텍스트 분류
컴퓨터가 문장이나 문서의 내용을 분석해 미리 정해진 범주중 하나 또는 여러개로 자동분류하는 자연어처리의 대표적인 기술
대량의 문서를 사람이 직접 읽지않고 자동으로 분석하기 위함.
텍스트 수집 - 텍스트 전처리 - 형태소 분석 - 불용어 제거 - 벡터화 - 모델학습 - 예측 및 평가
이진분류: 두개 클래스만 존재한다.
다중분류: 세개 이상의 클래스 중 하나를 선택한다.
다중레벨분류: 하나의 문장이 여러개의 클래스를 동시에 가진다.
텍스트 전처리: 소문자변환 - 특수문자제거 - 형태소분석 - 불용어 제거 - 토큰 생성 - 벡터화
형태소분석
문장을 의미있는 최소단위로 분리한다.
KoNLPy, Mecab, Okt, Komoran, Kkma, Hannanum
KoNLPy: 여러 한국어 형태소 분석기를 사용할 수 있도록 제공하는 대표적인 한국어 자연어 처리 라이브러리이다.
MeCab: 빠른 처리 속도와 높은 정확도를 제공하여 대용량 한국어 형태소 분석에 많이 사용된다.
Okt: SNS나 일상 대화처럼 구어체와 신조어 처리에 강점을 가진 형태소 분석기이다.
Komoran: 안정적인 품사 분석 성능을 제공하여 다양한 한국어 자연어 처리 작업에 활용된다.
Kkma: 문장 분리와 상세한 품사 분석 기능을 제공하지만 처리 속도는 다소 느린 편이다.
Hannanum: KAIST에서 개발한 형태소 분석기로 다양한 형태소 분석 기능을 제공한다.
한글은 영문과 다르게 불용어사전이 지원이 되지않아 직접 설정행.
토큰화: 문장을 단어 단위로 분리
정수인코딩: 단어를 숫자로 변환
패딩: 문장의 길이를 동일하게 만듬
벡터화: 컴퓨터가 이해핳 수 있도록 숫자로 변환
BOW, TF-IDFm Word2Vec, FastText, GloVe, BERT Embedding
Bag-of-Words> (BoW): 문서에 등장한 단어의 빈도를 이용하여 텍스트를 숫자 벡터로 변환하는 가장 기본적인 방법이다.
TF-IDF: 단어의 빈도와 문서 전체에서의 중요도를 함께 반영하여 텍스트를 벡터로 변환하는 방법이다.
Word2Vec: 단어의 의미와 문맥 관계를 학습하여 의미가 비슷한 단어를 가까운 벡터로 표현하는 방법이다.
FastText: 단어를 부분 문자열(Subword) 단위까지 학습하여 신조어나 희귀 단어도 효과적으로 표현하는 방법이다.
GloVe: 단어의 전체 출현 통계를 이용하여 의미 관계를 반영한 단어 벡터를 생성하는 방법이다.
BERT Embedding: BERT를 이용하여 문맥을 고려한 단어 또는 문장 임베딩을 생성하는 방법이다.
전통적인 머신러닝에서 사용되는 알고리즘
비교적 적은 데이터에서도 좋은 성능을 보이며 BOW나 TF-IDF 와 함게 많이 사용됨.
Naive Bayes, Logistic Regression, Decision tree, Random Forest, Support Vector Machine(SVM), XGBoost, LightGBM...
Naive Bayes: 단어들이 서로 독립이라고 가정하여 확률을 계산하는 빠르고 간단한 텍스트 분류 모델이다.
Logistic Regression: 입력 데이터가 특정 클래스에 속할 확률을 계산하여 분류하는 대표적인 선형 분류 모델이다.
Decision Tree: 조건을 순차적으로 분기하여 데이터를 분류하는 트리 구조의 모델이다.
Random Forest: 여러 개의 결정 트리를 결합하여 더 안정적이고 높은 분류 성능을 제공하는 앙상블 모델이다.
Support Vector Machine> (SVM): 클래스 간의 경계를 가장 크게 만드는 초평면을 찾아 데이터를 분류하는 모델이다.
XGBoost: 여러 개의 약한 모델을 순차적으로 학습하여 높은 예측 성능을 제공하는 부스팅 모델이다.
LightGBM: 대용량 데이터에서도 빠른 학습 속도와 높은 성능을 제공하는 경량 부스팅 모델이다.
사용되는 딥러닝 모델
RNN LSTM GRU, CNN, Transformer, BERT, GPT
RNN (Recurrent Neural Network): 이전 정보를 기억하며 순차적인 데이터를 처리하는 순환 신경망이다.
LSTM (Long Short-Term Memory): RNN의 장기 의존성 문제를 개선하여 중요한 정보를 오래 기억할 수 있도록 만든 모델이다.
GRU (Gated Recurrent Unit): LSTM을 단순화하여 적은 연산으로 비슷한 성능을 내는 순환 신경망이다.
CNN (Convolutional Neural Network): 합성곱 연산을 이용해 이미지나 텍스트의 중요한 특징을 추출하는 신경망이다.
Transformer: Attention 메커니즘을 사용하여 문장 전체의 관계를 동시에 학습하는 딥러닝 모델이다.
BERT: Transformer의 인코더를 기반으로 문장의 앞뒤 문맥을 함께 이해하도록 사전 학습된 언어 모델이다.
GPT: Transformer의 디코더를 기반으로 이전 단어를 바탕으로 다음 단어를 예측하며 자연스러운 문장을 생성하는 언어 모델이다.
성능평가
Accuracy, Precision, Recall, F1-Score, Confusion Matrix, ROC-AUC
최근 NLP 분야 기술은 단어의 출현빈도 BOW나 TF-IDF방식에서 벗어나 대규모 텍스트데이터를 사전에 학습한 사전학습 언어모델 PLM 과 생성형 대규모 언어모델 LLM을 활용하는 방법으로 발전하고있다.
BERT 계열 모델
BERT, RoBERTa, DistillBERT, ALBERT, ELECTRAm DeBERTa, KoBERT, KR-BERT, KoELECTRA
BERT: 양방향 문맥을 동시에 학습하여 문장의 의미를 깊이 이해하는 Transformer 기반 언어 모델이다.
RoBERTa: BERT의 학습 방식을 개선하여 더 많은 데이터와 긴 학습으로 성능을 향상시킨 모델이다.
DistilBERT: BERT를 경량화하여 속도는 높이고 모델 크기는 줄이면서 성능을 최대한 유지한 모델이다.
ALBERT: 파라미터를 공유하는 방식으로 모델 크기를 크게 줄인 경량 BERT 모델이다.
ELECTRA: 가짜 토큰을 구별하는 방식으로 학습하여 적은 학습량으로도 높은 성능을 내는 모델이다.
DeBERTa: 단어 정보와 위치 정보를 분리하여 처리하는 Attention 구조로 BERT보다 성능을 개선한 모델이다.
KoBERT: 한국어 데이터를 기반으로 사전 학습된 BERT 모델로 한국어 자연어 처리에 특화되어 있다.
KR-BERT: 한국어 문법과 형태소 특성을 반영하여 학습한 한국어 BERT 모델이다.
KoELECTRA: ELECTRA 구조를 한국어 데이터에 적용하여 빠른 학습과 높은 성능을 제공하는 한국어 언어 모델이다.
Zero-shot Classification
추가학습없이도 텍스트를 분류하는 방법
분류데이터를 학습하지않고, 라벨링 데이터가 없어도 된다. 새로운 분야 데이터에도 빠르게 적용할 수 있다는 장점. 자신의 사전학습 지식을 활용해 가장 적절한 범주를 선택한다.
Few-shot Classification
몇개의 예시만 제공한 후 새로운 문장을 분류하는 방식
'친절한상담에 만족했습니다'는 긍정, '제품 품질이 좋지않습니다'는 부정으로 예시를 주면 모델은 예시를 참고해 긍정부정을 분류하며 새로운 업무에 빠르게 적용할 수 있어 실무에서 자주 사용된다.
In-context Learning
모델의 가중치를 변경하지않고 프롬프트에 포함된 예시만으로 새로운 작업을 수행하는 학습 방식.
입력, 예시1, 2, 3, 새로운 문장 형태의 프롬프트만 제공하면 모델이 패턴을 이해하며 분류를 수행한다. 대규모 모델의 가장 큰 특징 중 하나이며 새로운 업무에 적용할 수 있다는 장점이 있다.
RAG 검색 증강 생성을 이용한 텍스트 분류
RAG Retrieval-Augmented Generation은 검색 Retrieval 과 생성 Generation을 결합한 기술
LLM과 다르게 학습 이후 외부 문서나 데이터베이스에서 필요한 정보를 검색해 결과를 바탕으로 분류나 답변을 수행한다.
최신문서나 사내 데이터와 같은 모델이 학습하지않은 정보도 활용할 수 있어 정확도가 향상된다. 사내문서자동분류, 고객상담이력분류, 법률문서 검색 및 분류, 의료논문분류, 연구논문분류, 연구논문분류, 이메일 자동분류
대표적인 Vector Database는 Qdrant, FAISS, Milvus, Vhroma, Pinecone, Weaviate가 있다.
Hybrid 텍스트 분류 모델
실무에서는 하나의 방법만 사용하는 경우보다 여러 기법을 결합한 하이브리드 모델을 사용한다.
기존 통계 기반 특징과 딥러닝 기반 의미 정보를 함께 활용하여 성능을 향상시키는 것이 목적이다.
TF-IDF + SVM, TF-IDF + XGBoost, BERT + Softmax, Sentence-BERT + Random Forest, Sentence-BERT + XGBoost, Embedding + Vector Search + LLM, RAG + LLM, Graph Neural Network + Transformer
TF-IDF + SVM: 데이터가 많지 않고 뉴스, 리뷰, 스팸 메일처럼 전통적인 텍스트 분류를 빠르고 정확하게 수행할 때 사용한다.
TF-IDF + XGBoost: 단어 빈도 정보와 강력한 부스팅 알고리즘을 결합하여 높은 분류 성능이 필요한 경우 사용한다.
BERT + Softmax: 문장의 문맥을 이해하여 감성 분석, 의도 분류, 뉴스 분류 등 일반적인 자연어 분류 작업에 사용한다.
Sentence-BERT + Random Forest: 문장을 임베딩한 뒤 비교적 적은 데이터에서도 안정적인 문장 분류를 수행할 때 사용한다.
Sentence-BERT + XGBoost: 문장 임베딩과 부스팅 모델을 결합하여 문맥 정보를 활용하면서 높은 예측 성능이 필요한 경우 사용한다.
Embedding + Vector Search + LLM: 대규모 문서에서 관련 내용을 검색한 후 LLM이 이를 바탕으로 답변하는 검색 기반 AI 시스템에 사용한다.
RAG + LLM: 외부 문서를 검색하여 최신 정보나 사내 지식을 반영한 정확한 답변을 생성할 때 사용한다.
Graph Neural Network + Transformer: 문서 간 관계나 지식 그래프 구조와 문맥 정보를 함께 활용해야 하는 복잡한 자연어 처리 작업에 사용한다.
최근 실무는 단순히 문서를 카테고리로 분류하는 것을 넘어서 검색, 분류, 요약, 질의응답을 하나 시스템으로 통합하는 방향으로 발전하고있다.
문서수집 - 텍승트 전처리 - 문서 임베딩 생성 - 벡터 데이터베이스 저장 - 사용자질의 입력 - 유사문서 검색 - LLM 분석 - 문서분류 - 요약생성 - 질의응답
코드 분석 Reuters_News_classification
import
# 운영체제와 파일 경로를 다루기 위해 os 모듈을 불러온다.
import os
# 실행 시간을 측정하거나 로그를 남길 때 사용할 수 있도록 time 모듈을 불러온다.
import time
# 난수 고정을 통해 매번 비슷한 실험 결과가 나오도록 random 모듈을 불러온다.
import random
# NumPy는 배열 처리와 수치 계산을 효율적으로 수행하기 위해 사용한다.
import numpy as np
# Matplotlib은 데이터 분포와 학습 결과를 그래프로 시각화하기 위해 사용한다.
import matplotlib.pyplot as plt
# PyTorch의 핵심 패키지로, Tensor 생성과 딥러닝 연산을 수행한다.
import torch
# torch.nn은 신경망 계층, 손실 함수, 활성화 함수 등을 제공한다.
import torch.nn as nn
# torch.optim은 Adam, SGD 같은 최적화 알고리즘을 제공한다.
import torch.optim as optim
# TensorDataset은 입력 Tensor와 정답 Tensor를 하나의 데이터셋으로 묶을 때 사용한다.
from torch.utils.data import TensorDataset
# DataLoader는 Dataset을 미니배치 단위로 나누어 학습 반복문에 공급한다.
from torch.utils.data import DataLoader
# 현재 설치된 PyTorch 버전을 출력하여 실행 환경을 확인한다.
print("PyTorch version:", torch.__version__)
# CUDA GPU를 사용할 수 있으면 GPU를 사용하고, 없으면 CPU를 사용하도록 장치를 설정한다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 실제 학습에 사용할 장치를 출력한다.
print("사용 장치:", device)
난수고정
# 실험 결과의 재현성을 높이기 위해 난수를 고정하는 함수를 정의한다.
def set_seed(seed=42):
# 파이썬 기본 random 모듈의 난수 시드를 고정한다.
random.seed(seed)
# NumPy에서 사용하는 난수 시드를 고정한다.
np.random.seed(seed)
# PyTorch CPU 연산에서 사용하는 난수 시드를 고정한다.
torch.manual_seed(seed)
# GPU가 사용 가능한 경우 모든 CUDA 장치의 난수 시드를 고정한다.
torch.cuda.manual_seed_all(seed)
# CuDNN 연산에서 가능한 한 결정론적 알고리즘을 사용하도록 설정한다.
torch.backends.cudnn.deterministic = True
# 입력 크기가 매번 달라질 때 자동 최적화를 수행하는 기능을 끈다.
torch.backends.cudnn.benchmark = False
# 위에서 정의한 함수를 호출하여 현재 노트북의 난수를 고정한다.
set_seed(42)
데이터셋 불러오기
# Reuters 데이터셋을 안전하게 불러오기 위한 함수를 정의한다.
def load_reuters_dataset(num_words=None, test_split=0.2):
# TensorFlow/Keras Reuters 로더가 있는 환경에서는 원본 Reuters 데이터셋을 사용한다.
try:
# Keras에서 제공하는 Reuters 뉴스 기사 데이터셋 로더를 불러온다.
from tensorflow.keras.datasets import reuters
# 지정한 단어 수와 테스트 비율에 맞추어 Reuters 데이터셋을 불러온다.
(X_train_raw, y_train_raw), (X_test_raw, y_test_raw) = reuters.load_data(
num_words=num_words,
test_split=test_split
)
# Reuters 단어 사전을 불러온다.
word_to_index = reuters.get_word_index()
# 실제 Reuters 데이터셋을 사용했다는 정보를 출력한다.
print("TensorFlow/Keras Reuters 데이터셋을 불러왔습니다.")
# 불러온 훈련 데이터, 테스트 데이터, 단어 사전을 반환한다.
return (X_train_raw, y_train_raw), (X_test_raw, y_test_raw), word_to_index
# TensorFlow가 없거나 Reuters 데이터를 불러오지 못해도 노트북이 중단되지 않도록 예외를 처리한다.
except Exception as error:
# 원본 데이터셋을 사용할 수 없다는 안내 문구를 출력한다.
print("Reuters 데이터셋 로딩에 실패하여 예제용 작은 데이터를 생성합니다.")
# 발생한 오류 내용을 출력하여 원인을 확인할 수 있도록 한다.
print("오류 내용:", error)
# 예제용 단어 사전을 직접 만든다.
word_to_index = {
"market": 1, "stock": 2, "profit": 3, "company": 4, "oil": 5,
"trade": 6, "bank": 7, "money": 8, "team": 9, "game": 10,
"win": 11, "minister": 12, "government": 13, "policy": 14,
"technology": 15, "computer": 16, "software": 17
}
# 예제용 훈련 기사 시퀀스를 만든다.
X_train_raw = [
[1, 2, 3, 4, 8], [5, 6, 1, 2], [9, 10, 11], [12, 13, 14],
[15, 16, 17], [1, 7, 8, 3], [9, 11, 10], [13, 12, 14]
]
# 예제용 훈련 라벨을 만든다.
y_train_raw = np.array([0, 0, 1, 2, 3, 0, 1, 2], dtype=np.int64)
# 예제용 테스트 기사 시퀀스를 만든다.
X_test_raw = [[2, 3, 4], [10, 11, 9], [16, 17, 15], [12, 14, 13]]
# 예제용 테스트 라벨을 만든다.
y_test_raw = np.array([0, 1, 3, 2], dtype=np.int64)
# 예제용 데이터를 반환한다.
return (X_train_raw, y_train_raw), (X_test_raw, y_test_raw), word_to_index
# Reuters 데이터셋을 전체 단어 사전 기준으로 한 번 불러와 데이터 구조를 확인한다.
(X_train_raw, y_train_raw), (X_test_raw, y_test_raw), word_to_index = load_reuters_dataset(
num_words=None,
test_split=0.2
)
# 훈련용 뉴스 기사 개수를 출력한다.
print("훈련용 뉴스 기사 수:", len(X_train_raw))
# 테스트용 뉴스 기사 개수를 출력한다.
print("테스트용 뉴스 기사 수:", len(X_test_raw))
# 훈련 라벨과 테스트 라벨을 하나로 합쳐 전체 카테고리 수를 계산한다.
num_classes_raw = len(set(np.concatenate([np.array(y_train_raw), np.array(y_test_raw)])))
# 전체 뉴스 카테고리 수를 출력한다.
print("전체 뉴스 카테고리 수:", num_classes_raw)# 첫 번째 훈련용 뉴스 기사는 이미 단어가 정수 인덱스로 변환된 리스트이다.
print("첫 번째 훈련용 뉴스 기사 정수 시퀀스:")
# 첫 번째 뉴스 기사 시퀀스를 출력한다.
print(X_train_raw[0])
# 첫 번째 훈련용 뉴스 기사의 라벨을 출력한다.
print("\n첫 번째 훈련용 뉴스 기사의 라벨:")
# 라벨은 뉴스 카테고리를 의미하는 정수값이다.
print(y_train_raw[0])
# 첫 번째 뉴스 기사에 포함된 토큰 개수를 출력한다.
print("\n첫 번째 훈련용 뉴스 기사의 길이:")
# len 함수로 첫 번째 뉴스 기사 시퀀스의 길이를 계산한다.
print(len(X_train_raw[0]))첫 번째 훈련용 뉴스 기사 정수 시퀀스:
[1, 27595, 28842, 8, 43, 10, 447, 5, 25, 207, 270, 5, 3095, 111, 16, 369, 186, 90, 67, 7, 89, 5, 19, 102, 6, 19, 124, 15, 90, 67, 84, 22, 482, 26, 7, 48, 4, 49, 8, 864, 39, 209, 154, 6, 151, 6, 83, 11, 15, 22, 155, 11, 15, 7, 48, 9, 4579, 1005, 504, 6, 258, 6, 272, 11, 15, 22, 134, 44, 11, 15, 16, 8, 197, 1245, 90, 67, 52, 29, 209, 30, 32, 132, 6, 109, 15, 17, 12]
첫 번째 훈련용 뉴스 기사의 라벨:
3
첫 번째 훈련용 뉴스 기사의 길이:
87
기사 길이 확인
# 모든 훈련용 뉴스 기사 길이를 리스트로 만든다.
train_lengths = [len(sample) for sample in X_train_raw]
# 훈련용 뉴스 기사 중 가장 긴 기사의 길이를 계산한다.
max_train_length = max(train_lengths)
# 훈련용 뉴스 기사 길이의 평균을 계산한다.
mean_train_length = sum(train_lengths) / len(train_lengths)
# 뉴스 기사의 최대 길이를 출력한다.
print("뉴스 기사의 최대 길이:", max_train_length)
# 뉴스 기사의 평균 길이를 소수 둘째 자리까지 출력한다.
print("뉴스 기사의 평균 길이: {:.2f}".format(mean_train_length))뉴스 기사의 최대 길이: 2376
뉴스 기사의 평균 길이: 145.54# 그래프 크기를 가로 10인치, 세로 5인치로 설정한다.
plt.figure(figsize=(10, 5))
# 훈련용 뉴스 기사 길이 분포를 히스토그램으로 출력한다.
plt.hist(train_lengths, bins=50)
# x축 이름을 설정한다.
plt.xlabel("Length of news articles")
# y축 이름을 설정한다.
plt.ylabel("Number of news articles")
# 그래프 제목을 설정한다.
plt.title("Reuters News Article Length Distribution")
# 그래프를 화면에 출력한다.
plt.show()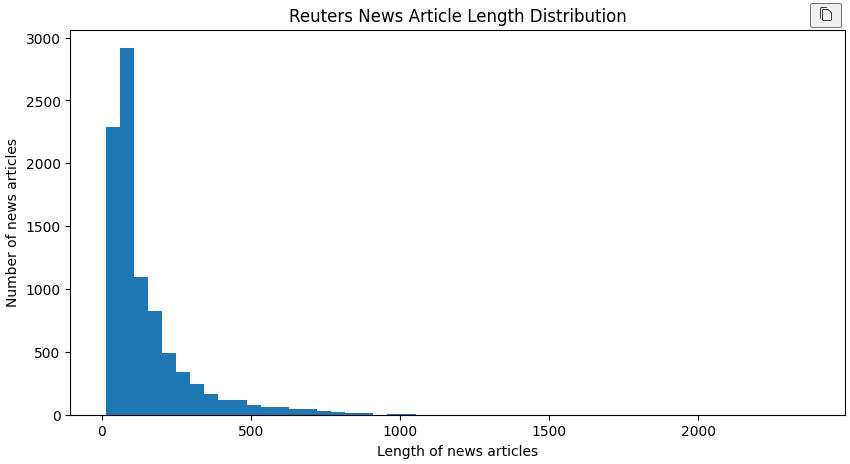
라벨 분포확인.
각 라벨 등장 횟수를 2행 배열형태로 묶어서 확인한다 .
# np.unique는 라벨 종류와 각 라벨의 등장 횟수를 함께 계산한다.
unique_labels, label_counts = np.unique(y_train_raw, return_counts=True)
# 라벨 번호와 빈도수를 2행 배열 형태로 묶는다.
label_distribution = np.asarray((unique_labels, label_counts))
# 라벨별 빈도수 정보를 출력한다.
print("각 라벨에 대한 빈도수:")
# 라벨 분포 배열을 출력한다.
print(label_distribution)각 라벨에 대한 빈도수:
[[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13
14 15 16 17 18 19 20 21 22 23 24 25 26 27
28 29 30 31 32 33 34 35 36 37 38 39 40 41
42 43 44 45]
[ 55 432 74 3159 1949 17 48 16 139 101 124 390 49 172
26 20 444 39 66 549 269 100 15 41 62 92 24 15
48 19 45 39 32 11 50 10 49 19 19 24 36 30
13 21 12 18]]
단어사전 크기와 딕셔너리형태를 list형으로 바꾼뒤 앞 10개만 출력해본다.
# 단어 사전의 전체 단어 개수를 출력한다.
print("Reuters 단어 사전 크기:", len(word_to_index))
# 단어 사전 중 앞부분 일부만 확인하기 위해 10개 항목을 출력한다.
print("단어 사전 샘플 10개:")
# 딕셔너리 항목을 리스트로 바꾼 후 앞의 10개만 출력한다.
print(list(word_to_index.items())[:10])Reuters 단어 사전 크기: 30979
단어 사전 샘플 10개:
[('mdbl', 10996), ('fawc', 16260), ('degussa', 12089), ('woods', 8803), ('hanging', 13796), ('localized', 20672), ('sation', 20673), ('chanthaburi', 20675), ('refunding', 10997), ('hermann', 8804)]
실제 데이터단어들을 인덱스 3을 더해 마지막 인덱스에 저장하고
패딩을 의미하는 pad, 문장시작을 의미하는 특수토큰 sos, 사전에 없는 단어를 의미하는 특수토큰 unk, 사용하지않는 예비 특수토큰을 unused에 저장하기로한다.
I love NLP <pad> <pad> <pad> 모델은 pad를 실제 단어가 아닌 빈칸처럼 취급한다.
<sos> I love NLP 문장시작을 의미
I, love, movie 단어가 있는데 wonderful 단어가 나오면 <unk>로 바꿈.등.. <>는 그저 관례 일반단어가 아닌 특수토큰.
# 정수 인덱스를 다시 단어로 바꾸기 위한 빈 딕셔너리를 생성한다.
index_to_word = {}
# Reuters 데이터셋에서는 0, 1, 2가 특수 토큰으로 사용되므로 실제 단어 인덱스에 3을 더해 저장한다.
for word, index in word_to_index.items():
# 현재 단어의 실제 시퀀스 인덱스를 key로 저장하고, 단어를 value로 저장한다.
index_to_word[index + 3] = word
# 패딩을 의미하는 특수 토큰을 0번 인덱스에 저장한다.
index_to_word[0] = "<pad>"
# 문장 시작을 의미하는 특수 토큰을 1번 인덱스에 저장한다.
index_to_word[1] = "<sos>"
# 사전에 없는 단어를 의미하는 특수 토큰을 2번 인덱스에 저장한다.
index_to_word[2] = "<unk>"
# 사용하지 않는 예비 특수 토큰을 3번 인덱스에 저장한다.
index_to_word[3] = "<unused>"
# 4번 인덱스가 존재할 때만 단어를 출력한다.
print("4번 인덱스 단어:", index_to_word.get(4, "<없음>"))
# 5번 인덱스가 존재할 때만 단어를 출력한다.
print("5번 인덱스 단어:", index_to_word.get(5, "<없음>"))
정수인덱스를 단어로 변환해보자.
# 첫 번째 훈련용 뉴스 기사에 포함된 정수 인덱스를 단어로 변환한다.
decoded_article = " ".join([index_to_word.get(index, "<unk>") for index in X_train_raw[0]])
# 복원된 첫 번째 뉴스 기사를 출력한다.
print("첫 번째 뉴스 기사 복원 결과:")
# 복원된 텍스트를 출력한다.
print(decoded_article)첫 번째 뉴스 기사 복원 결과:
<sos> mcgrath rentcorp said as a result of its december acquisition of space co it expects earnings per share in 1987 of 1 15 to 1 30 dlrs per share up from 70 cts in 1986 the company said pretax net should rise to nine to 10 mln dlrs from six mln dlrs in 1986 and rental operation revenues to 19 to 22 mln dlrs from 12 5 mln dlrs it said cash flow per share this year should be 2 50 to three dlrs reuter 3
하이퍼파라미터 설정
# vocab_size는 모델에서 사용할 상위 단어 개수를 의미한다.
vocab_size = 1000
# max_len은 모든 뉴스 기사 길이를 몇 개 토큰으로 맞출지 결정하는 값이다.
max_len = 100
# embedding_dim은 각 단어를 몇 차원의 밀집 벡터로 표현할지 결정한다.
embedding_dim = 128
# hidden_units는 LSTM 내부 은닉 상태의 차원 수를 의미한다.
hidden_units = 128
# dropout_rate는 Dropout에서 무작위로 비활성화할 뉴런 비율이다.
dropout_rate = 0.3
# batch_size는 한 번의 가중치 업데이트에 사용할 데이터 개수이다.
batch_size = 128
# epochs는 전체 훈련 데이터를 최대 몇 번 반복해서 학습할지 결정한다.
epochs = 5
# learning_rate는 Adam Optimizer가 가중치를 조정할 때 사용하는 학습률이다.
learning_rate = 0.001
# patience는 검증 손실이 개선되지 않아도 기다릴 에포크 수이다.
patience = 3
# 설정한 하이퍼파라미터를 출력한다.
print("vocab_size:", vocab_size)
print("max_len:", max_len)
print("embedding_dim:", embedding_dim)
print("hidden_units:", hidden_units)
print("batch_size:", batch_size)
print("epochs:", epochs)
패딩함수작성
입력으로 받은 정수시퀀스를 처리한다. 리스트로 변환. maxlen에 맞춰 토큰을 잘라낸다. 부족하면 길이를 계산해 pre로 채운다 .
# 길이가 서로 다른 정수 시퀀스를 동일한 길이로 맞추는 패딩 함수를 정의한다.
def pad_sequences_torch_style(sequences, maxlen, padding="pre", truncating="pre", value=0):
# 패딩 처리된 결과를 저장할 리스트를 생성한다.
padded_sequences = []
# 입력으로 받은 각 정수 시퀀스를 하나씩 처리한다.
for sequence in sequences:
# 원본 시퀀스가 리스트가 아닐 수도 있으므로 리스트로 변환한다.
sequence = list(sequence)
# 시퀀스 길이가 maxlen보다 길면 일부 토큰을 잘라낸다.
if len(sequence) > maxlen:
# truncating이 pre이면 앞쪽 토큰을 제거하고 뒤쪽 maxlen개만 남긴다.
if truncating == "pre":
sequence = sequence[-maxlen:]
# truncating이 post이면 뒤쪽 토큰을 제거하고 앞쪽 maxlen개만 남긴다.
else:
sequence = sequence[:maxlen]
# 시퀀스 길이가 maxlen보다 짧으면 부족한 길이를 계산한다.
pad_length = maxlen - len(sequence)
# padding이 pre이면 앞쪽에 0을 채운다.
if padding == "pre":
padded_sequence = [value] * pad_length + sequence
# padding이 post이면 뒤쪽에 0을 채운다.
else:
padded_sequence = sequence + [value] * pad_length
# 패딩이 완료된 시퀀스를 결과 리스트에 추가한다.
padded_sequences.append(padded_sequence)
# 패딩 결과를 NumPy 정수 배열로 변환하여 반환한다.
return np.array(padded_sequences, dtype=np.int64)
reuters 데이터셋에 함수적용,
라벨을 정수배열로 변환.
# Reuters 데이터셋을 상위 vocab_size개 단어만 사용하도록 다시 불러온다.
(X_train, y_train), (X_test, y_test), word_to_index = load_reuters_dataset(
num_words=vocab_size,
test_split=0.2
)
# 훈련용 뉴스 기사 길이를 max_len으로 맞춘다.
X_train = pad_sequences_torch_style(
X_train,
maxlen=max_len,
padding="pre",
truncating="pre",
value=0
)
# 테스트용 뉴스 기사 길이를 max_len으로 맞춘다.
X_test = pad_sequences_torch_style(
X_test,
maxlen=max_len,
padding="pre",
truncating="pre",
value=0
)
# 훈련 라벨을 NumPy 정수 배열로 변환한다.
y_train = np.array(y_train, dtype=np.int64)
# 테스트 라벨을 NumPy 정수 배열로 변환한다.
y_test = np.array(y_test, dtype=np.int64)
# 훈련 라벨과 테스트 라벨을 합쳐 전체 클래스 개수를 계산한다.
num_classes = int(max(np.max(y_train), np.max(y_test)) + 1)
# 패딩 후 훈련 데이터의 형태를 출력한다.
print("X_train shape:", X_train.shape)
# 패딩 후 테스트 데이터의 형태를 출력한다.
print("X_test shape:", X_test.shape)
# 훈련 라벨의 형태를 출력한다.
print("y_train shape:", y_train.shape)
# 테스트 라벨의 형태를 출력한다.
print("y_test shape:", y_test.shape)
# 클래스 개수를 출력한다.
print("num_classes:", num_classes)TensorFlow/Keras Reuters 데이터셋을 불러왔습니다.
X_train shape: (8982, 100)
X_test shape: (2246, 100)
y_train shape: (8982,)
y_test shape: (2246,)
num_classes: 46
tensor로 변환
# 훈련 입력 데이터를 PyTorch LongTensor로 변환한다.
X_train_tensor = torch.tensor(X_train, dtype=torch.long)
# 훈련 라벨 데이터를 PyTorch LongTensor로 변환한다.
y_train_tensor = torch.tensor(y_train, dtype=torch.long)
# 테스트 입력 데이터를 PyTorch LongTensor로 변환한다.
X_test_tensor = torch.tensor(X_test, dtype=torch.long)
# 테스트 라벨 데이터를 PyTorch LongTensor로 변환한다.
y_test_tensor = torch.tensor(y_test, dtype=torch.long)
# 훈련 입력 Tensor의 형태를 출력한다.
print("X_train_tensor shape:", X_train_tensor.shape)
# 훈련 라벨 Tensor의 형태를 출력한다.
print("y_train_tensor shape:", y_train_tensor.shape)
# 테스트 입력 Tensor의 형태를 출력한다.
print("X_test_tensor shape:", X_test_tensor.shape)
# 테스트 라벨 Tensor의 형태를 출력한다.
print("y_test_tensor shape:", y_test_tensor.shape)
dataloader생성
# 훈련 입력 Tensor와 훈련 라벨 Tensor를 하나의 Dataset으로 묶는다.
train_dataset = TensorDataset(X_train_tensor, y_train_tensor)
# 테스트 입력 Tensor와 테스트 라벨 Tensor를 하나의 Dataset으로 묶는다.
test_dataset = TensorDataset(X_test_tensor, y_test_tensor)
# 훈련 DataLoader는 데이터를 batch_size 단위로 나누고 매 에포크마다 순서를 섞는다.
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True
)
# 테스트 DataLoader는 평가용이므로 순서를 섞지 않는다.
test_loader = DataLoader(
test_dataset,
batch_size=batch_size,
shuffle=False
)
# 훈련 미니배치 개수를 출력한다.
print("훈련 미니배치 수:", len(train_loader))
# 테스트 미니배치 개수를 출력한다.
print("테스트 미니배치 수:", len(test_loader))
LSTM 모델 구현
LSTM 전에 nn.Embedding으로 밀집 벡티로 변환
ReutersLSTMClassifier 객체 생성
# PyTorch nn.Module을 상속하여 LSTM 기반 뉴스 분류 모델 클래스를 정의한다.
class ReutersLSTMClassifier(nn.Module):
# 모델에서 사용할 계층과 하이퍼파라미터를 초기화한다.
def __init__(self, vocab_size, embedding_dim, hidden_units, num_classes, dropout_rate):
# 부모 클래스인 nn.Module의 초기화 함수를 실행한다.
super().__init__()
# Embedding 층은 정수 단어 인덱스를 학습 가능한 밀집 벡터로 변환한다.
self.embedding = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=embedding_dim,
padding_idx=0
)
# LSTM 층은 단어 순서와 문맥 정보를 학습한다.
self.lstm = nn.LSTM(
input_size=embedding_dim,
hidden_size=hidden_units,
batch_first=True
)
# Dropout 층은 일부 뉴런 출력을 무작위로 0으로 만들어 과적합을 줄인다.
self.dropout = nn.Dropout(
p=dropout_rate
)
# Linear 층은 LSTM 출력 특징을 뉴스 카테고리 개수만큼의 점수로 변환한다.
self.fc = nn.Linear(
in_features=hidden_units,
out_features=num_classes
)
# 입력 데이터가 모델을 통과하는 순전파 과정을 정의한다.
def forward(self, x):
# 입력 x의 형태는 [배치 크기, 문장 길이]이다.
embedded = self.embedding(x)
# embedded의 형태는 [배치 크기, 문장 길이, 임베딩 차원]이다.
lstm_output, (hidden_state, cell_state) = self.lstm(embedded)
# hidden_state의 마지막 층 은닉 상태를 가져온다.
last_hidden = hidden_state[-1]
# Dropout을 적용하여 과적합을 완화한다.
dropped = self.dropout(last_hidden)
# 최종 출력층을 통과시켜 각 클래스에 대한 점수를 계산한다.
logits = self.fc(dropped)
# CrossEntropyLoss는 softmax를 내부적으로 처리하므로 확률이 아닌 logits를 반환한다.
return logits
# LSTM 뉴스 분류 모델 객체를 생성한다.
model = ReutersLSTMClassifier(
vocab_size=vocab_size,
embedding_dim=embedding_dim,
hidden_units=hidden_units,
num_classes=num_classes,
dropout_rate=dropout_rate
)
# 모델을 CPU 또는 GPU 장치로 이동한다.
model = model.to(device)
# 생성된 모델 구조를 출력한다.
print(model)ReutersLSTMClassifier(
(embedding): Embedding(1000, 128, padding_idx=0)
(lstm): LSTM(128, 128, batch_first=True)
(dropout): Dropout(p=0.3, inplace=False)
(fc): Linear(in_features=128, out_features=46, bias=True)
)
손실함수 CrossEntropyLoss
최적화 알고리즘 설정 optim.Adam
# CrossEntropyLoss는 다중 클래스 분류에서 사용하는 대표적인 손실 함수이다.
criterion = nn.CrossEntropyLoss()
# Adam Optimizer는 학습률을 적응적으로 조정하면서 모델 가중치를 업데이트한다.
optimizer = optim.Adam(
model.parameters(),
lr=learning_rate
)
# 가장 좋은 모델을 저장할 폴더를 생성한다.
os.makedirs("models", exist_ok=True)
# 가장 좋은 모델 가중치를 저장할 파일 경로를 지정한다.
best_model_path = os.path.join("models", "best_reuters_lstm_torch.pt")
# 최적 검증 손실을 무한대로 초기화한다.
best_val_loss = float("inf")
# Early Stopping을 위해 검증 손실이 개선되지 않은 에포크 수를 저장한다.
epochs_without_improvement = 0
정확도함수작성
# 모델 출력과 정답 라벨을 받아 정확도를 계산하는 함수를 정의한다.
def calculate_accuracy(logits, labels):
# logits에서 가장 큰 값을 갖는 클래스 인덱스를 예측 라벨로 선택한다.
predictions = torch.argmax(logits, dim=1)
# 예측 라벨과 실제 라벨이 같은지 비교한다.
correct = (predictions == labels).sum().item()
# 전체 라벨 개수를 계산한다.
total = labels.size(0)
# 맞힌 개수를 전체 개수로 나누어 정확도를 계산한다.
accuracy = correct / total
# 계산된 정확도를 반환한다.
return accuracy
학습함수작성
# 한 에포크 동안 모델을 학습하는 함수를 정의한다.
def train_one_epoch(model, data_loader, criterion, optimizer, device):
# 모델을 학습 모드로 전환한다.
model.train()
# 에포크 전체 손실 합계를 저장할 변수를 초기화한다.
total_loss = 0.0
# 에포크 전체 정확도 합계를 저장할 변수를 초기화한다.
total_accuracy = 0.0
# DataLoader에서 미니배치를 하나씩 가져온다.
for batch_inputs, batch_labels in data_loader:
# 입력 데이터를 CPU 또는 GPU 장치로 이동한다.
batch_inputs = batch_inputs.to(device)
# 정답 라벨을 CPU 또는 GPU 장치로 이동한다.
batch_labels = batch_labels.to(device)
# 이전 미니배치에서 계산된 기울기를 초기화한다.
optimizer.zero_grad()
# 모델에 입력 데이터를 넣어 클래스별 점수 logits를 계산한다.
logits = model(batch_inputs)
# 모델 출력과 정답 라벨을 비교하여 손실을 계산한다.
loss = criterion(logits, batch_labels)
# 손실을 기준으로 역전파를 수행하여 기울기를 계산한다.
loss.backward()
# 계산된 기울기를 사용하여 모델 가중치를 업데이트한다.
optimizer.step()
# 현재 미니배치 손실에 데이터 개수를 곱해 누적한다.
total_loss += loss.item() * batch_inputs.size(0)
# 현재 미니배치 정확도를 계산한다.
batch_accuracy = calculate_accuracy(logits, batch_labels)
# 현재 미니배치 정확도에 데이터 개수를 곱해 누적한다.
total_accuracy += batch_accuracy * batch_inputs.size(0)
# 전체 평균 손실을 계산한다.
average_loss = total_loss / len(data_loader.dataset)
# 전체 평균 정확도를 계산한다.
average_accuracy = total_accuracy / len(data_loader.dataset)
# 평균 손실과 평균 정확도를 반환한다.
return average_loss, average_accuracy
평가함수작성
# 모델을 평가하는 함수를 정의한다.
def evaluate(model, data_loader, criterion, device):
# 모델을 평가 모드로 전환한다.
model.eval()
# 평가 전체 손실 합계를 저장할 변수를 초기화한다.
total_loss = 0.0
# 평가 전체 정확도 합계를 저장할 변수를 초기화한다.
total_accuracy = 0.0
# 평가 단계에서는 기울기를 계산하지 않도록 설정한다.
with torch.no_grad():
# DataLoader에서 미니배치를 하나씩 가져온다.
for batch_inputs, batch_labels in data_loader:
# 입력 데이터를 CPU 또는 GPU 장치로 이동한다.
batch_inputs = batch_inputs.to(device)
# 정답 라벨을 CPU 또는 GPU 장치로 이동한다.
batch_labels = batch_labels.to(device)
# 모델에 입력 데이터를 넣어 클래스별 점수 logits를 계산한다.
logits = model(batch_inputs)
# 모델 출력과 정답 라벨을 비교하여 손실을 계산한다.
loss = criterion(logits, batch_labels)
# 현재 미니배치 손실에 데이터 개수를 곱해 누적한다.
total_loss += loss.item() * batch_inputs.size(0)
# 현재 미니배치 정확도를 계산한다.
batch_accuracy = calculate_accuracy(logits, batch_labels)
# 현재 미니배치 정확도에 데이터 개수를 곱해 누적한다.
total_accuracy += batch_accuracy * batch_inputs.size(0)
# 전체 평균 손실을 계산한다.
average_loss = total_loss / len(data_loader.dataset)
# 전체 평균 정확도를 계산한다.
average_accuracy = total_accuracy / len(data_loader.dataset)
# 평균 손실과 평균 정확도를 반환한다.
return average_loss, average_accuracy
한 epoch 돌때마다 모델을 평가해 출력
val_loss < best_val_loss 검증손실이 최적값보다 작으면 모델로 저장한다 .
# 학습 과정에서 발생한 훈련 손실을 저장할 리스트를 생성한다.
train_losses = []
# 학습 과정에서 발생한 검증 손실을 저장할 리스트를 생성한다.
val_losses = []
# 학습 과정에서 발생한 훈련 정확도를 저장할 리스트를 생성한다.
train_accuracies = []
# 학습 과정에서 발생한 검증 정확도를 저장할 리스트를 생성한다.
val_accuracies = []
# 전체 학습 시작 시간을 기록한다.
start_time = time.time()
# 지정한 에포크 수만큼 학습을 반복한다.
for epoch in range(1, epochs + 1):
# 한 에포크 동안 훈련 데이터를 사용하여 모델을 학습한다.
train_loss, train_accuracy = train_one_epoch(
model=model,
data_loader=train_loader,
criterion=criterion,
optimizer=optimizer,
device=device
)
# 한 에포크가 끝난 뒤 테스트 데이터를 사용하여 모델을 평가한다.
val_loss, val_accuracy = evaluate(
model=model,
data_loader=test_loader,
criterion=criterion,
device=device
)
# 현재 에포크의 훈련 손실을 리스트에 저장한다.
train_losses.append(train_loss)
# 현재 에포크의 검증 손실을 리스트에 저장한다.
val_losses.append(val_loss)
# 현재 에포크의 훈련 정확도를 리스트에 저장한다.
train_accuracies.append(train_accuracy)
# 현재 에포크의 검증 정확도를 리스트에 저장한다.
val_accuracies.append(val_accuracy)
# 현재 에포크의 학습 결과를 출력한다.
print(
f"Epoch [{epoch}/{epochs}] "
f"Train Loss: {train_loss:.4f} "
f"Train Acc: {train_accuracy:.4f} "
f"Val Loss: {val_loss:.4f} "
f"Val Acc: {val_accuracy:.4f}"
)
# 검증 손실이 이전 최적값보다 작으면 모델을 저장한다.
if val_loss < best_val_loss:
# 최적 검증 손실 값을 현재 검증 손실로 갱신한다.
best_val_loss = val_loss
# 개선되지 않은 에포크 수를 0으로 초기화한다.
epochs_without_improvement = 0
# 현재 모델의 가중치와 설정 정보를 파일로 저장한다.
torch.save(
{
"model_state_dict": model.state_dict(),
"vocab_size": vocab_size,
"embedding_dim": embedding_dim,
"hidden_units": hidden_units,
"num_classes": num_classes,
"dropout_rate": dropout_rate,
"max_len": max_len
},
best_model_path
)
# 모델이 저장되었음을 출력한다.
print("검증 손실이 개선되어 모델을 저장했습니다:", best_model_path)
# 검증 손실이 개선되지 않은 경우 처리한다.
else:
# 개선되지 않은 에포크 수를 1 증가시킨다.
epochs_without_improvement += 1
# 개선되지 않은 횟수를 출력한다.
print("검증 손실 미개선 횟수:", epochs_without_improvement)
# 개선되지 않은 횟수가 patience 이상이면 학습을 조기 종료한다.
if epochs_without_improvement >= patience:
# Early Stopping 안내 문구를 출력한다.
print("Early Stopping 조건을 만족하여 학습을 중단합니다.")
# 학습 반복문을 종료한다.
break
# 전체 학습 종료 시간을 기록한다.
end_time = time.time()
# 전체 학습 시간을 출력한다.
print("전체 학습 시간: {:.2f}초".format(end_time - start_time))
시각화
# 에포크 번호를 1부터 시작하는 리스트로 생성한다.
epochs_range = range(1, len(train_accuracies) + 1)
# 그래프 크기를 설정한다.
plt.figure(figsize=(10, 5))
# 훈련 정확도 그래프를 그린다.
plt.plot(epochs_range, train_accuracies, label="Train Accuracy")
# 검증 정확도 그래프를 그린다.
plt.plot(epochs_range, val_accuracies, label="Validation Accuracy")
# x축 이름을 설정한다.
plt.xlabel("Epoch")
# y축 이름을 설정한다.
plt.ylabel("Accuracy")
# 그래프 제목을 설정한다.
plt.title("Training and Validation Accuracy")
# 범례를 표시한다.
plt.legend()
# 그래프를 출력한다.
plt.show()
# 그래프 크기를 설정한다.
plt.figure(figsize=(10, 5))
# 훈련 손실 그래프를 그린다.
plt.plot(epochs_range, train_losses, label="Train Loss")
# 검증 손실 그래프를 그린다.
plt.plot(epochs_range, val_losses, label="Validation Loss")
# x축 이름을 설정한다.
plt.xlabel("Epoch")
# y축 이름을 설정한다.
plt.ylabel("Loss")
# 그래프 제목을 설정한다.
plt.title("Training and Validation Loss")
# 범례를 표시한다.
plt.legend()
# 그래프를 출력한다.
plt.show()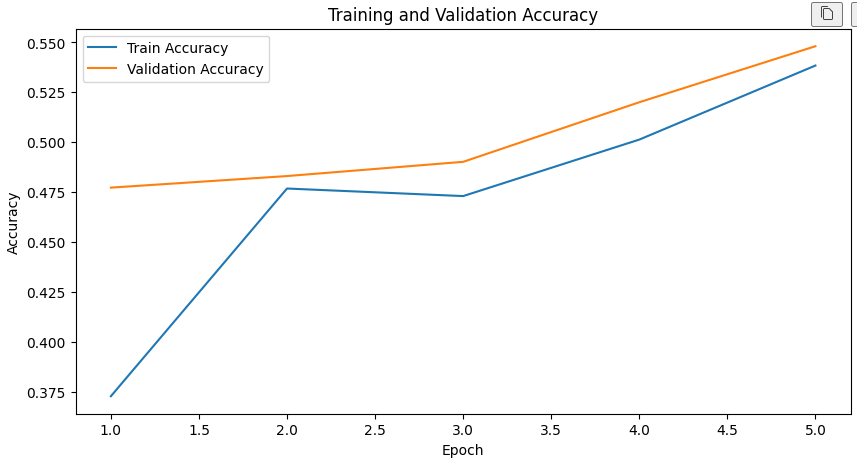
best_model_path 최적 모델파일이 존재하는지 확인
ReutersLSTMClassifier 동일한 구조의 모델 객체 생성
현재 장치로 이동해 가중치를 모델에 적용.
# 저장된 최적 모델 파일이 존재하는지 확인한다.
if os.path.exists(best_model_path):
# 저장된 체크포인트 파일을 현재 장치 기준으로 불러온다.
checkpoint = torch.load(best_model_path, map_location=device)
# 체크포인트에 저장된 설정값으로 동일한 구조의 모델 객체를 생성한다.
loaded_model = ReutersLSTMClassifier(
vocab_size=checkpoint["vocab_size"],
embedding_dim=checkpoint["embedding_dim"],
hidden_units=checkpoint["hidden_units"],
num_classes=checkpoint["num_classes"],
dropout_rate=checkpoint["dropout_rate"]
)
# 생성한 모델을 현재 장치로 이동한다.
loaded_model = loaded_model.to(device)
# 저장된 가중치를 모델에 적용한다.
loaded_model.load_state_dict(checkpoint["model_state_dict"])
# 모델 로딩 완료 메시지를 출력한다.
print("저장된 최적 모델을 불러왔습니다.")
# 저장된 파일이 없는 경우 현재 학습된 모델을 그대로 사용한다.
else:
# 현재 메모리에 있는 모델을 loaded_model 변수에 할당한다.
loaded_model = model
# 저장 파일이 없다는 안내 메시지를 출력한다.
print("저장된 모델이 없어 현재 모델을 사용합니다.")
최종평가
# 불러온 모델을 사용하여 테스트 데이터의 손실과 정확도를 계산한다.
test_loss, test_accuracy = evaluate(
model=loaded_model,
data_loader=test_loader,
criterion=criterion,
device=device
)
# 테스트 손실을 출력한다.
print("테스트 손실: {:.4f}".format(test_loss))
# 테스트 정확도를 출력한다.
print("테스트 정확도: {:.4f}".format(test_accuracy))
테스트해보기
테스트 기사 하나 선택해 평가.
# 테스트 데이터 중 첫 번째 뉴스 기사를 하나 선택한다.
sample_article = X_test_tensor[0:1]
# 선택한 뉴스 기사의 실제 라벨을 가져온다.
true_label = int(y_test_tensor[0].item())
# 모델을 평가 모드로 전환한다.
loaded_model.eval()
# 예측 단계에서는 기울기를 계산하지 않도록 설정한다.
with torch.no_grad():
# 샘플 기사를 현재 장치로 이동한다.
sample_article_device = sample_article.to(device)
# 모델을 사용하여 카테고리별 점수를 계산한다.
logits = loaded_model(sample_article_device)
# softmax를 적용하여 카테고리별 확률로 변환한다.
probabilities = torch.softmax(logits, dim=1)
# 가장 확률이 높은 카테고리 번호를 예측 라벨로 선택한다.
predicted_label = int(torch.argmax(probabilities, dim=1).item())
# 가장 높은 예측 확률값을 가져온다.
predicted_probability = float(torch.max(probabilities).item())
# 실제 라벨을 출력한다.
print("실제 라벨:", true_label)
# 예측 라벨을 출력한다.
print("예측 라벨:", predicted_label)
# 예측 확률을 출력한다.
print("예측 확률: {:.4f}".format(predicted_probability))
새문장을 입력해 평가
# 새 문장을 Reuters 단어 사전 기준의 정수 시퀀스로 바꾸는 함수를 정의한다.
def encode_new_text(text, word_to_index, vocab_size=1000, max_len=100):
# 입력 문장을 소문자로 변환하고 공백 기준으로 단어를 나눈다.
words = text.lower().split()
# Reuters 데이터셋의 문장 시작 토큰 인덱스 1을 먼저 넣는다.
encoded = [1]
# 입력 문장의 각 단어를 하나씩 확인한다.
for word in words:
# 단어가 Reuters 단어 사전에 있으면 해당 인덱스에 3을 더해 실제 시퀀스 인덱스로 변환한다.
index = word_to_index.get(word, 2) + 3
# 인덱스가 vocab_size보다 작으면 모델이 아는 단어로 처리한다.
if index < vocab_size:
# 변환된 단어 인덱스를 리스트에 추가한다.
encoded.append(index)
# vocab_size 범위를 벗어난 단어는 사전에 없는 단어로 처리한다.
else:
# 사전에 없는 단어를 의미하는 2번 인덱스를 추가한다.
encoded.append(2)
# 새 문장도 모델 입력 길이와 같도록 패딩한다.
padded = pad_sequences_torch_style(
[encoded],
maxlen=max_len,
padding="pre",
truncating="pre",
value=0
)
# 패딩된 정수 시퀀스를 PyTorch LongTensor로 변환한다.
tensor = torch.tensor(padded, dtype=torch.long)
# 변환된 Tensor를 반환한다.
return tensor
# 새 영어 뉴스 문장을 입력하면 카테고리를 예측하는 함수를 정의한다.
def predict_news_category(text, model, word_to_index, vocab_size=1000, max_len=100, device="cpu"):
# 입력 문장을 모델 입력 형식의 Tensor로 변환한다.
input_tensor = encode_new_text(
text=text,
word_to_index=word_to_index,
vocab_size=vocab_size,
max_len=max_len
)
# 입력 Tensor를 CPU 또는 GPU 장치로 이동한다.
input_tensor = input_tensor.to(device)
# 모델을 평가 모드로 전환한다.
model.eval()
# 예측 단계에서는 기울기를 계산하지 않는다.
with torch.no_grad():
# 모델을 사용하여 클래스별 점수를 계산한다.
logits = model(input_tensor)
# softmax를 적용하여 클래스별 확률로 변환한다.
probabilities = torch.softmax(logits, dim=1)
# 가장 높은 확률을 갖는 클래스 번호를 예측 라벨로 선택한다.
predicted_label = int(torch.argmax(probabilities, dim=1).item())
# 가장 높은 확률값을 가져온다.
predicted_probability = float(torch.max(probabilities).item())
# 예측 라벨과 예측 확률을 반환한다.
return predicted_label, predicted_probability
# 예측해 볼 새 영어 뉴스 문장을 작성한다.
new_text = "stock market profit company trade bank money"
# 새 문장의 카테고리를 예측한다.
predicted_label, predicted_probability = predict_news_category(
text=new_text,
model=loaded_model,
word_to_index=word_to_index,
vocab_size=vocab_size,
max_len=max_len,
device=device
)
# 입력 문장을 출력한다.
print("입력 문장:", new_text)
# 예측 라벨을 출력한다.
print("예측 라벨:", predicted_label)
# 예측 확률을 출력한다.
print("예측 확률: {:.4f}".format(predicted_probability))
형태소 분석 확인
# customized_konlpy 설치 여부와 실행 가능 여부를 안전하게 확인하기 위해 try-except를 사용한다.
try:
# customized_konlpy의 Twitter 형태소 분석기를 불러온다.
from ckonlpy.tag import Twitter
# Twitter 형태소 분석기 객체를 생성한다.
twitter = Twitter()
# 사용자 사전 추가 전 형태소 분석 결과를 출력한다.
print("사용자 사전 추가 전:")
# 기본 형태소 분석 결과를 출력한다.
print(twitter.morphs("은경이는 사무실로 갔습니다."))
# 사용자 사전에 '은경이'라는 단어를 명사로 추가한다.
twitter.add_dictionary("은경이", "Noun")
# 사용자 사전 추가 후 형태소 분석 결과를 출력한다.
print("\n사용자 사전 추가 후:")
# 사용자 사전이 반영된 형태소 분석 결과를 출력한다.
print(twitter.morphs("은경이는 사무실로 갔습니다."))
# customized_konlpy가 없거나 Java 환경 문제가 있으면 노트북 실행이 중단되지 않도록 처리한다.
except Exception as error:
# 선택 사항 코드를 건너뛰었다는 안내 메시지를 출력한다.
print("customized_konlpy 실행을 건너뜁니다.")
# 발생한 오류 내용을 출력하여 원인을 확인할 수 있게 한다.
print("오류 내용:", error)
# 설치가 필요한 경우 사용할 수 있는 명령어를 안내한다.
print("\n필요한 경우 다음 명령을 별도 셀에서 실행하세요:")
# 설치 명령어를 출력한다.
print("!pip install customized_konlpy")
BBC_RNN_Classifier 프로젝트 코드도 분석해보자.
모두 import한다.
from app.config import Config
from app.predict import load_artifacts, predict_text
from app.train import train_model
main.py
import한 객체를 사용한 파이프라인.
Config 전역 설정 객체 생성
train_model()
load_artifacts()
sample_news로 predict_text().
"""PyCharm에서 바로 실행할 수 있는 BBC 기사 RNN 분류 프로젝트 진입점."""
from app.config import Config
from app.predict import load_artifacts, predict_text
from app.train import train_model
if __name__ == "__main__":
# 프로젝트 전역 설정 객체를 생성한다.
config = Config()
# 샘플 BBC 기사 데이터로 LSTM 분류 모델을 학습하고 모델 파일을 저장한다.
train_model(config)
# 저장된 모델과 단어 사전, 라벨 사전을 다시 불러와 실제 서비스 예측 흐름을 확인한다.
model, metadata = load_artifacts(config)
# 새롭게 분류할 테스트 기사 문장을 준비한다.
sample_news = "The company released a new smartphone app with artificial intelligence security features"
# 테스트 기사 문장을 모델에 입력하여 예측 카테고리를 얻는다.
predicted_label = predict_text(sample_news, model, metadata, config)
# 최종 예측 결과를 화면에 출력한다.
print("\n새 기사:", sample_news)
print("예측 카테고리:", predicted_label)
@dataclass 데이터를 저장하는 클래스르 간편하게 만들기 위한 데코레이터
여러개의 변수 속성을 하나의 객체로 묶어 관리할때 사용
python이 자동으로 __init__ 해 각 변수를 포기화해주니 직접 작성하지않아도된다.
from dataclasses import dataclass
@dataclass
class Config:
max_vocab: int = 5000
max_len: int = 80
embed_dim: int = 64
hidden_dim: int = 64
batch_size: int = 8
epochs: int = 8
learning_rate: float = 0.001
test_size: float = 0.25
random_seed: int = 42
model_path: str = "../models/bbc_lstm_model.py"
train.py를 분석해보자 .
from __future__ import annotations 아직 정의되지않은 클래스나 복잡한 타입도 오류없이 사용할 수 있게 한다.
cpu 스레드를 1개로 제한.
일부 cpu환경시 LSTM 연산이 오래 멈추는 문제를 피하기 위해 MKLDNN비활성화한다. MKLDNN은 oneDNN이라고도 부르는데 Intel CPU에서 딥러닝 연산을 더 빠르게 수행하기 위한 최적화 라이브러리로 원래는 활성화하는 것이 좋지만 일부 환경에서 LSTM을 사용할때 문제가 발생하기도해 학습이 갑자기 멈추거나 Epoch가 진행되지않거나 CPU사용률이 10)%인데 출력이 없는등의 무한대기가 보고된적이 있기때문이다. 조금 느리지만 정상실행되는것이 더 중요함으로.
from __future__ import annotations
import os
import pickle
import random
from typing import Dict, Tuple
import numpy as np
import torch
torch.set_num.threads(1)
torch.backends.mkldnn.enabled = False
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
from torch import nn
from torch.utils.data import Dataset, DataLoader, TensorDataset
from app.config import Config
from app.data import load_sample_data
from app.model import TestLSTMClassifier
from app.preprocess import build_vocab, clean_text, encode_labels, pad_sequences, texts_to_sequences
'Personal > SK 네트웍스 AI 캠프' 카테고리의 다른 글
| SK 네트웍스 AI 캠프 - 3_초거대언어모델(LLM) - Day37_자연어 처리를 위한 번역 모델 구조 (0) | 2026.07.01 |
|---|---|
| SK 네트웍스 AI 캠프 - 3_초거대언어모델(LLM) - Day36_자연어 처리를 위한 언어 모델 (0) | 2026.06.30 |
| [SK네트웍스 Family AI 캠프] 32기 9주차 회고: Day32 ~ Day34 (0) | 2026.06.26 |
| SK 네트웍스 AI 캠프 - 3_초거대언어모델(LLM) - Day34_자연어 처리를 위한 딥러닝 모델 (0) | 2026.06.26 |
| SK 네트웍스 AI 캠프 - 3_초거대언어모델(LLM) - Day33_자연어 처리를 위한 워드 임베딩 (0) | 2026.06.25 |



