Transformer는 모든 단어를 동시에 처리(병렬 처리)할 수 있도록 설계되
standout.tistory.com
GPT
transformer의 decoder를 사용한 언어모델.
https://standout.tistory.com/1877
GPT (Generative Pre-trained Transformer) , Decoder-Only Transformer: Transformer의 Decoder만 사용하는 언어모델, GPT-1
GPT (Generative Pre-trained Transformer)GPT는 언어모델에 속하는 인공지능 모델이다 OpenAI 는 GPT 를 지속적으로 발전시켜 더욱 뛰어난 모델을 출시하고 있다. 이미지를 이해하는 멀티모달기능, 인식능력향
standout.tistory.com
실습코드를 분석해보자. GPT_KoGPT2_torch.ipynb
PyTorch가 기본 설치되어있지만 Colab에서 버전문제를 줄이기 위해 transformers와 sentencepoece를 함께 설치했다 .
# 현재 노트북 커널에 필요한 패키지를 설치합니다.
# - transformers: Hugging Face 사전 학습 모델과 토크나이저를 사용하기 위한 라이브러리입니다.
# - sentencepiece: 일부 토크나이저가 내부적으로 사용할 수 있는 서브워드 토큰화 라이브러리입니다.
# - accelerate: Colab GPU 환경에서 모델 로딩과 실행을 보조하는 라이브러리입니다.
%pip install -q transformers sentencepiece accelerate
import
re, torch,
transformers AutoTokenizer 모델 이름에 맞는 토크나이저를 자동으로 불러온다 .
transformers AutoModelForCausalLM 이정 토큰을 기준으로 다음 토큰을 예측하는 언어모델. 왼쪽에서 오른쪽으로 다음 토큰을 생성하는 언어모델
# 정규표현식 처리를 위한 파이썬 기본 라이브러리입니다.
# 생성된 문장에서 제어 문자나 깨진 문자를 제거할 때 사용합니다.
import re
# PyTorch 라이브러리입니다.
# Tensor 생성, GPU 사용, 모델 추론, 난수 고정 등에 사용합니다.
import torch
# AutoTokenizer는 모델 이름에 맞는 토크나이저를 자동으로 불러옵니다.
# 토크나이저는 사람이 입력한 문자열을 모델이 이해하는 정수 토큰 ID로 변환합니다.
from transformers import AutoTokenizer
# AutoModelForCausalLM은 GPT처럼 이전 토큰을 기준으로 다음 토큰을 예측하는 언어 모델을 불러옵니다.
# CausalLM은 왼쪽에서 오른쪽으로 다음 토큰을 생성하는 언어 모델을 의미합니다.
from transformers import AutoModelForCausalLM
장치설정
# 현재 Colab 런타임에서 GPU를 사용할 수 있는지 확인합니다.
# GPU가 있으면 "cuda", 없으면 "cpu" 장치를 사용합니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 실제 실행 장치를 출력하여 GPU 사용 여부를 확인합니다.
print("사용 장치:", device)
model 이름 kogpt2-base-v2
토크나이저는 사람이 입력한 모델을 컴퓨터가 이해할수있는 숫자로 변환하고 ,모델은 토크나이저가 만든 숫자를 입력받아 예측을 수행한다.
모델과 토크나이저는 반드시 같은 모델 이름으로 불러와야 토크나이저가 만든 정수 id체계와 모델의 어휘사전이 서로 일치한다.
이 model이름으로 AutoTokenizer.from_pretrained() 훈련된 토크나이저 불러오기, use_fase는 가능한 경우 빠른 토크나이저 구현을 사용하겠다는 의미.
model 불러오기 AutoModelForCausalLM,from_pretrained()
모델 장치이동
model.eval() 평가모드 전환.
tokenizer.pad_token_id가 none이면 generate() 실행시 padding 경고를 줄이기 위해 tokenizer.eos.token으로 맞춘다 .
AI모델은 한번에 여러문장을 처리할때 모든 문장의 길이가 같아야하기때문에 짧은 문장 뒤엔 빈칸 역할을 하는 토큰을 넣는다. 이때 대표적으로 gpt-2, Llama, mistral와 같은 생성모델은 패딩을 거의 사용하지않는 경우가 많다.
하지만 모델이 실행하는 함수 model.generate() 사용할때 padding 이 필요한 상황이 생길수있어 경고가 뜰 수 있다 .
즉 토큰나이저에 pad토큰이 정의되어있지않는다면 eos 토큰을 pad대신 사용하는 것. eos로 pad처럼 채워도 모델들은 큰 문제없이 처리하도록 설계되어있다.
model.config.pad_token_id, model.config.eos_tokenid 모델설정에도 토큰 지정.
모델 설정(config)에 알려주는 것 모델아, 패딩 토큰 ID는 이것이야. 모델아, EOS 토큰 ID는 이것이야. 보통은 이미 설정되어있지만 일부모델에서 비어있는 경우가 많아안전하게 지정해준다.
# 사용할 KoGPT2 모델 이름을 지정합니다.
# 같은 model_name으로 토크나이저와 모델을 불러와야 토큰 ID 체계가 일치합니다.
model_name = "skt/kogpt2-base-v2"
# KoGPT2 토크나이저를 불러옵니다.
# use_fast=True는 가능한 경우 빠른 토크나이저 구현을 사용하겠다는 의미입니다.
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=True)
# PyTorch 기반 KoGPT2 언어 모델을 불러옵니다.
# AutoModelForCausalLM은 문장 생성에 필요한 다음 토큰 예측 헤드가 포함된 모델입니다.
model = AutoModelForCausalLM.from_pretrained(model_name)
# 모델을 GPU 또는 CPU로 이동합니다.
# 입력 Tensor도 같은 device에 올려야 오류 없이 실행됩니다.
model = model.to(device)
# 이 노트북에서는 학습이 아니라 추론만 수행하므로 평가 모드로 전환합니다.
# eval()은 Dropout처럼 학습 때만 사용하는 기능을 비활성화합니다.
model.eval()
# KoGPT2 계열 모델은 pad_token이 명확하지 않은 경우가 있습니다.
# generate() 실행 시 padding 관련 경고와 오류를 줄이기 위해 pad_token을 eos_token으로 맞춥니다.
if tokenizer.pad_token_id is None:
tokenizer.pad_token = tokenizer.eos_token
# 모델 설정에도 pad_token_id를 지정해 generate()가 안정적으로 동작하도록 합니다.
model.config.pad_token_id = tokenizer.pad_token_id
# 모델 설정에 eos_token_id가 없으면 토크나이저의 eos_token_id를 사용합니다.
model.config.eos_token_id = tokenizer.eos_token_id
# 로드 결과를 확인합니다.
print("모델 로드 완료:", model_name)
print("pad_token:", tokenizer.pad_token, "| pad_token_id:", tokenizer.pad_token_id)
print("eos_token:", tokenizer.eos_token, "| eos_token_id:", tokenizer.eos_token_id)
난수고정
# PyTorch CPU 연산의 난수 시드를 고정합니다.
# 같은 환경에서 실행하면 샘플링 결과가 어느 정도 재현됩니다.
torch.manual_seed(42)
# GPU를 사용하는 경우 GPU 연산의 난수 시드도 함께 고정합니다.
if torch.cuda.is_available():
torch.cuda.manual_seed_all(42)
# 재현성 설정 완료 메시지를 출력합니다.
print("난수 시드 고정 완료")
clean_generate_text()
kogpt2가 생성한 문장에는 간혹 제어문자, 깨진문자, 과도한 공백이 포함될 수 있다 .
이는 모델의 학습 방식과 토큰(token) 처리 방식 때문
제어문자는 화면에 글자로 보이지 않고, 줄바꿈(\n), 탭(\t)처럼 동작을 제어하는 문자인데 KoGPT2가 학습할 때 인터넷 문서, 뉴스, 게시글, 위키 등 다양한 텍스트를 사용했기 때문에 학습데이터에 줄바꿈, 탭, 특수제어문자등이 포함되어있어 모델은 그것도 텍스트의 일부라고 학습하기 때문에 생성할 때도 그대로 출력하는 경우가 있다.
replace.re.sub
# 생성된 문자열을 정리하는 함수를 정의합니다.
# text 매개변수에는 tokenizer.decode()로 복원된 문자열이 들어옵니다.
def clean_generated_text(text: str) -> str:
# 유니코드 replacement character(�)는 디코딩 과정에서 깨진 글자가 있을 때 나타날 수 있으므로 제거합니다.
text = text.replace("�", "")
# ASCII 제어 문자 범위를 제거합니다.
# 줄바꿈, 탭처럼 출력 정리에 필요한 문자는 뒤에서 공백으로 정리할 것이므로 함께 처리합니다.
text = re.sub(r"[\x00-\x1F\x7F]", " ", text)
# KoGPT2 토크나이저에서 간혹 보일 수 있는 특수 토큰 문자열을 제거합니다.
text = text.replace("</s>", " ")
text = text.replace("<pad>", " ")
text = text.replace("<unk>", " ")
# 여러 개의 공백을 하나의 공백으로 줄입니다.
text = re.sub(r"\s+", " ", text)
# 문장 앞뒤의 불필요한 공백을 제거합니다.
text = text.strip()
# 정리된 문자열을 반환합니다.
return text
generate_korean_text() 문장을 생성하는 함수 정의
파라미터 설정.
prompt : 사용자가 입력하는 시작 문장
max_new_tokens : 최대 몇 개의 토큰을 생성할지
temperature : 창의성(다양성)
top_p : 누적 확률 기준으로 후보 선택
top_k : 상위 K개 후보만 사용
repetition_penalty : 같은 단어 반복 방지
no_repeat_ngram_size : 같은 구절 반복 방지
입력문장 encoded 를 토크나이저로 인코딩, PyTorch Tensor 형태로 반환.
입력문장중 input_ids를 input_ids에 할당
attention_mask가 있으면 할당. attention_mask는 실제 토큰과 패딩 토큰을 구분하는 역할을한다.
[오늘][날씨][PAD][PAD]
input_ids [123, 456, 0, 0]
attention_mask [1, 1, 0, 0]
모델은 0인 부분은 무시 할 수 있다 .
torch.no_grad() 학습이 아니라 추론(inference)만 한다.
model.generate()
tokenizer.decode() 생성된 토큰 id를 문자열로 복원한다. skip_special_tokens=True로 특수토큰은 출력에서 제외하도록 한다.
clean_up_tokenization_spaces=True는 토크나이저가 숫자(ID)를 다시 문장으로 변환(decode)할 때, 불필요한 공백을 자동으로 정리하는 옵션
clean_generated_text() 앞서 작성한 함수로 깨진 문자와 불필요한 공백등을 정리해 return.
# KoGPT2로 문장을 생성하는 함수를 정의합니다.
# prompt는 사용자가 입력하는 시작 문장입니다.
def generate_korean_text(
prompt: str,
max_new_tokens: int = 60,
temperature: float = 0.75,
top_p: float = 0.90,
top_k: int = 50,
repetition_penalty: float = 1.15,
no_repeat_ngram_size: int = 3,
) -> str:
# 입력 문장을 토크나이저로 인코딩합니다.
# return_tensors="pt"는 결과를 PyTorch Tensor 형태로 반환하라는 의미입니다.
encoded = tokenizer(
prompt,
return_tensors="pt",
add_special_tokens=False
)
# 인코딩 결과 중 input_ids를 모델과 같은 device로 이동합니다.
input_ids = encoded["input_ids"].to(device)
# attention_mask가 있으면 모델과 같은 device로 이동합니다.
# attention_mask는 실제 토큰과 패딩 토큰을 구분하는 역할을 합니다.
attention_mask = encoded.get("attention_mask", None)
if attention_mask is not None:
attention_mask = attention_mask.to(device)
# 문장 생성은 학습이 아니므로 기울기 계산을 비활성화합니다.
# 이렇게 하면 메모리 사용량이 줄고 실행 속도가 좋아집니다.
with torch.no_grad():
# generate() 함수로 입력 문장 뒤에 이어질 토큰을 생성합니다.
generated_ids = model.generate(
input_ids=input_ids, # 모델 입력 토큰 ID입니다.
attention_mask=attention_mask, # 패딩 여부를 알려주는 마스크입니다.
max_new_tokens=max_new_tokens, # 새로 생성할 토큰 수만 제한합니다.
do_sample=True, # 확률적 샘플링으로 자연스러운 후보를 선택합니다.
temperature=temperature, # 생성 다양성을 조절합니다.
top_p=top_p, # 누적 확률 기준으로 후보를 제한합니다.
top_k=top_k, # 상위 k개 후보로 선택 범위를 제한합니다.
repetition_penalty=repetition_penalty, # 같은 토큰 반복을 줄입니다.
no_repeat_ngram_size=no_repeat_ngram_size, # 같은 구절 반복을 줄입니다.
eos_token_id=tokenizer.eos_token_id, # 문장 종료 토큰 ID를 지정합니다.
pad_token_id=tokenizer.pad_token_id, # 패딩 토큰 ID를 지정합니다.
use_cache=True # 이전 계산 결과를 재사용하여 생성 속도를 높입니다.
)
# 생성된 토큰 ID 전체를 문자열로 복원합니다.
# skip_special_tokens=True는 특수 토큰을 출력에서 제외합니다.
decoded_text = tokenizer.decode(
generated_ids[0],
skip_special_tokens=True,
clean_up_tokenization_spaces=True
)
# 깨진 문자와 불필요한 공백을 정리합니다.
decoded_text = clean_generated_text(decoded_text)
# 최종 생성 문장을 반환합니다.
return decoded_text
테스트.
prompt에 샘플 문장을 넣고. 토큰 id리스트로 변환해보고, 다시 토큰 문자열로 변환해보자.
# 의미가 잘 이어지도록 시작 문장을 조금 더 구체적으로 작성합니다.
# 막연한 문장보다 목적과 방향이 분명한 문장이 생성 품질에 유리합니다.
prompt = "딥러닝을 잘 하기 위해서는 기초 수학과 파이썬을 꾸준히 공부해야 한다. 특히"
# 시작 문장을 토큰 ID 리스트로 변환합니다.
input_ids_list = tokenizer.encode(prompt, add_special_tokens=False)
# 토큰 ID를 실제 토큰 문자열로 변환합니다.
input_tokens = tokenizer.convert_ids_to_tokens(input_ids_list)
# 시작 문장을 출력합니다.
print("시작 문장:")
print(prompt)
# 정수 ID 리스트를 출력합니다.
print("\n정수 ID 리스트:")
print(input_ids_list)
# 토큰 목록을 출력합니다.
print("\n토큰 목록:")
print(input_tokens)시작 문장:
딥러닝을 잘 하기 위해서는 기초 수학과 파이썬을 꾸준히 공부해야 한다. 특히
정수 ID 리스트:
[500, 500, 500, 501, 501, 502, 499, 470, 501, 502, 501, 500, 499, 470, 501, 501, 502, 499, 502, 501, 501, 501, 499, 501, 502, 499, 500, 472, 502, 501, 502, 500, 389, 502, 502]
토큰 목록:
['ë', 'ë', 'ë', 'ì', 'ì', 'í', 'ê', '°', 'ì', 'í', 'ì', 'ë', 'ê', '°', 'ì', 'ì', 'í', 'ê', 'í', 'ì', 'ì', 'ì', 'ê', 'ì', 'í', 'ê', 'ë', '¶', 'í', 'ì', 'í', 'ë', '.', 'í', 'í']
Temperature를 낮춰 높은 확률의 단어를 더 선호해 자연스러운 문장이 나올 가능성이 높게 하고, 높은 상위 40개 단어만 후보로 사용한다 . 또 gpt계열은 같은 단어를 반복하는 경우가 많으니 repetition_penalty값을 높이고 no_repeat_ngram_size=3 연속된 토큰이 3개 연속해 생성되지않도록 막는다.
오늘은 좋은 날입니다.
좋은 날입니다.
좋은 날입니다.
좋은 날입니다.
# 개선된 생성 함수를 사용하여 문장을 생성합니다.
generated_text = generate_korean_text(
prompt=prompt, # 시작 문장입니다.
max_new_tokens=60, # 입력 뒤에 새로 생성할 토큰 수입니다.
temperature=0.70, # 너무 튀는 문장을 줄이기 위해 비교적 낮게 설정합니다.
top_p=0.90, # 누적 확률 90% 안의 후보에서 선택합니다.
top_k=40, # 상위 40개 후보 안에서 선택합니다.
repetition_penalty=1.15, # 반복 표현을 줄입니다.
no_repeat_ngram_size=3 # 같은 3토큰 구절 반복을 막습니다.
)
# 최종 생성 결과를 출력합니다.
print("생성된 문장:")
print(generated_text)[transformers] Ignoring clean_up_tokenization_spaces=True for BPE tokenizer GPT2Tokenizer. The clean_up_tokenization post-processing step is designed for WordPiece tokenizers and is destructive for BPE (it strips spaces before punctuation). Set clean_up_tokenization_spaces=False to suppress this warning, or set clean_up_tokenization_spaces_for_bpe_even_though_it_will_corrupt_output=True to force cleanup anyway.
생성된 문장:
. iti 로베르토▁뻬뜨르▁르▁파리지앵▁(▁Lberto▁de▁Parise▁Prtre▁)▁은▁프랑스▁남부▁지방의▁작은▁도시다. 파리에서는▁유명한▁성,▁또는▁파리▁중심가에▁있는▁지역이다.▁2016년▁2월▁24일부터▁4월
생성문장이 시작문장과 잘 이어지게 하려면 시작문장을 구체적으로 작성하는 것이 중요하다.
# 여러 시작 문장을 준비합니다.
# 각 문장은 생성 결과가 어떤 식으로 달라지는지 비교하기 위한 예시입니다.
prompts = [
"인공지능을 공부할 때 가장 먼저 이해해야 할 개념은 데이터와 모델의 관계이다. 데이터는",
"자연어 처리를 잘 이해하기 위해서는 토큰화 과정을 먼저 알아야 한다. 토큰화는",
"파이토치로 딥러닝 모델을 만들 때 중요한 흐름은 데이터 준비, 모델 정의, 학습, 평가이다. 이 중에서",
]
# 각 시작 문장에 대해 문장 생성을 수행합니다.
for i, p in enumerate(prompts, start=1):
# 현재 예시 번호와 시작 문장을 출력합니다.
print(f"\n===== 예시 {i} =====")
print("시작 문장:", p)
# 동일한 생성 함수를 사용하여 이어지는 문장을 만듭니다.
result = generate_korean_text(
prompt=p,
max_new_tokens=50,
temperature=0.70,
top_p=0.90,
top_k=40,
repetition_penalty=1.15,
no_repeat_ngram_size=3
)
# 생성 결과를 출력합니다.
print("생성 결과:", result)===== 예시 1 =====
시작 문장: 인공지능을 공부할 때 가장 먼저 이해해야 할 개념은 데이터와 모델의 관계이다. 데이터는
생성 결과: .rː }▁}▁##▁2018년▁2월▁7일부터▁2020년▁1월▁15일까지▁매주▁금요일▁오후▁5시에▁방송되는▁KBS2▁월화▁드라마이다. 1976년▁4월▁1일▁MBC에서▁개국한▁후▁1981년
===== 예시 2 =====
시작 문장: 자연어 처리를 잘 이해하기 위해서는 토큰화 과정을 먼저 알아야 한다. 토큰화는
생성 결과: .iǔtte.ixǐšǎn rr▁à▁́ltili #
===== 예시 3 =====
시작 문장: 파이토치로 딥러닝 모델을 만들 때 중요한 흐름은 데이터 준비, 모델 정의, 학습, 평가이다. 이 중에서
생성 결과: ,,,. 한편▁이탈리아는▁로마▁가톨릭을▁받아들이고▁있다. 로마▁가톨릭교회는▁로마의▁교황에▁해당하는▁주교들을▁선출할▁권한을▁가지고▁있으며,▁교황은▁바티칸으로부터▁공식적인▁사절을▁임명한다. 교황청은▁교황에게▁추기경들의▁임명을▁요청할▁수▁있는▁권한도▁갖고▁있다.▁
KoGPT2가 다음 단어를 어떻게 예측하는지 확인해보자 .
토크나이저가 만든 숫자(토큰 ID)를 모델에게 전달
어디까지가 진짜 문장이고, 어디부터는 패딩(PAD)인지 모델에게 알려준다.
logits는 모델이 계산한 "점수(score)"를 출력해보자.
# 시작 문장을 PyTorch Tensor 형태로 인코딩합니다.
encoded = tokenizer(
prompt,
return_tensors="pt",
add_special_tokens=False
)
# input_ids를 모델과 같은 device로 이동합니다.
input_ids = encoded["input_ids"].to(device)
# attention_mask를 모델과 같은 device로 이동합니다.
attention_mask = encoded["attention_mask"].to(device)
# 다음 토큰 후보 점수 계산은 추론이므로 기울기 계산을 비활성화합니다.
with torch.no_grad():
# 모델에 현재까지의 입력 문장을 넣어 logits를 계산합니다.
outputs = model(input_ids=input_ids, attention_mask=attention_mask)
# logits는 [배치 크기, 입력 토큰 개수, 어휘 사전 크기] 형태입니다.
print("logits shape:", outputs.logits.shape)logits shape: torch.Size([1, 35, 51200])
이 logits를 좀더 자세히 뜯어보며 출력해보자.
torch.topk() 점수가 가장 높은 k 값과 id를 반환한다.
이 5개를 뽑아보되, 깨진문자가있을 수 있으니 clean_generated_text() 로 보기좋게 정리하자.
이 점수가 logits. 이 점수를 가지고 다음 토큰을 예측한다.
# 첫 번째 문장의 마지막 위치에 해당하는 다음 토큰 후보 점수를 선택합니다.
last_token_logits = outputs.logits[0, -1, :]
# torch.topk()는 점수가 가장 높은 k개 값과 해당 토큰 ID를 반환합니다.
top5_values, top5_indices = torch.topk(last_token_logits, k=5)
# GPU Tensor를 CPU 리스트로 변환합니다.
top5_token_ids = top5_indices.cpu().tolist()
# 상위 토큰 ID를 실제 토큰 문자열로 변환합니다.
top5_tokens = tokenizer.convert_ids_to_tokens(top5_token_ids)
# 상위 후보를 순위별로 출력합니다.
print("상위 5개 다음 토큰 후보:")
for rank, (token_id, token, score) in enumerate(zip(top5_token_ids, top5_tokens, top5_values.cpu().tolist()), start=1):
# 토큰 문자열에 깨진 문자가 있을 수 있으므로 보기 좋게 정리합니다.
token_text = clean_generated_text(token)
# 순위, 토큰 ID, 토큰, 점수를 출력합니다.
print(f"{rank}위 | 토큰 ID: {token_id} | 토큰: {token_text} | 점수: {score:.4f}")상위 5개 다음 토큰 후보:
1위 | 토큰 ID: 498 | 토큰: é | 점수: 12.0479
2위 | 토큰 ID: 499 | 토큰: ê | 점수: 12.0271
3위 | 토큰 ID: 502 | 토큰: í | 점수: 11.6269
4위 | 토큰 ID: 5 | 토큰: | 점수: 11.5744
5위 | 토큰 ID: 497 | 토큰: è | 점수: 11.3572
옵션을 달리해서 비교해보자.
temperature를 높여봤다 . 표현이 다양해지지만 문맥이 흔들릴수있다.
# 비교에 사용할 시작 문장입니다.
compare_prompt = "머신러닝 모델의 성능을 높이기 위해서는 데이터를 잘 전처리해야 한다. 예를 들어"
# 안정적인 생성 옵션을 적용합니다.
stable_result = generate_korean_text(
prompt=compare_prompt,
max_new_tokens=50,
temperature=0.60,
top_p=0.85,
top_k=30,
repetition_penalty=1.15,
no_repeat_ngram_size=3
)
# 다양한 생성 옵션을 적용합니다.
creative_result = generate_korean_text(
prompt=compare_prompt,
max_new_tokens=50,
temperature=0.95,
top_p=0.95,
top_k=80,
repetition_penalty=1.10,
no_repeat_ngram_size=3
)
# 비교 결과를 출력합니다.
print("시작 문장:")
print(compare_prompt)
print("\n[안정적인 생성 결과]")
print(stable_result)
print("\n[다양한 생성 결과]")
print(creative_result)시작 문장:
머신러닝 모델의 성능을 높이기 위해서는 데이터를 잘 전처리해야 한다. 예를 들어
[안정적인 생성 결과]
.~ 이렇게▁해서▁만든▁것이▁바로▁‘알로하오’이다. ‘알로하이’는▁프랑스어로▁‘알레바(Allova)’의▁약자이다. 프랑스어로는▁‘알레르모(Alamo)’▁또는▁‘아르카(Arkar)’를▁뜻한다.
[다양한 생성 결과]
.∼ō 이▁중▁쩐의▁쫑▁(▁马宁▁)▁은▁쩐족인▁왕마오훙의▁이름을▁딴▁이름이다. 한자어로는▁쩐▁훙▁(▁红)으로▁쓰이고▁있다. 왕마오전자가
실습코드가 전혀 성능이 좋지않았다. 이유은 tokenizer 때문이었다.
앞서 모델과 토크나이저는 반드시 같은 모델 이름으로 불러와야 토크나이저가 만든 정수 id체계와 모델의 어휘사전이 서로 일치한다.라고 했었는데 해당 문제.
누리님이 예리하게 알아채서 공유했다. 결과 기록.

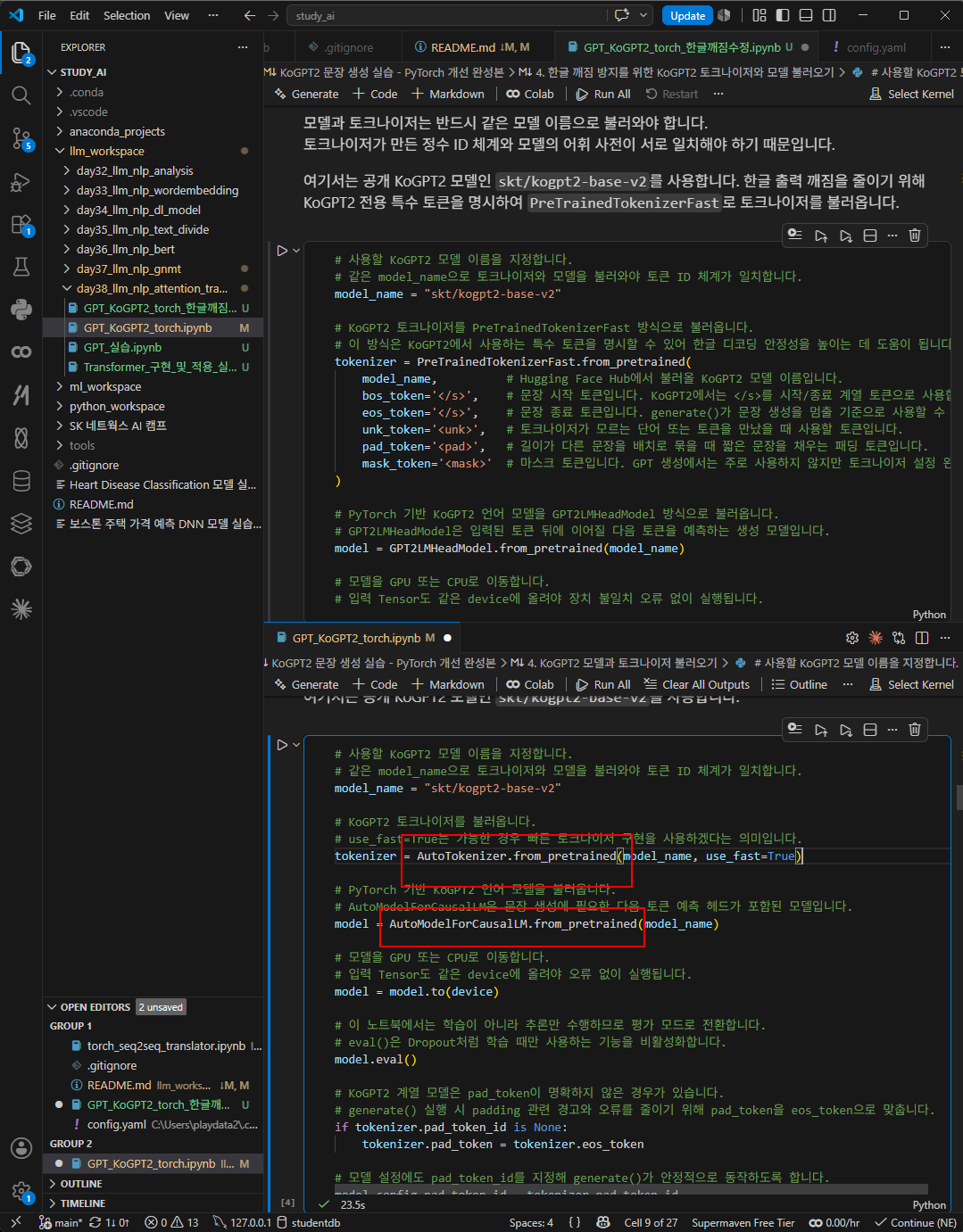
결과기록. 훨씬 나아졌다
시작 문장:
머신러닝 모델의 성능을 높이기 위해서는 데이터를 잘 전처리해야 한다. 예를 들어
[안정적인 생성 결과]
머신러닝 모델의 성능을 높이기 위해서는 데이터를 잘 전처리해야 한다. 예를 들어 컴퓨터에서 발생하는 데이터는 자동으로 처리되지만 이를 처리하는 소프트웨어는 매우 복잡하다. 만약 어떤 컴퓨터가 이 컴퓨터를 작동시키면 그 컴퓨터가 스스로 다른 컴퓨터로 신호를 보내도록 할 수 있다." 이런 점에서 인텔은 PC를 사용하는 데 있어서 가장 중요한 요소인 '데이터
[다양한 생성 결과]
머신러닝 모델의 성능을 높이기 위해서는 데이터를 잘 전처리해야 한다. 예를 들어 데이터 전송시간이 단축되는 모바일의 경우 이미 DB를 만들어 사용하고 있기 때문에 실시간 다운로드 품질을 확보하기 위한 기술이 반드시 필요하다. 또한 데이터 품질이 향상될수록 더 많은 데이터들이 쏟아져 나오기 때문이다. 예를 들면 인터넷에서 실시간 채팅을
실습코드 Transformer_구현_및_적용_실습.ipynb를 확인해보자.
실습환경 설치 학습루프를 간결하게 작성하기위한 pytorch-lightning, 정확도 계산을 위해 torchmetrics.
# Colab 또는 새 가상환경에서 PyTorch Lightning과 TorchMetrics가 없을 수 있으므로 설치합니다.
# -q 옵션은 설치 로그를 간단히 출력하게 하여 노트북 화면을 깔끔하게 유지합니다.
!pip install -q pytorch-lightning torchmetrics
import
torch.nn.functional softmax와 같은 함수형 신경망 연산을 사용하기 위해 f별칭 지정
tensordataset 여러개 텐서를 하나의 데이터셋으로 묶음
pytorch_lightning pl 학습과정을 단순화
tensorflow.keras.datasets imdb 영화리뷰 데이터셋을 불러오기 위해 tensorflow keras의 datasets 모듈 사용
tensorflow.keras.preprocessing,sequence pad_sequence 길이가 다른 시퀀스를 같은 길이로 맞추기 위한 pad_sequences
난수시드 고정
# 수치 계산과 배열 처리를 위해 NumPy를 불러옵니다.
import numpy as np
# PyTorch의 핵심 패키지인 torch를 불러옵니다.
import torch
# PyTorch 신경망 계층을 만들기 위해 torch.nn 모듈을 nn이라는 별칭으로 불러옵니다.
from torch import nn
# softmax와 같은 함수형 신경망 연산을 사용하기 위해 torch.nn.functional을 F라는 별칭으로 불러옵니다.
import torch.nn.functional as F
# 여러 개의 텐서를 하나의 데이터셋으로 묶기 위해 TensorDataset을 불러옵니다.
from torch.utils.data import TensorDataset
# 미니배치 단위로 데이터를 모델에 공급하기 위해 DataLoader를 불러옵니다.
from torch.utils.data import DataLoader
# 모델 파라미터를 업데이트하는 Adam 최적화 함수를 불러옵니다.
from torch.optim import Adam
# 학습 과정을 단순화하기 위해 PyTorch Lightning을 pl이라는 별칭으로 불러옵니다.
import pytorch_lightning as pl
# 분류 정확도를 계산하기 위해 torchmetrics의 Accuracy 클래스를 불러옵니다.
from torchmetrics.classification import Accuracy
# IMDB 영화 리뷰 데이터셋을 불러오기 위해 TensorFlow Keras의 datasets 모듈을 사용합니다.
from tensorflow.keras.datasets import imdb
# 길이가 서로 다른 문장 시퀀스를 같은 길이로 맞추기 위해 pad_sequences를 사용합니다.
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 실험 결과가 가능한 한 동일하게 나오도록 난수 시드를 고정합니다.
pl.seed_everything(42, workers=True)
self attenstion 구현
Query / Key / Value 생성하고 attention 계산, head별 결과 합친뒤 최종 출력 (B, L, D)한다.
d차원을 head마다 따로 만들기 위해 d*h 로 출력차원을 확장해 query, key, value생성.
unifyheads 통합 layer 생성. concat한뒤 원래 차원 d로 줄인다 .
forward() 각 head를 독립된 batch처럼 처리하기위해
queries WQ를 가져와 reshape, 문장길이 축과 head축을 바꿔 계산을 쉽게하고, contiguous() transpose후 메모리 배치를 연속적으로 만들어 view가 안전하게 동작하도록한다. 최종 view (b*h, l, d)
key도, value도.
attention_scores torch.bmm() 행렬을 행렬곱으로 계산해 토큰 간 관련도 점수를 구한다 . np.squrt(d)로 나눠 점수크기를 안정화하고 softmax가 한쪽으로 과도하게 쏠리는 문제를 줄인다. dot product 값이 너무 커지면 softmax가 “한쪽으로 쏠림” gradient 불안정해짐으로 인한 Transformer 핵심 공식
softmax() 각 토큰이 다른 토큰을 얼마나 볼지 확률화.
out = torch.bmm() attention 가중치를 value에 곱해 문맥 정보가 반영된 토큰 표현을 계산.
head축과 문장 길이축을 다시 원래 숫서로 바꾸고 다시 형태를 만든다. (b, l, h * d)
이 결과물 out을 unifyheads() 여러 head 결과를 하나로 압축해 embedding차원 d로 복원해 출력한다 .
# SelfAttention 클래스는 PyTorch의 모든 신경망 모듈이 상속하는 nn.Module을 상속합니다.
class SelfAttention(nn.Module):
# __init__ 메서드는 SelfAttention 계층에서 사용할 선형 변환 계층들을 초기화합니다.
def __init__(self, d: int, heads: int = 8):
# 부모 클래스인 nn.Module의 초기화 기능을 실행합니다.
super().__init__()
# d는 한 토큰을 표현하는 임베딩 벡터의 차원 수입니다.
self.d = d
# heads는 Multi-Head Attention에서 병렬로 사용할 attention head의 개수입니다.
self.h = heads
# 입력 벡터를 Query 벡터로 변환하는 선형 계층입니다.
# 출력 차원을 d * heads로 만들어 head별 Query를 한 번에 계산합니다.
self.WQ = nn.Linear(d, d * heads, bias=False)
# 입력 벡터를 Key 벡터로 변환하는 선형 계층입니다.
# Key는 Query와 내적되어 토큰 간 관련도 점수를 계산하는 데 사용됩니다.
self.WK = nn.Linear(d, d * heads, bias=False)
# 입력 벡터를 Value 벡터로 변환하는 선형 계층입니다.
# Value는 attention 가중치가 곱해져 최종 문맥 벡터를 만드는 데 사용됩니다.
self.WV = nn.Linear(d, d * heads, bias=False)
# 여러 head에서 나온 결과를 다시 하나의 d차원 벡터로 합치는 선형 계층입니다.
self.unifyheads = nn.Linear(heads * d, d)
# forward 메서드는 입력 텐서 x를 받아 Self-Attention 결과를 반환합니다.
def forward(self, x: torch.Tensor) -> torch.Tensor:
# x의 크기는 (배치 크기, 문장 길이, 임베딩 차원)입니다.
b, l, d = x.size()
# 현재 attention head 개수를 지역 변수 h에 저장하여 코드 가독성을 높입니다.
h = self.h
# 입력 x를 Query로 변환한 뒤 (b, l, h, d) 형태로 바꿉니다.
# transpose(1, 2)는 문장 길이 축과 head 축을 바꾸어 head별 계산을 쉽게 만듭니다.
# contiguous()는 transpose 후 메모리 배치를 연속적으로 만들어 view가 안전하게 동작하도록 합니다.
# 최종적으로 (b*h, l, d) 형태로 만들어 각 head를 독립 배치처럼 계산합니다.
queries = self.WQ(x).view(b, l, h, d).transpose(1, 2).contiguous().view(b * h, l, d)
# 입력 x를 Key로 변환하고 Query와 동일한 방식으로 (b*h, l, d) 형태로 정리합니다.
keys = self.WK(x).view(b, l, h, d).transpose(1, 2).contiguous().view(b * h, l, d)
# 입력 x를 Value로 변환하고 Query와 동일한 방식으로 (b*h, l, d) 형태로 정리합니다.
values = self.WV(x).view(b, l, h, d).transpose(1, 2).contiguous().view(b * h, l, d)
# Query와 Key의 전치 행렬을 배치 행렬곱으로 계산하여 토큰 간 관련도 점수를 구합니다.
# np.sqrt(d)로 나누어 점수 크기를 안정화하고 softmax가 한쪽으로 과도하게 쏠리는 문제를 줄입니다.
attention_scores = torch.bmm(queries, keys.transpose(1, 2)) / np.sqrt(d)
# 마지막 차원 기준으로 softmax를 적용하여 각 토큰이 다른 토큰을 얼마나 참고할지 확률 형태로 만듭니다.
attention_weights = F.softmax(attention_scores, dim=-1)
# attention 가중치를 Value에 곱하여 문맥 정보가 반영된 토큰 표현을 계산합니다.
out = torch.bmm(attention_weights, values).view(b, h, l, d)
# head 축과 문장 길이 축을 다시 원래 순서에 가깝게 바꿉니다.
# 이후 모든 head의 결과를 이어 붙여 (b, l, h*d) 형태로 만듭니다.
out = out.transpose(1, 2).contiguous().view(b, l, h * d)
# 이어 붙인 multi-head 결과를 선형 계층에 통과시켜 다시 d차원 표현으로 통합합니다.
return self.unifyheads(out)
즉
차원 바꿔서 계산 편하게 만든 다음 다시 원래 형태로 복구
torch.bmm = batch matrix multiplication (배치 행렬곱)
같은 연산을 배치 여러 개에 동시에 수행
A (D×D) × B (D×D) → (D×D)
head를 batch처럼 취급해서 bmm을 쓰기 위해 reshape했다.
BMM은 두번쓴다. 처음에는 점수계산, 두번째는 정보합성.
Multi-head attenstion은
head 1: Q1 K1 V1
head 2: Q2 K2 V2
head 3: Q3 K3 V3 각각 따로 for문으로 계산하면 느리니까
트릭으로 (B, L, H, D) → (B*H, L, D) batch로 착각시켜배치가 여러개인 일반 행렬곱으로 처리하는 것 .
torch.bmm은 “토큰 간 관계 계산(QK^T)과 정보 재조합(WV)을 batch 방식으로 빠르게 처리하는 핵심 연산”이고,
head를 batch처럼 바꾸는 이유는 “각 head를 독립적으로 동시에 계산하기 위해서”다
Transformer block은 self-attention으로 문장전체를 참고해 reidual + layernorm ->ffnn을 각 토큰 개별 변형을 한 뒤 또 reidual + laynorm - output의 순서이다 .
selft.attention() 다른 토큰들을 참고해서 나 자신을 업데이트 했다.
d, embedding 차원으로 layernorm. 각 토큰 d차원 벡터마다 정규화를 시키는것 . 따로따로 평균, 분산을 맞춰학습 폭주를 방지해 각 토큰 백터 내부값 스케일을 안정화하는 것이다 .
d차원과 n_mlp 받은 값을 * 해서 차원을 이부러 키워 linear() 표현을 확장하혀는것. 작은신경망. 중간에서 생각공간을 확장한것이다. fnn은 각 토큰을 따로 처리한다 .
relu로 비선형성을 추가하며 중요한 특징만 살리고
forward()
attention 문장 전체를 섞고, reisual+norm 즉 원본화 변화를 합쳐 안정화시킨다.
ff() 각 토큰 내부를 재처리한다.
# TransformerBlock 클래스는 하나의 Transformer 인코더 블록을 구현합니다.
class TransformerBlock(nn.Module):
# __init__ 메서드는 Self-Attention, LayerNorm, FFNN 계층을 초기화합니다.
def __init__(self, d: int, heads: int = 8, n_mlp: int = 4):
# 부모 클래스인 nn.Module의 초기화 기능을 실행합니다.
super().__init__()
# SelfAttention 모듈을 생성하여 입력 토큰 간 문맥 관계를 계산하도록 합니다.
self.attention = SelfAttention(d, heads=heads)
# 첫 번째 LayerNorm은 attention 결과와 원래 입력을 더한 뒤 분포를 안정화합니다.
self.norm1 = nn.LayerNorm(d)
# 두 번째 LayerNorm은 FFNN 결과와 이전 입력을 더한 뒤 분포를 안정화합니다.
self.norm2 = nn.LayerNorm(d)
# Feed Forward Neural Network는 각 토큰 위치마다 독립적으로 적용되는 작은 완전연결 신경망입니다.
self.ff = nn.Sequential(
# 첫 번째 선형 계층은 d차원 표현을 n_mlp*d차원으로 확장하여 더 풍부한 특징을 학습합니다.
nn.Linear(d, n_mlp * d),
# ReLU 활성화 함수는 비선형성을 추가하여 복잡한 패턴을 학습하게 합니다.
nn.ReLU(),
# 두 번째 선형 계층은 확장된 특징을 다시 d차원으로 축소하여 블록 출력 크기를 입력과 맞춥니다.
nn.Linear(n_mlp * d, d),
)
# forward 메서드는 입력 x를 Transformer Block에 통과시킵니다.
def forward(self, x: torch.Tensor) -> torch.Tensor:
# Self-Attention을 적용하여 각 토큰이 문장 안의 다른 토큰을 참고한 표현을 만듭니다.
x_prime = self.attention(x)
# Residual Connection으로 attention 결과와 원래 입력을 더하고 LayerNorm을 적용합니다.
x = self.norm1(x_prime + x)
# Feed Forward Neural Network를 적용하여 토큰별 표현을 추가로 변환합니다.
x_prime = self.ff(x)
# FFNN 결과와 입력을 다시 더한 뒤 LayerNorm을 적용하여 최종 블록 출력을 반환합니다.
return self.norm2(x_prime + x)
IMDBDataLoader
init() 설정저장 한번에 몇개학습할지, batch_size, 사용할 단어갯수 제한의 num_words, 문장길이 고정의 max_seq_len, 할당받은 train_samples수에 맞춰 실습시간을 줄이기 위한 방법을 세팅, 기본값은 5000, 사용할 테스트 샘플 개수도 마찬가지, 기본값은 2000.
setup() imdb.load_data keras에서 제공하는 IMDB 영화 리뷰 데이터 불러오기
지정된 갯수만큼 자르기
imdb.get_word_index() "good" → 1234 이러한 사전이 이미 있으니 가져다 쓴다. 위 raw_word2idx를 저장. word: index + 3 0~3은 pad, start, unk, unused로 예약될것이니 word는 index가 4부터 시작한다. 새로 저장된 사전에 특수토큰 추가. 인덱스를 다시 단어로 바꾸기 위한 역방향 사전도 만듬
정의한 pad_sequences로 x_train과 x_test에 pad 적용. torch.longTensor로 변환.
example() 학습데이터중 하나의 인덱스를 무작위로 random.randint 선택해 x, y가져와 특수토큰을 제외하고 정수인덱스를 단어로 변환한다.
1이면 긍정 아니면 부정으로 표시하는 sentiment 변수 초기화.
return.
train_dataloader() TensorDataset 학습입력과 정답을 하나의 tensordataset으로 묶는다 return.
val_dataloader() 도, test_dataloader도.
# IMDBDataLoader 클래스는 PyTorch Lightning의 DataModule을 상속하여 데이터 준비 과정을 모듈화합니다.
class IMDBDataLoader(pl.LightningDataModule):
# __init__ 메서드는 데이터 로딩에 필요한 하이퍼파라미터를 저장합니다.
def __init__(self, batch_size: int, num_words: int, max_seq_len: int, train_samples: int | None = 5000, test_samples: int | None = 2000):
# 부모 클래스인 LightningDataModule의 초기화 기능을 실행합니다.
super().__init__()
# 한 번의 학습 단계에서 사용할 샘플 개수인 배치 크기를 저장합니다.
self.batch_size = batch_size
# 사용할 단어 사전 크기를 저장합니다.
self.num_words = num_words
# 각 리뷰 문장을 맞출 최대 시퀀스 길이를 저장합니다.
self.max_seq_len = max_seq_len
# 실습 시간을 줄이기 위해 사용할 학습 샘플 개수를 저장합니다.
# 전체 데이터를 사용하려면 None으로 설정하면 됩니다.
self.train_samples = train_samples
# 실습 시간을 줄이기 위해 사용할 테스트 샘플 개수를 저장합니다.
# 전체 데이터를 사용하려면 None으로 설정하면 됩니다.
self.test_samples = test_samples
# setup 메서드는 실제 데이터를 다운로드하고 전처리합니다.
def setup(self, stage: str | None = None):
# Keras에서 제공하는 IMDB 영화 리뷰 데이터를 불러옵니다.
# num_words는 빈도 상위 num_words개 단어만 사용하도록 제한합니다.
(x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=self.num_words)
# 실습 속도를 높이기 위해 지정된 개수만큼 학습 데이터를 잘라 사용합니다.
if self.train_samples is not None:
x_train = x_train[:self.train_samples]
y_train = y_train[:self.train_samples]
# 실습 속도를 높이기 위해 지정된 개수만큼 테스트 데이터를 잘라 사용합니다.
if self.test_samples is not None:
x_test = x_test[:self.test_samples]
y_test = y_test[:self.test_samples]
# 단어에서 정수 인덱스로 가는 사전을 불러옵니다.
raw_word2idx = imdb.get_word_index()
# Keras IMDB 데이터는 0, 1, 2, 3번 인덱스를 특수 토큰으로 사용하므로 기존 인덱스에 3을 더합니다.
self.word2idx = {word: index + 3 for word, index in raw_word2idx.items()}
# padding, 시작, 알 수 없는 단어, 미사용 토큰에 해당하는 특수 토큰을 사전에 추가합니다.
self.word2idx.update({'<PAD>': 0, '<START>': 1, '<UNK>': 2, '<UNUSED>': 3})
# 정수 인덱스를 다시 단어로 바꾸기 위해 역방향 사전을 만듭니다.
self.idx2word = {index: word for word, index in self.word2idx.items()}
# 학습 리뷰의 길이를 max_seq_len으로 맞춥니다.
# 짧은 문장은 앞쪽에 0을 채우고, 긴 문장은 앞쪽을 잘라 마지막 max_seq_len개 토큰만 사용합니다.
x_train = pad_sequences(x_train, maxlen=self.max_seq_len, value=0, padding='pre', truncating='pre')
# 테스트 리뷰도 학습 데이터와 동일한 방식으로 길이를 맞춥니다.
x_test = pad_sequences(x_test, maxlen=self.max_seq_len, value=0, padding='pre', truncating='pre')
# NumPy 배열을 PyTorch LongTensor로 변환하여 임베딩 계층에 입력할 수 있게 합니다.
self.x_train = torch.LongTensor(x_train)
# 정답 레이블도 CrossEntropyLoss가 요구하는 LongTensor 형태로 변환합니다.
self.y_train = torch.LongTensor(y_train)
# 테스트 입력도 PyTorch LongTensor로 변환합니다.
self.x_test = torch.LongTensor(x_test)
# 테스트 정답도 PyTorch LongTensor로 변환합니다.
self.y_test = torch.LongTensor(y_test)
# example 메서드는 전처리된 정수 시퀀스를 사람이 읽을 수 있는 리뷰 문장으로 복원해 확인합니다.
def example(self) -> str:
# 학습 데이터 중 하나의 인덱스를 무작위로 선택합니다.
idx = np.random.randint(0, len(self.x_train))
# 선택한 인덱스에 해당하는 입력 시퀀스와 정답 레이블을 가져옵니다.
x, y = self.x_train[idx], self.y_train[idx]
# padding 토큰과 특수 토큰을 제외하고 정수 인덱스를 단어로 변환합니다.
review = ' '.join(self.idx2word.get(int(token_id), '<UNK>') for token_id in x if int(token_id) > 3)
# 레이블이 1이면 긍정, 0이면 부정으로 표시합니다.
sentiment = 'POSITIVE' if int(y) == 1 else 'NEGATIVE'
# 복원된 리뷰와 감성 레이블을 문자열로 반환합니다.
return f'Review : {review}\nSentiment: {sentiment}'
# train_dataloader 메서드는 학습용 DataLoader를 반환합니다.
def train_dataloader(self):
# 학습 입력과 정답을 하나의 TensorDataset으로 묶습니다.
dataset = TensorDataset(self.x_train, self.y_train)
# DataLoader를 만들어 미니배치 단위로 데이터를 섞어서 공급합니다.
return DataLoader(dataset, batch_size=self.batch_size, shuffle=True, num_workers=2, persistent_workers=True)
# val_dataloader 메서드는 검증용 DataLoader를 반환합니다.
def val_dataloader(self):
# 테스트 입력과 정답을 검증 데이터로 사용하기 위해 TensorDataset으로 묶습니다.
dataset = TensorDataset(self.x_test, self.y_test)
# 검증 단계에서는 결과 비교를 위해 데이터를 섞지 않습니다.
return DataLoader(dataset, batch_size=self.batch_size, shuffle=False, num_workers=2, persistent_workers=True)
# test_dataloader 메서드는 테스트용 DataLoader를 반환합니다.
def test_dataloader(self):
# 테스트 입력과 정답을 TensorDataset으로 묶습니다.
dataset = TensorDataset(self.x_test, self.y_test)
# 테스트 단계에서도 데이터를 섞지 않고 순서대로 평가합니다.
return DataLoader(dataset, batch_size=self.batch_size, shuffle=False, num_workers=2, persistent_workers=True)
IMDBTransformer() transformer를 직접 구현해보자.
__init__()
embedding을 지원한느 값 d,
attention head의 개수 heads
transformer 블록개수 depth,
최대문장길이 max_seq_len과 단어사전크기 num_tokens, 출력클래스 층 num_classes, 학습률인 learning_rate.
이 파라미터들은 self.save_jyperparameters()를 통해 로그용으로 자동저장하도록 한다 .
사용할 단어사전크기 저장.
token_emb = nn.embedding(num_tokens, d) d차원의 단어 임베딩 벡터로 변환한다.
pos_emb = nn.Embedding(max_seq_len, d) Transformer는 RNN처럼 순서를 처리하지않음으로 위치정보가 반드시 필요하니 정의.
depth만큼 순서대로 쌓아 Transformer 모델을 구성한다 .
classification, nn.linear()로 긍정/부정 점수로 변환하는 분류층 정의.
criteriton 손실함수정의. train, val, test 각기의 Accuray 구성.
forward()
x의 크기를 받아 배치크기와 문장길이 정의.
차원 d는 hparams.d에서 가져온다 .
x를 임베딩 벡터로 변환해 tokens.
torch.arange()로 문장길이까지의 위치인덱스 숫자를 생성.
위치를 임베딩 벡터로 변환. pos_emb()한뒤 unsqueeze() 확장한뒤 token과 같이 b, l, d 형식으로 바꿈
위 정의한 tokens와 positions를 합해 embeddings를 만듬
여러개의 transformer_blocks()에 임베딩을 통과시켜 out.
out의 평균값을 내어각 출력을 요약.
classification() 분류층에 통과시켜 각 클래스에대한 점수 logits를 계산한다.
return out
configure_optimizers() adam 함수 return. 이때 self.parameters와 hparams의 learning_rate를 사용함.
training_step()
batch에서 입력 x와 정답 y를 분리, 모델에 입력 x를 넣고 클래스별 점수 logits계산.
loss도 계산. criterion()
perds에는 torch.argmax() 가장 큰 점수를 가진 클래슬르 인덱스 예측값으로 선택
acc 정확도 계산 train_accuracy()
return loss
validation_step()
마찬가지로 batch 에서 x, y분리
logits, loss, preds, acc 계산.
test_step() 도 마찬가지.
# IMDBTransformer 클래스는 IMDB 감성분석을 위한 Transformer 기반 분류 모델입니다.
class IMDBTransformer(pl.LightningModule):
# __init__ 메서드는 모델 구조와 학습 설정을 초기화합니다.
def __init__(
self,
d: int = 128,
heads: int = 8,
depth: int = 4,
max_seq_len: int = 128,
num_tokens: int = 10000,
num_classes: int = 2,
learning_rate: float = 1e-4,
):
# 부모 클래스인 LightningModule의 초기화 기능을 실행합니다.
super().__init__()
# 전달받은 하이퍼파라미터를 self.hparams에 자동 저장하여 로그와 체크포인트에서 확인할 수 있게 합니다.
self.save_hyperparameters()
# 사용할 단어 사전 크기를 저장합니다.
self.num_tokens = num_tokens
# 정수 토큰 ID를 d차원의 단어 임베딩 벡터로 변환하는 계층입니다.
self.token_emb = nn.Embedding(num_tokens, d)
# 각 위치 인덱스를 d차원의 위치 임베딩 벡터로 변환하는 계층입니다.
# Transformer는 RNN처럼 순서대로 처리하지 않기 때문에 위치 정보가 반드시 필요합니다.
self.pos_emb = nn.Embedding(max_seq_len, d)
# 여러 개의 TransformerBlock을 순서대로 쌓아 깊은 Transformer 모델을 구성합니다.
self.transformer_blocks = nn.Sequential(
# depth 개수만큼 TransformerBlock을 생성하여 리스트로 만든 뒤 nn.Sequential에 전달합니다.
*[TransformerBlock(d=d, heads=heads) for _ in range(depth)]
)
# 평균 풀링으로 만든 문장 벡터를 긍정/부정 클래스 점수로 변환하는 선형 분류층입니다.
self.classification = nn.Linear(d, num_classes)
# 다중 클래스 분류 손실 함수입니다.
# 이진 분류도 클래스가 2개인 다중 클래스 문제로 처리할 수 있습니다.
self.criterion = nn.CrossEntropyLoss()
# 학습 정확도를 계산하는 TorchMetrics 객체입니다.
self.train_accuracy = Accuracy(task='multiclass', num_classes=num_classes)
# 검증 정확도를 계산하는 TorchMetrics 객체입니다.
self.val_accuracy = Accuracy(task='multiclass', num_classes=num_classes)
# 테스트 정확도를 계산하는 TorchMetrics 객체입니다.
self.test_accuracy = Accuracy(task='multiclass', num_classes=num_classes)
# forward 메서드는 입력 토큰 시퀀스를 받아 클래스별 점수 logits를 반환합니다.
def forward(self, x: torch.LongTensor) -> torch.FloatTensor:
# x의 크기는 (배치 크기, 문장 길이)입니다.
b, l = x.size()
# 임베딩 차원 d를 하이퍼파라미터에서 가져옵니다.
d = self.hparams.d
# 입력 정수 토큰 ID를 단어 임베딩 벡터로 변환합니다.
tokens = self.token_emb(x)
# 0부터 문장 길이 l-1까지의 위치 인덱스를 생성합니다.
position_ids = torch.arange(l, device=self.device)
# 위치 인덱스를 위치 임베딩 벡터로 변환합니다.
positions = self.pos_emb(position_ids)
# 위치 임베딩을 배치 크기만큼 확장하여 tokens와 같은 크기인 (b, l, d)로 만듭니다.
positions = positions.unsqueeze(0).expand(b, l, d)
# 단어 임베딩과 위치 임베딩을 더하여 의미 정보와 순서 정보를 모두 가진 입력 표현을 만듭니다.
embeddings = tokens + positions
# 임베딩 표현을 여러 개의 Transformer Block에 통과시켜 문맥이 반영된 토큰 표현을 얻습니다.
out = self.transformer_blocks(embeddings)
# 문장 길이 차원(dim=1)을 평균 내어 토큰별 출력들을 하나의 문장 벡터로 요약합니다.
out = out.mean(dim=1)
# 문장 벡터를 분류층에 통과시켜 각 클래스에 대한 점수 logits를 계산합니다.
out = self.classification(out)
# softmax 전의 클래스 점수 logits를 반환합니다.
return out
# configure_optimizers 메서드는 학습에 사용할 최적화 함수를 정의합니다.
def configure_optimizers(self):
# Adam은 학습률을 적응적으로 조절하여 신경망 학습에 널리 사용되는 최적화 함수입니다.
return Adam(self.parameters(), lr=self.hparams.learning_rate)
# training_step 메서드는 학습 배치 하나에 대한 손실과 정확도를 계산합니다.
def training_step(self, batch, batch_idx):
# batch에서 입력 x와 정답 y를 분리합니다.
x, y = batch
# 모델에 입력 x를 넣어 클래스별 점수 logits를 계산합니다.
logits = self(x)
# logits와 정답 y를 비교하여 CrossEntropyLoss를 계산합니다.
loss = self.criterion(logits, y)
# logits에서 가장 큰 점수를 가진 클래스 인덱스를 예측값으로 선택합니다.
preds = torch.argmax(logits, dim=1)
# 예측값과 정답을 비교하여 학습 정확도를 계산합니다.
acc = self.train_accuracy(preds, y)
# 학습 손실을 진행 막대와 로그에 기록합니다.
self.log('train_loss', loss, on_step=False, on_epoch=True, prog_bar=True)
# 학습 정확도를 진행 막대와 로그에 기록합니다.
self.log('train_acc', acc, on_step=False, on_epoch=True, prog_bar=True)
# PyTorch Lightning이 역전파에 사용할 손실값을 반환합니다.
return loss
# validation_step 메서드는 검증 배치 하나에 대한 손실과 정확도를 계산합니다.
def validation_step(self, batch, batch_idx):
# batch에서 입력 x와 정답 y를 분리합니다.
x, y = batch
# 모델에 입력 x를 넣어 클래스별 점수 logits를 계산합니다.
logits = self(x)
# logits와 정답 y를 비교하여 검증 손실을 계산합니다.
loss = self.criterion(logits, y)
# 가장 높은 점수의 클래스를 검증 예측값으로 선택합니다.
preds = torch.argmax(logits, dim=1)
# 검증 예측값과 정답을 비교하여 정확도를 계산합니다.
acc = self.val_accuracy(preds, y)
# 검증 손실을 진행 막대와 로그에 기록합니다.
self.log('val_loss', loss, on_step=False, on_epoch=True, prog_bar=True)
# 검증 정확도를 진행 막대와 로그에 기록합니다.
self.log('val_acc', acc, on_step=False, on_epoch=True, prog_bar=True)
# 검증 손실을 반환합니다.
return loss
# test_step 메서드는 테스트 배치 하나에 대한 손실과 정확도를 계산합니다.
def test_step(self, batch, batch_idx):
# batch에서 입력 x와 정답 y를 분리합니다.
x, y = batch
# 모델에 입력 x를 넣어 클래스별 점수 logits를 계산합니다.
logits = self(x)
# logits와 정답 y를 비교하여 테스트 손실을 계산합니다.
loss = self.criterion(logits, y)
# 가장 높은 점수의 클래스를 테스트 예측값으로 선택합니다.
preds = torch.argmax(logits, dim=1)
# 테스트 예측값과 정답을 비교하여 정확도를 계산합니다.
acc = self.test_accuracy(preds, y)
# 테스트 손실을 로그에 기록합니다.
self.log('test_loss', loss, on_step=False, on_epoch=True)
# 테스트 정확도를 진행 막대와 로그에 기록합니다.
self.log('test_acc', acc, on_step=False, on_epoch=True, prog_bar=True)
# 테스트 손실을 반환합니다.
return loss
모델 학습전 각각 파라미터 값 할당
파라미터 값으로 IMDBDataLoader 객체를 생성해 데이터 준비.
setup() 데이터를 다운로드하고 전처리.
example() 하나를 단어 문장으로 복원해 준비가 잘 되었는지 확인
# 사용할 단어 사전 크기를 지정합니다.
NUM_WORDS = 10000
# 각 리뷰 문장을 최대 128개 토큰으로 맞춥니다.
MAX_SEQ_LEN = 128
# 각 토큰을 128차원 임베딩 벡터로 표현합니다.
EMBEDDING_DIM = 128
# 한 번에 32개 리뷰를 학습에 사용합니다.
BATCH_SIZE = 32
# 실습 시간을 고려하여 학습 데이터 일부만 사용합니다.
# 전체 데이터를 사용하려면 TRAIN_SAMPLES = None으로 바꾸면 됩니다.
TRAIN_SAMPLES = 5000
# 실습 시간을 고려하여 테스트 데이터 일부만 사용합니다.
# 전체 데이터를 사용하려면 TEST_SAMPLES = None으로 바꾸면 됩니다.
TEST_SAMPLES = 2000
# 최대 학습 epoch 수를 지정합니다.
MAX_EPOCHS = 5
# IMDBDataLoader 객체를 생성하여 데이터 준비 설정을 저장합니다.
imdb_data = IMDBDataLoader(
batch_size=BATCH_SIZE,
num_words=NUM_WORDS,
max_seq_len=MAX_SEQ_LEN,
train_samples=TRAIN_SAMPLES,
test_samples=TEST_SAMPLES,
)
# setup을 직접 호출하여 데이터를 다운로드하고 전처리합니다.
imdb_data.setup()
# 전처리된 리뷰 하나를 단어 문장으로 복원하여 데이터가 정상적으로 준비되었는지 확인합니다.
print(imdb_data.example())
정의한 함수로 transformer 객체 생성
Trainer() 모델 학습 루프 epochs, batch, backprop, validation등을 자동으로 수행해주는 엔진을 활용해 수행.
trainer.fit() 학습.
# IMDB 감성분석용 Transformer 모델 객체를 생성합니다.
model = IMDBTransformer(
d=EMBEDDING_DIM,
heads=8,
depth=4,
max_seq_len=MAX_SEQ_LEN,
num_tokens=NUM_WORDS,
num_classes=2,
learning_rate=1e-4,
)
# GPU가 있으면 GPU를 사용하고, 없으면 CPU를 사용하도록 accelerator='auto'로 설정합니다.
trainer = pl.Trainer(
max_epochs=MAX_EPOCHS,
accelerator='auto',
devices='auto',
log_every_n_steps=10,
)
# trainer.fit은 학습 데이터로 모델을 훈련하고 검증 데이터로 성능을 확인합니다.
trainer.fit(model, datamodule=imdb_data)INFO:pytorch_lightning.utilities.rank_zero:GPU available: False, used: False
INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores
INFO:pytorch_lightning.utilities.rank_zero:💡 Tip: For seamless cloud logging and experiment tracking, try installing [litlogger](https://pypi.org/project/litlogger/) to enable LitLogger, which logs metrics and artifacts automatically to the Lightning Experiments platform.
INFO:pytorch_lightning.utilities.rank_zero:💡 Tip: For seamless cloud uploads and versioning, try installing [litmodels](https://pypi.org/project/litmodels/) to enable LitModelCheckpoint, which syncs automatically with the Lightning model registry.┏━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┳━━━━━━━┓
┃ ┃ Name ┃ Type ┃ Params ┃ Mode ┃ FLOPs ┃
┡━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━╇━━━━━━━┩
│ 0 │ token_emb │ Embedding │ 1.3 M │ train │ 0 │
│ 1 │ pos_emb │ Embedding │ 16.4 K │ train │ 0 │
│ 2 │ transformer_blocks │ Sequential │ 2.6 M │ train │ 0 │
│ 3 │ classification │ Linear │ 258 │ train │ 0 │
│ 4 │ criterion │ CrossEntropyLoss │ 0 │ train │ 0 │
│ 5 │ train_accuracy │ MulticlassAccuracy │ 0 │ train │ 0 │
│ 6 │ val_accuracy │ MulticlassAccuracy │ 0 │ train │ 0 │
│ 7 │ test_accuracy │ MulticlassAccuracy │ 0 │ train │ 0 │
└───┴────────────────────┴────────────────────┴────────┴───────┴───────┘Trainable params: 3.9 M
Non-trainable params: 0
Total params: 3.9 M
Total estimated model params size (MB): 15.693
Modules in train mode: 56
Modules in eval mode: 0
Total FLOPs: 0
/usr/local/lib/python3.12/dist-packages/pytorch_lightning/utilities/_pytree.py:21: `isinstance(treespec, LeafSpec)`
is deprecated, use `isinstance(treespec, TreeSpec) and treespec.is_leaf()` instead.INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=5` reached.
trainer.test() 평가
# trainer.test는 test_dataloader에서 제공하는 데이터로 최종 성능을 평가합니다.
test_result = trainer.test(model, datamodule=imdb_data)
# 테스트 결과 딕셔너리를 출력하여 test_loss와 test_acc를 확인합니다.
print(test_result)┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Test metric ┃ DataLoader 0 ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ test_acc │ 0.722000002861023 │
│ test_loss │ 0.5895406007766724 │
└───────────────────────────┴───────────────────────────┘
[{'test_loss': 0.5895406007766724, 'test_acc': 0.722000002861023}]
predict_review()
model.eval() 평가모드로 전환.
전달받은 review_text를 소문자로, 공백기준으로 단어를 나눈다. 이것을 단어사전에 있는 정수 id로 바꾸며 없다면 unk인 2로 설정한다.
만일 token_id가 data_module.num_words 크기를 넘어버리면 unk로 바꾼다.
pad_sequences() padding 값 지정.
padded 값을 longtensor로 변환해 x에 저장.
장치이동. model()를 통과해 logits를 계산. 클래스별 점수.
softmax를 사용해 클래스별 확률로 변환해 torch.argmax() 큰 확률을 가진 클래스를 예측값으로 선택.
label지정. 1이면 긍정, 아니면 부정.
return.
# predict_review 함수는 새로운 리뷰 문장을 입력받아 긍정/부정 예측 결과를 반환합니다.
def predict_review(review_text: str, model: IMDBTransformer, data_module: IMDBDataLoader) -> str:
# 모델을 평가 모드로 전환하여 Dropout/BatchNorm 등이 평가 방식으로 동작하게 합니다.
model.eval()
# 입력 문장을 소문자로 바꾸고 공백 기준으로 단어를 나눕니다.
words = review_text.lower().split()
# 각 단어를 IMDB 단어 사전의 정수 ID로 바꿉니다.
# 사전에 없는 단어는 <UNK>에 해당하는 2번 ID로 처리합니다.
token_ids = [data_module.word2idx.get(word, 2) for word in words]
# 모델의 단어 사전 크기를 넘는 토큰은 <UNK>로 바꾸어 임베딩 범위 오류를 방지합니다.
token_ids = [token_id if token_id < data_module.num_words else 2 for token_id in token_ids]
# 입력 토큰 시퀀스를 학습 때와 같은 길이로 padding/truncating 처리합니다.
padded = pad_sequences([token_ids], maxlen=data_module.max_seq_len, value=0, padding='pre', truncating='pre')
# NumPy 배열을 PyTorch LongTensor로 변환합니다.
x = torch.LongTensor(padded)
# 입력 텐서를 모델이 위치한 장치로 이동합니다.
x = x.to(model.device)
# 예측 과정에서는 기울기 계산이 필요 없으므로 torch.no_grad()를 사용합니다.
with torch.no_grad():
# 모델에 입력을 넣어 클래스별 점수 logits를 계산합니다.
logits = model(x)
# softmax를 적용하여 클래스별 확률로 변환합니다.
probs = torch.softmax(logits, dim=1)
# 가장 높은 확률을 가진 클래스를 예측값으로 선택합니다.
pred = torch.argmax(probs, dim=1).item()
# 예측 클래스가 1이면 긍정, 0이면 부정으로 해석합니다.
label = 'POSITIVE' if pred == 1 else 'NEGATIVE'
# 긍정 클래스 확률을 추출합니다.
positive_prob = probs[0, 1].item()
# 최종 예측 결과 문자열을 반환합니다.
return f'예측 결과: {label}, 긍정 확률: {positive_prob:.4f}'
# 긍정적인 의미의 예시 리뷰를 모델에 입력하여 예측 결과를 확인합니다.
print(predict_review('this movie was great and very interesting', model, imdb_data))
# 부정적인 의미의 예시 리뷰를 모델에 입력하여 예측 결과를 확인합니다.
print(predict_review('this movie was boring and terrible', model, imdb_data))예측 결과: POSITIVE, 긍정 확률: 0.9987
예측 결과: NEGATIVE, 긍정 확률: 0.4389
Seq2Seq = 입력 시퀀스 → 출력 시퀀스 구조
이번엔 어제 다뤘던 Seq2Seq 구조를 GRU를 이용해서 Encoder / Decoder를 만들어 구현한 Seq2Seq 번역 프로젝트를 Transformer로 바꿔보자.
Seq2Seq는 구조적으로 입력길이와 출력길이가 달라도 번역을 하는것 .
GRU는 RNN 개선형으로 긴문장에서 앞 정보가 사라지는 문제를 해결했다. 문장을 읽어서 의미를 압축해보낸다.
Encoder (GRU) → context vector → Decoder (GRU)
Seq2Seq는 입력-출력 시퀀스 문제 구조
현재 Seq2Seq 엔진들에는 RNN계열 GRU/LSTM, CNN 계열 ConvSeq2Seq, Transformer기준 Attention 기반 Seq2Seq가 있다 .
config에서 우선 hidden_size라는 개념이 transformer에서 없음으로 없애고,
차원, head, layer, dropout을 추가했다.

model.py는 아예 새로 구현해야했다.
RNN처럼 순서가 없는 Transformer는 positionㅣㅇ 필요함으로 torch.zero()를 할용해 pos를 만들어 대입 .
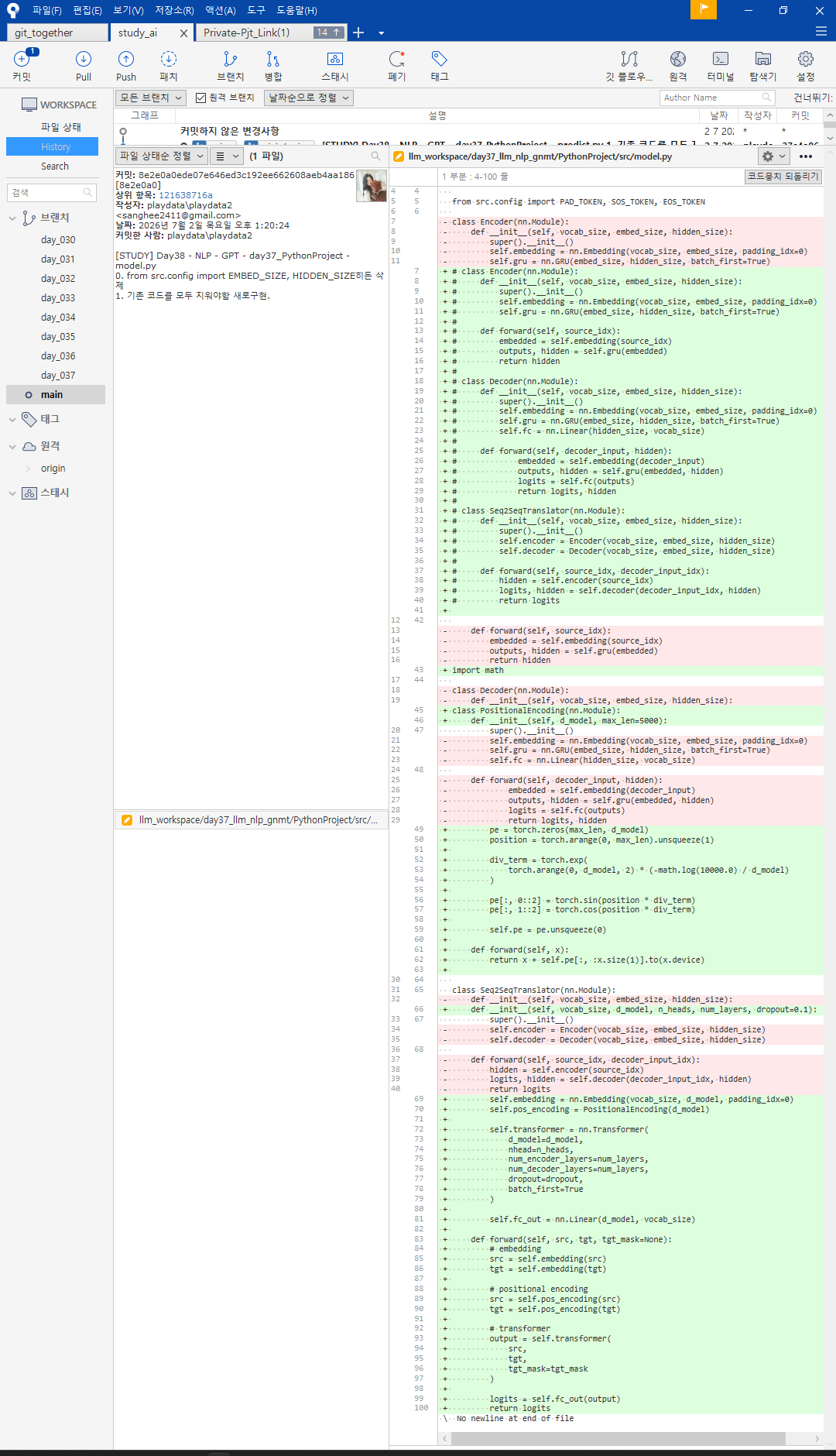
train.py에서 모델 생성 부분만 수정한다.
추가한 파라미터를 정의해주고 hidden_state는 없애준다.
nn.transformer(), forward()해 logits return.
transformer는 mask를 활용함으로 forward시 mask를 생성해 할당해 logits에 함께 태워 보낸다.
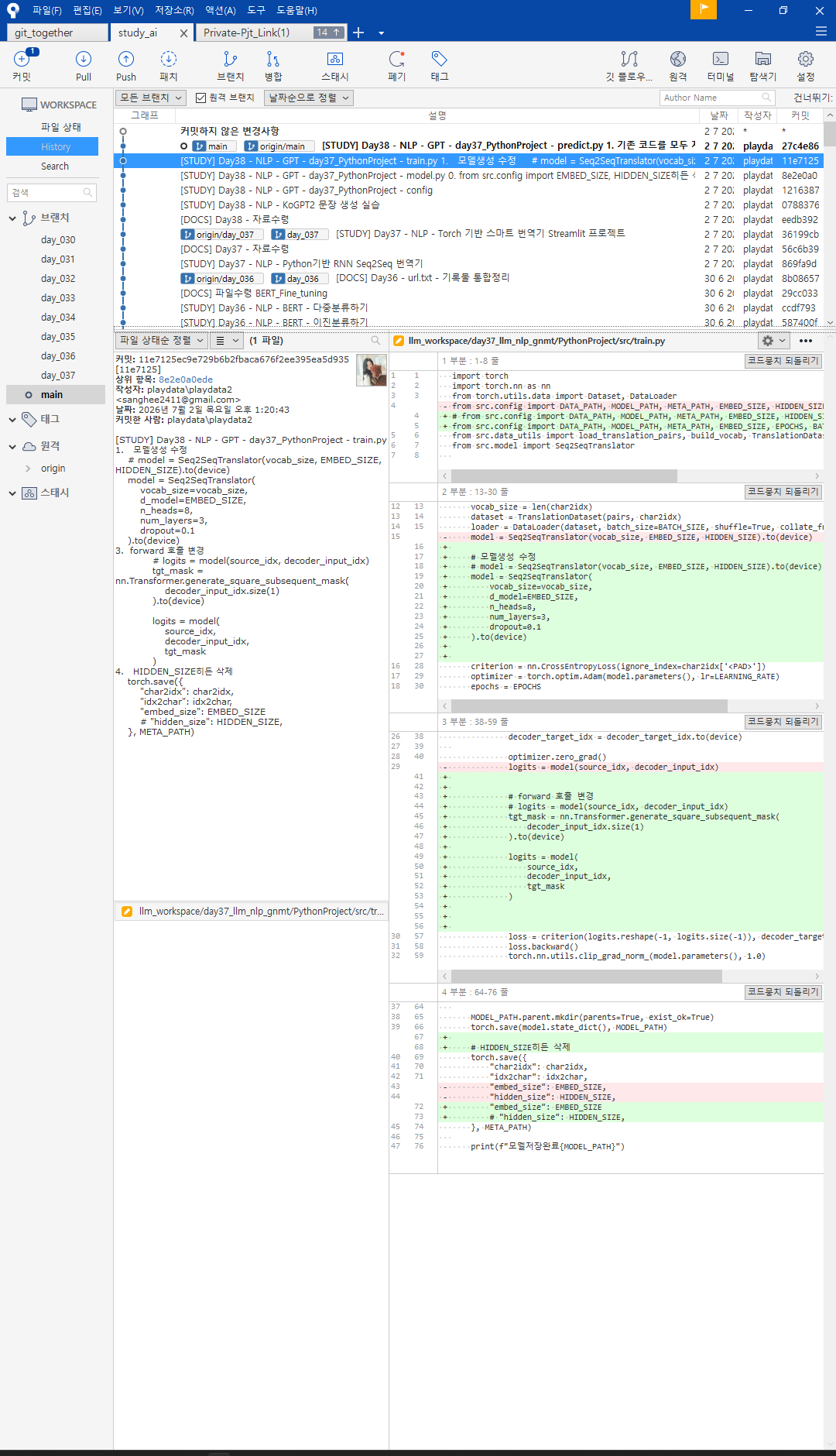
predict.py도 새로 구현해야했다 .
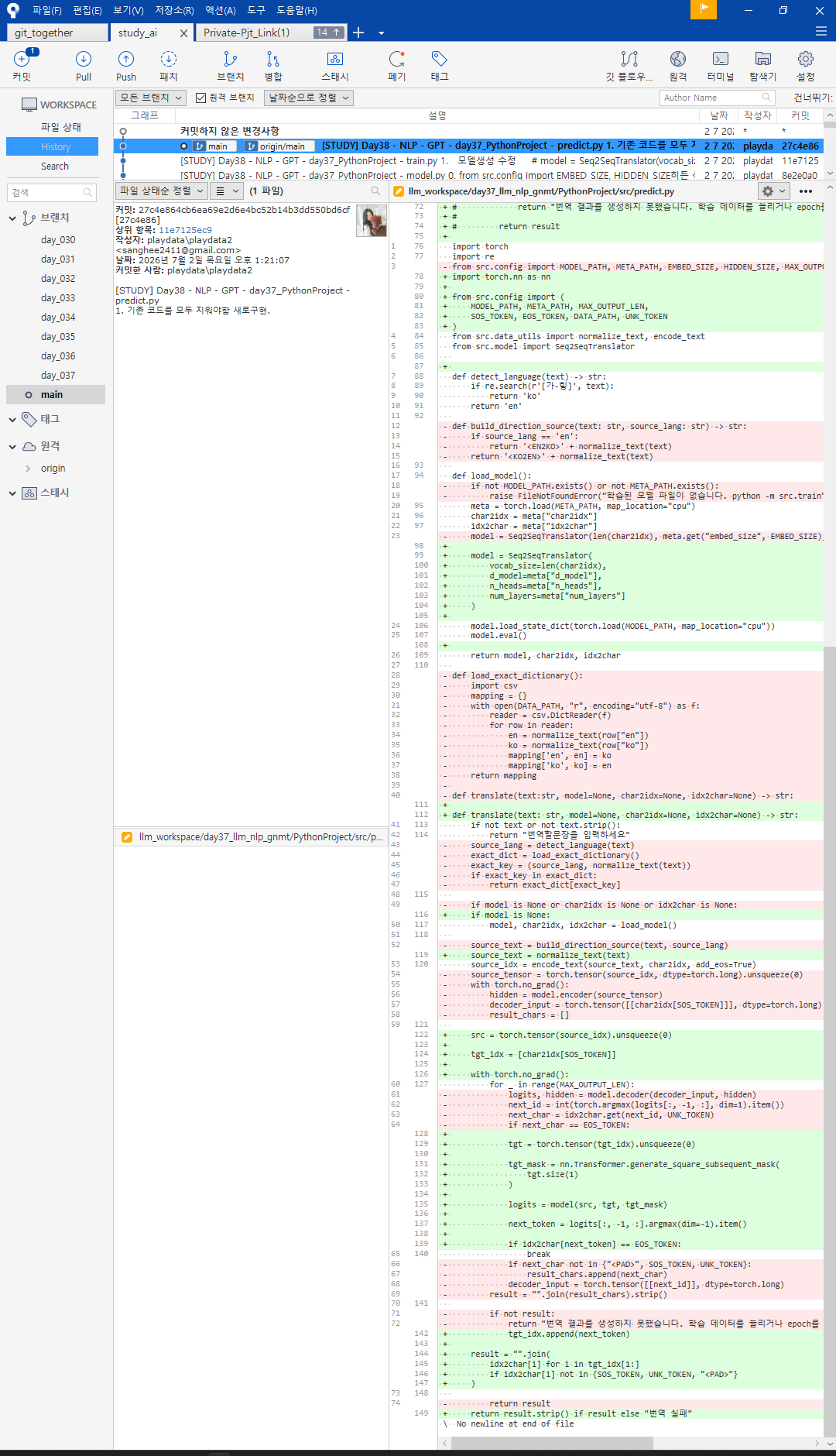
결과기록

앞서 살펴본 GPT_KoGPT2_torch_한글깨짐수정.ipynb로 chatbot을 만든 샘플 프로젝트를 분석해보자.
config
kogpt2를 사용하고, 외 사용할 파라미터를 정의한다.
default_max_new_tokens 한번 답변할때 새로 생성할 최대 토큰수.
default_temperature 다음 토큰 선택의 무작위성을 조절. 낮을수록 안정적이고높을 수록 다양한 답변이 생성된다.
default_top_p 후보 토큰을 제한
deftault_top_k 상위 k개 후보토큰만 사용
default_repetition_penalty 같은 표현이 반복되는 현상을 줄임. 1.0보다 크면 반복 토큰의 선택 확률을 낮춘다
default_no_repeat_ngram_size n-gram 구절 반복을 막는 옵션. 3 토큰 구절이 반복 생성되는 것을 줄인다.
welcomemessage 정의
"""
KoGPT2 챗봇 프로젝트에서 공통으로 사용하는 설정값을 모아 둔 파일입니다.
이 파일을 따로 두면 모델 이름, 생성 길이, 샘플링 옵션 등을 여러 코드 파일에서
중복 작성하지 않고 한 곳에서 관리할 수 있습니다.
"""
# Hugging Face Hub에서 불러올 KoGPT2 모델 이름입니다.
# 노트북에서 사용한 모델과 동일하게 skt/kogpt2-base-v2를 사용합니다.
MODEL_NAME = "skt/kogpt2-base-v2"
# 챗봇이 한 번 답변할 때 새로 생성할 최대 토큰 수입니다.
# 값이 너무 작으면 답변이 짧고, 너무 크면 답변이 장황하거나 반복될 수 있습니다.
DEFAULT_MAX_NEW_TOKENS = 80
# temperature는 다음 토큰 선택의 무작위성을 조절하는 값입니다.
# 낮을수록 안정적인 답변, 높을수록 다양한 답변이 생성됩니다.
DEFAULT_TEMPERATURE = 0.70
# top_p는 누적 확률 기준으로 후보 토큰을 제한하는 nucleus sampling 값입니다.
# 0.90이면 확률이 높은 후보부터 누적 확률 90% 안의 토큰만 사용합니다.
DEFAULT_TOP_P = 0.90
# top_k는 점수가 높은 상위 k개 후보 토큰만 사용하는 옵션입니다.
# 너무 크면 답변이 다양해지고, 너무 작으면 답변이 단조로워질 수 있습니다.
DEFAULT_TOP_K = 40
# repetition_penalty는 같은 표현이 반복되는 현상을 줄이는 값입니다.
# 1.0보다 크면 반복 토큰의 선택 확률을 낮춥니다.
DEFAULT_REPETITION_PENALTY = 1.15
# no_repeat_ngram_size는 같은 n-gram 구절 반복을 막는 옵션입니다.
# 3이면 같은 3토큰 구절이 반복 생성되는 것을 줄입니다.
DEFAULT_NO_REPEAT_NGRAM_SIZE = 3
# Streamlit 채팅창에 처음 표시할 기본 안내 문장입니다.
# 사용자가 앱을 처음 실행했을 때 사용 방법을 쉽게 이해하도록 돕습니다.
WELCOME_MESSAGE = "안녕하세요. KoGPT2 기반 한국어 챗봇입니다. 질문이나 시작 문장을 입력해 주세요."
chatbot.py
import
생성옵션을 하나의 객체로 묶어 관리하기위해 dataclass 사용. 특수토큰을 명시해 빠르게 불러온다.
PreTrainedTokenizerFast와 GPTLMHeadModel 사용 GPT2 계열 언어모델을 불러오는 클래스
config에서 정의한 설정값들을 불러온다.
# 운영체제 환경 변수 접근을 위한 파이썬 기본 라이브러리입니다.
# 토크나이저 병렬 처리 경고를 줄이기 위해 사용합니다.
import os
# 표준 출력 인코딩을 재설정하기 위한 파이썬 기본 라이브러리입니다.
# Windows 콘솔 환경에서 한글 출력이 깨지는 문제를 줄이는 보조 설정에 사용합니다.
import sys
# 타입 힌트를 위한 dataclass를 불러옵니다.
# 생성 옵션을 하나의 객체로 묶어 관리하기 위해 사용합니다.
from dataclasses import dataclass
# PyTorch 라이브러리입니다.
# Tensor 생성, GPU/CPU 장치 선택, 모델 추론에 사용합니다.
import torch
# KoGPT2 전용 특수 토큰을 명시하여 빠른 토크나이저를 불러오기 위한 클래스입니다.
# 노트북에서 한글 깨짐 문제를 줄이기 위해 사용한 방식과 동일합니다.
from transformers import PreTrainedTokenizerFast
# GPT2 계열 언어 모델을 불러오는 클래스입니다.
# KoGPT2는 GPT2 계열 구조이므로 GPT2LMHeadModel로 문장 생성을 수행할 수 있습니다.
from transformers import GPT2LMHeadModel
# 프로젝트 공통 설정값을 불러옵니다.
# 모델 이름과 기본 생성 옵션을 중앙에서 관리합니다.
from src.config import (
DEFAULT_MAX_NEW_TOKENS,
DEFAULT_NO_REPEAT_NGRAM_SIZE,
DEFAULT_REPETITION_PENALTY,
DEFAULT_TEMPERATURE,
DEFAULT_TOP_K,
DEFAULT_TOP_P,
MODEL_NAME,
)
# 생성 결과 정리와 대화 프롬프트 생성을 위한 유틸리티 함수를 불러옵니다.
# UI와 모델 로직에서 문자열 후처리를 중복 작성하지 않도록 분리했습니다.
from src.utils.text_cleaner import build_chat_prompt, clean_generated_text, extract_answer
os.environ[] 토큰 병렬 처리 경고를 줄이기 위해 false.
hasattr() 함수로 urf-8을 표준 인코딩으로 설정
@dataclass , GenerationOptions
각 정의한 파라미터 변수에 할당
# 토크나이저 병렬 처리 경고를 줄이기 위해 환경 변수를 설정합니다.
# Streamlit 재실행 과정에서 불필요한 경고가 반복 출력되는 것을 줄입니다.
os.environ["TOKENIZERS_PARALLELISM"] = "false"
# 현재 실행 환경이 표준 출력 인코딩 재설정을 지원하는지 확인합니다.
# 일부 Windows 콘솔에서는 기본 인코딩 때문에 한글 출력이 깨질 수 있습니다.
if hasattr(sys.stdout, "reconfigure"):
# 표준 출력 인코딩을 UTF-8로 설정합니다.
# print 로그에 한글이 포함될 때 깨짐을 줄이는 보조 설정입니다.
sys.stdout.reconfigure(encoding="utf-8")
# 문장 생성 옵션을 하나의 객체로 묶기 위한 데이터 클래스를 정의합니다.
# 함수 인자가 많아지는 것을 줄이고, Streamlit 슬라이더 값 전달을 단순하게 만듭니다.
@dataclass
class GenerationOptions:
# 새로 생성할 최대 토큰 수입니다.
# 토큰 수가 많을수록 답변이 길어지지만 속도는 느려질 수 있습니다.
max_new_tokens: int = DEFAULT_MAX_NEW_TOKENS
# 생성 다양성을 조절하는 temperature 값입니다.
# 낮으면 안정적이고, 높으면 창의적이지만 문장이 흔들릴 수 있습니다.
temperature: float = DEFAULT_TEMPERATURE
# nucleus sampling의 누적 확률 기준입니다.
# 확률이 높은 후보군 안에서 자연스럽게 샘플링하도록 돕습니다.
top_p: float = DEFAULT_TOP_P
# 상위 k개 후보 토큰만 선택 대상으로 사용하는 값입니다.
# 후보 범위를 제한하여 너무 엉뚱한 토큰이 선택되는 것을 줄입니다.
top_k: int = DEFAULT_TOP_K
# 반복 표현을 줄이기 위한 패널티 값입니다.
# 1.0보다 큰 값을 사용하면 이미 나온 표현의 반복 가능성이 낮아집니다.
repetition_penalty: float = DEFAULT_REPETITION_PENALTY
# 같은 n-gram 구절 반복을 막는 값입니다.
# 3이면 같은 3토큰 묶음이 반복되지 않도록 제한합니다.
no_repeat_ngram_size: int = DEFAULT_NO_REPEAT_NGRAM_SIZE
src/utils/text_cleaner.py
clean_generated_text 특수문자 제거, ASCII문자들을 공백으로 바꿈.
특수토큰 제거
여러개의 공백을 하나의 공백으로 줄여 return
build_chat_prompt 대화이력이 none이면 []로 바꿔 저장해 에러가 나지않도록함.
최근 대화이력만 넣기위해 history[-3:] 마지막 3개만 사용한다.
recent_histroy에서 for문을 돌려 role과 content를 뽑아 저장한다. role에 user라면 사용자: 라는 꼬리를 아니면 챗봇: 이라는 꼬리를 붙인다.
프롬프트에 이렇게 이력과 현재 입력을 추가해 return.
extract_answer() 디코딩 결과에는 입력 프롬프트까지 포함될 수 있음으로 시작프롬프트 부분을 슬라이싱으로 제거한다 .
사용자, 챗봇 같은 꼬리말도 제거해 자연스럽게 보이게 한다 .
정의한 clean_generated_text() 함수를 이용해 공백을 제거하고 answer가 비어버리면 안내문구, 아니면 answer return.
"""
KoGPT2 생성 결과를 화면에 보기 좋게 정리하는 유틸리티 파일입니다.
언어 모델은 토큰 단위로 문장을 생성하므로 특수 토큰, 제어 문자, 반복 공백 등이
섞일 수 있습니다. Streamlit 화면에 표시하기 전에 정리하면 결과가 더 읽기 좋아집니다.
"""
# 정규표현식 처리를 위한 파이썬 기본 라이브러리입니다.
# 제어 문자 제거, 반복 공백 축소 같은 문자열 정리에 사용합니다.
import re
# 생성된 문자열을 정리하는 함수를 정의합니다.
# text 매개변수에는 tokenizer.decode()로 복원된 문자열이 들어옵니다.
def clean_generated_text(text: str) -> str:
# 유니코드 replacement character(�)는 디코딩 오류가 있을 때 나타날 수 있으므로 제거합니다.
text = text.replace("�", "")
# ASCII 제어 문자를 공백으로 바꿉니다.
# 줄바꿈, 탭, 보이지 않는 문자가 섞이면 채팅 출력이 지저분해질 수 있습니다.
text = re.sub(r"[\x00-\x1F\x7F]", " ", text)
# KoGPT2에서 출력될 수 있는 문장 시작/종료 특수 토큰을 제거합니다.
# 사용자가 읽는 답변에는 특수 토큰이 보이지 않는 것이 좋습니다.
text = text.replace("</s>", " ")
# 패딩 토큰 문자열을 제거합니다.
# 패딩 토큰은 문장 길이를 맞추기 위한 기호이므로 최종 답변에는 필요하지 않습니다.
text = text.replace("<pad>", " ")
# 알 수 없는 토큰 문자열을 제거합니다.
# 알 수 없는 토큰이 화면에 그대로 보이면 문장이 어색해 보일 수 있습니다.
text = text.replace("<unk>", " ")
# 마스크 토큰 문자열을 제거합니다.
# GPT 생성에서는 주로 사용하지 않지만 출력될 경우를 대비합니다.
text = text.replace("<mask>", " ")
# 여러 개의 공백을 하나의 공백으로 줄입니다.
# 토큰 디코딩 후 공백이 반복될 수 있으므로 보기 좋게 정리합니다.
text = re.sub(r"\s+", " ", text)
# 문장 앞뒤의 불필요한 공백을 제거합니다.
# 최종 화면 출력이 깔끔해집니다.
text = text.strip()
# 정리된 문자열을 반환합니다.
return text
# 챗봇 프롬프트를 구성하는 함수를 정의합니다.
# KoGPT2는 대화 전용으로 미세조정된 모델이 아니므로 역할 표시를 넣어 답변 방향을 잡습니다.
def build_chat_prompt(user_message: str, history: list[dict[str, str]] | None = None) -> str:
# 대화 이력이 None이면 빈 리스트로 바꿉니다.
# 이렇게 하면 이후 반복문에서 NoneType 오류가 발생하지 않습니다.
history = history or []
# 프롬프트에 들어갈 문자열 조각을 저장할 리스트를 만듭니다.
# 여러 줄을 리스트에 담은 뒤 join하면 구조적인 프롬프트를 만들기 쉽습니다.
prompt_parts: list[str] = []
# 챗봇의 역할을 간단히 설명하는 시스템성 안내 문장을 추가합니다.
# KoGPT2가 사용자의 질문에 이어 답변하도록 문맥을 제공합니다.
prompt_parts.append("다음은 사용자와 한국어 인공지능 챗봇의 대화입니다.")
# 최근 대화 이력만 프롬프트에 넣기 위해 마지막 3개 메시지를 사용합니다.
# 너무 긴 이력을 넣으면 입력 토큰이 길어져 속도가 느려지고 답변 품질이 흔들릴 수 있습니다.
recent_history = history[-3:]
# 최근 대화 이력을 순서대로 프롬프트에 추가합니다.
# role 값이 user이면 사용자 발화, assistant이면 챗봇 응답으로 표시합니다.
for message in recent_history:
# 현재 메시지의 역할 값을 가져옵니다.
# 값이 없으면 빈 문자열을 사용하여 KeyError를 방지합니다.
role = message.get("role", "")
# 현재 메시지의 내용을 가져옵니다.
# 값이 없으면 빈 문자열을 사용하여 KeyError를 방지합니다.
content = message.get("content", "")
# 사용자 메시지이면 "사용자:" 형식으로 추가합니다.
# 이 형식은 모델이 대화 흐름을 구분하는 데 도움을 줍니다.
if role == "user":
prompt_parts.append(f"사용자: {content}")
# 챗봇 메시지이면 "챗봇:" 형식으로 추가합니다.
# 이전 답변을 함께 넣으면 짧은 문맥 유지에 도움이 됩니다.
elif role == "assistant":
prompt_parts.append(f"챗봇: {content}")
# 현재 사용자의 새 입력을 프롬프트에 추가합니다.
# 모델은 이 문장 뒤의 챗봇 답변을 생성하게 됩니다.
prompt_parts.append(f"사용자: {user_message}")
# 모델이 이어서 생성할 위치를 "챗봇:"으로 시작시킵니다.
# 이렇게 하면 답변 형식이 비교적 일정하게 유지됩니다.
prompt_parts.append("챗봇:")
# 줄바꿈으로 프롬프트 조각을 연결합니다.
# 대화 구조가 잘 보이도록 각 발화를 한 줄로 분리합니다.
prompt = "\n".join(prompt_parts)
# 완성된 프롬프트를 반환합니다.
return prompt
# 모델 출력에서 챗봇 답변 부분만 잘라내는 함수를 정의합니다.
# 전체 디코딩 결과에는 입력 프롬프트까지 포함될 수 있으므로 후처리가 필요합니다.
def extract_answer(full_text: str, prompt: str) -> str:
# 전체 생성 결과가 입력 프롬프트로 시작하면 프롬프트 부분을 제거합니다.
# 이렇게 해야 사용자가 입력한 문장이 답변에 반복 표시되지 않습니다.
if full_text.startswith(prompt):
full_text = full_text[len(prompt):]
# 혹시 남아 있는 "사용자:" 이후 문장은 다음 턴처럼 보일 수 있으므로 제거합니다.
# 생성 모델이 대화 형식을 흉내 내며 새 사용자 발화를 만들어 내는 것을 막기 위한 후처리입니다.
full_text = full_text.split("사용자:")[0]
# 혹시 남아 있는 "챗봇:" 라벨을 제거합니다.
# 화면에는 실제 답변 문장만 표시하는 것이 자연스럽습니다.
full_text = full_text.replace("챗봇:", " ")
# 공통 정리 함수를 적용하여 특수 토큰과 불필요한 공백을 제거합니다.
answer = clean_generated_text(full_text)
# 답변이 비어 있으면 기본 안내 답변을 사용합니다.
# 모델이 종료 토큰만 생성하거나 너무 짧게 끝나는 경우를 대비합니다.
if not answer:
answer = "답변을 생성하지 못했습니다. 질문을 조금 더 구체적으로 입력해 주세요."
# 최종 답변을 반환합니다.
return answer
KoGPT2 챗봇 클래스
class KoGPT2Chatbot:
생성자.
변수 할당.
device 정의
PreTrainedTokenizerFast.from_pretrained() 토큰 불러오기
model 장치이동
평가모드로 전환
pad, eos, bos 토큰 정의
# 클래스 생성자입니다.
# model_name을 바꾸면 다른 GPT2 계열 한국어 모델로 교체할 수 있습니다.
def __init__(self, model_name: str = MODEL_NAME) -> None:
# 사용할 Hugging Face 모델 이름을 인스턴스 변수에 저장합니다.
# 이후 모델 로딩과 화면 표시에서 같은 값을 재사용합니다.
self.model_name = model_name
# GPU가 가능하면 cuda를 사용하고, 아니면 CPU를 사용합니다.
# PyTorch 모델과 입력 Tensor는 반드시 같은 장치에 있어야 합니다.
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# KoGPT2 토크나이저를 노트북에서 사용한 방식 그대로 불러옵니다.
# 특수 토큰을 명시하면 디코딩 안정성과 generate 설정이 좋아집니다.
self.tokenizer = PreTrainedTokenizerFast.from_pretrained(
self.model_name, # Hugging Face Hub에서 불러올 모델 이름입니다.
bos_token="</s>", # 문장 시작 토큰입니다.
eos_token="</s>", # 문장 종료 토큰입니다.
unk_token="<unk>", # 알 수 없는 토큰입니다.
pad_token="<pad>", # 패딩 토큰입니다.
mask_token="<mask>", # 마스크 토큰입니다.
)
# KoGPT2 언어 모델을 GPT2LMHeadModel 클래스로 불러옵니다.
# 이 모델은 입력 토큰 뒤에 이어질 다음 토큰을 예측하여 문장을 생성합니다.
self.model = GPT2LMHeadModel.from_pretrained(self.model_name)
# 모델을 선택된 장치로 이동합니다.
# GPU가 있으면 GPU 메모리로, 없으면 CPU 메모리로 이동합니다.
self.model = self.model.to(self.device)
# 추론 전용으로 모델을 평가 모드로 전환합니다.
# Dropout 같은 학습 전용 동작을 비활성화하여 결과를 안정화합니다.
self.model.eval()
# generate() 함수가 패딩 토큰을 정확히 알 수 있도록 설정합니다.
# 이 설정이 없으면 attention mask 관련 경고가 발생할 수 있습니다.
self.model.config.pad_token_id = self.tokenizer.pad_token_id
# generate() 함수가 문장 종료 토큰을 정확히 알 수 있도록 설정합니다.
# 종료 토큰이 생성되면 답변 생성을 멈출 수 있습니다.
self.model.config.eos_token_id = self.tokenizer.eos_token_id
# generate() 함수가 문장 시작 토큰도 참조할 수 있도록 설정합니다.
# GPT 계열 모델 설정의 완성도를 높이는 역할을 합니다.
self.model.config.bos_token_id = self.tokenizer.bos_token_id
reply 답변을 생성하는 메서드
option이 전달되지않으면 GenerationOptions()객체를 실행함.
메세지에 strip()해 앞 뒤 공백을 제거함.
입력문장이 비어있을때 안내문구 정의
build_chat_prompt() 대화이력 history와 현재 입력을 이용해 프롬프트를 만듦.
tokenizer 정수 id tensor로 변환함.
input_ids, attention_mask모두 장치이동.
model.grnerate() 모델 생성.
full_text 생성된 토큰 id를 문자열로 디코딩
extract_answer() 생성문자열에서 실제 챗본 답변 부분만 추출.
# 챗봇 답변을 생성하는 메서드입니다.
# user_message에는 사용자가 Streamlit 입력창에 입력한 문장이 들어옵니다.
def reply(
self,
user_message: str,
history: list[dict[str, str]] | None = None,
options: GenerationOptions | None = None,
) -> str:
# 생성 옵션이 전달되지 않으면 기본 옵션 객체를 생성합니다.
# 이렇게 하면 호출 코드에서 매번 모든 옵션을 지정하지 않아도 됩니다.
options = options or GenerationOptions()
# 사용자가 입력한 문장의 앞뒤 공백을 제거합니다.
# 빈 공백만 입력되는 경우를 처리하기 위해 필요합니다.
user_message = user_message.strip()
# 입력 문장이 비어 있으면 안내 문장을 반환합니다.
# 모델에 빈 문자열을 넣으면 의미 없는 결과가 생성될 수 있습니다.
if not user_message:
return "질문이나 시작 문장을 입력해 주세요."
# 대화 이력과 현재 입력을 이용해 모델에 넣을 프롬프트를 만듭니다.
# KoGPT2가 대화 형식으로 답변하도록 역할 라벨을 포함합니다.
prompt = build_chat_prompt(user_message=user_message, history=history)
# 프롬프트를 토크나이저로 정수 ID Tensor로 변환합니다.
# return_tensors="pt"는 PyTorch Tensor로 반환하라는 의미입니다.
encoded = self.tokenizer(
prompt, # 모델에 입력할 대화 프롬프트입니다.
return_tensors="pt", # PyTorch Tensor 형태로 인코딩 결과를 받습니다.
add_special_tokens=False, # KoGPT2 프롬프트에는 별도 특수 토큰을 자동 추가하지 않습니다.
)
# input_ids를 모델이 올라간 장치로 이동합니다.
# 장치가 다르면 PyTorch에서 RuntimeError가 발생합니다.
input_ids = encoded["input_ids"].to(self.device)
# attention_mask를 모델이 올라간 장치로 이동합니다.
# attention_mask는 실제 토큰과 패딩 토큰을 구분하는 역할을 합니다.
attention_mask = encoded["attention_mask"].to(self.device)
# 추론 과정에서는 기울기 계산이 필요 없으므로 비활성화합니다.
# 메모리 사용량이 줄고 실행 속도가 좋아집니다.
with torch.no_grad():
# KoGPT2 generate() 함수로 답변 토큰을 생성합니다.
# 샘플링 옵션을 사용하여 너무 단조로운 답변을 줄입니다.
generated_ids = self.model.generate(
input_ids=input_ids, # 인코딩된 입력 토큰 ID입니다.
attention_mask=attention_mask, # 패딩 여부를 알려주는 마스크입니다.
max_new_tokens=options.max_new_tokens, # 새로 생성할 토큰 수입니다.
do_sample=True, # 확률적 샘플링을 사용합니다.
temperature=options.temperature, # 생성 다양성을 조절합니다.
top_p=options.top_p, # 누적 확률 기준 후보 제한 값입니다.
top_k=options.top_k, # 상위 k개 후보 제한 값입니다.
repetition_penalty=options.repetition_penalty, # 반복 표현을 줄이는 값입니다.
no_repeat_ngram_size=options.no_repeat_ngram_size, # 같은 구절 반복을 막는 값입니다.
eos_token_id=self.tokenizer.eos_token_id, # 문장 종료 토큰 ID입니다.
pad_token_id=self.tokenizer.pad_token_id, # 패딩 토큰 ID입니다.
use_cache=True, # 이전 계산 결과를 재사용하여 속도를 높입니다.
)
# 생성된 토큰 ID를 문자열로 디코딩합니다.
# skip_special_tokens=False로 두고 직접 정리하여 KoGPT2 특수 토큰 처리를 명확히 합니다.
full_text = self.tokenizer.decode(generated_ids[0], skip_special_tokens=False)
# 전체 생성 문자열에서 실제 챗봇 답변 부분만 추출합니다.
# 입력 프롬프트와 불필요한 역할 라벨을 제거합니다.
answer = extract_answer(full_text=full_text, prompt=prompt)
# 최종 답변 문자열을 반환합니다.
return answer
analyze_tokens()
encode를 가져다 id리스트로 변환
이 token_ids를 convert문자열 리스트로 변환. return. list
get_model_info()
info 딕셔너리를 생성해 반환 사이드바에서 모델 이름과 장치정보를 표시할때 사용하기 위한 함수.
# 입력 문장의 토큰 분석 결과를 반환하는 메서드입니다.
# Streamlit 화면에서 교육용으로 토큰 ID와 토큰 문자열을 보여줄 때 사용합니다.
def analyze_tokens(self, text: str) -> list[tuple[int, str]]:
# 입력 문장을 KoGPT2 토큰 ID 리스트로 변환합니다.
# add_special_tokens=False는 자동 특수 토큰 추가를 막습니다.
token_ids = self.tokenizer.encode(text, add_special_tokens=False)
# 토큰 ID 리스트를 실제 토큰 문자열 리스트로 변환합니다.
# KoGPT2가 문장을 어떤 조각으로 나누는지 확인할 수 있습니다.
tokens = self.tokenizer.convert_ids_to_tokens(token_ids)
# 토큰 ID와 토큰 문자열을 튜플로 묶어 반환합니다.
# zip 결과를 list로 바꾸어 Streamlit에서 표 형태로 다루기 쉽게 합니다.
return list(zip(token_ids, tokens))
# 현재 모델 실행 정보를 딕셔너리로 반환하는 메서드입니다.
# Streamlit 사이드바에서 모델 이름과 장치 정보를 표시할 때 사용합니다.
def get_model_info(self) -> dict[str, str]:
# 모델 정보 딕셔너리를 생성합니다.
# 문자열 값으로 변환하여 화면 출력이 간단하도록 만듭니다.
info = {
"model_name": self.model_name, # 사용 중인 Hugging Face 모델 이름입니다.
"device": str(self.device), # 현재 실행 장치입니다.
"pad_token": str(self.tokenizer.pad_token), # 패딩 토큰 문자열입니다.
"eos_token": str(self.tokenizer.eos_token), # 종료 토큰 문자열입니다.
}
# 완성된 모델 정보 딕셔너리를 반환합니다.
return info
문장생성함수
generate_ones()
KoGPT2Chatbot() 객체를 만들어 chatbot.reply(), return 이때 clean_generated_text를 거친다.
# 간단한 문장 생성 함수도 제공합니다.
# Streamlit 외부에서 파이썬 코드로 빠르게 테스트할 때 사용할 수 있습니다.
def generate_once(prompt: str) -> str:
# 챗봇 객체를 생성합니다.
# 최초 실행 시 Hugging Face 모델 파일이 다운로드될 수 있습니다.
chatbot = KoGPT2Chatbot()
# 기본 옵션으로 답변을 생성합니다.
# 사용자가 전달한 prompt를 챗봇 입력으로 사용합니다.
answer = chatbot.reply(user_message=prompt)
# 정리된 답변을 한 번 더 clean 처리하여 반환합니다.
# 외부 호출에서도 출력이 깔끔하게 유지됩니다.
return clean_generated_text(answer)
streamlit_app.py
import,작성한 config와 chatbot도 불러온다 .
# 프로젝트 루트 경로를 파이썬 모듈 검색 경로에 추가하기 위한 기본 라이브러리입니다.
# app 폴더에서 실행해도 src 패키지를 안정적으로 import하기 위해 사용합니다.
import sys
# 파일 경로를 운영체제에 맞게 다루기 위한 pathlib 모듈입니다.
# Windows와 macOS/Linux에서 모두 안전하게 프로젝트 루트 경로를 계산할 수 있습니다.
from pathlib import Path
# Streamlit 웹 화면을 만들기 위한 라이브러리입니다.
# 채팅 UI, 입력창, 사이드바, 버튼, 표 등을 구현합니다.
import streamlit as st
# 현재 파일의 상위 폴더를 기준으로 프로젝트 루트 경로를 계산합니다.
# app/streamlit_app.py의 부모는 app이고, 그 부모가 프로젝트 루트입니다.
PROJECT_ROOT = Path(__file__).resolve().parents[1]
# 프로젝트 루트 경로가 sys.path에 없으면 추가합니다.
# 이렇게 해야 "from src..." 형태의 import가 정상 작동합니다.
if str(PROJECT_ROOT) not in sys.path:
# 파이썬 모듈 검색 경로의 맨 앞에 프로젝트 루트를 추가합니다.
# 같은 이름의 외부 패키지보다 현재 프로젝트의 src를 우선 찾게 됩니다.
sys.path.insert(0, str(PROJECT_ROOT))
# 챗봇 모델 클래스와 생성 옵션 클래스를 불러옵니다.
# 실제 모델 로딩과 답변 생성은 src/chatbot.py에서 담당합니다.
from src.chatbot import GenerationOptions, KoGPT2Chatbot
# Streamlit 화면에 표시할 기본 환영 메시지를 불러옵니다.
# 안내 문구를 config.py에서 관리하면 문구 수정이 쉬워집니다.
from src.config import WELCOME_MESSAGE
페이지 기본 설정
# Streamlit 페이지의 기본 설정을 지정합니다.
# 페이지 제목, 아이콘, 레이아웃을 앱 시작 시 한 번 설정합니다.
st.set_page_config(
page_title="KoGPT2 한국어 챗봇", # 브라우저 탭에 표시될 제목입니다.
page_icon="🤖", # 브라우저 탭과 앱 상단에 표시될 아이콘입니다.
layout="wide", # 넓은 화면 레이아웃을 사용합니다.
)
캐시지정.
chatbot객체 생성은 최초실행시에해서 return.
# Streamlit 캐시를 이용해 모델을 한 번만 로드하는 함수를 정의합니다.
# 모델은 용량이 크므로 매 화면 갱신마다 다시 로드하면 매우 느려집니다.
@st.cache_resource(show_spinner="KoGPT2 모델을 불러오는 중입니다. 처음 실행 시 시간이 걸릴 수 있습니다.")
def load_chatbot() -> KoGPT2Chatbot:
# KoGPT2 챗봇 객체를 생성합니다.
# 최초 실행 시 Hugging Face Hub에서 모델과 토크나이저를 다운로드합니다.
chatbot = KoGPT2Chatbot()
# 로드된 챗봇 객체를 반환합니다.
# Streamlit은 이 객체를 캐시에 저장하여 재사용합니다.
return chatbot
세션에 대화이력이 없으면 초기화하고, tokens도 마찬가지
# 세션 상태에 대화 이력이 없으면 초기화합니다.
# Streamlit은 사용자 입력 때마다 스크립트를 다시 실행하므로 session_state가 필요합니다.
if "messages" not in st.session_state:
# messages에는 {"role": "user" 또는 "assistant", "content": "..."} 형식의 딕셔너리를 저장합니다.
st.session_state.messages = []
# 세션 상태에 마지막 토큰 분석 결과가 없으면 초기화합니다.
# 사용자가 입력한 문장의 토큰화 결과를 화면 아래에 보여주기 위해 사용합니다.
if "last_tokens" not in st.session_state:
# 토큰 분석 결과는 처음에는 비어 있는 리스트입니다.
st.session_state.last_tokens = []
타이틀 및 문구 출력
# 화면 상단 제목을 출력합니다.
# 사용자가 현재 앱의 목적을 바로 알 수 있도록 합니다.
st.title("🤖 KoGPT2 한국어 챗봇")
# 화면 상단 설명 문구를 출력합니다.
# 이 앱이 업로드된 GPT KoGPT2 노트북 코드를 PyCharm 프로젝트 구조로 바꾼 것임을 설명합니다.
st.caption("PyTorch + Hugging Face Transformers + Streamlit 기반 한국어 문장 생성 챗봇 앱")
sidebard 출력
slider()를 이용해 각 파라미터값을 설정할 수 있도록 한다 .
st.button 대화 초기화 버튼을 누르면 sesstion에 메세지와 토큰을 초기화한뒤 rerun()
# 왼쪽 사이드바 영역을 구성합니다.
# 생성 옵션을 사용자가 직접 조절할 수 있도록 슬라이더를 배치합니다.
with st.sidebar:
# 사이드바 제목을 표시합니다.
st.header("생성 옵션")
# 새로 생성할 토큰 수를 조절하는 슬라이더입니다.
# 값이 커질수록 답변은 길어지지만 실행 시간이 증가할 수 있습니다.
max_new_tokens = st.slider(
"최대 생성 토큰 수", # 슬라이더 라벨입니다.
min_value=20, # 최소 생성 토큰 수입니다.
max_value=180, # 최대 생성 토큰 수입니다.
value=80, # 기본 생성 토큰 수입니다.
step=10, # 한 번 움직일 때 증가/감소하는 단위입니다.
)
# temperature 값을 조절하는 슬라이더입니다.
# 낮으면 안정적이고 높으면 다양한 답변이 생성됩니다.
temperature = st.slider(
"Temperature", # 슬라이더 라벨입니다.
min_value=0.20, # 최소 temperature 값입니다.
max_value=1.20, # 최대 temperature 값입니다.
value=0.70, # 기본 temperature 값입니다.
step=0.05, # 한 번 움직일 때 증가/감소하는 단위입니다.
)
# top_p 값을 조절하는 슬라이더입니다.
# 확률이 높은 후보군 안에서 답변을 생성하도록 돕습니다.
top_p = st.slider(
"Top-p", # 슬라이더 라벨입니다.
min_value=0.50, # 최소 top_p 값입니다.
max_value=1.00, # 최대 top_p 값입니다.
value=0.90, # 기본 top_p 값입니다.
step=0.01, # 한 번 움직일 때 증가/감소하는 단위입니다.
)
# top_k 값을 조절하는 슬라이더입니다.
# 상위 k개 후보 토큰만 선택 대상으로 사용합니다.
top_k = st.slider(
"Top-k", # 슬라이더 라벨입니다.
min_value=10, # 최소 top_k 값입니다.
max_value=100, # 최대 top_k 값입니다.
value=40, # 기본 top_k 값입니다.
step=5, # 한 번 움직일 때 증가/감소하는 단위입니다.
)
# repetition_penalty 값을 조절하는 슬라이더입니다.
# 같은 말이 반복되는 현상을 줄이는 데 사용합니다.
repetition_penalty = st.slider(
"반복 패널티", # 슬라이더 라벨입니다.
min_value=1.00, # 반복 패널티 최소값입니다.
max_value=1.50, # 반복 패널티 최대값입니다.
value=1.15, # 기본 반복 패널티 값입니다.
step=0.01, # 한 번 움직일 때 증가/감소하는 단위입니다.
)
# no_repeat_ngram_size 값을 조절하는 슬라이더입니다.
# 같은 구절이 반복되는 것을 줄입니다.
no_repeat_ngram_size = st.slider(
"반복 금지 n-gram 크기", # 슬라이더 라벨입니다.
min_value=0, # 0이면 n-gram 반복 금지를 사용하지 않습니다.
max_value=5, # 최대 n-gram 크기입니다.
value=3, # 기본 n-gram 크기입니다.
step=1, # 한 번 움직일 때 증가/감소하는 단위입니다.
)
# 대화 초기화 버튼을 만듭니다.
# 버튼을 누르면 세션에 저장된 대화 이력을 삭제합니다.
clear_clicked = st.button("대화 초기화")
# 사용자가 대화 초기화 버튼을 누른 경우를 처리합니다.
# messages와 토큰 분석 결과를 모두 비웁니다.
if clear_clicked:
# 저장된 대화 메시지를 빈 리스트로 초기화합니다.
st.session_state.messages = []
# 저장된 토큰 분석 결과를 빈 리스트로 초기화합니다.
st.session_state.last_tokens = []
# 화면을 즉시 다시 실행하여 초기화 결과를 반영합니다.
st.rerun()
chatbot 불러오기
# 모델을 캐시에서 불러오거나 최초 한 번 로드합니다.
# 이 시점에 모델 다운로드 또는 로딩이 수행될 수 있습니다.
chatbot = load_chatbot()
st.sidebar에 divider 표시한 뒤 model_info 정보를 가져와 표시하기
# 사이드바에 모델 정보를 표시합니다.
# 사용자가 어떤 모델과 장치로 실행 중인지 확인할 수 있습니다.
with st.sidebar:
# 구분선을 표시합니다.
st.divider()
# 모델 정보 섹션 제목을 표시합니다.
st.header("모델 정보")
# 챗봇 객체에서 모델 실행 정보를 가져옵니다.
model_info = chatbot.get_model_info()
# 사용 중인 Hugging Face 모델 이름을 표시합니다.
st.write("모델:", model_info["model_name"])
# 현재 실행 장치를 표시합니다.
st.write("실행 장치:", model_info["device"])
# 종료 토큰 정보를 표시합니다.
st.write("종료 토큰:", model_info["eos_token"])
대화가 없을경우 환영문구,
session에 저장된 메세지를 다시 출력,
prompt st.chat_input() 사용자가 새 메세지를 입력할 수 있는 채팅 입력창을 만듬
# 대화가 아직 없으면 환영 안내 메시지를 표시합니다.
# 첫 화면이 비어 있지 않도록 기본 설명을 제공합니다.
if not st.session_state.messages:
# assistant 역할로 환영 메시지를 채팅 영역에 표시합니다.
with st.chat_message("assistant"):
# 기본 환영 문구를 출력합니다.
st.write(WELCOME_MESSAGE)
# 저장된 모든 대화 메시지를 화면에 다시 출력합니다.
# Streamlit은 매 입력마다 전체 스크립트를 재실행하므로 이 과정이 필요합니다.
for message in st.session_state.messages:
# 메시지 역할에 맞는 채팅 말풍선을 만듭니다.
with st.chat_message(message["role"]):
# 메시지 내용을 화면에 출력합니다.
st.write(message["content"])
# 사용자가 새 메시지를 입력할 수 있는 채팅 입력창을 만듭니다.
# 입력 후 Enter를 누르면 prompt 변수에 문자열이 들어옵니다.
prompt = st.chat_input("질문이나 시작 문장을 입력하세요.")
prompt가 있으면 즉 사용자가 메세지를 입력했을때 session에 prompt업데이트,
user 메세지 출력,
GenerationOptions() 객체를 만들어 options에 저장한다. 모델 생성 함수에 깔끔하게 옵션을 전달 할 수 있다.
st.spinner() 사용자를 위한 로딩.
chatbot.analyze_tokens를 세션에 저장.
최근 대화이력을 모델에 전달하고 chatbot.reply() 답변을 생성해 answer에 할당. 답변도 세션에 update
st.chat_message() assistant쪽에 answer를 출력
# 사용자가 실제로 메시지를 입력했을 때만 답변 생성을 수행합니다.
# 입력이 없으면 None이므로 아래 코드는 실행되지 않습니다.
if prompt:
# 사용자 메시지를 세션 대화 이력에 추가합니다.
# 이후 화면 재실행 시에도 이전 대화가 유지됩니다.
st.session_state.messages.append({"role": "user", "content": prompt})
# 사용자 메시지를 화면에 즉시 표시합니다.
# 답변 생성 전에 사용자의 입력을 채팅 영역에 보여줍니다.
with st.chat_message("user"):
# 사용자가 입력한 문장을 출력합니다.
st.write(prompt)
# Streamlit 슬라이더 값을 GenerationOptions 객체로 묶습니다.
# 모델 생성 함수에 여러 옵션을 깔끔하게 전달하기 위한 처리입니다.
options = GenerationOptions(
max_new_tokens=max_new_tokens, # 최대 생성 토큰 수입니다.
temperature=temperature, # 생성 다양성 값입니다.
top_p=top_p, # nucleus sampling 누적 확률입니다.
top_k=top_k, # 상위 후보 토큰 수입니다.
repetition_penalty=repetition_penalty, # 반복 표현 패널티입니다.
no_repeat_ngram_size=no_repeat_ngram_size, # 반복 금지 n-gram 크기입니다.
)
# 답변 생성 중임을 알려주는 스피너를 표시합니다.
# 모델 추론 시간이 걸릴 수 있으므로 사용자에게 진행 상태를 보여줍니다.
with st.spinner("KoGPT2가 답변을 생성하는 중입니다..."):
# 현재 사용자 입력의 토큰 분석 결과를 저장합니다.
# 화면 하단에서 토큰 ID와 토큰 문자열을 확인할 수 있습니다.
st.session_state.last_tokens = chatbot.analyze_tokens(prompt)
# 최근 대화 이력을 모델에 전달합니다.
# 방금 추가한 사용자 메시지는 reply 내부에서 새 입력으로 처리하므로 history에서는 제외합니다.
history = st.session_state.messages[:-1]
# KoGPT2 모델을 사용하여 챗봇 답변을 생성합니다.
# 생성 옵션은 사이드바 슬라이더 값이 반영됩니다.
answer = chatbot.reply(user_message=prompt, history=history, options=options)
# 챗봇 답변을 세션 대화 이력에 추가합니다.
# 이후 화면 재실행 시에도 답변이 유지됩니다.
st.session_state.messages.append({"role": "assistant", "content": answer})
# 챗봇 답변을 화면에 표시합니다.
# assistant 역할의 채팅 말풍선으로 출력합니다.
with st.chat_message("assistant"):
# 생성된 답변 문장을 출력합니다.
st.write(answer)
st.expander 익스펜더, 아코디언을 만들어 session에서 마지만 토큰이 있다면 토큰아이디와 세션에 저장된 토큰들을 for문을 출력해 dataframe()으로 보여준다. 만일 분석할 입력이 없다면 안내문구 표시
# 화면 아래쪽에 토큰 분석 섹션을 만듭니다.
# 교육용 프로젝트이므로 사용자가 입력 문장이 어떻게 토큰화되는지 확인할 수 있게 합니다.
with st.expander("마지막 입력 문장의 토큰 분석 보기"):
# 토큰 분석 결과가 있으면 표로 표시합니다.
# 각 행은 토큰 ID와 토큰 문자열로 구성됩니다.
if st.session_state.last_tokens:
# Streamlit 표에 표시할 딕셔너리 리스트를 만듭니다.
token_rows = [
{"token_id": token_id, "token": token} # 각 토큰의 ID와 문자열입니다.
for token_id, token in st.session_state.last_tokens
]
# 토큰 분석 결과를 표 형태로 출력합니다.
st.dataframe(token_rows, use_container_width=True)
# 아직 분석할 입력이 없으면 안내 문구를 표시합니다.
# 사용자가 먼저 채팅 입력을 해야 토큰 분석이 가능합니다.
else:
# 토큰 분석 결과가 없다는 메시지를 출력합니다.
st.write("아직 분석할 입력 문장이 없습니다.")
앞서서 자연어를 시작할때 naver 영화 리뷰를 했었다. 이를 Transformer로 변경한 뒤 streamlit 프로젝트화한 코드를 분석해보자.
config.py
path 지정
저장할 폴더경로 지정
학습된 모델과 단어사전 파일을 저장할 폴더경로 지정 checkpoints
학습 데이터 파일을 저장할 경로 지정 ratings_test.txt
학습된 transformer 모델 파라미터 저장할 파일경로 지정 naver_transformer_sentiment.pt
단어 사전 파일 경로 지정 vocab.json
학습 다운로드 url지정
테스트 다운로드 url지정
토큰, vocab, batch, d차원, h Multi-head self Attention 에 사용할 head 개수를 지정, l, ff feed forward 중간차원 지정, dropout, learning_rate, epochs, 학습/검증에서 검증 데이터 비율 지정하는valid_ratio, seed 값 지정
"""프로젝트 전체에서 공통으로 사용할 설정값을 모아 둔 파일입니다."""
# pathlib.Path는 운영체제별 경로 구분자 차이를 자동으로 처리하기 위해 사용합니다.
from pathlib import Path
# 현재 config.py 파일의 위치에서 부모 폴더를 두 번 올라가 프로젝트 루트 경로를 계산합니다.
BASE_DIR = Path(__file__).resolve().parents[1]
# 원본 NSMC 데이터 파일을 저장할 폴더 경로를 지정합니다.
RAW_DATA_DIR = BASE_DIR / "data" / "raw"
# 학습된 모델과 단어 사전 파일을 저장할 폴더 경로를 지정합니다.
CHECKPOINT_DIR = BASE_DIR / "checkpoints"
# NSMC 학습 데이터 파일을 저장할 전체 경로를 지정합니다.
TRAIN_FILE = RAW_DATA_DIR / "ratings_train.txt"
# NSMC 테스트 데이터 파일을 저장할 전체 경로를 지정합니다.
TEST_FILE = RAW_DATA_DIR / "ratings_test.txt"
# 학습된 Transformer 모델 파라미터를 저장할 파일 경로를 지정합니다.
MODEL_PATH = CHECKPOINT_DIR / "naver_transformer_sentiment.pt"
# 학습 데이터에서 만든 단어 사전 파일을 저장할 경로를 지정합니다.
VOCAB_PATH = CHECKPOINT_DIR / "vocab.json"
# NSMC 학습 데이터 다운로드 URL을 지정합니다.
TRAIN_URL = "https://raw.githubusercontent.com/e9t/nsmc/master/ratings_train.txt"
# NSMC 테스트 데이터 다운로드 URL을 지정합니다.
TEST_URL = "https://raw.githubusercontent.com/e9t/nsmc/master/ratings_test.txt"
# 문장을 토큰 ID 시퀀스로 변환할 때 사용할 최대 토큰 길이를 지정합니다.
MAX_LEN = 64
# 단어 사전에 등록할 최대 토큰 개수를 지정합니다.
VOCAB_SIZE = 30000
# 한 번의 학습 단계에서 사용할 리뷰 개수를 지정합니다.
BATCH_SIZE = 64
# Transformer 내부 임베딩 벡터 차원을 지정합니다.
D_MODEL = 128
# Multi-Head Self-Attention에서 사용할 head 개수를 지정합니다.
N_HEADS = 4
# Transformer Encoder Block을 몇 층 쌓을지 지정합니다.
N_LAYERS = 2
# Feed Forward Network의 중간 차원을 지정합니다.
FF_DIM = 256
# 과적합을 줄이기 위해 사용할 Dropout 비율을 지정합니다.
DROPOUT = 0.1
# 모델 학습률을 지정합니다.
LEARNING_RATE = 1e-4
# 기본 학습 epoch 수를 지정합니다.
EPOCHS = 3
# 학습/검증 분할에서 검증 데이터 비율을 지정합니다.
VALID_RATIO = 0.1
# 재현 가능한 실험을 위해 난수 시드를 지정합니다.
SEED = 42
tokenizer.py
import json, re, counter, path
vocabulary 클래스, init() 단어수, 최소 등장 빈도저장, 최소등장빈도, 특수토큰 정의,
단어를 정수 id로 바꾸는, 정수id를 단어 로 바꾸는 딕셔너리등을 초기화.
len()
@staticmethod
tokenize()
문자열이 아니면 빈문자열로 바꾸기
re.sub 특수문자 제거 공백관리 및 Split() 해 return
build() 학습 문장을 목록으로 단어 사전을 생성.
text를 하나씩 반복하며 tokenize() 한뒤 counter.update.
빈도가 높은 단어부터 정렬된 목록을 만든다.
확인
이미 등록된 단어가 아니면 새로운 id를 부여. 현재 사전 크기가 새 단어 id가 된다.
stoi[word] = idx, itos[idx] = word 단어에서 id, id에서 단어로 가는 매핑을 저장.
encode()
문장을 id로 변환하는 함수.
뭉장을 tokenize() 토큰화하고 정수 id로 바꾸고 사전에 없을경우 unk를 사용한다.
maxlen만큼만 문장을 자르고 부족하면 padding 추가해서 return ids.
save()
path를 지정해 파이리을 만들고 데이터를 구성해 write_text().
@classmethod
load()
위 저장한 json파일을 불러와 저장된 설정값으로 vocav 객체를 생성한다.
stoi 딕셔너리를 복원하고,
stoi를 뒤집어 다시 딕셔너리를 만들어 vocab return.
"""한국어 리뷰 문장을 단순 토큰화하고 정수 ID로 변환하는 유틸리티입니다."""
# json은 단어 사전을 파일로 저장하고 다시 불러오기 위해 사용합니다.
import json
# re는 한글, 영어, 숫자, 공백 외의 문자를 정리하기 위해 사용합니다.
import re
# Counter는 학습 데이터에서 단어 빈도를 계산하기 위해 사용합니다.
from collections import Counter
# Path는 저장 경로를 안전하게 다루기 위해 사용합니다.
from pathlib import Path
# Vocabulary 클래스는 단어와 정수 ID 사이의 매핑을 관리합니다.
class Vocabulary:
# __init__ 메서드는 특수 토큰과 단어 사전 자료구조를 초기화합니다.
def __init__(self, max_size: int = 30000, min_freq: int = 2):
# 사용할 최대 단어 수를 저장합니다.
self.max_size = max_size
# 단어 사전에 포함할 최소 등장 빈도를 저장합니다.
self.min_freq = min_freq
# padding 토큰은 짧은 문장을 같은 길이로 맞출 때 사용합니다.
self.pad_token = "<PAD>"
# unknown 토큰은 사전에 없는 단어를 표현할 때 사용합니다.
self.unk_token = "<UNK>"
# 단어를 정수 ID로 바꾸는 딕셔너리를 초기화합니다.
self.stoi = {self.pad_token: 0, self.unk_token: 1}
# 정수 ID를 단어로 바꾸는 딕셔너리를 초기화합니다.
self.itos = {0: self.pad_token, 1: self.unk_token}
# __len__ 메서드는 현재 단어 사전 크기를 반환합니다.
def __len__(self) -> int:
# stoi 딕셔너리의 길이가 전체 토큰 개수입니다.
return len(self.stoi)
# tokenize 메서드는 한국어 문장을 공백 기준 토큰 리스트로 변환합니다.
@staticmethod
def tokenize(text: str) -> list[str]:
# 입력값이 문자열이 아니면 빈 문자열로 바꾸어 오류를 방지합니다.
text = "" if text is None else str(text)
# 한글, 영어, 숫자, 공백을 제외한 기호를 공백으로 치환합니다.
text = re.sub(r"[^가-힣a-zA-Z0-9\s]", " ", text)
# 연속된 공백을 하나의 공백으로 줄이고 앞뒤 공백을 제거합니다.
text = re.sub(r"\s+", " ", text).strip()
# 정리된 문장을 공백 기준으로 나누어 토큰 리스트를 만듭니다.
return text.split()
# build 메서드는 학습 문장 목록으로 단어 사전을 생성합니다.
def build(self, texts: list[str]) -> None:
# 모든 문장의 토큰 빈도를 저장할 Counter 객체를 생성합니다.
counter = Counter()
# 학습 문장들을 하나씩 반복합니다.
for text in texts:
# 현재 문장을 토큰화한 뒤 빈도 Counter에 더합니다.
counter.update(self.tokenize(text))
# 빈도가 높은 단어부터 정렬된 목록을 만듭니다.
most_common = counter.most_common(self.max_size - 2)
# 정렬된 단어 목록을 하나씩 확인합니다.
for word, freq in most_common:
# 최소 빈도보다 적게 등장한 단어는 사전에 넣지 않습니다.
if freq < self.min_freq:
continue
# 이미 등록된 단어가 아니면 새 ID를 부여합니다.
if word not in self.stoi:
# 현재 사전 크기를 새 단어의 ID로 사용합니다.
idx = len(self.stoi)
# 단어에서 ID로 가는 매핑을 저장합니다.
self.stoi[word] = idx
# ID에서 단어로 가는 매핑을 저장합니다.
self.itos[idx] = word
# encode 메서드는 문장을 고정 길이 정수 ID 리스트로 변환합니다.
def encode(self, text: str, max_len: int) -> list[int]:
# 문장을 토큰화합니다.
tokens = self.tokenize(text)
# 각 토큰을 정수 ID로 바꾸고 사전에 없으면 <UNK> ID를 사용합니다.
ids = [self.stoi.get(token, self.stoi[self.unk_token]) for token in tokens]
# 최대 길이를 넘는 문장은 앞에서부터 max_len개만 남깁니다.
ids = ids[:max_len]
# 부족한 길이만큼 <PAD> ID를 뒤쪽에 추가합니다.
ids += [self.stoi[self.pad_token]] * (max_len - len(ids))
# 완성된 고정 길이 정수 리스트를 반환합니다.
return ids
# save 메서드는 단어 사전을 JSON 파일로 저장합니다.
def save(self, path: str | Path) -> None:
# 문자열 경로와 Path 경로를 모두 Path 객체로 변환합니다.
path = Path(path)
# 부모 폴더가 없으면 자동으로 생성합니다.
path.parent.mkdir(parents=True, exist_ok=True)
# 저장할 데이터를 딕셔너리로 구성합니다.
data = {"max_size": self.max_size, "min_freq": self.min_freq, "stoi": self.stoi}
# JSON 파일을 UTF-8 인코딩으로 저장합니다.
path.write_text(json.dumps(data, ensure_ascii=False, indent=2), encoding="utf-8")
# load 클래스 메서드는 저장된 JSON 파일에서 단어 사전을 복원합니다.
@classmethod
def load(cls, path: str | Path) -> "Vocabulary":
# JSON 파일을 UTF-8 인코딩으로 읽어 딕셔너리로 변환합니다.
data = json.loads(Path(path).read_text(encoding="utf-8"))
# 저장된 설정값으로 Vocabulary 객체를 생성합니다.
vocab = cls(max_size=data["max_size"], min_freq=data["min_freq"])
# 저장된 stoi 딕셔너리를 복원합니다.
vocab.stoi = {str(k): int(v) for k, v in data["stoi"].items()}
# stoi를 뒤집어 itos 딕셔너리를 다시 만듭니다.
vocab.itos = {idx: word for word, idx in vocab.stoi.items()}
# 복원된 Vocabulary 객체를 반환합니다.
return vocab
data,py
import
config에서 설정값을 가져온다 .
tokenizer에서 vocaburay 를 가져온다. 한국어 문장을 토큰 id로 변환하기 위해 사용할것이다.
download_file()
폴더가없으면 자동생성, 파일이 있으면 다운로드 생략, urllib.request.urlretrieve() url정보로 데이터 다운로드
ensure_nsmc_download()
원본데이터 다운로드. 정의한 download_file함수를 사용한다. 학습데이터파일, 테스트 데이터 파일 다운로드
load_name()
csv파일을 읽고 dropna 결측치 제거하고, label을 정수형 int로 변환해 손실함수입력 형식에 맞춰 return.
NaberReviewDataset()
init() 리뷰 문장 목록과 정답, vocab, max_len 초기화
len()
getitem() 인덱스에 해당하는 리뷰 문장을 가져오고 vocab.encode()로 id리스트로 변환하고 longtensor로 변환해 x, y 리턴.
create_dataloaders()
ensure_nsmc_download() 파일이 없으면 다운로드하고, 학습파일을 dataframe으로 읽는다.
빠른 학습을 위해 학습 데이터 일부만 사용한다. 지정한 샘플수만 copy() 해서 사용.
test_df를 읽어 full_train_dataset()전체 학습 데이터셋, 테스트 데이터셋 객체를 생성하고
검증과 학습 데이터 개수를 계산
generagor에 시드생성.
전체 학습 데이터를 학습용과 검증요으로 나누고 dataloader생성. train, valid, test.
"""NSMC 데이터를 다운로드하고 PyTorch Dataset/DataLoader로 변환하는 파일입니다."""
# urllib.request는 외부 URL에서 NSMC 텍스트 파일을 다운로드하기 위해 사용합니다.
import urllib.request
# pandas는 탭으로 구분된 NSMC 파일을 DataFrame으로 읽기 위해 사용합니다.
import pandas as pd
# torch는 텐서 변환에 사용합니다.
import torch
# Dataset과 DataLoader는 PyTorch 학습용 데이터 공급 객체를 만들기 위해 사용합니다.
from torch.utils.data import Dataset, DataLoader, random_split
# 프로젝트 설정값을 가져옵니다.
from src.config import TRAIN_URL, TEST_URL, TRAIN_FILE, TEST_FILE, RAW_DATA_DIR, VALID_RATIO, SEED
# Vocabulary 클래스는 한국어 문장을 토큰 ID로 변환하기 위해 사용합니다.
from src.tokenizer import Vocabulary
# download_file 함수는 URL에서 파일을 내려받되, 이미 있으면 다시 받지 않습니다.
def download_file(url: str, path) -> None:
# 저장 폴더가 없으면 자동으로 생성합니다.
path.parent.mkdir(parents=True, exist_ok=True)
# 파일이 이미 존재하고 크기가 0보다 크면 다운로드를 생략합니다.
if path.exists() and path.stat().st_size > 0:
# 이미 있는 파일을 그대로 사용하므로 함수를 종료합니다.
return
# URL에서 지정 경로로 파일을 다운로드합니다.
urllib.request.urlretrieve(url, path)
# ensure_nsmc_downloaded 함수는 NSMC 학습/테스트 파일을 준비합니다.
def ensure_nsmc_downloaded() -> None:
# 원본 데이터 저장 폴더를 생성합니다.
RAW_DATA_DIR.mkdir(parents=True, exist_ok=True)
# NSMC 학습 데이터 파일을 다운로드합니다.
download_file(TRAIN_URL, TRAIN_FILE)
# NSMC 테스트 데이터 파일을 다운로드합니다.
download_file(TEST_URL, TEST_FILE)
# load_nsmc 함수는 NSMC 파일을 읽고 결측 리뷰를 제거합니다.
def load_nsmc(path) -> pd.DataFrame:
# NSMC는 id, document, label 컬럼을 가진 탭 구분 텍스트 파일입니다.
df = pd.read_csv(path, sep="\t")
# 리뷰 문장 또는 레이블이 없는 행을 제거합니다.
df = df.dropna(subset=["document", "label"])
# 레이블을 정수형으로 변환하여 손실 함수 입력 형식에 맞춥니다.
df["label"] = df["label"].astype(int)
# 인덱스를 0부터 다시 정리한 DataFrame을 반환합니다.
return df.reset_index(drop=True)
# NaverReviewDataset 클래스는 리뷰 문장과 감성 레이블을 텐서로 반환합니다.
class NaverReviewDataset(Dataset):
# __init__ 메서드는 DataFrame, 단어 사전, 최대 길이를 저장합니다.
def __init__(self, dataframe: pd.DataFrame, vocab: Vocabulary, max_len: int):
# 리뷰 문장 목록을 문자열 리스트로 저장합니다.
self.texts = dataframe["document"].astype(str).tolist()
# 정답 레이블 목록을 정수 리스트로 저장합니다.
self.labels = dataframe["label"].astype(int).tolist()
# 문장을 토큰 ID로 바꾸는 단어 사전을 저장합니다.
self.vocab = vocab
# 모델 입력 길이를 저장합니다.
self.max_len = max_len
# __len__ 메서드는 전체 샘플 개수를 반환합니다.
def __len__(self) -> int:
# 리뷰 문장 리스트의 길이가 전체 데이터 개수입니다.
return len(self.texts)
# __getitem__ 메서드는 특정 인덱스의 입력 텐서와 레이블 텐서를 반환합니다.
def __getitem__(self, index: int):
# 인덱스에 해당하는 리뷰 문장을 가져옵니다.
text = self.texts[index]
# 리뷰 문장을 고정 길이 정수 ID 리스트로 변환합니다.
input_ids = self.vocab.encode(text, self.max_len)
# 정수 ID 리스트를 LongTensor로 변환합니다.
x = torch.tensor(input_ids, dtype=torch.long)
# 정답 레이블을 LongTensor로 변환합니다.
y = torch.tensor(self.labels[index], dtype=torch.long)
# 모델 입력과 정답을 튜플로 반환합니다.
return x, y
# create_dataloaders 함수는 학습/검증/테스트 DataLoader를 생성합니다.
def create_dataloaders(vocab: Vocabulary, max_len: int, batch_size: int, sample_size: int = 0):
# NSMC 파일이 없으면 다운로드합니다.
ensure_nsmc_downloaded()
# 학습 파일을 DataFrame으로 읽습니다.
train_df = load_nsmc(TRAIN_FILE)
# 빠른 실습을 위해 sample_size가 양수이면 학습 데이터 일부만 사용합니다.
if sample_size and sample_size > 0:
# 지정한 샘플 수만큼 학습 데이터를 앞에서부터 선택합니다.
train_df = train_df.iloc[:sample_size].copy()
# 테스트 파일을 DataFrame으로 읽습니다.
test_df = load_nsmc(TEST_FILE)
# 전체 학습 데이터셋 객체를 생성합니다.
full_train_dataset = NaverReviewDataset(train_df, vocab, max_len)
# 테스트 데이터셋 객체를 생성합니다.
test_dataset = NaverReviewDataset(test_df, vocab, max_len)
# 검증 데이터 개수를 계산합니다.
valid_size = int(len(full_train_dataset) * VALID_RATIO)
# 학습 데이터 개수를 계산합니다.
train_size = len(full_train_dataset) - valid_size
# 재현 가능한 분할을 위해 torch Generator에 시드를 설정합니다.
generator = torch.Generator().manual_seed(SEED)
# 전체 학습 데이터셋을 학습용과 검증용으로 나눕니다.
train_dataset, valid_dataset = random_split(full_train_dataset, [train_size, valid_size], generator=generator)
# 학습 DataLoader는 데이터를 섞어서 미니배치를 구성합니다.
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
# 검증 DataLoader는 성능 평가용이므로 순서를 섞지 않습니다.
valid_loader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=False)
# 테스트 DataLoader는 최종 평가용이므로 순서를 섞지 않습니다.
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 세 가지 DataLoader를 반환합니다.
return train_loader, valid_loader, test_loader
model.py
import
# math는 scaled dot-product attention에서 sqrt 계산을 위해 사용합니다.
import math
# torch는 텐서 연산을 수행하기 위해 사용합니다.
import torch
# nn은 PyTorch 신경망 계층을 정의하기 위해 사용합니다.
from torch import nn
SelfAttention 클래스 생성
# SelfAttention 클래스는 Multi-Head Self-Attention을 직접 구현합니다.
class SelfAttention(nn.Module):
init()
임베딩 차원을 저장
attention head 개수 저장
head_dim head하나가 담당할 벡터 차원을 계산,
query 백터로 변환하는 선형 계층 저장
key 벡터로 변환하는 선형 계층 저장
value 벡터로 변환하는 선형 계층 저장
여러 head 출력을 다시 d_model 차원으로합치는 선형 계층 저장
def __init__(self, d_model: int, n_heads: int):
# nn.Module의 초기화 기능을 실행합니다.
super().__init__()
# 임베딩 차원이 head 개수로 나누어떨어지지 않으면 head별 차원을 만들 수 없습니다.
assert d_model % n_heads == 0, "d_model은 n_heads로 나누어떨어져야 합니다."
# 전체 임베딩 차원을 저장합니다.
self.d_model = d_model
# attention head 개수를 저장합니다.
self.n_heads = n_heads
# head 하나가 담당할 벡터 차원을 계산합니다.
self.head_dim = d_model // n_heads
# 입력 벡터를 Query 벡터로 변환하는 선형 계층입니다.
self.WQ = nn.Linear(d_model, d_model, bias=False)
# 입력 벡터를 Key 벡터로 변환하는 선형 계층입니다.
self.WK = nn.Linear(d_model, d_model, bias=False)
# 입력 벡터를 Value 벡터로 변환하는 선형 계층입니다.
self.WV = nn.Linear(d_model, d_model, bias=False)
# 여러 head의 출력을 다시 d_model 차원으로 합치는 선형 계층입니다.
self.WO = nn.Linear(d_model, d_model, bias=False)
forward()
입력텐서에서 배치 크기와 문장 길이를 가져온다.
query를 계산해 head 단위로 모양을 바꾸고,
key를 계산하고 head 단위로 모양을 바꾼다.
value를 계산하고 head 단위로 모양을 바꾼다.
토큰 간 관련도 점수를 계산한다. torch.matmul()
mask가 있으면 매우 작은 값으로 설정gksek.
softmax로 가중치를 계산하고 torch.matmul() 곱해 문맥이 반영된 표현을 계산한다.
context.transpose() head 차원을 다시 d_nodel() 차원으로 합친다. 이를 여러 head의 출력을 다시 d_model 차원으로 합치는 선형 계층 WO로 retun
# forward 메서드는 입력 토큰 시퀀스에 self-attention을 적용합니다.
def forward(self, x: torch.Tensor, pad_mask: torch.Tensor | None = None) -> torch.Tensor:
# 입력 텐서에서 배치 크기와 문장 길이를 가져옵니다.
batch_size, seq_len, _ = x.shape
# 입력 x에서 Query를 계산하고 head 단위로 모양을 바꿉니다.
q = self.WQ(x).view(batch_size, seq_len, self.n_heads, self.head_dim).transpose(1, 2)
# 입력 x에서 Key를 계산하고 head 단위로 모양을 바꿉니다.
k = self.WK(x).view(batch_size, seq_len, self.n_heads, self.head_dim).transpose(1, 2)
# 입력 x에서 Value를 계산하고 head 단위로 모양을 바꿉니다.
v = self.WV(x).view(batch_size, seq_len, self.n_heads, self.head_dim).transpose(1, 2)
# Query와 Key의 내적으로 토큰 간 관련도 점수를 계산합니다.
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.head_dim)
# pad_mask가 있으면 padding 위치가 attention에 참여하지 못하게 매우 작은 값으로 바꿉니다.
if pad_mask is not None:
# pad_mask를 attention score와 broadcasting 가능한 형태로 변환합니다.
mask = pad_mask[:, None, None, :]
# padding 위치의 score를 매우 작은 값으로 채워 softmax 결과가 거의 0이 되게 합니다.
scores = scores.masked_fill(mask, -1e9)
# score에 softmax를 적용하여 attention 가중치를 계산합니다.
attn = torch.softmax(scores, dim=-1)
# attention 가중치를 Value에 곱해 문맥이 반영된 표현을 계산합니다.
context = torch.matmul(attn, v)
# head 차원을 다시 하나의 d_model 차원으로 합칩니다.
context = context.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
# 최종 선형 계층을 통과시켜 attention 출력을 반환합니다.
return self.WO(context)
transformer블럭 클래스
# TransformerBlock 클래스는 Self-Attention, Residual, LayerNorm, FFN으로 구성된 인코더 블록입니다.
class TransformerBlock(nn.Module):
마찬가지로 init()
attention과 정규화를 위한 layernorm 생성, dropout과 작은신경망 ff생성
# __init__ 메서드는 블록 내부 계층을 초기화합니다.
def __init__(self, d_model: int, n_heads: int, ff_dim: int, dropout: float):
# nn.Module의 초기화 기능을 실행합니다.
super().__init__()
# Multi-Head Self-Attention 계층을 생성합니다.
self.attention = SelfAttention(d_model, n_heads)
# Attention 이후 정규화를 위한 LayerNorm 계층을 생성합니다.
self.norm1 = nn.LayerNorm(d_model)
# FFN 이후 정규화를 위한 LayerNorm 계층을 생성합니다.
self.norm2 = nn.LayerNorm(d_model)
# 과적합 완화와 안정적인 학습을 위한 Dropout 계층을 생성합니다.
self.dropout = nn.Dropout(dropout)
# 각 토큰 위치에 독립적으로 적용되는 Feed Forward Network를 생성합니다.
self.ff = nn.Sequential(
# d_model 차원을 ff_dim 차원으로 확장합니다.
nn.Linear(d_model, ff_dim),
# 비선형성을 추가하기 위해 ReLU 활성화 함수를 적용합니다.
nn.ReLU(),
# 중간 표현에 Dropout을 적용합니다.
nn.Dropout(dropout),
# ff_dim 차원을 다시 d_model 차원으로 축소합니다.
nn.Linear(ff_dim, d_model),
)
forward()
attention을 거친 뒤 norm1를 거쳐 ff작은 신경망을 거쳐 norm2다시 안정화
return x
# forward 메서드는 Transformer Block의 순전파를 수행합니다.
def forward(self, x: torch.Tensor, pad_mask: torch.Tensor | None = None) -> torch.Tensor:
# Self-Attention 결과를 계산합니다.
attn_out = self.attention(x, pad_mask)
# Residual Connection과 Dropout을 적용한 뒤 LayerNorm으로 안정화합니다.
x = self.norm1(x + self.dropout(attn_out))
# Feed Forward Network 결과를 계산합니다.
ff_out = self.ff(x)
# Residual Connection과 Dropout을 적용한 뒤 LayerNorm으로 안정화합니다.
x = self.norm2(x + self.dropout(ff_out))
# 블록 출력 텐서를 반환합니다.
return x
NaverTransformerSentiment() 클래스
# NaverTransformerSentiment 클래스는 한국어 리뷰 감성 분류를 위한 전체 모델입니다.
class NaverTransformerSentiment(nn.Module):
init()
마찬가지로 변수할당. 이때 embedding 계층을 생성해 단어 id를 의미벡터로 바꿀수있게.
위치 id도 위치 벡터로 바꾸는 embedding 계층 생성
dropout설정
block nn.ModuleList() TransformerBlock을 쌍아 Modulelist로 저장해 세팅.
classifier num_classes수로 nn.linear() 긍정/부정로빗으로 바꾸는 분류층
# __init__ 메서드는 임베딩, 위치 임베딩, Transformer 블록, 분류층을 초기화합니다.
def __init__(self, vocab_size: int, max_len: int, d_model: int, n_heads: int, n_layers: int, ff_dim: int, dropout: float, num_classes: int = 2):
# nn.Module의 초기화 기능을 실행합니다.
super().__init__()
# padding 토큰 ID를 저장합니다.
self.pad_id = 0
# 최대 문장 길이를 저장합니다.
self.max_len = max_len
# 단어 ID를 의미 벡터로 바꾸는 Embedding 계층을 생성합니다.
self.token_emb = nn.Embedding(vocab_size, d_model, padding_idx=self.pad_id)
# 위치 ID를 위치 벡터로 바꾸는 Embedding 계층을 생성합니다.
self.pos_emb = nn.Embedding(max_len, d_model)
# 임베딩 결과에 적용할 Dropout 계층을 생성합니다.
self.dropout = nn.Dropout(dropout)
# TransformerBlock을 n_layers개 쌓아 ModuleList로 저장합니다.
self.blocks = nn.ModuleList([TransformerBlock(d_model, n_heads, ff_dim, dropout) for _ in range(n_layers)])
# 문장 벡터를 긍정/부정 로짓으로 바꾸는 분류층을 생성합니다.
self.classifier = nn.Linear(d_model, num_classes)
forward()
장치이동
배치사이즈 및 문장길이 가져옴
pad 마스크 만들기
position 생성하기
단어임베딩과 위치 임베딩을 더해 x생성
dropout적용
for문으로 transformer block을 순서대로 통과시킨. block(x, pad_mask)
padding이 아닌 토큰 위치를 1로 표시하는 마스크.
실제 토큰만 남기고 padding 위치는 0으로 세팅.
실제 lengths 토큰 수를 계산하되 최소값은 1로 제한.
평균을 내어 대표하는 벡터를 만든다.
classifier() 문자엑터를 분류층에 넣어 클래스별 로짓 계산.
logits return
# forward 메서드는 토큰 ID 시퀀스를 받아 감성 클래스 점수를 반환합니다.
def forward(self, input_ids: torch.Tensor) -> torch.Tensor:
# 입력 텐서가 위치한 장치를 확인합니다.
device = input_ids.device
# 입력 텐서에서 배치 크기와 문장 길이를 가져옵니다.
batch_size, seq_len = input_ids.shape
# padding 토큰 위치를 True로 표시하는 마스크를 만듭니다.
pad_mask = input_ids.eq(self.pad_id)
# 0부터 seq_len-1까지의 위치 ID를 생성합니다.
positions = torch.arange(seq_len, device=device).unsqueeze(0).expand(batch_size, seq_len)
# 단어 임베딩과 위치 임베딩을 더해 순서 정보가 포함된 입력 표현을 만듭니다.
x = self.token_emb(input_ids) + self.pos_emb(positions)
# 임베딩 표현에 Dropout을 적용합니다.
x = self.dropout(x)
# Transformer Block을 순서대로 통과시킵니다.
for block in self.blocks:
# 현재 블록에 입력 표현과 padding mask를 전달합니다.
x = block(x, pad_mask)
# padding이 아닌 실제 토큰 위치를 1.0으로 표시하는 마스크를 만듭니다.
non_pad = (~pad_mask).float().unsqueeze(-1)
# 실제 토큰 표현만 남기고 padding 위치는 0으로 만듭니다.
masked_x = x * non_pad
# 실제 토큰 개수를 계산하되 0으로 나누는 문제를 방지하기 위해 최소값을 1로 제한합니다.
lengths = non_pad.sum(dim=1).clamp(min=1.0)
# 실제 토큰들의 평균을 내어 문장 전체를 대표하는 벡터를 만듭니다.
pooled = masked_x.sum(dim=1) / lengths
# 문장 벡터를 분류층에 넣어 클래스별 로짓을 계산합니다.
logits = self.classifier(pooled)
# 클래스별 로짓을 반환합니다.
return logits
train.py
import
argparse는 터미넣에서 epoch, batch size같은 옵션을 받을 때 사용한다.
tqdm 학습진행률을 보기좋게 출력하기 위해 사용한다.
config 설정값 가져오기
data 다운로드와 dataloader 생성함수 가져오기
tokenizer vocavulary 사전 가져오기 학습 데이터 기반 단어사전을 만들 수 있다.
model. naverTransformersentient 감성분류 모델 클래스 가져오기
# argparse는 터미널에서 epoch, batch size 같은 옵션을 받을 때 사용합니다.
import argparse
# random은 파이썬 기본 난수 시드를 고정하기 위해 사용합니다.
import random
# numpy는 NumPy 난수 시드를 고정하기 위해 사용합니다.
import numpy as np
# torch는 모델 학습과 텐서 연산을 위해 사용합니다.
import torch
# nn은 손실 함수를 사용하기 위해 불러옵니다.
from torch import nn
# tqdm은 학습 진행률을 보기 좋게 출력하기 위해 사용합니다.
from tqdm import tqdm
# 프로젝트 설정값을 가져옵니다.
from src.config import MAX_LEN, VOCAB_SIZE, BATCH_SIZE, D_MODEL, N_HEADS, N_LAYERS, FF_DIM, DROPOUT, LEARNING_RATE, EPOCHS, SEED, MODEL_PATH, VOCAB_PATH, CHECKPOINT_DIR, TRAIN_FILE
# NSMC 데이터 다운로드와 DataLoader 생성 함수를 가져옵니다.
from src.data import ensure_nsmc_downloaded, load_nsmc, create_dataloaders
# Vocabulary 클래스는 학습 데이터 기반 단어 사전을 만들기 위해 사용합니다.
from src.tokenizer import Vocabulary
# Transformer 감성 분류 모델 클래스를 가져옵니다.
from src.model import NaverTransformerSentiment
시드설정
# set_seed 함수는 실행할 때마다 최대한 같은 결과가 나오도록 난수 시드를 고정합니다.
def set_seed(seed: int) -> None:
# 파이썬 random 모듈의 난수 시드를 고정합니다.
random.seed(seed)
# NumPy 난수 시드를 고정합니다.
np.random.seed(seed)
# PyTorch CPU 난수 시드를 고정합니다.
torch.manual_seed(seed)
# CUDA 사용 가능 시 GPU 난수 시드도 고정합니다.
torch.cuda.manual_seed_all(seed)
한 epoch동안 학습하는 함수
model.train()
손실값, 맞힌 샘플 수 , 전체 샘플수 변수 초기화
for문으로 돌려 dataloader에서 미니배치를 하나씩 가져온다.
model()모델에 입력을 넣고 클래스별 로짓을 계산해 criteriton, backward, optimizer,step(), total_loss와 가장 큰 값을 가진 클래ㅐ스를 예측값으로 설정하고 예측값과 정답이 같은 샘플 수를 누적,해 return
# train_one_epoch 함수는 모델을 한 epoch 동안 학습합니다.
def train_one_epoch(model, loader, criterion, optimizer, device):
# 모델을 학습 모드로 전환하여 Dropout이 학습 방식으로 동작하게 합니다.
model.train()
# 누적 손실값을 저장할 변수를 초기화합니다.
total_loss = 0.0
# 맞힌 샘플 수를 저장할 변수를 초기화합니다.
total_correct = 0
# 전체 샘플 수를 저장할 변수를 초기화합니다.
total_count = 0
# DataLoader에서 미니배치를 하나씩 가져옵니다.
for x, y in tqdm(loader, desc="train", leave=False):
# 입력 토큰 ID 텐서를 학습 장치로 이동합니다.
x = x.to(device)
# 정답 레이블 텐서를 학습 장치로 이동합니다.
y = y.to(device)
# 이전 미니배치에서 계산된 기울기를 초기화합니다.
optimizer.zero_grad()
# 모델에 입력을 넣어 클래스별 로짓을 계산합니다.
logits = model(x)
# 로짓과 정답 레이블을 비교하여 손실을 계산합니다.
loss = criterion(logits, y)
# 손실을 기준으로 역전파를 수행하여 기울기를 계산합니다.
loss.backward()
# 계산된 기울기를 이용해 모델 파라미터를 업데이트합니다.
optimizer.step()
# 현재 미니배치 손실에 샘플 수를 곱해 누적합니다.
total_loss += loss.item() * x.size(0)
# 가장 큰 로짓을 가진 클래스를 예측값으로 선택합니다.
pred = torch.argmax(logits, dim=1)
# 예측값과 정답이 같은 샘플 수를 누적합니다.
total_correct += (pred == y).sum().item()
# 현재 미니배치 샘플 수를 누적합니다.
total_count += x.size(0)
# 평균 손실과 정확도를 계산하여 반환합니다.
return total_loss / total_count, total_correct / total_count
평가함수
디바이스를 이동해 model(x)모델에 입력값을 넣어 logits를 얻어내 criterion, loss, pred,를 구해 평균손실과 정확도를 계산해 return
# evaluate 함수는 검증/테스트 데이터에 대한 손실과 정확도를 계산합니다.
def evaluate(model, loader, criterion, device):
# 모델을 평가 모드로 전환하여 Dropout이 비활성화되게 합니다.
model.eval()
# 누적 손실값을 저장할 변수를 초기화합니다.
total_loss = 0.0
# 맞힌 샘플 수를 저장할 변수를 초기화합니다.
total_correct = 0
# 전체 샘플 수를 저장할 변수를 초기화합니다.
total_count = 0
# 평가에서는 기울기를 계산하지 않아 메모리와 시간을 줄입니다.
with torch.no_grad():
# DataLoader에서 미니배치를 하나씩 가져옵니다.
for x, y in tqdm(loader, desc="eval", leave=False):
# 입력 토큰 ID 텐서를 평가 장치로 이동합니다.
x = x.to(device)
# 정답 레이블 텐서를 평가 장치로 이동합니다.
y = y.to(device)
# 모델에 입력을 넣어 클래스별 로짓을 계산합니다.
logits = model(x)
# 로짓과 정답 레이블을 비교하여 손실을 계산합니다.
loss = criterion(logits, y)
# 현재 미니배치 손실에 샘플 수를 곱해 누적합니다.
total_loss += loss.item() * x.size(0)
# 가장 큰 로짓을 가진 클래스를 예측값으로 선택합니다.
pred = torch.argmax(logits, dim=1)
# 예측값과 정답이 같은 샘플 수를 누적합니다.
total_correct += (pred == y).sum().item()
# 현재 미니배치 샘플 수를 누적합니다.
total_count += x.size(0)
# 평균 손실과 정확도를 계산하여 반환합니다.
return total_loss / total_count, total_correct / total_count
main()
argumentparser() 명령행 옵션을 처리할 객체를 생성한다. 옵션을 추가한다.
입력 옵션을 파싱한다.
시드고정.
장치설정
파일다운로드
load_nsmc() 데이터 읽기
학습 단어사전 생성.
단어사전에 학습리뷰토큰 빈도를 반영해 json파일로 저장.
dataloader 생성
model 생성
장치이동
손실함수 만들기
optimizer 만ㄷㄹ기
epoch 만큼 for문으로 돌려 train_one_epoch()를 하고, evaluate() 평가.
정확도가 최고보다 높으면 모델을 저장.
최고모델 파라미터를 불러와 모델에 적용해 평가해 print()
# main 함수는 데이터 준비, 모델 생성, 학습, 저장 과정을 순서대로 실행합니다.
def main():
# 명령행 옵션을 처리할 ArgumentParser 객체를 생성합니다.
parser = argparse.ArgumentParser(description="NSMC Transformer 감성 분류 모델 학습")
# epoch 수를 터미널에서 변경할 수 있게 옵션을 추가합니다.
parser.add_argument("--epochs", type=int, default=EPOCHS)
# batch size를 터미널에서 변경할 수 있게 옵션을 추가합니다.
parser.add_argument("--batch-size", type=int, default=BATCH_SIZE)
# 최대 문장 길이를 터미널에서 변경할 수 있게 옵션을 추가합니다.
parser.add_argument("--max-len", type=int, default=MAX_LEN)
# 단어 사전 크기를 터미널에서 변경할 수 있게 옵션을 추가합니다.
parser.add_argument("--vocab-size", type=int, default=VOCAB_SIZE)
# 빠른 테스트용으로 학습 데이터 일부만 사용할 수 있게 옵션을 추가합니다.
parser.add_argument("--sample-size", type=int, default=0, help="0이면 전체 데이터 사용, 양수이면 일부 샘플만 사용")
# 터미널 입력 옵션을 파싱합니다.
args = parser.parse_args()
# 실험 재현성을 위해 난수 시드를 고정합니다.
set_seed(SEED)
# GPU가 있으면 cuda를 사용하고 없으면 cpu를 사용합니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 체크포인트 저장 폴더를 생성합니다.
CHECKPOINT_DIR.mkdir(parents=True, exist_ok=True)
# NSMC 데이터 파일을 다운로드합니다.
ensure_nsmc_downloaded()
# 학습 데이터를 DataFrame으로 읽습니다.
train_df = load_nsmc(TRAIN_FILE)
# sample_size가 양수이면 빠른 실습을 위해 일부 데이터만 사용합니다.
if args.sample_size and args.sample_size > 0:
# 지정한 샘플 수만큼 학습 데이터를 앞에서부터 선택합니다.
train_df = train_df.iloc[: args.sample_size].copy()
# 학습 리뷰 문장으로 단어 사전을 생성합니다.
vocab = Vocabulary(max_size=args.vocab_size, min_freq=2)
# 단어 사전에 학습 리뷰의 토큰 빈도를 반영합니다.
vocab.build(train_df["document"].astype(str).tolist())
# 생성된 단어 사전을 JSON 파일로 저장합니다.
vocab.save(VOCAB_PATH)
# 학습/검증/테스트 DataLoader를 생성합니다.
train_loader, valid_loader, test_loader = create_dataloaders(vocab, args.max_len, args.batch_size, args.sample_size)
# Transformer 감성 분류 모델을 생성합니다.
model = NaverTransformerSentiment(len(vocab), args.max_len, D_MODEL, N_HEADS, N_LAYERS, FF_DIM, DROPOUT)
# 모델을 CPU 또는 GPU 장치로 이동합니다.
model = model.to(device)
# 다중 클래스 분류에 적합한 CrossEntropyLoss를 손실 함수로 사용합니다.
criterion = nn.CrossEntropyLoss()
# AdamW는 Adam에 weight decay를 안정적으로 적용하는 최적화 함수입니다.
optimizer = torch.optim.AdamW(model.parameters(), lr=LEARNING_RATE)
# 가장 좋은 검증 정확도를 저장할 변수를 초기화합니다.
best_valid_acc = 0.0
# 지정한 epoch 수만큼 학습을 반복합니다.
for epoch in range(1, args.epochs + 1):
# 한 epoch 동안 학습을 수행하고 손실/정확도를 받습니다.
train_loss, train_acc = train_one_epoch(model, train_loader, criterion, optimizer, device)
# 검증 데이터로 현재 모델 성능을 평가합니다.
valid_loss, valid_acc = evaluate(model, valid_loader, criterion, device)
# 현재 epoch 결과를 화면에 출력합니다.
print(f"Epoch {epoch}/{args.epochs} | train_loss={train_loss:.4f}, train_acc={train_acc:.4f}, valid_loss={valid_loss:.4f}, valid_acc={valid_acc:.4f}")
# 검증 정확도가 기존 최고 정확도보다 높으면 모델을 저장합니다.
if valid_acc > best_valid_acc:
# 최고 검증 정확도를 갱신합니다.
best_valid_acc = valid_acc
# 모델 파라미터와 설정값을 체크포인트 파일로 저장합니다.
torch.save({"model_state_dict": model.state_dict(), "max_len": args.max_len, "vocab_size": len(vocab)}, MODEL_PATH)
# 저장 완료 메시지를 출력합니다.
print(f"모델 저장 완료: {MODEL_PATH}")
# 저장된 최고 모델 파라미터를 다시 불러옵니다.
checkpoint = torch.load(MODEL_PATH, map_location=device)
# 체크포인트의 파라미터를 현재 모델에 적용합니다.
model.load_state_dict(checkpoint["model_state_dict"])
# 테스트 데이터로 최종 성능을 평가합니다.
test_loss, test_acc = evaluate(model, test_loader, criterion, device)
# 최종 테스트 결과를 출력합니다.
print(f"최종 테스트 결과 | test_loss={test_loss:.4f}, test_acc={test_acc:.4f}")
# 이 파일을 직접 실행할 때만 main 함수를 호출합니다.
if __name__ == "__main__":
# 전체 학습 절차를 시작합니다.
main()
predict.py
load_model_and_voacb()
디바이스가 없으면 cpu로
사전을 복원해 저장, 읽기. 체크포인트 읽기, len 읽기, 모델생성, 체크포인트의 학습된 파라미터를 모델에 적용, 평가모드 전환, 반환.
predict_sentiment
입력문장을 정수 id리스트로 변환해 longtensor로 변환. model() 돌리기, softmax() 확률로 변환해 가장 높은 클래스 id선택, label긍정 부정을 나누어 확률을 실수로 float 추출해 반환
"""학습된 Transformer 모델로 새로운 한국어 리뷰의 감성을 예측하는 파일입니다."""
# torch는 모델 로딩과 예측 연산에 사용합니다.
import torch
# 프로젝트 설정값을 가져옵니다.
from src.config import MODEL_PATH, VOCAB_PATH, MAX_LEN, D_MODEL, N_HEADS, N_LAYERS, FF_DIM, DROPOUT
# Transformer 감성 분류 모델 클래스를 가져옵니다.
from src.model import NaverTransformerSentiment
# 저장된 단어 사전을 불러오기 위해 Vocabulary 클래스를 가져옵니다.
from src.tokenizer import Vocabulary
# load_model_and_vocab 함수는 저장된 단어 사전과 모델을 함께 불러옵니다.
def load_model_and_vocab(device: torch.device | None = None):
# device가 전달되지 않으면 GPU 가능 여부에 따라 자동으로 선택합니다.
device = device or torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 단어 사전 파일이 없으면 학습을 먼저 실행해야 하므로 오류를 발생시킵니다.
if not VOCAB_PATH.exists() or not MODEL_PATH.exists():
# 사용자에게 학습 명령을 안내하는 오류 메시지를 제공합니다.
raise FileNotFoundError("모델 파일이 없습니다. 먼저 `python -m src.train` 명령으로 학습을 실행하세요.")
# JSON 파일에서 단어 사전을 복원합니다.
vocab = Vocabulary.load(VOCAB_PATH)
# 저장된 모델 체크포인트를 지정 장치 기준으로 읽습니다.
checkpoint = torch.load(MODEL_PATH, map_location=device)
# 체크포인트에 저장된 최대 길이를 우선 사용하고 없으면 설정값을 사용합니다.
max_len = int(checkpoint.get("max_len", MAX_LEN))
# 단어 사전 크기와 저장된 설정으로 모델 구조를 생성합니다.
model = NaverTransformerSentiment(len(vocab), max_len, D_MODEL, N_HEADS, N_LAYERS, FF_DIM, DROPOUT)
# 체크포인트의 학습된 파라미터를 모델에 적용합니다.
model.load_state_dict(checkpoint["model_state_dict"])
# 모델을 예측 장치로 이동합니다.
model = model.to(device)
# 모델을 평가 모드로 전환합니다.
model.eval()
# 모델, 단어 사전, 최대 길이, 장치를 반환합니다.
return model, vocab, max_len, device
# predict_sentiment 함수는 리뷰 문장 하나를 받아 감성 라벨과 확률을 반환합니다.
def predict_sentiment(text: str, model, vocab: Vocabulary, max_len: int, device: torch.device):
# 입력 문장을 학습 때와 같은 방식으로 정수 ID 리스트로 변환합니다.
ids = vocab.encode(text, max_len)
# 정수 ID 리스트를 배치 차원이 있는 LongTensor로 변환합니다.
x = torch.tensor([ids], dtype=torch.long).to(device)
# 예측 과정에서는 기울기 계산이 필요 없으므로 비활성화합니다.
with torch.no_grad():
# 모델에 입력을 넣어 클래스별 로짓을 계산합니다.
logits = model(x)
# softmax를 적용해 클래스별 확률로 변환합니다.
probs = torch.softmax(logits, dim=1).squeeze(0)
# 가장 높은 확률의 클래스 ID를 선택합니다.
pred_id = int(torch.argmax(probs).item())
# 클래스 ID가 1이면 긍정, 0이면 부정으로 해석합니다.
label = "긍정" if pred_id == 1 else "부정"
# 긍정 클래스 확률을 실수로 추출합니다.
positive_prob = float(probs[1].item())
# 부정 클래스 확률을 실수로 추출합니다.
negative_prob = float(probs[0].item())
# 예측 결과를 딕셔너리로 반환합니다.
return {"label": label, "positive_prob": positive_prob, "negative_prob": negative_prob}
위 기능을 streamlit에 연결하면 끝.
"""Streamlit 화면에서 한국어 영화 리뷰 감성을 예측하는 앱입니다."""
# sys는 src 폴더를 import 경로에 추가하기 위해 사용합니다.
import sys
# Path는 프로젝트 루트 경로를 계산하기 위해 사용합니다.
from pathlib import Path
# streamlit은 웹 화면을 구성하기 위해 사용합니다.
import streamlit as st
# torch는 CPU/GPU 장치 선택에 사용합니다.
import torch
# 현재 파일 기준으로 프로젝트 루트 경로를 계산합니다.
PROJECT_ROOT = Path(__file__).resolve().parents[1]
# 프로젝트 루트 경로를 파이썬 import 검색 경로에 추가합니다.
sys.path.append(str(PROJECT_ROOT))
# 학습된 모델과 단어 사전을 불러오는 함수를 가져옵니다.
from src.predict import load_model_and_vocab, predict_sentiment
# load_resource 함수는 Streamlit 캐시를 사용해 모델을 한 번만 로딩합니다.
@st.cache_resource
# 캐시된 모델/단어 사전/설정값을 반환하는 함수를 정의합니다.
def load_resource():
# GPU가 있으면 cuda, 없으면 cpu를 사용하도록 장치를 선택합니다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 저장된 모델, 단어 사전, 최대 길이, 장치를 불러옵니다.
model, vocab, max_len, device = load_model_and_vocab(device)
# 로딩된 객체들을 반환합니다.
return model, vocab, max_len, device
# main 함수는 Streamlit 화면 전체를 구성합니다.
def main():
# Streamlit 페이지 제목, 아이콘, 화면 폭을 설정합니다.
st.set_page_config(page_title="네이버 영화 리뷰 감성 분류", page_icon="🎬", layout="centered")
# 앱의 큰 제목을 출력합니다.
st.title("🎬 네이버 영화 리뷰 감성 분류")
# 앱의 간단한 설명 문장을 출력합니다.
st.write("한국어 영화 리뷰 문장을 입력하면 Transformer 모델이 긍정/부정을 예측합니다.")
# 구분선을 출력하여 화면 영역을 나눕니다.
st.divider()
# 모델 파일이 없을 때 보여 줄 안내 문장을 미리 준비합니다.
train_help = "모델이 없으면 PyCharm 터미널에서 `python -m src.train --epochs 3` 명령을 먼저 실행하세요."
# 사용자가 리뷰 문장을 입력할 수 있는 큰 텍스트 입력창을 만듭니다.
review_text = st.text_area("리뷰 문장 입력", value="배우들의 연기가 좋고 스토리가 감동적이었어요.", height=140)
# 예측 실행 버튼을 만듭니다.
clicked = st.button("감성 예측하기", type="primary")
# 버튼이 클릭되었을 때만 예측을 수행합니다.
if clicked:
# 입력 문장이 비어 있으면 경고 메시지를 출력합니다.
if not review_text.strip():
# 빈 입력에 대한 사용자 안내를 표시합니다.
st.warning("리뷰 문장을 입력하세요.")
# 이후 예측 로직을 실행하지 않기 위해 함수를 종료합니다.
return
# 모델 로딩 또는 예측 중 오류가 날 수 있으므로 예외 처리를 사용합니다.
try:
# 캐시된 모델과 단어 사전을 불러옵니다.
model, vocab, max_len, device = load_resource()
# 입력 리뷰에 대한 감성 예측을 수행합니다.
result = predict_sentiment(review_text, model, vocab, max_len, device)
# 예측 결과 라벨을 큰 글씨로 출력합니다.
st.subheader(f"예측 결과: {result['label']}")
# 긍정 확률을 progress bar로 표시합니다.
st.progress(result["positive_prob"], text=f"긍정 확률: {result['positive_prob']:.2%}")
# 부정 확률을 progress bar로 표시합니다.
st.progress(result["negative_prob"], text=f"부정 확률: {result['negative_prob']:.2%}")
# 현재 모델이 실행된 장치 정보를 출력합니다.
st.caption(f"실행 장치: {device}")
# 모델 파일이 없을 때 발생하는 오류를 처리합니다.
except FileNotFoundError as error:
# 모델 학습이 필요하다는 오류 메시지를 출력합니다.
st.error(str(error))
# 학습 명령 안내 문장을 출력합니다.
st.info(train_help)
# 그 외 예상하지 못한 오류를 처리합니다.
except Exception as error:
# 오류 내용을 화면에 표시합니다.
st.error(f"예측 중 오류가 발생했습니다: {error}")
# 학습 명령 안내 문장을 함께 출력합니다.
st.info(train_help)
# 화면 하단에 학습 명령을 안내합니다.
with st.expander("학습 실행 방법 보기"):
# PyCharm 터미널에서 실행할 명령을 코드 블록으로 표시합니다.
st.code("pip install -r requirements.txt\npython -m src.train --epochs 3\nstreamlit run app/streamlit_app.py", language="bash")
# 이 파일을 직접 실행할 때만 main 함수를 호출합니다.
if __name__ == "__main__":
# Streamlit 앱 화면을 실행합니다.
main()
'Personal > SK 네트웍스 AI 캠프' 카테고리의 다른 글
| SK 네트웍스 AI 캠프 - 3_초거대언어모델(LLM) - Day39_LLM의 개념과 API (0) | 2026.07.03 |
|---|---|
| SK 네트웍스 AI 캠프 - 3_초거대언어모델(LLM) - Day37_자연어 처리를 위한 번역 모델 구조 (0) | 2026.07.01 |
| SK 네트웍스 AI 캠프 - 3_초거대언어모델(LLM) - Day36_자연어 처리를 위한 언어 모델 (0) | 2026.06.30 |
| SK 네트웍스 AI 캠프 - 3_초거대언어모델(LLM) - Day35_자연어 처리를 위한 텍스트 분류 (0) | 2026.06.30 |
| [SK네트웍스 Family AI 캠프] 32기 9주차 회고: Day32 ~ Day34 (0) | 2026.06.26 |



