자바설치
https://standout.tistory.com/658
자바설치 및 환경변수 설정
우선 java가 설치되어있는지 확인해보자. java를 다운받거나, 보유한 exe를 실행한다. https://www.oracle.com/java/technologies/downloads/ Download the Latest Java LTS Free Subscribe to Java SE and get the most comprehensive Java sup
standout.tistory.com

자연어와 자연어처리
https://standout.tistory.com/1822
자연어와 자연어처리, Natural Language, NLP Natural Language Processing (feat. 정형데이터와 비정형데이터):
정형 데이터: 표, 필드값이 명확함, 숫자/문자 구분 가능, Excel, Python, SQL비정형 데이터: 텍스트기반, 이미지기반, 음성, 영상기반자연데이터는 구조가 없고 형태가 다양하고 분석이 어렵지만 중
standout.tistory.com
정규화 Normalization
다른 단어들을 통합해주는 작업.
표현 통일. 합니다.한다.하다
하나의 단어로 통일하거나(대한민국, 한국, 코리아), 규칙에 따른 표기가 다른 단어를 통합하거나 (USA, US), 대소문자를 통일, 불필요하거나 의미가 너무 짧은 불용어제거, 빈도가 너무 낮은 단어 제거, 길이가 짧거나 의미없는 단어 제거.
전처리: 원본 - 단어 - 의미요소로 분해해 의미있는 요소만 남겨 분석한다. 음성시 발음 억양의 영향으로 텍스트 변환과정이 필요해 분석방법이 다르다.
https://standout.tistory.com/1772
머신러닝/딥러닝에서의 활성화/데이터전처리, 데이터 전처리에서 정규화(스케일링) 여러가지 방
문득 머신러닝/딥러닝을 공부하는데아래의 내용이 반복해서 나오기 시작했다. 뭔가 정리가 필요하다 .0~1 사이 숫자확률정규화스케일링SigmoidSoftmaxMinMaxScaler 활성화함수. Softmax, Sigmoid출력값을 특
standout.tistory.com
영문자연어처리
정제 - 토큰화 - 불용어 제거
정제
단어 집합으로부터 노이즈 데이터를 제거하는 작업, 불필요한 문자/기호 제거
불필요한 문자, 특수문자, 중복 데이터 등 분석에 방해가 되는 노이즈를 제거하는 과정
- 파이썬의 string punctuation은 영어 문장에서 자주 사용되는 특수문자 목록을 제공한다.
- 정규식을 이용한 특수문자 제거 re.sub()
- 대소문자 통일 lower()
https://standout.tistory.com/1823
PyThon 자연어 전처리 - 정제하기 punctuation, lower, re.sub()
정제 단어 집합으로부터 노이즈 데이터를 제거하는 작업, 불필요한 문자/기호 제거불필요한 문자, 특수문자, 중복 데이터 등 분석에 방해가 되는 노이즈를 제거하는 과정https://standout.tistory.com/18
standout.tistory.com
실습예제. 영어문장에서 자주 사용되는 특수문자 목록을 확인, 정규표현식으로 제거
re.sub(r'[^a-zA-Z0-9\s]', '', txt) 특수문자제거
clean_n = re.sub('\n','',txt) 줄바꿈제거
clean_n.lower() 소문자변환
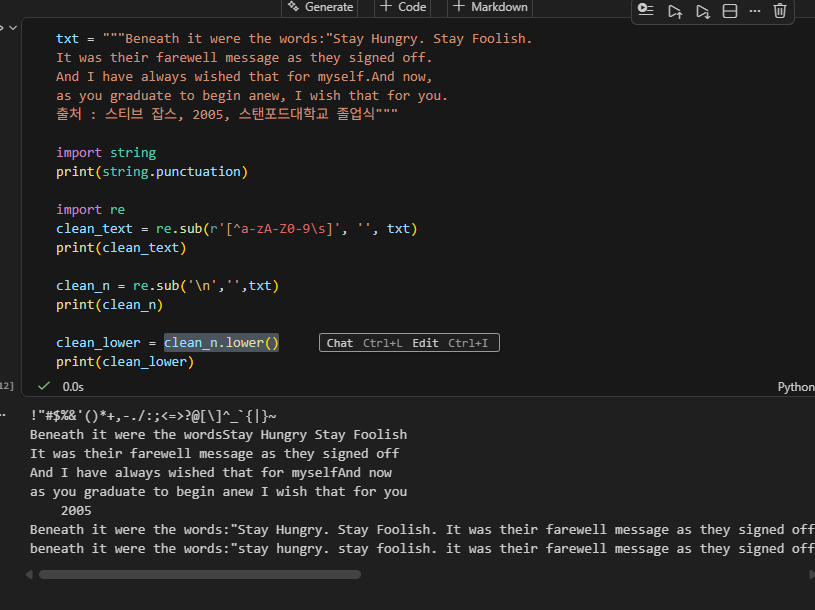
txt = """Beneath it were the words:"Stay Hungry. Stay Foolish.
It was their farewell message as they signed off.
And I have always wished that for myself.And now,
as you graduate to begin anew, I wish that for you.
출처 : 스티브 잡스, 2005, 스탠포드대학교 졸업식"""
import string
print(string.punctuation)
import re
clean_text = re.sub(r'[^a-zA-Z0-9\s]', '', txt)
print(clean_text)
clean_n = re.sub('\n','',txt)
print(clean_n)
clean_lower = clean_n.lower()
print(clean_lower)
토큰화
문장/다니어 단위로 쪼개기
코퍼스 Corpus에서 분리자 Separator를 포함하지 않는 연속적인 문자열 단위로 문장, 단어 단위로 토큰화한다.
https://standout.tistory.com/1824
토큰화란?: 문장/다니어 단위로 쪼개기 (feat.코퍼스 Corpus) - nltk.sent_tokenize, okt.morphs, okt.pos, sent_to
토큰화 문장/다니어 단위로 쪼개기코퍼스 Corpus에서 분리자 Separator를 포함하지 않는 연속적인 문자열 단위로 문장, 단어 단위로 토큰화한다. * 코퍼스 Corpus 자연어 처리에서 사용하는 대량의 텍
standout.tistory.com
실습예제
nltk다운
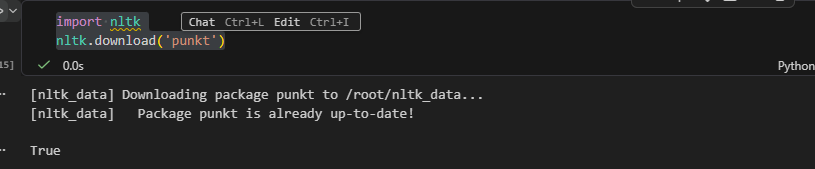

import nltk
nltk.download('punkt')
nltk.download('punkt_tab')https://standout.tistory.com/1825
NLTK의 토큰화 모델이 다운로드되지 않았을 때: Resource punkt not found Resource punkt_tab not found. (feat.nltk.
LookupError Traceback (most recent call last) /tmp/ipykernel_2213/2634140280.py in () ----> 1 sent_tokens = nltk.sent_tokenize(clean_lower) 2 print(sent_tokens) /usr/local/lib/python3.12/dist-packages/nltk/tokenize/__init__.py in sent_tokenize(text, langua
standout.tistory.com
sent_tokens = nltk.sent_tokenize(clean_lower)
print(sent_tokens)
불용어 제거
의미없는 단어 제거
- 전치사, 관사 등 문장이나 문서 특징을 표현하는데 불필요한 단어를 제거하는 단계, 의미전달에 큰 도움이 되지않는 단어를 제거한다.

실습예시
정규표현식, 한글, 영어, 숫자뺴고 삭제하기
cleaned_txt = re.sub('[^가-힣a-zA-Z0-9]', '', txt)
txt = """안녕하세요!!! 😊😊
저는 NLP(Natural Language Processing)를 공부하고 있는 학생입니다.
오늘은 Python 3.12와 NLTK, KoNLPy를 사용해서 자연어 처리 실습을 진행했습니다.
수업 자료는 https://www.example.com 에서 다운로드했고,
문의사항은 student123@test.com 으로 보낼 수 있습니다.
오늘 날씨는 28°C 였고, 점심값은 ₩12,000 이었습니다.
친구는 "NLP is very interesting!!!" 라고 말했습니다.
광고문의 ☎ 010-1234-5678
광고문의 ☎ 010-1234-5678
ㅋㅋㅋㅋ 정말 재밌네요~~~
AI, Machine Learning, Deep Learning, LLM 등을 공부하고 있습니다!!!
특수문자 테스트:
@#$%^&*()_+=[]{}|;:'",.<>?/`~
중복 공백도 포함되어 있습니다.
감사합니다!!!!"""
import string
import re
cleaned_txt = re.sub('[^가-힣a-zA-Z0-9]', '', txt)
print(cleaned_txt)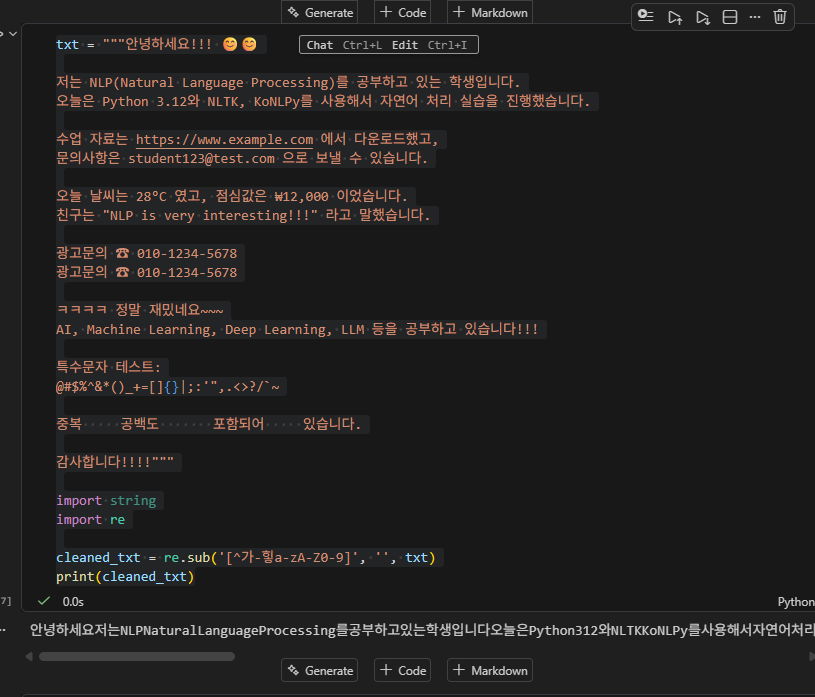
띄어쓰기를 잘 사용하지않아 분석에 오류가 생길 경우
!pip install git+https://github.com/haven-jeon/PyKoSpacing.git

띄어쓰기 복원은 확률적 예측이므로 오류가 발생할 수 있다
from pykospacing import Spacing
spacing = Spacing()
new_sent = spacing(txt_no_spaces)
print(new_sent)
토큰화
!pip install kss 한글 문장 단위 토큰화. kss.split_sentences()
import kss
sent_tokens = kss.split_sentences(new_sent)
print(sent_tokens)

단어단위 토큰화
def tokenizer(words):
tokens = words.split()
return tokens
tokens = tokenizer(new_sent)
print(tokens)
판다스로 읽기
from google.colab import drive
drive.mount('/content/drive')
file_path = '/content/drive/MyDrive/data/sample2.csv'
with open(file_path, 'r', encoding='cp949') as f:
print(f.read())
import pandas as pd
df = pd.read_csv(
"/content/drive/MyDrive/data/sample2.csv",
encoding="cp949"
)
print(df.head())
형태소 Morpheme
의미를 가지는 가장 작은 언어단위, 춤사구분 과정을 통해 문장 문법 구조를 이해할 수 있다 .
명사 조사 명사 조사 부사 형용사 어미
최근 LLM은 형태소 대신 subword기반 토크나이저를 많이 사용한다.
BPE Byte Pair Encoding
자주 등장하는 문자 조합을 하나의 토큰으로 결합.
#BPE Byte Pair Encoding
#자주 등장하는 문자 조합을 하나의 토큰으로 결합.
!pip install subword-nmt
from subword_nmt.learn_bpe import learn_bpe
with open("corpus.txt", "r", encoding="utf-8") as infile:
with open("codes.bpe", "w", encoding="utf-8") as outfile:
learn_bpe(infile, outfile, num_symbols=100)
from subword_nmt.apply_bpe import BPE
with open("codes.bpe", "r", encoding="utf-8") as codes:
bpe = BPE(codes)
result = bpe.process_line(
"중장년의 재취업을 지원하기 위해 취업역량 특화 과정 운영"
)
print(result)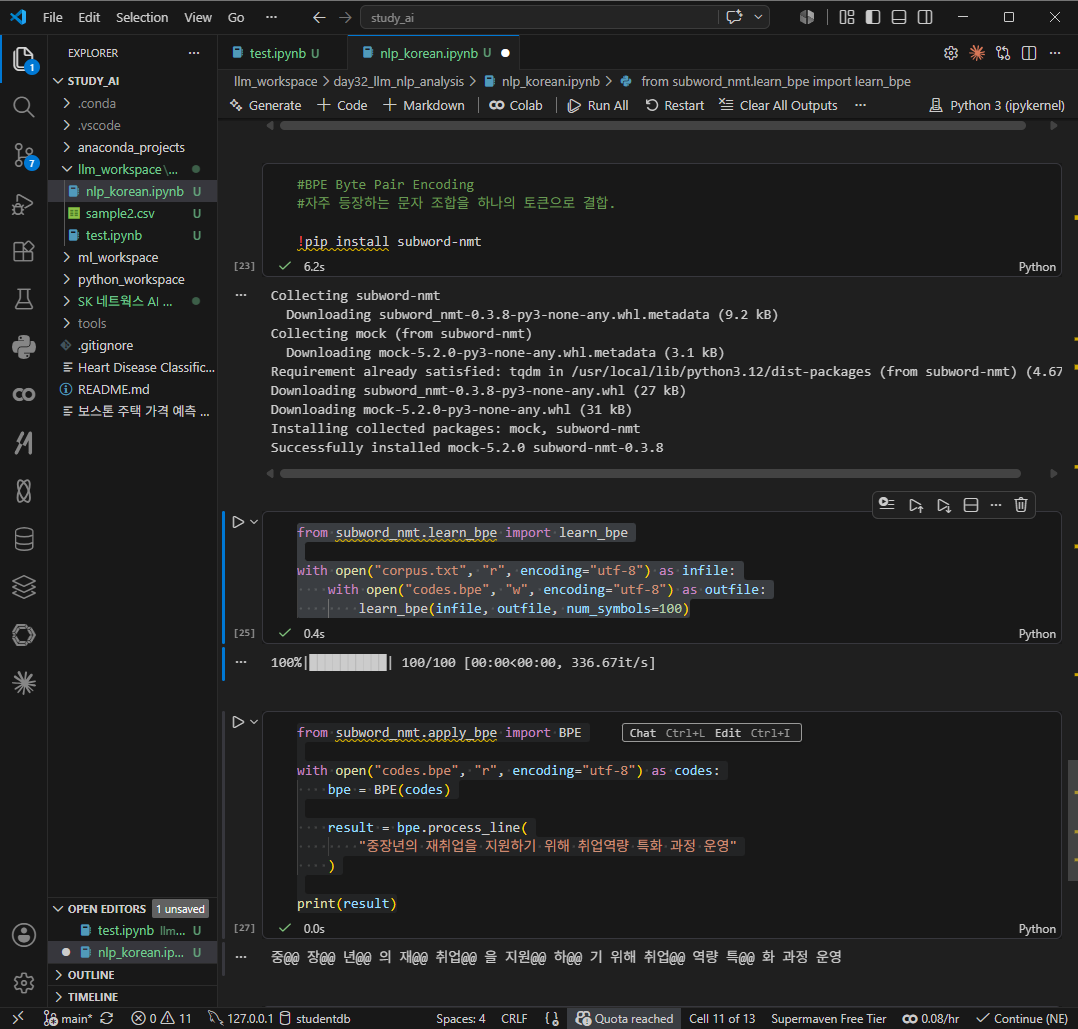
* @는 아직 단어가 끝나지않았다는 의미..
재@@ 취업 = 재 + 취업 로 나뉘어진 토큰이라는 의미.
자주 등장하는 부분 문자열을 학습. 이 문자 조합을 반복적으로 병합하여 subword 단위 토큰을 생성함.
WordPiece
자주 사용되는 단어 조각을 학습
#는 앞 토큰에 이어붙이는 조각.
재
##취업
##을
SentencePiece
공백을 포함해 토큰을 생성하는 방식, 한국어 처리에 많이 사용됨.
KoNLPy
Kkma는 서울대학교 IDS 연구소에서 자바로 작성된 형태학적 분석기 자연어처리.
Komoran 자바 한국어 형태소 분석기 2013년부터 개발함.
한나눔: 자바로 작성된 형태학적 분석기 POS 1999년부터 KAIST에서 개발함.
Okt 스칼라로 쓰여진 한국어 처리기 정규화, 형태소분석, 스테밍. 짧은 트윗에서 긴글도 처리할 수 있다.
## 설치하기
!pip install konlpy
Kkma, Komoran, Hannaum, Okt를 import해
example와 taggers로 세팅해서 출력할것이다.
pos 품사태킹
morphs 형태소만 추출
nouns 명사 추출
# -*- coding: utf-8 -*-
from konlpy.tag import Kkma
from konlpy.tag import Komoran
from konlpy.tag import Hannanum
from konlpy.tag import Okt
example = u'살인 용의자와 변호사가 주고받는 대화로 '\
'인해 달라지는 상황에 따라 얼굴을 바꾸는 배우들의 '\
'다양한 연기를 볼 수 있는 것 또한 장점이다'
taggers = [ ('꼬꼬마', Kkma()),
('코모란', Komoran()),
('트위터', Okt()),
('한나눔', Hannanum())]
####################################################
# 공통 함수 테스트
###################################################
for name,tagger in taggers:
print('%s %s %s'%('-'*10,name,'-'*10))
try:
print(tagger.pos(example)) # 품사 태깅
print(tagger.morphs(example)) # 형태소만 추출
print(tagger.nouns(example)) # 명사 추출
except Exception as e:
print(e)
#####################################################
# 단독 함수 및 옵션 테스트
#####################################################
print('='*50)
# [ 꼬꼬마 ]
print( taggers[0][1].sentences( example ) ) # 문장 추출
# [ 코모란 ]
print('-'*25, '코모란','-'*25)
print( taggers[1][1].pos( phrase=example, flatten=False ) ) # flatten=False이면, 어절 단위 PoS Tagging
print( taggers[1][1].pos( phrase=example, flatten=True ) ) # 차이 비교용
# [ Okt(트위터) ]
print('-'*25, 'otk(트위터)','-'*25)
print( taggers[2][1].pos( phrase=example, norm=True, stem=True) ) # norm=True 이면, 토큰 노멀라이즈, stem=True 이면, 토큰 스테밍
print( taggers[2][1].pos( phrase=example, norm=False, stem=False) ) # 차이 비교용---------- 꼬꼬마 ----------
[('살인', 'NNG'), ('용의자', 'NNG'), ('와', 'JC'), ('변호사', 'NNG'), ('가', 'JKS'), ('주고받', 'VV'), ('는', 'ETD'), ('대화', 'NNG'), ('로', 'JKM'), ('인하', 'VV'), ('어', 'ECS'), ('달라지', 'VV'), ('는', 'ETD'), ('상황', 'NNG'), ('에', 'JKM'), ('따르', 'VV'), ('아', 'ECS'), ('얼굴', 'NNG'), ('을', 'JKO'), ('바꾸', 'VV'), ('는', 'ETD'), ('배우', 'NNG'), ('들', 'XSN'), ('의', 'JKG'), ('다양', 'NNG'), ('하', 'XSV'), ('ㄴ', 'ETD'), ('연기', 'NNG'), ('를', 'JKO'), ('보', 'VV'), ('ㄹ', 'ETD'), ('수', 'NNB'), ('있', 'VV'), ('는', 'ETD'), ('것', 'NNB'), ('또한', 'MAG'), ('장점', 'NNG'), ('이', 'VCP'), ('다', 'EFN')]
['살인', '용의자', '와', '변호사', '가', '주고받', '는', '대화', '로', '인하', '어', '달라지', '는', '상황', '에', '따르', '아', '얼굴', '을', '바꾸', '는', '배우', '들', '의', '다양', '하', 'ㄴ', '연기', '를', '보', 'ㄹ', '수', '있', '는', '것', '또한', '장점', '이', '다']
['살인', '용의자', '변호사', '대화', '상황', '얼굴', '배우', '다양', '연기', '수', '장점']
---------- 코모란 ----------
[('살인', 'NNP'), ('용의자', 'NNP'), ('와', 'JC'), ('변호사', 'NNG'), ('가', 'JKS'), ('주고받', 'VV'), ('는', 'ETM'), ('대화', 'NNG'), ('로', 'JKB'), ('인해', 'NNP'), ('달라지', 'VV'), ('는', 'ETM'), ('상황', 'NNG'), ('에', 'JKB'), ('따르', 'VV'), ('아', 'EC'), ('얼굴', 'NNG'), ('을', 'JKO'), ('바꾸', 'VV'), ('는', 'ETM'), ('배우', 'NNG'), ('들', 'XSN'), ('의', 'JKG'), ('다양', 'XR'), ('하', 'XSA'), ('ㄴ', 'ETM'), ('연기', 'NNG'), ('를', 'JKO'), ('보', 'VV'), ('ㄹ', 'ETM'), ('수', 'NNB'), ('있', 'VV'), ('는', 'ETM'), ('것', 'NNB'), ('또한', 'MAJ'), ('장점', 'NNG'), ('이', 'VCP'), ('다', 'EC')]
['살인', '용의자', '와', '변호사', '가', '주고받', '는', '대화', '로', '인해', '달라지', '는', '상황', '에', '따르', '아', '얼굴', '을', '바꾸', '는', '배우', '들', '의', '다양', '하', 'ㄴ', '연기', '를', '보', 'ㄹ', '수', '있', '는', '것', '또한', '장점', '이', '다']
['살인', '용의자', '변호사', '대화', '인해', '상황', '얼굴', '배우', '연기', '수', '것', '장점']
---------- 트위터 ----------
[('살인', 'Noun'), ('용의자', 'Noun'), ('와', 'Josa'), ('변호사', 'Noun'), ('가', 'Josa'), ('주고받는', 'Verb'), ('대화', 'Noun'), ('로', 'Josa'), ('인해', 'Adjective'), ('달라지는', 'Verb'), ('상황', 'Noun'), ('에', 'Josa'), ('따라', 'Verb'), ('얼굴', 'Noun'), ('을', 'Josa'), ('바꾸는', 'Verb'), ('배우', 'Noun'), ('들', 'Suffix'), ('의', 'Josa'), ('다양한', 'Adjective'), ('연기', 'Noun'), ('를', 'Josa'), ('볼', 'Noun'), ('수', 'Noun'), ('있는', 'Adjective'), ('것', 'Noun'), ('또한', 'Noun'), ('장점', 'Noun'), ('이다', 'Josa')]
['살인', '용의자', '와', '변호사', '가', '주고받는', '대화', '로', '인해', '달라지는', '상황', '에', '따라', '얼굴', '을', '바꾸는', '배우', '들', '의', '다양한', '연기', '를', '볼', '수', '있는', '것', '또한', '장점', '이다']
['살인', '용의자', '변호사', '대화', '상황', '얼굴', '배우', '연기', '볼', '수', '것', '또한', '장점']
---------- 한나눔 ----------
[('살', 'N'), ('이', 'J'), ('ㄴ', 'E'), ('용의자', 'N'), ('와', 'J'), ('변호사', 'N'), ('가', 'J'), ('주', 'P'), ('고', 'E'), ('받', 'P'), ('는', 'E'), ('대화', 'N'), ('로', 'J'), ('인하', 'P'), ('어', 'E'), ('다르', 'P'), ('아', 'E'), ('지', 'P'), ('는', 'E'), ('상황', 'N'), ('에', 'J'), ('따르', 'P'), ('아', 'E'), ('얼굴', 'N'), ('을', 'J'), ('바꾸', 'P'), ('는', 'E'), ('배우들', 'N'), ('의', 'J'), ('다양한', 'N'), ('연기', 'N'), ('를', 'J'), ('보', 'P'), ('ㄹ', 'E'), ('수', 'N'), ('있', 'P'), ('는', 'E'), ('것', 'N'), ('또한', 'M'), ('장점', 'N'), ('이', 'J'), ('다', 'E')]
['살', '이', 'ㄴ', '용의자', '와', '변호사', '가', '주', '고', '받', '는', '대화', '로', '인하', '어', '다르', '아', '지', '는', '상황', '에', '따르', '아', '얼굴', '을', '바꾸', '는', '배우들', '의', '다양한', '연기', '를', '보', 'ㄹ', '수', '있', '는', '것', '또한', '장점', '이', '다']
['살', '용의자', '변호사', '대화', '상황', '얼굴', '배우들', '다양한', '연기', '수', '것', '장점']
==================================================
['살인 용의자와 변호사가 주고받는 대화로 인해 달라지는 상황에 따라 얼굴을 바꾸는 배우들의 다양한 연기를 볼 수 있는 것 또한 장점이다']
------------------------- 코모란 -------------------------
[[('살인', 'NNP'), ('용의자', 'NNP'), ('와', 'JC'), ('변호사', 'NNG'), ('가', 'JKS'), ('주고받', 'VV'), ('는', 'ETM'), ('대화', 'NNG'), ('로', 'JKB'), ('인해', 'NNP'), ('달라지', 'VV'), ('는', 'ETM'), ('상황', 'NNG'), ('에', 'JKB'), ('따르', 'VV'), ('아', 'EC'), ('얼굴', 'NNG'), ('을', 'JKO'), ('바꾸', 'VV'), ('는', 'ETM'), ('배우', 'NNG'), ('들', 'XSN'), ('의', 'JKG'), ('다양', 'XR'), ('하', 'XSA'), ('ㄴ', 'ETM'), ('연기', 'NNG'), ('를', 'JKO'), ('보', 'VV'), ('ㄹ', 'ETM'), ('수', 'NNB'), ('있', 'VV'), ('는', 'ETM'), ('것', 'NNB'), ('또한', 'MAJ'), ('장점', 'NNG'), ('이', 'VCP'), ('다', 'EC')]]
[('살인', 'NNP'), ('용의자', 'NNP'), ('와', 'JC'), ('변호사', 'NNG'), ('가', 'JKS'), ('주고받', 'VV'), ('는', 'ETM'), ('대화', 'NNG'), ('로', 'JKB'), ('인해', 'NNP'), ('달라지', 'VV'), ('는', 'ETM'), ('상황', 'NNG'), ('에', 'JKB'), ('따르', 'VV'), ('아', 'EC'), ('얼굴', 'NNG'), ('을', 'JKO'), ('바꾸', 'VV'), ('는', 'ETM'), ('배우', 'NNG'), ('들', 'XSN'), ('의', 'JKG'), ('다양', 'XR'), ('하', 'XSA'), ('ㄴ', 'ETM'), ('연기', 'NNG'), ('를', 'JKO'), ('보', 'VV'), ('ㄹ', 'ETM'), ('수', 'NNB'), ('있', 'VV'), ('는', 'ETM'), ('것', 'NNB'), ('또한', 'MAJ'), ('장점', 'NNG'), ('이', 'VCP'), ('다', 'EC')]
------------------------- otk(트위터) -------------------------
[('살인', 'Noun'), ('용의자', 'Noun'), ('와', 'Josa'), ('변호사', 'Noun'), ('가', 'Josa'), ('주고받다', 'Verb'), ('대화', 'Noun'), ('로', 'Josa'), ('인하다', 'Adjective'), ('달라지다', 'Verb'), ('상황', 'Noun'), ('에', 'Josa'), ('따르다', 'Verb'), ('얼굴', 'Noun'), ('을', 'Josa'), ('바꾸다', 'Verb'), ('배우', 'Noun'), ('들', 'Suffix'), ('의', 'Josa'), ('다양하다', 'Adjective'), ('연기', 'Noun'), ('를', 'Josa'), ('볼', 'Noun'), ('수', 'Noun'), ('있다', 'Adjective'), ('것', 'Noun'), ('또한', 'Noun'), ('장점', 'Noun'), ('이다', 'Josa')]
[('살인', 'Noun'), ('용의자', 'Noun'), ('와', 'Josa'), ('변호사', 'Noun'), ('가', 'Josa'), ('주고받는', 'Verb'), ('대화', 'Noun'), ('로', 'Josa'), ('인해', 'Adjective'), ('달라지는', 'Verb'), ('상황', 'Noun'), ('에', 'Josa'), ('따라', 'Verb'), ('얼굴', 'Noun'), ('을', 'Josa'), ('바꾸는', 'Verb'), ('배우', 'Noun'), ('들', 'Suffix'), ('의', 'Josa'), ('다양한', 'Adjective'), ('연기', 'Noun'), ('를', 'Josa'), ('볼', 'Noun'), ('수', 'Noun'), ('있는', 'Adjective'), ('것', 'Noun'), ('또한', 'Noun'), ('장점', 'Noun'), ('이다', 'Josa')]
프로젝트를 만들어 .실습. 전체적으로 돌려보자
# KAIST 말뭉치를 이용해 생성된 사전 분석기
from konlpy.tag import Hannanum
han = Hannanum()
text = u"길동 마트의 흑마늘 양념 치킨이 논란이 되고있다. "
print("KAIST","------"*5)
print(han.analyze(text))
print(han.morphs(text))
print(han.nouns(text))
print(han.pos(text))
from konlpy.tag import Kkma
kkma = Kkma()
print("Kkma","------"*5)
print(kkma.sentences(text))
print(kkma.morphs(text))
print(kkma.nouns(text))
print(kkma.pos(text))
from konlpy.tag import Komoran
kom = Komoran()
print("문장 분리:", kom.morphs(text))
print("형태소 분석:", kom.morphs(text))
print("명사 추출:", kom.nouns(text))
print("품사 태깅:", kom.pos(text))
from konlpy.tag import Okt
okt = Okt()
print("Okt", "------"*5)
print("형태소 분석:", okt.morphs(text))
print("명사 추출:", okt.nouns(text))
print("품사 태깅:", okt.pos(text))
stem=True
동사/형용사를 기본형으로 바꿔준다.
되고 -> 되다.
머물렀던 -> 머무르다.
그치지 -> 그치다.
norm = True
정규화, 비표준어, 반복 표현등을 정규화한다.
되나욬ㅋㅋㅋㅋ -> 되나요
from konlpy.tag import Okt
from konlpy.utils import read_txt
okt = Okt()
text = read_txt('./data/sample.txt', encoding='utf-8')
print('norm= True, stem = True-------------')
mal_list = okt.pos(text, norm=True, stem=True)
print(mal_list)
print('norm= False, stem = False-------------')
mal_list = okt.pos(text, norm=False, stem=False)
print(mal_list)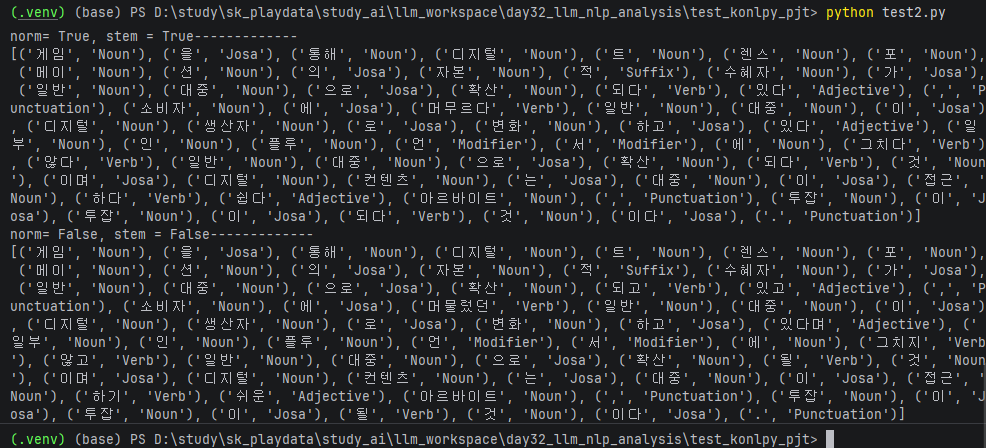
row단위 행 객체를 생성하고 쉼표를 기준으로 데이터를 나누어 각행을 하나씩 꺼내 반복한다.
with open('./data/sample2.csv', "r", encoding="cp949") as raws:
render = csv.reader(raws)
for row in render:
lines.append(row)
print(row)
각 행을 하나의 문장으로 합친 뒤 품사태깅 pos 수행
for line in lines:
# print(''.join(line))
mal_list = okt.pos(' '.join(line))
print(mal_list)
형태소 분석되어 들어있는 리스트를 하나씩 꺼내 출력
for word in mal_list:
print(word)
명사 Noun만 골라서 단어 빈도수를 셈.
for word in mal_list:
if word[1] == 'Noun':
if not word[0] in word_dic:
word_dic[word[0]] = 0
word_dic[word[0]] += 1
print(word_dic)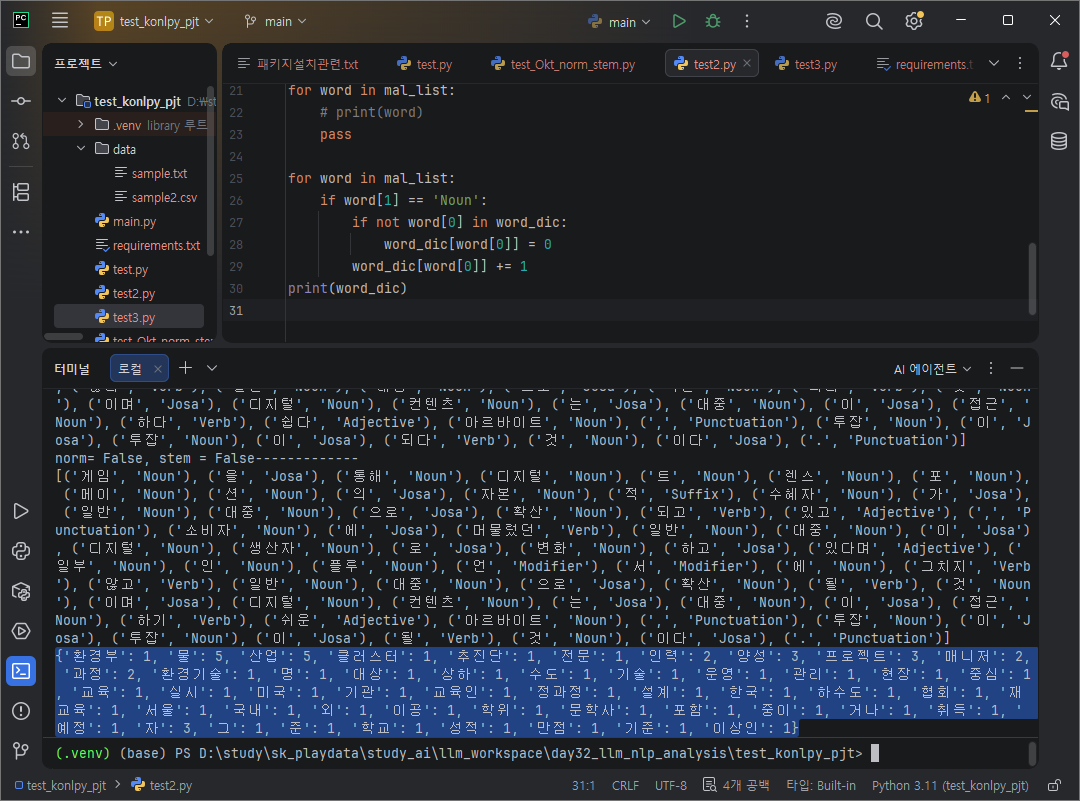
단어빈도수에 내림차순 정리물, 산업이 제일 많다.
# 단어빈도수에 대새 내림차순 정리
keys = sorted(word_dic.items(), key=lambda x : x[1], reverse=True)
for word, count in keys:
print(word, count, end=", ")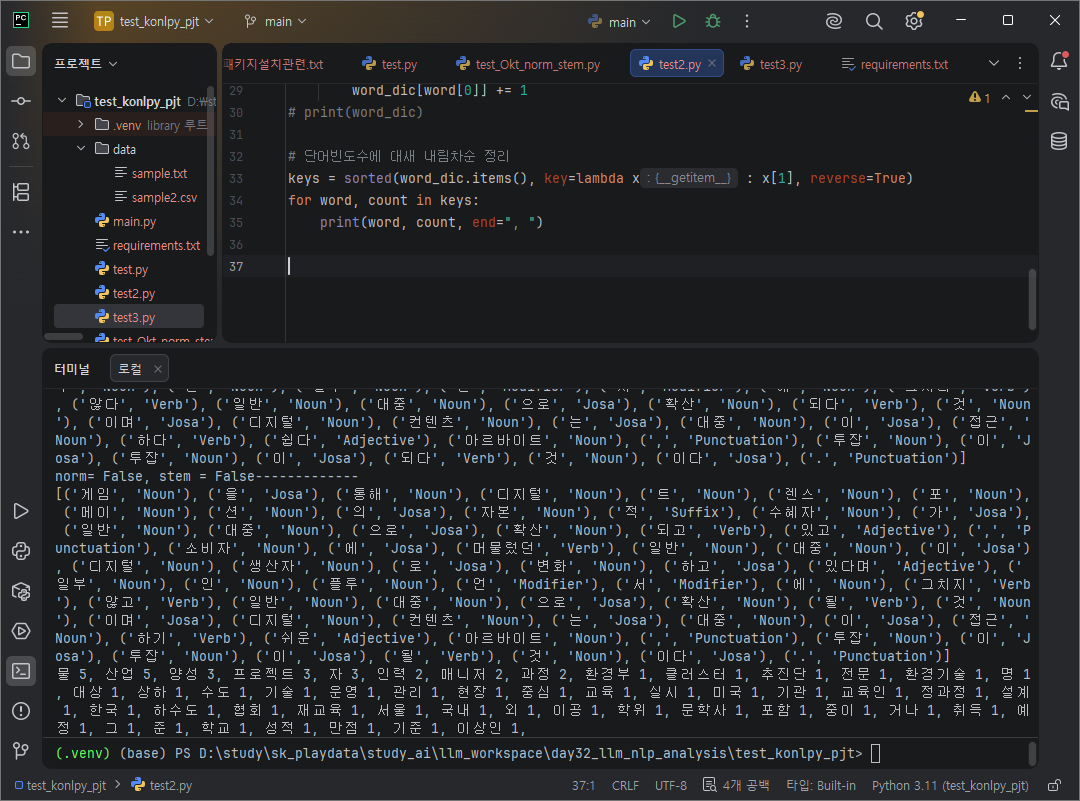
워드클라우드로 출력하기
wordcloud.recolor(color_func=pink_color_func)
Image.open() -> np.array(img) -> mask = imgArray
from PIL import Image
import numpy as np
import random
pink_colors = [
"#FF69B4", # 핫핑크
"#FF85A2",
"#FFB6C1", # 라이트핑크
"#FFC0CB", # 핑크
"#FF9EB5",
"#F8C8DC", # 파스텔핑크
"#E6A8D7" # 연보라핑크
]
def pink_color_func(*args, **kwargs):
return random.choice(pink_colors)
img= Image.open('./images/heart.png')
imgArray = np.array(img)
wordcloud = WordCloud(
font_path = r"C:/Windows/Fonts/malgun.ttf",
width=1000,
height=800,
background_color="#FFF5F7",
colormap = "Set3",
max_font_size= 100,
mask = imgArray
)
wordcloud.generate_from_frequencies(word_dic)
wordcloud.recolor(color_func=pink_color_func)
plt.figure(figsize=(10,10))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()

실습코드 제출
# ============================================
# PyTorch 기반 한국어 워드 클라우드 작성 실습
# ============================================
# 정규표현식을 사용하기 위한 re 모듈을 불러옵니다.
import re
# 단어 빈도 계산을 쉽게 하기 위해 Counter를 불러옵니다.
from collections import Counter
# PyTorch 텐서 처리를 위해 torch를 불러옵니다.
import torch
# 표 형태 데이터 처리를 위해 pandas를 불러옵니다.
import pandas as pd
# 그래프 출력을 위해 matplotlib을 불러옵니다.
import matplotlib.pyplot as plt
# 워드 클라우드 생성을 위해 WordCloud를 불러옵니다.
from wordcloud import WordCloud
# 한국어 형태소 분석을 위해 Okt 형태소 분석기를 불러옵니다.
from konlpy.tag import Okt
# --------------------------------------------
# 1. 예제 텍스트 준비
# --------------------------------------------
# 실제 수업에서는 txt 파일을 open()으로 읽을 수 있지만,
# 여기서는 코드가 바로 실행되도록 예제 문장을 직접 작성합니다.
text = """
인공지능은 데이터를 학습하여 예측과 분류를 수행한다.
딥러닝은 인공지능의 중요한 분야이며, 이미지 분석과 자연어 처리에 많이 사용된다.
자연어 처리는 문장을 분석하고 단어의 의미를 이해하는 기술이다.
워드 클라우드는 텍스트에서 자주 등장하는 단어를 크게 보여주는 시각화 방법이다.
데이터 분석에서는 단어 빈도를 계산하고 중요한 키워드를 찾는 과정이 필요하다.
머신러닝과 딥러닝 모델은 데이터 품질에 따라 성능이 크게 달라진다.
"""
# --------------------------------------------
# 2. 정규표현식으로 불필요한 문자 제거
# --------------------------------------------
# 한글과 공백을 제외한 모든 문자를 제거하는 정규표현식 패턴입니다.
# ^는 제외를 의미하고, ㄱ-ㅎㅏ-ㅣ가-힣은 한글 범위를 의미합니다.
# 여러 개의 공백을 하나의 공백으로 정리합니다.
clean_text = re.sub('[^가-힣a-zA-Z0-9]', '', text)
# 정제된 텍스트를 확인합니다.
print("정제된 텍스트:")
print(clean_text)
# --------------------------------------------
# 3. Okt 형태소 분석기 생성
# --------------------------------------------
# Okt 객체를 생성합니다.
# Okt는 한국어 문장에서 명사, 동사, 형용사 등을 분리할 수 있습니다.
okt = Okt()
print(okt.morphs(clean_text))
# --------------------------------------------
# 4. 명사 추출
# --------------------------------------------
# nouns() 함수는 문장에서 명사만 추출합니다.
print(okt.nouns(clean_text))
# 한 글자 단어는 의미가 약한 경우가 많기 때문에 두 글자 이상만 남깁니다.
# 추출된 명사를 확인합니다.
nouns = okt.nouns(clean_text)
print("\n추출된 명사:")
print(nouns)
# --------------------------------------------
# 5. 단어를 숫자 ID로 변환
# --------------------------------------------
# 중복을 제거한 단어 목록을 정렬하여 vocabulary를 만듭니다.
vocab = sorted(set(nouns))
# 단어를 숫자 인덱스로 바꾸기 위한 딕셔너리를 만듭니다.
word_to_id = {word: idx for idx, word in enumerate(vocab)}
# 각 명사를 숫자 ID로 변환합니다.
word_ids = [word_to_id[word] for word in nouns]
# 숫자 ID 리스트를 PyTorch 텐서로 변환합니다.
import torch
word_ids_tensor = torch.tensor(word_ids)
# --------------------------------------------
# 6. PyTorch로 단어 빈도 계산
# --------------------------------------------
# torch.bincount()는 각 숫자 ID가 몇 번 나왔는지 계산합니다.
word_counts_tensor = torch.bincount(word_ids_tensor)
# PyTorch 텐서를 파이썬 딕셔너리 형태로 변환합니다.
word_freq = {
vocab[i]: int(word_counts_tensor[i].item())
for i in range(len(vocab))
}
# 빈도수가 높은 순서대로 정렬합니다.
word_freq_sorted = dict(sorted(word_freq.items(), key=lambda x : x[1], reverse=True))
# 빈도 결과를 출력합니다.
print("\n단어 빈도:")
print(word_freq_sorted)
# --------------------------------------------
# 7. pandas로 상위 단어 확인
# --------------------------------------------
# 단어 빈도 딕셔너리를 pandas Series로 변환합니다.
import pandas as pd
word_series = pd.Series(word_freq_sorted)
# 상위 10개 단어를 출력합니다.
print("\n상위 단어:")
print(word_series.head(10))
# --------------------------------------------
# 8. 한글 폰트 경로 설정
# --------------------------------------------
# Windows 사용자는 보통 아래 경로를 사용할 수 있습니다.
# Colab에서는 별도 한글 폰트 설치가 필요할 수 있습니다.
font_path = "C:/Windows/Fonts/malgun.ttf"
# --------------------------------------------
# 9. 워드 클라우드 생성
# --------------------------------------------
# WordCloud 객체를 생성합니다.
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
import random
pink_colors = [
"#FF69B4", # 핫핑크
"#FF85A2",
"#FFB6C1", # 라이트핑크
"#FFC0CB", # 핑크
"#FF9EB5",
"#F8C8DC", # 파스텔핑크
"#E6A8D7" # 연보라핑크
]
def pink_color_func(*args, **kwargs):
return random.choice(pink_colors)
img= Image.open('./images/heart.png')
imgArray = np.array(img)
wc = WordCloud(
font_path = r"C:/Windows/Fonts/malgun.ttf",
width=1000,
height=800,
background_color="#FFF5F7",
colormap = "Set3",
max_font_size= 100,
mask = imgArray
)
wc.generate_from_frequencies(word_series)
wc.recolor(color_func=pink_color_func)
# --------------------------------------------
# 10. 워드 클라우드 출력
# --------------------------------------------
# 그래프 크기를 설정합니다.
plt.figure(figsize=(12, 8))
# 워드 클라우드 이미지를 화면에 표시합니다.
plt.figure(figsize=(10,10))
# 축 눈금을 제거합니다.
plt.axis("off")
# 제목을 설정합니다.
plt.title("Word Cloud")
plt.imshow(wc)
# 그래프를 출력합니다.
plt.show()'Personal > SK 네트웍스 AI 캠프' 카테고리의 다른 글
| SK 네트웍스 AI 캠프 - 3_초거대언어모델(LLM) - Day34_자연어 처리를 위한 딥러닝 모델 (0) | 2026.06.26 |
|---|---|
| SK 네트웍스 AI 캠프 - 3_초거대언어모델(LLM) - Day33_자연어 처리를 위한 워드 임베딩 (0) | 2026.06.25 |
| [SK네트웍스 Family AI 캠프] 32기 8주차 회고: Day27 ~ Day31 (0) | 2026.06.20 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day31_AI 모델 검증을 통한 고도화 (0) | 2026.06.19 |
| SK 네트웍스 AI 캠프 - 2 _데이터 분석과 머신러닝 / 딥러닝 - Day30_AI 모델 검증 및 평가 (0) | 2026.06.19 |



